目录
[1.1 网络重试是幂等性的根本驱动力](#1.1 网络重试是幂等性的根本驱动力)
[1.2 HTTP 语义幂等 vs 业务语义幂等](#1.2 HTTP 语义幂等 vs 业务语义幂等)
[1.3 副作用的幂等才是真正的硬仗](#1.3 副作用的幂等才是真正的硬仗)
[1.4 天然幂等 vs 合成幂等](#1.4 天然幂等 vs 合成幂等)
[2.1 Snowflake ID 的精妙设计](#2.1 Snowflake ID 的精妙设计)
[2.2 时钟为什么会回拨?](#2.2 时钟为什么会回拨?)
[2.3 三种应对策略](#2.3 三种应对策略)
[2.4 更根本的思考:去掉时钟依赖](#2.4 更根本的思考:去掉时钟依赖)
[3.1 单机隔离级别的本质](#3.1 单机隔离级别的本质)
[3.2 分布式下,隔离级别的代价陡增](#3.2 分布式下,隔离级别的代价陡增)
[3.3 锁粒度的分布式影响](#3.3 锁粒度的分布式影响)
[3.4 幻读在分布式下的特殊形态](#3.4 幻读在分布式下的特殊形态)
[四、性能 vs 一致性:没有免费的午餐](#四、性能 vs 一致性:没有免费的午餐)
[4.1 CAP 定理的实践解读](#4.1 CAP 定理的实践解读)
[4.2 2PC:强一致,但代价是什么?](#4.2 2PC:强一致,但代价是什么?)
[4.3 TCC:2PC 的应用层变形](#4.3 TCC:2PC 的应用层变形)
[4.4 Saga:长事务的现实选择](#4.4 Saga:长事务的现实选择)
[4.5 如何选择:不是技术问题,是业务问题](#4.5 如何选择:不是技术问题,是业务问题)
一、幂等性:比你想象的更复杂
幂等性的教科书定义极其简洁:一个操作执行一次和执行多次,产生的结果相同。但"结果相同"这四个字,在分布式系统里藏着巨大的复杂度。
1.1 网络重试是幂等性的根本驱动力
为什么需要幂等性?因为分布式系统中有一条铁律:你永远无法区分"请求没有送达"和"请求送达了但响应丢了"。
面对这两种情况,调用方的选择只有两个:要么放弃这次调用(承担丢失风险),要么重试(承担重复执行风险)。消息队列给你"at-least-once"的交付保证,意味着它选择了重试------把幂等性的责任推给了消费者。TCP 协议本身在传输层保证了幂等性;但 HTTP 语义层没有,你的支付接口会被重复调用。
幂等性的本质是:让接收方有能力识别并安全地处理重复请求。
1.2 HTTP 语义幂等 vs 业务语义幂等
HTTP 规范定义了方法级的幂等性:GET、HEAD、PUT、DELETE 是幂等的;POST 不是。但这只是协议层的约定,不是实现保证。
真正的业务幂等性需要额外的设计。Stripe 的做法是标准范本:客户端在创建支付请求时,在 Header 里带上一个 Idempotency-Key(通常是 UUID)。服务端将这个 key 与请求结果绑定持久化。任何携带相同 key 的重复请求,直接返回缓存的原始响应,不再执行业务逻辑。
这个方案的精妙之处在于:它把"是否已处理"的判断权,完全交给了服务端,而不依赖客户端的去重逻辑。
java
// 伪代码:Token 式幂等保护
String key = request.getHeader("Idempotency-Key");
IdempotencyRecord record = store.get(key);
if (record != null) {
return record.getCachedResponse(); // 直接返回,不重复执行
}
Response result = doBusinessLogic(request);
store.set(key, result, TTL_24H); // 持久化结果
return result;1.3 副作用的幂等才是真正的硬仗
核心业务操作的幂等性相对好实现------用唯一键约束就能拦截大多数重复写入。真正难的是副作用的幂等性。
一次"扣款成功"的操作,可能伴随:发送短信、推送通知、更新用户积分、触发下游风控系统、写 Kafka 消息。这些副作用中,哪些是幂等的,哪些不是?
严格的实现要求:所有副作用都要在核心业务状态成功变更后才触发,且触发前要检查是否已经触发过。这意味着你要么对每个副作用单独做幂等保护,要么引入一个"已发送副作用"的状态标记。这个细节在工程实践中极其容易被忽视------它不会在冒烟测试中暴露,只会在生产环境压力下偶发重复通知。
1.4 天然幂等 vs 合成幂等
有些操作天然就是幂等的:将某字段设置为固定值(UPDATE t SET status=2 WHERE id=1)天然幂等;将某字段累加值(UPDATE t SET balance=balance-100)天然不幂等。
工程上的一个重要原则:尽量将非幂等操作改写为幂等操作。扣款不要写成"余额减 N",而要写成"将余额设置为(当前余额 - N),但仅当余额 > N 且本次操作 ID 未处理过时"。这样即使重复执行,第二次也会因为操作 ID 已存在而被拦截。
二、时钟回拨:雪花算法的隐秘地雷
2.1 Snowflake ID 的精妙设计
Twitter 2010 年提出的 Snowflake 算法,用一个 64 位整数编码了"时间 + 机器 + 序列"三个维度,生成全局唯一、单调递增(在同一机器上)、不依赖中心节点的分布式 ID。

这个设计中,41 位时间戳是整个算法的"脊梁"。ID 的单调递增性完全依赖于时间戳字段单调递增------而这个前提,在现实中并不总是成立。
2.2 时钟为什么会回拨?
时钟回拨(Clock Skew / Clock Drift)的成因主要有三类:
NTP 时间同步是最常见的来源。分布式集群中每台机器的硬件时钟都会产生漂移,NTP 协议定期将本地时钟与时间服务器校准。当本地时钟比标准时间快时,NTP 会将时钟"拨回"------这个操作对 Snowflake 算法而言是灾难性的。
虚拟化环境是第二个来源。宿主机和虚拟机之间的时钟同步机制(如 VMware Tools 的时钟同步)会导致 VM 内的时钟在迁移、快照恢复后出现突然跳变。
夏令时切换在部分国家/地区会造成时钟回拨整整一小时------这是最极端的情况。
2.3 三种应对策略
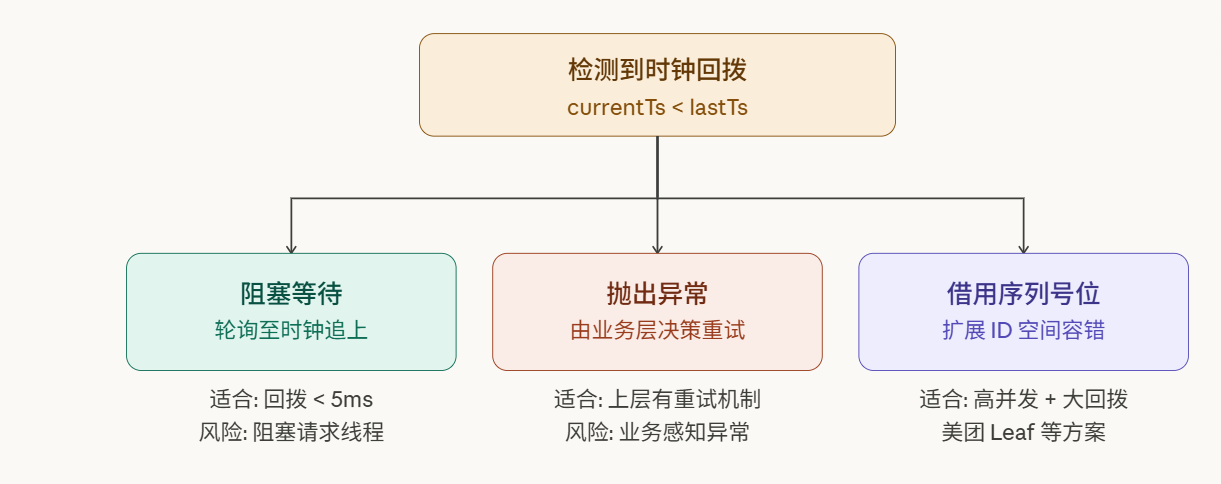
三种策略没有绝对的优劣,选择取决于业务的容忍度。阻塞等待 是最保守的方案,适合回拨幅度极小(< 5ms)且业务允许短暂延迟的场景;抛出异常 将决策权交给调用方,对框架设计者来说是最正确的选择,但要求上层做好重试;借用序列号位是最激进也最工程化的方案------在回拨期间,将部分序列号位临时用于扩展 ID 空间,以确保连续生成不中断,代表实现有美团 Leaf 和百度 UidGenerator。
2.4 更根本的思考:去掉时钟依赖
一个更激进的问题是:能否完全摆脱对时钟的依赖?答案是可以。美团 Leaf 的 Segment 模式和数据库号段方案,完全用"数据库中的号段"替代时钟,以数据库的单点序列性换取 ID 的唯一性。代价是引入了数据库依赖,但彻底消除了时钟回拨问题。这是一个典型的"用可靠依赖替代不可靠依赖"的架构决策。
三、事务隔离级别在分布式下的变形
3.1 单机隔离级别的本质
SQL 标准定义了四个隔离级别,本质上是对"读写并发干扰程度"的渐进式限制。

3.2 分布式下,隔离级别的代价陡增
在单机数据库里,实现 Repeatable Read 只需要在事务开始时创建一个本地快照(MVCC 的 ReadView)。代价是内存中多维护一份版本链。这在单进程内是可接受的。
但在分布式数据库里,"事务级快照"意味着:这个快照需要在所有参与节点之间全局一致。每个读操作都需要从全局时钟(或 Lamport 时钟)获取一个全局时间戳,以此确定哪些版本对当前事务可见。Google Spanner 的 TrueTime 方案为这个问题提供了一个硬件级解法(GPS + 原子钟),而普通分布式数据库往往需要通过中心化的 TSO(Timestamp Oracle)服务来提供全局单调递增时间戳------这个 TSO 本身就是性能瓶颈和单点风险。
3.3 锁粒度的分布式影响
锁粒度(Lock Granularity)在单机上的选择是:行锁性能好但开销大,表锁性能差但开销小。在分布式环境下,这个选择多了一个新维度:锁的位置。
行锁需要在数据所在的节点上持有,一个跨节点的事务要同时持有多个节点上的行锁,而且这些锁的申请必须以防死锁的顺序进行。任何一个节点的网络抖动,都会让整个事务的锁等待时间成倍增加。
这就是为什么分布式数据库通常推荐使用范围分区(而不是随机哈希分区)来存储相关联的数据------将会被同一事务访问的行尽量放在同一分片,将分布式事务降级为本地事务,彻底规避跨节点锁的代价。
3.4 幻读在分布式下的特殊形态
在单机 MySQL InnoDB 中,Repeatable Read 通过间隙锁(Gap Lock)来防止幻读。但在分布式 Sharding 场景下,间隙锁只能在单分片上生效。
考虑这个场景:查询所有 age > 18 的用户(数据分布在多个分片),事务 A 在时刻 t1 读到了 100 条记录,期间事务 B 在另一个分片上插入了 10 条 age=20 的数据,事务 A 在 t2 再次执行同样的查询------结果变成了 110 条。这是跨分片幻读,传统的间隙锁机制完全无法防御。
解决这个问题需要在应用层或分布式数据库层实现全局序列化(Global Serialization),代价极高,大多数业务选择接受这种弱一致性,并在应用层通过版本号或乐观锁来处理冲突。
四、性能 vs 一致性:没有免费的午餐
4.1 CAP 定理的实践解读
CAP 定理说:分布式系统在网络分区(Partition)发生时,无法同时保证一致性(Consistency)和可用性(Availability)。但这个表述过于抽象。工程层面更有指导意义的描述是 PACELC 模型:即使没有网络分区,在延迟(Latency)和一致性之间,系统也必须做出权衡。
分布式事务协议的演化史,就是这个权衡不断被工程化的历史。
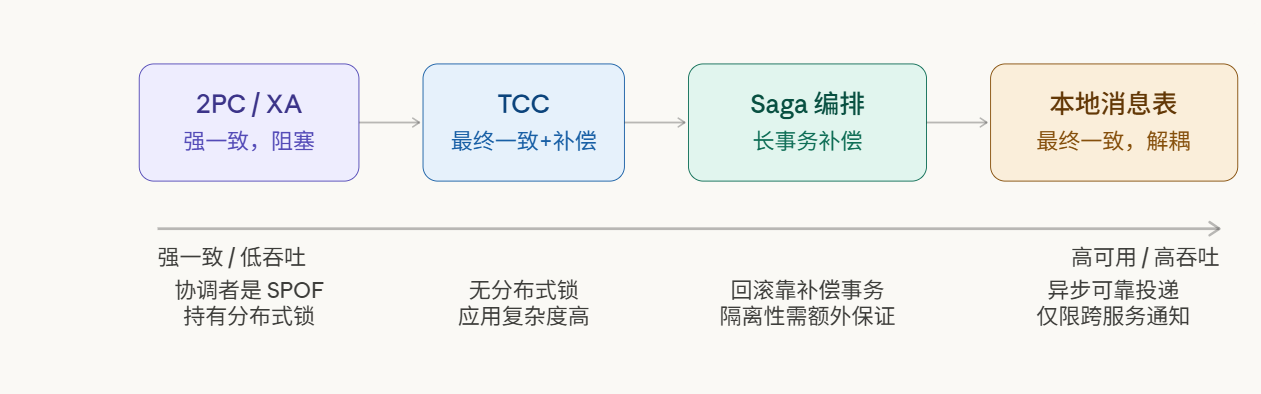
4.2 2PC:强一致,但代价是什么?
2PC(两阶段提交)是所有分布式事务协议的"原型"。它提供了真正的 ACID 语义,但其阻塞特性让它在高并发场景下难以使用。
2PC 最根本的问题不是"慢",而是协调者故障时的不确定状态 。在第二阶段(Commit Phase)开始后,如果协调者在发出 Commit 指令后崩溃,部分参与者收到了 Commit,部分没有------系统进入一个没有任何节点知道"应该提交还是回滚"的不确定窗口。此时所有参与者都持有锁,等待协调者恢复。这个等待没有上限。
3PC 是对 2PC 的改进尝试,加入了超时机制和预提交阶段,但在网络分区时仍然无法完全避免不一致。
4.3 TCC:2PC 的应用层变形
TCC 本质上是"把 2PC 的逻辑从数据库层移到了应用层"。它的核心优势不是一致性更强,而是持有资源锁的时间大幅缩短。
2PC 在整个事务过程中(从 Try 到 Confirm/Cancel)持有数据库行锁;TCC 的 Try 阶段只是"业务层的资源冻结"(比如将订单状态置为"预占"),不持有数据库锁。这意味着其他事务可以读到这个中间状态并做出反应,而不是被阻塞。代价是:你需要自己保证 Try-Confirm-Cancel 三个阶段的业务语义正确,以及第一篇文章讨论的空回滚、悬挂、幂等问题。
4.4 Saga:长事务的现实选择
当一个业务流程跨越多个微服务(机票预订 → 酒店预订 → 租车 → 支付),且每个步骤都可能执行数秒乃至数分钟时,TCC 的"持有预留状态"策略变得不可行------预留 5 分钟的机票座位,会把资源利用率打垮。
Saga 模式接受了这个现实:不尝试实现分布式 ACID,而是用"前向补偿"替代"回滚"。每个步骤执行后,系统记录该步骤的补偿操作(Cancel Booking, Refund Payment...)。一旦某个步骤失败,依次执行之前所有步骤的补偿操作,最终达到"业务上等价于未执行"的状态。
Saga 有两种实现方式。**编排式(Orchestration)**由中心化的 Saga 协调者控制整个流程,优点是流程清晰可追踪,缺点是协调者成为耦合点。**编舞式(Choreography)**各服务只订阅和发布事件,没有中心协调者,优点是松耦合,缺点是整体流程难以追踪和调试。
Saga 的软肋是缺乏隔离性。在补偿执行完成之前,其他事务可以读到中间状态(比如机票已预订但支付失败的状态)。这需要业务层通过"隐藏预留状态"或"允许超卖后补偿"等手段来处理,本质上是把一致性问题推迟并降级为一个业务问题。
4.5 如何选择:不是技术问题,是业务问题
这个问题没有技术层面的标准答案。正确的问法是:这个业务场景对一致性窗口的容忍度是多少?
金融转账:账户余额的一致性窗口必须为零------同一时刻永远不能有钱既不在转出账户又不在转入账户。TCC 是最低要求,甚至需要 XA 或数据库内置的分布式事务。
电商库存:允许"超卖后取消"的场景,Saga 加补偿已经足够。允许短暂超卖的场景,甚至只需要最终一致的消息队列。
日志、审计:最终一致就足够了,本地消息表或 Outbox Pattern 是最轻量的选择。
五、四问背后的统一逻辑
读完这四个问题,可以发现一条贯穿始终的主线:分布式系统的所有难题,都是"在不可靠的基础设施上构建可靠保证"的同一问题的不同切面。
幂等性是对"网络不可靠导致重复调用"的防御;时钟回拨是对"时钟不可靠导致 ID 碰撞"的防御;隔离级别是对"并发执行导致数据干扰"的防御;一致性-性能权衡是对"网络延迟导致分布式操作无法原子化"的设计取舍。
它们共享同一套应对哲学:
不要假设基础设施的可靠性,要在不可靠之上主动设计可靠性(重要)。 不要假设消息只会送达一次,就有了幂等性设计。不要假设时钟单调递增,就有了时钟回拨处理。不要假设分布式操作是原子的,就有了 TCC、Saga 的补偿机制。
这些设计的终极目标不是"让系统不出错",而是"让系统出错时,依然能以可预测的方式处理错误,并最终达到正确的状态"。这,才是分布式系统工程的真正内核。