在大数据开发中,我们很少Linux 终端里敲写长篇的 SQL。而通过 IDEA 等集成开发环境连接 Hive,不仅能高亮提示代码,还能提升开发和调试自定义函数的效率。
这一次我将详细介绍如何使用 IDEA 可视化连接 Hive,并手把手带你走通 UDF 开发的完整流程。
一、创建 Maven 项目
在开始编写 UDF 代码之前,我们需要先在 IDEA 中创建一个基础的 Maven 工程。
打开 IDEA,点击新建项目,构建系统选择 Maven,填写好项目名称,点击创建即可。
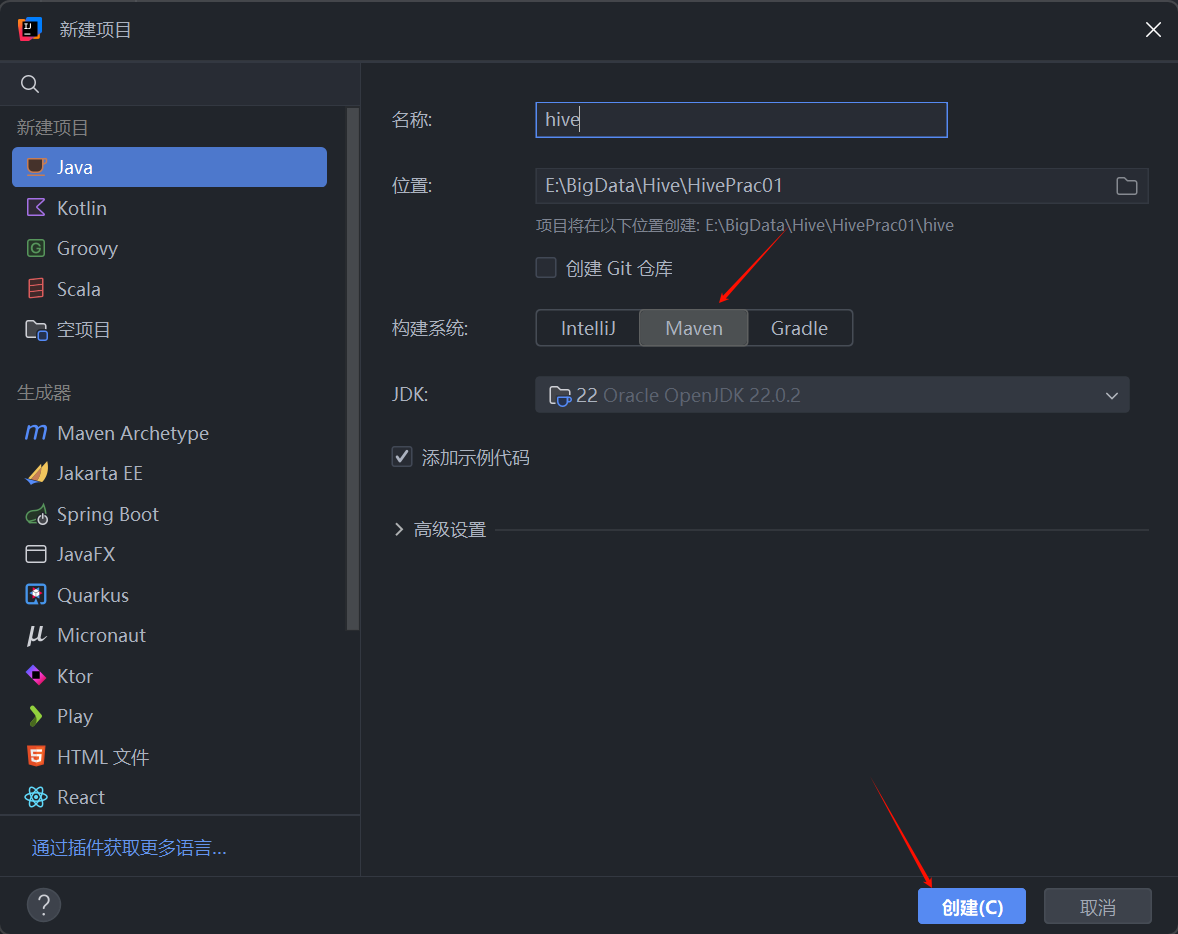
如果对 IDEA 创建 Maven 项目的过程还不熟悉,或者需要配置完整的本地大数据开发环境,建议大家先去阅读我之前写的文章《二、Spark 开发环境搭建 IDEA + Maven 及 WordCount 案例实战》这里面有详细写如何配置maven,感兴趣的可以去看看。
二、 IDEA 可视化连接 Hive
为了能在 IDEA 中直接执行 HQL 语句,我们需要利用 IDEA 自带的 Database 工具连接到虚拟机里的 HiveServer2 服务。
第一步 :先点击 IDEA 右侧边栏的数据库图标,再点击那个带齿轮的图标。
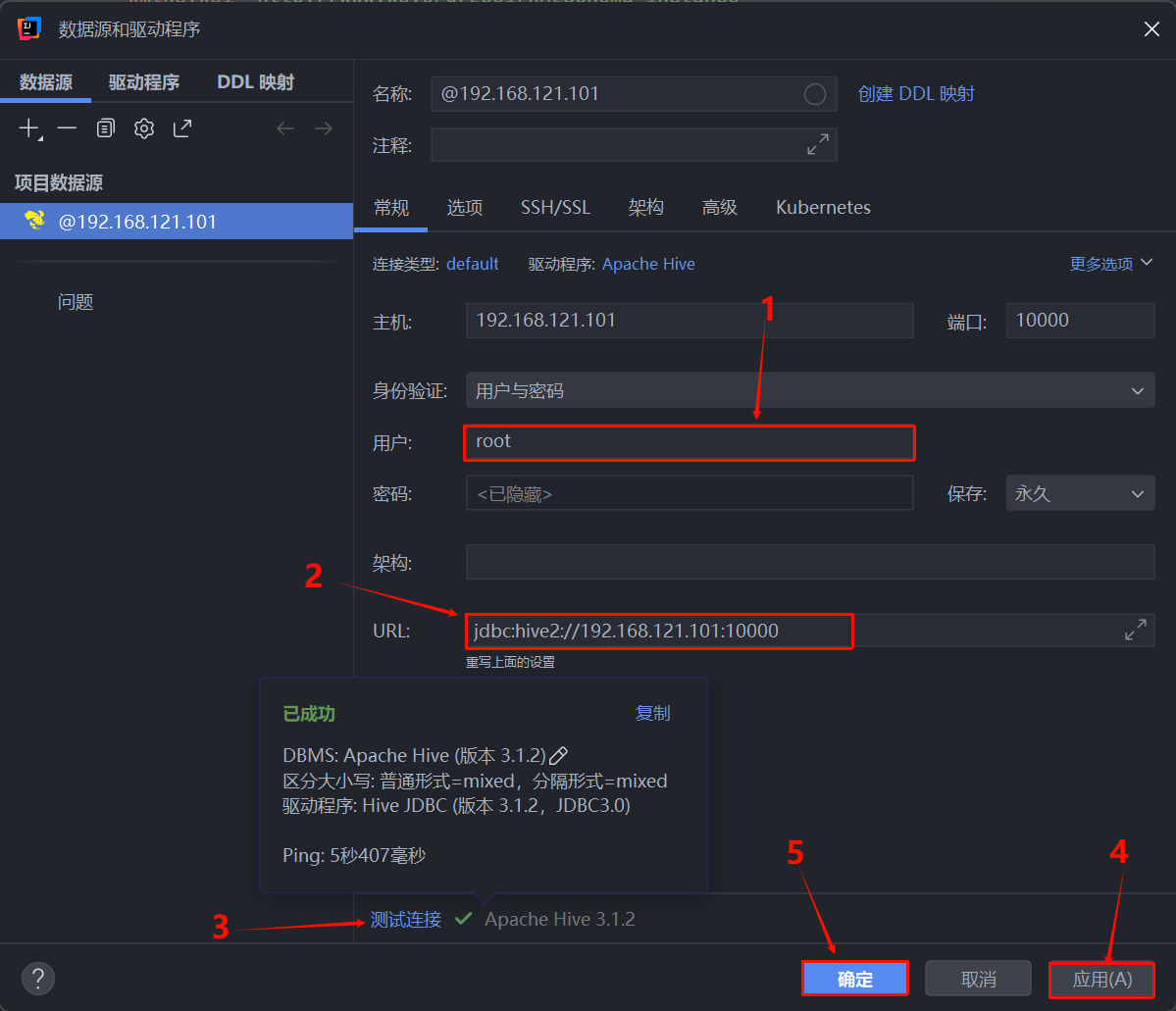
第二步:配置连接参数。
在这里我们需要填写连接 Hive 的核心信息:
1.用户 :填写你虚拟机中启动 Hive 的用户名(通常是
root或hadoop)。
2.URL :按照标准的 JDBC 格式填写,例如jdbc:hive2://192.168.121.101:10000(请务必将 IP 替换为你自己虚拟机的实际 IP 地址,HiveServer2 默认端口为 10000)。
3. 填写完毕后,点击底部的 测试连接 。如果左下角出现了绿色的打勾提示,说明网络打通且连接成功。最后依次点击 应用 和 确定。
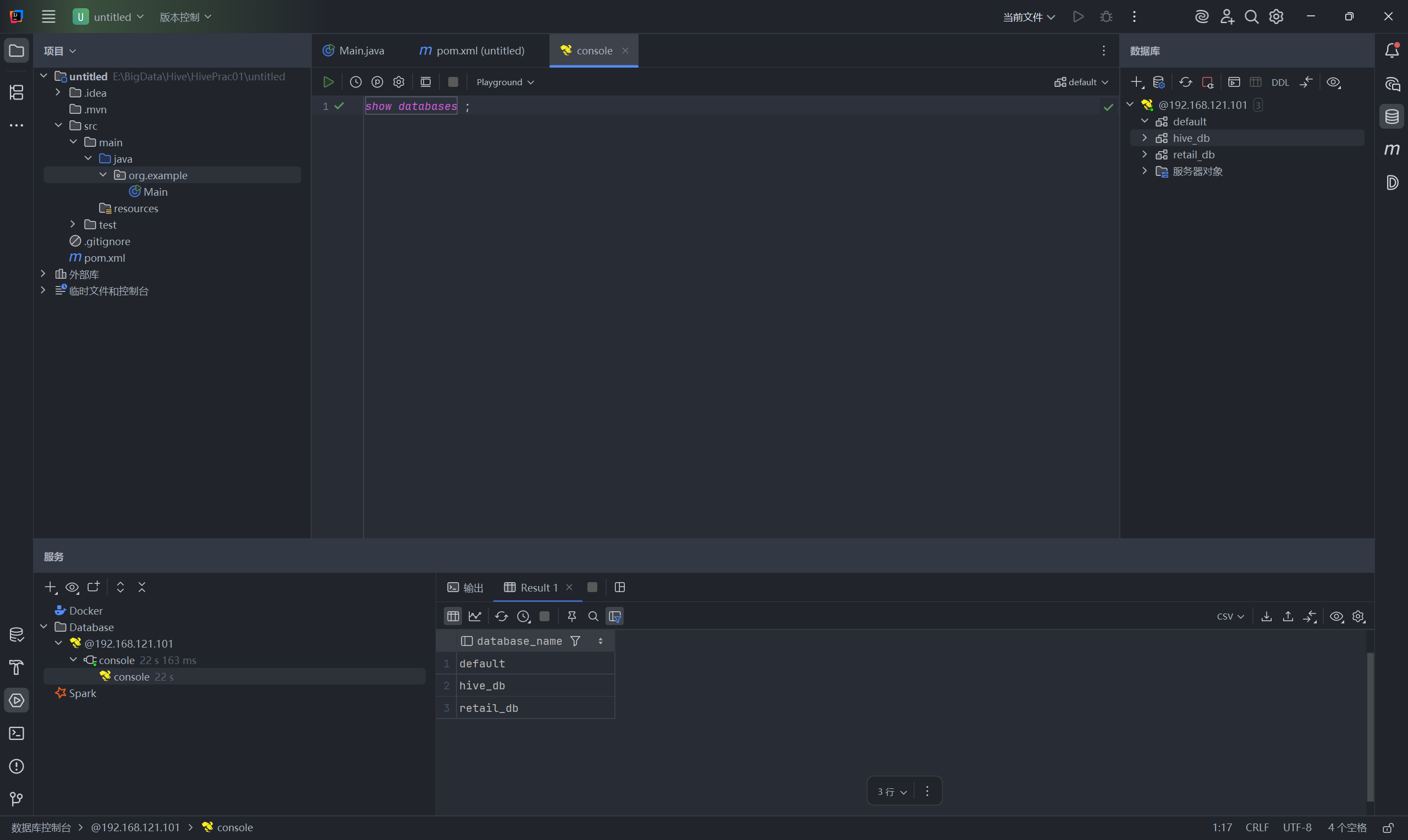
第三步:测试执行环境。
连接成功后,在自动弹出的 Console 控制台中输入测试语句 show databases; 并运行。如果你也在下方看到了 Hive 中的数据库列表,那就说明远程连接已完全,配置完毕。
三、 Hive UDF 开发完整流程
Hive 自带的内置函数虽然丰富,但在处理复杂任务时,依然困难。这时候就需要我们使用 Java 编写用户自定义函数也就是UDF。
UDF 的标准开发流程清晰地分为五步:添加依赖 -> 编写类 -> 打包上传 -> Add Jar -> Create Function。
1. 添加依赖
打开刚才创建的 Maven 项目的 pom.xml 文件,在 <dependencies> 标签中添加 Hive 核心执行库的依赖。注意,这里的 <version> 版本号需要与你 Linux 服务器上安装的 Hive 版本保持一致。
xml
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>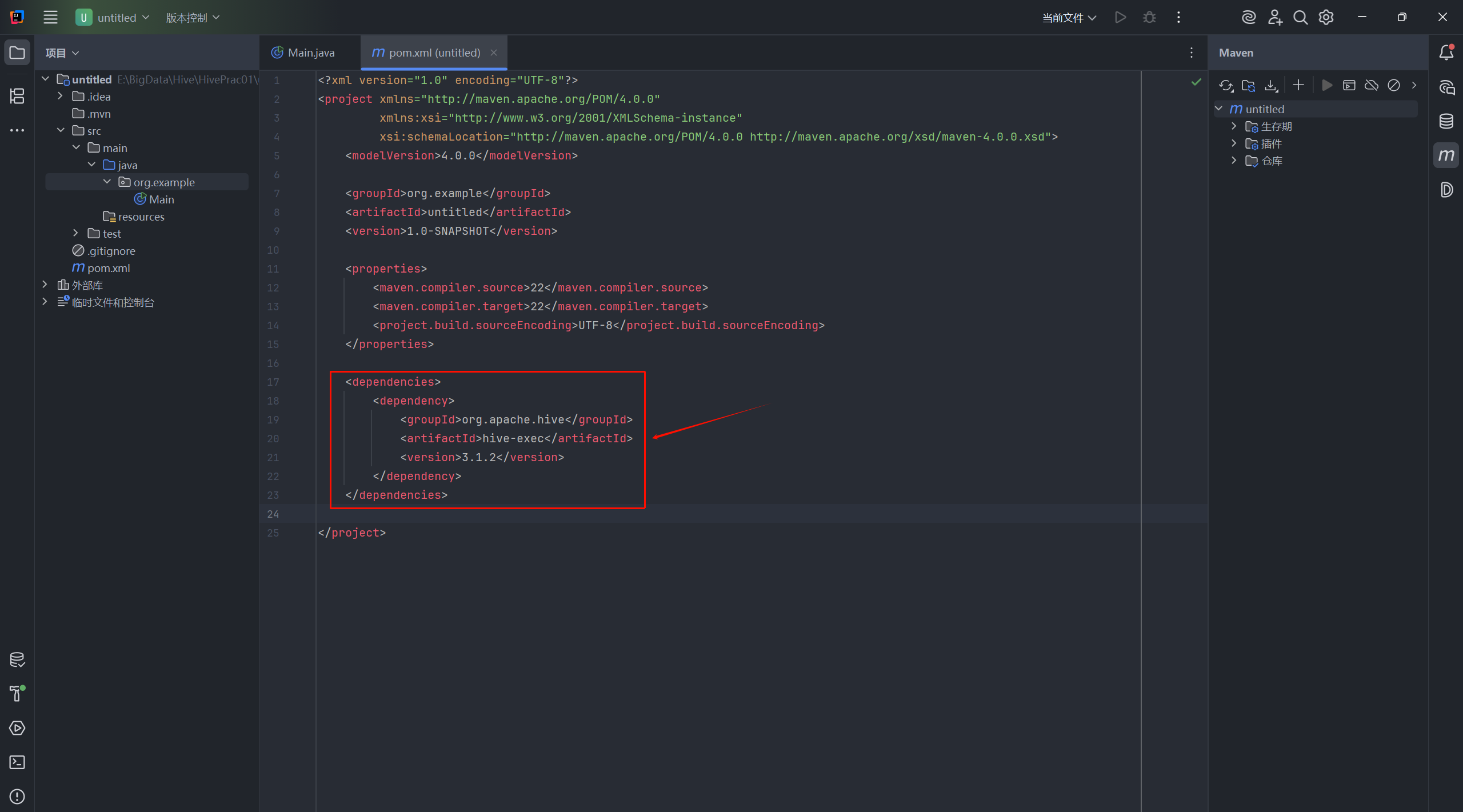
2. 编写 UDF 类
在项目的 src/main/java 目录下创建一个名为 hive_udf 的包,并在其中新建一个 Java 类 DateUDF。
编写 Hive UDF 的核心准则是:必须继承 org.apache.hadoop.hive.ql.exec.UDF 类,并且实现一个或多个名为 evaluate 的公开方法。
下面是计算两个日期字符串相差天数的完整 UDF 代码实现。这段代码不仅计算了时间差,还包含了一个 setDate 辅助方法,专门用来处理和清洗原始业务数据中格式不规范的脏数据。例如自动给个位数的月份补零,以及处理缺省的异常日期。
java
package hive_udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUDF extends UDF {
// 编写UDF统计用户入会时长函数DateUDF
public String evaluate(String arg1,String arg2) throws ParseException {
// TODO 更正原数据中字符串的格式
String date1 = setDate(arg1);
String date2 = setDate(arg2);
// TODO 将字符串类型转换为日期类型
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
Date LOAD_TIME = format.parse(date1);
Date FFP_DATE = format.parse(date2);
// TODO 日期相减,由于相减后单位为毫秒,需要转换成天数
long result = (LOAD_TIME.getTime() - FFP_DATE.getTime())/(24 * 60 * 60 * 1000);
// TODO 返回结果
return String.valueOf(result);
}
public static String setDate(String arg){
String[] argList = arg.split("-");
// TODO 修正部分数据LOAD_TIME的错误(脏数据处理)
if (argList.length!=3){
return "2014-03-31"; // 遇到异常数据给予默认值
}
// 补齐月份或日期前面的 0
for (int i=1; i<argList.length; i++){
if (argList[i].length()<2){
argList[i] = "0" + argList[i];
}
}
String date = argList[0] + "-" + argList[1] + "-" + argList[2];
return date;
}
}3. 打包并上传
Java 代码编写完成后,我们需要将其编译并打包成 Jar 文件,以便丢给后端的 Hive 引擎读取。
点击 IDEA 右侧边栏的 Maven 面板,展开你的项目目录,双击生命期 下的 package 选项开始打包流程。
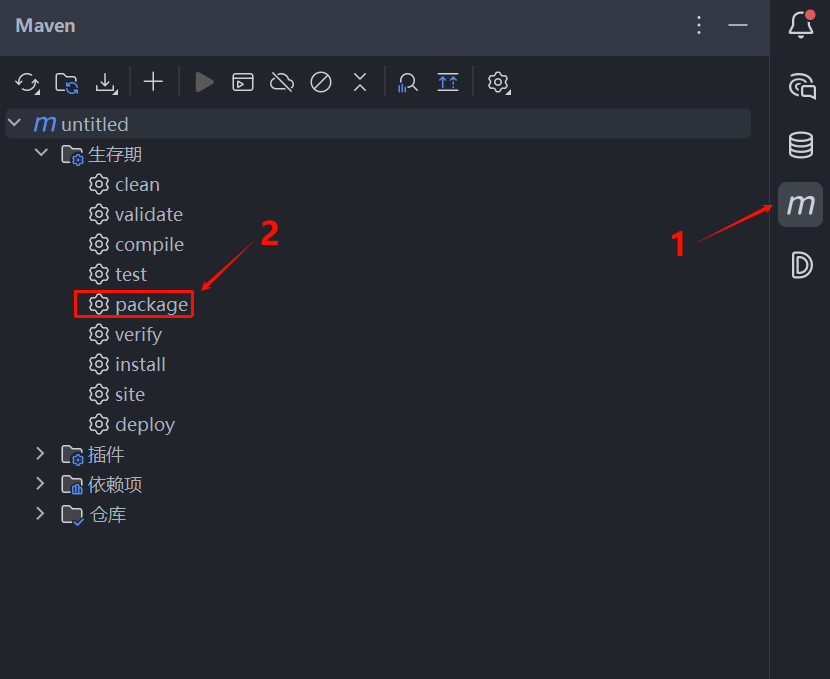
等待控制台输出 BUILD SUCCESS 打包成功后,在项目左侧资源管理器的 target 目录下,你就能找到刚刚编译生成的 Jar 包了。
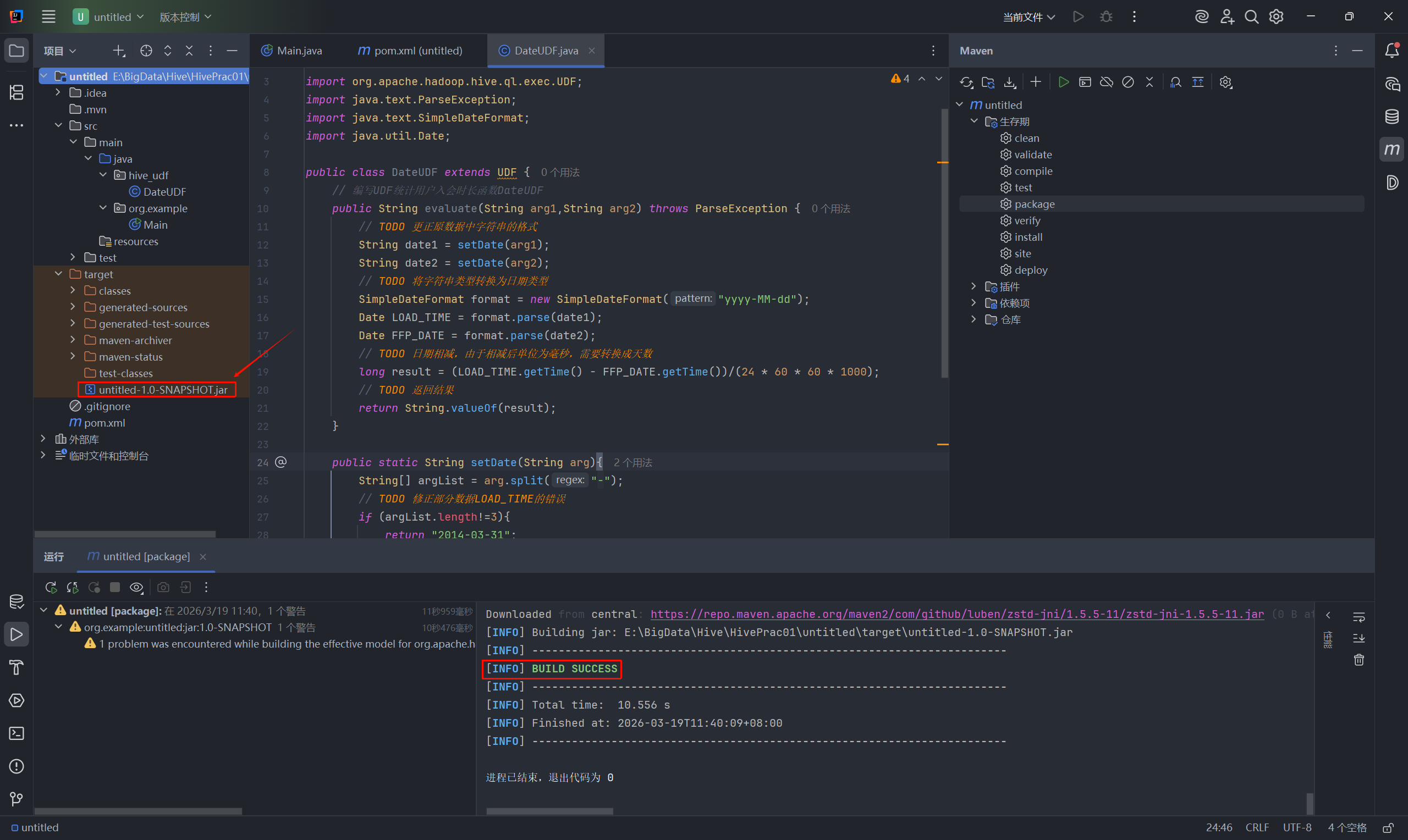
**关键操作:**请使用 FinalShell、MobaXterm 或其他 SFTP 传输工具,将这个生成的 Jar 包重命名,改为 MyUDF.jar,并上传到你 Linux 服务器的一个目录中,例如统一上传到 /opt/ 目录下。
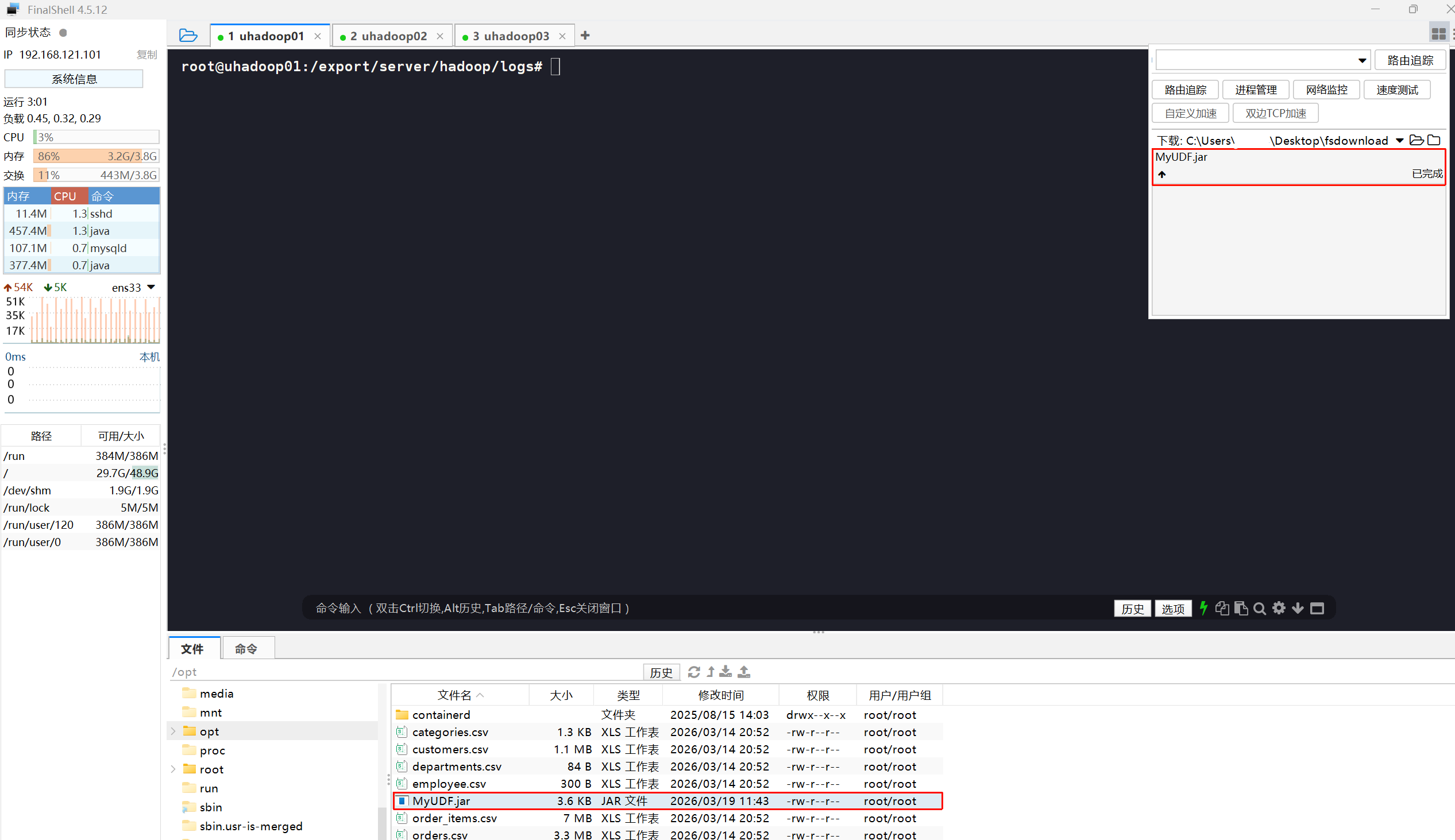
4 & 5. Add Jar 与 Create Function
现在回到 IDEA 的 Database 控制台窗口,我们需要执行 HQL 命令,告诉 Hive 引擎这个外部 Jar 包的具体路径,并为其注册一个能在 SQL 语句中直接调用的短函数名。
在控制台中执行以下两条命令:
sql
-- 第4步:将服务器本地目录下的 Jar 包临时加载到当前 Hive 会话的运行环境中
add jar /opt/MyUDF.jar;
-- 第5步:创建一个名为 dateudf 的临时函数,并将其映射关联到你刚才编写的 Java 类的全限定名
create temporary function dateudf as 'hive_udf.DateUDF';
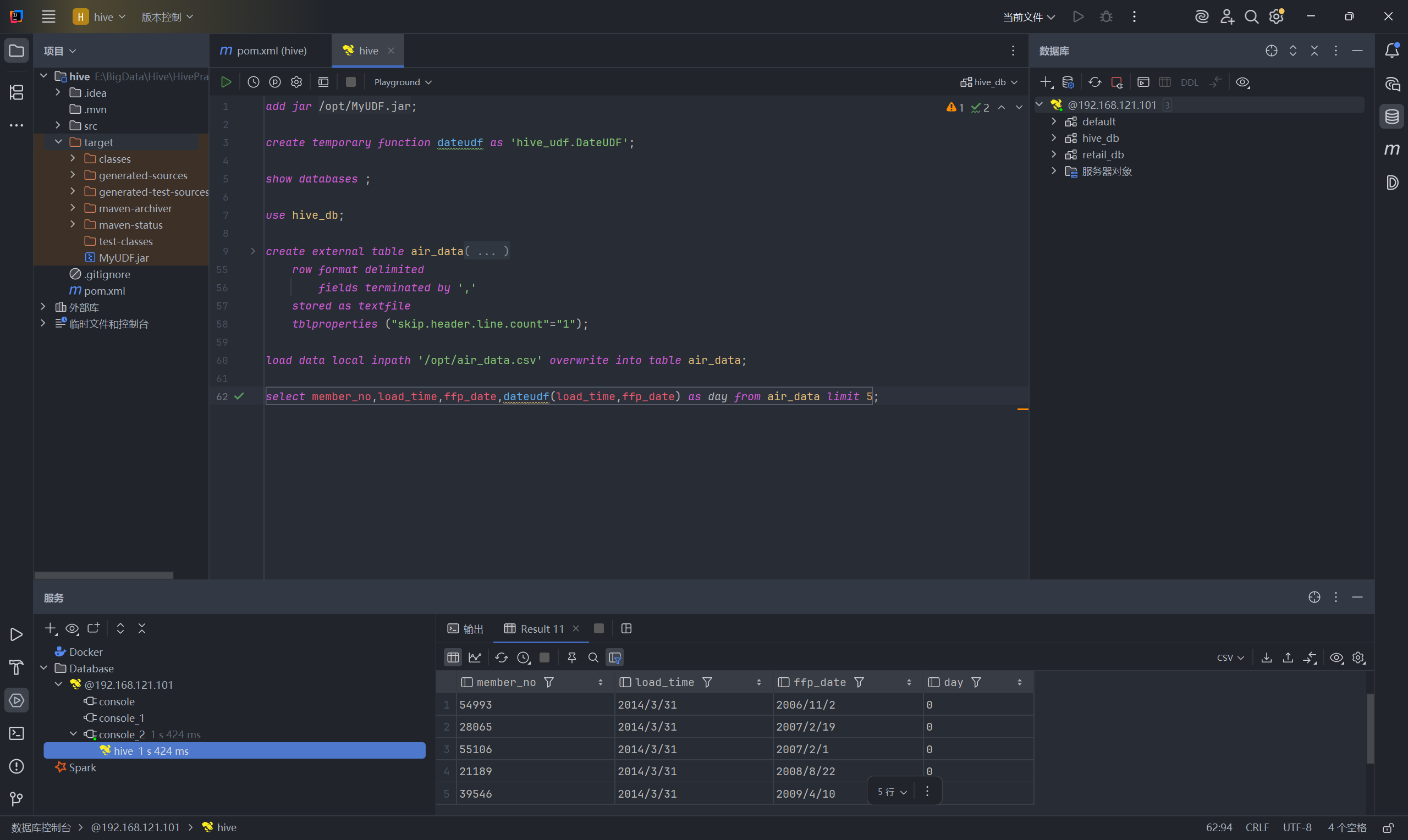
6.最终测试:在业务 SQL 中丝滑调用
dateudf 函数现在已经完全融入了 Hive,可以像自带的 count() 或 sum() 函数一样直接写在 SQL 里。
我们编写一段完整的 SQL 脚本进行测试(假设你已经建好了包含相应字段的 air_data 表并加载了数据):
sql
-- 使用刚才注册的 dateudf 函数,直接传入两列日期字符串,计算它们的相差天数并命名为 day 列
select
member_no,
load_time,
ffp_date,
dateudf(load_time, ffp_date) as day
from air_data
limit 5;运行这段脚本,如果看到了下方这个查询出来的表格,那么恭喜你,Hive UDF 的完整工业级开发流程你已经彻底掌握了。

日期:2026年3月19日
专栏:Hive教程