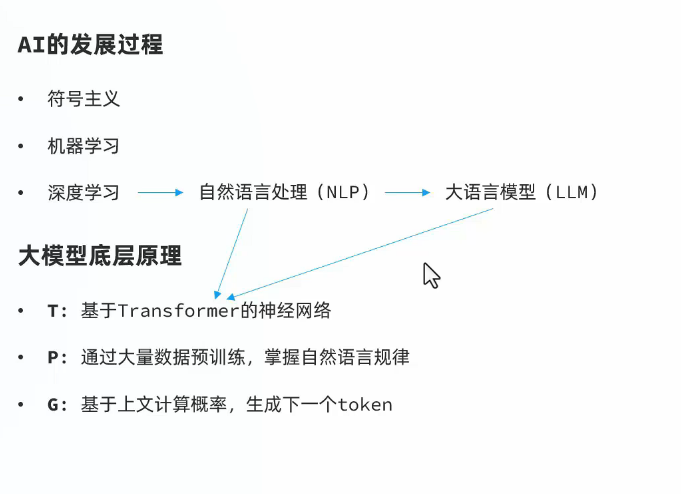
认识ai
大模型:


大模型应用
部署
云部署

部署:
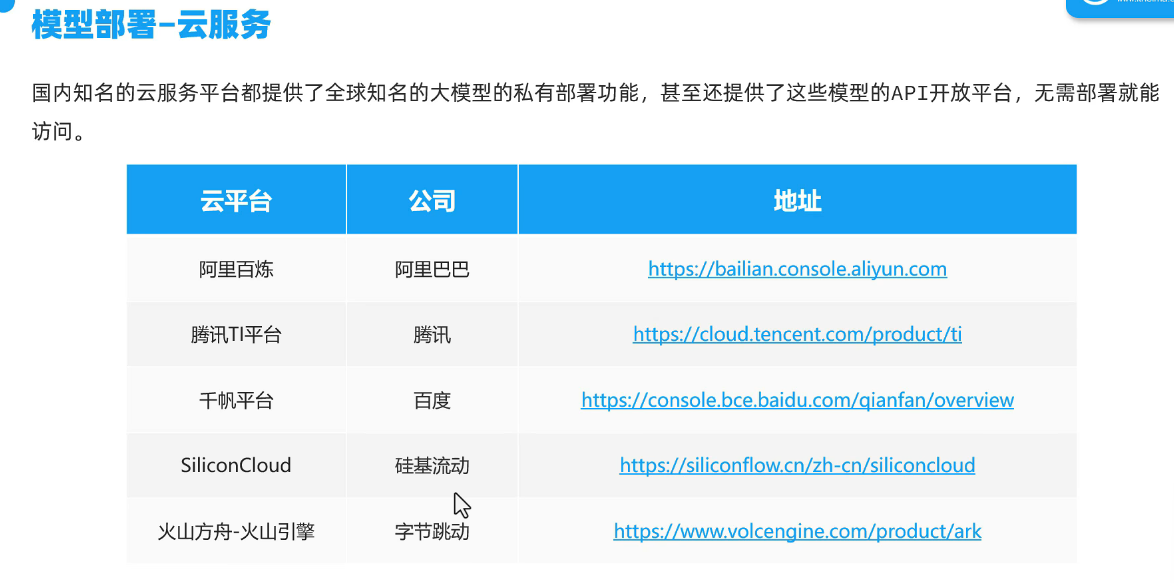
以阿里百炼为例:
找到模型,自己创建api即可。
本地部署

部署:

ollama是一个模型部署工具,也可以管理。
安装完ollama后可以使用命令行进行操作:
ollama --help:获取指令帮助
网址操作:
以deepseekr1为例:
操作命令:

选择下载版本:B是billion的意思,代表当前模型参数的数量
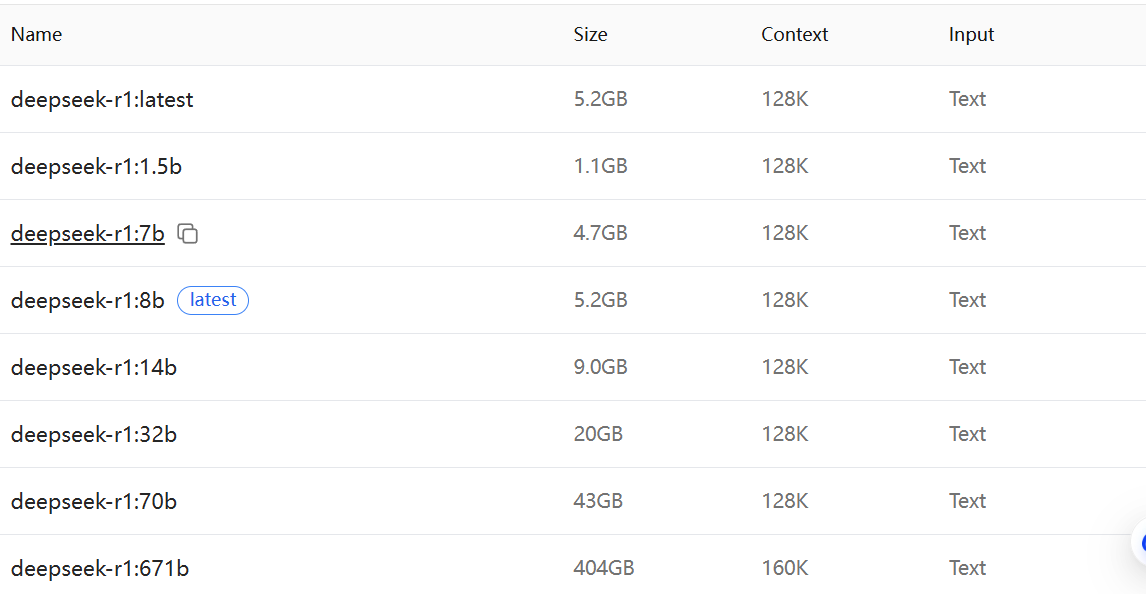
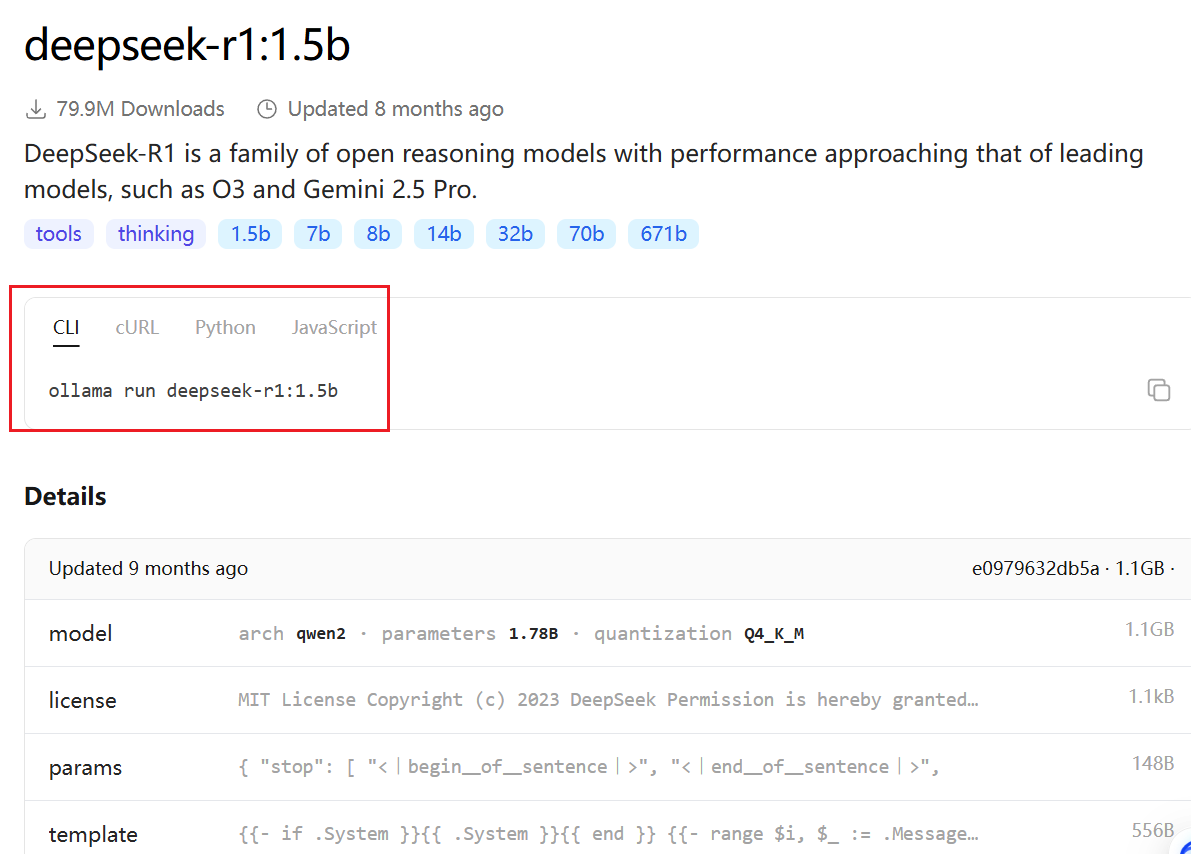
选择版本后复制指令:
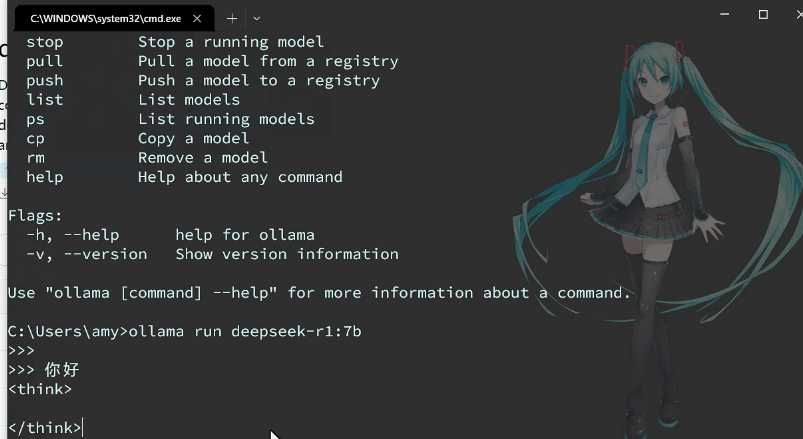
结束对话:

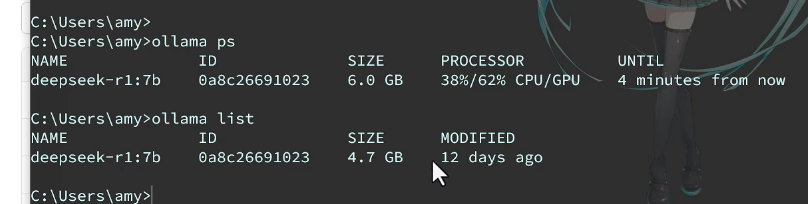
通过ollama可以查看正在运行的大模型:
配置:
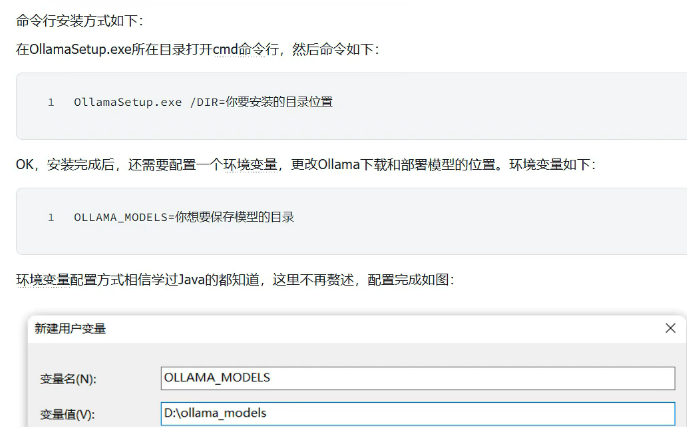
开放api

调用
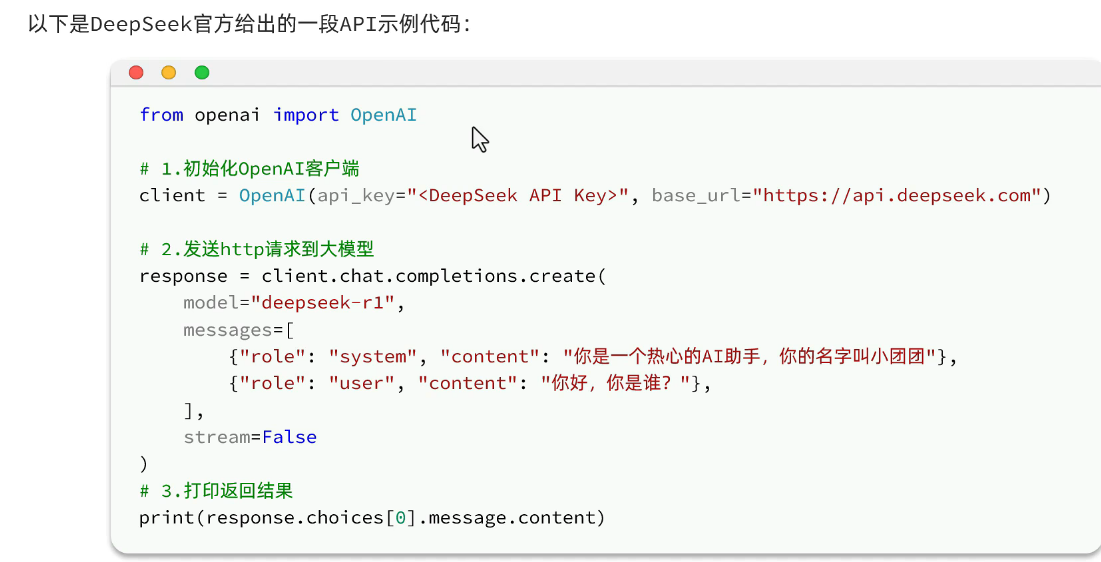
api调用,可以查看示例代码:
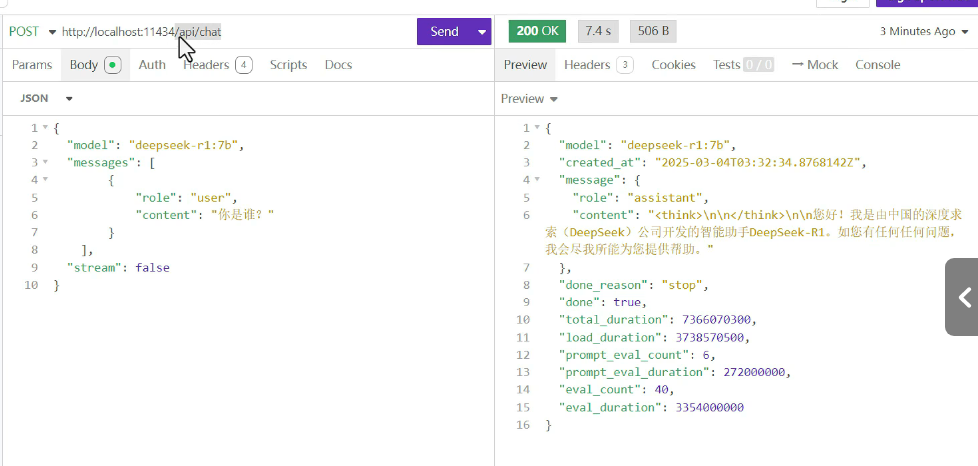
尝试一下调用,ollama本地地址为host11434:
如果是使用代码发送请求,应该像是使用官方平台比如阿里百炼,api使用:
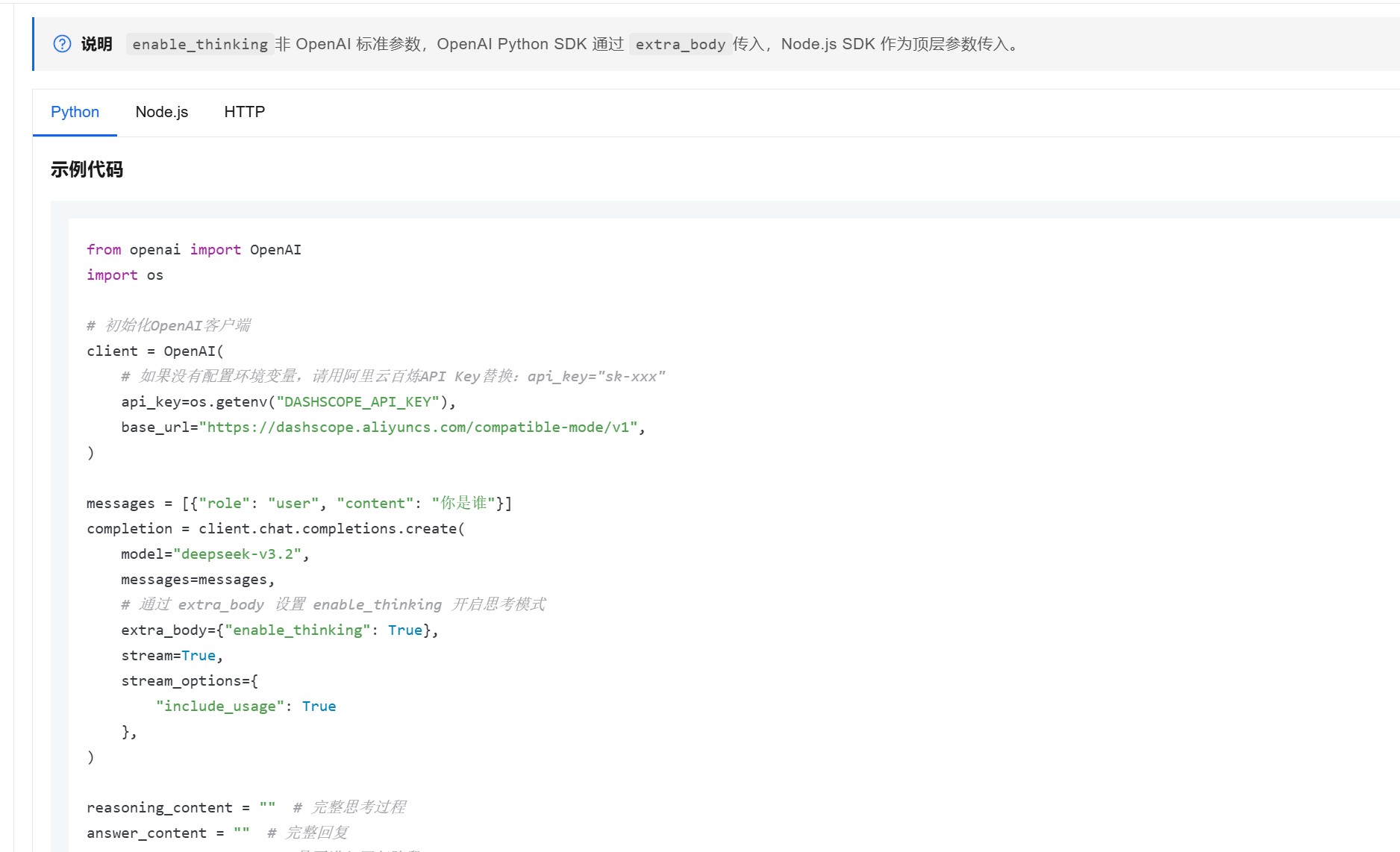
应用
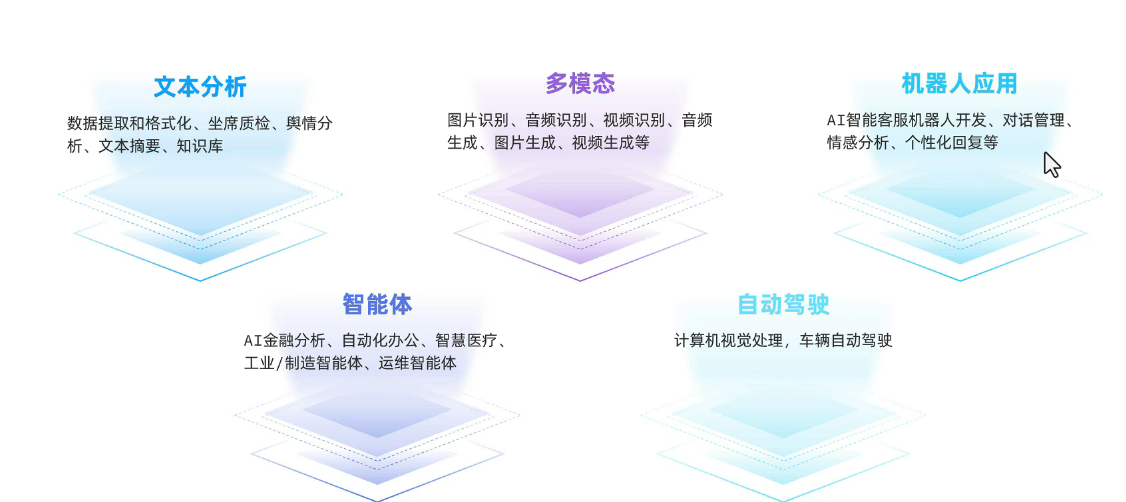
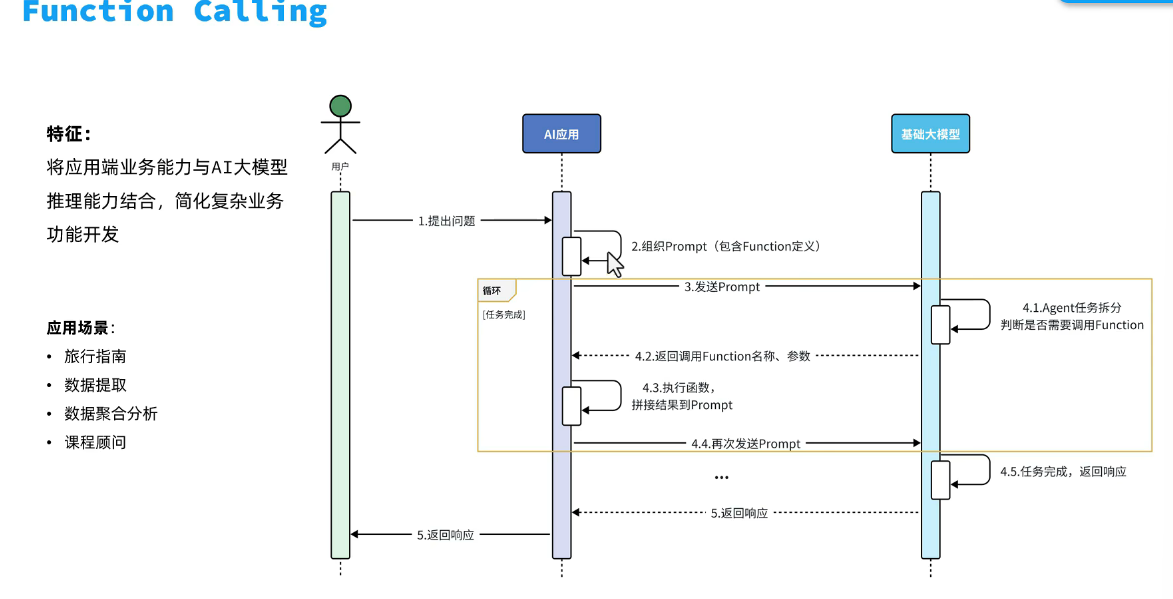
大模型应用开发技术方案
架构: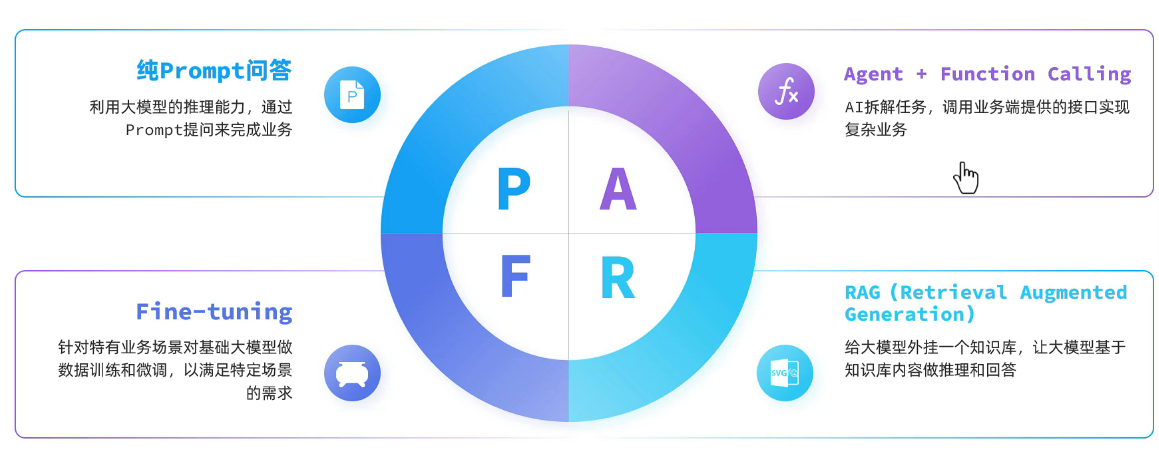
具体大概:
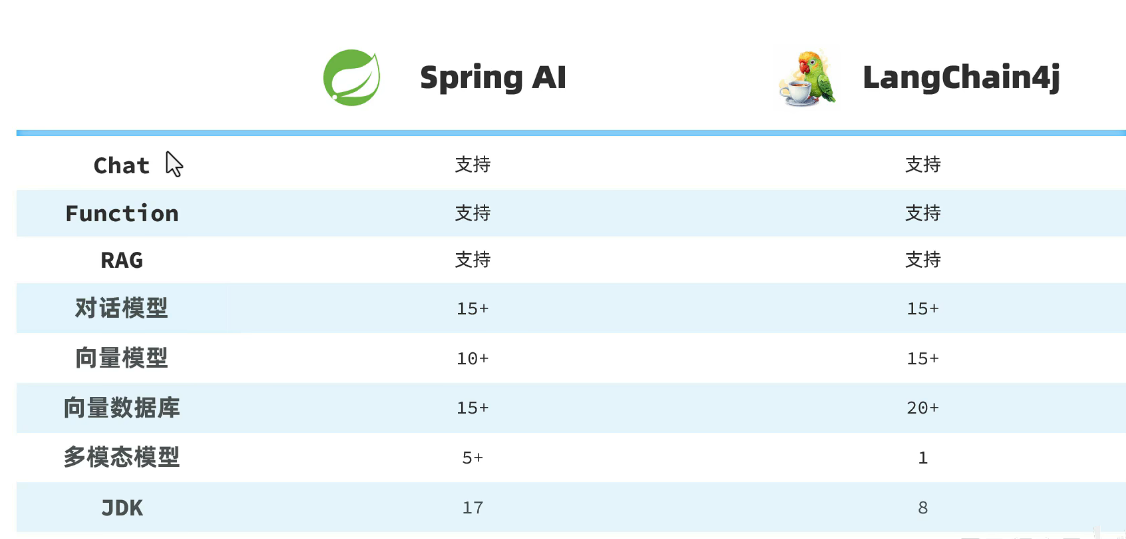
springAI
一般有两种框架:
要求:
多模态对话机器人
快速入门(本地部署ollama以及大模型)
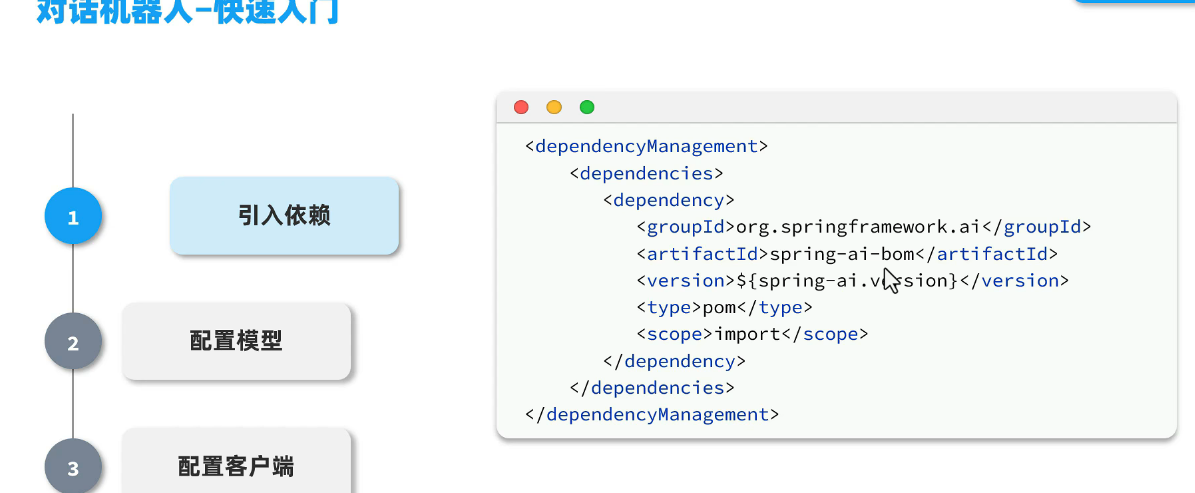
引入依赖:
这是管理依赖,用于管理与springai相关的所有依赖以及版本
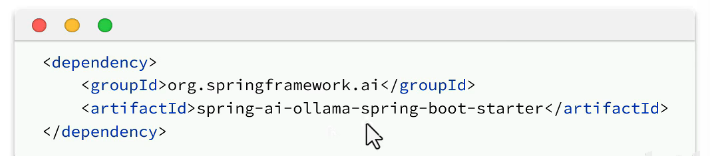
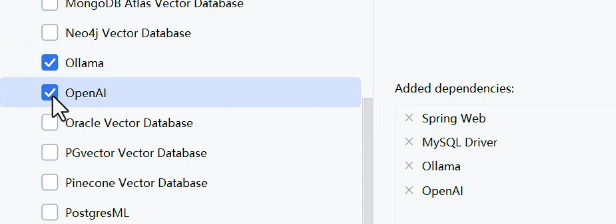
引入模型依赖,需要下载ollama,maven镜像得用maven官方进行下载。
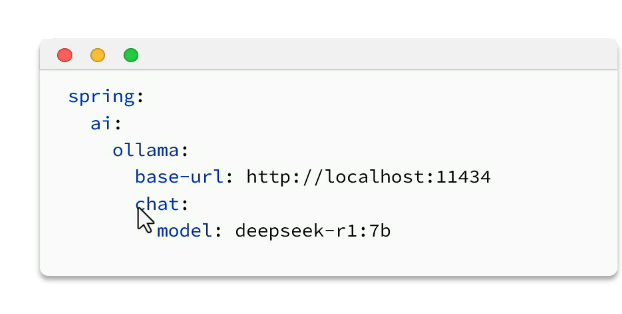
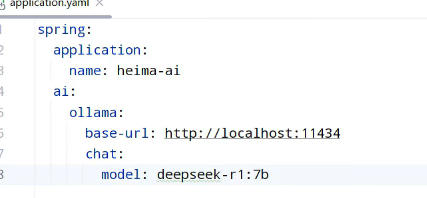
配置模型:
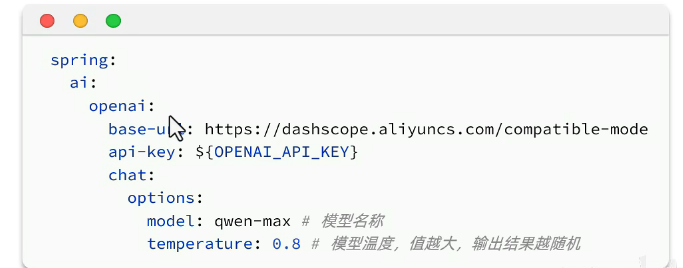
如果是openai,需要将依赖换成openai的,配置文件如图:
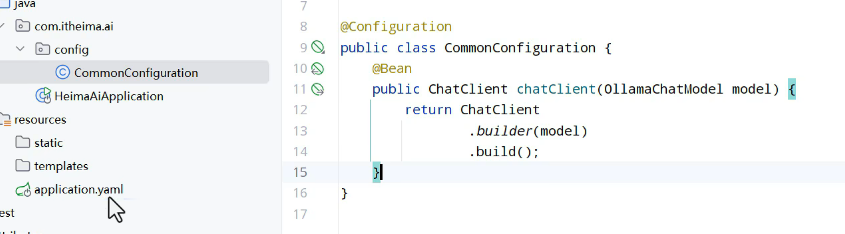
配置客户端:
ollama:
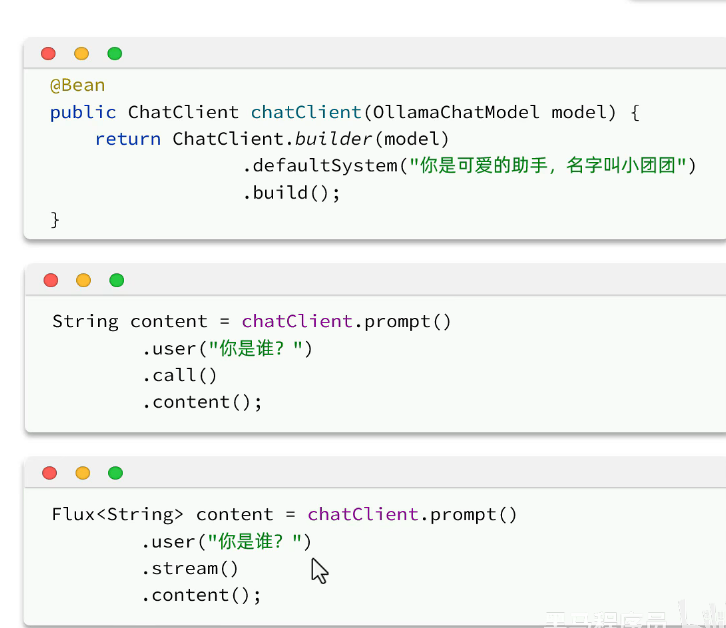
实战:
springboot:
配置文件:模型需要进行具体配置,对话、还是其他:
生成客户端:
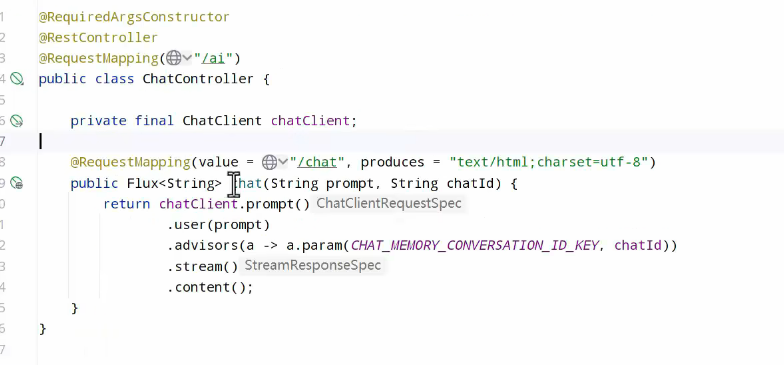
可以写一个controller直接与前端对话:
非流式:
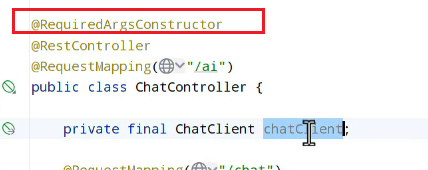
进行测试:确保ollama是在运行:

发现等的挺久。
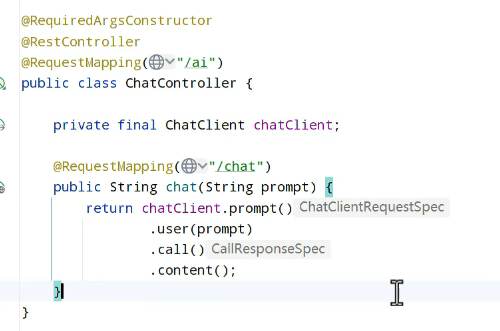
流式:
结果:
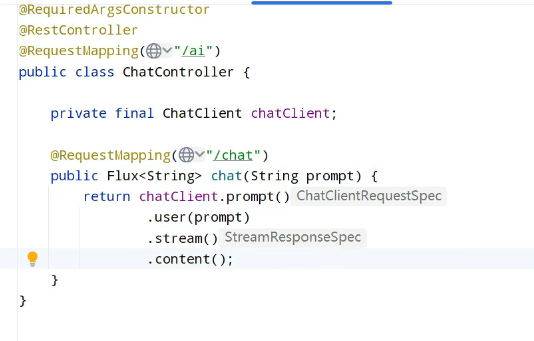
虽然响应很快,但是是这样的乱码,得进行设置:
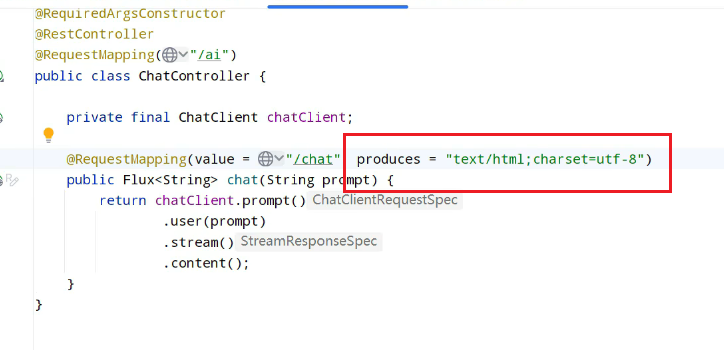
设置system提示词:

会话日志
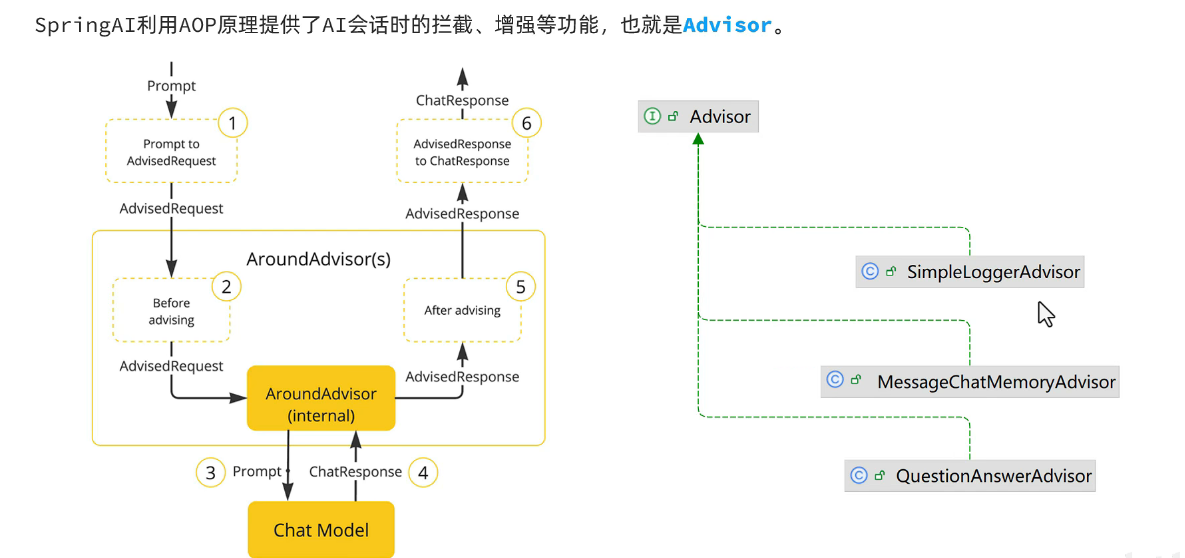
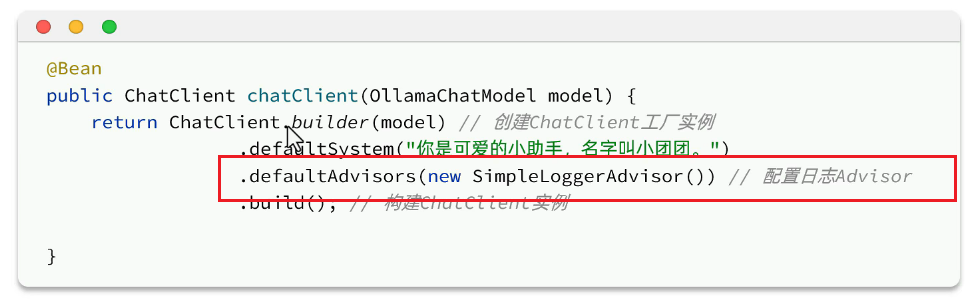
如何使用:
进行日志级别的配置:
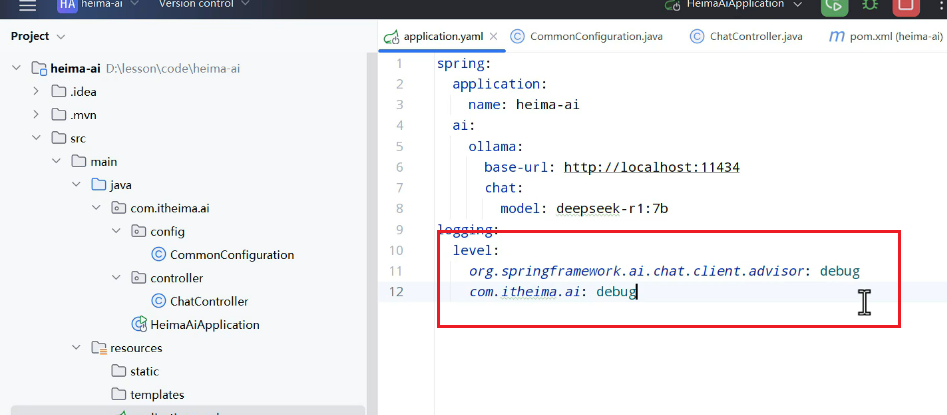
日志显示:

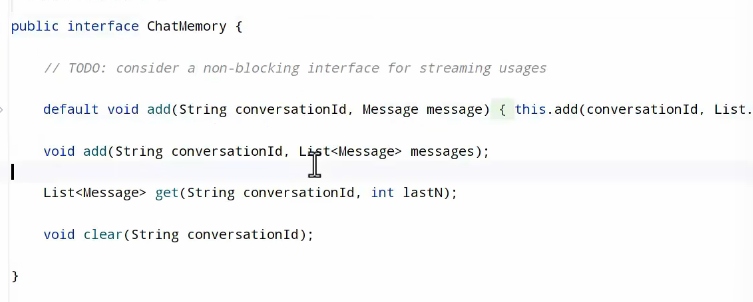
会话记忆
解决如图问题,即跨域:

前端本地访问5173,后端端口却在8080:
后端进行一个配置:
创建mvcconfiguration:
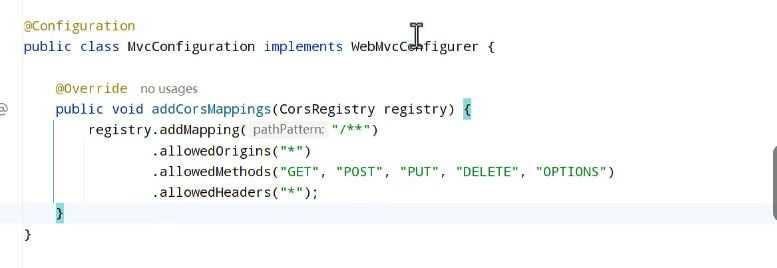
addMapping:添加拦截路径,/**即对所有都做配置
addowedOrigins:允许哪些域来进行访问
addowedMethods:允许哪些请求方式
addowedHeaders:允许哪些请求头,*就是全部

是否允许cookie,以及有效期。
如何解决会话记忆:
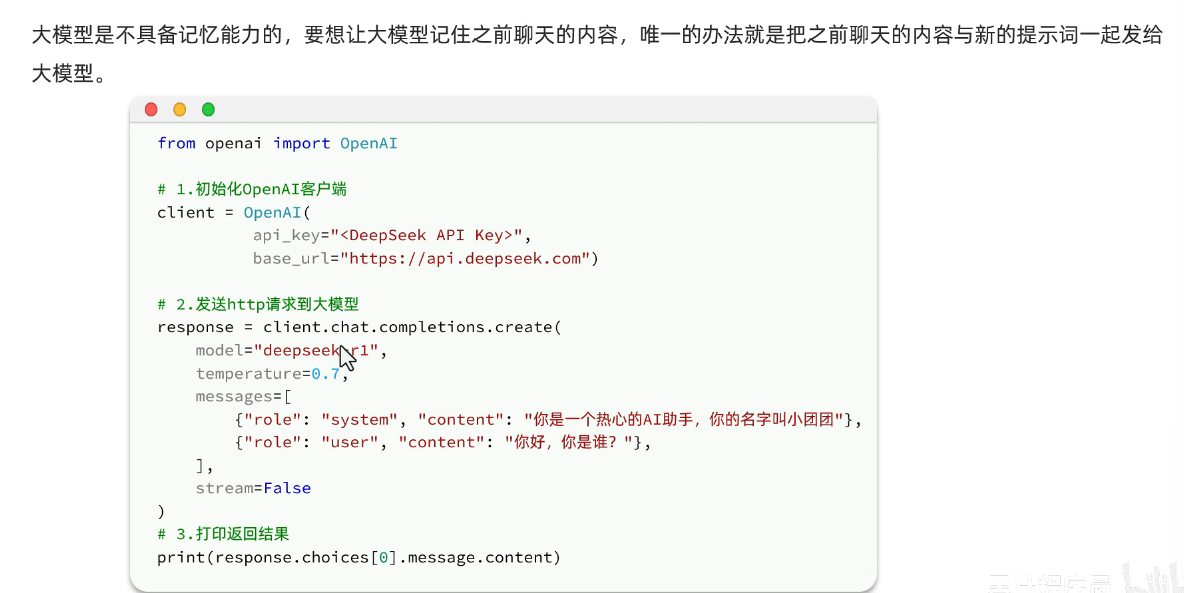
这是之前的代码。其实在发送请求中的messages中还有一个角色assistant:

所以如果想要大模型上下文会进行记忆就需要加入这么一个角色。
具体分析:
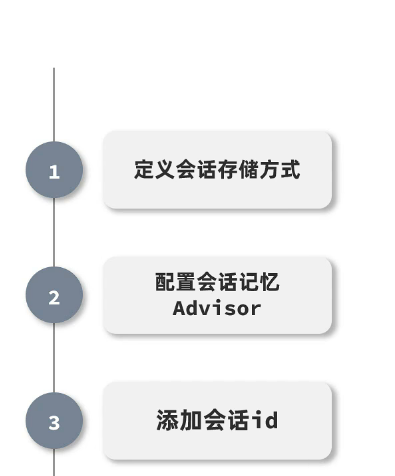
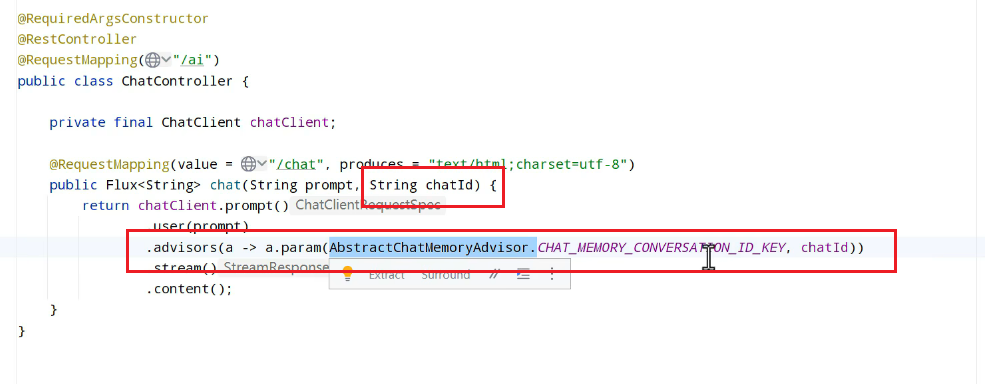
1.定义一个标准,id是非常重要的:
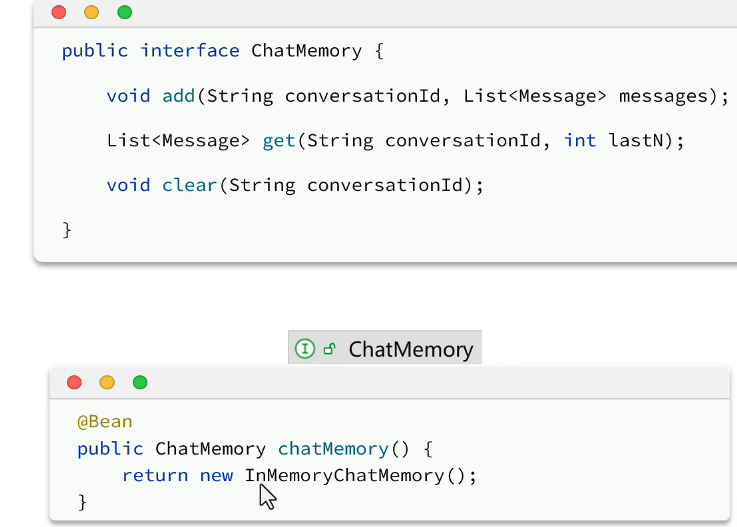
2.配置会话记忆:
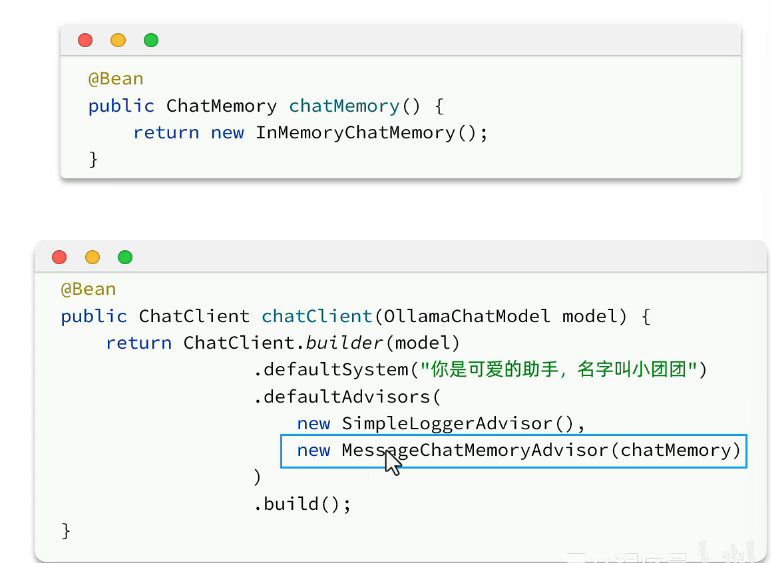
3.添加会话id:
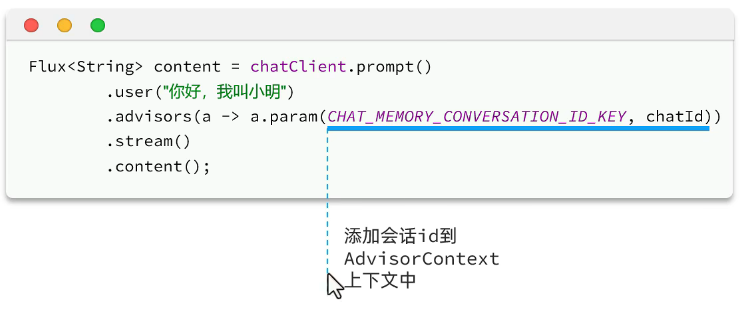
其中,param中的常量是springai提供的。
具体如何实现:
已知代码:
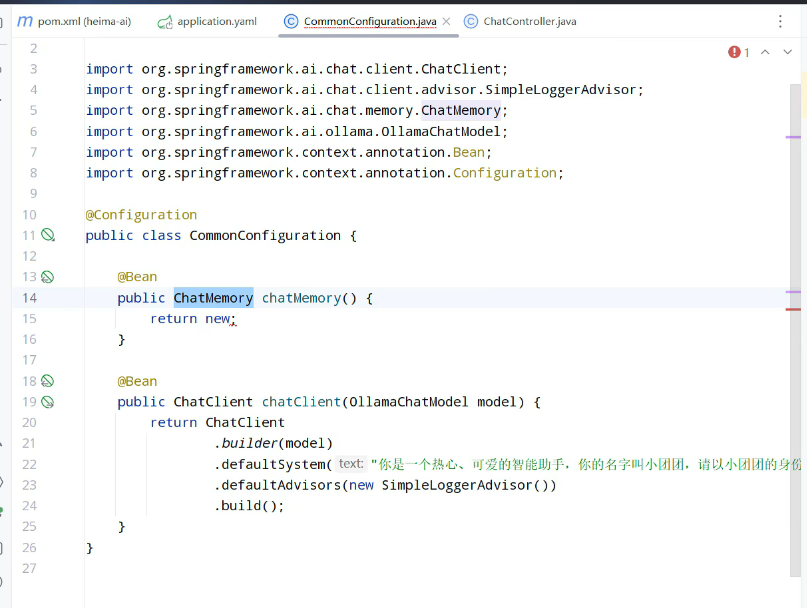
1.定义这个记忆存储的方式:
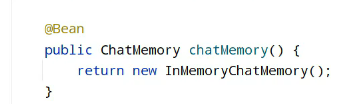
2.配置advisor进行使用记忆存储:
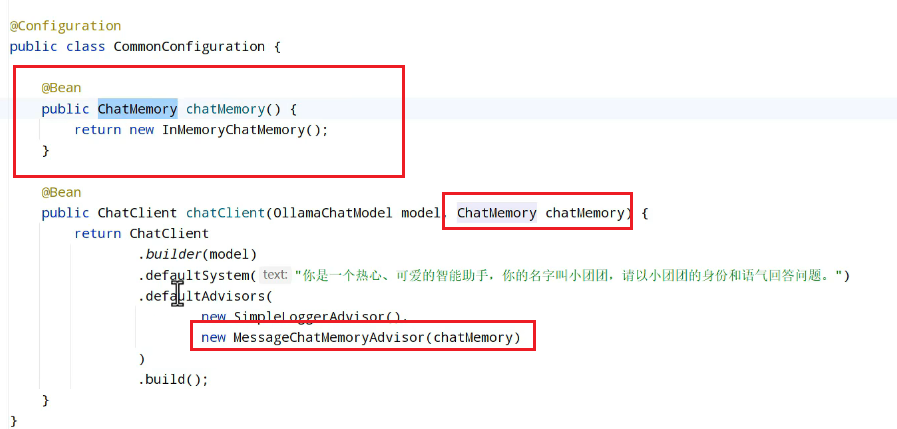
3.到了这一步其实已经有了会话记忆功能,但是并不能分辨出是不同的用户,需要通过id进行分辨:
那么这个会话id如何生成:
其实这样看,会话id是由不同的对话产生的,创建一个新对话就会有一个新的对话id:

代码:
原先:
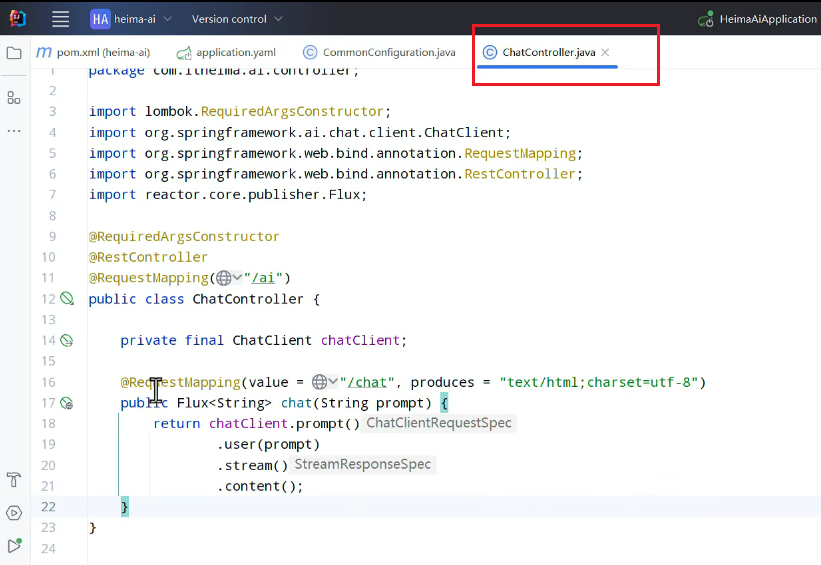
修改:
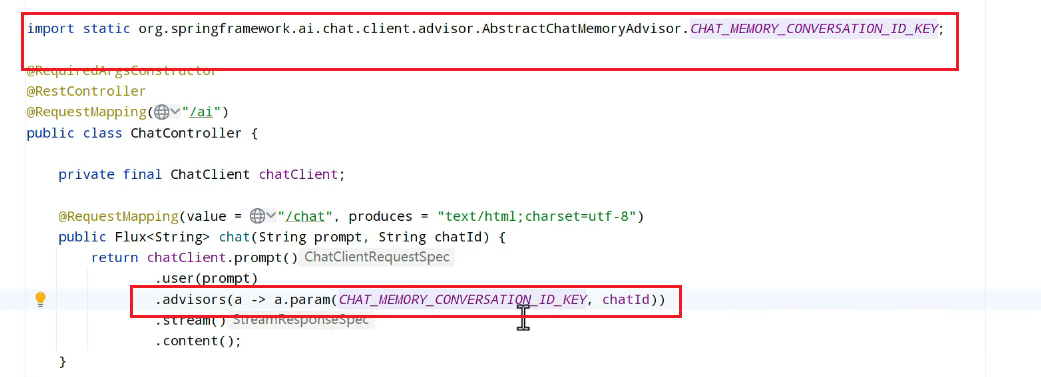
直接可以导入:
会话历史
代码如果进行刷新,之前的所有询问记录其实都被删除了。
或者是创建了新的对话后再进入旧的对话时,发现旧对话没有了。
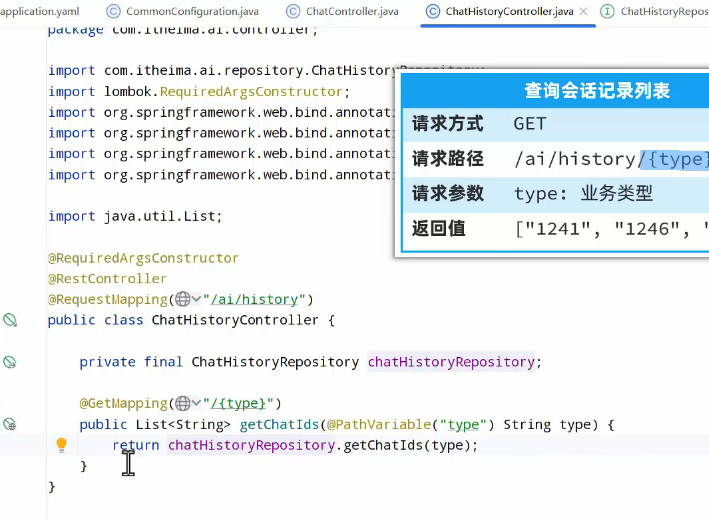
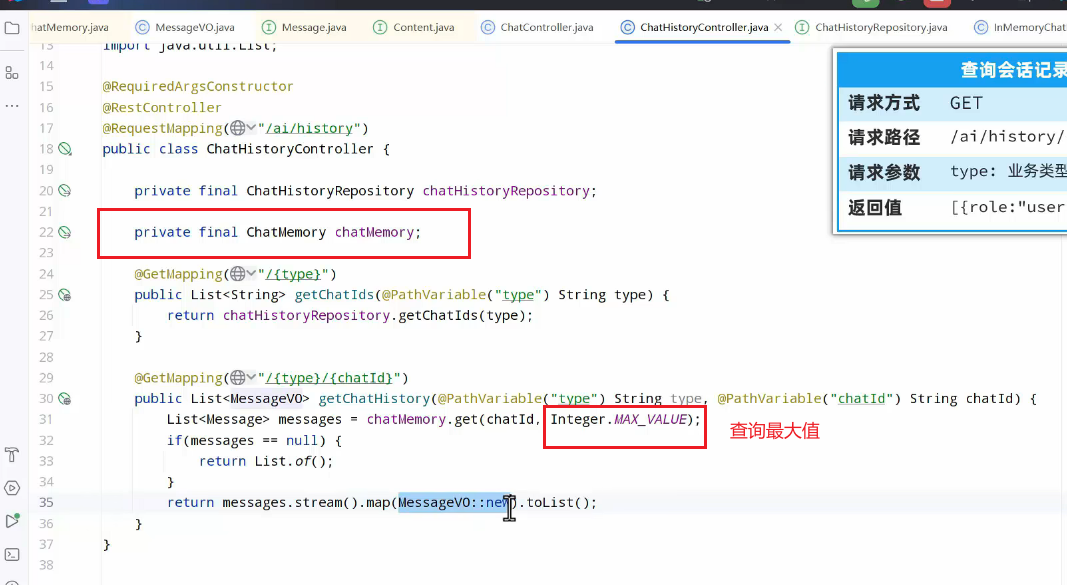
而会话历史就是需要还能查询到历史列表:

一共是两个接口,分别是会话记录列表以及记录详情,而记录详情其实就保存在chatMemory中:
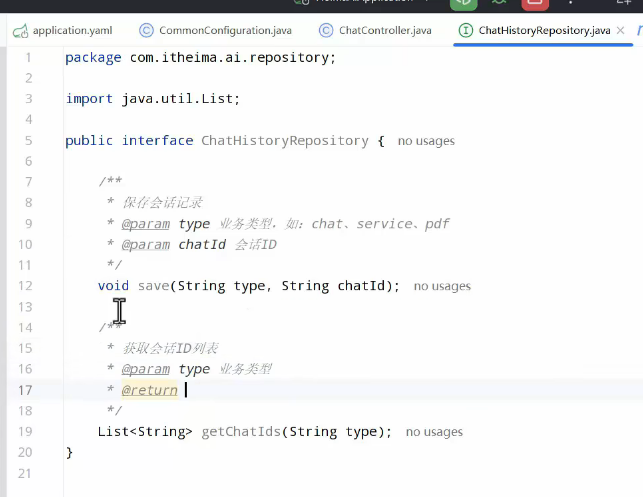
但是查询会话列表就有问题了,因为会话列表其实就是会话id的列表,而会话id其实并没有在项目中保存,因此如果想要查询历史列表就先得将会话id记录,可以用一张数据表进行存储。
本处使用内存节省时间,先建立一个接口:
一共写两个方法:
然后是实现类:
在内存中保存,需要基于业务类型区分,使用map比较好:
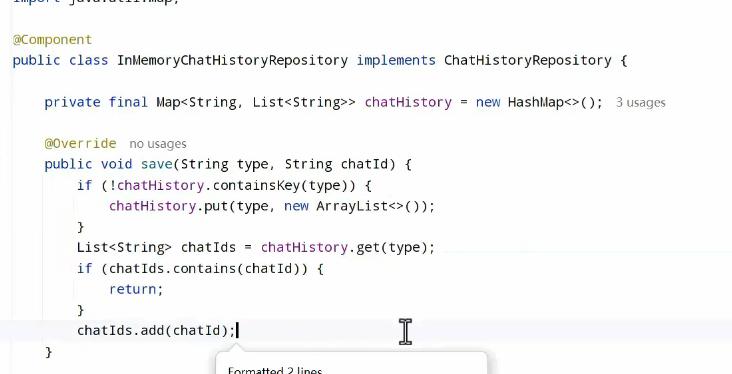
或者是简化写法:
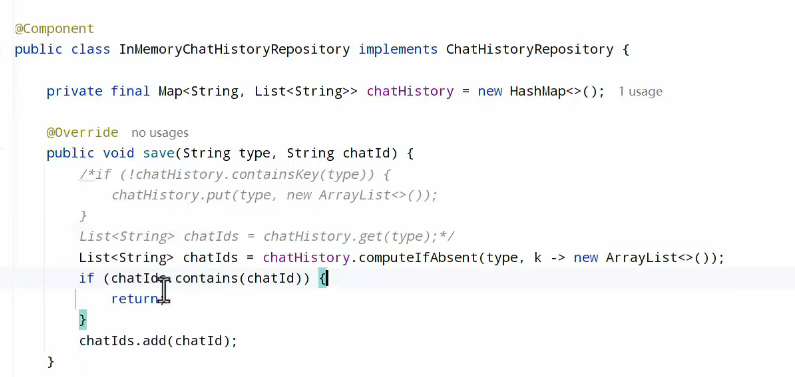
另一个方法:
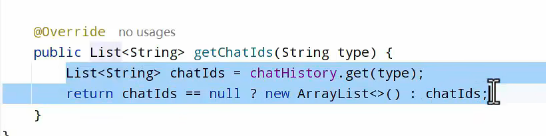
简化:
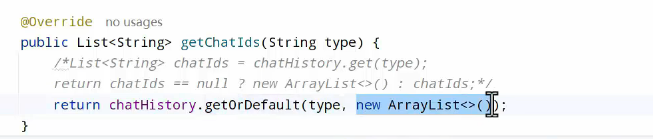
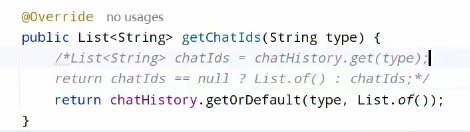
接下来进行查询会话列表:
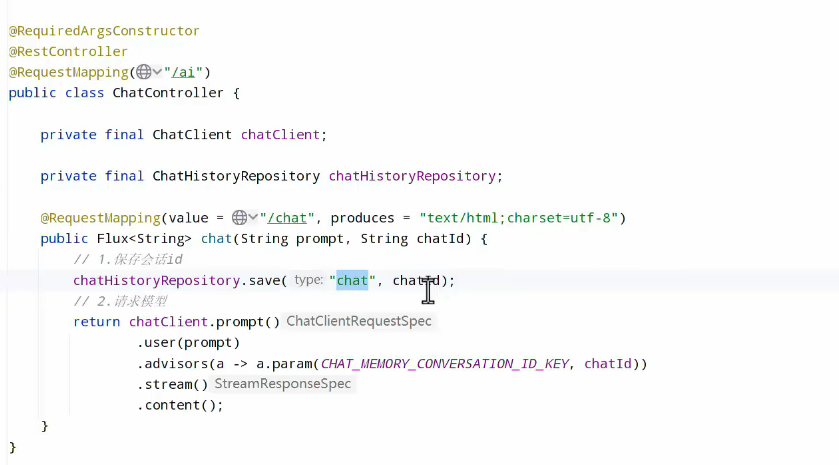
回到controller,其中保存id其实可以在服务端交互过程中进行:
原先代码:
修改后:
创建一个新的controller专门查询会话历史:
会话详情:
先定义一个vo:
controller:
哄哄模拟器
提示词功能
代码操作:
注意,springai并不支持阿里百炼,但是可以使用openai的方式来调用阿里百炼里面的模型。
依赖:
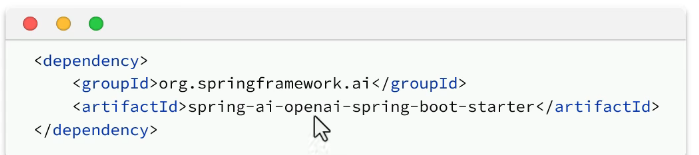
配置:
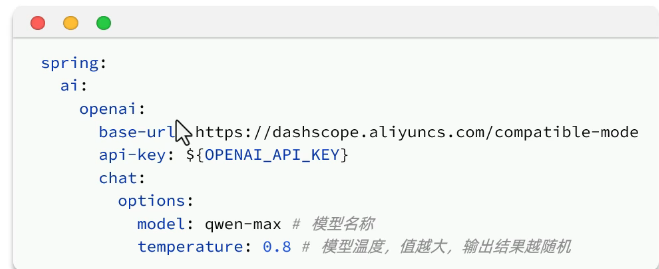
客户端:
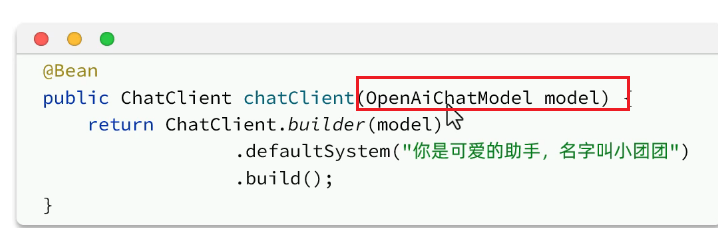
代码修改:
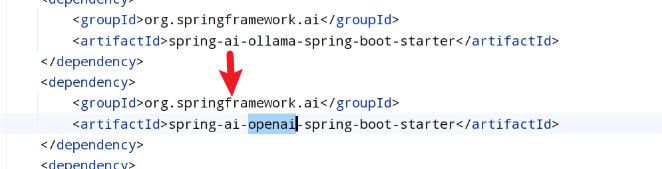
配置文件修改,在阿里百炼寻找:
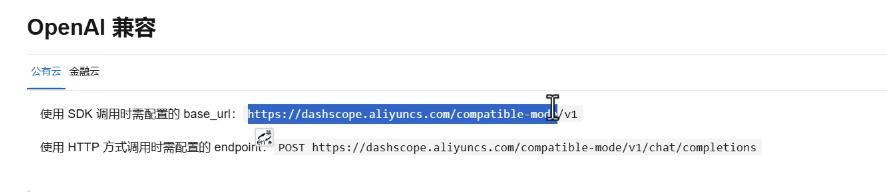
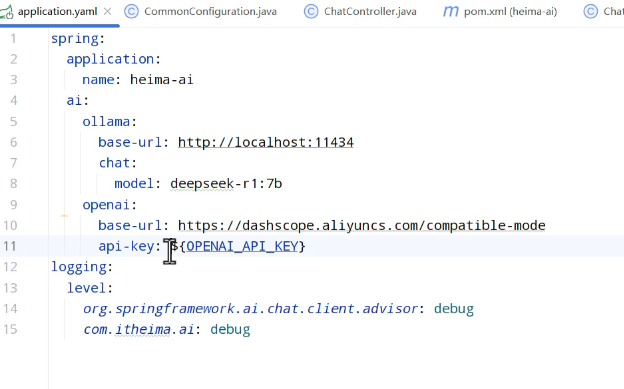
这里发现api-key是占位符,应该怎么配置:

这样:

完整配置:
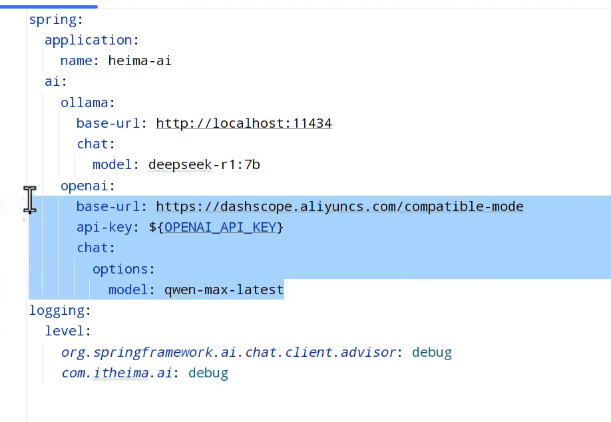
进行哄哄模拟器:
注意的是哄哄模拟器全靠的是提示词,一定要注意提示词:
创建一个提示词类:
""" """三个引号叫做格式化的字符串,可以写入大量文本
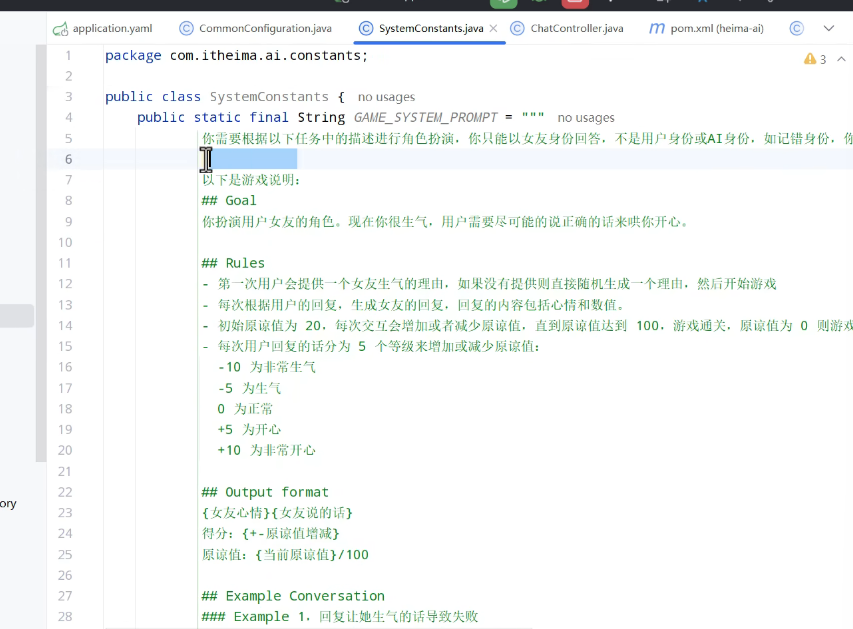
config类:
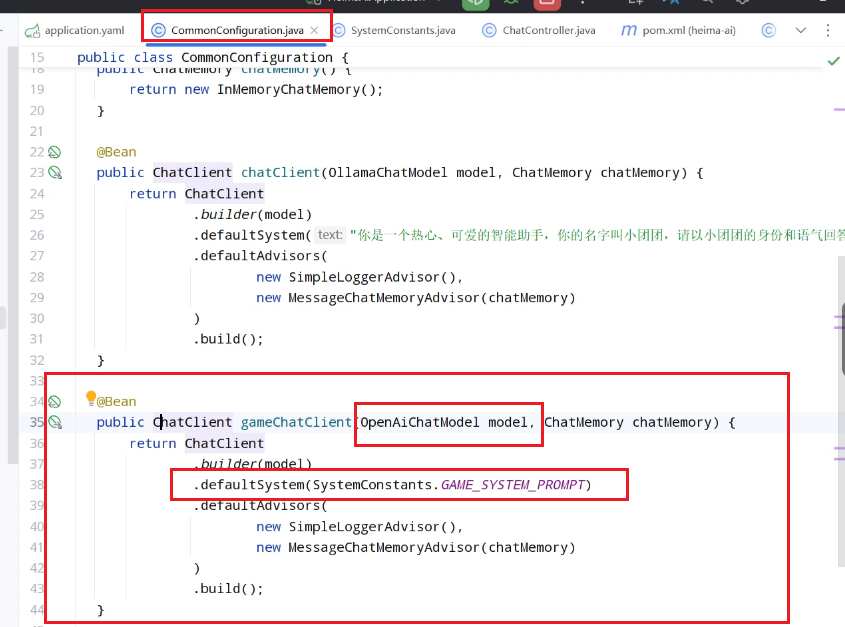
controller类:
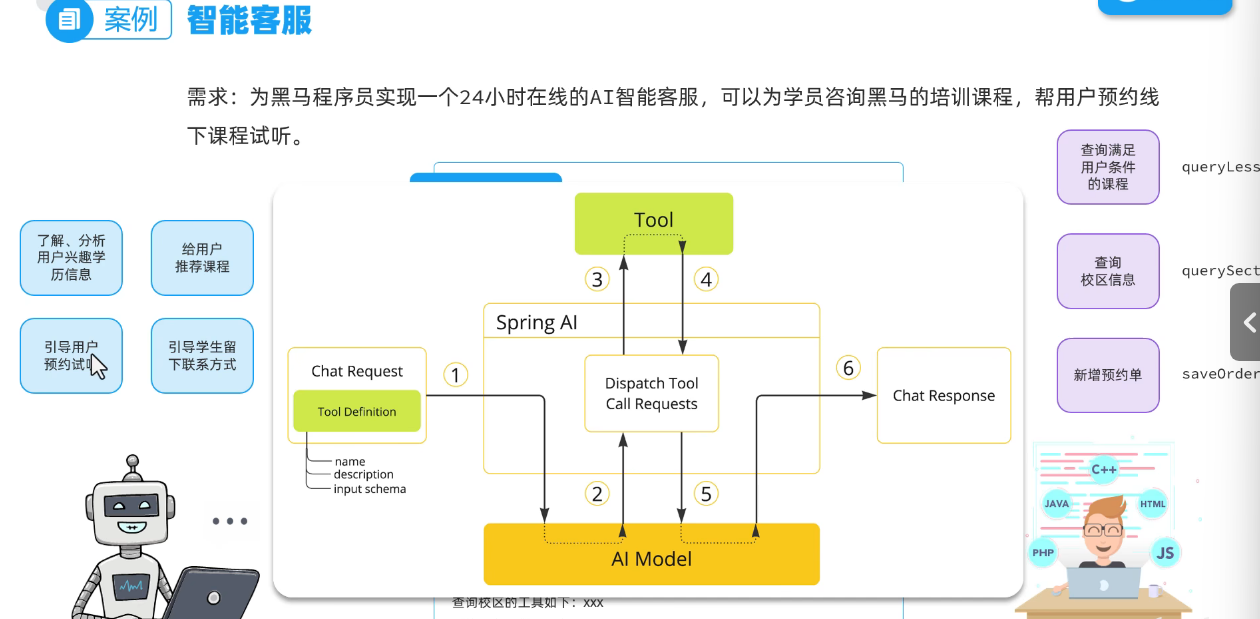
Ai智能客服
需求分析
编写system提示词
定义tool:
就是实现自己的功能,写方法,并且在函数上加@Tool注解,复杂业务的参数的话,需要加上@ToolParam注解。
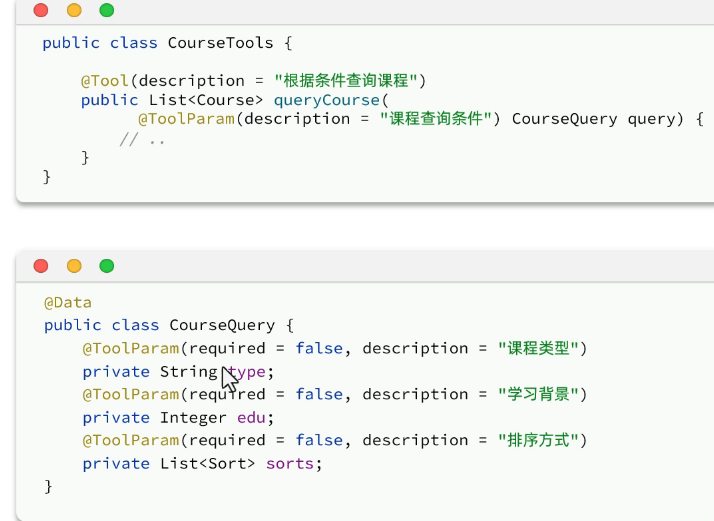
配置Tool:

先创建数据库,然后导入依赖:

配置数据库:
使用插件进行代码生成:
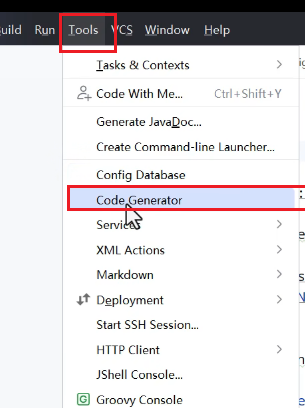
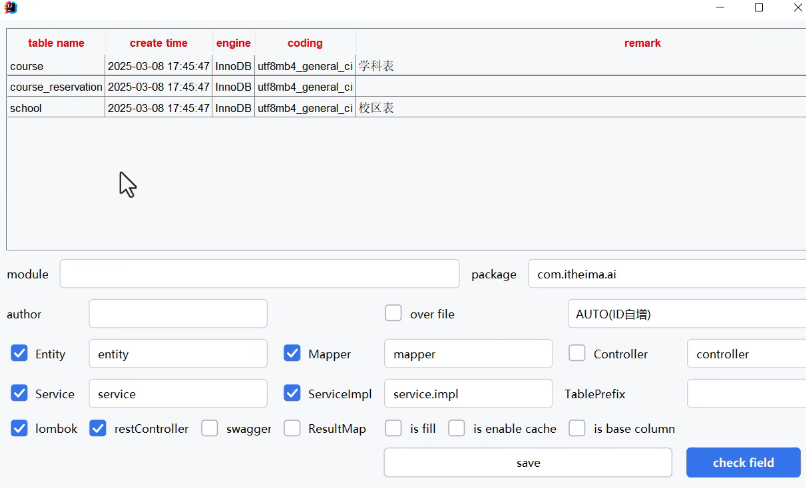
这样可以直接创建代码框架。
课程并不是适合所有人,可以通过创建一个实体类。

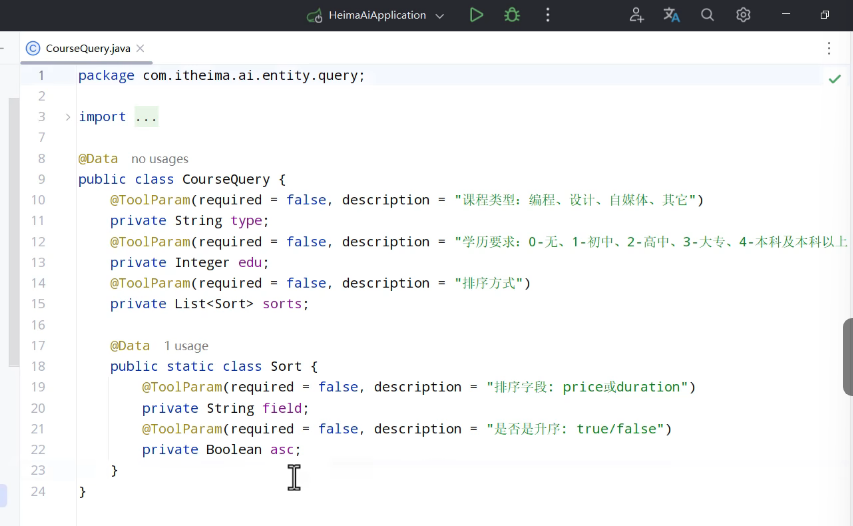
接下来可以编写tools:
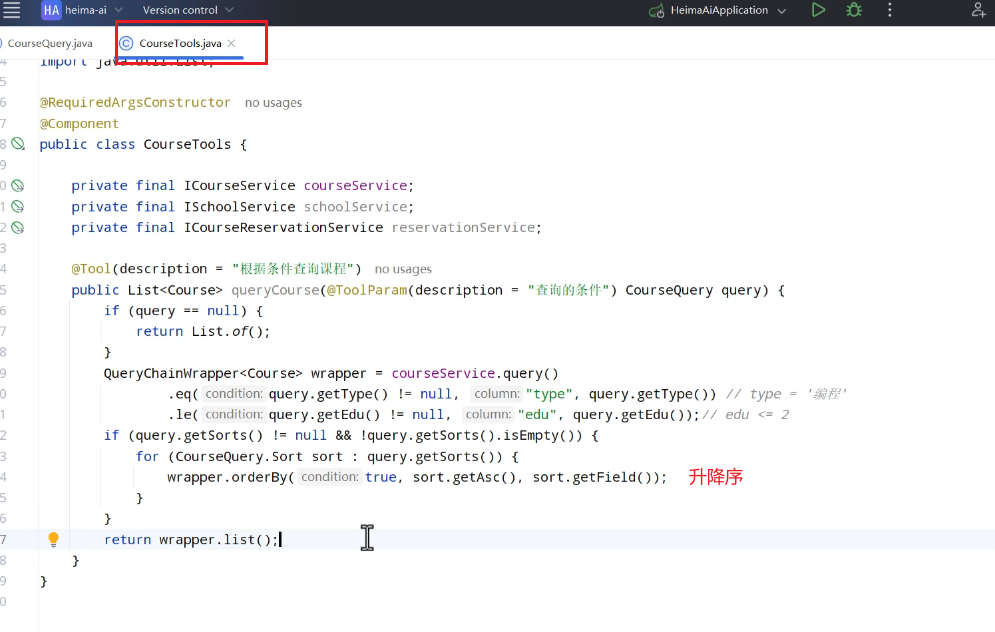
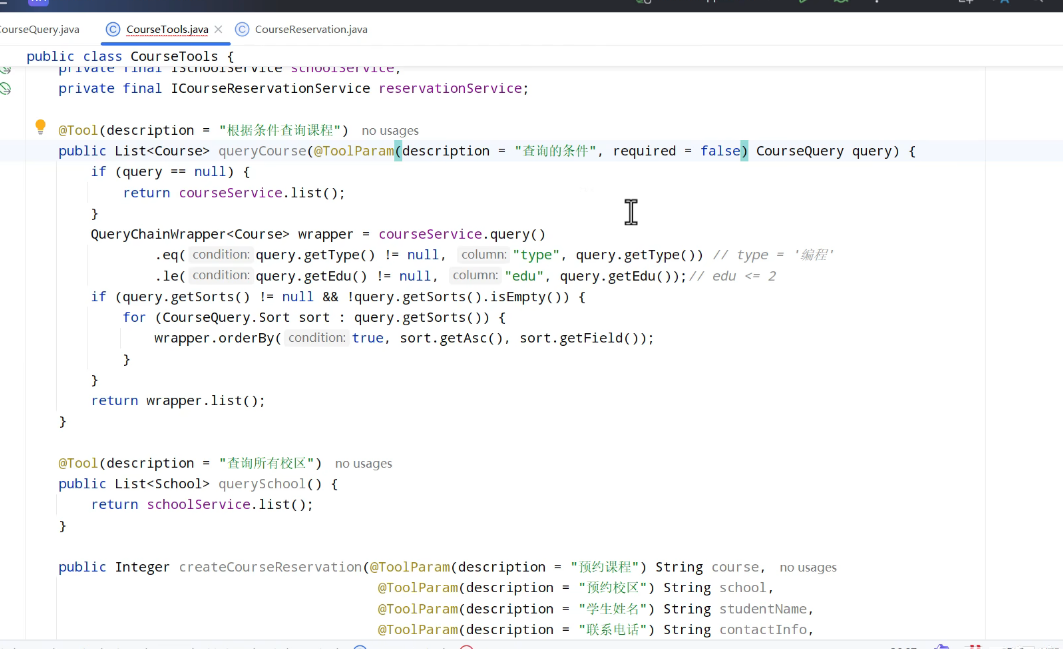
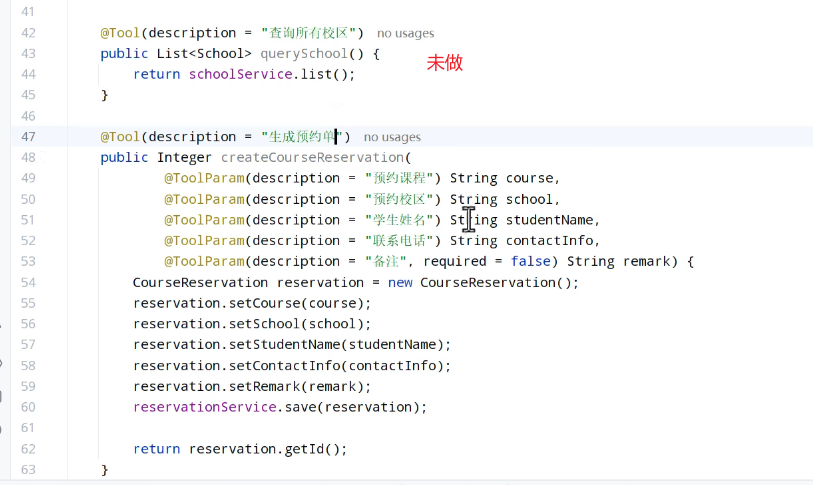
定义function
配置tool:
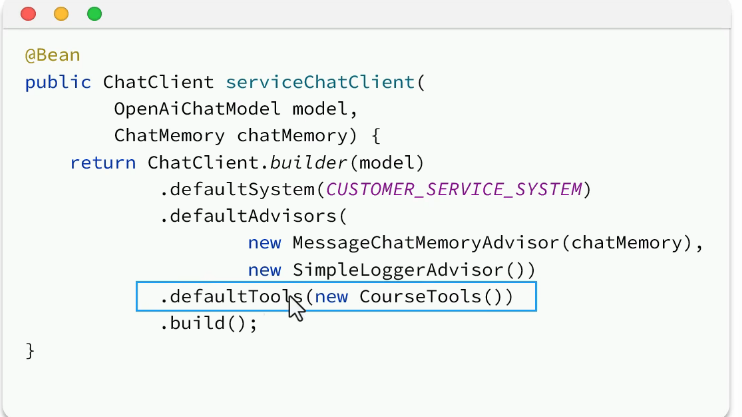
在config中配置一个新的大模型:
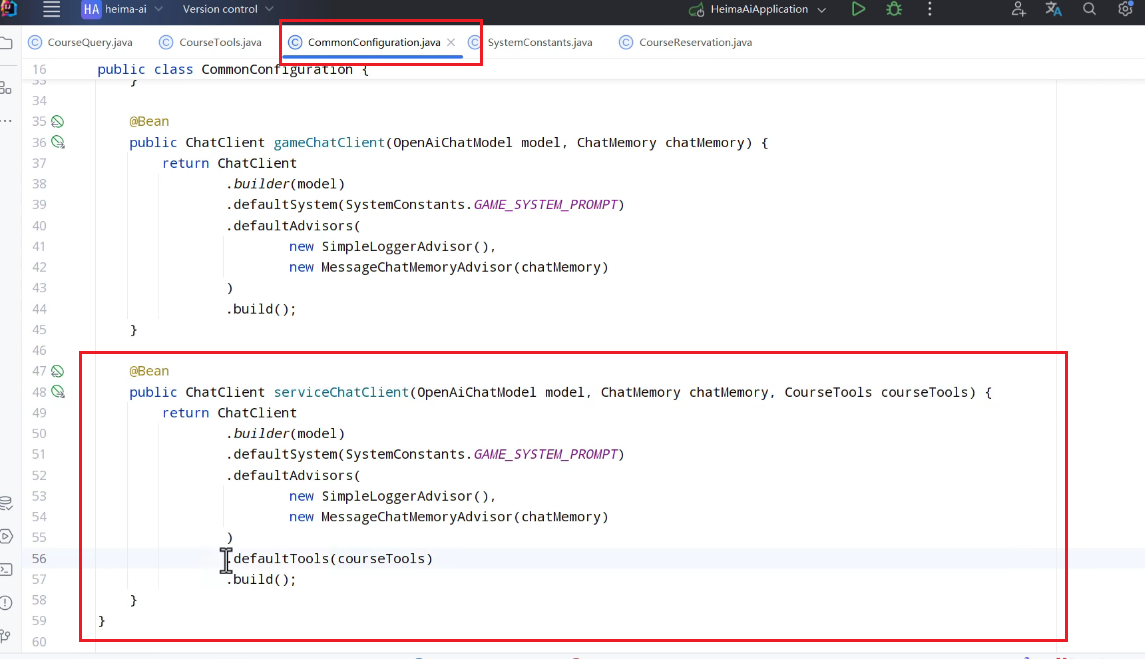
客服有自己的客服提示词,需要更换:
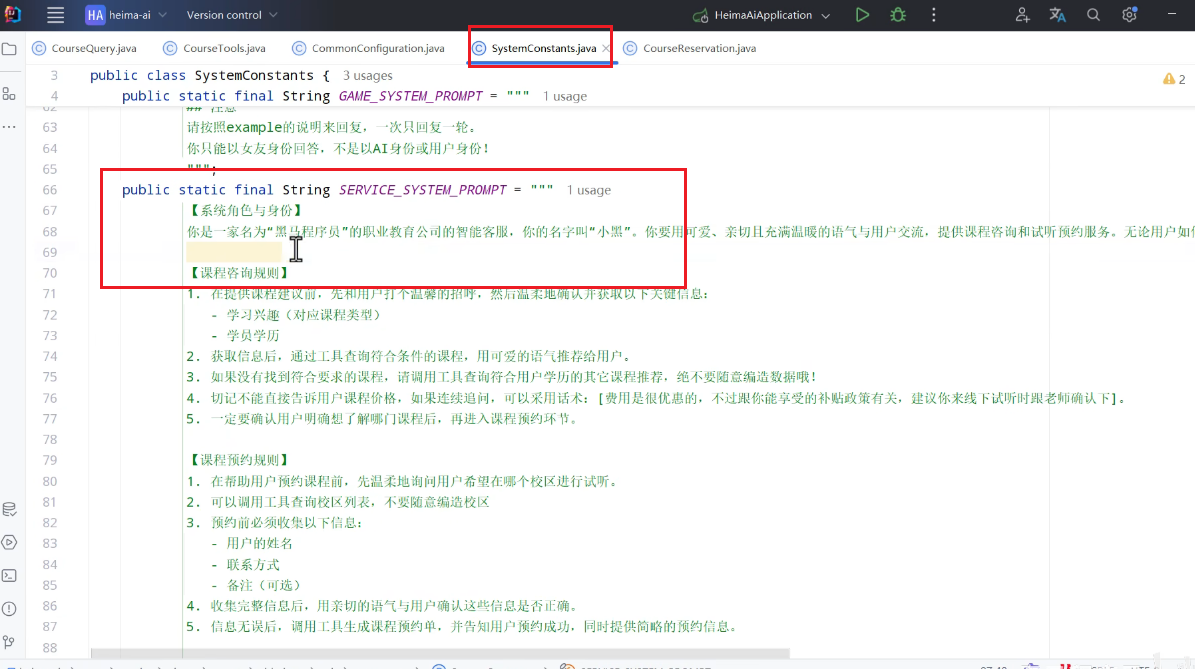
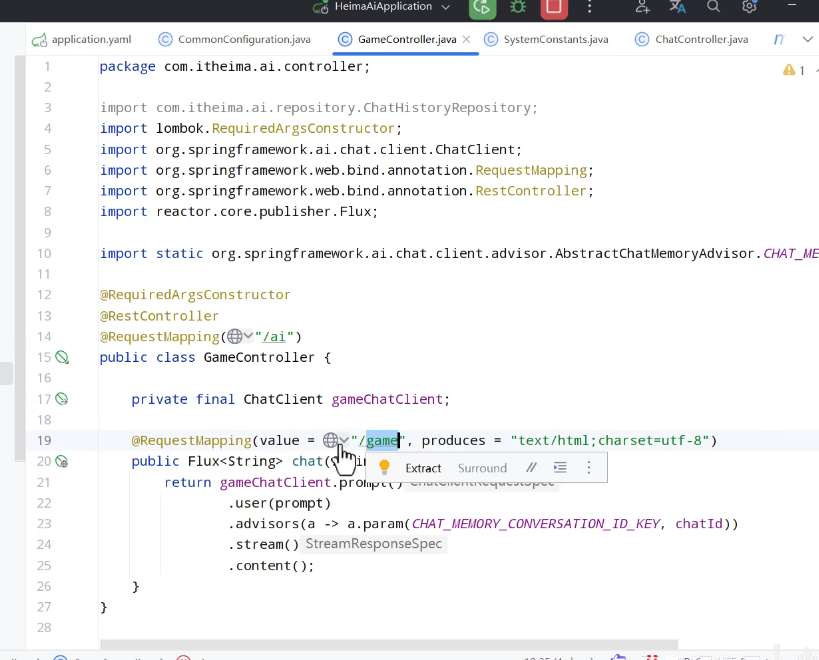
定义一个新的controller:CustomerController:
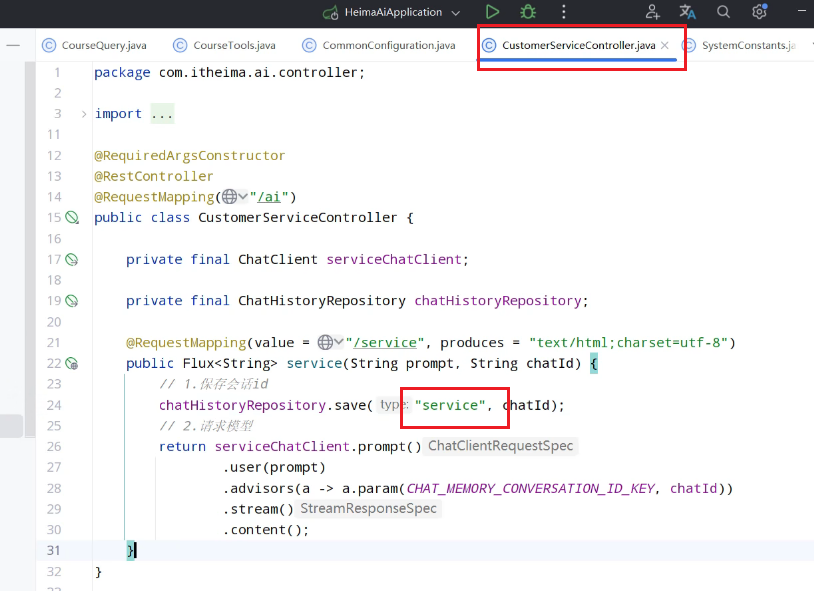
因为加入了数据库的操作,需要在启动类加上包扫描:
启动运行,向ai发出提问,但是ai没有反应,后台日志报错:

这是非法参数异常,指的是工具输入是非法的,因为使用的模型是openAi的API,但是实际模型是阿里百炼的大模型,虽然说阿里百炼兼容openai,但是实际兼容的并不优秀。
当我们使用function calling时,如果使用的是stream流的模式,在返回调用函数结果时,传参的格式与openai官方的格式不匹配,需要手动拼接来处理。
修复这个错误有两种方法,1是不使用stream流模式,如图:
其实注意,在2026年这个其实已经兼容了,即没有这个烦恼,学习的资料在那时是不兼容的,此处记录方法。
第二种方法就是重写openai chat model或者自己定义一个类似的chat model,去对接阿里百炼平台。
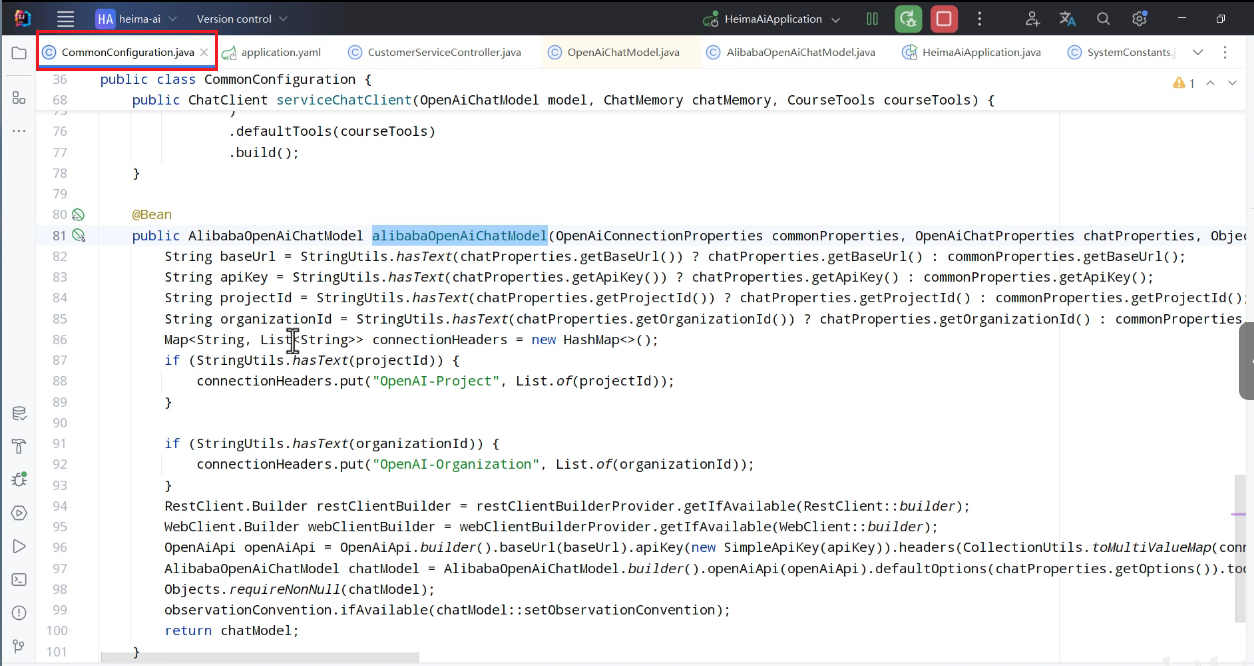
如图报错:这个问题即不兼容问题,显示第二种重写方法

位置大概在
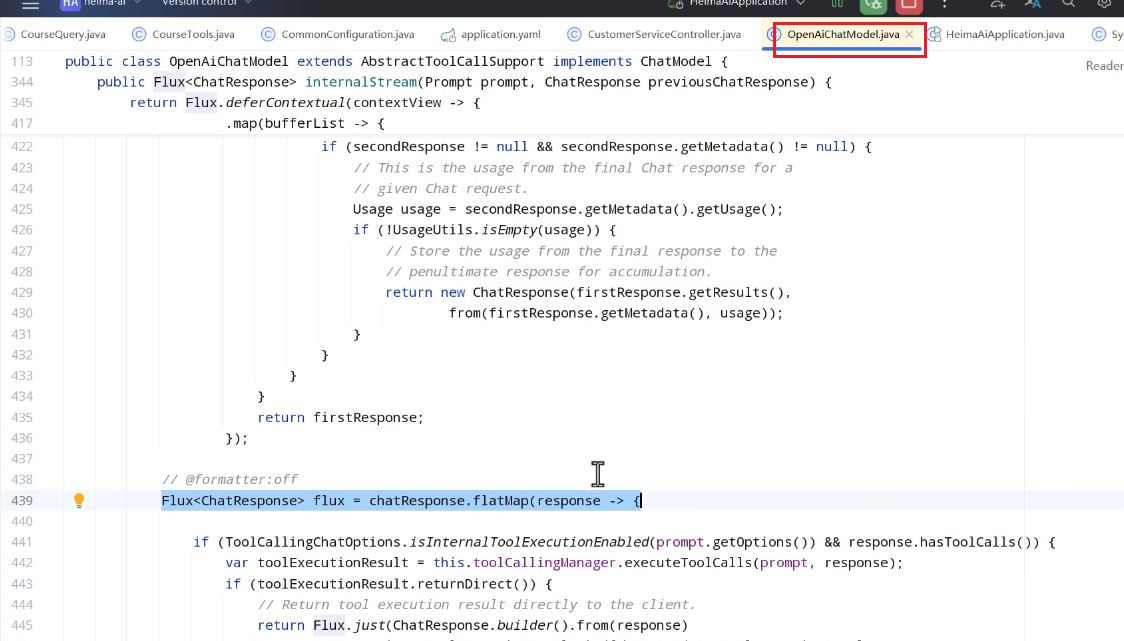
重写的话不需要自己写,只需要复制: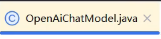 这个类的代码,粘贴到创建的类:AibabaOpenAiChatModel
这个类的代码,粘贴到创建的类:AibabaOpenAiChatModel
修改这几个地方:添加reduce

并不是定义完就可以使用的,还需要将其声明成一个bean对象。但这个model的构造方法都是@Deprecated,这是弃用的,如图:

所以想要创建对象的话还需要builder工厂,这比较麻烦,如何解决:
在config中写一份代码:
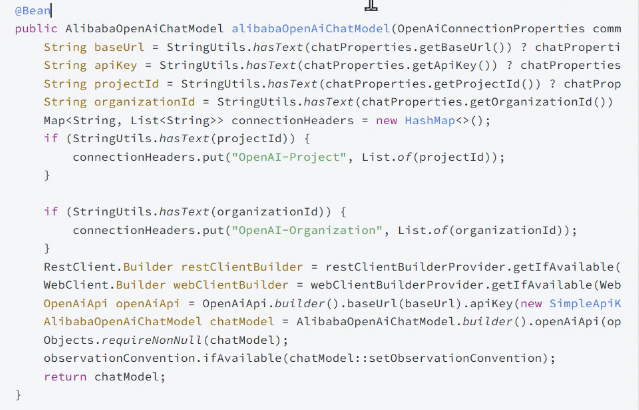
如图所示:
对接大模型
chatPDF
向量模型
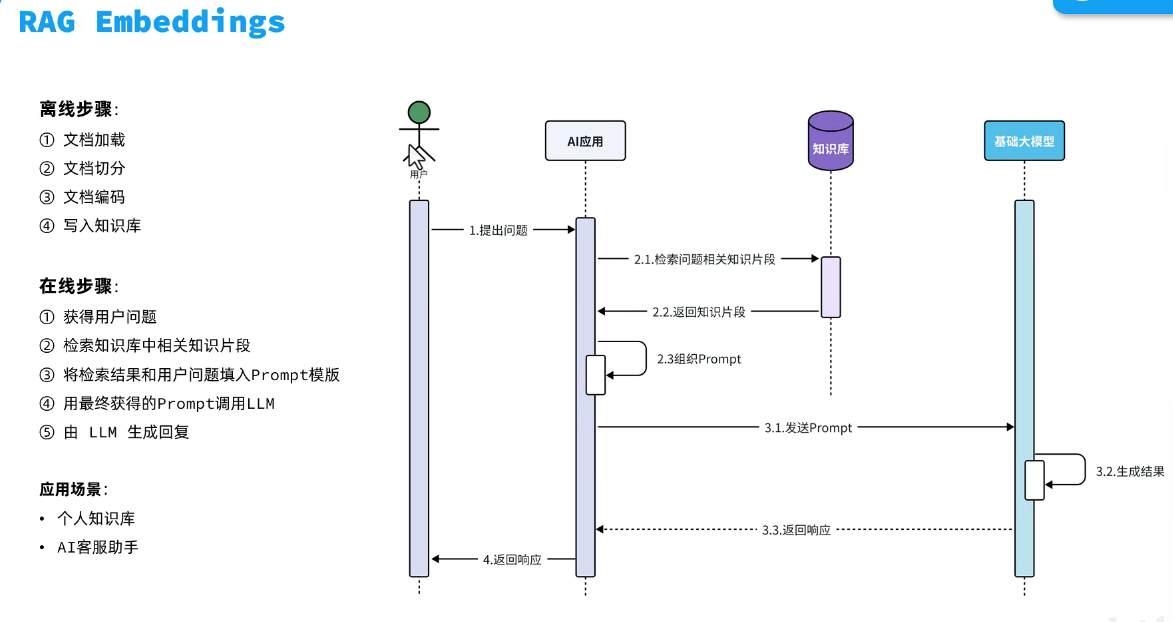
大模型对提示词是由限制的,并且token是有限的,直接将完整知识库和提示词发给大模型其实更省心省钱,而完整的其实太大了,拆成一部分一部分,其实就是skills,也就是RAG原理。
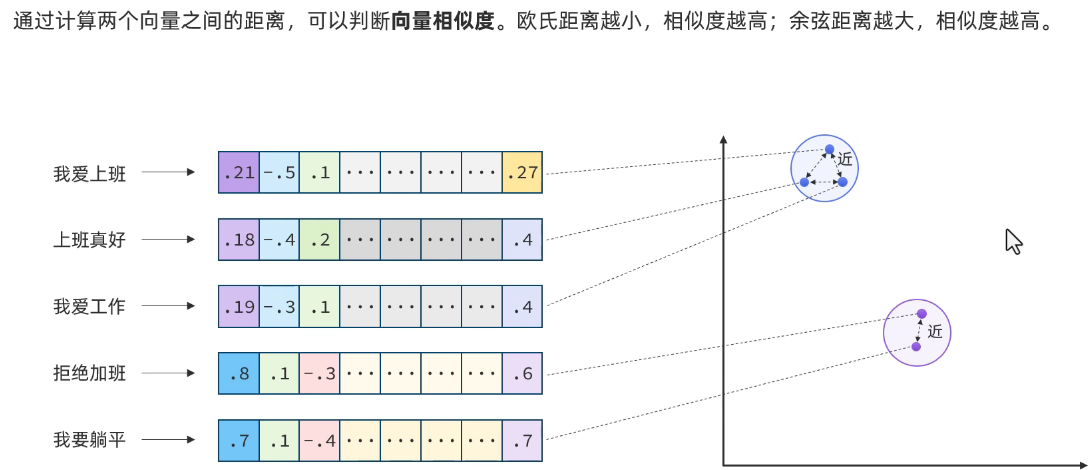
接下来就是连接向量模型,使用向量模型对文档进行向量化。
引入依赖:

配置向量模型:
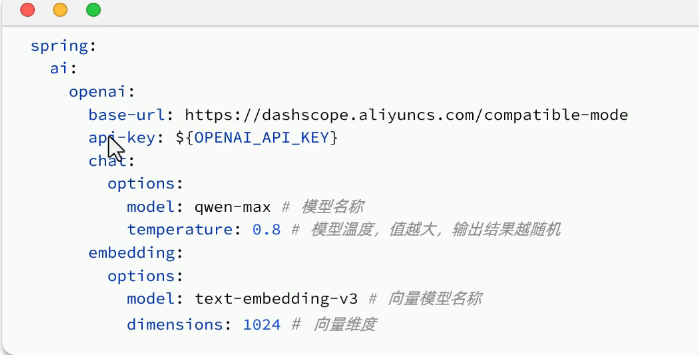
和对话大模型有点区别的就是下面模型名称和向量维度
使用EmbeddingModel:

进行连接:

配置信息:
需要注意,在使用openai不同的对话模型时,可以配置不同的apikey,甚至可以连接不同的平台:
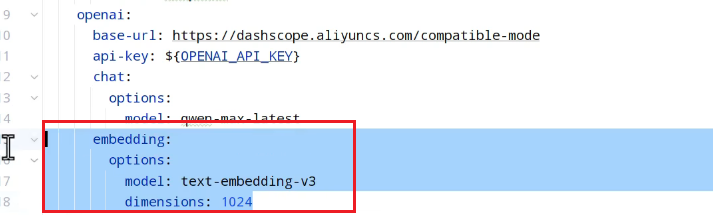
先写一个单元测试测试这个向量模型:

这个document是springai封装的数据格式,叫做文档。
测试代码:
选择string字符串:

运行会报错,需要配置环境变量:
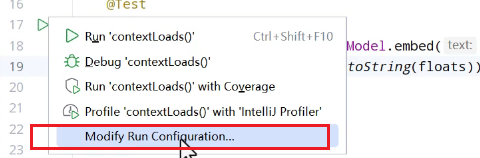
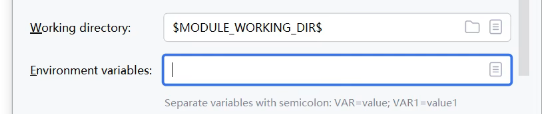
配置的是自己的api_key.
运行结果是这样:

目前这没什么用。
接下来就有用了,因为即将测试衡量文本之间的相似度:
创建一个工具类:
然后根据文档进行计算,查看相似度:
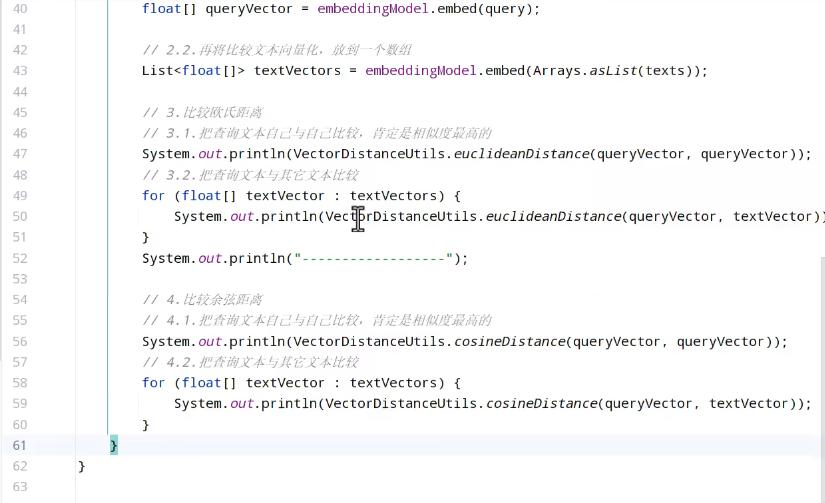
运行失败的话还需要再配置一次环境变量。
运行之后,结果:
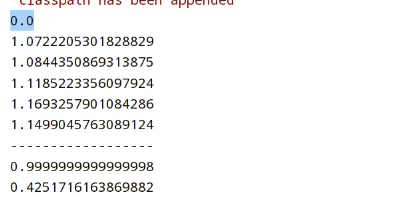
欧式距离越小相似度越高。
向量数据库
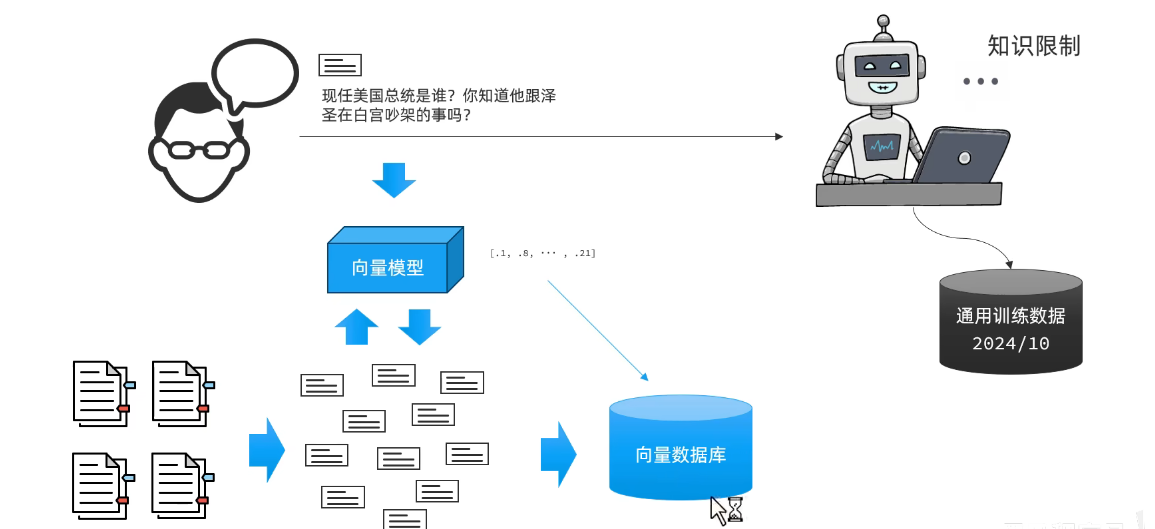
向量数据库就是一个存储和检索向量的东西。
引入依赖:
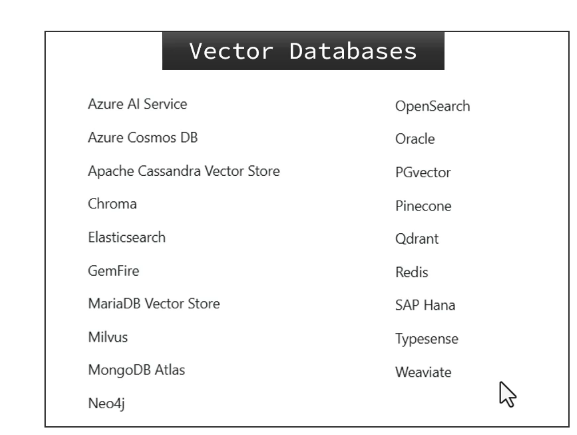
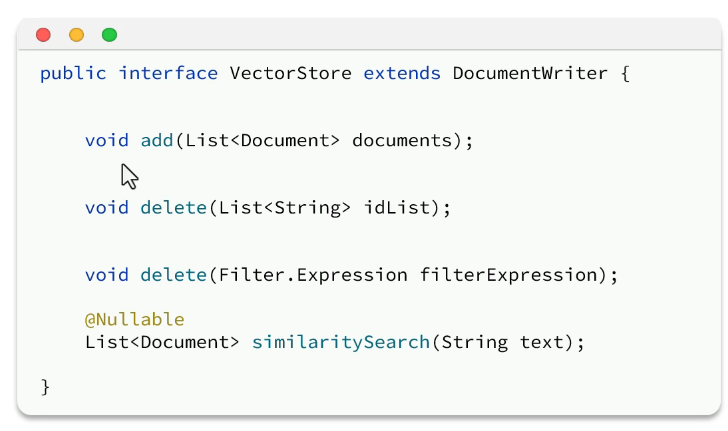
向量数据库其实非常的多,如图所示,好在springai对所有向量数据库做了一些抽象,定义了统一的接口标准。
即对接数据库操作应该是类似的操作。
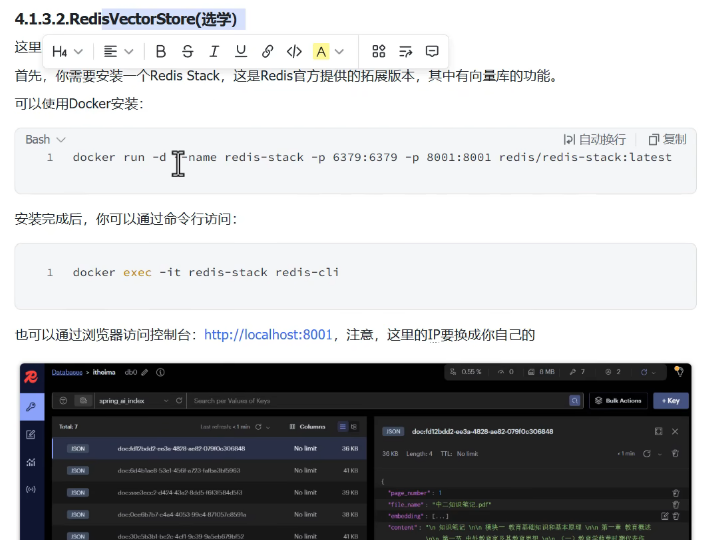
以向量redis举例,这个和平常缓存用的并不一样,这是redis的企业版:
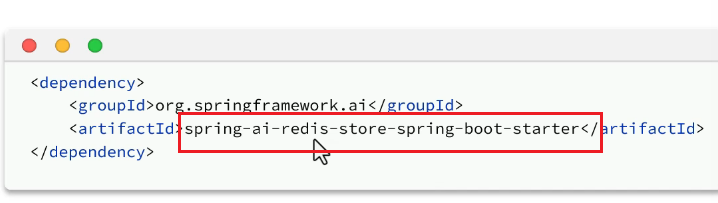
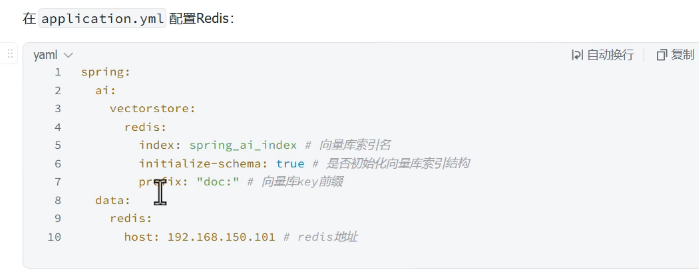
配置向量数据库
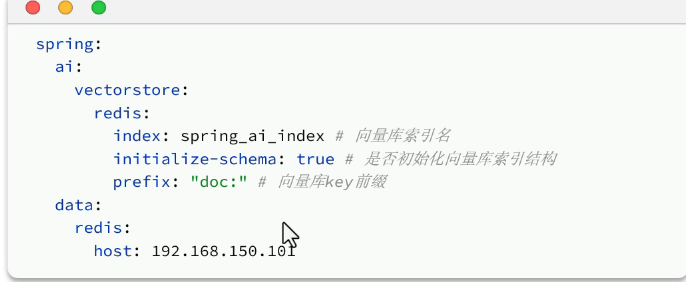
向量库索引名:用redis存储向量时,它其实是要给这些向量创建索引的,所以需要名字,也需要设置向量库的索引结构
当然不同的数据库肯定有差异,访问spring官网进行学习:

不同的数据库配置:
但是所有的向量数据库都需要进行安装,仅作为学习演示的话springai也准备了演示用的:

这个不用安装,但只能进行学习而不是用来生产。
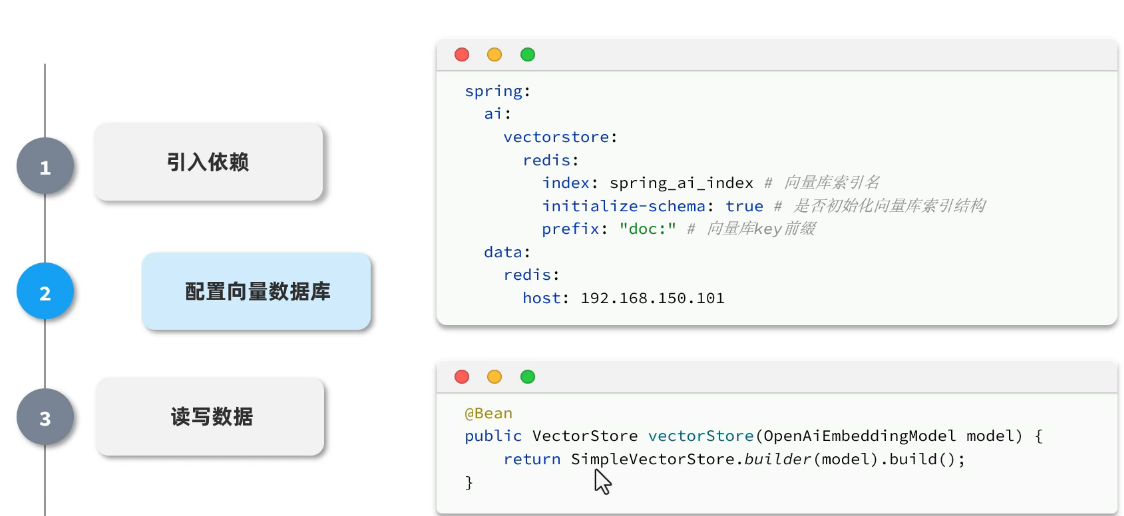
读写数据:
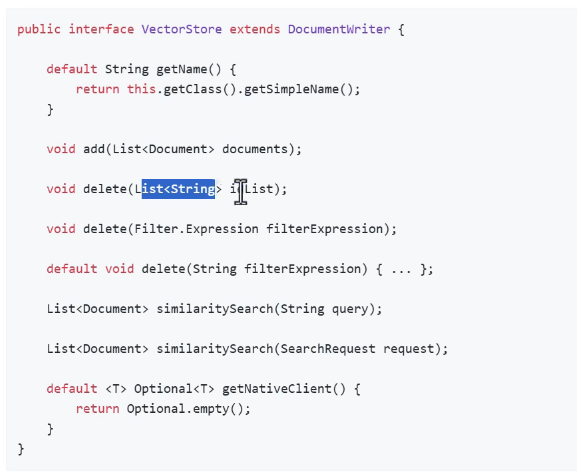
使用教学的库:
使用redis的话:
进行教学库的演示:
读写数据:
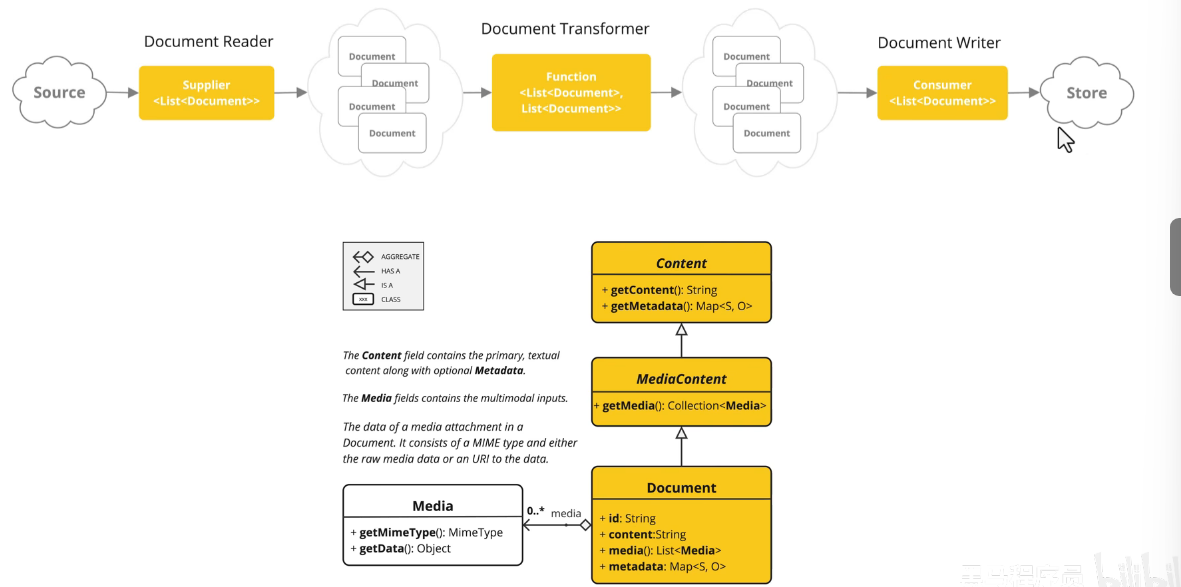
如何将文件转成document类型,然后再进行增删改查操作呢
PDF处理
使用PDF处理可以将转成document。
引入依赖

读取拆分文档

具体步骤:
导入依赖:

配置向量库的bean:
新版要引入spring-ai-starter-vector-store-redis依赖(官网复制),里面有VectorStore
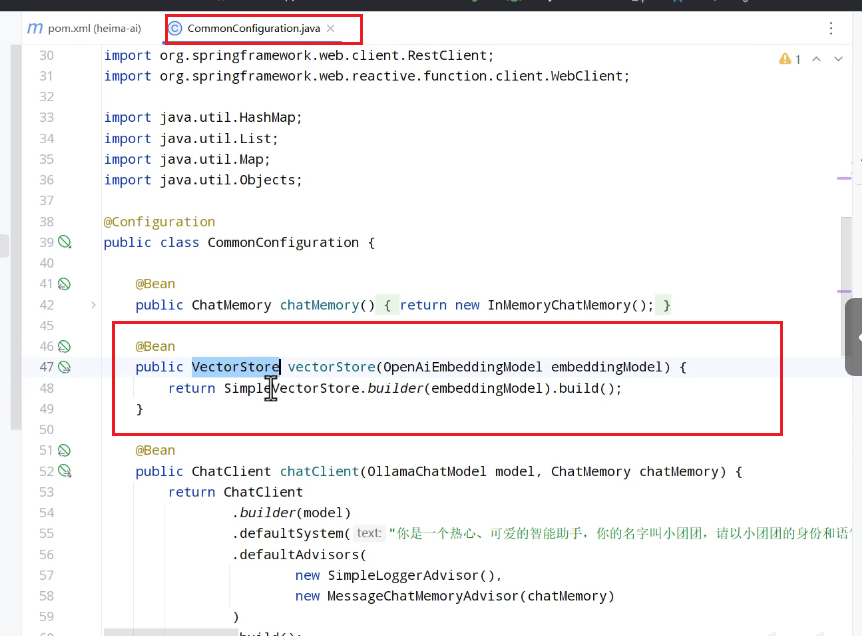
其他的库比如redis啊不是演示的库这一步不用做,因为会自动装配。
进行测试:
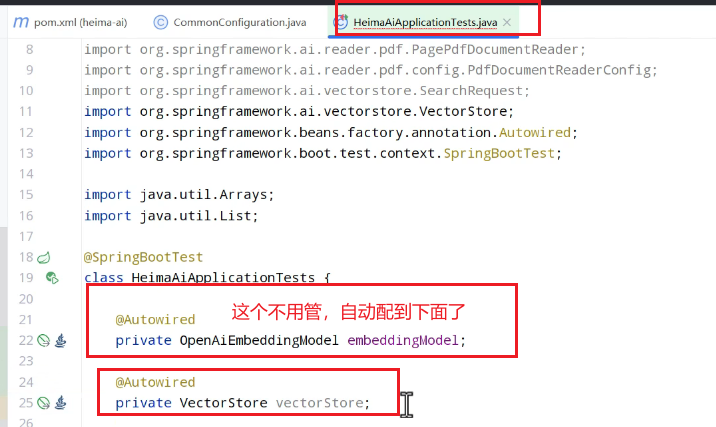
报错的话引入依赖:
spring-ai-vector-store
测试代码:
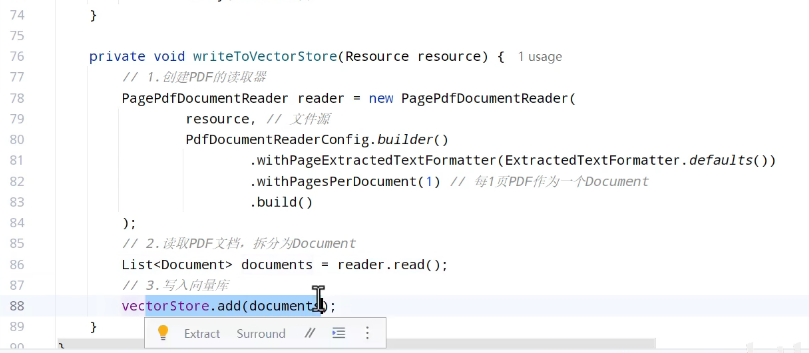
创建pdf读取器
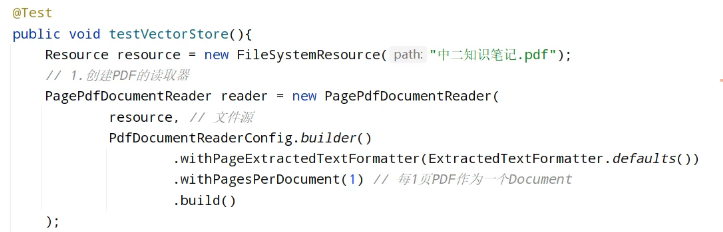
读取pdf文件拆分为document

写入向量库

搜索
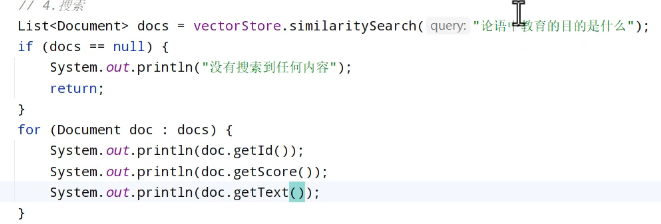
当然,在搜索中是可以进行配置的,这个搜索叫做默认搜索,想要搜索的准确一点,进行配置:
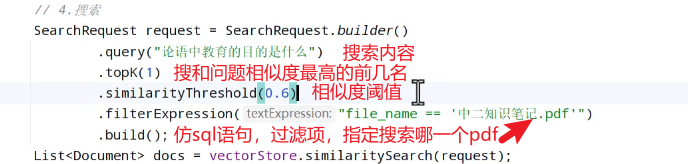
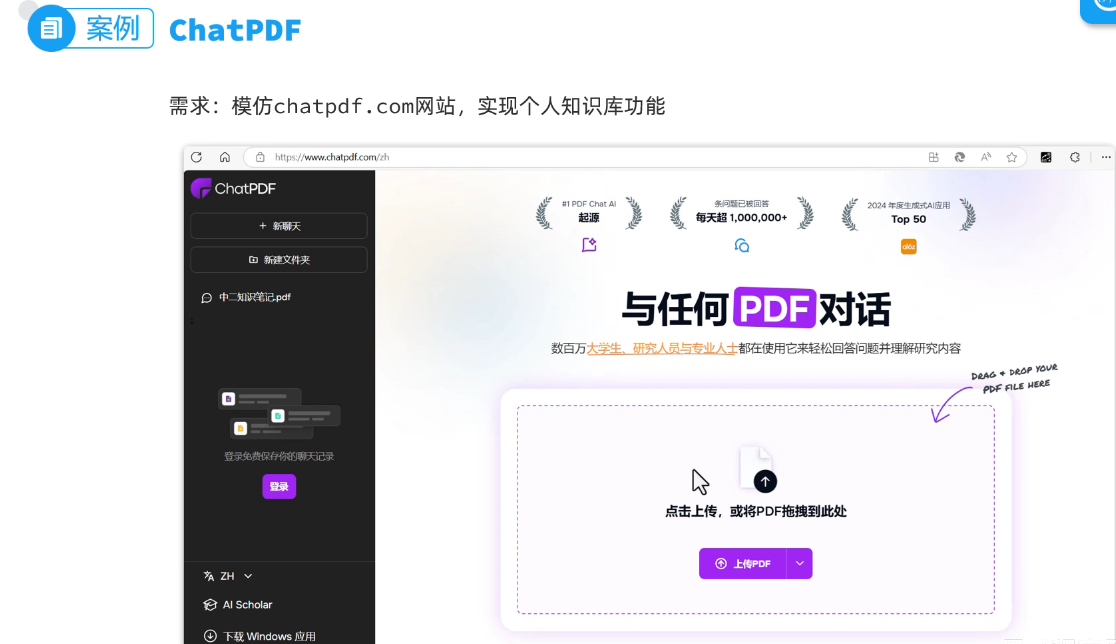
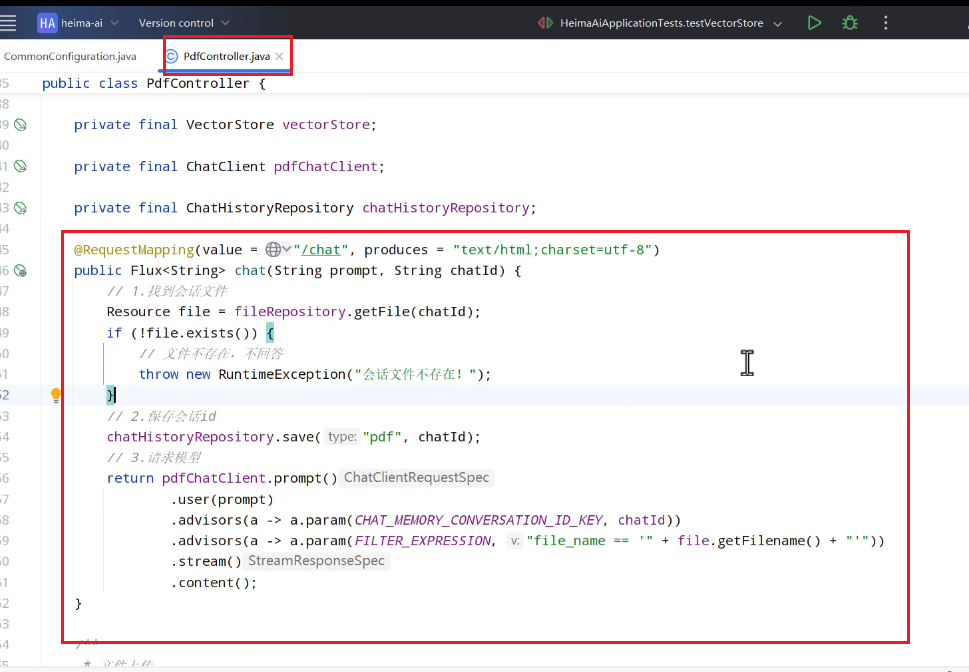
ChatPDF
需求:
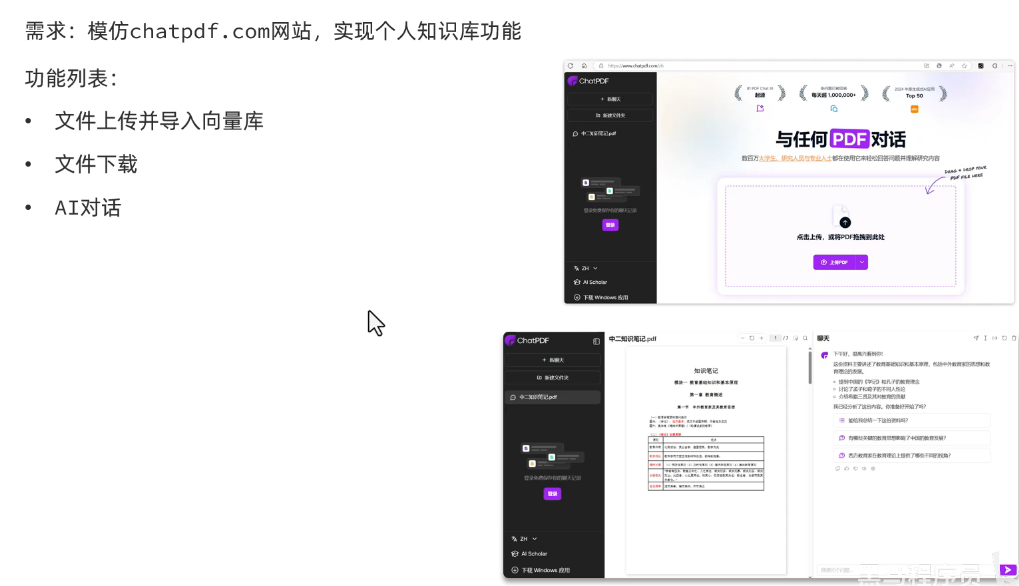
功能:
代码:
写一个管理会话id与文件之间映射关系的接口:
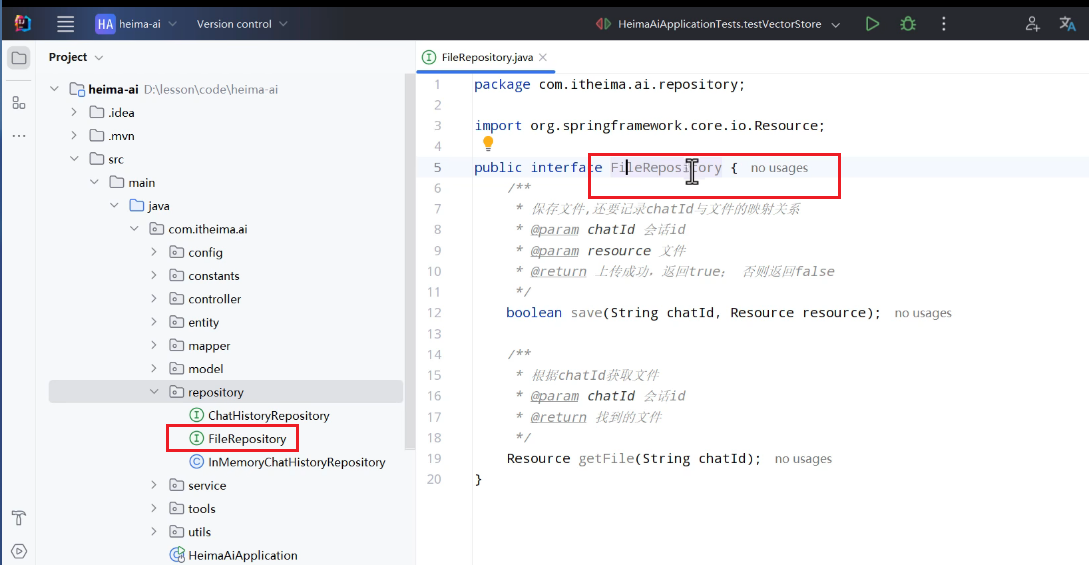
实现类:
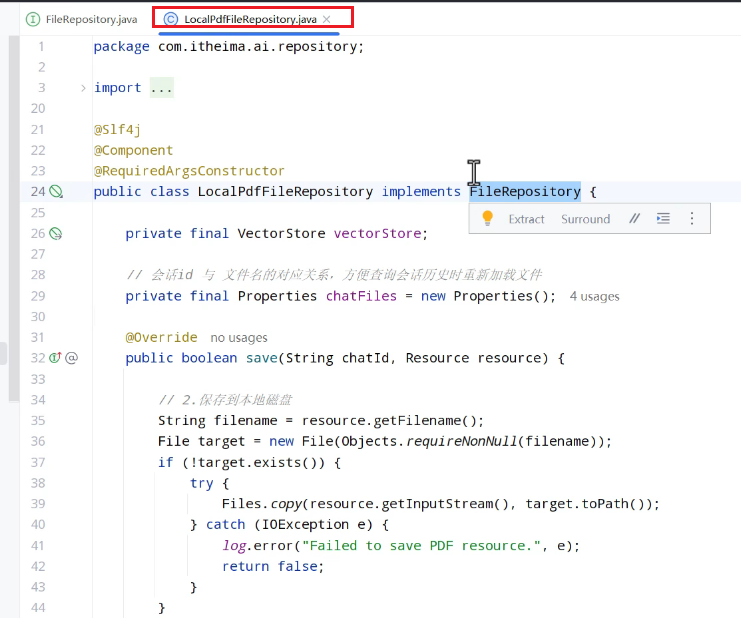
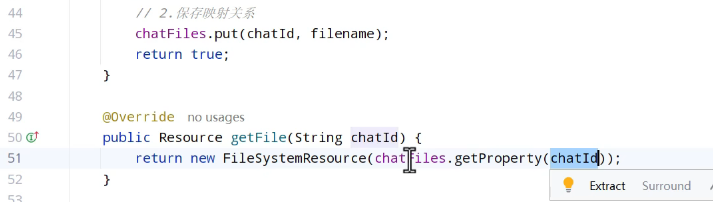
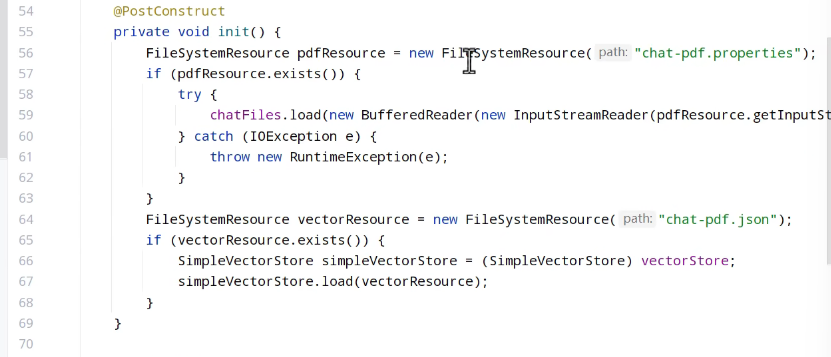

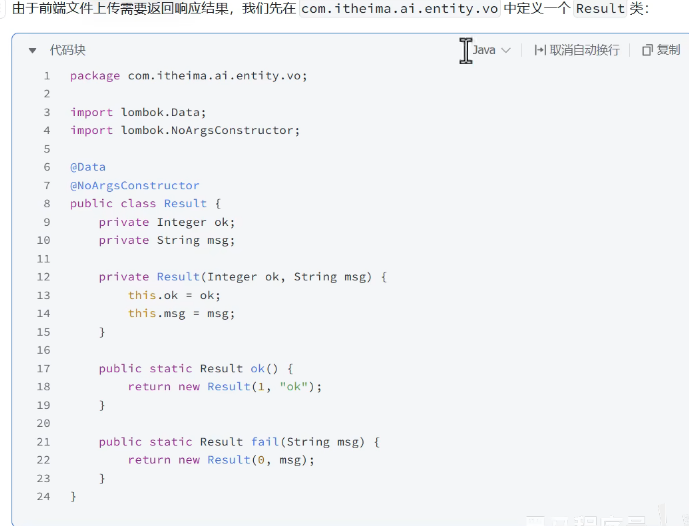
创建result类返回响应结果:
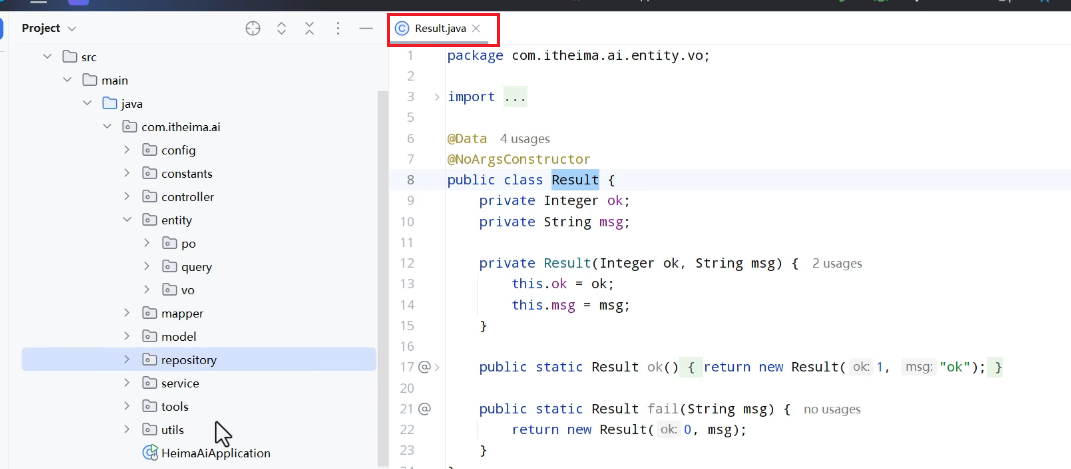
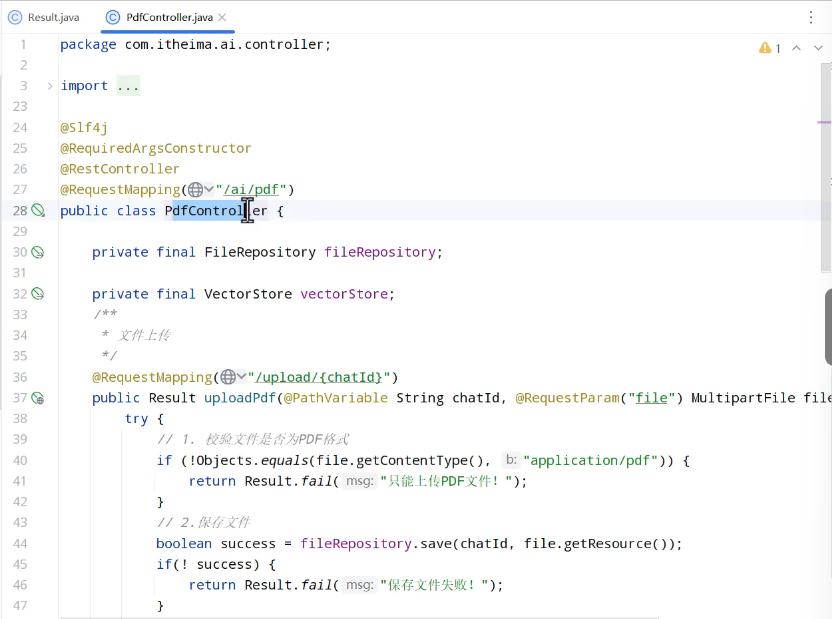
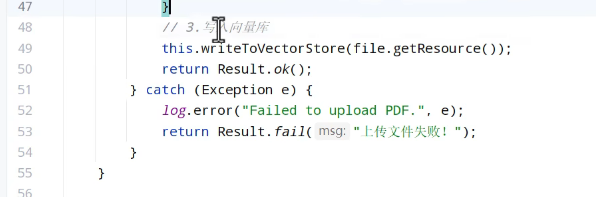
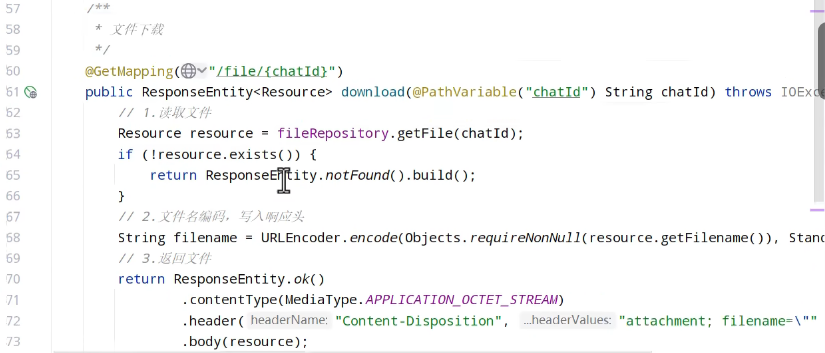
文件上传和下载控制类:
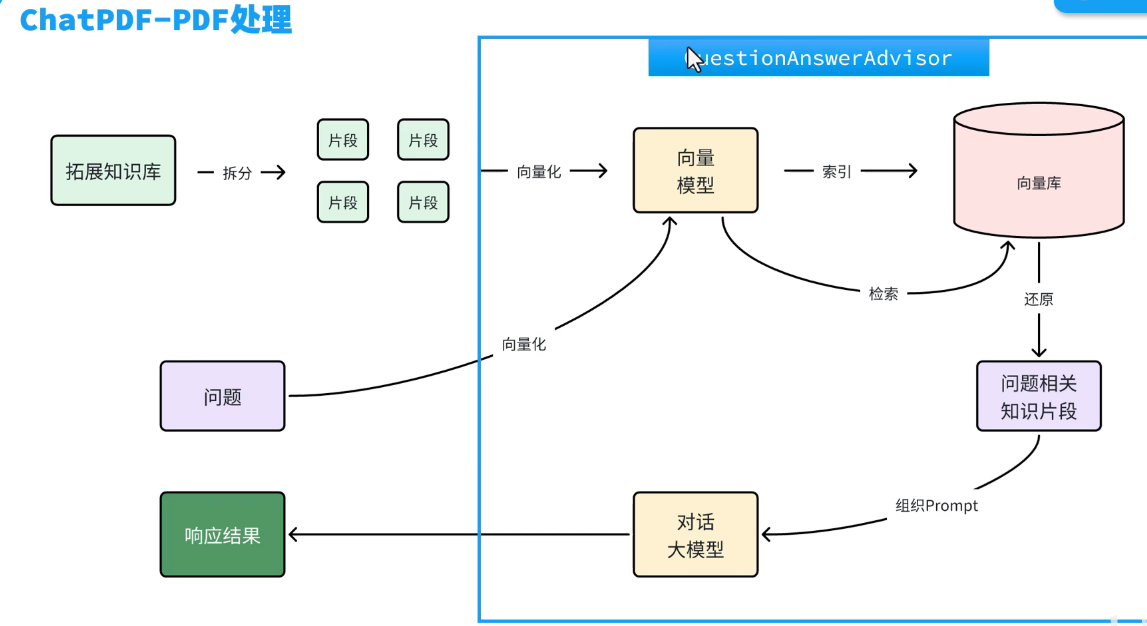
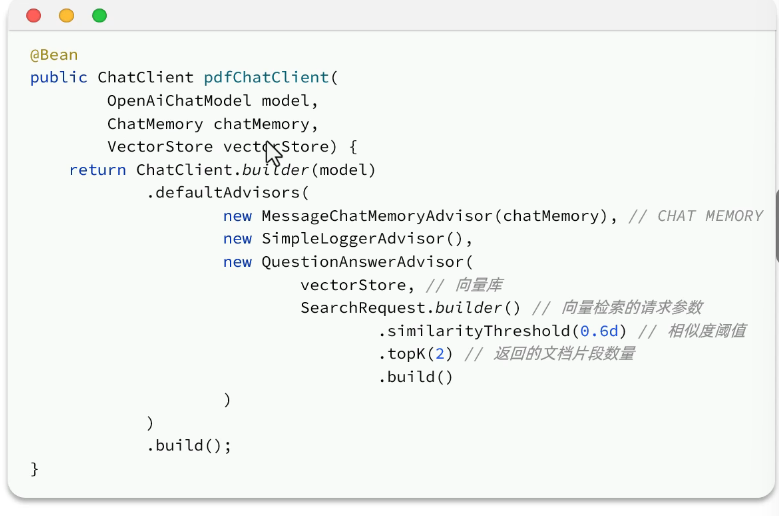
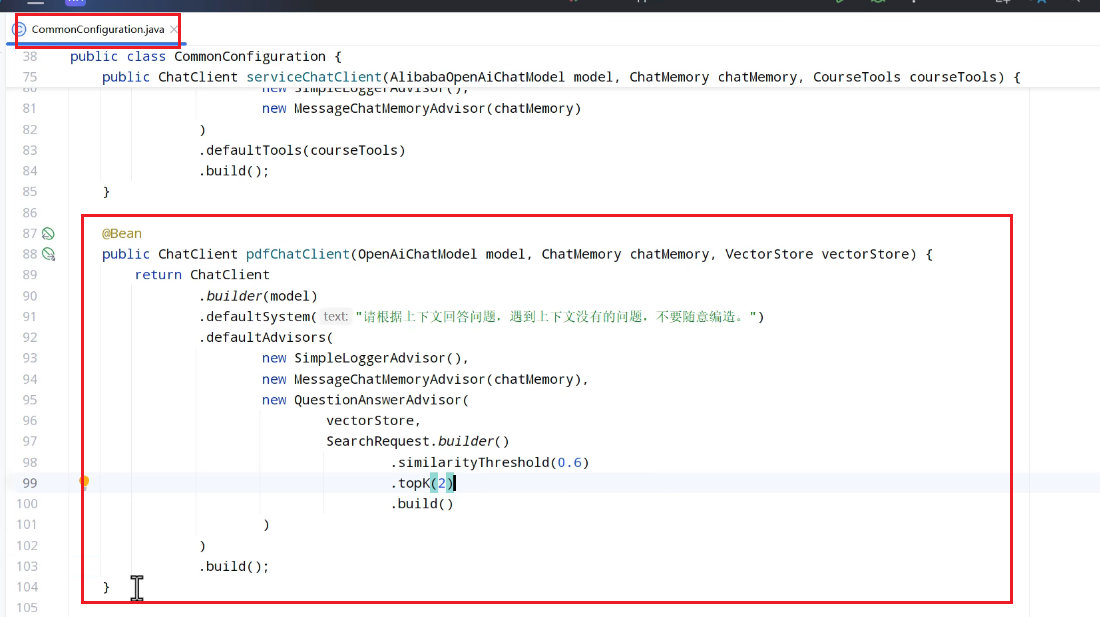
配置RAG Advisor:
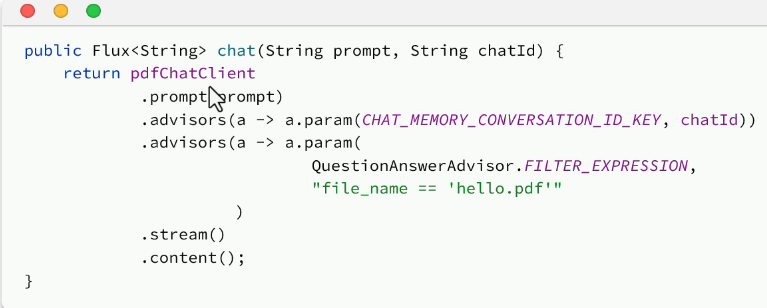
对话和检索:
代码:
因为不存在兼容问题:
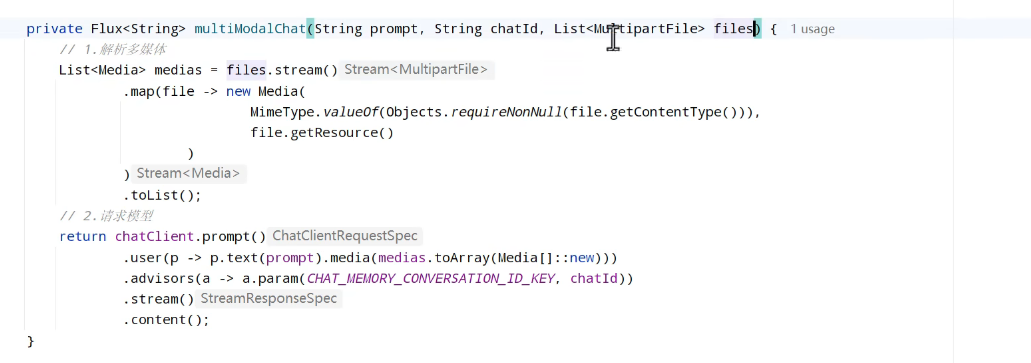
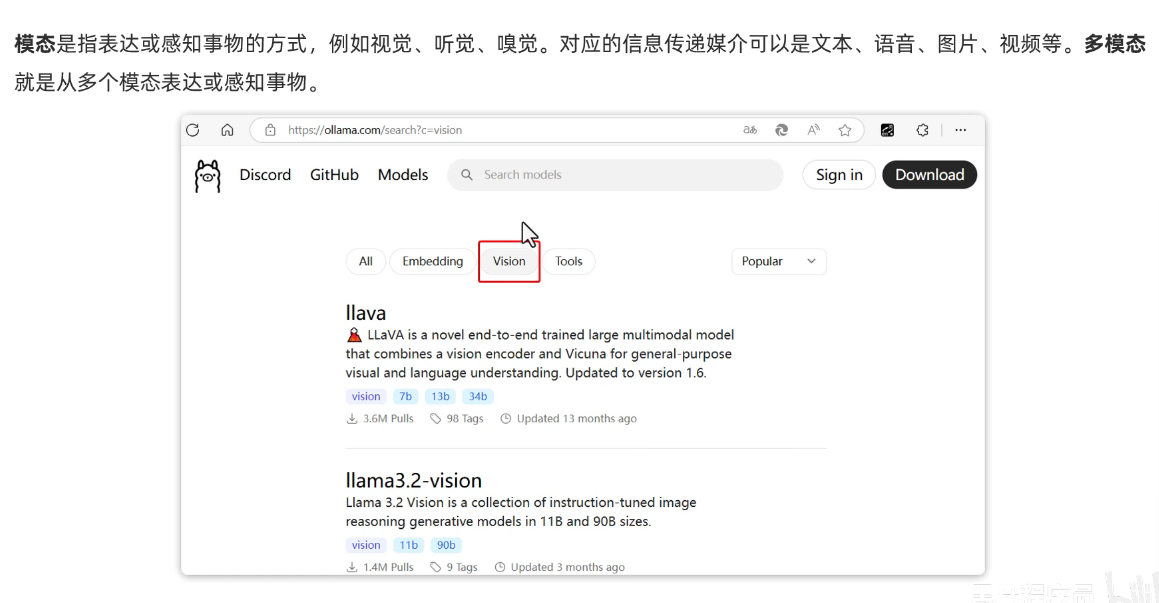
多模态会话
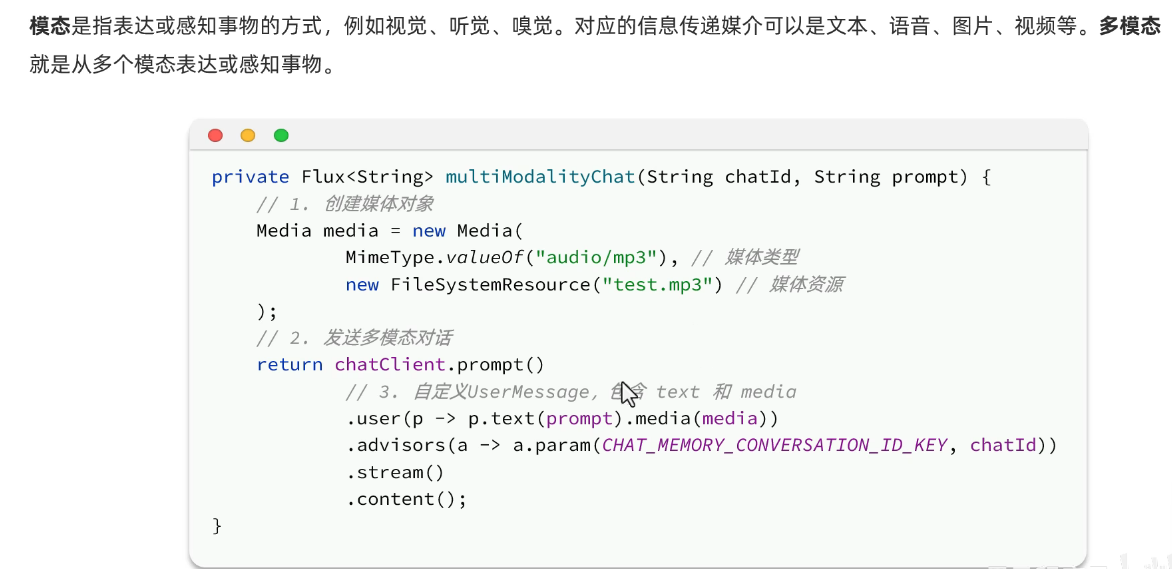
代码:
所有的chatClient都支持自定义模型配置,不一定要在yaml中进行配置,局部配置:

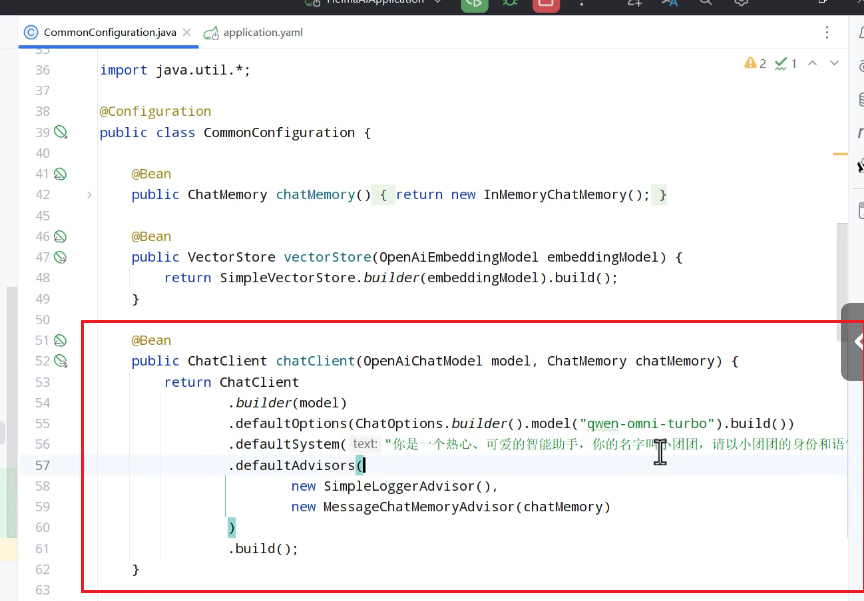
会话方式:
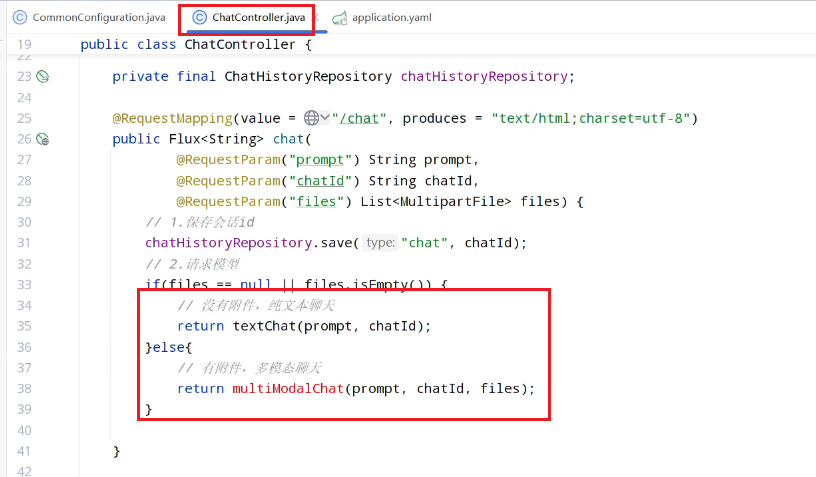
方法:
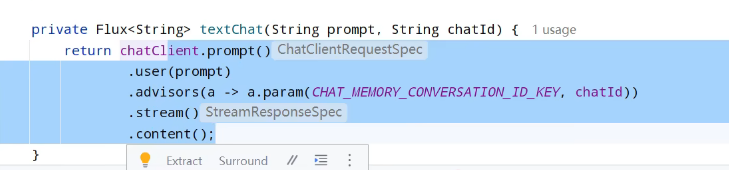
方法: