🔔 关注【IvorySQL开源数据库社区】公众号即可获取 PostgreSQL 一手干货与最新动态

⚙️ PostgreSQL技术文章
🧩 PGConf.dev 2026 日程公布!

PGConf.dev 2026,即PostgreSQL Development Conference,将于2026年5月19-22日在加拿大不列颠哥伦比亚省Vancouver举行。会议日程已公布,今年的议程有所扩展,包括周二的社区主导会议和庆祝PostgreSQL项目30周年的特别活动。这个为期四天的活动汇集了PostgreSQL用户、开发者和社区组织者,专注于开发协作和社区发展。会议将涵盖即将推出的PostgreSQL功能、开发挑战和用户故事。目前注册已开放,组织者建议提前预订住宿。此次会议得到赞助商的支持,是全球PostgreSQL贡献者合作未来发展的顶级聚会。
www.postgresql.org/about/news/...
🧩 开发人员在存储传感器数据方面经常犯的错误

开发人员在存储传感器数据时经常错误地将其视为传统的事务数据库行,使用标准化模式和关系模式。当设备数量增加、采样率提高、历史数据积累时,这种方法在规模上会失败。核心问题是概念性的:传感器数据看起来像行,但实际上表现为时间有序的数据流,其价值随着时间推移而下降。传统的面向行的方法难以处理连续的数据摄取突发、时间范围查询和乱序数据到达。解决方案需要认识到传感器数据是具有衰减特性的仅追加日志,需要专门的时间序列架构,具备日志优化摄取、时间分区组织、生命周期分层和针对不同工作负载的角色分离。
www.tigerdata.com/blog/what-d...
📨 PostgreSQL Hacker 电子邮件讨论精选
🧩 添加 REPACK 并发
讨论重点是修复REPACK CONCURRENTLY实现中的崩溃问题。Srinath确定了根本原因:在DecodingContextFindStartpoint期间repacked_rel_locator.relNumber被设置为InvalidOid,导致change_useless_for_repack过滤器失效。这使得不相关的变更被解码并添加到reorderbuffer队列中,从而引发断言失败。Alvaro发布了v43版本,进行了重大修改,将实现改为使用table AM和slots中的元组而不是HeapTuple,以避免昂贵的重复元组形成/解构操作。他将Srinath的修复作为补丁0005并包含了table AM选项更改。Antonin澄清他的0004补丁的元组解构是必要的,用于处理外部属性并将其写入文件,因为来自reorderbuffer.c的元组可能包含指向worker内存的外部间接属性。
www.postgresql.org/message-id/...
🧩 通用计划和"初始"修剪
Amit Langote提出了一个解决方案,通过早期剪枝来避免PostgreSQL通用计划中不必要的分区锁定。当前方法通过AcquireExecutorLocks()预先锁定所有分区,即使是初始剪枝会消除的分区。提议的修复在GetCachedPlan()中引入ExecutorPrep(),在锁定决策之前执行有限的执行器工作(范围表初始化、权限、剪枝)。该解决方案通过使新的CachedPlanPrepData参数可选来保持向后兼容性。主要关注点包括确保调用者正确地将prep EStates传递给执行器,以避免在未锁定的关系上操作。调试断言验证适当的锁定不变量。该方法跨越了计划缓存和执行器之间的传统边界,需要仔细的契约执行。Amit寻求关于在GetCachedPlan()内运行执行器逻辑是否可接受的反馈,目标是先提交补丁0001-0003。
www.postgresql.org/message-id/...
🧩 pg_plan_advice 查询计划建议
讨论的焦点是新提交的test_plan_advice模块(用于pg_plan_advice)的性能问题。Tom Lane强烈反对该测试运行整个核心回归测试套件两次(每个计划一次),称其为对buildfarm资源的"过度滥用",在较慢的机器上增加了10%的运行时间。Robert Haas为全面测试辩护,认为这是开发过程中最有效的工具,发现bug的效果比其他方法高出几个数量级。该测试在两天内已经发现了三个独立的问题,包括虚拟生成列索引问题、memoized嵌套循环问题,以及当统计信息在计划周期间发生变化时AlternativeSubPlan机制的冲突。提出的解决方案包括添加测试优先级以减少挂钟时间、搭载现有回归运行,或在buildfarm成员子集上运行测试。Tom承认发现bug的价值,但仍然担心资源消耗,而Robert探索已发现问题的技术修复,并考虑修订相关的pg_collect_advice补丁。
www.postgresql.org/message-id/...
🧩 索引预取
Peter Geoghegan在v15出现代码腐化后发布了index prefetching补丁集的第16版。此次更新包含两个显著变化。首先,他对修复selfuncs.c机制问题采取了更保守的方法,该机制在get_actual_variable_range在规划期间执行过多工作时会放弃操作。由于缺乏共识和时间限制,他没有实施基于叶页面的新方法,而是在heapam端重新实现了现有的VISITED_PAGES_LIMIT机制。新的基于slot的接口无法支持调用者自行计算检查的堆页面数量。其次,他通过激进的专门化改进了缓存工作负载性能,为不同扫描类型创建了四个版本的回调例程(仅索引扫描vs普通索引扫描,配合amgetbatch vs amgettuple)。尽管对增加代码大小存在担忧,但这个版本在所有可用基准测试中都实现了最佳性能指标。
www.postgresql.org/message-id/...
🧩 更好的共享数据结构管理和可调整大小的共享数据结构
Heikki Linnakangas和Robert Haas正在讨论PostgreSQL共享内存管理系统的改进。Linnakangas提出使用ShmemRegisterStruct()的新API来替代当前的shmem_request/startup_hook机制,旨在消除请求和分配内存大小之间的不匹配。该提案包括移动pg_stat_statements初始化代码并引入将结构体、哈希表和回调函数捆绑在一起的"子系统"概念。Haas对基于描述符的方法表示担忧,认为与命令式代码相比过于限制,更倾向于命名内存对象和更简单的回调机制。他建议采用DefineShmemRegion()函数的替代设计,当模块未通过shared_preload_libraries加载时,可以从DSA或剩余空间动态分配。两人都认同核心问题:内存请求与分配之间的脱节、需要条件检查的不明确初始化上下文,以及对更好扩展加载灵活性的需求。讨论显示了基于描述符的声明式方法与更灵活的命令式代码设计之间的分歧。
www.postgresql.org/message-id/...
🧩 不要在读取流中同步等待已在进行的IO
Andres Freund正在修订PostgreSQL读取流功能中异步I/O处理的补丁系列。原始方法引入了:
PrepareHeadBufferReadIO()和PrepareAdditionalBufferReadIO()函数,但Freund发现了代码重复和测试覆盖率降低的问题。他提出了一种不同的方法,修改现有的StartBufferIO()函数以返回枚举值并接受用于异步等待的PgAioWaitRef参数。这种方法整合了逻辑并与现有测试基础设施保持兼容性。修订后的方法需要调用者自己设置operation->foreign_io,但避免了在多个变体中重复逻辑。Freund还进行了其他清理工作,包括在AsyncReadBuffers()中移动pgstat_prepare_report_checksum_failure()和标志计算,并用断言替换了关于暂存I/O提交的注释。他在扩展测试覆盖率之前寻求对这一结构性变更的反馈。
www.postgresql.org/message-id/...
🌐 社交媒体动态
🧩 Wordle和 PostgreSQL有什么关系?

本内容宣布了 pgDay Paris 2026 的一场会议,高级开发人员 Pavlo Golub 将演示如何使用 PostgreSQL 定制 Wordle 游戏。演讲将涵盖单词选择逻辑和用户会话处理等技术方面。会议将于 2026 年 3 月 26 日 15:30 至 16:15 在巴黎圣马丹街 199bis 号礼堂举行。该会议面向 PostgreSQL 专...
www.linkedin.com/posts/cyber...
🧩 在#NVIDIAGTC大会上,NVIDIA推出AIRuntime,Databricks现已提供无服务器NVIDIAA10和H100GPU用于训练和微调。
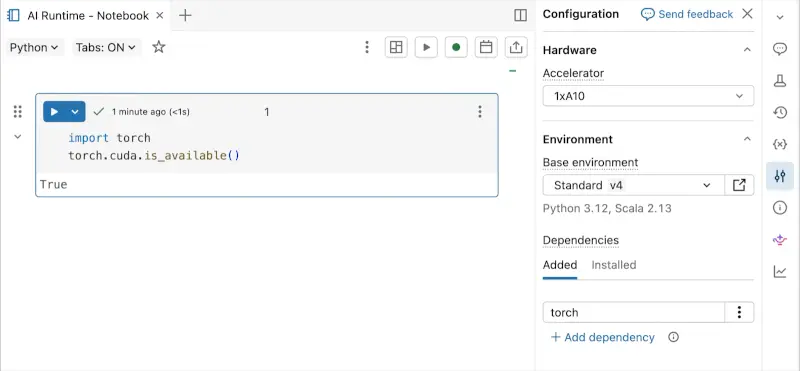
在 #NVIDIAGTC 大会上,NVIDIA 推出了 AI Runtime 现已在 Databricks 上提供无服务器 NVIDIA A10 和 H100 GPU 用于训练和微调。GPU 基础设施一直是 AI 团队面临的主要障碍,包括冗长的采购周期、复杂的分布式设置和数据瓶颈问题。AI Runtime 通过提供无需集群管理的按需 GPU、预装框架的优化...
www.linkedin.com/posts/datab...
🧩 Databricks上的Apache Spark结构化流处理实时模式现已完成发布。

Real-Time Mode(RTM)用于Apache Spark结构化流处理,现已在Databricks上正式发布。此前,团队需要使用Apache Flink等独立引擎来实现超低延迟,导致代码库和运营开销重复。RTM为现有的Spark API带来了毫秒级延迟。早期采用者报告了显著成果:Coinbase在计算250多个机器学习特征的同时实现了超过80%的延...