版本 : 2026-03-17
硬件 : 2× NVIDIA DGX Spark (GB10 GPU, SM121, 128GB 统一内存)
模型 : MiniMax-M2.5-NVFP4 (230B MoE, NVFP4 量化, ~120GB)
软件栈 : SGLang (源码编译) + PyTorch 2.9.1+cu130 + CUDA 13.0
网络: QSFP 200GbE 直连线缆
Openclaw配置参考:
结果展示:
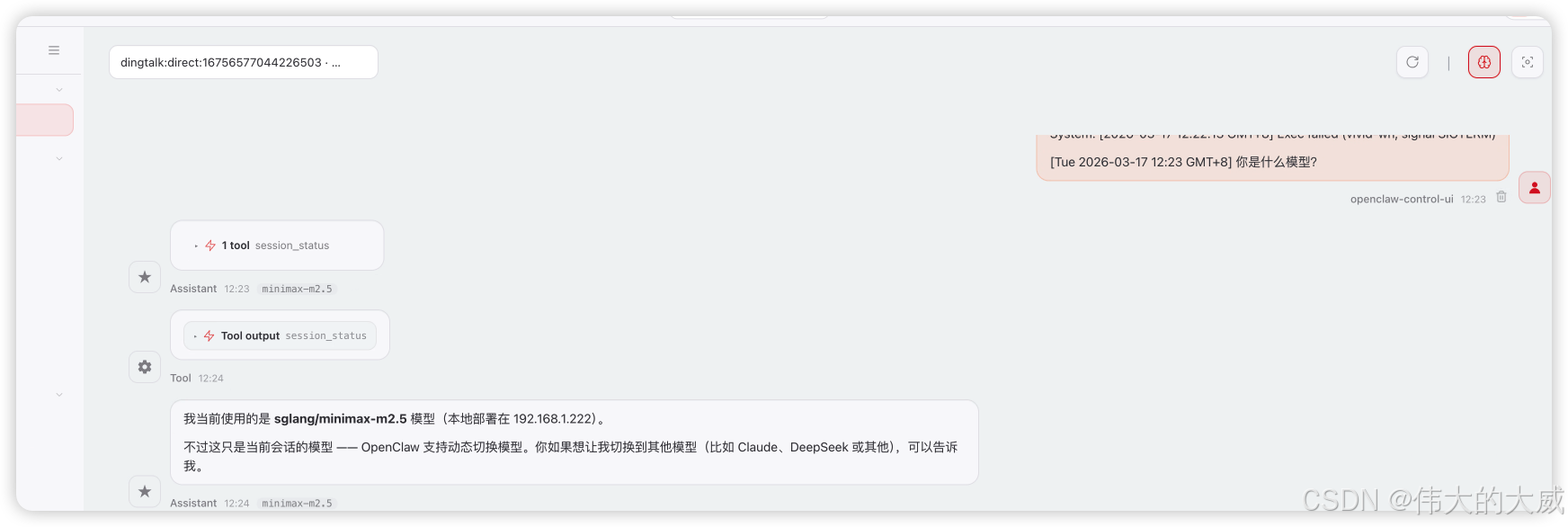
DGX 设备:

目录
- 背景与架构说明
- 硬件与网络准备
- 已知问题与解决方案总览
- [Step 1: 环境清理](#Step 1: 环境清理)
- [Step 2: 安装 PyTorch 2.9.1+cu130](#Step 2: 安装 PyTorch 2.9.1+cu130)
- [Step 3: 安装编译依赖](#Step 3: 安装编译依赖)
- [Step 4: 克隆 SGLang 源码](#Step 4: 克隆 SGLang 源码)
- [Step 5: 编译 sgl-kernel](#Step 5: 编译 sgl-kernel)
- [Step 6: 安装 SGLang](#Step 6: 安装 SGLang)
- [Step 7: 修复 Triton ptxas](#Step 7: 修复 Triton ptxas)
- [Step 8: 验证安装](#Step 8: 验证安装)
- [Step 9: 配置 Worker 节点](#Step 9: 配置 Worker 节点)
- [Step 10: 启动多节点推理服务](#Step 10: 启动多节点推理服务)
- [Step 11: 测试与监控](#Step 11: 测试与监控)
- [Step 12: OpenClaw 集成配置](#Step 12: OpenClaw 集成配置)
- 故障排除手册
- 性能参考数据
1. 背景与架构说明
1.1 DGX Spark GB10 的特殊性
DGX Spark 搭载的 GB10 GPU 计算能力为 SM121 (compute capability 12.1),这与数据中心级 Blackwell GPU (SM100) 有本质区别:
| 特性 | SM100 (B200/B300) | SM121 (DGX Spark GB10) |
|---|---|---|
| tcgen05 指令 | ✅ 支持 | ❌ 不支持 |
| TMEM (Tensor Memory) | ✅ 支持 | ❌ 不支持 |
| WGMMA 指令 | ✅ 支持 | ❌ 不支持 |
| FlashMLA 原生支持 | ✅ | ❌ |
| FlashAttention 4 | ✅ | ❌ |
| 共享内存限制 | 228KB | 101,376 bytes |
这意味着大量 ML 库的预编译二进制文件不能直接在 DGX Spark 上运行,必须从源码编译。
1.2 为什么不用 Docker
NVIDIA 官方提供了 lmsysorg/sglang:spark Docker 镜像,但:
- 镜像版本可能滞后
- 多节点 Docker 网络配置复杂
- 本教程覆盖源码编译的完整流程,适用于任何自定义需求
1.3 部署架构
┌─────────────────────┐ 200GbE ┌─────────────────────┐
│ spark-1 (Head) │◄──────────────►│ spark-2 (Worker) │
│ 169.254.131.196 │ QSFP 直连 │ 169.254.191.100 │
│ GB10 GPU (TP0) │ │ GB10 GPU (TP1) │
│ SGLang Server │ │ SGLang Worker │
│ HTTP :8000 │ │ (无 HTTP 端口) │
└─────────────────────┘ └─────────────────────┘
│
▼
API 端点: http://169.254.131.196:8000/v1- Tensor Parallelism (TP=2): 模型权重按层切分到两张 GPU
- 多节点 TP : 使用
--nnodes 2模式,通过 NCCL over TCP/IP 通信 - 单点 API: 只有 Head 节点 (spark-1) 提供 HTTP API
2. 硬件与网络准备
2.1 确认网络连通性
bash
# 在 spark-1 上 ping spark-2
ping -c 3 169.254.191.100
# 在 spark-2 上 ping spark-1
ping -c 3 169.254.131.196
# 确认网络接口名称 (用于 NCCL 绑定)
ip addr show | grep "enp.*np"
# 记下接口名,如 enp1s0f1np12.2 确认 GPU 状态
bash
python3 -c "
import subprocess
result = subprocess.run(['nvidia-smi'], capture_output=True, text=True)
print(result.stdout[:500] if result.stdout else 'nvidia-smi failed')
"
# 或者直接:
nvidia-smi2.3 确认模型文件
模型需要提前下载到两台机器的相同路径:
bash
# 确认模型文件存在
ls -la /home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4/
# 应有 26 个 safetensors 分片文件,总计约 120GB如果只有一台机器有模型,可以用 rsync 同步:
bash
rsync -avP /home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4/ \
spark-2:/home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4/3. 已知问题与解决方案总览
在 DGX Spark 上编译和运行 SGLang 会遇到以下问题。本教程按顺序解决所有问题。
| # | 问题 | 原因 | 解决方案 |
|---|---|---|---|
| 1 | sgl_kernel undefined symbol |
预编译 wheel 针对 nightly PyTorch ABI | 使用 torch==2.9.1 (stable) + 源码编译 |
| 2 | FlashMLA kerutils static assertion |
SM121 未被 kerutils 识别 | 编译时 patch static_assert,或禁用 FlashMLA |
| 3 | PyTorch 版本反复切换 | SGLang 依赖拉回 stable,用户又装 nightly | 锁定 torch==2.9.1+cu130,永不安装 nightly |
| 4 | cmake >= 4.0 Policy 问题 |
cmake 4.x 引入不兼容的 CMake Policy | 安装 cmake<4.0 |
| 5 | Triton ptxas 不认识 sm_121a | Triton 自带的 ptxas 版本太旧 | 用系统 CUDA 13.0 的 ptxas 替换 |
| 6 | CUDA error: invalid device ordinal |
单机模式下找不到第二张 GPU | 使用 --nnodes 2 多节点模式 |
| 7 | port number missing |
--dist-init-addr 缺少端口号 |
加上端口如 :25001 |
| 8 | .multicast::cluster ptxas 警告 |
SM121 不完全支持某些集群指令 | 仅为警告,不影响运行 |
| 9 | DeepGemm scale_fmt 警告 | NVFP4 checkpoint 格式差异 | 仅为警告,不影响运行 |
Step 1: 环境清理
⚠️ 重要 : 在 两台机器 上都执行此步骤
bash
conda activate sglang-spark # 或你的环境名
# 彻底卸载所有残留包
pip uninstall -y sgl-kernel sglang flashinfer_python flashinfer_cubin \
torch torchvision torchaudio
# 停止所有相关进程
pkill -9 python
ray stop -f 2>/dev/null
# 清理系统缓存
sync; sudo bash -c 'echo 3 > /proc/sys/vm/drop_caches'
# 清理旧的源码和编译产物
rm -rf /home/nvidia/workspaces/sglang
rm -rf /home/nvidia/workspaces/sgl_kernel*.whl
# 清理 pip 缓存 (可选)
pip cache purgeStep 2: 安装 PyTorch 2.9.1+cu130
⚠️ 关键决策 : 必须使用 torch==2.9.1+cu130 (stable) 。
绝对不要安装 nightly (2.12.0.dev),否则会导致 sgl_kernel ABI 不兼容。
bash
cd /home/nvidia/workspaces # 确保在一个存在的目录
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 \
--index-url https://download.pytorch.org/whl/cu130 \
--force-reinstall
# 验证 (必须通过)
python -c "import torch; print('torch:', torch.__version__, 'CUDA:', torch.cuda.is_available())"
# 期望输出: torch: 2.9.1+cu130 CUDA: True注意 :
moviepy requires pillow<12.0的警告可以忽略,不影响推理。
注意 :Found GPU0 NVIDIA GB10 which is of cuda capability 12.1警告是已知的,PyTorch 2.9.1 尚未正式声明支持 SM121,但实际可以运行。
Step 3: 安装编译依赖
bash
# cmake 必须 < 4.0,否则会有 CMake Policy 兼容问题
pip install "cmake<4.0" ninja scikit-build-core build wheel
# 确认版本
cmake --version # 应显示 3.31.xStep 4: 克隆 SGLang 源码
bash
cd /home/nvidia/workspaces
git clone https://github.com/sgl-project/sglang.git --recursive
cd sglang/sgl-kernelStep 5: 编译 sgl-kernel
这是最关键也最耗时的步骤 (45-90 分钟)。
5.1 设置编译环境变量
bash
export TORCH_CUDA_ARCH_LIST="12.1a" # 'a' 后缀表示 architecture-accelerated
export MAX_JOBS=4 # 限制并行数,防 OOM (128GB 内存)
export CMAKE_BUILD_PARALLEL_LEVEL=1 # CMake 层面也限制并行
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:${LD_LIBRARY_PATH:-}5.2 降低 nvcc 线程数 (防 OOM)
bash
python3 -c "
import os, re
for root, dirs, files in os.walk('.'):
if '.git' in root: continue
for f in files:
if f.endswith(('CMakeLists.txt', '.cmake')):
p = os.path.join(root, f)
with open(p, 'r', errors='ignore') as fh: c = fh.read()
n = re.sub(r'--threads=\d+', '--threads=1', c)
if n != c:
with open(p, 'w') as fh: fh.write(n)
print(f'patched: {p}')
"5.3 开始编译
bash
python -m build --wheel --no-isolation 2>&1 | tee /tmp/sgl_kernel_build.log监控编译进度 (另一个终端):
bash
tail -f /tmp/sgl_kernel_build.log | grep -E "^\[.*\/.*\]"
# 会看到 [127/479] 这样的进度编译过程中的正常警告:
以下警告可以安全忽略:
'.multicast::cluster' modifier ... should be used on .target 'sm_90a/sm_100a'--- SM121 的集群指令性能降级警告Potential Performance Loss: 'setmaxnreg' ignored--- 寄存器分配优化降级narrowing conversion ... from 'char' to 'c10::DeviceIndex'--- 类型转换警告expression has no effect--- 未使用变量警告
5.4 如果遇到 FlashMLA 编译错误
如果编译在 step 415/479 附近失败,错误信息包含:
kerutils/device/common.h(45): error: static assertion failed with
"kerutils doesn't support SM architectures below SM80"这是 FlashMLA 的 kerutils 不识别 SM121。MiniMax-M2.5 使用 GQA 而非 MLA,不需要 FlashMLA。
解决方案: 找到并 patch 该文件:
bash
# 查找 FlashMLA 的 kerutils 文件
find /tmp -name "common.h" -path "*/kerutils/*" 2>/dev/null
# 编辑找到的文件,将 static_assert 行注释掉或改为:
# static_assert(__CUDA_ARCH__ >= 800 || __CUDA_ARCH__ == 0 || __CUDA_ARCH__ >= 1200,
# "kerutils doesn't support SM architectures below SM80");然后重新运行编译命令。
5.5 编译成功的标志
*** Created sgl_kernel-0.3.21-cp310-abi3-linux_aarch64.whl
Successfully built sgl_kernel-0.3.21-cp310-abi3-linux_aarch64.whlwheel 文件位于 dist/ 目录。
Step 6: 安装 SGLang
bash
# 安装编译好的 sgl-kernel
pip install dist/sgl_kernel-0.3.21-cp310-abi3-linux_aarch64.whl
# 安装 SGLang Python 包
cd /home/nvidia/workspaces/sglang
pip install -e "python[all]" --no-build-isolationStep 7: 修复 Triton ptxas
Triton 自带的 ptxas 版本太旧,不认识 sm_121a,会导致 CUDA graph 捕获阶段失败。
⚠️ 两台机器都需要执行
bash
# 替换 Triton 自带的旧版 ptxas
TRITON_PTXAS=/root/miniconda3/envs/sglang-spark/lib/python3.11/site-packages/triton/backends/nvidia/bin/ptxas
# 备份原文件
mv $TRITON_PTXAS ${TRITON_PTXAS}.bak
# 链接到系统 CUDA 13.0 的 ptxas
ln -s /usr/local/cuda/bin/ptxas $TRITON_PTXAS
# 验证
$TRITON_PTXAS --version
# 应显示: Cuda compilation tools, release 13.0, V13.0.88注意 : 如果你的 conda 环境路径不同,需要调整
TRITON_PTXAS变量。可以用
find / -name "ptxas" -path "*/triton/*" 2>/dev/null查找。
Step 8: 验证安装
bash
python -c "
import torch
import sgl_kernel
print('torch:', torch.__version__, 'CUDA:', torch.cuda.is_available())
print('sgl_kernel:', sgl_kernel.__version__)
import sglang
print('sglang: OK')
print('GPU:', torch.cuda.get_device_name(0))
print('Compute Capability:', torch.cuda.get_device_capability(0))
"期望输出:
torch: 2.9.1+cu130 CUDA: True
sgl_kernel: 0.3.21
sglang: OK
GPU: NVIDIA GB10
Compute Capability: (12, 1)Step 9: 配置 Worker 节点
在 spark-2 上复制编译好的 wheel,免去重新编译。
在 spark-1 上执行:
bash
# 把编译好的 wheel 传到 spark-2
scp /home/nvidia/workspaces/sglang/sgl-kernel/dist/sgl_kernel-0.3.21-cp310-abi3-linux_aarch64.whl \
spark-2:/home/nvidia/workspaces/在 spark-2 上执行:
bash
conda activate sglang-spark
# 1. 安装 PyTorch (如果 spark-2 还没装)
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 \
--index-url https://download.pytorch.org/whl/cu130 --force-reinstall
# 2. 安装编译好的 sgl-kernel (免编译!)
pip install /home/nvidia/workspaces/sgl_kernel-0.3.21-cp310-abi3-linux_aarch64.whl
# 3. 克隆并安装 SGLang
cd /home/nvidia/workspaces
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]" --no-build-isolation
# 4. 修复 Triton ptxas (同 Step 7)
TRITON_PTXAS=/root/miniconda3/envs/sglang-spark/lib/python3.11/site-packages/triton/backends/nvidia/bin/ptxas
mv $TRITON_PTXAS ${TRITON_PTXAS}.bak
ln -s /usr/local/cuda/bin/ptxas $TRITON_PTXAS
# 5. 验证
python -c "import torch; import sgl_kernel; print('OK:', torch.__version__, sgl_kernel.__version__)"Step 10: 启动多节点推理服务
10.1 关键参数说明
| 参数 | 值 | 说明 |
|---|---|---|
--tp-size 2 |
2 | 两张 GPU 做 Tensor Parallel |
--nnodes 2 |
2 | 两台物理机 |
--node-rank |
0 或 1 | 节点编号 |
--dist-init-addr |
IP:PORT |
torch.distributed 会合点 |
--quantization modelopt_fp4 |
--- | NVFP4 量化格式 |
--attention-backend flashinfer |
--- | FlashInfer 注意力后端 |
--kv-cache-dtype bf16 |
--- | KV Cache 使用 BF16 |
--disable-custom-all-reduce |
--- | 禁用自定义 AllReduce (跨节点不稳定) |
10.2 在 spark-1 上启动 (Head, node-rank=0)
先启动 spark-1,它会等待 spark-2 连接。
bash
source /root/miniconda3/bin/activate sglang-spark
export NCCL_SOCKET_IFNAME=enp1s0f1np1 # 替换为你的网络接口名
export GLOO_SOCKET_IFNAME=enp1s0f1np1
export OMP_NUM_THREADS=4
export MKL_NUM_THREADS=4
python -m sglang.launch_server \
--model-path /home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4 \
--served-model-name minimax-m2.5 \
--quantization modelopt_fp4 \
--attention-backend flashinfer \
--kv-cache-dtype bf16 \
--disable-custom-all-reduce \
--tp-size 2 \
--nnodes 2 \
--node-rank 0 \
--dist-init-addr 169.254.131.196:25001 \
--trust-remote-code \
--mem-fraction-static 0.85 \
--context-length 65536 \
--reasoning-parser minimax \
--tool-call-parser minimax-m2 \
--host 0.0.0.0 \
--port 800010.3 在 spark-2 上启动 (Worker, node-rank=1)
spark-1 启动后立即启动 spark-2。
bash
source /root/miniconda3/bin/activate sglang-spark
export NCCL_SOCKET_IFNAME=enp1s0f1np1
export GLOO_SOCKET_IFNAME=enp1s0f1np1
export OMP_NUM_THREADS=4
export MKL_NUM_THREADS=4
python -m sglang.launch_server \
--model-path /home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4 \
--served-model-name minimax-m2.5 \
--quantization modelopt_fp4 \
--attention-backend flashinfer \
--kv-cache-dtype bf16 \
--disable-custom-all-reduce \
--tp-size 2 \
--nnodes 2 \
--node-rank 1 \
--dist-init-addr 169.254.131.196:25001 \
--trust-remote-code \
--mem-fraction-static 0.85 \
--context-length 65536 \
--reasoning-parser minimax \
--tool-call-parser minimax-m2 \
--host 0.0.0.0 \
--port 800010.4 启动流程时间线
[00:00] spark-1 启动,等待 spark-2 连接
[00:10] spark-2 启动,torch.distributed 握手完成
[00:15] torch distributed 初始化完成 (~15s)
[08:00] 模型权重加载完成 (26 个 shard, ~8 分钟)
[08:05] KV Cache 分配 (~210K tokens)
[10:00] CUDA Graph 捕获完成 (~2 分钟)
[12:00] Piecewise CUDA Graph 编译+捕获 (~2 分钟)
[12:05] "The server is fired up and ready to roll!" ✅10.5 后台运行 (nohup)
bash
# spark-1
nohup bash -c 'source /root/miniconda3/bin/activate sglang-spark && \
export NCCL_SOCKET_IFNAME=enp1s0f1np1 && \
export GLOO_SOCKET_IFNAME=enp1s0f1np1 && \
python -m sglang.launch_server \
--model-path /home/nvidia/workspaces/models/MiniMax-M2.5-NVFP4 \
--served-model-name minimax-m2.5 \
--quantization modelopt_fp4 \
--attention-backend flashinfer \
--kv-cache-dtype bf16 \
--disable-custom-all-reduce \
--tp-size 2 --nnodes 2 --node-rank 0 \
--dist-init-addr 169.254.131.196:25001 \
--trust-remote-code --mem-fraction-static 0.85 \
--context-length 65536 \
--reasoning-parser minimax --tool-call-parser minimax-m2 \
--host 0.0.0.0 --port 8000' \
> /home/nvidia/workspaces/ray/sglang_m25.log 2>&1 &
# 监控日志
tail -f /home/nvidia/workspaces/ray/sglang_m25.logStep 11: 测试与监控
11.1 基础测试
bash
# 健康检查
curl http://localhost:8000/health
# 模型信息
curl http://localhost:8000/model_info
# 简单对话
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "minimax-m2.5",
"messages": [{"role": "user", "content": "你好,请介绍一下你自己"}],
"max_tokens": 256,
"temperature": 0.7
}'11.2 推理能力测试
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "minimax-m2.5",
"messages": [{"role": "user", "content": "一个水池有两个进水管和一个出水管。单独开A管8小时注满,单独开B管12小时注满,单独开排水管16小时排完。三管同时开,多久注满?"}],
"max_tokens": 1024,
"temperature": 0.7
}'11.3 流式输出测试
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "minimax-m2.5",
"messages": [{"role": "user", "content": "写一首关于春天的诗"}],
"max_tokens": 512,
"stream": true
}'11.4 Python SDK 测试
python
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
resp = client.chat.completions.create(
model="minimax-m2.5",
messages=[{"role": "user", "content": "What is the DGX Spark?"}],
max_tokens=256
)
print(resp.choices[0].message.content)11.5 监控
bash
# 查看服务状态和吞吐
curl -s http://localhost:8000/get_server_info | python3 -c "
import json,sys
d=json.load(sys.stdin)
s=d['internal_states'][0]
m=s['memory_usage']
tp=s.get('last_gen_throughput',0)
print('吞吐: %.1f tok/s' % tp)
print('显存: 权重=%.1fGB KV=%.1fGB Graph=%.1fGB' % (m['weight'],m['kvcache'],m['graph']))
print('Token容量: %d' % m['token_capacity'])
"
# 统计已处理请求数
grep -c "POST.*HTTP" /home/nvidia/workspaces/ray/sglang_m25.log
# 查看 prefill/decode 活动
grep "Prefill batch\|Decode batch" /home/nvidia/workspaces/ray/sglang_m25.log | tail -20提示 : 下次启动时加
--enable-metrics --log-requests可以启用/metrics端点。
Step 12: OpenClaw 集成配置
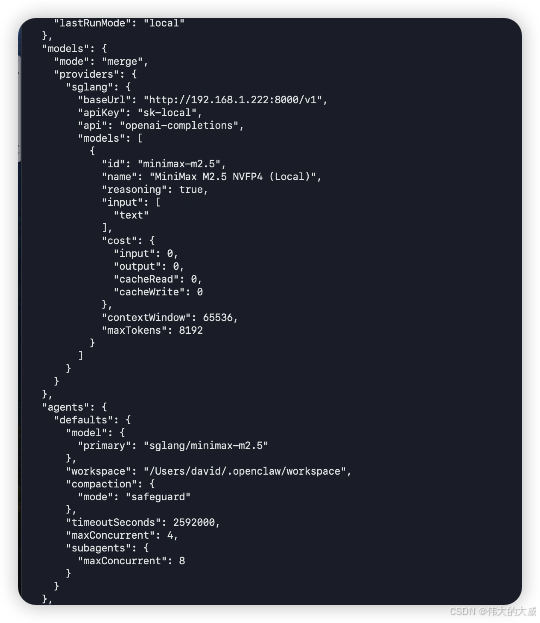
编辑 ~/.openclaw/openclaw.json,添加本地模型 provider:
json
{
"models": {
"mode": "merge",
"providers": {
"sglang": {
"baseUrl": "http://169.254.131.196:8000/v1",
"apiKey": "sk-local",
"api": "openai-completions",
"models": [
{
"id": "minimax-m2.5",
"name": "MiniMax M2.5 NVFP4 (Local DGX Spark)",
"reasoning": true,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 65536,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "sglang/minimax-m2.5"
}
}
}
}关键配置说明:
baseUrl: 指向 spark-1 的 SGLang 服务地址id: 必须与--served-model-name一致api: 使用openai-completions(SGLang 暴露 OpenAI 兼容 API)- 模型引用格式:
sglang/minimax-m2.5(provider名/model id)
故障排除手册
F1: undefined symbol: _ZN3c104cuda29c10_cuda_check_implementationE...
原因: sgl_kernel 编译时使用的 PyTorch ABI 与运行时的不一致。
解决:
bash
pip uninstall -y sgl-kernel torch
pip install torch==2.9.1 --index-url https://download.pytorch.org/whl/cu130
# 重新编译 sgl-kernelF2: The folder you are executing pip from can no longer be found
原因 : 你删除了当前工作目录 (如 rm -rf sglang 后还在 sglang 目录下)。
解决 : cd /home/nvidia/workspaces 然后重试。
F3: cmake Policy CMP0177 is not set
原因: cmake >= 4.0 引入的不兼容策略。
解决 : pip install "cmake<4.0"
F4: ptxas fatal: Value 'sm_121a' is not defined for option 'gpu-name'
原因: Triton 自带的 ptxas 版本太旧。
解决 (见 Step 7):
bash
TRITON_PTXAS=$(python -c "import triton; print(triton.__path__[0])")/backends/nvidia/bin/ptxas
mv $TRITON_PTXAS ${TRITON_PTXAS}.bak
ln -s /usr/local/cuda/bin/ptxas $TRITON_PTXASF5: CUDA error: invalid device ordinal (TP=2 单机)
原因 : 每台 DGX Spark 只有 1 张 GPU,但 --tp-size 2 尝试在本机找 2 张。
解决 : 使用多节点模式 --nnodes 2 --node-rank 0/1 --dist-init-addr IP:PORT
F6: port number missing in torch.distributed
原因 : --dist-init-addr 只写了 IP 没写端口。
解决 : --dist-init-addr 169.254.131.196:25001
F7: kerutils doesn't support SM architectures below SM80
原因: FlashMLA 的 kerutils 不识别 SM121。
解决: Patch static_assert 或在 CMakeLists.txt 中禁用 FlashMLA 相关目标。
F8: 模型加载超时
原因: 230B 模型的 26 个 shard 加载需要 8-10 分钟。
解决 : 增加超时 export RAY_CGRAPH_get_timeout=600,或在 --dist-timeout 600
F9: spark-2 上 curl localhost:8000 返回 404
原因: API 端点只在 spark-1 (Head 节点) 上。
解决 : 从 spark-2 访问时用 curl http://169.254.131.196:8000/v1/...
性能参考数据
基于实际部署测量:
| 指标 | 值 |
|---|---|
| 模型 | MiniMax-M2.5-NVFP4 (230B MoE, 10B active) |
| 量化 | NVFP4 (modelopt_fp4) |
| 权重显存占用 (每节点) | ~70 GB |
| KV Cache 容量 | ~210,000 tokens |
| KV Cache 显存 (每节点) | ~12.5 GB × 2 (K+V) |
| CUDA Graph 显存 | ~5.2 GB |
| 剩余可用显存 | ~6 GB |
| 生成吞吐 | ~25 tokens/s |
| 模型加载时间 | ~8.5 分钟 |
| CUDA Graph 捕获时间 | ~2 分钟 |
| Piecewise Graph 编译时间 | ~2 分钟 |
| 上下文长度 | 65,536 tokens |
| 最大 batch size | 256 |
| sgl-kernel 编译时间 | 45-90 分钟 |
附录: 快速部署 Checklist
在新的 DGX Spark 集群上部署时,按此顺序执行:
- 确认两台机器网络互通 (
ping) - 确认 GPU 状态 (
nvidia-smi) - 确认模型文件在两台机器的相同路径
- 两台机器: 清理环境 (Step 1)
- 两台机器: 安装 PyTorch 2.9.1+cu130 (Step 2)
- Head 节点: 安装编译依赖 (Step 3)
- Head 节点: 克隆源码 (Step 4)
- Head 节点: 编译 sgl-kernel (Step 5, 约 60 分钟)
- Head 节点: 安装 SGLang (Step 6)
- 两台机器: 修复 Triton ptxas (Step 7)
- Head 节点: 验证安装 (Step 8)
- Worker 节点: 复制 wheel + 安装 (Step 9)
- 先启动 Head, 再启动 Worker (Step 10)
- 等待 ~12 分钟,看到 "ready to roll"
- 测试 API (Step 11)
- 配置 OpenClaw (Step 12, 可选)