流程
map阶段流程
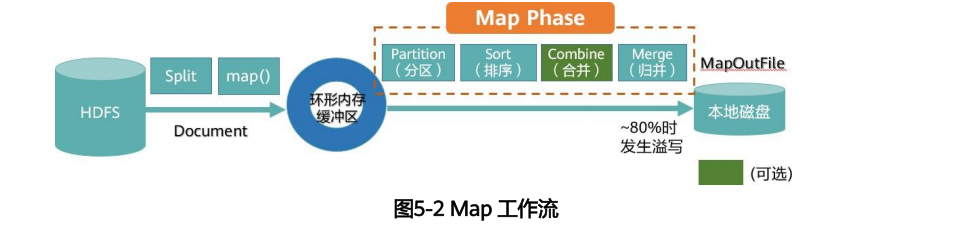
reduce阶段流程

mapreduce程序源码学习-以wordcount为例
Driver代码
c
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 获取配置信息以及获取job对象
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize","500");
Job job = Job.getInstance(conf,"wordcount");
// job.setInputFormatClass(CombineTextInputFormat.class);
// CombineTextInputFormat.setMaxInputSplitSize(job,500);
// 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
// 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入和输出路径
// FileInputFormat.setInputPaths(job, new Path());
// FileOutputFormat.setOutputPath(job,new Path());
FileInputFormat.setInputPaths(job,new Path("C:\\Users\\qichsiii\\IdeaProjects\\MapReduceDemo\\src\\main\\resources\\word\\inputflow\\log.txt"));
FileOutputFormat.setOutputPath(job,new Path("C:\\Users\\qichsiii\\IdeaProjects\\MapReduceDemo\\src\\main\\resources\\word\\outputCombiner"));
job.setCombinerClass(WordCountCombiner.class);
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}map代码:
c
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
// 获取一行
String line = value.toString();
// 切割
String[] words = line.split(" ");
// 输出
for(String word:words){
k.set(word);
context.write(k,v);
}
}
}reduce代码:
c
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable v=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
// 累加求和
sum = 0;
for(IntWritable value:values){
sum+=value.get();
}
// 输出
v.set(sum);
context.write(key,v);
}
}combiner代码:
c
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
outV.set(sum);
context.write(key,outV);
}
}1. 首先,程序的入口为WordCountDriver中的boolean result = job.waitForCompletion(true);。断点进入该代码内部。
c
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException, ClassNotFoundException {
if (this.state == Job.JobState.DEFINE) {
this.submit();
}
if (verbose) {
this.monitorAndPrintJob();
} else {
int completionPollIntervalMillis = getCompletionPollInterval(this.cluster.getConf());
while(!this.isComplete()) {
try {
Thread.sleep((long)completionPollIntervalMillis);
} catch (InterruptedException var4) {
}
}
}
return this.isSuccessful();
}该段代码关注第二行,this.submit();
c
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
this.ensureState(Job.JobState.DEFINE);
this.setUseNewAPI();
this.connect();
final JobSubmitter submitter = this.getJobSubmitter(this.cluster.getFileSystem(), this.cluster.getClient());
this.status = (JobStatus)this.ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
return submitter.submitJobInternal(Job.this, Job.this.cluster);
}
});
this.state = Job.JobState.RUNNING;
LOG.info("The url to track the job: " + this.getTrackingURL());
}2. 进入submit方法,关注两行代码,final JobSubmitter submitter = this.getJobSubmitter(this.cluster.getFileSystem(), this.cluster.getClient());
和submitter.submitJobInternal(Job.this, Job.this.cluster);
第一行代码获取集群信息,用于提交作业。
第二行代码用于提交作业。
3. 进入submitJobInternal方法。
c
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {
this.checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
this.submitHostAddress = ip.getHostAddress();
this.submitHostName = ip.getHostName();
conf.set("mapreduce.job.submithostname", this.submitHostName);
conf.set("mapreduce.job.submithostaddress", this.submitHostAddress);
}
JobID jobId = this.submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
JobStatus var25;
try {
conf.set("mapreduce.job.user.name", UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set("mapreduce.job.dir", submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir");
TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[]{submitJobDir}, conf);
this.populateTokenCache(conf, job.getCredentials());
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance("HmacSHA1");
keyGen.init(64);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt("mapreduce.am.max-attempts", 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediatedata spill is enabled");
}
this.copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
LOG.debug("Creating splits at " + this.jtFs.makeQualified(submitJobDir));
int maps = this.writeSplits(job, submitJobDir);
conf.setInt("mapreduce.job.maps", maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt("mapreduce.job.max.map", -1);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps + " exceeded limit " + maxMaps);
}
String queue = conf.get("mapreduce.job.queuename", "default");
AccessControlList acl = this.submitClient.getQueueAdmins(queue);
conf.set(QueueManager.toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean("mapreduce.job.token.tracking.ids.enabled", false)) {
ArrayList<String> trackingIds = new ArrayList();
for(Token<? extends TokenIdentifier> t : job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings("mapreduce.job.token.tracking.ids", (String[])trackingIds.toArray(new String[trackingIds.size()]));
}
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set("mapreduce.job.reservation.id", reservationId.toString());
}
this.writeConf(conf, submitJobFile);
this.printTokens(jobId, job.getCredentials());
status = this.submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
if (status == null) {
throw new IOException("Could not launch job");
}
var25 = status;
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (this.jtFs != null && submitJobDir != null) {
this.jtFs.delete(submitJobDir, true);
}
}
}
return var25;
}关注代码int maps = this.writeSplits(job, submitJobDir);
该行代码获取的map的数量,即分片的数量。该数量根据Driver程序中我们的配置conf.set("mapreduce.input.fileinputformat.split.maxsize","500");和文件的长度计算得到。
4. 进入LocalJobRunner的run()方法。
c
public void run() {
JobID jobId = profile.getJobID();
JobContext jContext = new JobContextImpl(job, jobId);
org.apache.hadoop.mapreduce.OutputCommitter outputCommitter = null;
try {
outputCommitter = createOutputCommitter(conf.getUseNewMapper(), jobId, conf);
} catch (Exception e) {
LOG.info("Failed to createOutputCommitter", e);
return;
}
try {
TaskSplitMetaInfo[] taskSplitMetaInfos =
SplitMetaInfoReader.readSplitMetaInfo(jobId, localFs, conf, systemJobDir);
int numReduceTasks = job.getNumReduceTasks();
outputCommitter.setupJob(jContext);
status.setSetupProgress(1.0f);
Map<TaskAttemptID, MapOutputFile> mapOutputFiles =
Collections.synchronizedMap(new HashMap<TaskAttemptID, MapOutputFile>());
List<RunnableWithThrowable> mapRunnables = getMapTaskRunnables(
taskSplitMetaInfos, jobId, mapOutputFiles);
initCounters(mapRunnables.size(), numReduceTasks);
ExecutorService mapService = createMapExecutor();
runTasks(mapRunnables, mapService, "map");
try {
if (numReduceTasks > 0) {
List<RunnableWithThrowable> reduceRunnables = getReduceTaskRunnables(
jobId, mapOutputFiles);
ExecutorService reduceService = createReduceExecutor();
runTasks(reduceRunnables, reduceService, "reduce");
}
} finally {
for (MapOutputFile output : mapOutputFiles.values()) {
output.removeAll();
}
}
// delete the temporary directory in output directory
outputCommitter.commitJob(jContext);
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.SUCCEEDED);
}
JobEndNotifier.localRunnerNotification(job, status);
} catch (Throwable t) {
try {
outputCommitter.abortJob(jContext,
org.apache.hadoop.mapreduce.JobStatus.State.FAILED);
} catch (IOException ioe) {
LOG.info("Error cleaning up job:" + id);
}
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.FAILED);
}
LOG.warn(id.toString(), t);
JobEndNotifier.localRunnerNotification(job, status);
} finally {
try {
try {
// Cleanup distributed cache
localDistributedCacheManager.close();
} finally {
try {
fs.delete(systemJobFile.getParent(), true); // delete submit dir
} finally {
localFs.delete(localJobFile, true); // delete local copy
}
}
} catch (IOException e) {
LOG.warn("Error cleaning up "+id+": "+e);
}
}
}关注List mapRunnables = getMapTaskRunnables(
taskSplitMetaInfos, jobId, mapOutputFiles);
这行代码根据上面获取map数量过程中划分的分片信息生成task。
然后是runTasks(mapRunnables, mapService, "map");异步执行任务。
5. 执行map方法。进入到MapTask的runNewMapper方法。
c
private <INKEY, INVALUE, OUTKEY, OUTVALUE> void runNewMapper(JobConf job, JobSplit.TaskSplitIndex splitIndex, TaskUmbilicalProtocol umbilical, Task.TaskReporter reporter) throws IOException, ClassNotFoundException, InterruptedException {
TaskAttemptContext taskContext = new TaskAttemptContextImpl(job, this.getTaskID(), reporter);
Mapper<INKEY, INVALUE, OUTKEY, OUTVALUE> mapper = (Mapper)ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
InputFormat<INKEY, INVALUE> inputFormat = (InputFormat)ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
org.apache.hadoop.mapreduce.InputSplit split = null;
split = (org.apache.hadoop.mapreduce.InputSplit)this.getSplitDetails(new Path(splitIndex.getSplitLocation()), splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY, INVALUE> input = new NewTrackingRecordReader<INKEY, INVALUE>(split, inputFormat, reporter, taskContext);
job.setBoolean("mapreduce.job.skiprecords", this.isSkipping());
RecordWriter output = null;
if (job.getNumReduceTasks() == 0) {
output = new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE> mapContext = new MapContextImpl(job, this.getTaskID(), input, output, this.committer, reporter, split);
Mapper<INKEY, INVALUE, OUTKEY, OUTVALUE>.Context mapperContext = (new WrappedMapper()).getMapContext(mapContext);
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
this.mapPhase.complete();
this.setPhase(Phase.SORT);
this.statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
this.closeQuietly(input);
this.closeQuietly(output, mapperContext);
}
}然后执行mapper.run(mapperContext);run方法会执行我们之前配置的Mapper类中的map方法。
mapper是根据我们在Driver中的配置,通过反射获取的。 Mapper<INKEY, INVALUE, OUTKEY, OUTVALUE> mapper = (Mapper)ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
然后进入到map方法,这里有多少行数据,就调用多少次。
c
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
// 获取一行
String line = value.toString();
// 切割
String[] words = line.split(" ");
// 输出
for(String word:words){
k.set(word);
context.write(k,v);
}
}write方法将数据写入缓冲区中。
c
public void write(K key, V value) throws IOException, InterruptedException {
this.collector.collect(key, value, this.partitioner.getPartition(key, value, this.partitions));
}write前会进行分区,这里默认是哈希分区器,如果自定义了分区方法,可以在Driver中进行配置。map阶段结束。
6. map阶段结束后,执行output.close(mapperContext);
该方法会将数据刷写到磁盘中。进入flush方法。
c
public void flush() throws IOException, ClassNotFoundException, InterruptedException {
MapTask.LOG.info("Starting flush of map output");
if (this.kvbuffer == null) {
MapTask.LOG.info("kvbuffer is null. Skipping flush.");
} else {
this.spillLock.lock();
try {
while(this.spillInProgress) {
this.reporter.progress();
this.spillDone.await();
}
this.checkSpillException();
int kvbend = 4 * this.kvend;
if ((kvbend + 16) % this.kvbuffer.length != this.equator - this.equator % 16) {
this.resetSpill();
}
if (this.kvindex != this.kvend) {
this.kvend = (this.kvindex + 4) % this.kvmeta.capacity();
this.bufend = this.bufmark;
MapTask.LOG.info("Spilling map output");
MapTask.LOG.info("bufstart = " + this.bufstart + "; bufend = " + this.bufmark + "; bufvoid = " + this.bufvoid);
MapTask.LOG.info("kvstart = " + this.kvstart + "(" + this.kvstart * 4 + "); kvend = " + this.kvend + "(" + this.kvend * 4 + "); length = " + (this.distanceTo(this.kvend, this.kvstart, this.kvmeta.capacity()) + 1) + "/" + this.maxRec);
this.sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
this.spillLock.unlock();
}
assert !this.spillLock.isHeldByCurrentThread();
try {
this.spillThread.interrupt();
this.spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
this.kvbuffer = null;
this.mergeParts();
Path outputPath = this.mapOutputFile.getOutputFile();
this.fileOutputByteCounter.increment(this.rfs.getFileStatus(outputPath).getLen());
if (!MapTask.SHUFFLE_OUTPUT_PERM.equals(MapTask.SHUFFLE_OUTPUT_PERM.applyUMask(FsPermission.getUMask(this.job)))) {
Path indexPath = this.mapOutputFile.getOutputIndexFile();
this.rfs.setPermission(outputPath, MapTask.SHUFFLE_OUTPUT_PERM);
this.rfs.setPermission(indexPath, MapTask.SHUFFLE_OUTPUT_PERM);
}
}
}关注this.sortAndSpill();
7. 排序和归并
进入sortAndSpill方法
c
private void sortAndSpill() throws IOException, ClassNotFoundException, InterruptedException {
long size = (long)(this.distanceTo(this.bufstart, this.bufend, this.bufvoid) + this.partitions * 150);
FSDataOutputStream out = null;
FSDataOutputStream partitionOut = null;
try {
SpillRecord spillRec = new SpillRecord(this.partitions);
Path filename = this.mapOutputFile.getSpillFileForWrite(this.numSpills, size);
out = this.rfs.create(filename);
int mstart = this.kvend / 4;
int mend = 1 + (this.kvstart >= this.kvend ? this.kvstart : this.kvmeta.capacity() + this.kvstart) / 4;
this.sorter.sort(this, mstart, mend, this.reporter);
int spindex = mstart;
IndexRecord rec = new IndexRecord();
MapOutputBuffer<K, V>.InMemValBytes value = new InMemValBytes();
for(int i = 0; i < this.partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
partitionOut = CryptoUtils.wrapIfNecessary(this.job, out, false);
writer = new IFile.Writer(this.job, partitionOut, this.keyClass, this.valClass, this.codec, this.spilledRecordsCounter);
if (this.combinerRunner == null) {
for(DataInputBuffer key = new DataInputBuffer(); spindex < mend && this.kvmeta.get(this.offsetFor(spindex % this.maxRec) + 2) == i; ++spindex) {
int kvoff = this.offsetFor(spindex % this.maxRec);
int keystart = this.kvmeta.get(kvoff + 1);
int valstart = this.kvmeta.get(kvoff + 0);
key.reset(this.kvbuffer, keystart, valstart - keystart);
this.getVBytesForOffset(kvoff, value);
writer.append(key, value);
}
} else {
int spstart;
for(spstart = spindex; spindex < mend && this.kvmeta.get(this.offsetFor(spindex % this.maxRec) + 2) == i; ++spindex) {
}
if (spstart != spindex) {
this.combineCollector.setWriter(writer);
RawKeyValueIterator kvIter = new MRResultIterator(spstart, spindex);
this.combinerRunner.combine(kvIter, this.combineCollector);
}
}
writer.close();
if (partitionOut != out) {
partitionOut.close();
partitionOut = null;
}
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + (long)CryptoUtils.cryptoPadding(this.job);
rec.partLength = writer.getCompressedLength() + (long)CryptoUtils.cryptoPadding(this.job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) {
writer.close();
}
}
}
if (this.totalIndexCacheMemory >= this.indexCacheMemoryLimit) {
Path indexFilename = this.mapOutputFile.getSpillIndexFileForWrite(this.numSpills, (long)(this.partitions * 24));
spillRec.writeToFile(indexFilename, this.job);
} else {
this.indexCacheList.add(spillRec);
this.totalIndexCacheMemory += spillRec.size() * 24;
}
MapTask.LOG.info("Finished spill " + this.numSpills);
++this.numSpills;
} finally {
if (out != null) {
out.close();
}
if (partitionOut != null) {
partitionOut.close();
}
}
}这里面关注两点
this.sorter.sort(this, mstart, mend, this.reporter);和
this.combinerRunner.combine(kvIter, this.combineCollector);
第一个排序默认快排。
第二个合并根据在Driver中的配置进行选取。
8. reduce阶段
上面关注了LocalJobRunner中的对map方法的调用,下面关注对reduce方法的调用。
c
public void run() {
JobID jobId = profile.getJobID();
JobContext jContext = new JobContextImpl(job, jobId);
org.apache.hadoop.mapreduce.OutputCommitter outputCommitter = null;
try {
outputCommitter = createOutputCommitter(conf.getUseNewMapper(), jobId, conf);
} catch (Exception e) {
LOG.info("Failed to createOutputCommitter", e);
return;
}
try {
TaskSplitMetaInfo[] taskSplitMetaInfos =
SplitMetaInfoReader.readSplitMetaInfo(jobId, localFs, conf, systemJobDir);
int numReduceTasks = job.getNumReduceTasks();
outputCommitter.setupJob(jContext);
status.setSetupProgress(1.0f);
Map<TaskAttemptID, MapOutputFile> mapOutputFiles =
Collections.synchronizedMap(new HashMap<TaskAttemptID, MapOutputFile>());
List<RunnableWithThrowable> mapRunnables = getMapTaskRunnables(
taskSplitMetaInfos, jobId, mapOutputFiles);
initCounters(mapRunnables.size(), numReduceTasks);
ExecutorService mapService = createMapExecutor();
runTasks(mapRunnables, mapService, "map");
try {
if (numReduceTasks > 0) {
List<RunnableWithThrowable> reduceRunnables = getReduceTaskRunnables(
jobId, mapOutputFiles);
ExecutorService reduceService = createReduceExecutor();
runTasks(reduceRunnables, reduceService, "reduce");
}
} finally {
for (MapOutputFile output : mapOutputFiles.values()) {
output.removeAll();
}
}
// delete the temporary directory in output directory
outputCommitter.commitJob(jContext);
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.SUCCEEDED);
}
JobEndNotifier.localRunnerNotification(job, status);
} catch (Throwable t) {
try {
outputCommitter.abortJob(jContext,
org.apache.hadoop.mapreduce.JobStatus.State.FAILED);
} catch (IOException ioe) {
LOG.info("Error cleaning up job:" + id);
}
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.FAILED);
}
LOG.warn(id.toString(), t);
JobEndNotifier.localRunnerNotification(job, status);
} finally {
try {
try {
// Cleanup distributed cache
localDistributedCacheManager.close();
} finally {
try {
fs.delete(systemJobFile.getParent(), true); // delete submit dir
} finally {
localFs.delete(localJobFile, true); // delete local copy
}
}
} catch (IOException e) {
LOG.warn("Error cleaning up "+id+": "+e);
}
}
}关注代码:runTasks(reduceRunnables, reduceService, "reduce");
同样是异步提交。
c
public void run(JobConf job, TaskUmbilicalProtocol umbilical) throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean("mapreduce.job.skiprecords", this.isSkipping());
if (this.isMapOrReduce()) {
this.copyPhase = this.getProgress().addPhase("copy");
this.sortPhase = this.getProgress().addPhase("sort");
this.reducePhase = this.getProgress().addPhase("reduce");
}
Task.TaskReporter reporter = this.startReporter(umbilical);
boolean useNewApi = job.getUseNewReducer();
this.initialize(job, this.getJobID(), reporter, useNewApi);
if (this.jobCleanup) {
this.runJobCleanupTask(umbilical, reporter);
} else if (this.jobSetup) {
this.runJobSetupTask(umbilical, reporter);
} else if (this.taskCleanup) {
this.runTaskCleanupTask(umbilical, reporter);
} else {
this.codec = this.initCodec();
RawKeyValueIterator rIter = null;
ShuffleConsumerPlugin shuffleConsumerPlugin = null;
Class combinerClass = this.conf.getCombinerClass();
Task.CombineOutputCollector combineCollector = null != combinerClass ? new Task.CombineOutputCollector(this.reduceCombineOutputCounter, reporter, this.conf) : null;
Class<? extends ShuffleConsumerPlugin> clazz = job.getClass("mapreduce.job.reduce.shuffle.consumer.plugin.class", Shuffle.class, ShuffleConsumerPlugin.class);
shuffleConsumerPlugin = (ShuffleConsumerPlugin)ReflectionUtils.newInstance(clazz, job);
LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin);
ShuffleConsumerPlugin.Context shuffleContext = new ShuffleConsumerPlugin.Context(this.getTaskID(), job, FileSystem.getLocal(job), umbilical, super.lDirAlloc, reporter, this.codec, combinerClass, combineCollector, this.spilledRecordsCounter, this.reduceCombineInputCounter, this.shuffledMapsCounter, this.reduceShuffleBytes, this.failedShuffleCounter, this.mergedMapOutputsCounter, this.taskStatus, this.copyPhase, this.sortPhase, this, this.mapOutputFile, this.localMapFiles);
shuffleConsumerPlugin.init(shuffleContext);
rIter = shuffleConsumerPlugin.run();
this.mapOutputFilesOnDisk.clear();
this.sortPhase.complete();
this.setPhase(Phase.REDUCE);
this.statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
this.runNewReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass);
} else {
this.runOldReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass);
}
shuffleConsumerPlugin.close();
this.done(umbilical, reporter);
}
}关注rIter = shuffleConsumerPlugin.run();该方法会调用如下方法:
java
public RawKeyValueIterator run() throws IOException, InterruptedException {
int eventsPerReducer = Math.max(100, 3000000 / this.jobConf.getNumReduceTasks());
int maxEventsToFetch = Math.min(10000, eventsPerReducer);
EventFetcher<K, V> eventFetcher = new EventFetcher(this.reduceId, this.umbilical, this.scheduler, this, maxEventsToFetch);
eventFetcher.start();
boolean isLocal = this.localMapFiles != null;
int numFetchers = isLocal ? 1 : this.jobConf.getInt("mapreduce.reduce.shuffle.parallelcopies", 5);
Fetcher<K, V>[] fetchers = new Fetcher[numFetchers];
if (isLocal) {
fetchers[0] = new LocalFetcher(this.jobConf, this.reduceId, this.scheduler, this.merger, this.reporter, this.metrics, this, this.reduceTask.getShuffleSecret(), this.localMapFiles);
fetchers[0].start();
} else {
for(int i = 0; i < numFetchers; ++i) {
fetchers[i] = new Fetcher(this.jobConf, this.reduceId, this.scheduler, this.merger, this.reporter, this.metrics, this, this.reduceTask.getShuffleSecret());
fetchers[i].start();
}
}
while(!this.scheduler.waitUntilDone(2000)) {
this.reporter.progress();
synchronized(this) {
if (this.throwable != null) {
throw new ShuffleError("error in shuffle in " + this.throwingThreadName, this.throwable);
}
}
}
eventFetcher.shutDown();
for(Fetcher<K, V> fetcher : fetchers) {
fetcher.shutDown();
}
this.scheduler.close();
this.copyPhase.complete();
this.taskStatus.setPhase(Phase.SORT);
this.reduceTask.statusUpdate(this.umbilical);
RawKeyValueIterator kvIter = null;
try {
kvIter = this.merger.close();
} catch (Throwable e) {
throw new ShuffleError("Error while doing final merge ", e);
}
synchronized(this) {
if (this.throwable != null) {
throw new ShuffleError("error in shuffle in " + this.throwingThreadName, this.throwable);
} else {
return kvIter;
}
}
}上面是run方法具体执行的方法,int numFetchers = isLocal ? 1 : this.jobConf.getInt("mapreduce.reduce.shuffle.parallelcopies", 5);根据是否是本地执行确定拉取数据的线程数。本地执行,只有一个线程拉取;非本地执行,默认有5个线程执行拉取操作。
java
if (isLocal) {
fetchers[0] = new LocalFetcher(this.jobConf, this.reduceId, this.scheduler, this.merger, this.reporter, this.metrics, this, this.reduceTask.getShuffleSecret(), this.localMapFiles);
fetchers[0].start();
} else {
for(int i = 0; i < numFetchers; ++i) {
fetchers[i] = new Fetcher(this.jobConf, this.reduceId, this.scheduler, this.merger, this.reporter, this.metrics, this, this.reduceTask.getShuffleSecret());
fetchers[i].start();
}
}上述代码根据具体是否是本地执行创建具体的fetcher线程执行数据拉取操作。
执行完shuffleConsumerPlugin.run();方法后执行reduce逻辑。
java
if (useNewApi) {
this.runNewReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass);
} else {
this.runOldReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass);
}
java
public void run(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKey()) {
this.reduce(context.getCurrentKey(), context.getValues(), context);
Iterator<VALUEIN> iter = context.getValues().iterator();
if (iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator)iter).resetBackupStore();
}
}
} finally {
this.cleanup(context);
}
}可以看到有几个key,就调用几次reduce函数。
java
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable v=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
// 累加求和
sum = 0;
for(IntWritable value:values){
sum+=value.get();
}
// 输出
v.set(sum);
context.write(key,v);
}
}