文章目录
- [1. 软件测试 (Software Testing)的简介](#1. 软件测试 (Software Testing)的简介)
-
- [1.1 为什么要做软件测试?](#1.1 为什么要做软件测试?)
- [1.2 软件测试流程(Testing Activities)](#1.2 软件测试流程(Testing Activities))
- [1.3 测试停止准则(Test Stopping Criteria)](#1.3 测试停止准则(Test Stopping Criteria))
- [2. Black Box / Functional Testing(黑盒测试 / 功能测试)](#2. Black Box / Functional Testing(黑盒测试 / 功能测试))
-
- [2.1 黑盒测试的定义](#2.1 黑盒测试的定义)
- [2.2 测试方法](#2.2 测试方法)
-
- [2.2.1 Boundary Value Testing(BVT, 边界值测试)](#2.2.1 Boundary Value Testing(BVT, 边界值测试))
-
- [2.2.1.1 程序 P 的有效输入范围](#2.2.1.1 程序 P 的有效输入范围)
- [2.2.1.2 Boundary Value Testing(BVT,边界值测试)的分类](#2.2.1.2 Boundary Value Testing(BVT,边界值测试)的分类)
-
- [2.2.1.2.1 Normal Boundary Value Testing(普通边界值测试)](#2.2.1.2.1 Normal Boundary Value Testing(普通边界值测试))
- [2.2.1.2.2 Generalizing Boundary Value Analysis(边界值分析的推广)](#2.2.1.2.2 Generalizing Boundary Value Analysis(边界值分析的推广))
- [2.2.1.2.3 边界值分析的局限性](#2.2.1.2.3 边界值分析的局限性)
- [2.2.1.2.4 Robust Boundary Value Testing(健壮边界值测试)](#2.2.1.2.4 Robust Boundary Value Testing(健壮边界值测试))
- [2.2.1.2.5 Worst-case Boundary Value Testing(最坏情况边界值测试)](#2.2.1.2.5 Worst-case Boundary Value Testing(最坏情况边界值测试))
- [2.2.1.2.6 Robust Worst-case Boundary Value Testing(健壮最坏情况边界值测试)](#2.2.1.2.6 Robust Worst-case Boundary Value Testing(健壮最坏情况边界值测试))
- [2.2.1.3 示例 1](#2.2.1.3 示例 1)
- [2.2.1.4 示例 2](#2.2.1.4 示例 2)
- [2.2.2 Equivalence Class Testing(等价类测试)](#2.2.2 Equivalence Class Testing(等价类测试))
-
- [2.2.2.1 Input Equivalence Class(输入等价类)](#2.2.2.1 Input Equivalence Class(输入等价类))
-
- [2.2.2.1.1 两个输入变量的函数,如何做等价类测试](#2.2.2.1.1 两个输入变量的函数,如何做等价类测试)
- [2.2.2.1.2 两个变量函数的等价类测试:健壮性测试版本(Robustness Testing)](#2.2.2.1.2 两个变量函数的等价类测试:健壮性测试版本(Robustness Testing))
- [2.2.2.1.3 Weak Normal Equivalence Class Testing(弱普通等价类测试)](#2.2.2.1.3 Weak Normal Equivalence Class Testing(弱普通等价类测试))
- [2.2.2.1.4 Strong Normal Equivalence Class Testing(强普通等价类测试)](#2.2.2.1.4 Strong Normal Equivalence Class Testing(强普通等价类测试))
- [2.2.2.1.5 Weak Robust Equivalence Class Testing(弱健壮等价类测试)](#2.2.2.1.5 Weak Robust Equivalence Class Testing(弱健壮等价类测试))
- [2.2.2.1.6 Strong Robust Equivalence Class Testing(强健壮等价类测试)](#2.2.2.1.6 Strong Robust Equivalence Class Testing(强健壮等价类测试))
- [2.2.2.1.7 示例 1](#2.2.2.1.7 示例 1)
- [2.2.2.2 Output Equivalence Class(输出等价类)](#2.2.2.2 Output Equivalence Class(输出等价类))
-
- [2.2.2.2.1 示例 2](#2.2.2.2.1 示例 2)
- [2.2.2.3 Effective coverage of test cases(如何让测试用例覆盖更有效)](#2.2.2.3 Effective coverage of test cases(如何让测试用例覆盖更有效))
- [2.2.2.4 Scenario for Equivalence Class Testing(适合使用等价类测试的场景)](#2.2.2.4 Scenario for Equivalence Class Testing(适合使用等价类测试的场景))
- [2.2.3 Decision Table(决策表)](#2.2.3 Decision Table(决策表))
-
- [2.2.3.1 决策表结构](#2.2.3.1 决策表结构)
- [2.2.3.2 示例 1](#2.2.3.2 示例 1)
- [2.2.3.3 示例 2](#2.2.3.3 示例 2)
- [2.2.3.4 Decision Table Development Methodology(决策表开发方法)](#2.2.3.4 Decision Table Development Methodology(决策表开发方法))
- [2.2.3.5 决策表的使用条件](#2.2.3.5 决策表的使用条件)
- [2.2.3.6 使用决策表时要注意的问题](#2.2.3.6 使用决策表时要注意的问题)
- [2.2.3.7 示例3](#2.2.3.7 示例3)
- [2.2.3.8 决策表的适合情况](#2.2.3.8 决策表的适合情况)
1. 软件测试 (Software Testing)的简介
软件测试是一个"评估和验证"的过程,用来确认一个软件应用或系统是否:
- 满足它的需求(requirements);
- 功能是否按预期运行(functions)。
比如一个购物网站要求:
用户能登录、能搜索商品、能加入购物车、能付款。
那么测试人员就要检查这些功能是否真的能正常完成。
测试永远不能完全证明一个软件是百分之百正确的。测试只能发现缺陷,不能证明软件没有任何缺陷。
换句话说:
我们测试了 100 个情况都没问题,只能说明这 100 个情况没发现问题;但不代表第 101 个情况也一定没问题。
1.1 为什么要做软件测试?
测试的目的之一是尽可能多地发现软件里的错误、缺陷和问题。
Meyer 对软件测试的定义是:软件测试是一个在产品中寻找错误的过程。
测试永远不会完全结束。
因为软件功能很多,用户操作方式也很多,不可能把所有情况都测试完。
即使测了很多情况,也不能保证没有其他隐藏问题。
测试的第二个目的是为了保证软件质量。
检查这个产品是否符合需求。
1.2 软件测试流程(Testing Activities)
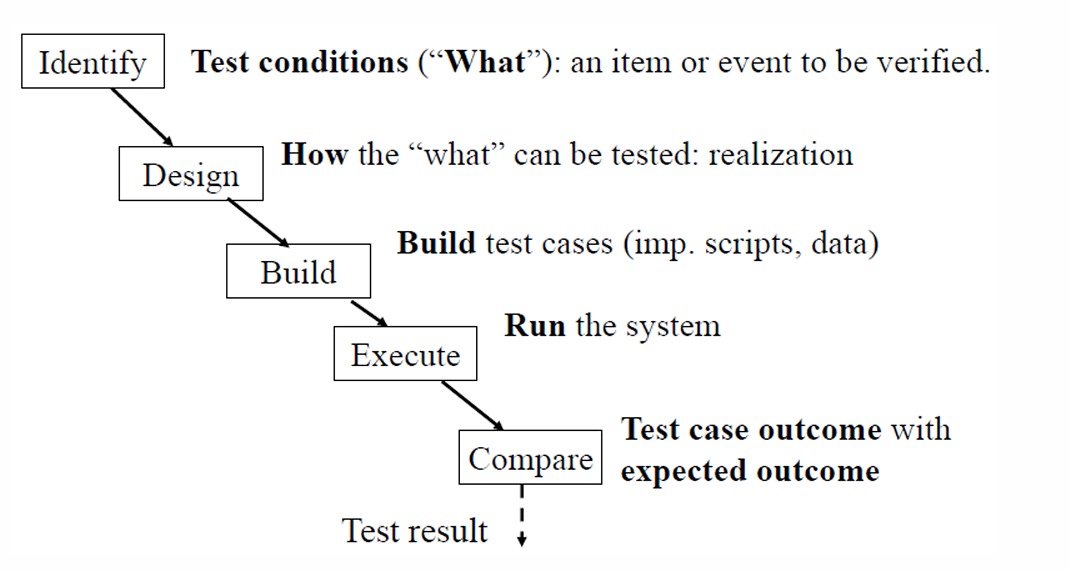
软件测试可以分成以下几个步骤:
- Identify(识别测试条件):
先确定要测试什么。找出系统中哪些功能、事件、条件需要被验证。 - Design(设计测试方法):
设计怎么测试这些内容。也就是针对上一步确定的测试条件,想清楚具体测试方式。 - Build(构建测试用例):
编写具体的测试用例(cases),包括测试脚本和测试数据。 - Execute(执行测试):
运行系统,真正开始测试。 - Compare(比较实际结果和预期结果):
把测试得到的实际结果和预期结果进行比较。 - Test result(得到测试结果)
1.3 测试停止准则(Test Stopping Criteria)
因为前面说过,测试永远不能证明软件完全没有 bug,所以实际项目中不可能无限测试下去。必须有一些停止条件。
准则如下:
- 到了截止日期,或者预算用完了(Meet deadline, exhaust budget)
如果项目已经到了规定交付时间,或者测试经费用完了,管理层可能决定停止测试。
这是一个 管理决策,不一定代表软件已经完全没问题了。 - 达到了预期的测试覆盖率(Achieved desired coverage)
也就是测试已经覆盖了足够多的功能、代码或场景。 - 故障发生频率已经降低到可接受水平(Achieved desired level of failure intensity)
比如刚开始测试时,每天能发现 20 个 bug;后来每天只发现 1 个很小的问题,甚至连续几天没有严重问题。
2. Black Box / Functional Testing(黑盒测试 / 功能测试)
黑盒测试把软件当成一个黑盒子,测试人员不关心软件内部代码是怎么写的,只看输入是什么,输出是否符合要求。
黑盒测试只使用软件规格说明书 / 需求说明书中的信息(The only information used is the specification of the software)。
比如需求文档写:
"用户密码长度必须为 8 到 16 位。"
那么测试人员就根据这个要求设计测试:
- 输入 7 位密码;
- 输入 8 位密码;
- 输入 16 位密码;
- 输入 17 位密码。
功能测试用例的两个优点:
- 功能测试和软件内部实现方式无关。即使代码改了,测试用例仍然有用(They are independent of how the software is developed, so if the implementation changes, the test cases are still useful)。
- 测试用例可以和软件开发同时进行,从而缩短项目开发时间(Test case development can occur in parallel with the implementation, thereby reducing overall project development interval)。
功能测试也有两个问题:
- 不同测试用例之间可能会重复测试相似内容(Significant redundancies may exist among test cases)。
- 可能会有一些软件功能或情况没有被测试到(Compounded by the possibility of gaps of untested software)。
2.1 黑盒测试的定义
黑盒测试是一种软件测试方法:测试人员只看软件的外部表现,不看内部代码。
- 根据软件的外部行为来评估软件(evaluated based on its external behavior)。
- 不需要了解软件内部代码、结构或实现细节(without knowledge of its internal code, structure, or implementation details)。
- 测试人员关注输入和输出(Testers focus on inputs and outputs)。
- 验证软件功能是否符合规定的需求(validating whether the software functions according to specified requirements)。
黑盒测试关注输入和输出(I/O behavior),而不是内部代码。
对于某个输入,如果我们能够知道它应该输出什么,并且实际输出和预期输出一致,那么这个模块就通过测试。
目标:通过等价类划分,减少测试用例的数量(Reduce number of test cases by equivalence partitioning)。
它的核心思想是把很多类似的输入归为一类,然后每一类选一个代表来测试。
因此步骤如下:
- 把输入条件分成不同的等价类。
- 从每个等价类里选择测试用例。
比如一个系统要求年龄必须在 18 到 60 岁之间。
那么可以分成三类:
| 输入范围 | 类型 |
|---|---|
| 小于 18 岁 | 无效输入 |
| 18 到 60 岁 | 有效输入 |
| 大于 60 岁 | 无效输入 |
测试时不需要测所有年龄,只需要每类选几个代表。
比如:15岁、30岁、70岁。这样就能减少测试数量。
2.2 测试方法
黑盒测试的常用方法如下:
-
Boundary Value Testing(BVT, 边界值测试)
核心思想:程序最容易在边界附近出错,所以重点测试边界值。
其包含:
Normal boundary value testing(普通边界值测试)
Robust boundary value testing(健壮边界值测试)
Worst-case boundary value testing(最坏情况边界值测试)
Robust worst-case boundary value testing(健壮最坏情况边界值测试)
-
Equivalence Class Testing(等价类测试)
核心思想:把输入分成几类,每一类选一个代表值来测试。
其包含:
Weak Normal Equivalence Class Testing(弱普通等价类测试)
Strong Normal Equivalence Class Testing(强普通等价类测试)
Weak Robust Equivalence Class Testing(弱健壮等价类测试)
Strong Robust Equivalence Class Testing(强健壮等价类测试)
-
Decision Table Based Testing(决策表测试)
2.2.1 Boundary Value Testing(BVT, 边界值测试)
任何程序都可以理解成:输入一些东西,然后输出一些结果。
程序的输入构成它的 domain(输入范围 / 定义域)。
程序的输出构成它的 range(输出范围 / 值域)。
边界值分析是最著名、最常用的功能测试技术之一。
功能测试的目标,是根据程序功能本身的特点来设计测试用例。
传统上,功能测试主要关注输入范围,但也可以从输出结果的角度来设计测试用例。
比如成绩评级系统:
| 输入分数 | 输出 |
|---|---|
| 90-100 | A |
| 80-89 | B |
| 70-79 | C |
| 60-69 | D |
| 0-59 | F |
测试时不能只随便选几个分数,还要保证每一种输出结果都被测到。
边界值测试主要关注输入范围的边界,用这些边界来设计测试用例。
边界值分析背后的原因是:错误往往容易出现在输入变量的极端值附近(errors tend to occur near the extreme values of an input variable)。
用弱类型语言(not strongly typed languages)写的程序,更适合做边界值测试。
Strongly typed languages (强类型语言),比如 Java、C# 等。它们对变量类型要求比较严格。
Not strongly typed languages (弱类型语言),比如 JavaScript、PHP 等。这些语言有时候会自动转换类型。
边界值测试通常会产生比较多的测试用例,但测试覆盖率可能不如 domain testing 或 equivalence testing。
因为边界值测试规则比较简单,所以测试用例很容易自动生成。
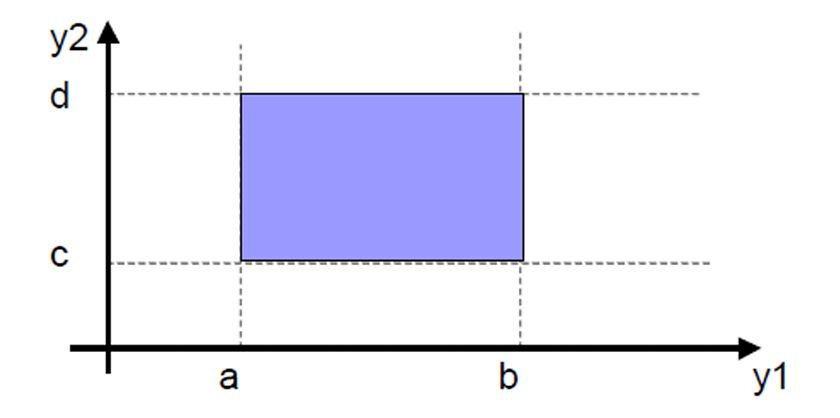
接下来讨论时,假设有一个程序 P,它接受两个输入: y 1 y_1 y1和 y 2 y_2 y2。
其中: a ≤ y 1 ≤ b a ≤ y_1 ≤ b a≤y1≤b, c ≤ y 2 ≤ d c ≤ y_2 ≤ d c≤y2≤d。
2.2.1.1 程序 P 的有效输入范围
我们刚刚提到程序 P,它接受两个输入: y 1 y_1 y1和 y 2 y_2 y2。
其中: a ≤ y 1 ≤ b a ≤ y_1 ≤ b a≤y1≤b, c ≤ y 2 ≤ d c ≤ y_2 ≤ d c≤y2≤d。
那么 n n n个输入变量的边界不等式,会定义出一个 n n n维输入空间。
2.2.1.2 Boundary Value Testing(BVT,边界值测试)的分类
边界值测试可以从两个角度来划分,最后得到 4 种类型。
测试时要不要考虑变量的非法输入值?
只测试合法值。那么就是 Normal。
既测试合法值,也测试非法值。那么就是 Robust。
是否采用单故障假设?(是否假设一次测试中只有一个变量出问题?)
如果采用 single fault assumption(单故障假设),测试时通常只让一个变量出问题。
如果不采用,那么就要考虑多个变量一起出问题,或者多个变量组合导致错误。
两个角度组合后得到 4 种边界值测试:
- Normal boundary value testing(普通边界值测试)
只测合法边界值,而且通常一次只改变一个变量。 - Robust boundary value testing(健壮边界值测试)
测合法边界值和非法边界值,但通常也是一次只让一个变量变化。 - Worst-case boundary value testing(最坏情况边界值测试)
只测合法值,但会把多个变量的边界值组合起来测试。 - Robust worst-case boundary value testing(健壮最坏情况边界值测试)
既测合法值和非法值,又把多个变量的边界值组合起来测试。
2.2.1.2.1 Normal Boundary Value Testing(普通边界值测试)
普通边界值测试选择输入变量的位置如下:
| 英文 | 含义 | 简写 |
|---|---|---|
| Minimum | 最小值 | min |
| Just above the minimum | 刚刚大于最小值 | min+ |
| A nominal value | 一个正常中间值 | nom |
| Just below the maximum | 刚刚小于最大值 | max- |
| Maximum | 最大值 | max |
nominal value(正常值 / 中间值 / 代表值):(minimum + maximum) / 2。
普通边界值测试采用"单故障假设"。
软件失败很少是由两个或多个错误同时发生造成的。
因此,它假设:一次测试中,通常只需要让一个变量处在边界值,其他变量保持正常值。
这样可以更容易判断问题到底是哪个变量导致的。
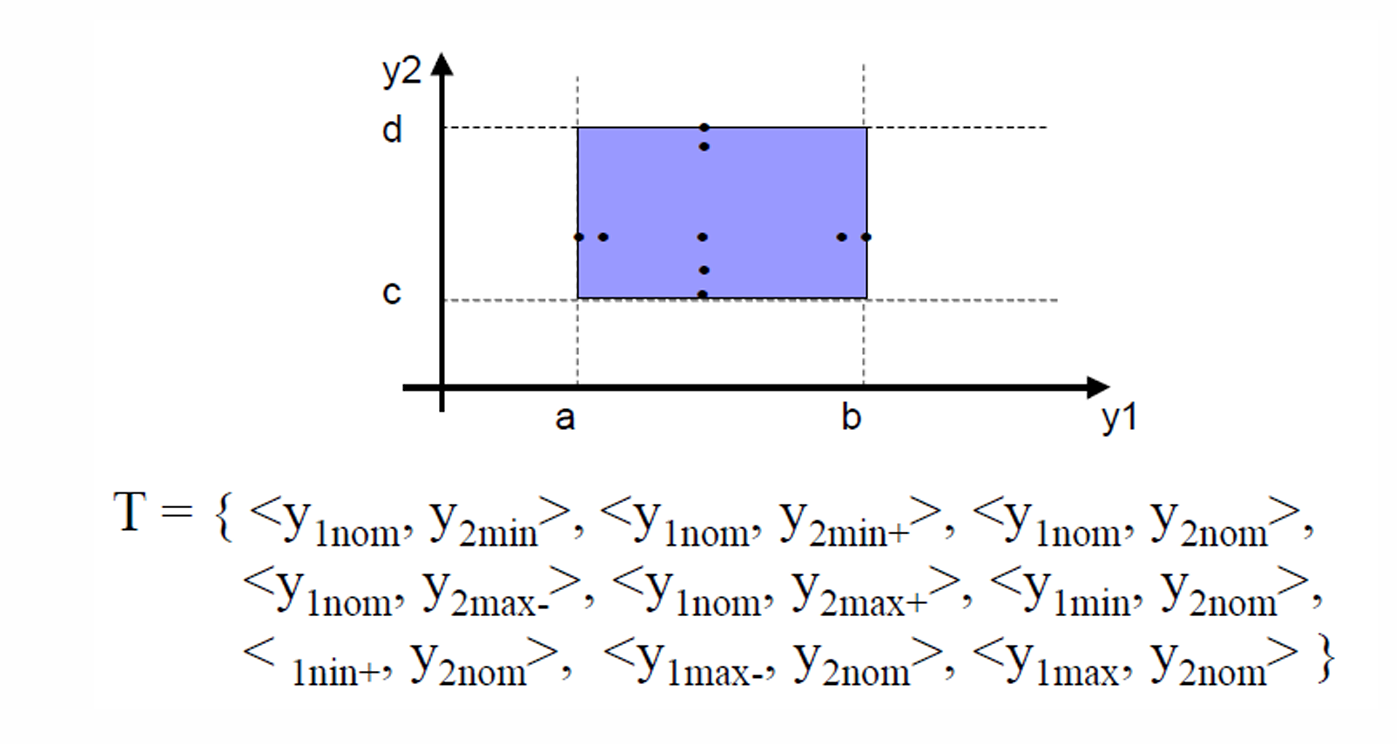
在生成普通边界值测试用例时:
每次只改变一个输入变量,让它取边界值;其他变量都保持正常中间值。
一个变量要取这 5 个值:
| 简写 | 意思 |
|---|---|
| min | 最小值 |
| min+ | 刚大于最小值 |
| nom | 正常中间值 |
| max- | 刚小于最大值 |
| max | 最大值 |
但是因为其他变量都保持 nom,所以不会把所有变量的边界值全部组合起来。
因此,如果程序有 n n n个输入变量,普通边界值测试会产生 4 n + 1 4n + 1 4n+1个不重复的测试用例。
如果不懂为什么是 4 n + 1 4n + 1 4n+1个不重复的测试用例。
我们可以慢点看:
因为每个变量除了正常值 nom 外,还有 4 4 4个边界相关值:
min, min+, max-, max
每个变量贡献 4 4 4个测试用例,一共有 n n n个变量:
4 n 4n 4n
再加上一个所有变量都取正常值的测试用例:
- 1 +1 +1
所以总数是:
4 n + 1 4n + 1 4n+1
比如有 2 2 2个变量:
4 × 2 + 1 = 9 4 × 2 + 1 = 9 4×2+1=9
所以普通边界值测试会有 9 9 9个不重复测试用例。
如果认为应该是 5 n 5n 5n,那其实会把变量为 nom 的情况重复计算。
下图给出了具体的 9 9 9个用例。
2.2.1.2.2 Generalizing Boundary Value Analysis(边界值分析的推广)
边界值分析是一种测试用例设计方法,用来选择输入值或输出值。
普通边界值测试可以从两个方面推广:
- 根据变量数量推广(By the number of variables):
如果程序有 n n n个输入变量,普通边界值测试会生成 4 n + 1 4n + 1 4n+1个测试用例。
这是前面刚刚讲过的公式。 - 不同类型的变量范围,边界值测试的处理方式也不同(By the kinds of ranges of variables)。
有界离散变量(Bounded discrete variable):如果变量有明确的上下界,而且是离散的,就选 5 个测试值。这就是普通边界值测试的基本形式。
无界离散变量(Unbounded discrete (no upper or lower bounds clearly defined)):如果变量没有明确的上界或下界,就人为设置一个边界。
逻辑变量 / 布尔变量(Logical variables):逻辑变量不太适合做边界值分析,因为它只有 true 和 false 两种值。
2.2.1.2.3 边界值分析的局限性
-
当程序有几个相互独立的输入变量,并且这些变量是有明确范围的物理量时,边界值分析效果很好。
-
边界值分析只是机械地根据最小值、最大值选测试数据,并没有真正考虑程序功能和变量的实际含义。
比如 PIN 码是 4 位数字:0000 到 9999
如果只按边界值测试,可能会测:0000, 0001, 5000, 9998, 9999
但 PIN 码的重点不一定是"数值大小"。所以对这种变量,单纯测边界值意义不大。
-
我们要区分物理变量和逻辑变量。
例如刚刚例子中的 PIN 码就是逻辑变量,它只是一个标识符,不是物理量,因此其的最小值、最大值等通常没有太大意义。
2.2.1.2.4 Robust Boundary Value Testing(健壮边界值测试)
Robust Boundary Value Testing(健壮边界值测试)是边界值分析的一个简单扩展。
普通边界值测试测 5 个值:
min, min+, nom, max-, max
而 Robust Boundary Value Testing(健壮边界值测试) 会额外加入两个值:
min-, max+
也就是:
| 名称 | 含义 |
|---|---|
| min- | 刚小于最小值,非法值 |
| max+ | 刚大于最大值,非法值 |
所以健壮边界值测试一共考虑 7 个值:
min-, min, min+, nom, max-, max, max+
因此,如果程序有 n n n个输入变量,健壮边界值测试会产生 6 n + 1 6n + 1 6n+1个不重复测试用例。
因为这里每个变量多了 min-, max+。
因此现在比如两个变量,那就是 13 13 13个不重复用例。
如下图所示。
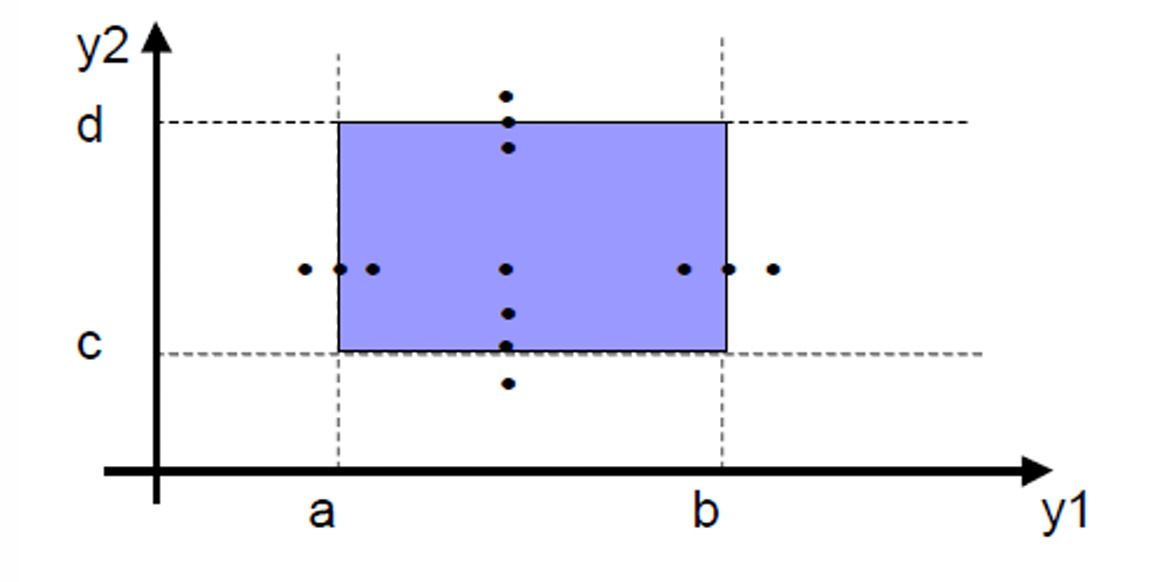
更详细的版本如下图所示。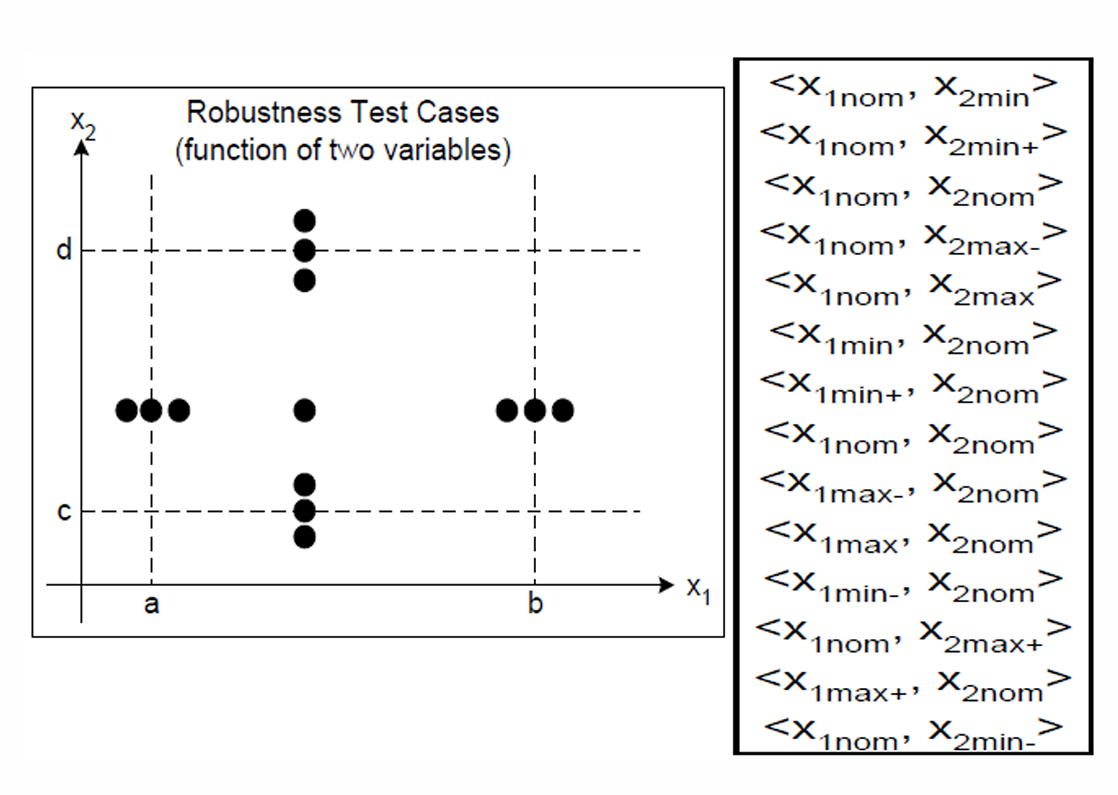
健壮性测试的主要价值,是让我们关注异常处理(exception handling)。
在一些强类型语言中,如果输入值超过了预先定义的范围,程序运行时可能会直接报错。
处理越界值时,有两种思路:
- 弱类型语言 + 异常处理
也就是程序允许输入比较灵活,但要写好异常处理。 - 强类型语言 + 明确的判断逻辑
也就是在强类型语言中,程序员要明确写判断条件来处理越界值。
2.2.1.2.5 Worst-case Boundary Value Testing(最坏情况边界值测试)
它和前面的 Normal Boundary Value Testing(普通边界值测试) 最大区别是:
普通边界值测试:一次只让一个变量取边界值,其他变量保持正常值。
最坏情况边界值测试:允许多个变量同时取边界值,测试它们组合起来会不会出问题。
在最坏情况测试中,我们不再采用"单故障假设"。
这里我们把每个变量的所有可能测试值(5个值)全部组合起来(Cartesian product)。
因此如果有 n n n个输入变量,每个变量有 5 5 5个边界值,那么最坏情况边界值测试会产生 5 n 5ⁿ 5n个测试用例。
| 输入变量数量 | 测试用例数 |
|---|---|
| 1 个变量 | 5¹ = 5 |
| 2 个变量 | 5² = 25 |
| 3 个变量 | 5³ = 125 |
| 4 个变量 | 5⁴ = 625 |
所以它比普通边界值测试多很多。
最坏情况测试最适合用于:多个物理变量之间有很多相互影响,而且程序失败代价很高的系统。
我们继续以 2 个变量为例,那么选取的测试用例如下图所示。
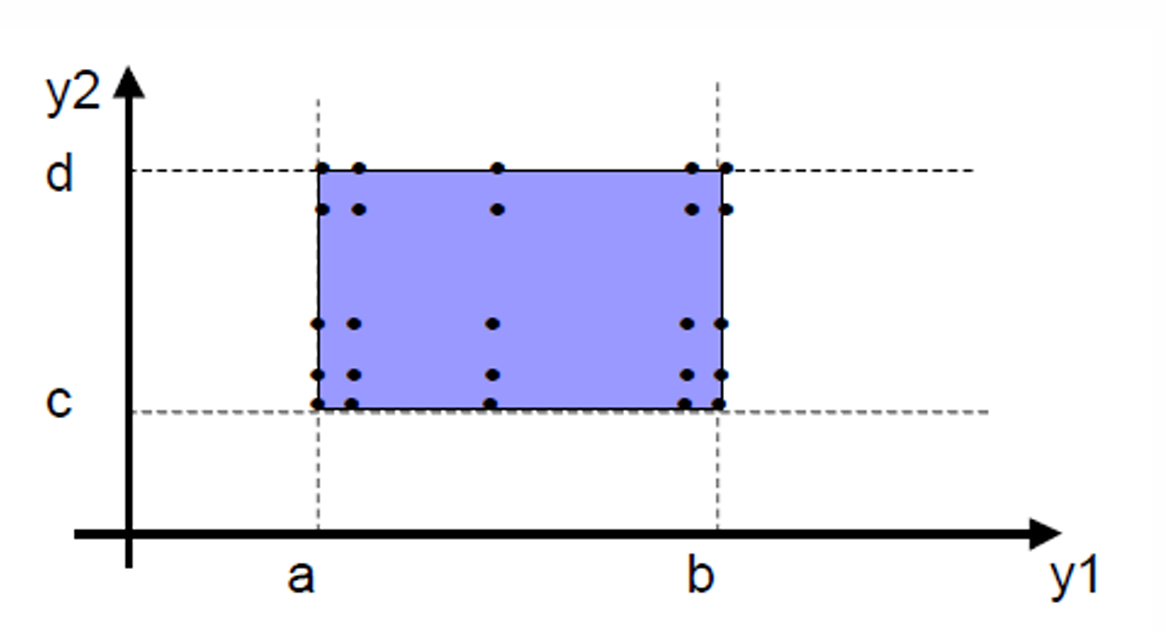
2.2.1.2.6 Robust Worst-case Boundary Value Testing(健壮最坏情况边界值测试)
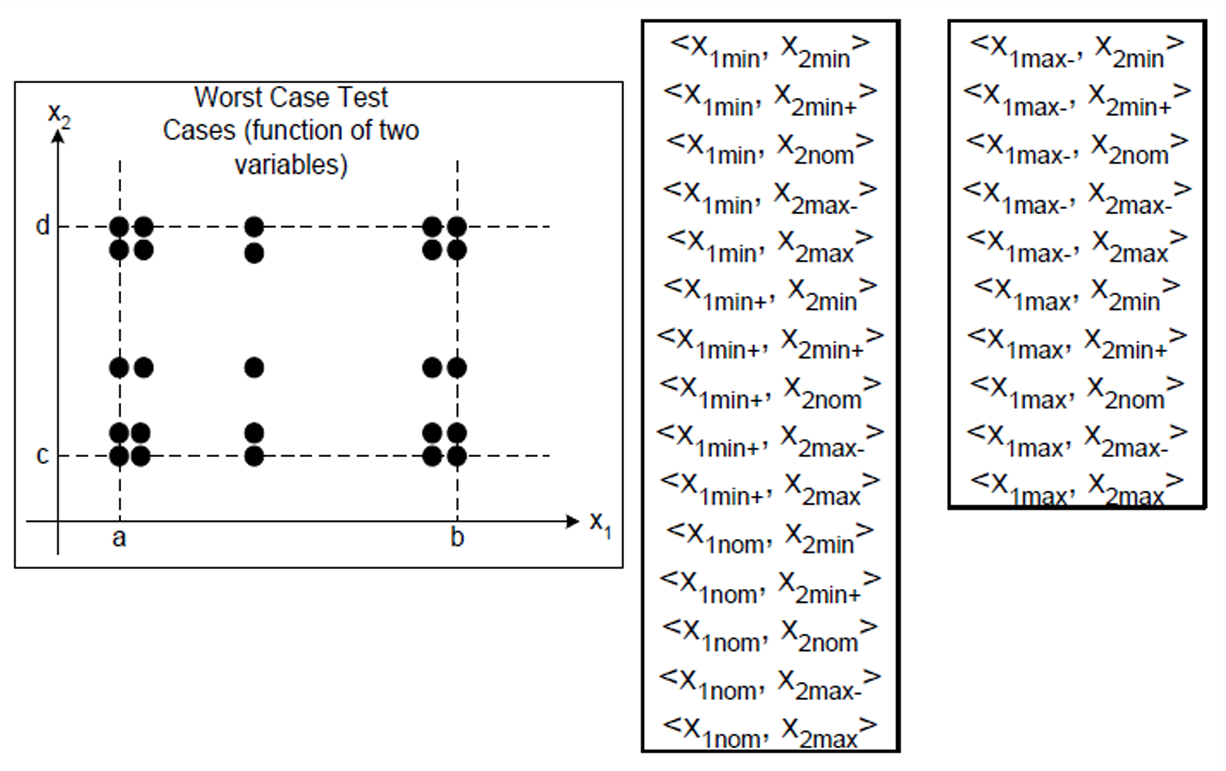
我们现在也很容易通过前面的学习知道什么是Robust Worst-case Boundary Value Testing(健壮最坏情况边界值测试)了。
普通的 Worst-case Boundary Value Testing 每个变量取 5 个值:
min, min+, nom, max-, max
而 Robust Worst-case Boundary Value Testing 会再加上两个非法边界值:
min-, max+
所以每个变量一共取 7 个值:
min-, min, min+, nom, max-, max, max+
把每个变量的 7 7 7个值全部组合起来测试。
如果有 n n n个输入变量,每个变量有 7 7 7个候选值,那么总测试用例数就是 7 n 7ⁿ 7n。
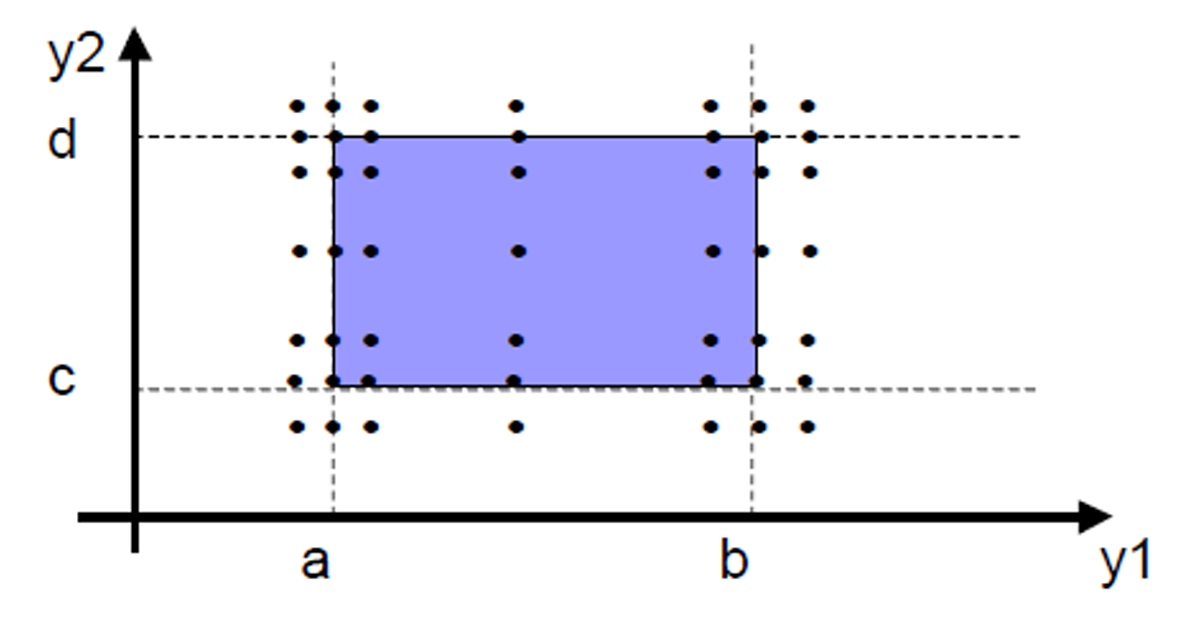
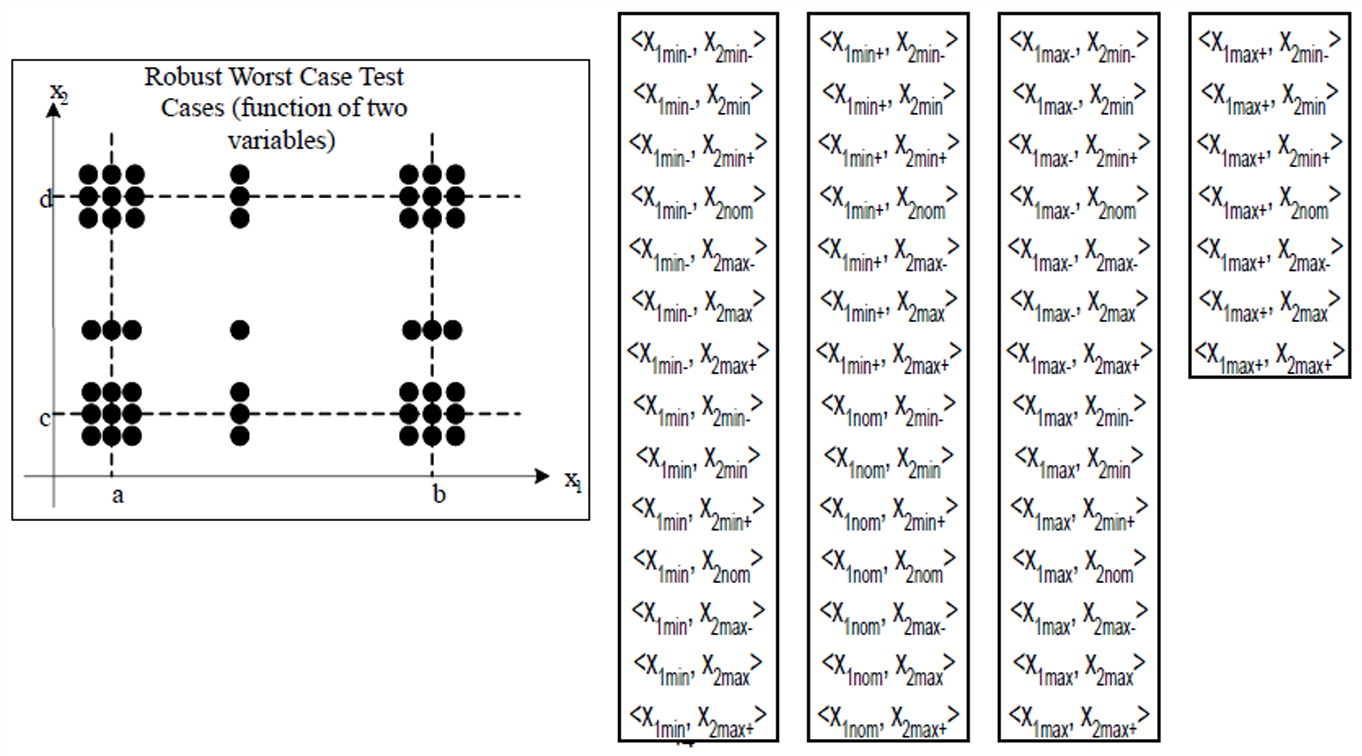
2.2.1.3 示例 1
我们现在说一个示例来展示黑盒测试以及边界值测试。
我们现在的程序可以判断三角形的类型。
因此其输入 3 个整数,表示三角形的三条边。
然后输出三角形的类型。
| 英文 | 中文 | 含义 |
|---|---|---|
| Equilateral | 等边三角形 | 三条边都相等 |
| Isosceles | 等腰三角形 | 有两条边相等 |
| Scalene | 不等边三角形 | 三条边都不相等 |
| NotATriangle | 不是三角形 | 三条边不能组成三角形 |
扩展版本会增加一种输出类型:直角三角形(Right Triangle)。
我们现在明确了问题,那就开始设计测试。
这个程序输入三条边,但题目只说"三条边是整数",没有明确规定边长范围,所以测试人员要自己设定测试范围。
三角形边长不可能是 0 或负数,所以每条边的最小合法值是 1。
因为题目没有给最大值,所以这里人为规定最大边长是 200。
因此对每一条边,都取 5 个普通边界值:
| 类型 | 值 |
|---|---|
| min | 1 |
| min+ | 2 |
| nom | 100 |
| max- | 199 |
| max | 200 |
如果做 Robust Boundary Value Testing(健壮边界值测试),还要加入非法边界值:0 和 201。
下表格展示了生成的 普通边界值测试用例。
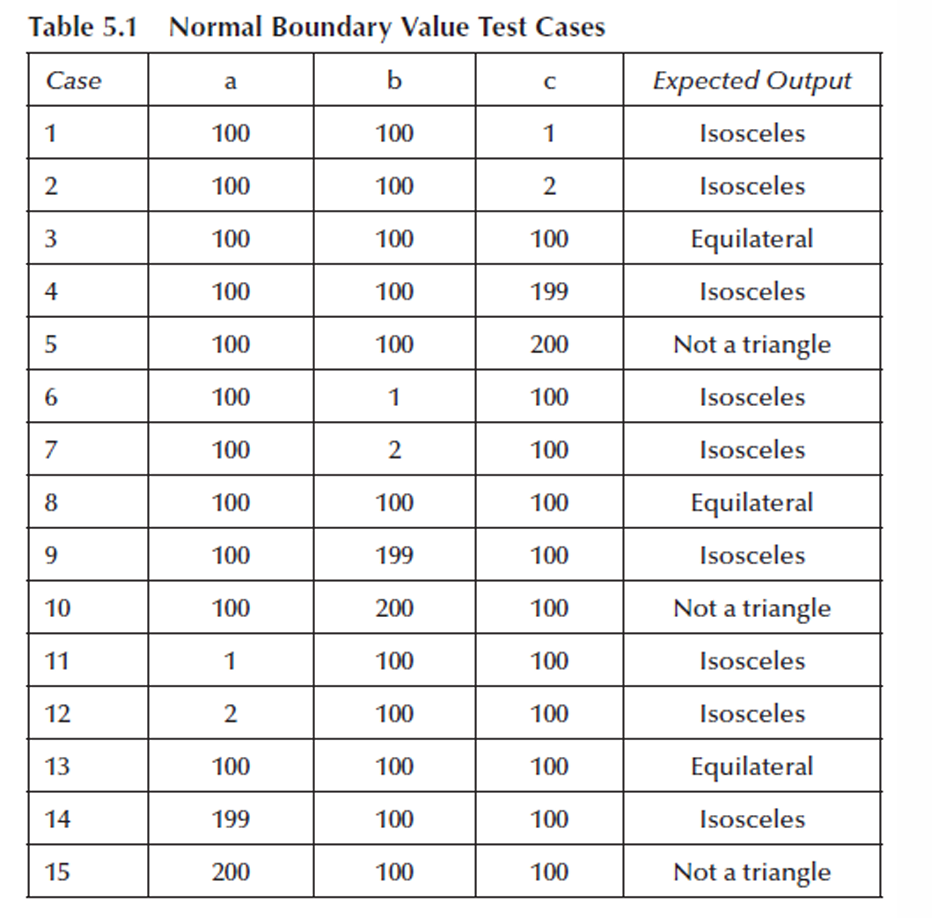
我们从这里也可以发现如果程序有 n n n个输入变量,普通边界值测试会产生 4 n + 1 4n + 1 4n+1个不重复的测试用例。
如表中所示,第 3、8、13 个测试用例是一样的,这些是重复测试用例,叫 Redundant(冗余的)。
因此不重复的测试用例的确是 13 13 13个。
但这里其实还有个问题,那就是这些普通边界值测试用例里,没有不等边三角形的测试用例。
2.2.1.4 示例 2
我们要测试的是NextDate Function(下一日期函数)。它是一个函数,输入 3 个变量:month, day, year
我们给定一个日期,返回下一天的日期。
我们可以把月份编码成数字:
| 月份 | 数字 |
|---|---|
| January 一月 | 1 |
| February 二月 | 2 |
| March 三月 | 3 |
| ... | ... |
| December 十二月 | 12 |
这个例子使用 最坏情况边界值测试。
这里有 3 3 3个变量,所以测试用例数量是: 5 3 = 125 5³ = 125 53=125。
也就是一共会有 125 125 125个测试用例。
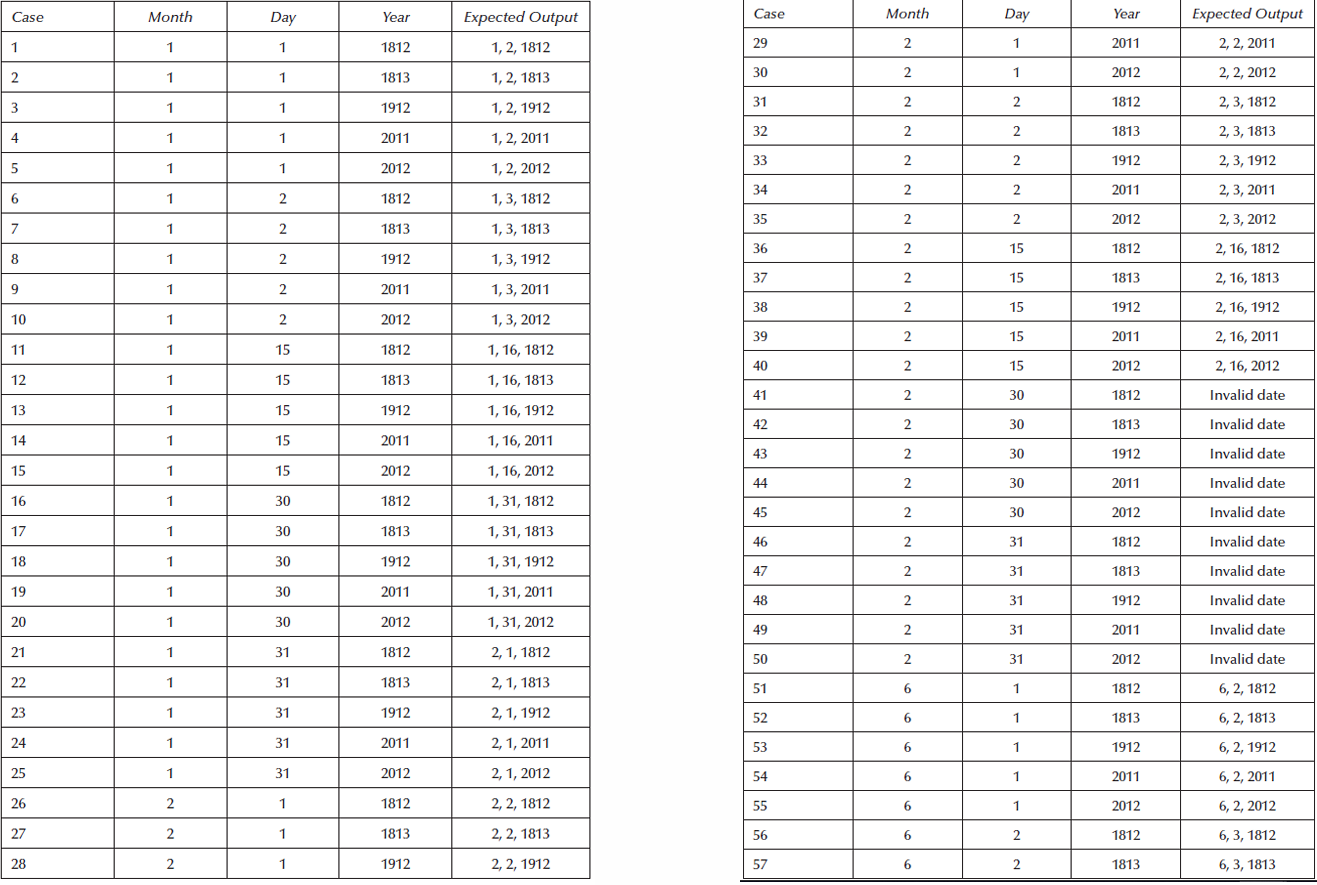
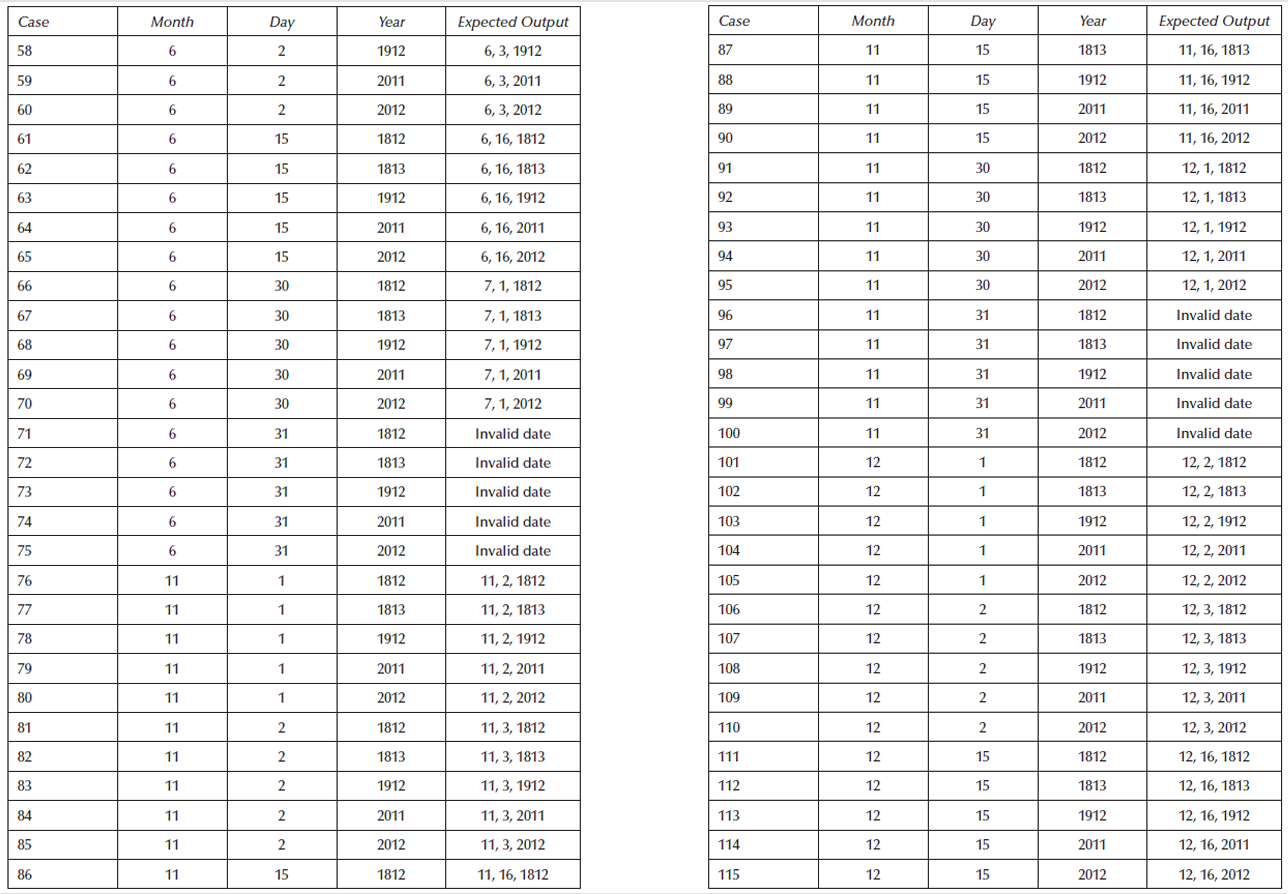
接下来要检查两个问题:
- Gaps of untested functionality(没有测试到的功能空缺 / 漏测)
虽然生成了 125 125 125个测试用例,但有些重要功能可能还是没测到。
比如:
2 月 28 日的下一天;
闰年 2 月 29 日的下一天;
4 月 30 日的下一天;
12 月 31 日跨年。
这些才是日期函数真正容易出错的地方。 - Redundant testing(重复测试 / 冗余测试)
这就暴露了边界值测试的缺点。
因为没有必要在5 个不同年份里都测试 1 月 1 日,而且 日期函数里,2 月是最特殊的,而在这里 2 月没有被充分测试。
2.2.2 Equivalence Class Testing(等价类测试)
边界值测试通常假设输入变量之间是相互独立的。
但其实它们并不是完全独立的,比如 2月31日就是非法的组合。
所以单纯用边界值测试,有时候不能很好处理变量之间的关系。
边界值测试可能会生成较多测试用例,但覆盖效果不一定好。
等价类会把一个输入集合划分成几个互不重叠的小集合。
等价类划分对测试有两个重要意义。
- Completeness(完整性):
因为所有输入都被某个等价类覆盖,所以测试具有一定完整性。 - Non-redundancy(非冗余性):
因为各个等价类互不重叠,所以可以减少重复测试。
等价类测试就是:把输入分成几类,然后每一类选一个代表值来测试。
如果等价类划分得合理,就可以大大减少重复测试。
等价类测试最关键的是:用什么规则来划分类别(equivalence relation that determines the classes(partitions))。
等价类选择很像一门"手艺"。它不像边界值测试那样有明确公式,关键在于能不能合理地把输入分成不同类别。
等价类测试不依赖代码知识,只依赖需求说明书。
等价类选择需要了解输入领域知识,而这些知识往往超过界面说明书本身。
这里必须理解输入之间是如何相互依赖的。
2.2.2.1 Input Equivalence Class(输入等价类)
2.2.2.1.1 两个输入变量的函数,如何做等价类测试
先假设有一个函数 f ( x 1 , x 2 ) f(x_1, x_2) f(x1,x2),其中 a ≤ x 1 ≤ b a ≤ x_1 ≤ b a≤x1≤b, c ≤ x 2 ≤ d c ≤ x_2 ≤ d c≤x2≤d。
对 x 1 x_1 x1进行等价类划分:
{ a , a + 1 , . . . , t a } , { t a + 1 , t a + 2 , . . . , t b } , { t b + 1 , t b + 2 , . . . , b } \{a, a+1, ..., t_a\}, \{t_{a+1}, t_{a+2}, ..., t_b\}, \{t_{b+1}, t_{b+2}, ..., b\} {a,a+1,...,ta},{ta+1,ta+2,...,tb},{tb+1,tb+2,...,b}
对 x 2 x_2 x2进行等价类划分:
{ c , c + 1 , . . . , t c } , { t c + 1 , t c + 2 , . . . , t d } , { t d + 1 , t d + 2 , . . . , d b } \{c, c+1, ..., t_c\}, \{t_{c+1}, t_{c+2}, ..., t_d\}, \{t_{d+1}, t_{d+2}, ..., db\} {c,c+1,...,tc},{tc+1,tc+2,...,td},{td+1,td+2,...,db}
如下图所示。
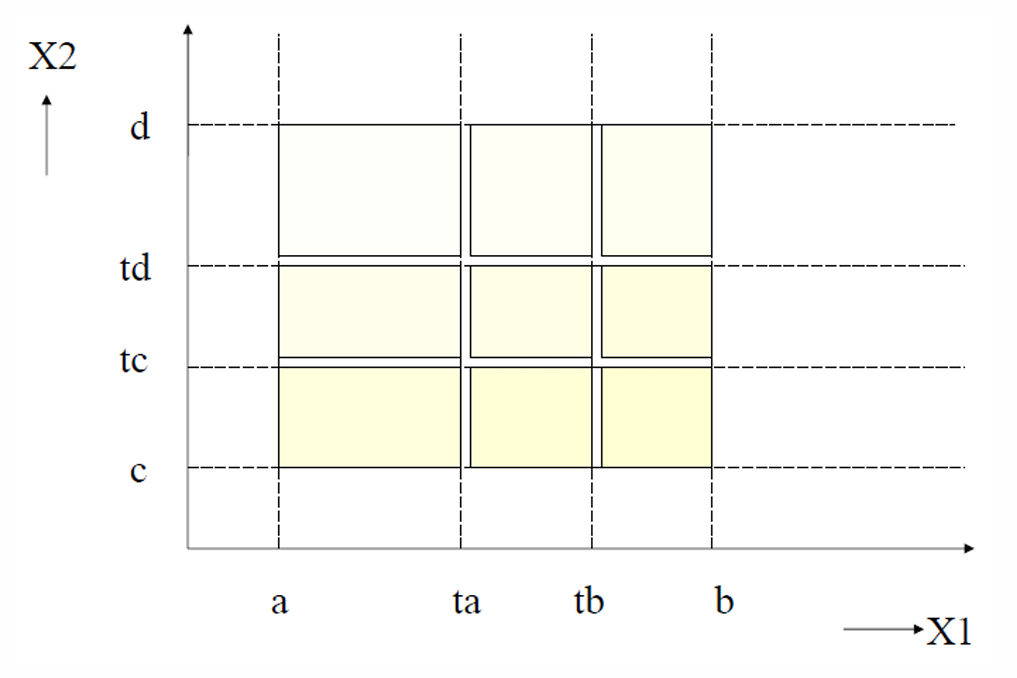
所以如果一个函数有两个输入变量,做等价类测试时,不是只看每个变量的最小值和最大值,而是要先把每个变量的输入范围划分成几个有意义的类别。
我们划分完毕后,从每一个划分出来的区域里选一个值作为测试数据。
每个选出来的值,都代表它所在区域里的所有值。
所以总测试数据数量是 n × m n × m n×m,其中 n = x 1 的等价类数量 n = x_1 的等价类数量 n=x1的等价类数量, m = x 2 m = x_2 m=x2 的等价类数量。
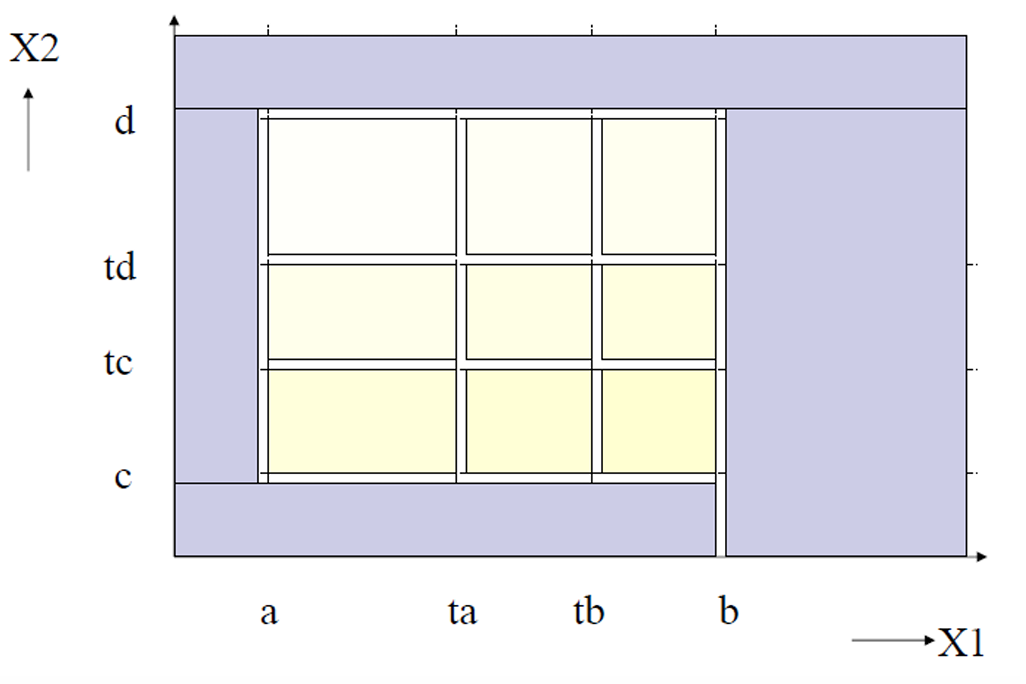
2.2.2.1.2 两个变量函数的等价类测试:健壮性测试版本(Robustness Testing)
我们也可以像前面 BVT 那样,将前面的扩展为 Robustness Testing。
也就是在普通等价类测试的基础上,加入非法输入等价类,用来检查程序面对异常输入时能不能正确处理。
普通等价类测试只会在合法范围内划分,Robustness Testing 会加入非法等价类。
因此对于原来的 a ≤ x 1 ≤ b a ≤ x_1 ≤ b a≤x1≤b
现在扩展成 5 个等价类: { v a l u e s < a } , { a , a + 1 , . . . , t a } , { t a + 1 , t a + 2 , . . . , t b } , { t b + 1 , t b + 2 , . . . , b } , { v a l u e s > b } \{values < a\},\{a, a+1, ..., t_a\},\{t_{a+1}, t_{a+2}, ..., t_b\},\{t_{b+1}, t_{b+2}, ..., b\},\{values > b\} {values<a},{a,a+1,...,ta},{ta+1,ta+2,...,tb},{tb+1,tb+2,...,b},{values>b}
对于 x 2 x_2 x2进行同样的操作: { v a l u e s < c } , { c , c + 1 , . . . , t c } , { t c + 1 , t c + 2 , . . . , t d } , { t d + 1 , t d + 2 , . . . , d } , { v a l u e s > d } \{values < c\},\{c, c+1, ..., t_c\},\{t_{c+1}, t_{c+2}, ..., t_d\},\{t_{d+1}, t_{d+2}, ..., d\},\{values > d\} {values<c},{c,c+1,...,tc},{tc+1,tc+2,...,td},{td+1,td+2,...,d},{values>d}
如下图所示。
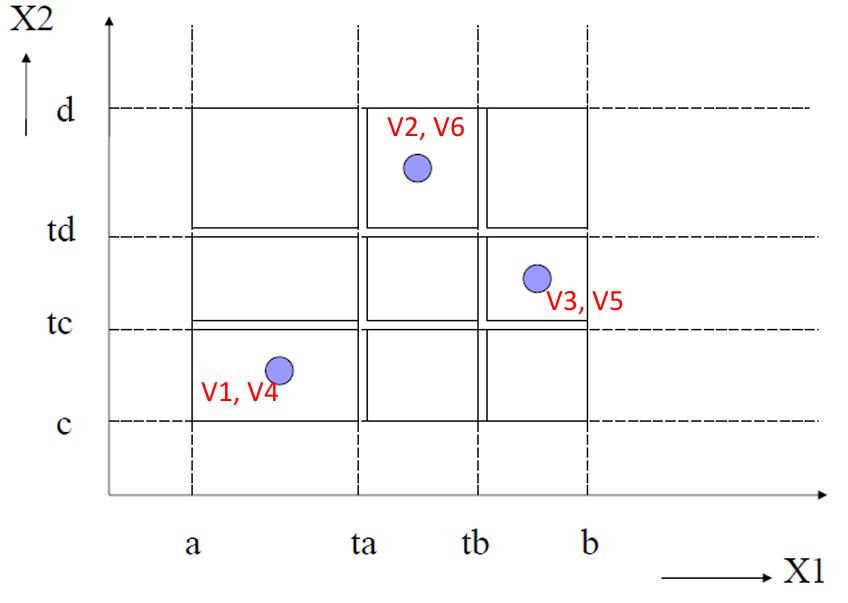
2.2.2.1.3 Weak Normal Equivalence Class Testing(弱普通等价类测试)
这里的 Weak 不是"很差"的意思,而是说不要求测试所有等价类组合,只要求每个等价类至少被覆盖一次。
这里的 Normal 自然是跟前面说的 Robust 向对应,表示只考虑有效等价类,也就是合法输入范围内的类别。
Weak Normal Equivalence Class Testing(弱普通等价类测试)的目标是让每一个等价类至少被测试一次。
不需要把所有等价类组合都测一遍。
比如:年龄有 3 3 3类,成绩有 2 2 2类。
如果全部组合,就是: 3 × 2 = 6 3 × 2 = 6 3×2=6个测试用例
但 Weak Normal 不要求全部组合,只要每个类出现一次即可。
例如只用 3 个测试用例:
| 测试用例 | 年龄类 | 成绩类 |
|---|---|---|
| 1 | 儿童 | 及格 |
| 2 | 成年人 | 不及格 |
| 3 | 老人 | 及格 |
因此最少测试用例数量 = 等价类数量最多的那个输入变量的等价类个数。
就像刚刚例子中只用 3 个测试用例。
如下图所示, x 1 x_1 x1有 3 类, x 2 x_2 x2有 3 类,所以理论上全部组合是: 3 × 3 = 9 3 × 3 = 9 3×3=9个区域。
Weak Normal 只需要 3 3 3个测试用例,就让所有等价类都至少出现了一次。
2.2.2.1.4 Strong Normal Equivalence Class Testing(强普通等价类测试)
这里的 Strong 就与前面的 Weak 相对应了,需要覆盖所有合法等价类组合。
强等价类测试是基于等价类子集的笛卡尔积。
同样的例子,现在就需要 3 × 3 = 9 3 × 3 = 9 3×3=9个测试用例。如下图所示。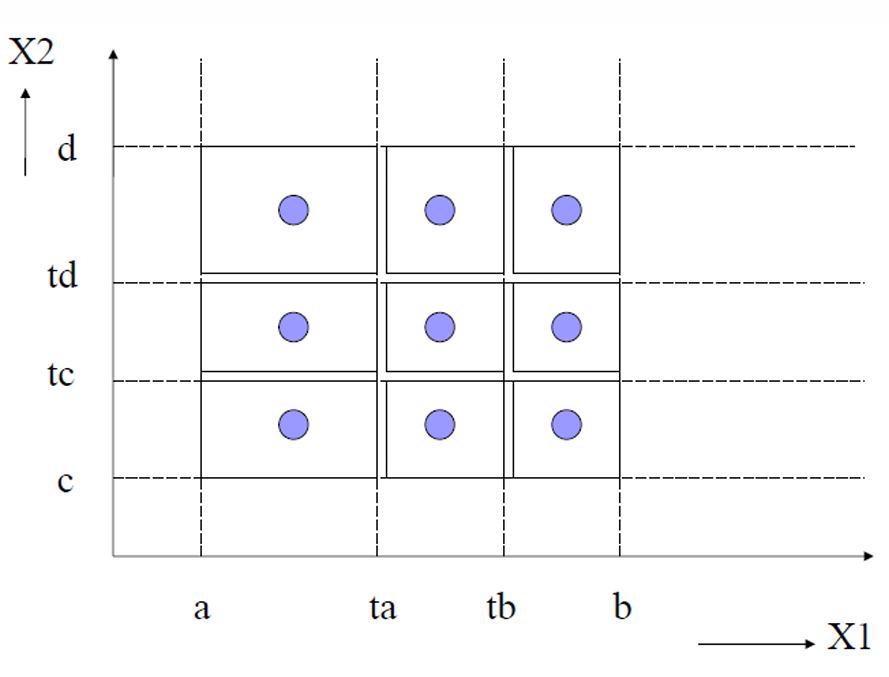
它会产生更多测试用例,用来检查不同等价类组合之间是否存在相互影响。
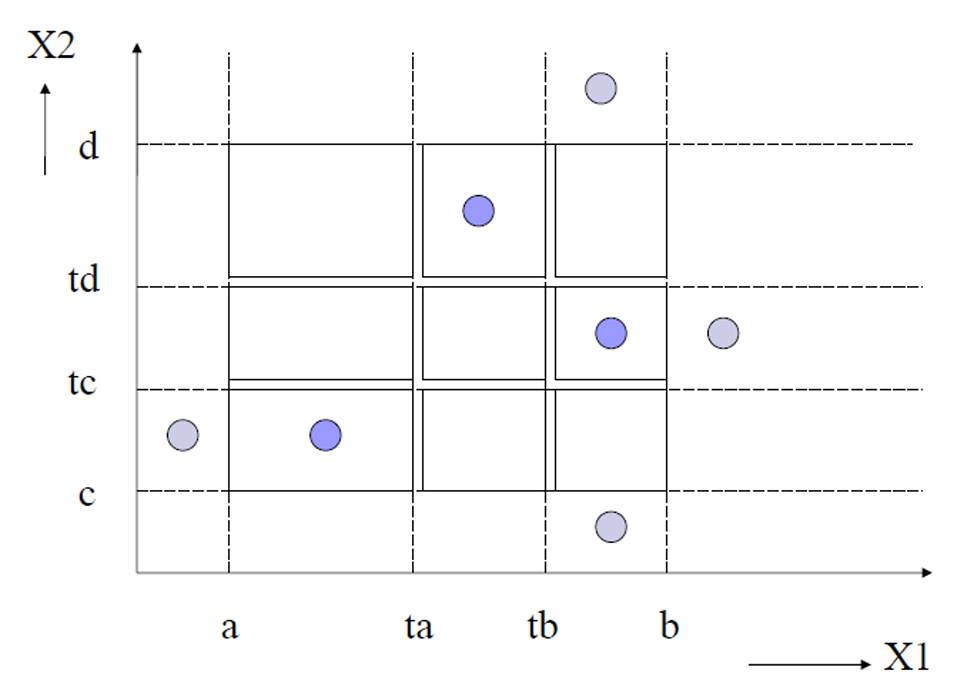
2.2.2.1.5 Weak Robust Equivalence Class Testing(弱健壮等价类测试)
弱健壮等价类测试和弱普通等价类测试类似,只是额外加入了范围之外的非法等价类。
对于每个变量的超出范围情况,至少选择一个测试用例来覆盖。
如下图所示。
2.2.2.1.6 Strong Robust Equivalence Class Testing(强健壮等价类测试)
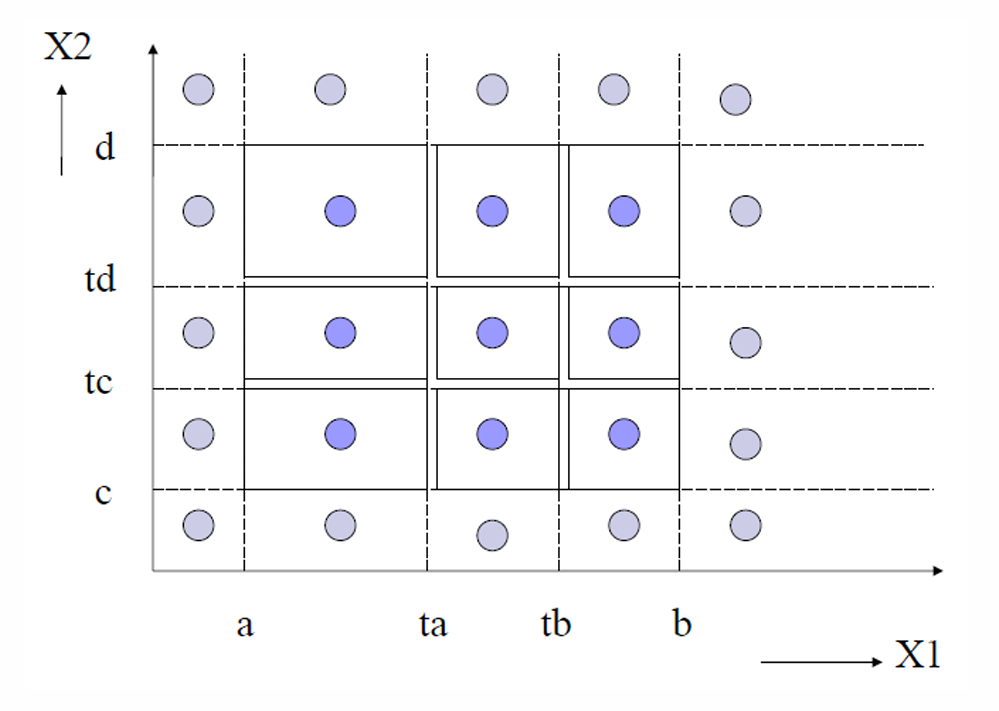
强健壮等价类测试和强普通等价类测试类似,只是额外加入了超出范围的非法等价类。
测试用例再次来自所有等价类的笛卡尔积。
如下图所示。
2.2.2.1.7 示例 1
我们现在举一个 等价类测试(Equivalence Class Testing) 的例子。
我们现在的程序时做除法运算。
X 是被除数,Y 是除数。
因为输入整数有很多,不可能全部测试,所以把它们分成几类。
对于除法来说,整数大致可以分成:负数、0、正数。
所以 X 被分成三类:
| X 的等价类 | 含义 |
|---|---|
| values <= -1 | 负数 |
| 0 | 零 |
| values >= 1 | 正数 |
而到 Y 的时候:
| Y 的等价类 | 含义 |
|---|---|
| values <= -1 | 负数除数 |
| 0 | 零除数 |
| values >= 1 | 正数除数 |
Y = 0 是 invalid(非法输入),因为除法中不能除以 0。所以如果这里这不是合法输入,所以在 normal 中就得排除,但是 robust 会考虑。
用弱普通等价类测试方法,为 X / Y 这个除法程序选 3 组测试输入。
可以是:(X, Y) = (-3, -5), (0, 8), (12, 2)
2.2.2.2 Output Equivalence Class(输出等价类)
等价类划分也可以应用在软件的输出范围上。
输出等价类表示软件面对不同输入时可能产生的不同响应或行为。
比如三角形问题中,输出可能有:
| 输出等价类 | 含义 |
|---|---|
| Equilateral | 等边三角形 |
| Isosceles | 等腰三角形 |
| Scalene | 不等边三角形 |
| NotATriangle | 不是三角形 |
所以测试时不能只随便测几组输入,而要确保这几种输出结果都能被触发。
输出等价类就可以验证软件对于每一类输出是否都能按预期工作。
2.2.2.2.1 示例 2
用一个租车系统来说明等价类不仅可以按照输入划分,也可以按照输出结果来划分。
这是一个简单的租车系统,系统最终要输出的是租车费用。
系统根据 3 个输入来计算费用:车的类型、租车天数、是否会员。
经济型车:20 美元/天
SUV:50 美元/天
豪华车:100 美元/天
如果客户是会员,总价打 9 折。
我们可以按照 Output Equivalence Class(输出等价类)来划分等价类。
前面规则是:
- Economy car:20 美元/天
- SUV:50 美元/天
- Luxury car:100 美元/天
- 会员有 10% 折扣
- 非会员没有折扣
所以输出等价类可以分成 6 类:
- 非会员租经济型车的费用。
- 会员租经济型车的费用。
- 非会员租 SUV 的费用。
- 会员租 SUV 的费用。
- 非会员租豪华车的费用。
- 会员租豪华车的费用。
我们现在如果使用弱普通等价类测试来测试"输出等价类"。
那我们现在只需要从每一个输出等价类中选一个代表案例来测试,不需要测试所有可能天数。
- 非会员租经济型车 3 天。
- 会员租经济型车 2 天。
- 非会员租 SUV 4 天。
- 会员租 SUV 7 天。
- 非会员租豪华车 1 天。
- 会员租豪华车 5 天。
如果我们还是从输入角度划分,那么结果就是 3 种,但是我们按照前面输出等价类进行的划分。
那么如果我们使用 Strong Normal Equivalence Class Testing(强普通等价类测试)来测试租车系统。
那么我们不仅每个等价类要覆盖,还要测试所有可能组合。
所以现在对于每一类都要测试单天和多天的情况,因此测试用例如下:
| 测试用例 | 车型 | 是否会员 | 天数 |
|---|---|---|---|
| 1 | Economy | 非会员 | 1 天 |
| 2 | Economy | 非会员 | 2 天 |
| 3 | Economy | 会员 | 1 天 |
| 4 | Economy | 会员 | 2 天 |
| 5 | SUV | 非会员 | 1 天 |
| 6 | SUV | 非会员 | 2 天 |
| 7 | SUV | 会员 | 1 天 |
| 8 | SUV | 会员 | 2 天 |
| 9 | Luxury | 非会员 | 1 天 |
| 10 | Luxury | 非会员 | 2 天 |
| 11 | Luxury | 会员 | 1 天 |
| 12 | Luxury | 会员 | 2 天 |
如果我们使用Robust Equivalence Class Testing(健壮等价类测试)来测试租车系统。
那么我们不仅要测试合法输入,还要测试非法输入。
这个租车系统的合法输入有:三种合法车型,租车天数得是正整数,两种合法会员状态。
所以非法输入有:
- 非法车型:除了 Economy、SUV、Luxury 之外的车型都是非法的。比如:compact, pickup。
- 非法租车天数:非正整数,也就是小于等于 0 的整数。比如:0, -1, -5。
- 非法会员状态:除了 member 和 non-member 之外的状态都是非法的。比如:pending。
2.2.2.3 Effective coverage of test cases(如何让测试用例覆盖更有效)
单独使用某一种测试方法可能不够,最好把输入、输出、非法情况、边界情况结合起来考虑。
-
最好同时对输入和输出都做等价类测试。
实际中很多人只对输入做等价类划分。
-
最好加入健壮等价类,也就是非法输入等价类。
-
最好把等价类测试和边界值测试结合起来。
最好考虑最坏情况,也就是多个变量可能同时出问题。
前面普通测试常常假设:一次只有一个变量有问题。
但是现实中可能多个输入同时非法:这就是 multiple-fault assumption(多故障假设)。
2.2.2.4 Scenario for Equivalence Class Testing(适合使用等价类测试的场景)
- Large Input Domain(输入范围很大时):当一个系统有大量可能输入时,不可能把所有输入都测试一遍。
所以可以把输入分成不同组,也就是等价类,然后每组挑一个代表值来测试。 - Boundary Conditions(边界条件):等价类测试也有助于发现边界附近的问题。
当你把输入分成有效类和无效类时,它们之间的边界往往容易出错。 - Reducing Redundancy(减少重复测试):如果我们认为同一个等价类里的输入效果差不多,那么只测其中一个代表值就可以,不需要重复测很多类似的值。
优点:
- Software with Defined Inputs(输入范围明确的软件):等价类测试最适合用于输入范围比较明确、容易分类的软件。
- Quick and Early Bug Discovery(快速、早期发现 Bug):等价类测试可以帮助测试人员更快地测试,并且在测试早期发现高风险缺陷。
缺点:
虽然等价类测试可以发现很多问题,但它不能保证发现所有错误。
所以它不能单独使用,应该和其他测试方法一起用。
2.2.3 Decision Table(决策表)
决策表是一种精确而且简洁的方法,用来表示复杂逻辑。
决策表和程序里的 if-then-else、switch-case 很像,都是根据条件决定执行什么动作。
决策表可以很清楚地把多个独立条件和多个动作对应起来。
决策表可以检查所有条件是否都考虑到了。
决策表可以用来描述复杂的程序逻辑。
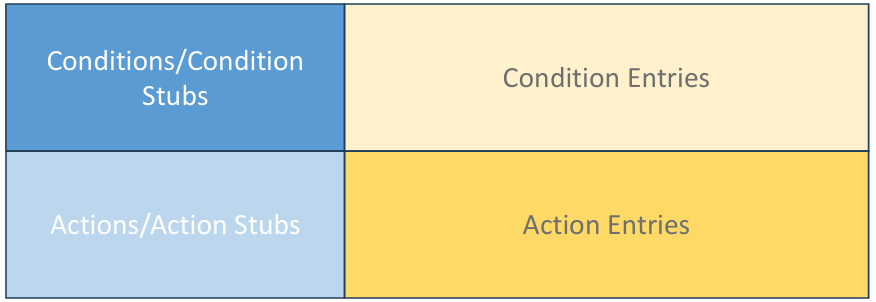
图中决策表分成四个部分:
| 区域 | 中文意思 | 作用 |
|---|---|---|
| Conditions / Condition Stubs | 条件项 | 写有哪些条件 |
| Condition Entries | 条件取值 | 写每种规则下条件是 Yes 还是 No |
| Actions / Action Stubs | 动作项 | 写可能执行的动作 |
| Action Entries | 动作取值 | 写每种规则下执行哪个动作 |
2.2.3.1 决策表结构
下面展示了一个决策表结构。
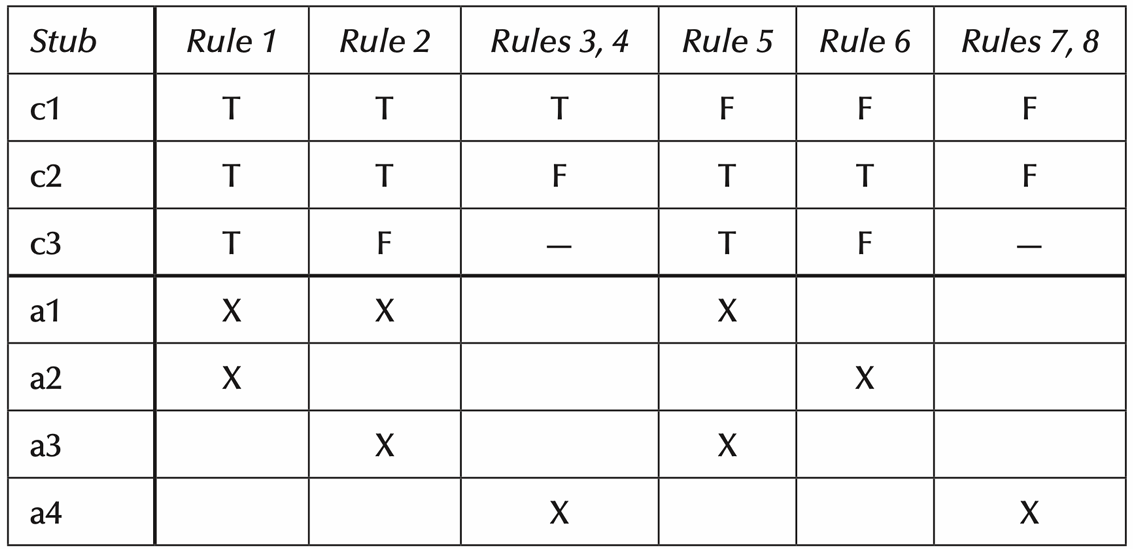
上半部分:条件(Conditions)
下半部分:动作(Actions)
每一列表示一种 条件组合,也就是一种测试场景。
例如这里第一列表示,条件1、2、3的情况下执行a1和a2的动作。
决策表里的每一个条件,都对应一个变量、关系判断或谓词判断。
条件的可能取值会写在 condition entries 里面。
- Boolean values:True / False。
有些条件只有两个值 True / False
比如:是否会员?是否登录?密码是否正确?
这种决策表叫 Limited Entry Decision Table(有限项决策表) - Several values:多个取值
有些条件不只是 True / False,而是有多个可能值。
这种叫 Extended Entry Decision Table(扩展项决策表) - Don't care value:也可以不关心这里的值。
比如用户名不对的时候,密码对不对都无所谓了。
每一个 action 都是系统要执行的操作。
action entries 用来说明某个规则下是否执行某个动作。
通常用 X 表示执行,如前面的图中所示。
2.2.3.2 示例 1
我们现在有一个函数 f(x1, x2),当输入满足条件时,执行计算;否则输出错误信息。
用决策表设计测试结果如下:

| 条件 | Rule 1 | Rule 2 | Rule 3 | Rule 4 |
|---|---|---|---|---|
| x1 在范围内? | T | T | F | F |
| x2 在范围内? | T | F | T | F |
| Compute y | X | |||
| Output error | X | X | X |
也可以用 Don't care value,因为这里一个条件已经足够决定结果,另一个条件无论是 T 还是 F,结果都一样。
结果如下图所示。

我们用 − − -- −−表示 Don't care value。
我们还可以划分得更详细。

2.2.3.3 示例 2
我们再看一个 Extended Entry Decision Table(扩展项决策表)的例子。
现在系统根据两个条件决定员工工资。
员工类型:
| 符号 | 含义 |
|---|---|
| S | Salaried employee,固定薪资员工 |
| H | Hourly employee,小时工 |
工作时长:
| 条件 | 含义 |
|---|---|
| < 40 | 工作少于 40 小时 |
| 40 | 正好工作 40 小时 |
| > 40 | 工作超过 40 小时 |
具体结果如下图所示。
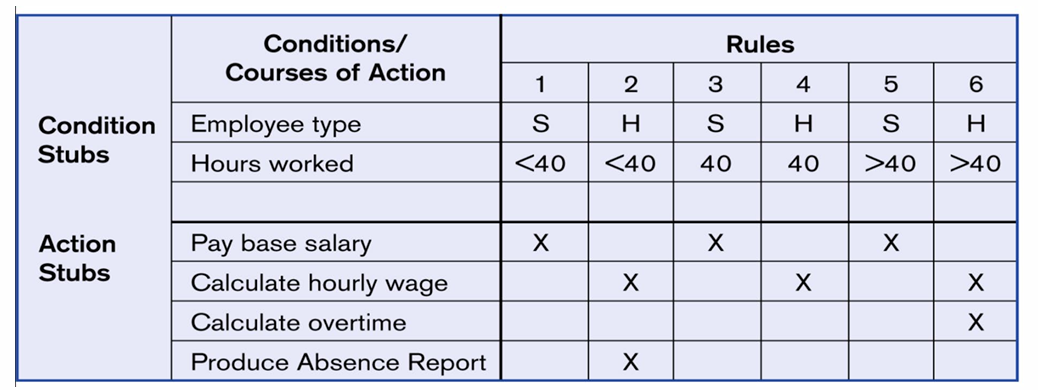
2.2.3.4 Decision Table Development Methodology(决策表开发方法)
做一个决策表的步骤如下:
- Determine conditions and values(确定条件和条件取值)
先找出系统里有哪些判断条件,以及每个条件可能有哪些值。 - Determine maximum number of rules(确定最多有多少条规则)
规则数量通常等于所有条件取值的组合数。 - Determine actions(确定动作)
找出系统可能执行哪些动作。 - Encode possible rules(填写所有可能规则)
把各种条件组合写进决策表。 - Encode the appropriate actions for each rule(为每条规则填写对应动作)
也就是判断每一种条件组合下,系统应该执行什么操作。 - Verify the policy(检查规则是否正确)
- Simplify the rules(简化规则)
如果某些规则可以合并,就减少列数。
用 don't care value,把两列合并成一列。
2.2.3.5 决策表的使用条件
- 如果需求说明本身就是表格形式,或者可以整理成决策表,就适合用决策表。
- 条件判断顺序不影响结果。
例子:如果先判断"是否会员",再判断"是否有优惠券",结果和反过来判断一样,那就适合用决策表。 - 先看哪条规则、后看哪条规则,不会影响最后执行的动作。
例子:Rule 1 对应登录成功,Rule 2 对应密码错误,Rule 3 对应账号冻结。
只要条件组合明确,哪条规则满足就执行哪条对应动作。 - 一旦找到满足条件的规则,并确定了动作,就不用再看其他规则了。
例子:已经确定是"用户名正确 + 密码错误",那就直接执行"提示密码错误",不用再检查其他规则。 - 如果某条规则对应多个动作,这些动作的执行顺序不影响最终结果。
例子:如果先计算工资再生成报告,或者先生成报告再计算工资,结果没有本质区别,那就适合用决策表。
2.2.3.6 使用决策表时要注意的问题
使用决策表时要注意的问题如下:
- 规则必须完整(Rules must be complete)
所有条件组合都必须在决策表里明确列出来,包括默认情况。 - 规则必须一致(Rules must be consistent)
同一种条件组合,只能对应一个动作,或者一组明确的动作。
不能出现同一个条件组合对应两个互相矛盾的结果。
下图就展示了一个不一致的决策表。
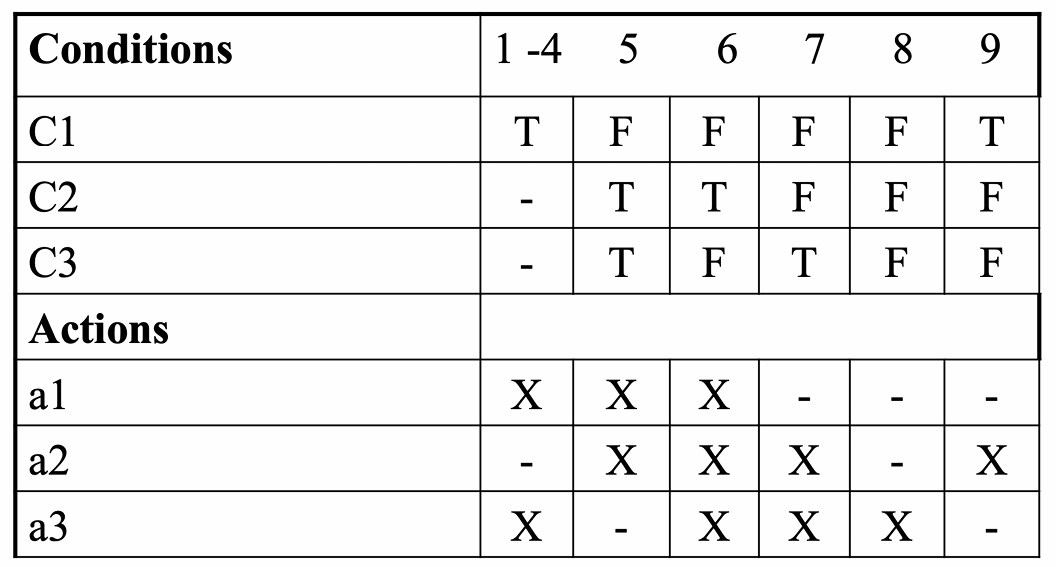
这里规则1-4明明包含了规则9,但是执行的动作不一致(inconsistent)。
2.2.3.7 示例3
我们回到之前的三角形问题。
如果用决策表设计结果如下图所示。
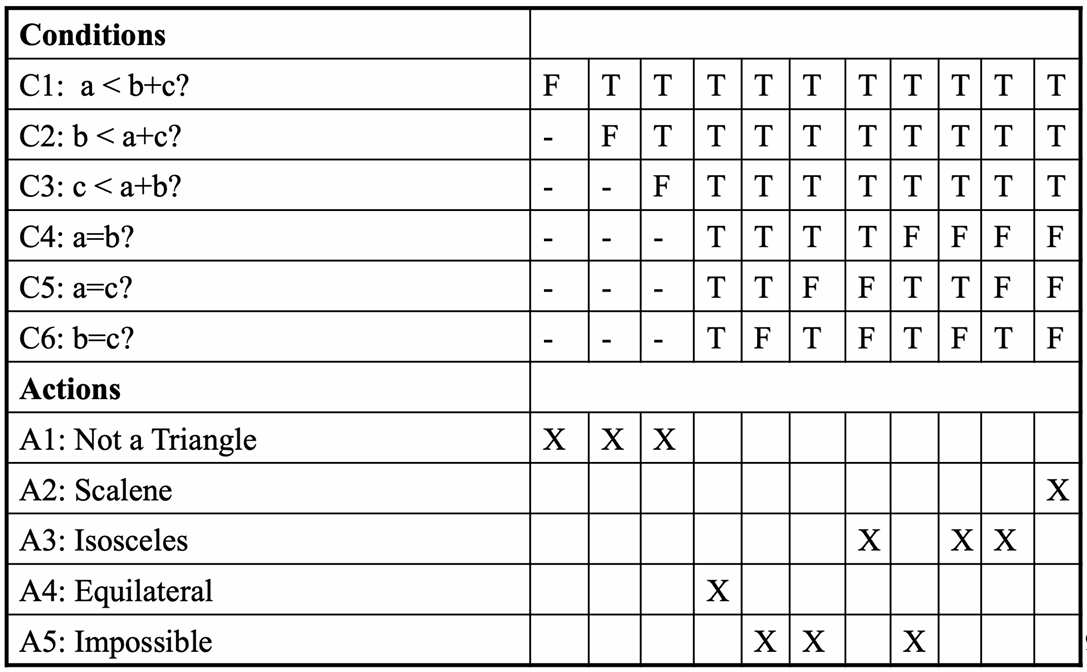
我们进入 build 阶段,把决策表转成具体测试用例表。
如下图所示。
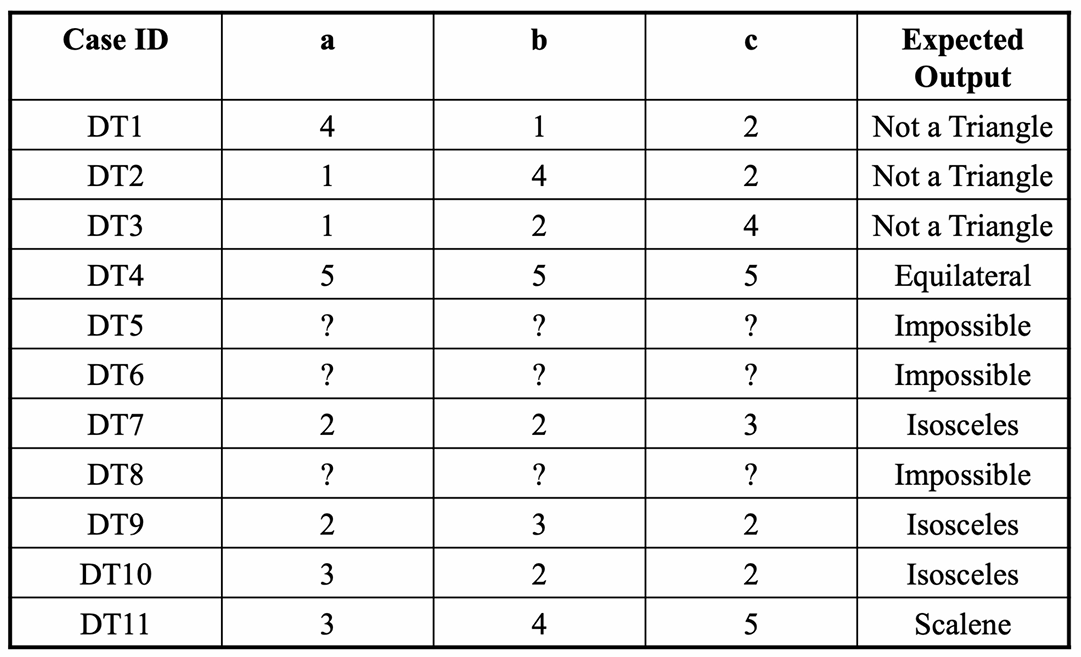
2.2.3.8 决策表的适合情况
- 决策表测试最适合用于具有复杂判断逻辑的程序。
- 程序里有明显的 if-then-else 判断逻辑。
- 输入变量之间有重要逻辑关系。
- 计算涉及部分输入变量。
- 输入和输出之间有因果关系。
- 有复杂计算逻辑。
- 决策表的缺点(Decision tables do not scale up very well):决策表不太适合规模特别大的情况。
- 决策表可以不断改进(Decision tables can be iteratively refined)。