目录
EdgeCrafter:实时目标检测任务新SOTA
大家好,简单给大家介绍一下我们最新的工作EdgeCrafter ,在实时目标检测、实例分割、人体姿态估计上都取得了SOTA。在目标检测上超过了RT-DETRv4,包括我们的之前的工作DEIMv2。代码已经开源。欢迎大家提issue和star!
项目主页 : https://intellindust-ai-lab.github.io/projects/EdgeCrafter/
研究背景与动机
在资源受限的边缘设备上,目标检测、实例分割和姿态估计等密集预测任务长期由CNN架构(如YOLO系列)主导。虽然Vision Transformers(ViTs)在大规模场景下表现出色,但简单缩小模型规模会导致性能显著下降,甚至不如从头训练。小规模ViTs缺乏任务特定的表示学习,而非架构本身的缺陷。传统的ImageNet预训练对紧凑型ViT效果有限,这促使我们探索更高效的表征迁移方法。
解决方案
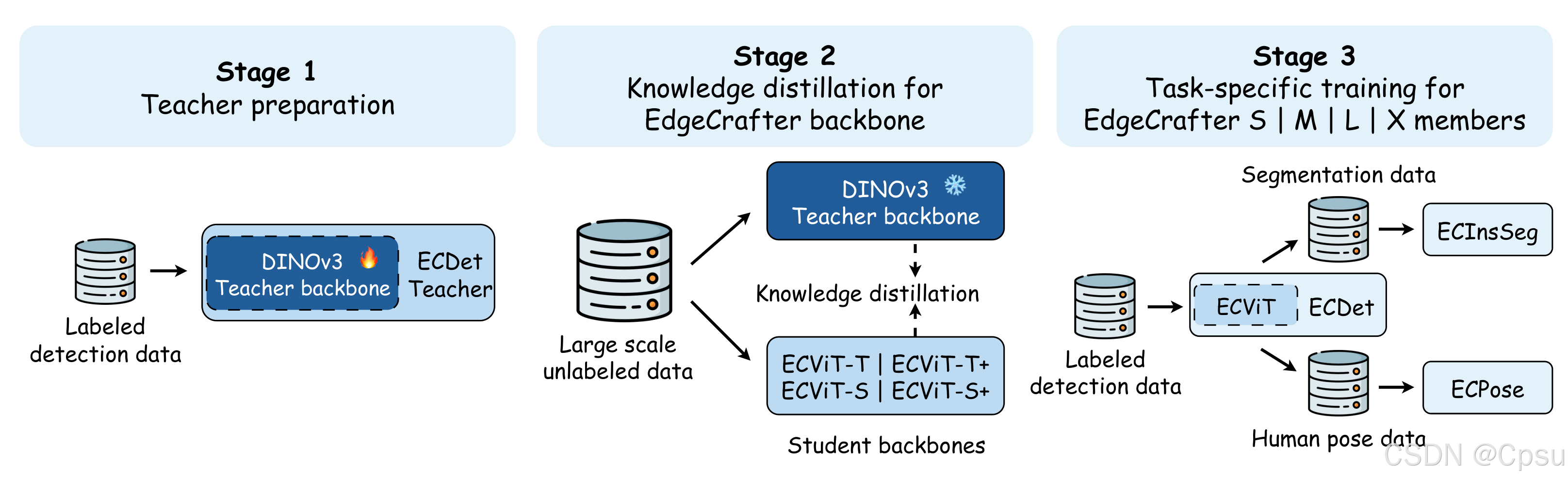
1. 任务特定蒸馏
- 将DINOv3大模型适配为目标检测任务,构建专门的教师模型
- 通过特征对齐,将教师网络的检测导向表征迁移到紧凑型学生网络(ECViT)
- 实验表明,教师模型容量需与学生匹配,过大反而降低迁移效果
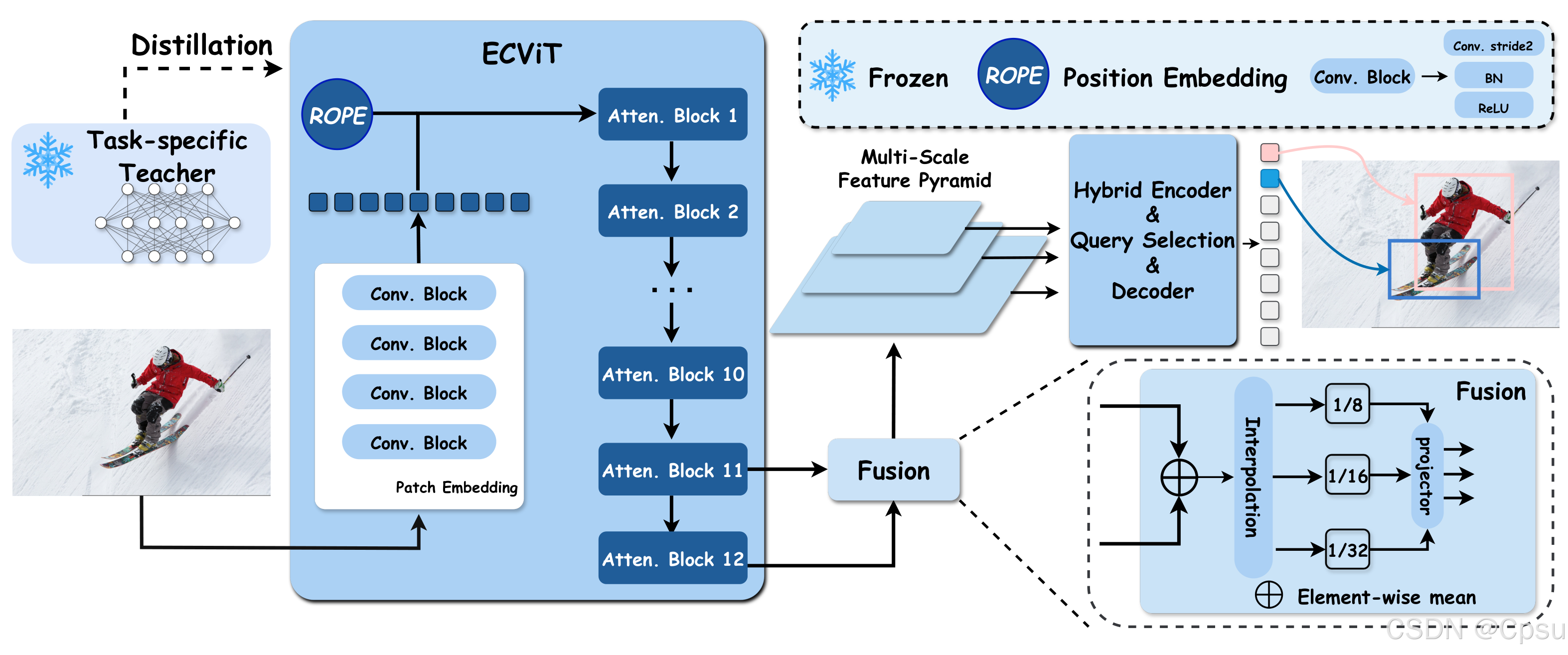
2. Real-Time Object Detection
- 采用卷积Stem替代传统Patch Embedding,更好地保留局部空间信息
- 通过简单插值和线性投影构建多尺度特征,避免复杂的特征金字塔网络
- 检测训练得到的骨干网络可直接复用于分割和姿态估计任务
实验结果
我们的方法ECDet / ECInSeg / ECPose在COCO数据集上结果:
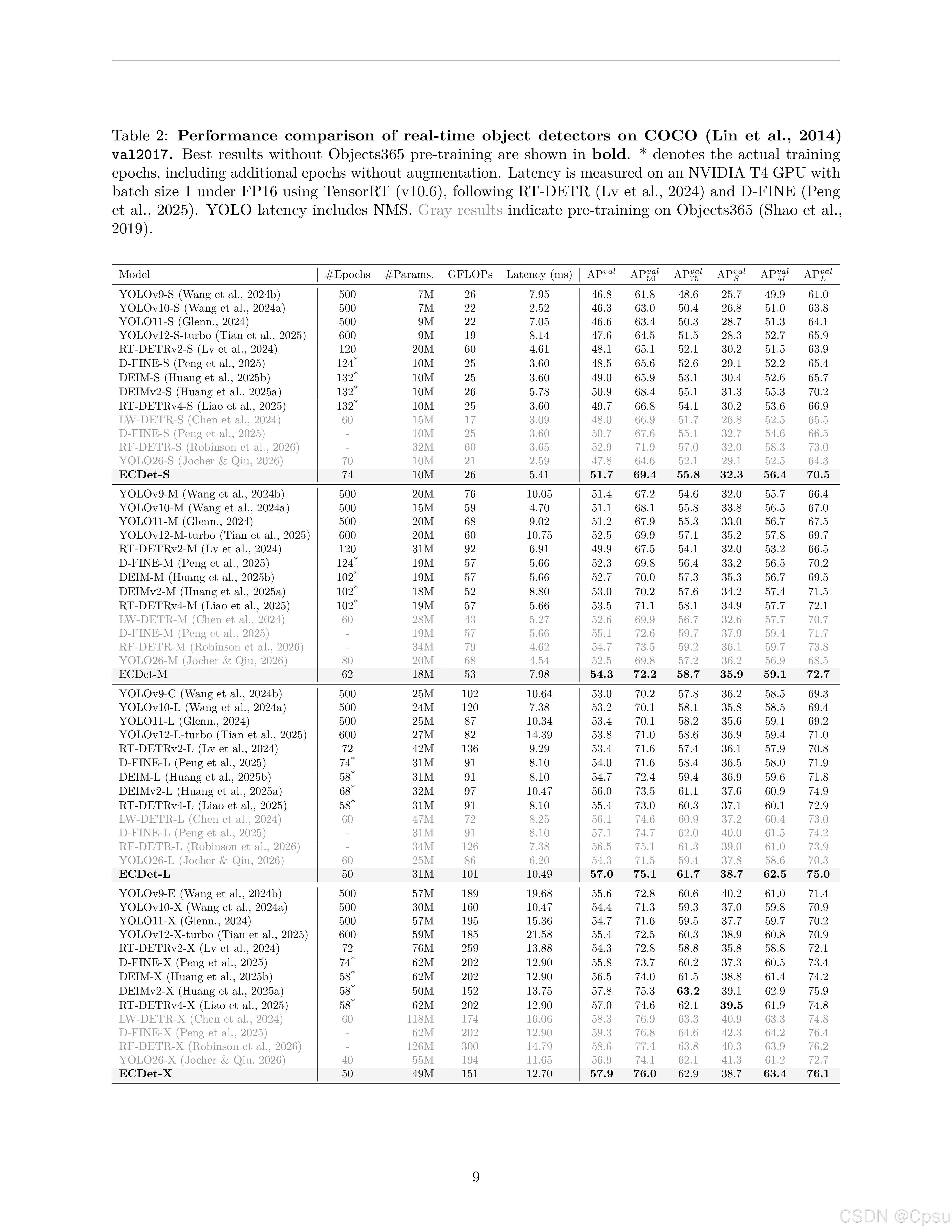
Object Detection(ECDet)
| Model | Size | AP50:95 | #Params | GFLOPs | Latency (ms) |
|---|---|---|---|---|---|
| ECDet-S | 640 | 51.7 | 10 | 26 | 5.41 |
| ECDet-M | 640 | 54.3 | 18 | 53 | 7.98 |
| ECDet-L | 640 | 57.0 | 31 | 101 | 10.49 |
| ECDet-X | 640 | 57.9 | 49 | 151 | 12.70 |
- ECDet-S(10M参数)达到51.7 AP,在不依赖Objects365预训练的情况下,与现有实时检测器相比具有竞争力
- 随着模型规模增大,ECDet-L/X在Latency上优势明显
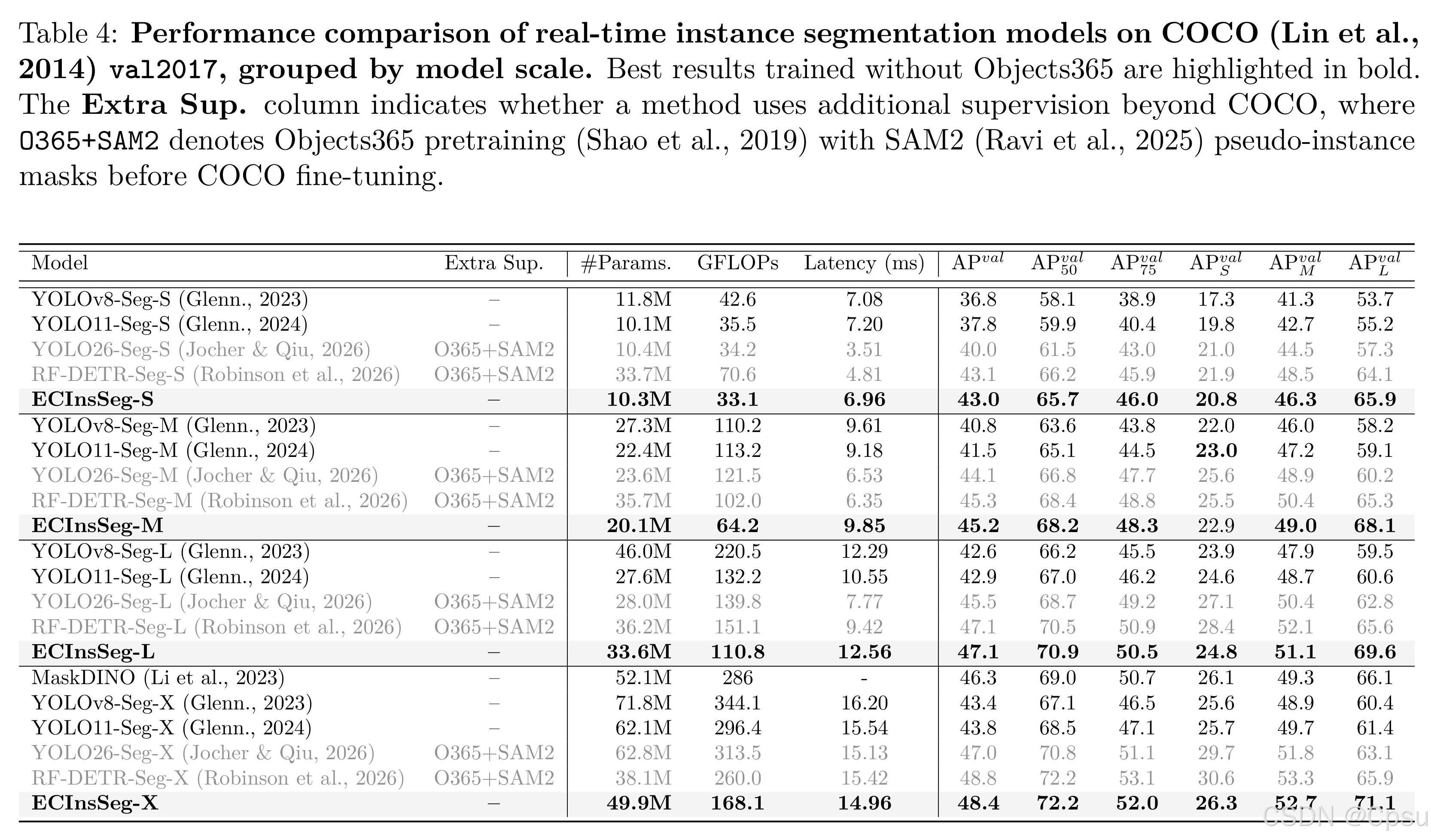
Instance Segmentation (ECInSeg)
| Model | Size | AP50:95 | #Params | GFLOPs | Latency (ms) |
|---|---|---|---|---|---|
| ECSeg-S | 640 | 43.0 | 10 | 33 | 6.96 |
| ECSeg-M | 640 | 45.2 | 20 | 64 | 9.85 |
| ECSeg-L | 640 | 47.1 | 34 | 111 | 12.56 |
| ECSeg-X | 640 | 48.4 | 50 | 168 | 14.96 |
- ECInsSeg-S(10.3M参数)达到43.0 AP
- 与RF-DETR-Seg-S相比,参数量减少约三分之二,性能接近
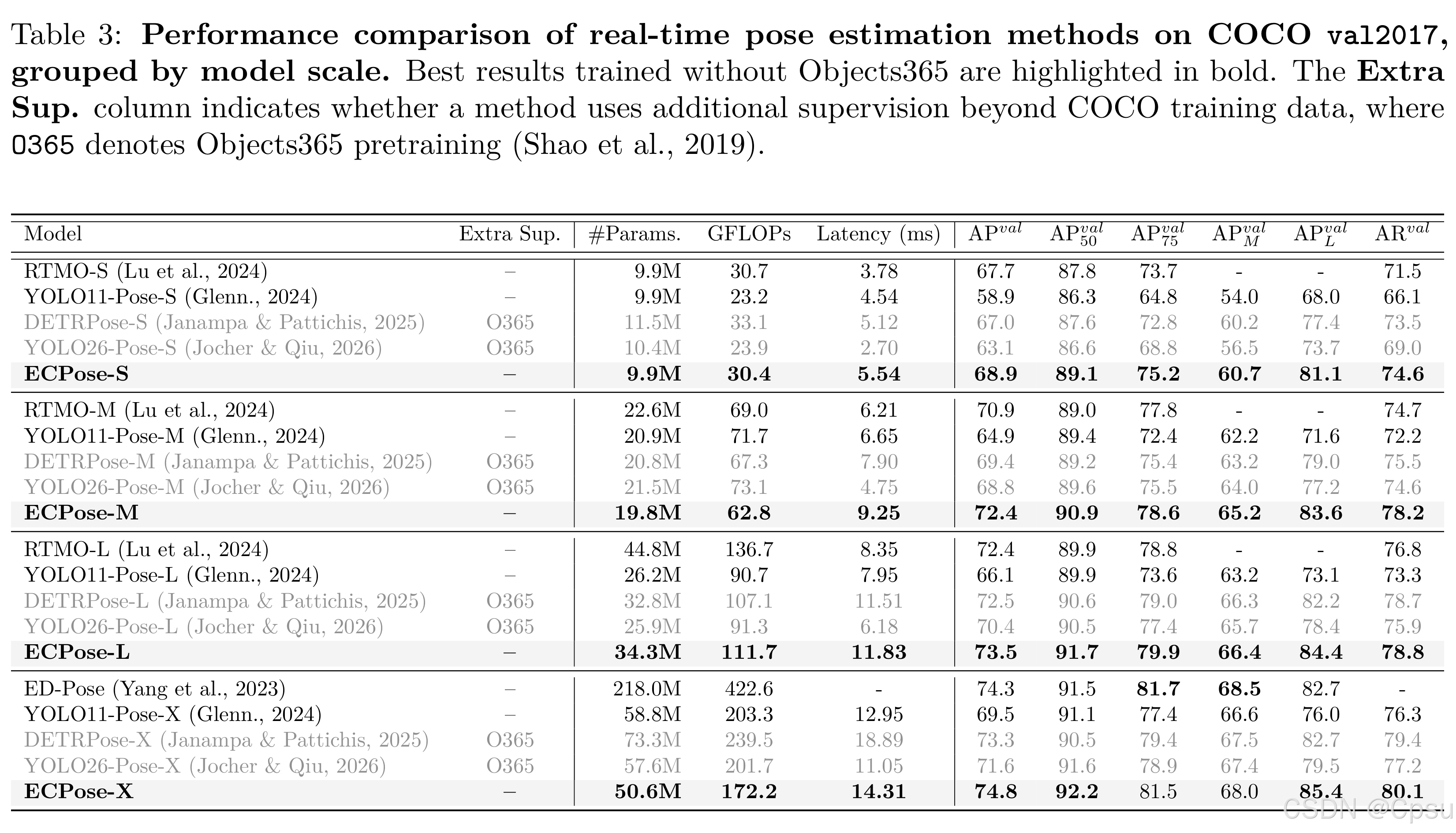
Pose Estimation (ECPose)
| Model | Size | AP50:95 | #Params | GFLOPs | Latency (ms) |
|---|---|---|---|---|---|
| ECPose-S | 640 | 68.9 | 10 | 30 | 5.54 |
| ECPose-M | 640 | 72.4 | 20 | 63 | 9.25 |
| ECPose-L | 640 | 73.5 | 34 | 112 | 11.83 |
| ECPose-X | 640 | 74.8 | 51 | 172 | 14.31 |
- ECPose-X达到74.8 AP,优于YOLO26-Pose-X(71.6 AP)
- 值得注意的是,YOLO26-Pose-X依赖Objects365预训练,而ECPose仅使用COCO数据
当前局限:
- 在NVIDIA T4 GPU上的推理延迟并非所有尺度都是最优,ViT架构的硬件优化仍有提升空间
- 需要特定的蒸馏训练流程,相比直接训练增加了前期准备步骤
总结
EdgeCrafter展示了通过任务专业化蒸馏和针对性架构设计,紧凑型ViTs能够在边缘密集预测任务中达到与CNN方案更优的性能表现。该方法为在资源受限环境中部署Transformer模型提供了一种可行的技术路径。