3.概率联邦神经匹配
基于贝叶斯非参机制的神经网络联邦学习
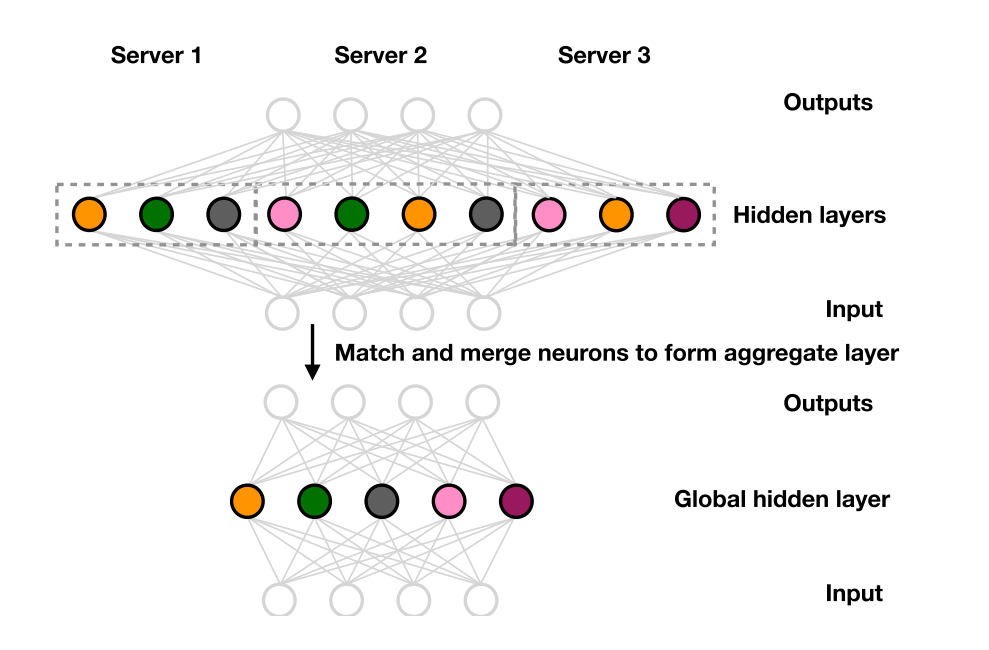
识别J个本地模型中对应匹配的神经元集合
基于这个些集合形成全局模型
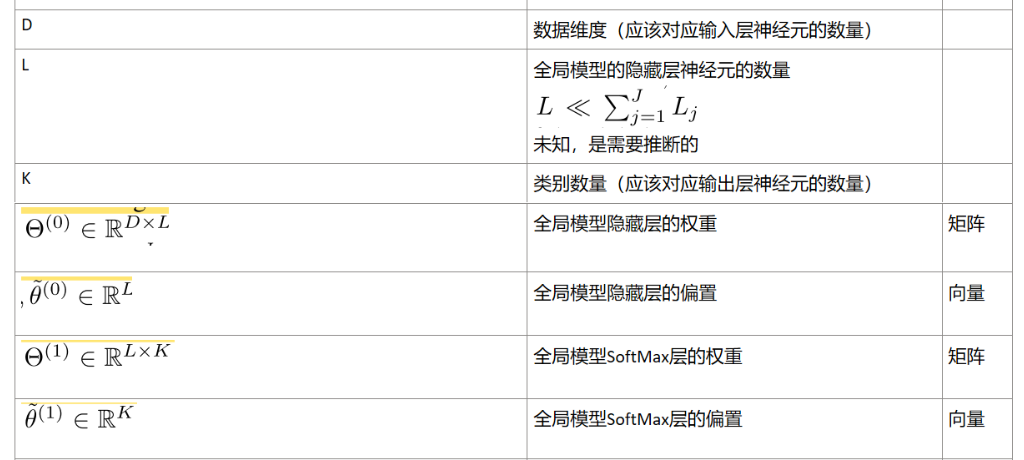
J个模型,每个模型是只有一层隐藏层的多层感知机:

目标训练模型:
利用隐藏层神经元置换不变性,改造与隐藏层有关的权重和偏置表示为无序集合:
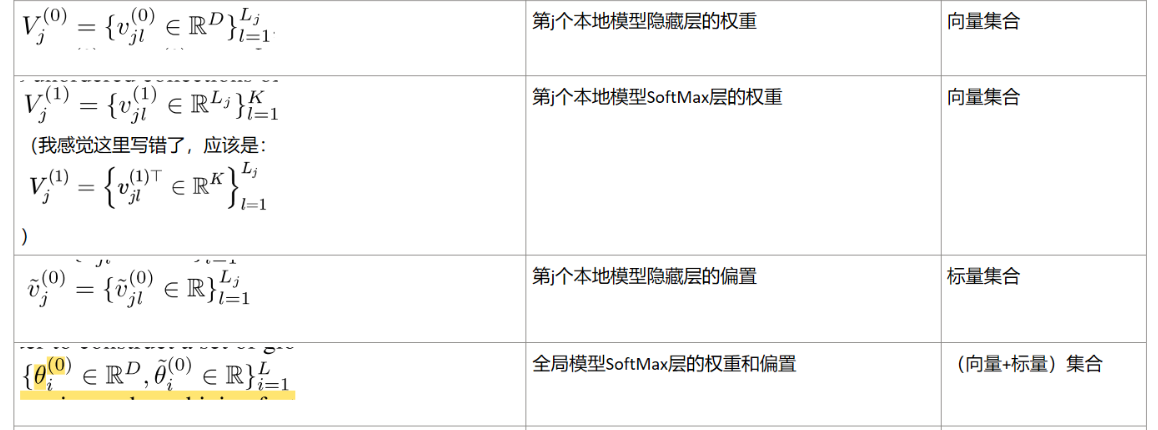
将隐藏层的神经元视作特征提取器:

由于J个本地模型实在相同的数据类型上训练的,因此作者猜测这些本地模型的隐藏层中有一些特征提取器的作用是相同的,是可以共享的。但是在没有做神经元匹配的传统联邦学习中,这些具有相同作用的特征提取器的位置一般不会一直,因此会影响全局聚合的效果。为此,需要对本地模型神经元的匹配和合并过程进行建模。
3.1.单层神经网络匹配
基于贝塔-伯努利过程的MLP权重参数模型
模型假设生成过程为:
-
从贝塔过程中获取全局模型隐藏层神经元的连接向量集合(称原子集合)

-
每个客户端模型通过伯努利过程从全局模型的原子集合中抽取一部分子集

-
为每个客户端的原子集合加噪(这就是在本地模型中观察到的权重偏置数据)

我们要推断表示匹配客户端模型原子和全局模型原子的随机变量集合:

目标函数为最大化后验估计:

这里利用一个命题结论:
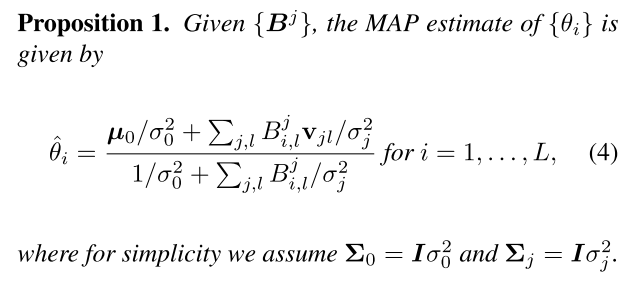
利用这个结论可以把MAP目标函数转变为只关于{Bj}j=1J\left\{\boldsymbol{B}^{j}\right\}_{j=1}^{J}{Bj}j=1J的目标函数:
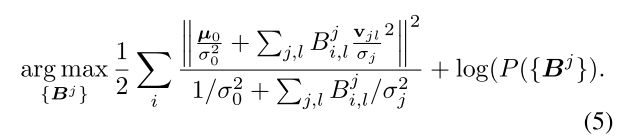
现在直接求解难题入手,因此可以采用迭代优化方法:
- 在{Bj}j=1J\left\{\boldsymbol{B}^{j}\right\}_{j=1}^{J}{Bj}j=1J中,固定除了某个矩阵Bj\boldsymbol{B}^{j}Bj的所有矩阵变量,找到Bj\boldsymbol{B}^{j}Bj的最优解
- 随机挑选一个其他的矩阵进行同样的优化,不断进行这样的操作直到收敛
这里规范一下变量表示:


在找Bj\boldsymbol{B}^{j}Bj的最优解的时候,去掉和Bj\boldsymbol{B}^{j}Bj无关的项,并运用∑lBi,lj∈{0,1}\sum_{l} B_{i, l}^{j} \in\{0,1\}∑lBi,lj∈{0,1}的性质,改造目标函数:
| 前半部分 | 后半部分 |
|---|---|
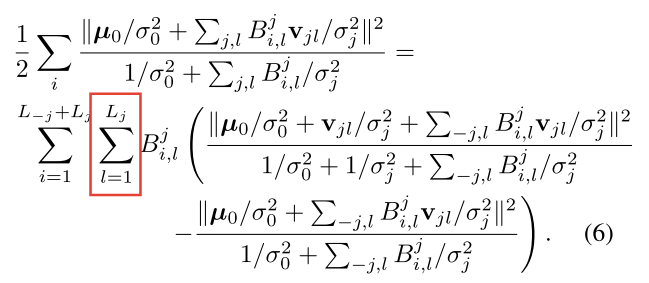 |
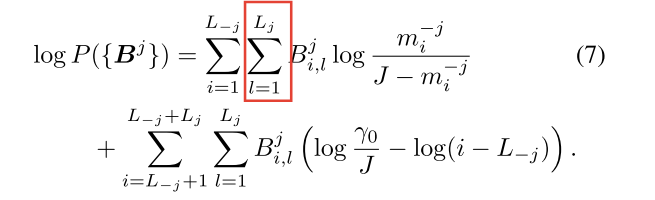 |
注:

结合目标函数的两部分可以得到分配成本
MAP:越大越好
对于每个l对应的部分:越大越好,取反就是越小越好,可以作为成本

然后可以用匈牙利算法求解,通过最小化总成本来获取神经元匹配指派