- 开发语言:Python
- 框架:flask
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页
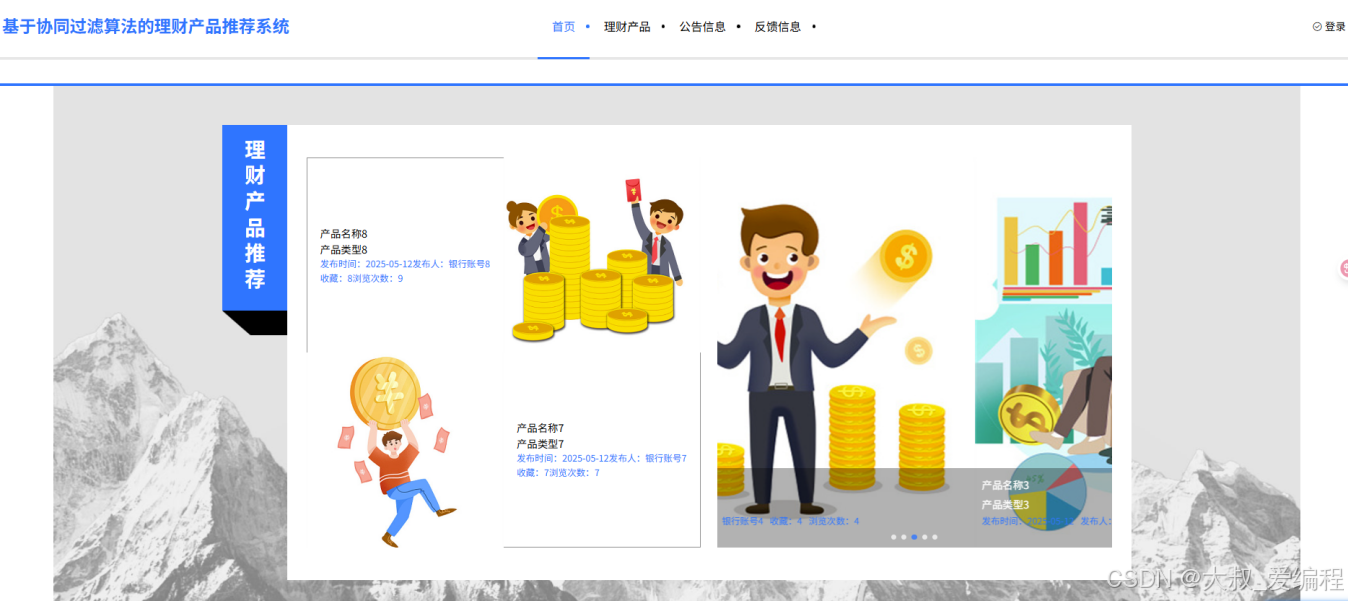
推荐算法
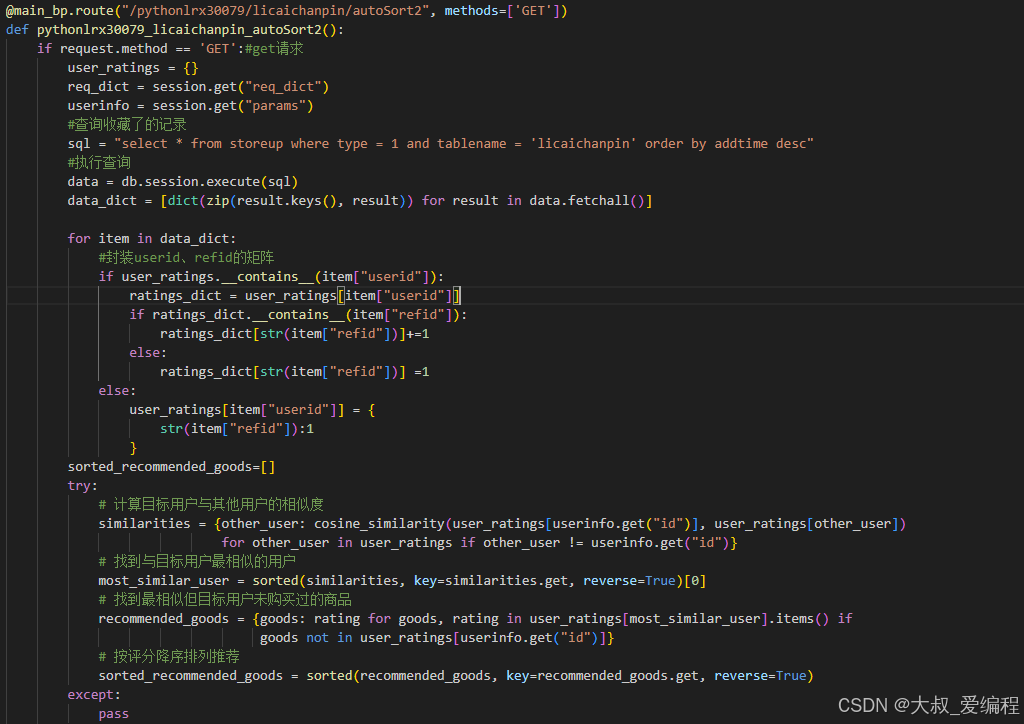
用户登录
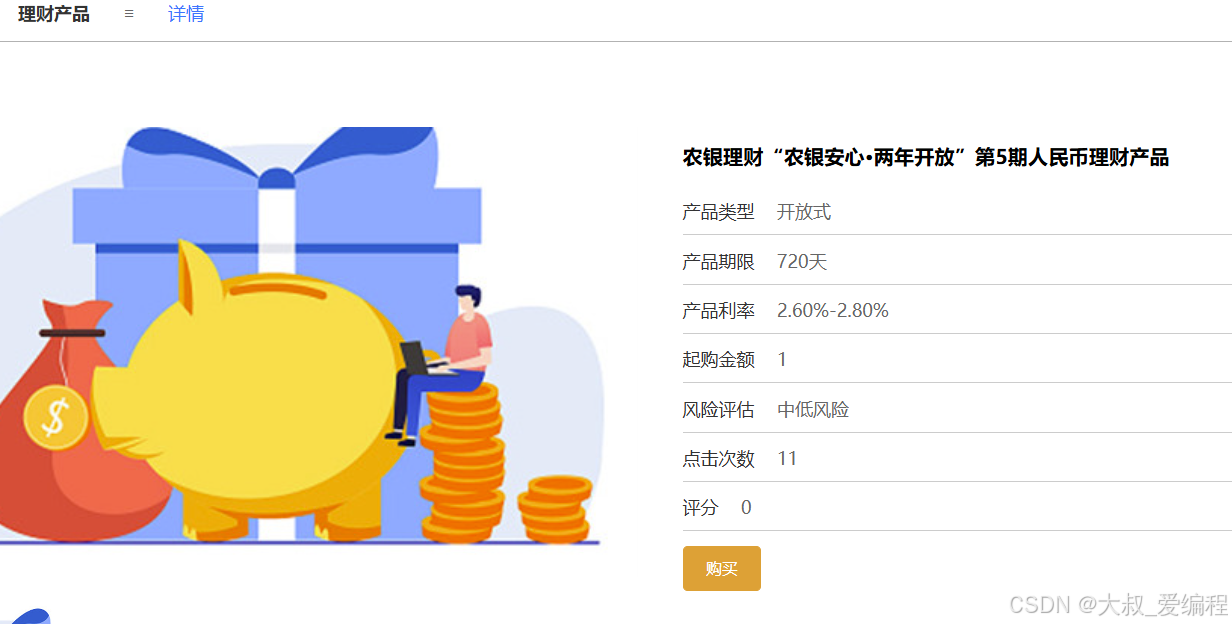
理财产品
个人中心
管理员登录
管理员功能界面
用户管理
理财产品管理
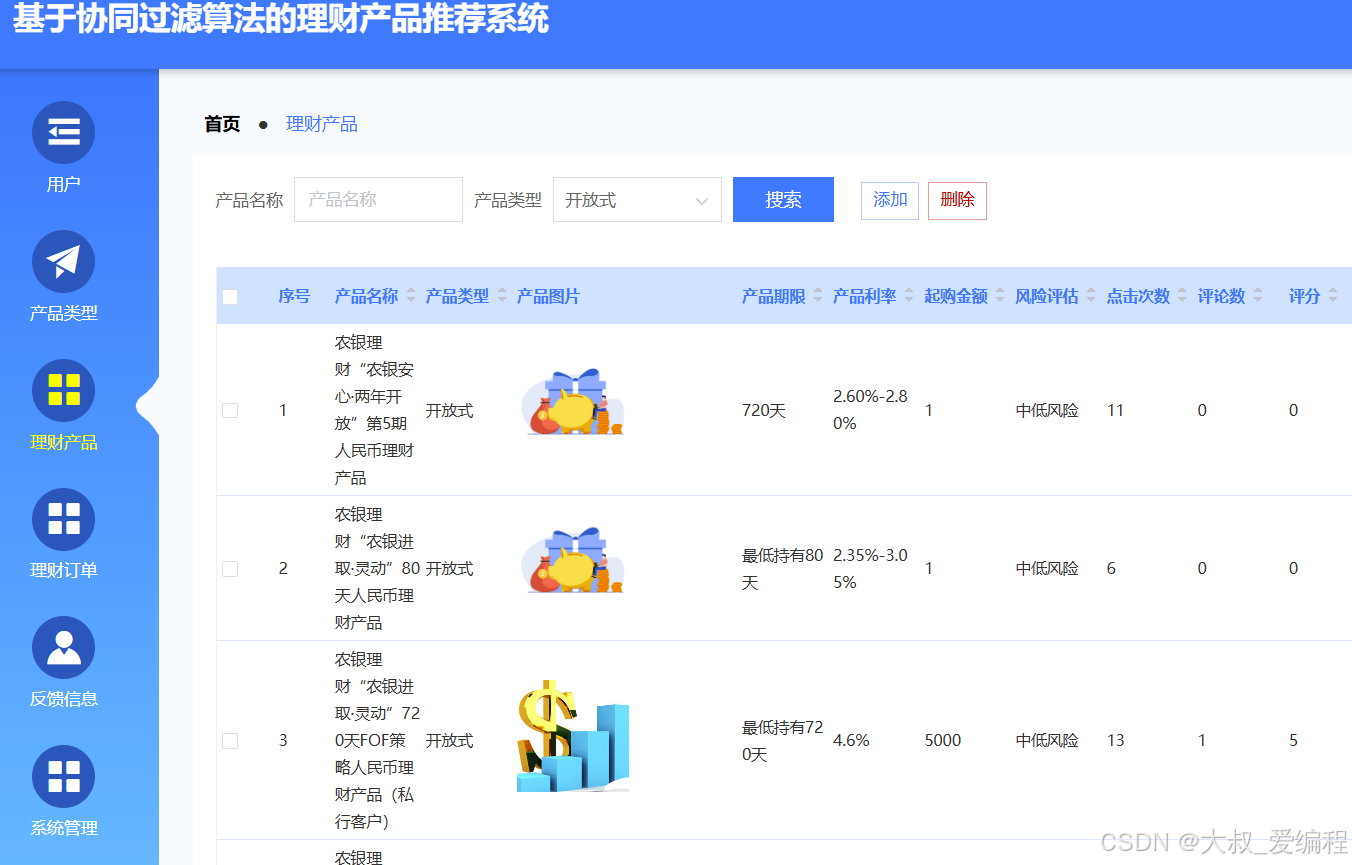
理财订单
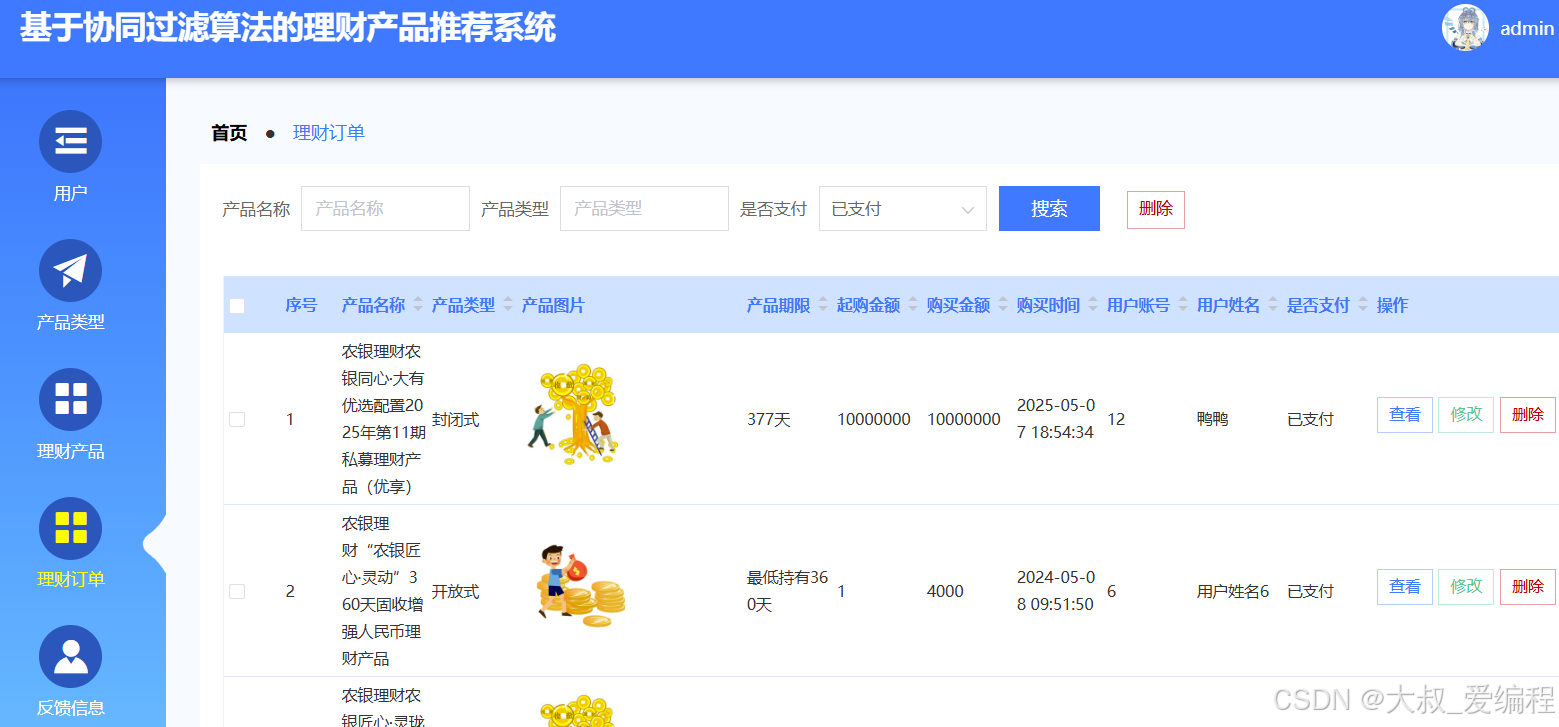
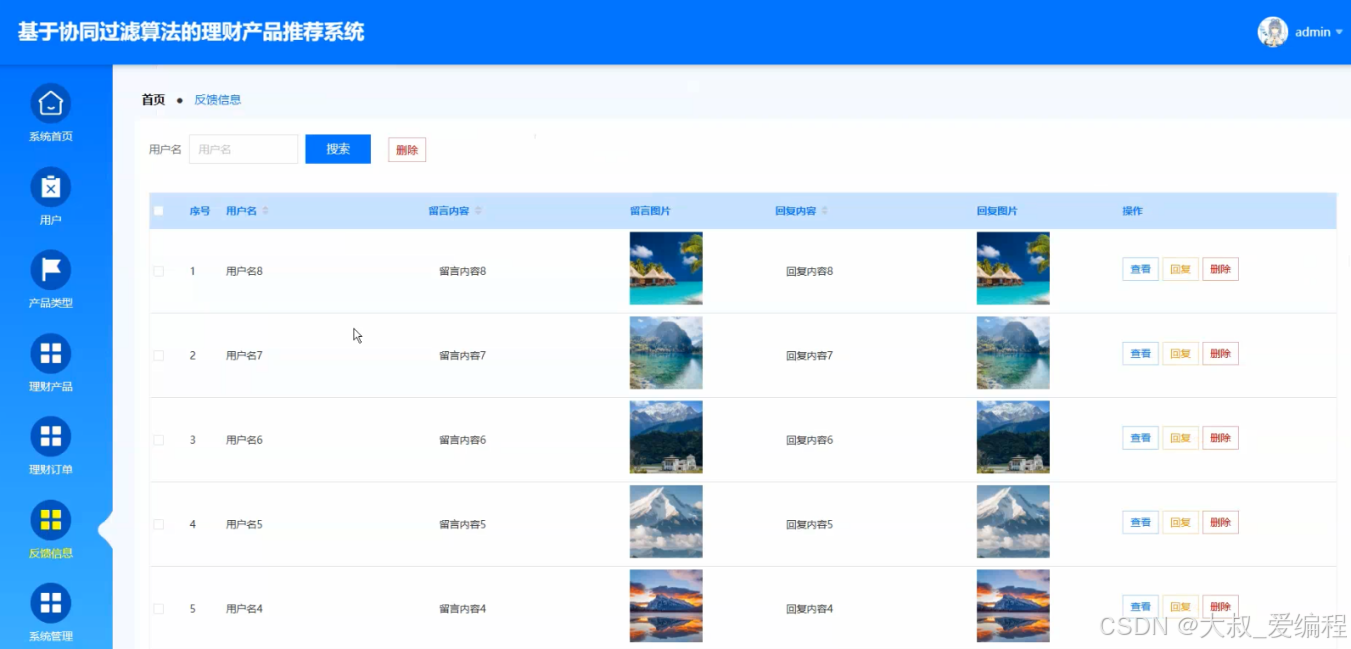
反馈信息
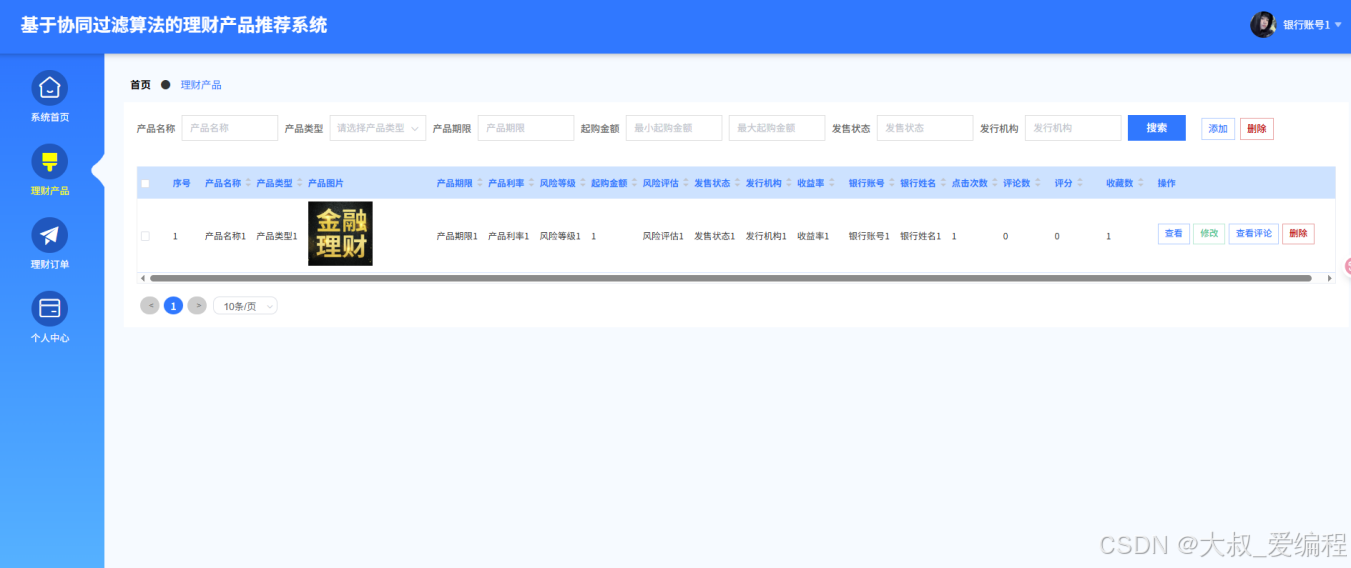
产品经理功能界面
摘要
在设计这款基于协同过滤算法的理财产品推荐系统时,我始终秉持着易用性、高性能与功能全面的原则。平台不仅涵盖了用户、产品类型、理财产品、理财订单、反馈信息等基础功能,为用户提供更加丰富、便捷的使用体验。我坚信,通过我的不懈努力,这款平台定能以其实用性、高效性和创新性,赢得广大用户的青睐与认可,成为理财产品推荐管理领域的佼佼者。
研究背景
传统的管理手段逐渐显露出其局限性,尤其是在面对日益增长的信息管理需求时,传统方式不仅工作量大,而且极易出错,对于理财产品、公告信息、反馈信息等的管理更是需要投入大量的人力资源,进行单调且重复的操作,这些错误往往难以被及时发现,给管理工作带来了极大的挑战。面对这一现状,各平台迫切需要寻找一种更加高效、便捷的管理方式。开发一个基于协同过滤算法的理财产品推荐系统显得尤为迫切和必要。借助Django框架的强大功能以及Windows系统的广泛普及,旨在将传统的线下理财产品推荐管理模式转化为线上管理模式,从而极大地提升交易效率和管理便利性。
平台的开发与应用,不仅为用户提供了更加便捷、高效的理财产品推荐服务,同时也为管理员提供了强大的管理工具,使得整个平台的管理更加科学化、规范化。我相信,随着该平台的推广与使用,将有力推动平台的繁荣发展,为广大用户提供更加优质、便捷的理财产品推荐管理服务。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Flask是一个使用Python编写的轻量级Web应用框架。它被称为一个"微框架"(microframework),因为它只提供Web应用所需的最核心的功能,如路由、会话管理和模板引擎等,而不像一些更全面的框架那样包含数据库层、表单处理等功能。然而,Flask的扩展生态系统非常丰富,开发者可以通过添加扩展来为Flask应用添加这些额外的功能。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
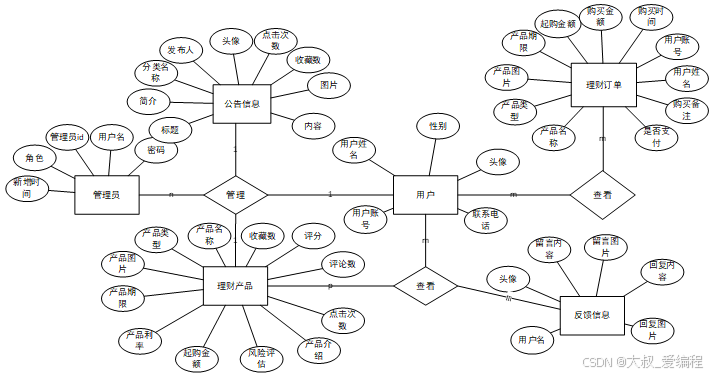
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
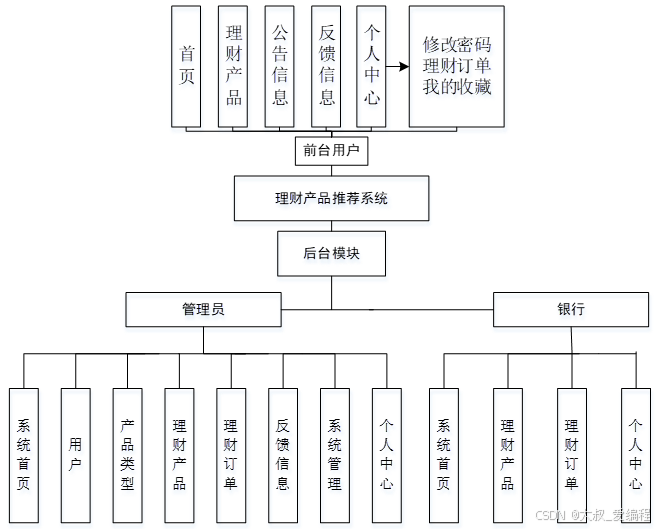
系统实现
首页理财产品的推荐采用的是协同过滤推荐算法。该算法通过分析用户的历史行为和偏好,识别出用户之间或理财产品之间的相似性,从而为用户提供个性化的推荐。具体而言,系统会根据用户过去的选择和评分,预测其可能感兴趣的理财产品。这种推荐方式能够有效根据用户的兴趣和行为模式,推测出其对其他尚未接触过的产品的潜在兴趣,从而提高推荐的准确性和相关性。当用户点击理财产品页面时,可以在搜索栏中输入产品名称、产品类型等具体信息来进行搜索。搜索结果将展示理财产品的相关信息;还可以点击购买、收藏或者评论等操作;
管理员登录系统后,可以访问并管理系统首页、用户、产品类型、理财产品、理财订单、反馈信息、系统管理、个人中心等各项管理功能,并对这些内容执行具体的操作和管理任务。理财产品经理端的管理界面,主要包含理财产品展示与操作功能。顶部显示系统名称和当前菜单位置,中部为理财产品表格,列明产品名称、类型、期限、金额范围、发行状态及机构等关键信息。底部提供搜索、添加和删除功能按钮,支持经理快速查找和管理产品。右侧展示理财信息概览和个人中心入口,整体布局清晰,功能齐全,便于高效管理理财产品。
代码实现
python
#计算相似度
def cosine_similarity(a, b):
numerator = sum([a[key] * b[key] for key in a if key in b])
denominator = math.sqrt(sum([a[key]**2 for key in a])) * math.sqrt(sum([b[key]**2 for key in b]))
return numerator / denominator
#收藏协同算法
@main_bp.route("/pythonlrx30079/licaichanpin/autoSort2", methods=['GET'])
def pythonlrx30079_licaichanpin_autoSort2():
if request.method == 'GET':#get请求
user_ratings = {}
req_dict = session.get("req_dict")
userinfo = session.get("params")
#查询收藏了的记录
sql = "select * from storeup where type = 1 and tablename = 'licaichanpin' order by addtime desc"
#执行查询
data = db.session.execute(sql)
data_dict = [dict(zip(result.keys(), result)) for result in data.fetchall()]
for item in data_dict:
#封装userid、refid的矩阵
if user_ratings.__contains__(item["userid"]):
ratings_dict = user_ratings[item["userid"]]
if ratings_dict.__contains__(item["refid"]):
ratings_dict[str(item["refid"])]+=1
else:
ratings_dict[str(item["refid"])] =1
else:
user_ratings[item["userid"]] = {
str(item["refid"]):1
}
sorted_recommended_goods=[]
try:
# 计算目标用户与其他用户的相似度
similarities = {other_user: cosine_similarity(user_ratings[userinfo.get("id")], user_ratings[other_user])
for other_user in user_ratings if other_user != userinfo.get("id")}
# 找到与目标用户最相似的用户
most_similar_user = sorted(similarities, key=similarities.get, reverse=True)[0]
# 找到最相似但目标用户未购买过的商品
recommended_goods = {goods: rating for goods, rating in user_ratings[most_similar_user].items() if
goods not in user_ratings[userinfo.get("id")]}
# 按评分降序排列推荐
sorted_recommended_goods = sorted(recommended_goods, key=recommended_goods.get, reverse=True)
except:
pass
L = []
#按评分顺序查询要推荐列表(当前用户收藏关注过的同类型优先)
where = " AND ".join([f"{key} = '{value}'" for key, value in req_dict.items() if key!="page" and key!="limit" and key!="order"and key!="sort"])
if where:
sql = f'''SELECT * FROM (SELECT * FROM licaichanpin WHERE {where}) AS table1 WHERE id IN ('{"','".join(sorted_recommended_goods)}') union all SELECT * FROM (SELECT * FROM licaichanpin WHERE {where}) AS table1 WHERE id NOT IN ('{"','".join(sorted_recommended_goods)}')'''
else:
sql ="select * from licaichanpin where id in ('%s"%("','").join(sorted_recommended_goods)+"') union all select * from licaichanpin where id not in('%s"%("','").join(sorted_recommended_goods)+"')"
#执行查询
data = db.session.execute(sql)
#封装结果
data_dict = [dict(zip(result.keys(), result)) for result in data.fetchall()]
for online_dict in data_dict:
for key in online_dict:
if 'datetime.datetime' in str(type(online_dict[key])):
online_dict[key] = online_dict[key].strftime(
"%Y-%m-%d %H:%M:%S")
elif 'datetime' in str(type(online_dict[key])):
online_dict[key] = online_dict[key].strftime(
"%Y-%m-%d %H:%M:%S")
else:
pass
L.append(online_dict)
#返回封装的json结果
return jsonify({"code": 0, "msg": '', "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":5,"list": L[0:int(req_dict['limit'])]}})系统测试
在程序投入使用之前,进行测试工作是不可或缺的环节,这是为了确保程序的可靠性,防止在实际运行中发生不必要的错误。通过测试,可以进一步提升程序的品质、完善度和稳定性。测试工作在程序开发中占据至关重要的地位,作为开发流程的最终阶段,它扮演着极为关键的角色。尽管开发者在编写代码时会力求严谨和细致,但仍难以完全避免错误的出现。事实上,任何程序在开发过程中都可能潜藏一些难以直观察觉的错误,这些错误需要借助测试手段才能被有效识别。测试的主要目标就是检测程序中的问题,进而修正错误,这一过程需要反复进行,不断发现并解决问题。可以说,只有通过测试验证的程序,才能放心地投入使用。
结论
此次系统从整体看来,已基本达到预期的设计目的,能够实现基本的功能,但相较于市场的一些优秀系统而言,还是有许多不足的地方。遗憾的是,由于时间的有限,已经不允许再投入更多的时间和精力进行研究开发。相信在以后的工作中,我会接触到更多相关的知识,会更丰富自身的经验,我希望到时能够在此基础上完成一个丰富完整的系统,这将对我有很大的意义。
通过这次的毕业设计,我学到了很多,除了学识方面的知识,在态度上也有了很大的转变,细心和耐心是整个开发过程中最重要的两件事。我也在跟随着系统的完善而成长,这次毕业设计考核地也不单单是所学的知识,也同样在衡量着面对困难时的态度。