前言:本来想发下一篇,结果先把"配图判断"做成了一个 skill
大家好呀,我又回归掘金了(没法,前端可能快失业了,先找回状态,懂的都懂 ^_^)
这段时间给自己做了一点小调整:少焦虑,多沉淀。AI 来得很快,我并不排斥------它确实帮我补上了不少短板,也把很多又碎又慢的事情提速了。
⏱️ 预计阅读时间:12 分钟
📖 读这篇,你可以了解到什么
| # | 你会了解到 | 对应章节 |
|---|---|---|
| 1 | 为什么"配图决策"比"生图工具"更重要 | 一、二、三 |
| 2 | 一个 skill 是怎么从真实卡点里长出来的 | 四 |
| 3 | 6+1 配图分类法:每种图该在什么时候用 | 五 |
| 4 | 一张可以直接复用的文章配图执行表 | 六 |
| 5 | 封面题图的 brief 怎么写,才不会出"AI 科幻海报" | 七 |
| 6 | 从"用工具"到"定义工具",这一步怎么迈 | 八、九 |
本来准备先发另一篇:《我把 OpenAI 官方三篇 Codex 指南读完了,整理成这一篇》。结果写着写着,被一个看似很小的问题卡住了:
这篇文章到底该怎么配图?
是配 3 张还是 5 张?哪些地方需要截图?哪些地方更适合画结构图?哪些地方其实根本不该有图?题图该怎么做,才既有主题感,又不至于太跑偏?
与其空谈,不如先把这个问题走一遍。既然下一篇就真实需要一套配图方案,那不如索性把这个过程沉淀成一个可复用的 skill。
于是,这篇文章就诞生了。你看到这篇的配图也是我用该 skill 生成的------这就是最好的证明不是?
先给大家看看效果:
仓库已经放到 GitHub 了:Fridolph/article-visual-planning
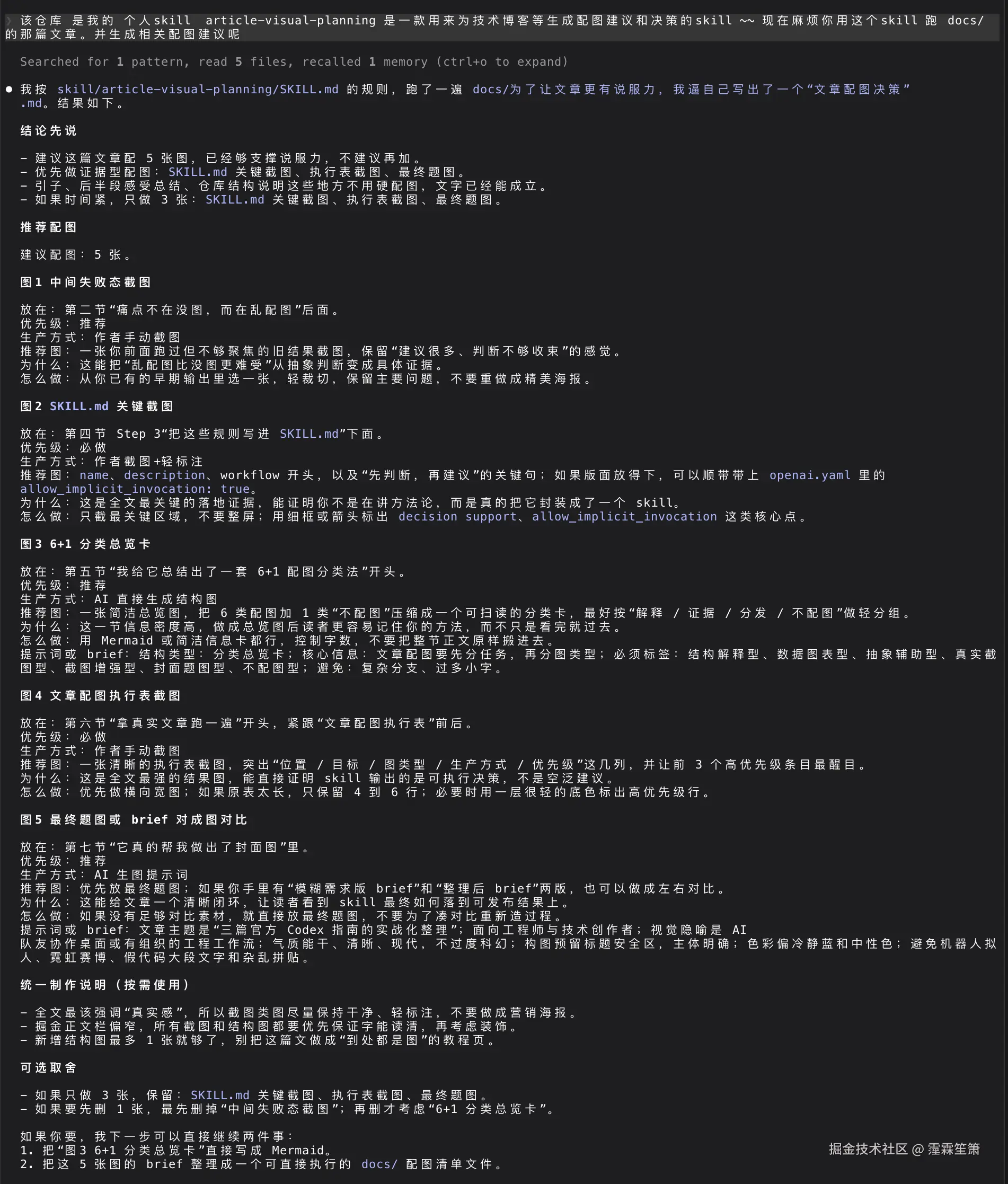
还在完善中,需要自提或者提issue ~
一、起因很简单:我只是想给文章配几张图
事情一开始真的非常朴素------给 Codex 长文做一张封面图,再配上几张正文插图,整体观感更完整,读起来也更轻松。
所以我最初的需求,大概就是:
- 1 张封面图
- 几张正文配图
看起来很简单,对吧?
但只要真的开始做,就会发现问题根本不是"有没有图",而是图到底该怎么存在。
- 到底配几张才合适?
- 哪些段落值得配图,哪些其实不需要?
- 每张图承担的是解释作用、证据作用,还是只是辅助节奏?
- 哪些内容适合 AI 直接生成?哪些内容反而必须自己截图?
我中间试过几个现成的 skill,也跑出过一些结果。但慢慢发现,那些结果的问题不在于"完全没用",而在于它们更偏向"帮你往前生成",却没有先帮你把判断做扎实。
换句话说,它们很容易回答:可以配什么图。
但我真正需要的是:这段到底要不要配图?如果要,这张图最应该承担什么作用?
这两者看起来只差一点点,实际差很多------前者偏执行,后者偏决策。
二、痛点不在没图,而在乱配图
这次写到一半时,最大的感受非常简单:
不是文章没图很难受,而是图配错了更难受。
很多时候我们会天然觉得"有图总比没图好"。尤其在 AI 把生图门槛降得这么低的情况下,最容易出现的幻觉就是:反正出图已经不贵了,那就多来几张。(就像买了个无限子弹的枪,结果把自己脚打了)
但真正把图放进文章里之后你会发现,事情完全不是这样。
这次在整理 Codex 那篇长文时,我就很明显地遇到了几类完全不同的情况:
| 位置 | 最适合的图类型 | 原因 |
|---|---|---|
Plan 模式 |
真实截图 | 很多读者没见过这个界面,解释再多不如一眼看到 |
AGENTS.md |
真实截图 | 概念抽象,一张文件截图理解门槛直接降下来 |
Skills + Shell + Compaction |
结构图 | 重点是三者关系,不是某个界面 |
/review |
真实截图 + 轻标注 | 需要证明"真的能用",抽象图没有说服力 |
| 文章头图 | 封面题图 | 承担传播入口职责,不能混进正文插图逻辑 |
也就是说,文章配图这件事,根本不是"帮我多出几张图",而是先判断:这里值不值得配图、这张图是拿来解释还是证明、该由 AI 生成还是作者亲自处理。
当这些问题想清楚之后,后面的 prompt、生图、截图,反而变成了相对容易的一步。
三、我想要的不是生图器,而是一个"配图决策辅助"
我真正想做的,并不是一个"给文章生成配图"的 skill。
如果只是生成图片,那其实已经有很多工具在做了。它们不是没用,只是它们默认把问题理解成了"怎么出图更快"。
可我这次碰到的问题,核心根本不在"出图快不快"。核心在于:这篇文章,哪些地方真的值得可视化?这些可视化承担的到底是解释功能、证据功能,还是传播功能?
如果这一步判断错了,后面 prompt 写得再漂亮,图出得再快,也只是把错误更高效地放大。
所以我后来给这个 skill 的定位,就定成了一句话:
它不是一个"直接帮你生成图片"的 skill,而是一个"文章配图决策辅助"的 skill。
它首先做的不是"产图",而是"判断"------
- 这段到底要不要配图?
- 如果要配,这张图最主要的任务是什么?
- 更适合结构图、图表、抽象辅助图,还是真实截图?
- 应该由 AI 直接生成,还是应该由作者自己截图处理?
- 如果只是为了"看起来丰富一点",那这张图是不是其实可以不要?
这一点让我第一次更明确地感受到:
AI 时代里,很多场景真正稀缺的,不是执行能力,而是前面的判断能力。执行越来越便宜,判断反而越来越值钱。
四、这个 skill 是怎么长出来的
这个 skill 不是我坐下来规划好的,它更像是在解决真实问题的过程中,一点点长出来的。
Step 1:把模糊需求压成一句清晰的问题
最开始的原始需求非常散:给文章做几张图、题图好看一点、正文别太干......
这种说法放在脑子里没问题,真要交给 AI,就会很容易跑偏。
所以我做的第一件事,不是写 skill,而是先把问题压缩成一句更清楚的话:
这篇文章,哪里该配图,配什么图,怎么最稳地把图做出来?
这句话里已经隐含了 3 层判断,而且这 3 层是有顺序的------如果第一层没判断好,后面两层做得越努力,偏差反而越大。
Step 2:从真实文章里把规则归纳出来
问题说清楚之后,不是空想,而是回到那篇正在写的 Codex 长文里,一段一段去看。
也就是在这个过程中,一些比较稳定的判断开始浮现出来了(就是上面那张表)。
好的 skill 不是靠脑补设计出来的,而是从真实工作流里长出来的。
Step 3:把这些规则写进 SKILL.md
当规则开始变清楚之后,才轮到真正写 skill。
这里最大的感受是:SKILL.md 最重要的,不是写得多,而是写得准。
尤其是 name 和 description,它们几乎决定了这个 skill 会不会被正确理解、会不会在对的时候触发。
所以我没有把它写成一种"很会生成图"的描述,而是写成一种"先判断,再建议"的描述。
对应到 agents/openai.yaml,配置长这样:

allow_implicit_invocation: true 这一行挺关键的------它让 agent 在你粘贴文章草稿时,能自动判断"这个时候应该调用配图规划 skill",而不是每次都要手动触发。
Step 4:整理成可复用的仓库结构
如果只是自己本地临时用一下,写完 SKILL.md 也差不多能用了。但我后面还是把它整理成了更完整的仓库结构,补了双语 README、examples、references------因为一旦准备公开,你就必须把那些原本只存在于自己脑子里的默契,转成别人也能读懂的东西。
从那一刻开始,你不再只是"用工具的人",而是在慢慢变成"定义工具的人"。(这个感觉,有点像从看番到自己写同人文的那种转变 🤣)
五、我给它总结出了一套 6+1 配图分类法
当我把前面的真实判断整理出来之后,后面最自然的一步,就是给这些判断起名字。
这次总结出来的,是一套 6+1 配图分类法。
之所以说是 6+1,是因为我把**"不要配图"也单独算成了一类**------真正成熟的配图建议,不是"尽量给你多配几张图",而是能明确告诉你:这里不用图,反而更好。
好的建议应该包含克制。
对应到 references/illustration-taxonomy.md 里的判断逻辑:
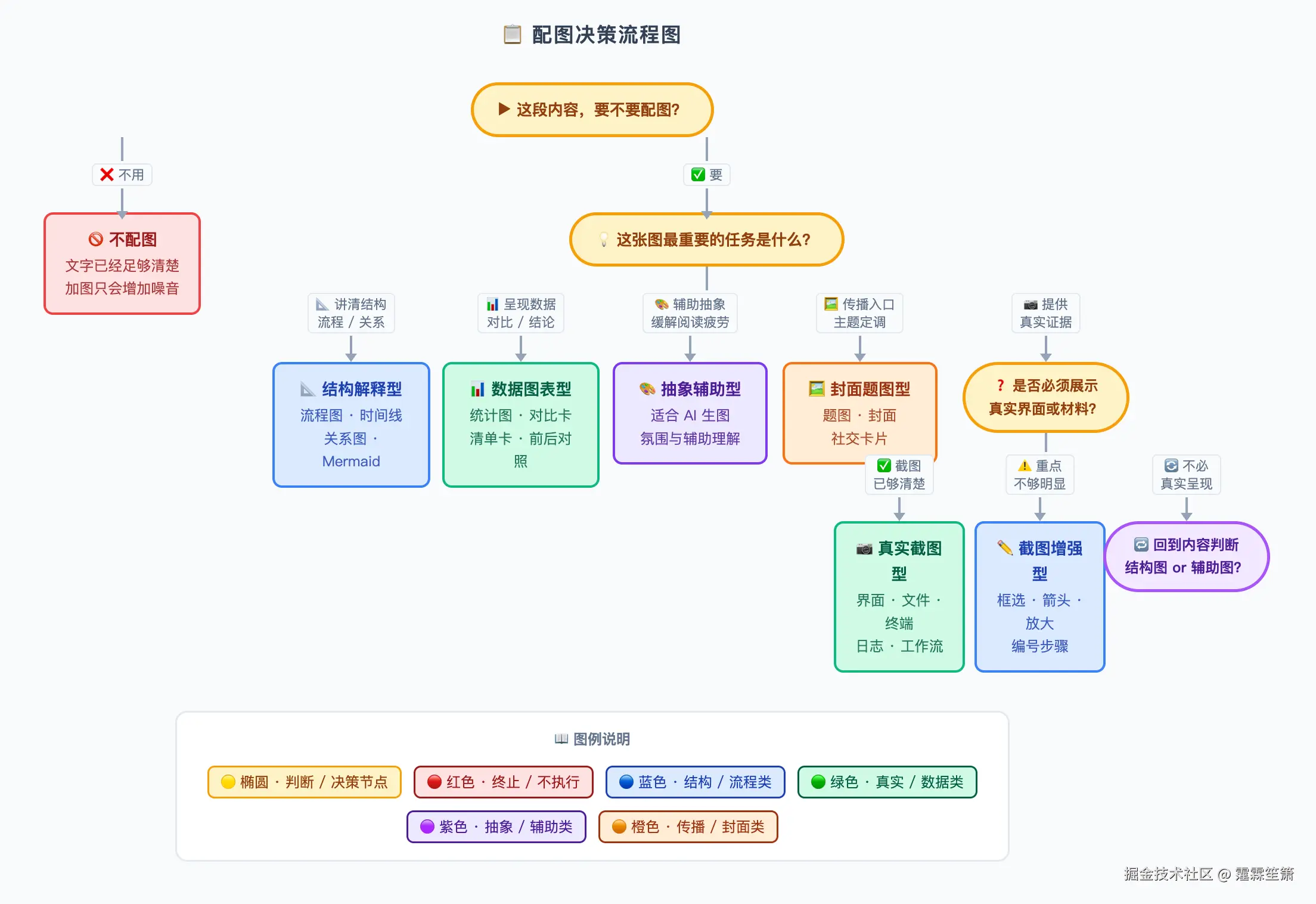
| 文章信号 | 最适合的图类型 | 原因 |
|---|---|---|
| 多步骤工作流 | 结构解释型(Diagram-first) | 顺序比文字更清晰 |
| 工具对比 | 结构解释型 / 数据图表型 | 矩阵或评分卡更好扫读 |
| 抽象概念 / 思维转变 | 抽象辅助型(Generative) | 辅助氛围,不需要当证据 |
| 真实产品演示 | 真实截图型 | 真实感比精致感更重要 |
| 截图存在但焦点不清 | 截图增强型 | 引导读者看到重点 |
| 数据 / 排名 / 前后对比 | 数据图表型 | 读者需要结构化证据 |
| 文章头图 / 分发卡片 | 封面题图型 | 主要任务是发现和定调 |
| 短小具体的段落 | 不配图型 | 加图只会增加噪音 |
0. 不配图型
这段文字本身已经足够清楚、主要承担过渡作用、加图只会打断节奏------那就不加。
如果一个 skill 永远都在建议"这里也可以加一张图",那它大概率还不够成熟。
1. 结构解释型
最适合交给 AI 助手直接生成的一类。
适用场景:流程讲解、架构关系、步骤拆解、多概念之间的联系。
常见形式:流程图、思维导图、时间线、Mermaid 图。
比如 Skills + Shell + Compaction 这一段,讲的是三者如何协同工作,用 Mermaid 直接画出来:
对应的 diagram brief 模板:
yaml
Diagram type: flowchart LR
Core message: Skills 负责保存可复用流程,Shell 负责执行,Compaction 负责控制长任务上下文
Required nodes: Skills、Shell、Compaction、Long-running workflow
Avoid: 过多分支、复杂嵌套2. 数据图表型
有些内容不是"讲关系",而是在讲数字、变化和对比。
更适合的方式:柱状图、折线图、对比表卡片、指标信息图。
3. 抽象辅助型
不承担证据职责,用来帮章节转场、给抽象概念一点视觉锚点、缓解长文纯文字的疲劳感。
这类图更适合"AI 帮你组织表达",而不是"AI 直接决定最终长什么样"。
对应的 prompt 模板:
css
Create an editorial illustration for a Chinese tech article about {topic}.
Show {scene or metaphor}. Style: {style}. Mood: {mood}.
Composition: {composition}. Color direction: {palette}.
Keep it clean, readable, and suitable for a blog article.
Do not include UI chrome, brand logos, or dense text.4. 真实截图型
这是我这次最明显感受到价值的一类。
很多内容一旦涉及"真实界面""真实文件""真实工作流",截图的说服力会远远高于一张生成图。
这里最重要的一点不是"图好不好看",而是**"它是不是真的"**。
对应的截图 brief 模板:
yaml
Capture target: # 截什么
Navigation path: # 怎么到达
Required state: # 需要处于什么状态
Crop focus: # 裁切重点
What to redact: # 需要打码的内容
What to annotate: # 需要标注的内容
Fallback: # 如果截不到,备选方案5. 截图增强型
截图有时候虽然对了,但还不够------真实截图往往信息量很大,读者未必一眼就知道重点在哪里。
这时候需要最小量增强:箭头、框选、局部放大、编号步骤。
对应的增强 brief 模板:
yaml
Base screenshot: # 基础截图
Main focal point: # 主要焦点
Annotation style: # 标注风格
Need arrow or box: # 是否需要箭头/框选
Need numbered steps: # 是否需要编号步骤
Need crop or zoom: # 是否需要裁切/放大
What to keep hidden: # 需要隐藏的内容6. 封面题图型
题图和正文插图,真的不是同一套判断逻辑。
正文里的图,大多服务于理解;题图更偏向于:吸引点击、建立主题气质、帮读者快速识别这篇文章在讲什么。
所以题图最好单独判断,不要混进正文插图那条线上。
对应的封面 brief 模板:
yaml
Article topic: # 文章主题
Target audience: # 目标读者
Visual metaphor: # 视觉隐喻
Mood: # 氛围
Composition: # 构图
Safe area for title text: # 标题安全区
Color direction: # 色彩方向
Avoid: # 需要避免的元素六、拿真实文章跑一遍,结果比我预想中更有用
真正让我觉得这个 skill 开始有价值,是因为我很快就拿那篇正在写的 Codex 长文,实打实跑了一遍。
这一轮验证最直接的产物,就是那张"文章配图执行表":
| # | 位置 | 目标 | 图类型 | 生产方式 | 优先级 | 可选 |
|---|---|---|---|---|---|---|
| 1 | Plan 模式 | 降低陌生感 | 真实截图型 | 手动截图 | 🔴 高 | 否 |
| 2 | AGENTS.md | 降低抽象度 | 真实截图型 | 手动截图 | 🔴 高 | 否 |
| 3 | Skills + Shell + Compaction | 解释三者关系 | 结构解释型 | AI 生成 Mermaid | 🔴 高 | 否 |
| 4 | /review 代码审查 |
增强可信度 | 真实截图 + 增强型 | 手动截图 + 标注 | 🟡 中 | 是 |
| 5 | 运维 / MCP 日志 | 把抽象流程具象化 | 真实截图型 | 手动截图 | 🟡 中 | 是 |
| 6 | 文章头图 | 建立主题识别 | 封面题图型 | 外部生图 | 🟡 中 | 是 |
它真正有价值的地方,不在于表本身,而在于它帮我把很多本来模糊的判断,一次性收紧了------哪几张图是高优先级、哪些图必须我亲自处理、哪些图完全可以交给 AI。

它终于帮我把"哪些该做、哪些别做"判断清楚了。
内容创作里最消耗人的,很多时候不是执行,而是反复犹豫。这个 skill 真正帮到我的地方,就是把这种犹豫往前压缩了一层。
还有一个很现实的好处:它让我第一次比较自然地接受了"有些地方就是不该配图"。
一张真正解释问题的图,胜过三张只是为了"显得丰富"的图。
七、最先落地的成果:它真的帮我做出了封面图
最先让我看到具体成果的,其实是题图。
在这个前提下,skill 给出的不是一张现成图,而是一段更适合用来出图的提示词:
yaml
Article topic: 三篇官方 Codex 指南的实战化整理
Target audience: 工程师与技术创作者
Visual metaphor: AI 队友协作桌面,或有组织的工程工作流
Mood: 能干、清晰、现代,不要科幻感过重
Composition: 预留标题安全区,避免元素过多,主体明确
Color direction: 冷静的蓝色 / 中性色科技风
Avoid: 机器人拟人、霓虹赛博、假代码大段文字、杂乱拼贴顺带一提,这里也想小小推荐一下 Coze。对我这种以前连一张图都懒得折腾的人来说,它现在的体验已经非常够用了:个人版9.9便宜、上手快、轻量需求基本够用,不需要为了做一张封面图就把流程搞得特别重。(不是广告,我真没收钱 😂)
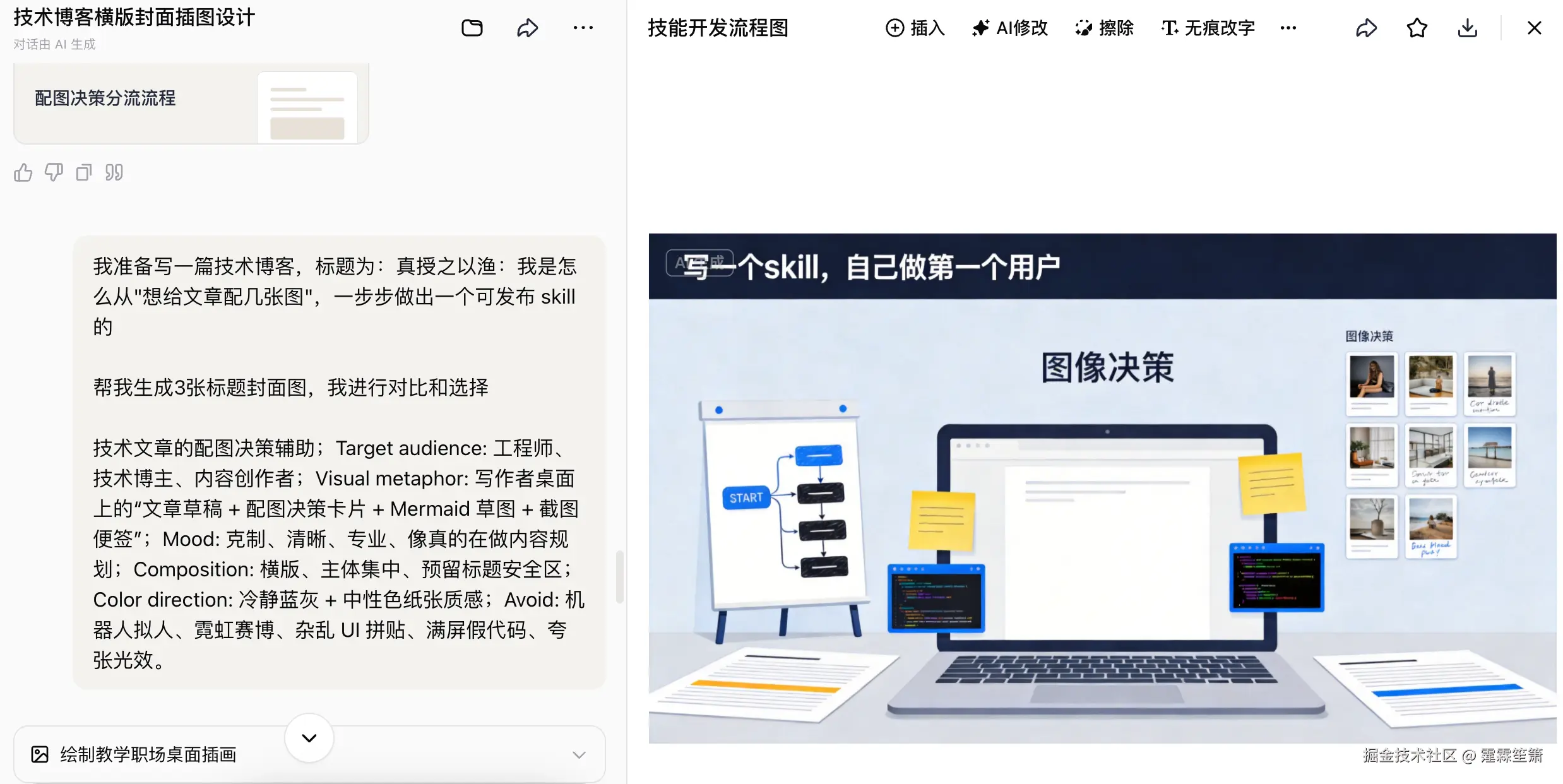
我后来把这个 brief 拿去跑了一版图,结果比我预想中顺手------技术内容感是对的,工程协作感是对的,整体调性比较克制,不会太花。
这张图不是凭空"灵光一闪"跑出来的,而是先经过了一层更靠前的判断:这是一张题图,它服务的不是正文解释,而是主题识别和传播入口。
当这个判断成立之后,后面的 prompt 才不容易飘。但我最想强调的还是:
真正帮到我的,不是"某个平台能出图",而是我终于先把"这张图该长成什么方向"说清楚了。
八、我顺手把它整理成了一个可发布的 skill
当这个 skill 在真实文章上跑出第一轮结果之后,我很快就把它整理成了一个更标准的 skill 包,发到了 GitHub:
Fridolph/article-visual-planning
感兴趣的可以直接去看,里面有 SKILL.md、双语 README、examples 和 references,结构比较完整,应该能直接拿去用。
当你开始补 examples/ 和 README 的时候,你脑子里想的已经不是"我自己怎么用",而是"别人拿到它能不能也看懂"。
从那一刻开始,你不再只是"用工具的人",而是在慢慢变成"定义工具的人"。
九、这次最大的感受:AI 时代最值钱的,不只是会用,而是会沉淀
如果要给这次经历做一个总结,我最想记下来的,不是"我又做了一个 skill",而是我对 AI 协作这件事的理解,又往前走了一点。
真正有复利的,往往不是"这次结果还不错",而是你有没有把这次结果背后的过程,整理成一个以后还能继续复用的东西。
真正值钱的,不只是会"用",而是会"沉淀"。
提示词 vs skill:不是同一个层级的事情
提示词更像一次性的交流------很灵活,也很轻便,但很多经验会随着这次对话结束而散掉。
skill 就不太一样了。当你开始写一个 skill 的时候,你其实是在逼自己回答一些更本质的问题:
- 这个任务真正要解决的是什么?
- 它什么时候应该被触发?
- 它最容易跑偏的地方在哪里?
- 它输出什么样的结果,才算真的有帮助?
提示词更像即时反应,skill 更像长期资产。
虽然这只是一个图片选择的 skill 但思想通用,代码、写作、视频剪辑等可运用,这才是 skill 的价值。
从"要结果"到"先判断"
这次配图 skill 最让我受用的一点,就是它把我的注意力,从"赶紧出几张图"拉回到了"先判断该不该出图"。
AI 越强,我们越容易直接冲向结果。但很多时候,真正决定质量的,并不是执行这一步,而是更前面的判断这一步。
这件事几乎可以外延到很多 AI 协作场景里:
- 写代码前,先判断应该改哪里
- 做重构前,先判断边界在哪里
- 写文档前,先判断读者真正关心什么
- 做图前,先判断视觉承担的任务是什么
AI 越强,前面的判断力越不能丢。判断力,会越来越成为"人真正该负责的部分"。
从"调用别人的方法"到"定义自己的工作流"
会用别人的工具,当然已经很好了;但一旦你开始把自己的工作流也沉淀出来,你和 AI 的关系就会发生变化。
这很可能就是 AI 时代一个非常重要的分界线:
- 有的人停留在"我会用很多工具"
- 有的人会继续往前走,开始把自己的方法也做成工具
前者已经能提效,后者则更容易建立起真正属于自己的生产力系统。
十、后续计划
这件事还没有结束。
- 继续拿不同文章类型去跑:目前跑通的是偏 AI 工具方法论的长文,接下来想试试技术教程、项目复盘、产品说明。只有在不同类型的内容里都保持稳定,才能说它是一套真正可复用的方法。
- 继续压缩输出,让建议更轻:skill 很容易越写越丰富,但输出一旦太重,作者的决策成本反而会上升。我更希望它像一个熟悉内容创作的搭档:该提醒的提醒,该收束的收束。
- 继续整理发布,看看它能不能真正走出去:我还挺好奇:如果它真的公开出去,别人会不会在我没想到的场景里,也跑出一些新的经验?
- 下一篇,回到那篇本来要发的 Codex 长文:绕了一圈,坑还是要填的。
只是现在回头看,我反而觉得先写这一篇挺值的------如果没有这次中途停下来,把"配图判断"这件事单独拎出来,我可能还是会像以前一样,边写边犹豫、边配图边试错。
而现在,至少我已经先给自己写好了一个能反复使用的辅助工具。
我本来只是想给下一篇文章配几张图,结果最先写完的,是这个 skill。
现在回头看,这部分反而比"图本身"更值得记下来。
顺便问一句:大家是讨厌 AI 生成的内容,还是讨厌低质量的内容?
欢迎留言聊聊,或者来 GitHub 看看, 有踩坑经历的也可以一起交流呀 ^_^ 🔥