分布式消息引擎的核心竞争力,除了高吞吐、低延迟,更在于极致的高可用保障。Kafka作为业界主流的消息中间件,其高可用能力的基石,正是分区副本机制与ISR(In-Sync Replicas)同步模型。绝大多数线上Kafka故障------无论是数据丢失、消息乱序,还是leader选举异常、集群吞吐量抖动,本质上都是对分区副本与ISR机制的底层逻辑理解不到位导致的。本文将从物理存储本质出发,逐层拆解副本机制、ISR核心规则、HW/LEO底层语义、leader选举与故障转移全流程,配合代码示例与避坑指南,帮你彻底吃透Kafka高可用的核心逻辑。
一、Kafka分区:分布式存储与并行能力的最小单元
Kafka的主题(Topic)是逻辑上的消息容器,而分区(Partition)是物理存储的最小单元,也是Kafka实现分布式并行处理的核心载体。
1.1 分区的物理存储模型
每个主题的多个分区,会分散存储在集群的不同Broker节点上,每个分区对应Broker磁盘上的一个独立目录,目录命名规则为{topic名称}-{分区编号}。每个分区目录内,由多个固定大小的日志段(Log Segment)组成,每个日志段包含3个核心文件:
.log文件:存储消息的实体数据,每条消息都有唯一的offset偏移量,作为消息在分区内的唯一标识。.index文件:偏移量索引文件,建立offset与.log文件中物理地址的映射,用于快速定位消息。.timeindex文件:时间戳索引文件,基于时间戳快速查找对应offset的消息。
分区内的消息严格遵循offset递增的顺序写入,且只能追加写入,无法修改删除,这是Kafka实现高吞吐的核心设计之一。
1.2 分区的核心特性与认知误区
- 核心特性1:分区内消息严格有序,多分区全局无序。单分区主题可以实现消息的全局有序,多分区主题仅能保证单个分区内的消息有序,无法保证跨分区的消息顺序。
- 核心特性2:分区是分布式水平扩展的最小单元。通过增加分区数,可以线性提升主题的读写吞吐量,分区数的上限取决于集群的Broker节点数与硬件资源。
- 核心特性3:分区是副本机制的最小载体。Kafka的副本、ISR、高可用能力,都是以分区为维度进行管理的,不同分区的副本管理完全独立。
易混淆点明确区分:很多开发者会误以为主题级别的有序性,在实际使用中,如果需要全局有序,只能使用单分区主题,同时会牺牲吞吐量;如果需要高吞吐,可通过业务key的hash路由,将同一业务的消息发送到同一个分区,实现业务级别的有序。
二、副本机制:Kafka高可用的核心载体
Kafka的高可用能力,本质上是通过副本的冗余存储实现的。当集群中的某个Broker节点故障时,该节点上分区的副本可以接管服务,实现故障的无感知转移。
2.1 副本的核心定义与分类
每个分区可以配置多个副本,副本的总数称为副本因子(Replication Factor) 。每个分区的副本中,有且仅有一个Leader副本,其余为Follower副本,特殊场景下可配置Observer副本。
- Leader副本:每个分区唯一的读写入口,所有生产者的写入请求、消费者的读取请求,都由Leader副本直接处理,Follower副本不对外提供任何读写服务。
- Follower副本:仅作为Leader副本的冗余备份,唯一的工作是从Leader副本拉取消息,同步数据到本地日志,维护与Leader的数据一致性。
- Observer副本:不参与ISR集合的维护,不参与Leader选举,仅异步同步Leader的数据,可用于实现跨机房的读扩容,不会影响集群的写入性能与Leader选举的稳定性。
易混淆点明确区分:很多开发者认为Follower副本可以提供读服务,提升集群的读吞吐量。实际上,Kafka默认关闭了Follower副本的读能力,所有读写请求都由Leader副本处理。2.4版本之后引入的追随者读(Follower Fetching)功能,仅能在机架感知的场景下手动开启,且会引入消息一致性延迟的问题,线上场景极少使用。
2.2 副本的机架感知分配策略
Kafka的副本分配策略,直接决定了集群的高可用能力。默认采用机架感知的分配算法,核心目标是将副本均匀分散在不同的Broker节点、不同的机架上,避免单节点、单机架故障导致分区不可用。
默认分配算法的核心规则:
- 将集群中所有可用的Broker节点,按机架分组并排序。
- 分区的优先副本(Preferred Replica,即AR列表的第一个副本),轮询分配到不同的Broker节点上,保证Leader副本的均匀分布。
- 分区的其余副本,依次分配到与优先副本不同机架、不同Broker的节点上,确保同一个分区的所有副本,不会出现在同一个机架、同一个Broker上。
示例:集群有6个Broker节点,分为2个机架,机架1包含broker0、broker1、broker2,机架2包含broker3、broker4、broker5。创建一个分区数为3、副本因子为3的主题,最终的副本分配结果如下:
| 分区编号 | Leader副本(优先副本) | 副本分配列表(AR) |
|---|---|---|
| 0 | broker0 | broker0,broker3,broker1 |
| 1 | broker1 | broker1,broker4,broker2 |
| 2 | broker2 | broker2,broker5,broker0 |
可以看到,每个分区的3个副本,都分散在2个机架的不同Broker上,任意一个机架故障、任意一个Broker故障,都不会导致分区的所有副本不可用,保障了集群的高可用。
2.3 副本因子的配置原则
副本因子的配置,需要在可用性、可靠性与存储成本之间做平衡,核心配置原则:
- 副本因子最小值为2,线上场景推荐配置为3,金融级场景可配置为4。
- 副本因子不能超过集群中可用的Broker节点数,否则无法完成副本分配。
- 副本因子越大,数据可靠性越高,集群的写入延迟越高,存储成本也越高。
三、ISR机制:Kafka高可用与数据一致性的灵魂
ISR(In-Sync Replicas),即同步副本集合,是Kafka实现数据一致性与高可用平衡的核心设计。它定义了哪些副本与Leader保持了数据同步,只有ISR内的副本,才有资格参与Leader选举,成为新的Leader副本。
3.1 ISR的准入规则与核心参数
很多老旧技术文章会提到,ISR的判断有两个维度:消息数差距与时间差距,这是完全错误的。从Kafka 0.10.0版本开始,replica.lag.max.messages参数已经被完全废弃,当前ISR的准入规则,仅通过时间阈值判断。
ISR的核心准入规则:Follower副本必须在replica.lag.time.max.ms参数配置的时间内,持续与Leader保持数据同步,默认值为5000ms(5秒)。
具体的判断逻辑:
- Follower副本会持续向Leader发送FETCH请求,拉取消息数据。
- 如果Follower副本连续超过
replica.lag.time.max.ms时间,没有向Leader发送FETCH请求,或者没有追上Leader的最新消息,就会被踢出ISR集合。 - 被踢出ISR的Follower副本,后续持续同步数据,追上Leader的最新LEO(Log End Offset),并持续保持同步超过
replica.lag.time.max.ms时间,会被重新加入ISR集合。
易混淆点明确区分:为什么废弃消息数阈值?因为在流量突增的场景下,Leader的写入速度瞬间提升,Follower副本可能会暂时落后一定数量的消息,但很快就能追上,此时如果用消息数阈值,会导致Follower被频繁踢出ISR,引发集群元数据的频繁变更,造成吞吐量抖动。而时间阈值可以很好的规避这个问题,仅判断副本的同步活性。
3.2 ISR的维护与更新机制
ISR集合的维护,是由Leader副本所在的Broker节点负责的,而非集群的Controller节点,核心更新流程:
- Leader副本所在的Broker,会定期(默认每500ms)检查所有Follower副本的同步状态,判断是否符合ISR的准入规则。
- 如果ISR集合发生变更(新增或剔除副本),Leader节点会将最新的ISR集合信息上报给集群的Controller节点。
- Controller节点收到ISR变更信息后,会更新集群的元数据,并将最新的元数据同步到集群中所有的Broker节点,同时持久化到KRaft元数据分区(或ZooKeeper)中。
3.3 ISR与消息可靠性的核心关联:acks与min.insync.replicas
ISR集合的配置,直接决定了消息的可靠性,而这一能力,是通过acks参数与min.insync.replicas参数的配合实现的。
首先明确三个核心配置的语义:
-
acks参数:生产者发送消息时,配置需要多少个副本写入成功,才认为消息发送成功。acks=0:生产者发送消息后,不需要等待任何Broker的响应,直接认为发送成功。性能最高,可靠性最低。acks=1:生产者发送消息后,等待Leader副本写入本地日志成功后,就返回成功。是Kafka的默认配置,平衡了性能与可靠性。acks=-1(acks=all):生产者发送消息后,需要等待ISR集合中所有的副本,都成功写入消息后,才返回成功。可靠性最高,性能最低。
-
min.insync.replicas参数:分区的ISR集合中,最少需要有多少个同步副本,才能正常处理写入请求,默认值为1。
易混淆点明确区分 :很多开发者认为,配置acks=all就能保证消息绝对不丢失,这是完全错误的。acks=all必须配合min.insync.replicas≥2,才能实现真正的数据不丢失。
示例说明: 场景1:副本因子=3,acks=all,min.insync.replicas=1。 此时,如果两个Follower副本都被踢出ISR,ISR集合中只有Leader副本。生产者发送消息时,acks=all只需要Leader副本写入成功,就返回成功。如果此时Leader节点突然故障,两个Follower副本都没有同步到这条消息,新的Leader选举后,这条消息就会永久丢失。
场景2:副本因子=3,acks=all,min.insync.replicas=2。 此时,ISR集合中最少需要有2个同步副本,才能正常处理写入请求。生产者发送消息时,acks=all需要ISR中所有副本都写入成功,也就是至少2个副本(包含Leader)都写入了这条消息。即使此时Leader节点故障,ISR中至少还有1个Follower副本已经同步了这条消息,新的Leader会从这个Follower中选举,消息不会丢失。
3.4 ISR的异常场景与风险控制
ISR最常见的异常场景,就是ISR频繁收缩与扩张,也就是俗称的"ISR抖动",会导致集群的吞吐量下降、写入延迟升高,甚至引发Leader选举异常。
ISR抖动的核心诱因:
- 网络波动:Broker节点之间的网络延迟升高,超过
replica.lag.time.max.ms阈值,导致Follower副本被踢出ISR。 - Broker节点负载过高:CPU、内存、磁盘IO使用率过高,导致Follower副本无法及时拉取和写入消息,同步延迟超过阈值。
- 流量突增:生产者的写入流量瞬间飙升,Leader的写入速度远超Follower的同步速度,导致Follower的同步延迟超过阈值。
对应的优化方案:
- 合理调整
replica.lag.time.max.ms参数,可根据网络情况,调整为10000ms(10秒),避免网络波动导致的频繁踢除。 - 保障Broker节点的硬件资源,磁盘优先使用SSD,避免机械磁盘的IO瓶颈导致的同步延迟。
- 控制生产者的写入流量,设置合理的流量阈值,避免流量突增对集群造成冲击。
- 开启机架感知,保证副本分散在不同的机架、不同的交换机上,降低网络故障的影响范围。
四、底层核心语义:LEO、HW与数据一致性保障
要彻底吃透Kafka的副本同步与数据一致性,必须理解两个核心语义:LEO(Log End Offset)与HW(High Watermark),这两个参数定义了副本的同步进度与消息的可见性。
4.1 核心语义定义
每个副本(包括Leader与Follower),都维护了自己独立的LEO与HW,核心定义:
- LEO(Log End Offset) :日志结束偏移量,指向下一条待写入的消息的offset,也就是当前副本已经写入的最后一条消息的offset+1。比如,副本已经写入了offset 0-9的消息,那么LEO就是10。
- HW(High Watermark) :高水位,代表ISR集合中所有副本都已经成功同步的消息的最大offset,消费者只能消费offset小于HW的消息,也就是HW之前的消息对消费者是可见的。
- LSO(Log Start Offset) :日志起始偏移量,代表当前分区中可消费的最小offset,受日志保留策略与日志清理策略的影响。
易混淆点明确区分:消费者只能消费到offset < HW的消息,而非offset ≤ HW。HW是所有ISR副本都同步的最大offset,比如HW=8,代表offset 0-7的消息,所有ISR副本都已经同步,消费者可以消费;offset 8的消息,还没有被所有ISR副本同步,对消费者不可见。
4.2 LEO与HW的更新全流程
我们通过一个完整的示例,拆解LEO与HW的更新流程,帮助你彻底理解底层逻辑。 示例前提:分区副本因子=3,1个Leader副本(broker0),2个Follower副本(broker1、broker2),ISR集合包含所有3个副本,初始状态下,所有副本的LEO=0,HW=0。
步骤1:生产者发送一条消息,Leader副本接收消息,写入本地日志。
- Leader副本的LEO更新为1,HW暂时保持0(因为还没有Follower副本同步这条消息)。
步骤2:Follower副本向Leader发送FETCH请求,拉取消息,请求中携带自己当前的LEO=0。
- Leader副本收到FETCH请求,返回从offset 0开始的消息数据,响应中携带Leader当前的HW=0。
步骤3:Follower副本收到消息,写入本地日志,更新自己的LEO为1。
- Follower副本根据Leader响应中的HW,更新自己的HW为min(自己的LEO=1, Leader的HW=0)=0。
- Follower副本再次发送FETCH请求,携带自己的新LEO=1。
步骤4:Leader副本收到两个Follower的FETCH请求,确认两个Follower的LEO都已经更新为1。
- Leader副本计算ISR集合中所有副本的最小LEO,也就是min(1,1,1)=1,将自己的HW更新为1。
- Leader副本在返回给Follower的FETCH响应中,携带自己的新HW=1。
步骤5:Follower副本收到FETCH响应,根据Leader的HW,更新自己的HW为min(自己的LEO=1, Leader的HW=1)=1。
- 此时,所有副本的LEO=1,HW=1,offset 0的消息对消费者可见,完成了一次完整的消息同步流程。
整个流程的核心逻辑:Leader的HW,永远是ISR集合中所有副本的最小LEO;Follower的HW,永远是自己的LEO与Leader的HW的最小值。这一机制,保证了消费者只能消费到所有ISR副本都已经同步的消息,即使Leader发生故障,新的Leader也一定包含这些消息,不会出现消费到的数据丢失的情况。
4.3 Leader故障后的HW截断机制
当Leader副本发生故障,新的Leader选举完成后,会执行HW截断机制,保证新Leader的日志与旧Leader的日志一致性。 核心规则:新的Leader会将自己的LEO,截断到自己的HW值,丢弃HW之后的未同步消息。
为什么要这么做?因为旧Leader的HW之后的消息,还没有被所有ISR副本同步,消费者也无法消费到这些消息,新的Leader截断这些消息,保证了集群的消息一致性,避免出现消息乱序、数据不一致的问题。
示例:旧Leader的LEO=10,HW=8,也就是offset 8、9的消息,还没有被ISR中的Follower副本同步。此时旧Leader故障,新的Leader从Follower中选举,Follower的LEO=8,HW=8。新的Leader会将自己的LEO设置为8,后续的消息从offset 8开始写入,旧Leader中offset 8、9的未同步消息,会被截断丢弃,保证了集群的消息一致性。
五、高可用核心流程:Leader选举与故障转移
Kafka的高可用能力,最终落地在Leader选举与故障转移流程上。当Broker节点故障时,集群可以自动完成Leader副本的重新选举,实现故障的无感知转移,保障服务的持续可用。
5.1 集群Controller的核心作用
Kafka集群中,有且仅有一个Controller节点(KRaft模式下为Controller Quorum),负责集群所有的元数据管理与控制操作,核心职责包括:
- 监听Broker节点的上下线,处理节点故障事件。
- 管理分区的副本分配与Leader选举。
- 维护集群的主题、分区、副本元数据,同步给所有Broker节点。
- 处理主题的创建、删除、分区扩容等操作。
在KRaft模式下,Kafka移除了对ZooKeeper的依赖,将集群的元数据存储在一个内置的元数据分区中,由Controller Quorum负责元数据的一致性管理,提升了集群的稳定性与可扩展性。
5.2 Leader选举的核心规则
Leader选举的核心原则:只有ISR集合中的副本,才有资格参与Leader选举,成为新的Leader副本。这一原则,是Kafka保证数据不丢失的核心底线。
完整的Leader选举规则:
- 优先选择优先副本(AR列表的第一个副本)作为新的Leader,保证分区的Leader分布均匀。
- 优先副本必须在当前的ISR集合中,且处于存活状态,才能当选Leader。
- 如果优先副本不可用,从ISR集合中,选择LEO最大的副本作为新的Leader,保证数据丢失量最小。
- 如果ISR集合中没有可用的副本,集群会根据
unclean.leader.election.enable参数的配置,决定后续的处理逻辑。
5.3 故障转移的全流程
当集群中的某个Broker节点发生故障下线时,集群会自动完成故障转移,完整流程如下:
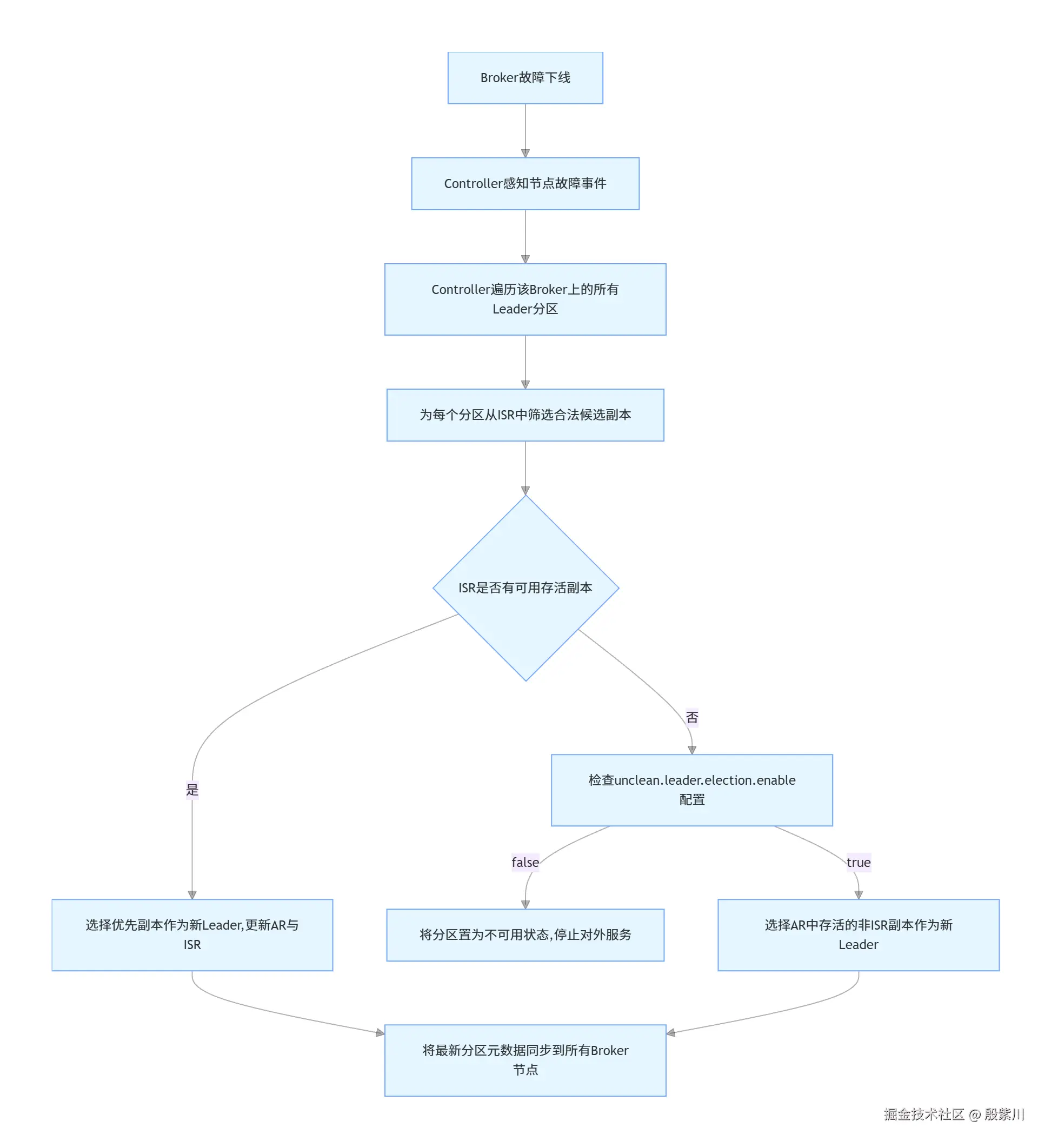
易混淆点明确区分 :unclean.leader.election.enable参数,默认值为false,也就是不允许非ISR集合中的副本参与Leader选举。如果将该参数设置为true,当ISR集合中没有可用副本时,会允许非ISR的副本当选Leader,虽然提升了分区的可用性,但会导致大量的消息数据丢失,因为非ISR的副本与旧Leader的数据差距很大,会截断大量未同步的消息。线上场景绝对禁止开启该参数,否则会面临数据丢失的严重风险。
5.4 优先副本选举
优先副本,就是分区AR列表中的第一个副本,也是分区创建时指定的原始Leader副本。随着集群的故障转移与Leader切换,分区的Leader副本可能会分布不均,导致部分Broker节点的压力过大,部分节点的压力过小。
优先副本选举,就是将分区的Leader副本,重新切换回优先副本,保证Leader副本在集群中均匀分布,平衡各个Broker节点的压力。Kafka提供了自动与手动两种优先副本选举方式:
- 自动优先副本选举:通过
auto.leader.rebalance.enable参数开启,默认值为true,集群会定期自动执行优先副本选举。 - 手动优先副本选举:通过Kafka提供的
kafka-leader-election.sh脚本,手动触发指定主题、指定分区的优先副本选举。
六、Java客户端实战:副本与ISR状态管理
以下为实现,基于JDK 17编写,实现Kafka主题的创建、分区副本与ISR状态查询、消息生产与消费、ISR状态监控等核心功能。
6.1 项目Maven依赖配置
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam</groupId>
<artifactId>kafka-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka-demo</name>
<properties>
<java.version>17</java.version>
<kafka.version>3.7.0</kafka.version>
<fastjson2.version>2.0.52</fastjson2.version>
<guava.version>33.1.0-jre</guava.version>
<mybatis-plus.version>3.5.6</mybatis-plus.version>
<mysql.version>8.3.0</mysql.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>6.2 配置文件application.yml
less
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
acks: all
retries: 3
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
linger.ms: 10
batch.size: 16384
buffer.memory: 33554432
consumer:
group-id: kafka-demo-group
auto-offset-reset: earliest
enable-auto-commit: false
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500
listener:
ack-mode: manual_immediate
concurrency: 3
datasource:
url: jdbc:mysql://127.0.0.1:3306/kafka_demo?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: auto
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
packages-to-scan: com.jam.demo.controller6.3 Kafka Admin客户端配置类
kotlin
package com.jam.demo.config;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* Kafka Admin客户端配置类
* @author ken
*/
@Configuration
public class KafkaAdminConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
/**
* 构建Kafka AdminClient实例
* @return AdminClient实例
*/
@Bean
public AdminClient adminClient() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configs.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
configs.put(AdminClientConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, 60000);
return AdminClient.create(configs);
}
}6.4 主题信息VO类
kotlin
package com.jam.demo.vo;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.util.List;
/**
* 主题信息VO
* @author ken
*/
@Data
@Schema(description = "Kafka主题分区信息")
public class TopicInfoVO {
@Schema(description = "主题名称")
private String topicName;
@Schema(description = "分区编号")
private Integer partitionId;
@Schema(description = "Leader副本所在BrokerID")
private Integer leaderBrokerId;
@Schema(description = "Leader副本所在Broker地址")
private String leaderBrokerHost;
@Schema(description = "所有副本所在的BrokerID列表")
private List<Integer> replicaBrokers;
@Schema(description = "ISR同步副本所在的BrokerID列表")
private List<Integer> isrBrokers;
@Schema(description = "ISR副本数量")
private Integer isrSize;
}6.5 Kafka主题管理服务
ini
package com.jam.demo.service;
import com.alibaba.fastjson2.JSON;
import com.google.common.collect.Lists;
import com.jam.demo.vo.TopicInfoVO;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.Node;
import org.apache.kafka.common.TopicPartitionInfo;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import jakarta.annotation.Resource;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ExecutionException;
import java.util.stream.Collectors;
/**
* Kafka主题管理服务
* @author ken
*/
@Slf4j
@Service
public class KafkaTopicService {
@Resource
private AdminClient adminClient;
/**
* 创建Kafka主题
* @param topicName 主题名称
* @param numPartitions 分区数
* @param replicationFactor 副本因子
* @return 创建结果
*/
public String createTopic(String topicName, int numPartitions, short replicationFactor) {
if (!StringUtils.hasText(topicName)) {
return "主题名称不能为空";
}
if (numPartitions <= 0) {
return "分区数必须大于0";
}
if (replicationFactor <= 0) {
return "副本因子必须大于0";
}
try {
Set<String> existingTopics = adminClient.listTopics().names().get();
if (existingTopics.contains(topicName)) {
return "主题" + topicName + "已存在";
}
NewTopic newTopic = new NewTopic(topicName, numPartitions, replicationFactor);
CreateTopicsResult result = adminClient.createTopics(Lists.newArrayList(newTopic));
result.all().get();
log.info("主题{}创建成功,分区数:{},副本因子:{}", topicName, numPartitions, replicationFactor);
return "主题创建成功";
} catch (InterruptedException | ExecutionException e) {
log.error("主题创建失败", e);
return "主题创建失败:" + e.getMessage();
}
}
/**
* 查询主题的分区副本与ISR信息
* @param topicName 主题名称
* @return 主题信息列表
*/
public List<TopicInfoVO> getTopicInfo(String topicName) {
List<TopicInfoVO> resultList = Lists.newArrayList();
if (!StringUtils.hasText(topicName)) {
return resultList;
}
try {
DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Lists.newArrayList(topicName));
Map<String, TopicDescription> topicDescriptionMap = describeTopicsResult.allTopicNames().get();
if (CollectionUtils.isEmpty(topicDescriptionMap)) {
return resultList;
}
TopicDescription topicDescription = topicDescriptionMap.get(topicName);
if (ObjectUtils.isEmpty(topicDescription)) {
return resultList;
}
List<TopicPartitionInfo> partitions = topicDescription.partitions();
for (TopicPartitionInfo partition : partitions) {
TopicInfoVO vo = new TopicInfoVO();
vo.setTopicName(topicName);
vo.setPartitionId(partition.partition());
Node leader = partition.leader();
if (!ObjectUtils.isEmpty(leader)) {
vo.setLeaderBrokerId(leader.id());
vo.setLeaderBrokerHost(leader.host());
}
List<Integer> replicaList = partition.replicas().stream().map(Node::id).collect(Collectors.toList());
vo.setReplicaBrokers(replicaList);
List<Integer> isrList = partition.isr().stream().map(Node::id).collect(Collectors.toList());
vo.setIsrBrokers(isrList);
vo.setIsrSize(isrList.size());
resultList.add(vo);
}
log.info("主题{}信息查询成功,结果:{}", topicName, JSON.toJSONString(resultList));
return resultList;
} catch (InterruptedException | ExecutionException e) {
log.error("主题信息查询失败", e);
return resultList;
}
}
/**
* 查询集群所有主题名称
* @return 主题名称列表
*/
public List<String> listAllTopics() {
try {
Set<String> topics = adminClient.listTopics().names().get();
return Lists.newArrayList(topics);
} catch (InterruptedException | ExecutionException e) {
log.error("主题列表查询失败", e);
return Lists.newArrayList();
}
}
/**
* 删除主题
* @param topicName 主题名称
* @return 删除结果
*/
public String deleteTopic(String topicName) {
if (!StringUtils.hasText(topicName)) {
return "主题名称不能为空";
}
try {
DeleteTopicsResult result = adminClient.deleteTopics(Lists.newArrayList(topicName));
result.all().get();
log.info("主题{}删除成功", topicName);
return "主题删除成功";
} catch (InterruptedException | ExecutionException e) {
log.error("主题删除失败", e);
return "主题删除失败:" + e.getMessage();
}
}
}6.6 消息生产服务
typescript
package com.jam.demo.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import jakarta.annotation.Resource;
/**
* Kafka消息生产服务
* @author ken
*/
@Slf4j
@Service
public class KafkaProducerService {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息到指定主题
* @param topicName 主题名称
* @param messageKey 消息key
* @param messageBody 消息内容
* @return 发送结果
*/
public String sendMessage(String topicName, String messageKey, String messageBody) {
if (!StringUtils.hasText(topicName)) {
return "主题名称不能为空";
}
if (!StringUtils.hasText(messageBody)) {
return "消息内容不能为空";
}
try {
kafkaTemplate.send(topicName, messageKey, messageBody).addCallback(
result -> {
if (!ObjectUtils.isEmpty(result)) {
log.info("消息发送成功,主题:{},分区:{},offset:{}",
topicName,
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset());
}
},
ex -> log.error("消息发送失败,主题:{},内容:{}", topicName, messageBody, ex)
);
return "消息发送成功";
} catch (Exception e) {
log.error("消息发送异常", e);
return "消息发送异常:" + e.getMessage();
}
}
}6.7 消息消费服务
typescript
package com.jam.demo.service;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
import org.springframework.util.ObjectUtils;
/**
* Kafka消息消费服务
* @author ken
*/
@Slf4j
@Service
public class KafkaConsumerService {
/**
* 消费指定主题的消息
* @param record 消息记录
* @param ack 手动确认对象
*/
@KafkaListener(topics = {"kafka-demo-topic"}, groupId = "${spring.kafka.consumer.group-id}")
public void consumeMessage(ConsumerRecord<String, String> record, Acknowledgment ack) {
if (ObjectUtils.isEmpty(record)) {
ack.acknowledge();
return;
}
try {
log.info("收到消息,主题:{},分区:{},offset:{},key:{},value:{}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
handleMessage(record.value());
ack.acknowledge();
log.info("消息消费完成,offset:{}", record.offset());
} catch (Exception e) {
log.error("消息消费失败,offset:{}", record.offset(), e);
}
}
/**
* 处理消息业务逻辑
* @param messageBody 消息内容
*/
private void handleMessage(String messageBody) {
// 业务处理逻辑实现
}
}6.8 对外接口Controller
less
package com.jam.demo.controller;
import com.jam.demo.service.KafkaProducerService;
import com.jam.demo.service.KafkaTopicService;
import com.jam.demo.vo.TopicInfoVO;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.web.bind.annotation.*;
import jakarta.annotation.Resource;
import java.util.List;
/**
* Kafka管理接口
* @author ken
*/
@RestController
@RequestMapping("/kafka")
@Tag(name = "Kafka管理接口", description = "Kafka主题、消息、副本与ISR管理接口")
public class KafkaController {
@Resource
private KafkaTopicService kafkaTopicService;
@Resource
private KafkaProducerService kafkaProducerService;
@PostMapping("/topic/create")
@Operation(summary = "创建Kafka主题", description = "创建指定分区数与副本因子的Kafka主题")
public String createTopic(
@Parameter(description = "主题名称", required = true) @RequestParam String topicName,
@Parameter(description = "分区数", required = true) @RequestParam int numPartitions,
@Parameter(description = "副本因子", required = true) @RequestParam short replicationFactor) {
return kafkaTopicService.createTopic(topicName, numPartitions, replicationFactor);
}
@GetMapping("/topic/info")
@Operation(summary = "查询主题分区与ISR信息", description = "查询指定主题的分区、Leader副本、副本列表与ISR列表信息")
public List<TopicInfoVO> getTopicInfo(
@Parameter(description = "主题名称", required = true) @RequestParam String topicName) {
return kafkaTopicService.getTopicInfo(topicName);
}
@GetMapping("/topic/list")
@Operation(summary = "查询集群所有主题", description = "查询Kafka集群中所有的主题名称列表")
public List<String> listAllTopics() {
return kafkaTopicService.listAllTopics();
}
@DeleteMapping("/topic/delete")
@Operation(summary = "删除主题", description = "删除指定的Kafka主题")
public String deleteTopic(
@Parameter(description = "主题名称", required = true) @RequestParam String topicName) {
return kafkaTopicService.deleteTopic(topicName);
}
@PostMapping("/message/send")
@Operation(summary = "发送消息", description = "向指定主题发送消息")
public String sendMessage(
@Parameter(description = "主题名称", required = true) @RequestParam String topicName,
@Parameter(description = "消息Key") @RequestParam(required = false) String messageKey,
@Parameter(description = "消息内容", required = true) @RequestParam String messageBody) {
return kafkaProducerService.sendMessage(topicName, messageKey, messageBody);
}
}6.9 项目启动类
kotlin
package com.jam.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* Kafka Demo项目启动类
* @author ken
*/
@SpringBootApplication
@MapperScan("com.jam.demo.mapper")
public class KafkaDemoApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaDemoApplication.class, args);
}
}七、核心避坑指南与最佳实践
7.1 数据零丢失的核心配置方案
要实现Kafka消息的零丢失,必须同时满足以下配置:
- 副本因子≥3,保证足够的副本冗余。
- 生产者配置
acks=all,等待ISR中所有副本写入成功。 - 主题配置
min.insync.replicas≥2,保证ISR中至少有2个同步副本,才能处理写入请求。 - 生产者配置
retries≥3,开启消息发送重试。 - 消费者关闭自动提交offset,采用手动提交模式,保证消息消费成功后再提交offset。
- 关闭
unclean.leader.election.enable参数,禁止非ISR副本参与Leader选举。
7.2 ISR抖动的优化方案
- 合理调整
replica.lag.time.max.ms参数,根据网络情况调整为10000ms,避免网络波动导致的频繁踢除。 - 保障Broker节点的硬件资源,使用SSD磁盘,提升磁盘IO性能,避免IO瓶颈导致的同步延迟。
- 控制生产者的写入流量,设置合理的批量发送参数,避免流量突增。
- 优化Broker的JVM参数,避免Full GC导致的节点停顿,引发同步延迟。
- 保证集群的网络稳定性,副本跨机房部署时,需要保障机房之间的网络带宽与延迟。
7.3 分区与副本的最佳实践
- 分区数的设置:单个主题的分区数,推荐设置为集群Broker节点数的2-3倍,避免分区数过多导致的元数据管理压力过大。
- 副本因子的设置:线上场景推荐设置为3,金融级场景可设置为4,不要超过Broker节点数。
- 定期执行优先副本选举,保证Leader副本在集群中均匀分布,平衡各个Broker的压力。
- 开启机架感知,保证副本分散在不同的机架上,避免单机架故障导致的分区不可用。
- 避免单分区主题的分区日志过大,单个分区的日志大小超过1TB时,建议进行分区扩容。
7.4 常见故障排查思路
- ISR频繁收缩:优先检查Broker节点的磁盘IO使用率、网络延迟、JVM GC情况,定位同步延迟的根因。
- 消息写入延迟升高:优先检查ISR集合是否正常,副本同步是否延迟,Leader副本是否分布均匀。
- 消费者消费延迟:优先检查分区数与消费者的并发数是否匹配,消费者的业务处理逻辑是否耗时过长。
- 分区不可用:优先检查该分区的ISR集合是否有可用副本,Broker节点是否正常运行,
unclean.leader.election.enable参数是否关闭。
Kafka的高可用能力,本质上是分区副本、ISR机制、HW/LEO语义、Leader选举这几个核心模块协同工作的结果。只有彻底吃透这些底层逻辑,才能在实际使用中搭建出稳定、高可用、高可靠的Kafka集群,规避线上故障,解决业务中的各种实际问题。