1 论文介绍
个性化对话系统通过数据集构建 、训练方法论 以及整合用户特定偏好以增强对话能力的研究 而不断演进。
随着大语言模型(LLMs)的出现,通过系统提示词(System Prompts)嵌入角色人设(Personas)已变得非常有效 。
这些进展使得应用范围不断扩大,包括:
- 个性化聊天机器人
- LLM之间对话提升下游任务表现
- 合成数据生成等
现在的核心技术路径已经从早期的"模型训练"转向了基于 LLM 的 "Prompt Engineering"(提示工程)
尽管取得了这些进展,近期研究表明:
LLM 对上下文的情感极性(sentiment polarity)非常敏感
相比之下,人格本身的情感倾向(persona sentiment)对对话质量的影响却尚未被充分研究。
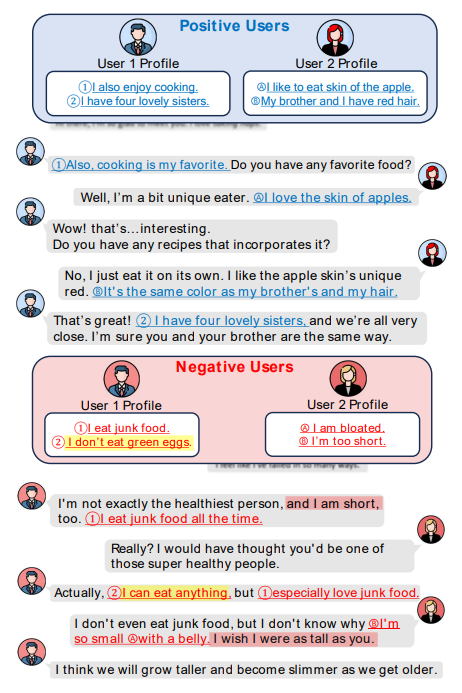
图1展示了不同情感人格(正向 vs 负向)生成的对话
正面人设: LLM 表现得很丝滑,能够"有选择性"地提及人设,保持对话流畅 。
负面人设: LLM 容易"用力过猛" 。比如图 1 中的负面例子,User 1 说自己不吃绿蛋,但后面又说自己什么都吃,产生了严重的逻辑矛盾(图中黄色高亮部分)
情感极性会直接干扰模型的逻辑推理能力 。
本文构建了一个**不同情绪极性的用户画像集合,**进行分析,得到以下结论:
- 负向极性用户之间的对话倾向于过度强调人设属性,这导致矛盾增加并降低了整体连贯性 。
- 正向极性用户之间的对话会选择性地整合人设信息,从而产生既连贯又符合语境的互动 。
- 情感微弱或中性的人设通常产生的对话质量较低,这在各种指标的显著差异中得到了证实 。
为了解决上述问题,本文提出了一种对话生成框架,该框架结合了轮次控制策略、人设排序机制以及情感感知提示 。
表现出中性或微弱情感的人设被放置在对话较早的位置,而更正向的人设则放置在较后的位置 。使用 prompt进一步指示模型在生成回复时要仔细关注负向或中性情感 。这些方法促进了更一致且连贯的互动
2 研究设计
2.1 数据集
早期个性化对话系统通常采用,与用户画像(User Profiles)配对的双人对话。这些 persona 通常有三种表示方式:
- 描述性句子:每个 persona 用几句话描述(通常5句),共同构成用户画像。
- 稀疏 key-value 属性:使用结构化属性(Key-Value)来指定人设。
- 用户历史:每个说话者由一个 ID 标识,该 ID 可用于检索外部人设信息。
尽管存在多个数据集,但大多数都可追溯到PersonaChat和ConvAI2。在本文的实验中,采用ConvAI2数据集,主要通过描述性句子来定义用户角色。
因为现代大模型最擅长处理和理解的就是自然语言(Prompt)
2.2 极性化用户画像构建
提取极性 persona
使用情感分类器,从 ConvAI2 中提取带有情感极性的 persona
作者使用了一个经典的轻量级情感分类器(distilbert-base-uncased-finetuned-sst-2-english)模型对每个句子的情感进行分类,仅保留置信度得分高于 0.99 的句子作为"极性化人设"。
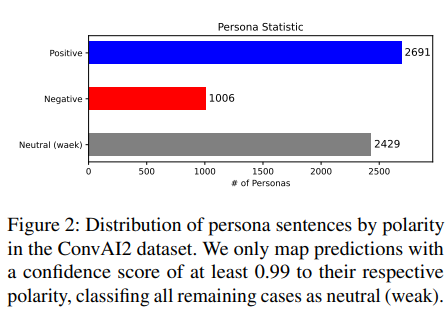
如图 2 所示,2691 个人设被归类为正向,1006 个为负向,2429 个为中性(微弱),这表明极性化人设占据了多数(约占所有人设的 60%)。值得注意的是,数据集中大约 17% 的人设是负向极性的
构建用户画像(Profile)
为了构建一个用户画像,作者组合了 K 个 persona 句子(K代表每个画像中包含的人设数量),每个人抽取K个人设,人设之间需要逻辑自洽。
为了避免内部矛盾,作者使用 nli-deberta-v3-large 模型检测到与现有集合没有冲突时,才迭代地添加额外的人设。 这种方法产生了三种画像类型:
- 负向画像 (Negative Profile): 仅包含负向人设。
- 正向画像 (Positive Profile): 仅包含正向人设。
- 混合画像 (Mixed Profile): 正负向人设的随机混合。
作者为每种类型生成了 1 万个独特的画像
2.3 研究问题
基于构建的"极性用户画像",本文提出两个问题:
-
RQ1. LLMs 对用户的(情感)极性敏感吗?
-
RQ2. 如果是,如何让 LLMs 对极性具有鲁棒性?
2.4 对话生成策略
传统的个性化对话系统使用**基于轮次(turn-based)**的方法,根据给定的人设和对话上下文依次生成回复。
然而,LLMs 的最新进展促成了**双角色联合生成(dual-persona joint generation)**方法,该方法同时编码两个人的画像,一次性生成完整的对话。
文中主要使用双角色联合生成来进行大规模的对话生产和分析,同时也尝试基于轮次的生成以寻找最优策略,这两种方法都使用贪婪解码(greedy decoding,即温度为 0)
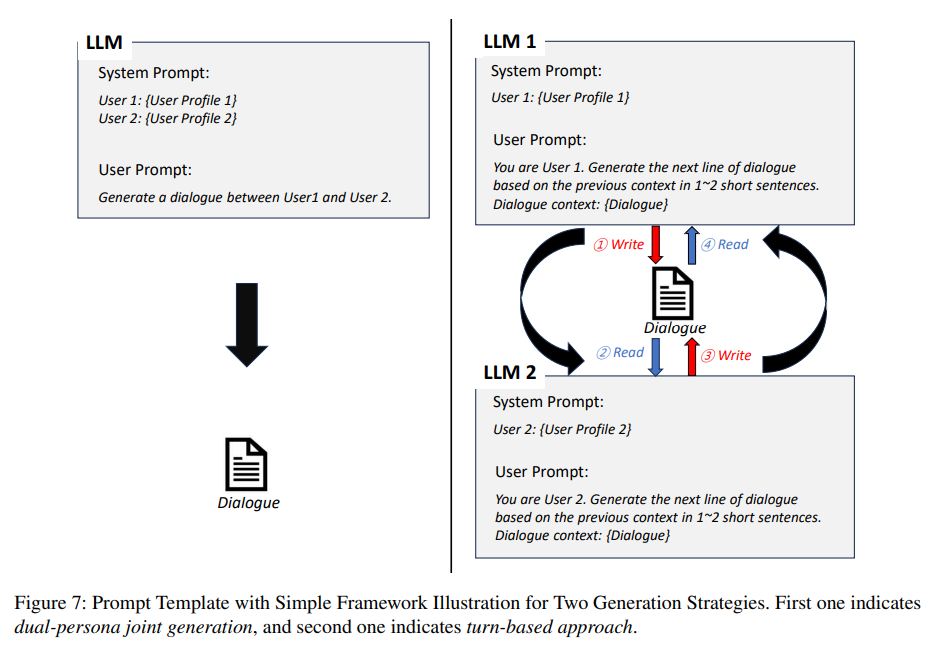
方案一(左图):联合生成 (Joint Generation)。 直接把 User 1 和 User 2 的人设全部塞进同一个 System Prompt 里,让大模型"左右互搏",一次性吐出完整的剧本。优点: 极大地节省 API 调用次数和上下文 token,适合跑 6 万条对话这种大规模实验。缺点: 容易因为两个 Prompt 互相干扰而产生逻辑混淆。
方案二(右图):基于轮次的生成 (Turn-based Approach)。 启动两个独立的大模型实例(LLM 1 和 LLM 2),各自只看自己的人设。LLM 1 生成一句话后,将其追加到
Dialogue context中发给 LLM 2,LLM 2 读完再回复,循环往复。这就非常类似于用 Python 编写一个真实的 Agent 交互循环。
2.5 评估指标
Consistency(一致性)
C score(一致性得分)
C score 是一种广泛用于评估个性化对话中一致性的指标。它使用 NLI(自然语言推断)模型计算用户人设与话语对的蕴含(entailment)得分。
设用户 n 的用户画像为 ,其构成的人设句子为
。同样地,用
表示对话,它由用户 n 的话语
(用户 n 在第 i 轮的发言)组成。
将这些utterance--persona对输入到一个微调过的 NLI(自然语言推断)模型中以获得蕴含得分,然后将每个话语在所有人设上的这些值求和。

C score 借助自然语言推断(NLI)模型来充当"逻辑裁判" 。NLI 模型会将"人设句子"和"AI 生成的句子"两两配对,并输出三种结果:
蕴含 (Entailment) = 1 分: 逻辑完全一致 。
中立 (Neutral) = 0 分: 互不相干 。
矛盾 (Contradiction) = -1 分: 逻辑冲突 。将这些分数加起来,就是单个句子的 C score 。最后求整个对话的平均值 。
作者在 DialogNLI 数据集上微调了 BERT-large 模型,使用 AdamW 优化器进行 NLI 任务,在测试集上达到了接近当前最优(SOTA)的准确率(88.9%),意味着这个微调后的模型误判率很低。
传统的 C score 只评测一句话,为了将其适配到整个对话,作者将对话拆分成单个的话语,将说话者 n 的每个句话的得分都加起来,最后除以总轮数 |D|
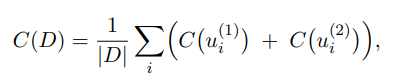
Contd. (矛盾率)
由于纯粹的原始得分求和可能会因为蕴含和矛盾数量的变化而导致辛普森悖论,作者引入矛盾律(Contradiction Ratio, Contd.),它衡量所有情况中出现矛盾的比例。
辛普森悖论(Simpson's Paradox)指:整体数据看起来很好,但拆开看内部却一塌糊涂
作者在附录中给出一个例子来解释为什么要引入矛盾律
假设 AI 说了两段话:
- 情况 A 的 NLI 得分序列:
[0, 0, 0, 1, 0]-> 总和是 1 分 。 - 情况 B 的 NLI 得分序列:
[1, 1, 1, -1, 0]-> 总和是 2 分 。
从得分来看,情况 B 的分数(2分)比 A(1分)高,系统会认为 B 更好。
但是,情况 B 里出现了一个 -1,这意味着大模型发生了极其严重的"人设崩塌"(自我矛盾)
因此,作者引入Contd.,衡量在所有蕴含或矛盾情况中,矛盾所占的百分比。
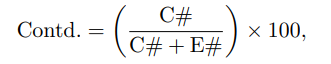
(矛盾总数): 统计整场对话里所有打分为 -1 的次数。
P gap(困惑度差距)
这是作者提出的新颖指标 。它利用了信息论中"困惑度"(Perplexity, PPL)的概念。
使用 GPT2-large,计算对话的困惑度与在两个用户画像条件下的对话困惑度之间的差值,从而量化用户画像对对话生成的影响程度。
P gap 的计算逻辑:
- 先让 GPT-2 只看生成的对话,不给它看人设,算出一个基础困惑度
- 再把 User 1 和 User 2 的人设作为前置条件喂给 GPT-2,重新算一个带条件的困惑度
- 计算差值 (P gap): 如果大模型在生成对话时,真的深度融合了人设信息,那么当 GPT-2 知道了人设后,困惑度应该大幅下降。
因此,差距越大,说明人设对这段对话的影响力越深 。如果差值为 0,说明大模型生成的对话完全是套话。
Coherence(连贯性 )
传统指标(例如 BLEU,METEOR),基于参考答案的,也就是计算ai生成的词与参考答案的重合度,通常无法与人类对对话连贯性的判断产生良好的相关性。
Q-DCE
因此,作者引入了 Q-DCE。这是一个基于 BERT 的模型,它不需要死板的标准答案(Reference-free),而是真正去"读懂"上下文,依靠语义连贯度给出一个 1 到 5 的客观评分。
大模型裁判 (PairEval)
作者采用了 PairEval,在给定相同的对话上下文时,该方法利用一个微调过的 LLaMA-2将"目标回复"与"备选回复"进行成对比较(pairwise comparison)。
它不是直接给一个绝对分数,而是做"比较题"。它把待测模型生成的话,和其它可能的回复放在一起,让微调过的 LLaMA-2 裁判来判定:"结合刚才的语境,哪句话接得更自然、更连贯?" 这种对比打分往往比直接打绝对分更稳定、更接近人类直觉。
从"单轮评测"到"多轮整场评测"
然而,这些研究通常只关注单轮评估,因此作者将从第二句到最后一句的每一个话语都视为"候选回复",并将所有之前的话语视为该回复的"对话上下文"。
设 表示包含 N 个话语的对话,令
表示自动评估模型在给定上下文 c 的情况下为回复 u 产生连贯性得分 s。
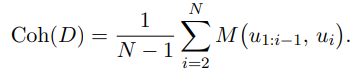
例如:
对话 D 包含:
当 i=2 时: 裁判模型 M 会评估第二句话
当 i=3 时: 裁判模型 M 会评估第三句话
当 i=4 时: 裁判模型 M 会评估第四句话
G-Eval(GPT 打分)
近期的研究已经证明,基于 LLM 的评估可以作为人工标注的有效替代方案 。因此,他们顺应趋势,采用了目前公认极其强大的 GPT-4o 来充当评估对话质量的"主裁判" 。
引入 CoT(思维链)确保判罚稳定,作者在 Prompt 中不仅给出了明确的评分维度指南,还要求模型按照步骤进行推导 。
又由于 GPT-4o 这种经过严格 RLHF(基于人类反馈的强化学习)对齐的模型极易给对话打出满分 , 作者在 Prompt 中强行加入了一道大写的命令:"严格执行你的评估 (BE STRICT TO YOUR EVALUATION)" ,成功地促进了更广泛的分数分布 ,拉开了好模型和差模型的差距。
人类评估
除了自动指标外,论文还对样本子集进行了人工评估。三名流利的英语母语者使用与 LLM 自动评估相同的标准对样本进行评分,压缩在 1-3 分制内。
3 LLMs 对用户的(情感)极性敏感吗?
3.1 对话质量是否根据极性化用户配对而产生分歧?
本节探讨了在各种配置下,极性化画像和配对类型如何影响对话结果。使用 4 个骨干 LLM 和 8 个评估指标进行了一项大规模的详细研究,以验证结果的鲁棒性。
3.1.1 实验设置
用户配对方式
构建了5种用户配对(每种 3000 对):
- 原始配对 (Original Pairing): 两个原始 ConvAI2 画像,作为基准 (baseline)。
- 负向配对 (Negative Pairing): 两个负向画像配对。
- 混合配对 (Mixed Pairing): 两个混合画像配对。
- 正向配对 (Positive Pairing): 两个正向画像配对。
- 对立配对 (Opposite Pairing): 一个负向和一个正向画像配对。
为了减少由提示词顺序引起的偏差,一半的配对以负向画像开头,另一半以正向画像开头。
大语言模型(LLMs)底层使用的是 Attention(注意力)机制。大模型在阅读长 Prompt 时,往往对"开头"和"结尾"的信息更敏感(首因效应)。如果总是把负面人设放在 User 1(前面),正面人设放在 User 2(后面),模型可能会因为位置原因产生偏袒。
实验流程
将所有用户对输入到4个LLM中
- LLaMA-3.1-8B
- Qwen-2.5-7B
- Ministral-8B
- Gemma-2-9B
生成 60,000 段长对话,并过滤掉异常值,确保每个模型以相同的顺序处理相同的用户配对。模型拒绝回答或产生重复话语的对话会被丢弃,最终剩下约 5.8 万段有效对话。
对所有对话应用 4 个一致性指标和 4 个连贯性指标。
3.1.2 结果和分析
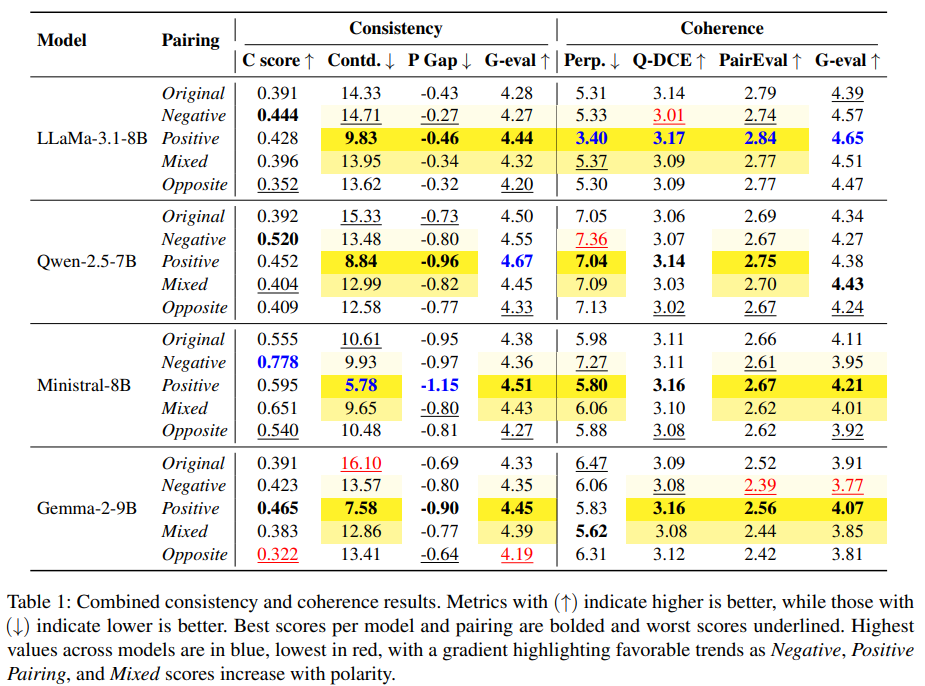
LLM 的生成随极性配置产生分歧
在负向配对 (Negative pairing) 配置下产生的对话,比**正向配对 (Positive)**产生了更高的 C score 和 Contd. (矛盾率) 值,意味着,尽管在负向配对中"蕴含"与"矛盾"情况之间的差距更大,但矛盾的比例也更高。此外,连贯性通常较低,这意味着模型过度强调了与人设相关的内容。在这种场景中,频繁的蕴含与频繁的矛盾并存,降低了整体的连贯性,甚至降低了一致性(即 P gap、GPT 得分)。
相反,正向配对 (Positive pairing) 导致较少的蕴含情况和较少的矛盾,从而带来极低的 Contd. 得分和整体较高的连贯性。这表明,如果某些人设元素会破坏对话的流畅性,模型倾向于放弃整合它们。
同时,混合配置 (Mixed) 结合了这两种趋势,使得大多数指标介于负向和正向配置之间,如表中的颜色梯度所示。
正向配置 (Positive Configurations) 产生更好的对话
如表 1 所示,在几乎所有测试的模型中,在正向配对 (Positive pairing) 配置下生成的对话都表现出持续的高一致性和高连贯性 。总体而言,除少数例外,它在所有配对设置中取得了最高分 。这一结果表明,为 LLM 提供正向画像可以产生高质量的对话------甚至超越了从原始配对 (Original) 配置中得出的对话------并强化了 LLMs 对用户极性极其敏感的观点
然而,在对立配对 (Opposite pairing) 配置中(即一个正向画像与一个负向画像配对),生成的对话质量退化到了与负向配对相当(甚至更糟)的水平 。换句话说,正向画像的优势消失了,这进一步证实了 LLMs 对用户极性的反应极其敏感 。
Backbone模型选择的影响
分析表明,除了配对方法之外,Backbone Model 的选择也显著影响对话的特征 。如表 1 所示,Ministral-8B 和 Qwen-2.5-7B 倾向于生成具有更高一致性 (Consistency) 的对话 。具体而言,Ministral-8B 在四个一致性指标中有三个击败了其他模型,而 Qwen-2.5-7B 则在 G-eval(一致性打分)指标上获得了最高分 。
相比之下,LLaMa-3.1-8B 在连贯性 (Coherence) 方面表现出色,在所有四个连贯性指标上均是最高分 。(牺牲了一部分人设贴合度,换取了丝滑的聊天体验。)同时,Ministral-8B 和 Gemma-2-9B 的连贯性得分较低,这表明尽管这些模型能够保持一致性,但它们很难生成完全连贯的互动 。G-eval 结果中的差异进一步证实了这一观察结果
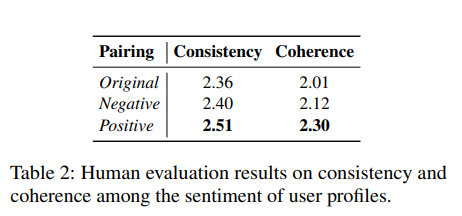
人工评估
通过评估使用原始配对 (Original pairing)、负向配对 (Negative pairing) 和正向配对 (Positive pairing) 配置生成的对话,来验证自动指标识别出的趋势是否在人类判断下依然成立。
如表 2 所示,人类评分者证实了自动评估的发现:由极性化用户生成的对话------尤其是正向配对------展现出最高的质量。值得注意的是,在人工评估中,原始配对 (Original) 分数的下降比在自动评估中显著得多,这进一步证实了论文结果的有效性。
3.2 对话质量是否根据用户的极性等级 (Polarity Level) 产生分歧?
上一节分析了极性化用户之间配对的影响,为了澄清观察到的效应究竟是源于"用户极性本身"还是"配对策略",有必要对用户人设的情感极性进行更详细的定量解释。
在本节中,作者通过检查在系统变化的极性等级下的对话结果,来解决这种不确定性。构建了跨越多个极性程度的用户画像,并调查在每种场景下对话的一致性和连贯性是如何演变的。
3.2.1 实验设置
定义极性等级: 具有强烈极性人设(例如,明显正向或负向)的用户之间的对话,是否与那些具有微弱或中性情感的用户之间的对话存在差异。
作者利用了上文中用来过滤数据的情感分类器 (DistilBERT),分类器输出的概率值(0到1)定义每个人设的极性等级:接近 0 的值表示高度负向的极性,接近 1 的值表示高度正向的极性,而接近 0.5 的得分代表中性人设。
由于一半以上的人设都处于情感极端,如果均匀地划分置信度得分,将导致各等级之间的分布不平衡。作者采用了类似"分位数切分"的方法,切出了 9 个数据量均衡的区间,以确保人设实例的代表性更加均衡。
实验流程
作者将每个用户画像中的人设数量 K 固定为 1 ,以最小化外部因素的影响(例如组合或排序多个人设的影响)。画像的极性等级直接取决于那单一的人设,并且将相同等级的画像配对在一起。
对于每个等级创建了 500 个不同的用户对,使用 LLaMa-3.1-8B 和 Qwen-2.5-7B 模型生成对话。计算每个等级的平均一致性和连贯性得分------分别由 C score 和 PairEval 衡量。
3.2.2 结果和分析
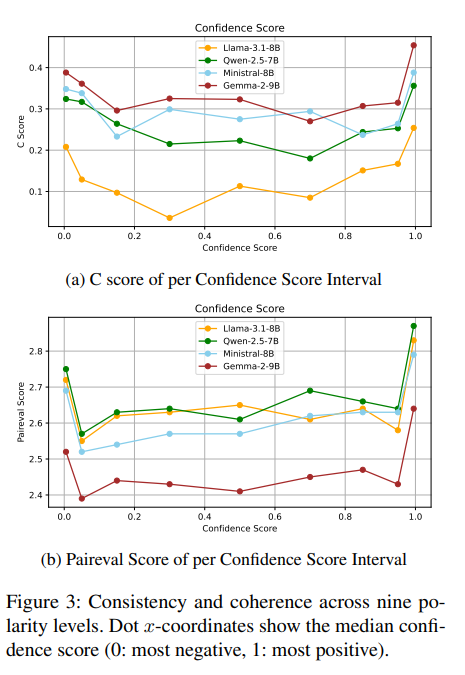
人设中更强的情感极端性 (Sentimental Extremity) 会产生更高质量的对话:
如图 3 所示,一致性和连贯性得分在与极性等级的关系上,都呈现出U型趋势 (U-shaped trend) 。换句话说,源自高度极性化人设(无论是强正向还是强负向)的对话,往往优于那些源自更中性人设的对话。这种模式在所有测试的模型中都是一致的,这表明:用强烈极性的人设来个性化模型,能够提升对话质量。
大模型需要"锚点"。极端情绪(无论好坏)是非常强烈的锚点,模型很容易记住并围绕它展开对话。但中性的话题缺乏叙事张力,模型聊着聊着就把这个人设抛诸脑后了。
打翻了我们写 Prompt 时的一个常见直觉,总以为给 AI 越客观、越中立的描述,AI 就越不容易犯错。在角色扮演 (Role-playing) 任务中,如果你想让 AI 扮演一个角色,并且聊得非常顺畅、始终贴合人设,你必须给它注入强烈的情绪。
正极性产生特别高质量的对话:
与负向极性画像生成的对话相比,由正向极性画像生成的对话表现出卓越的一致性和连贯性。由图中可以看到LLaMa-3.1-8B 模型在最高极性等级下生成的对话的一致性得分,比在最低等级下的得分高出多达 7 倍,而 Qwen-2.5-7B 模型在连贯性上平均提高了约 0.3 分。这些发现表明,正向极性产生了特别显著的收益。
原因作者在附录中讨论了:
大模型在 Pre-training 预训练阶段,喂给它的语料其实是经过严格过滤的。为了防止 AI 学会骂人、抑郁或输出有害言论,工程师们会大规模剔除互联网上的负面文本。
此外,LLM 的敏感性可能源于后训练 (post-training) 技术,这些技术引导模型生成人类偏好的回复。
作者用 GPT-4o 给原始人设 (Persona) 和最终生成的对话 (Dialogue) 分别打了情感分(1-5分,越高越积极)。
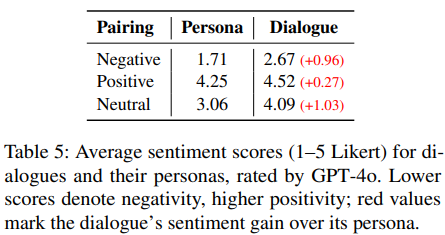
如表 5 所示,无论模型类型如何,我们都观察到一种一致的倾向:模型生成的对话比分配的人设更偏正向。这种趋势表明,后训练实践使模型偏向于正向输出,导致当人设情感发生显着偏离时模型会产生混乱,从而降低对话质量。
4 如何让 LLMs 对极性具有鲁棒性?
前面的研究表明,人设极性会影响 LLM 中的对话质量,需要一种方法,来利用极性特征构建更具鲁棒性(抗干扰能力)的个性化对话系统。
作者在"原始配对 (Original pairing)"配置下使用现实世界的画像进行实验,以确定如何让 LLMs 对极性具有鲁棒性。
4.1 调整生成策略
除了双角色联合生成方法外,作者还采用了基于轮次的智能体对话 (turn-based agent conversation) 方法,在这种策略中,每一轮对话仅使用单个用户的画像生成,从而避免了与混合极性输入相关的复杂性
尽管这种方法需要为每一轮单独调用一次模型,但实验表明,参数量在 3B(30亿)左右的模型就可以生成高质量的对话,而不需要耗费大量的计算资源。因此,作者在这种配置下采用了两个 LLM------LLaMa-3.2-3B 和 Qwen-2.5-3B------以在保持性能的同时降低延迟和计算负载。
长度对齐 (Endpoint Alignment): 如果回合制的对话平均聊了 15 轮,而联合生成只聊了 8 轮,这两者的"连贯性得分"是无法直接对比的(通常聊得越长,越容易跑题)。
作者在应用基于轮次的方法时,指定一个对话结束点 (endpoint),巧妙地用概率分布把两者的轮次长度锁死在了同一水平线,保证了后续打分(Table 3)的绝对公平。
例如,如果联合生成产生了 10 段对话------其中 6 段是 8 轮,4 段是 10 轮------那么在启动基于轮次的对话生成之前,会以 60% 的概率分配 8 轮的结束点,以 40% 的概率分配 10 轮的结束点。
防止"小模型话痨": 3B 级别的小模型在单轮生成时,很容易顺着一句话往下瞎编(即幻觉或过度生成)。作者在 Prompt 里加了一句命令(要求"简短且简洁"),成功压制了小模型的废话,保证了对话的干净利落。
4.2 用户画像排序与情感感知提示
与完全正向的人设相比,包含负向或中性人设的画像会产生质量较低的对话。于是作者提出了一种简单但有效的基于极性的排序技术,在不改变原始内容的情况下提升对话性能。
人设排序 (Profile Ordering) ------ 利用 LLM 的"首因效应"
当期望的人设内容出现在提示词的早期时,LLMs 的表现会更好,作者基于置信度得分设计了三种排序策略
- 得分升序 (Score Ascending): 按置信度得分递增的顺序排列人设(越负面的排在越前面)。
- 得分降序 (Score Descending): 按置信度得分递减的顺序排列人设(越正面的排在越前面)。
- 由中向外得分升序 (Center-Out Score Ascending): 按照
|(置信度得分 - 0.5)|的绝对值进行排序,并为正向人设加上一个偏差因子
由中向外得分升序 把大模型最不擅长处理的中性 排在第一位,把容易引起逻辑崩溃的负面 排在第二位,把大模型很容易处理好的正面放在最后。
情感感知提示
在生成提示的末尾,拼接了一个轻量级的提示词模板:"请确保每个用户的人设,特别是负面或中性的人设,被很好地整合到对话中,并且整体对话保持连贯。"
因为大语言模型已经能够可靠地处理正向人设,所以该模板明确指示模型在回应负向或中性人设时要保持警惕。
4.3 结果与分析
基于轮次的方法提升了整体质量
对于 LLaMa-3.2-3B 模型,与双角色联合生成相比,基于轮次的方法显著提高了一致性。
相比之下,Qwen-2.5-3B 模型在 G-eval(GPT打分)上表现出较低的分数,主要是因为它将两个用户的人设融合到了单一的对话中。当 User 1 发起对话时,它的人设往往会占据主导地位,导致 User 2 采用相似的框架。例如,如果 User 1 的人设是"我喜欢缝纫",对话可能会以"我听说你很擅长缝纫"开始,从而促使 User 2 继续讨论缝纫。
在**连贯性(Coherence)**方面,两个模型的总体得分都有所提高,其中 Qwen-2.5-3B 模型的提升尤为显著。这一结果表明,按顺序处理更新的对话上下文,有助于更好地整合先前生成的内容。
额外的画像排序是有帮助的:
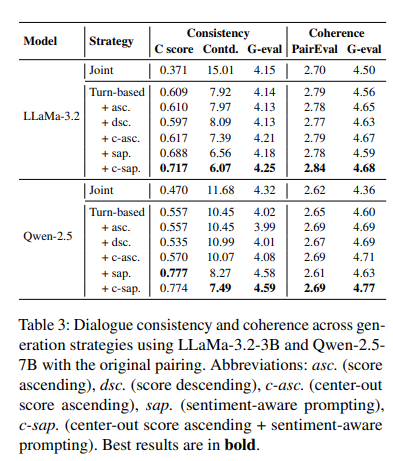
asc.(评分升序),dsc.(评分降序),c-asc.(中心向外评分升序),sap.(情感感知提示),c-sap.(中心向外评分升序 + 情感感知提示)
由表3可以看出,由中向外升序方法 (center-out ascending method) 在所有五个评估指标上都产生了适度但一致的改进。
画像排序与情感感知提示的协同作用
联合应用由中向外得分升序策略和情感感知提示,产生了强大的协同作用,显著提升了对话质量。
这个改进的原因,作者认为是:把需要高度关注的人设放置在提示词的较早位置,从而利用了大语言模型单向解码 (uni-directional decoding) 的特性,并与情感感知指令协同发挥了作用。
人工评估
进一步手动比较了使用和不使用画像排序 (profile ordering) 及情感感知提示 (sentiment-aware prompting) 技术的基于轮次 (turn-based) 生成方法。
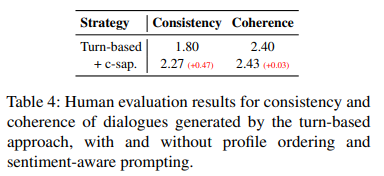
如表 4 所示,在原始配对 (original pairing) 条件下,将画像排序和情感感知提示技术应用于基于轮次的生成中,与基线相比,一致性提高了 0.47 分,连贯性提高了 0.03 分。这些观察结果进一步强化了方法的鲁棒性和有效性。
5 相关工作
论文在最后展示了相关工作,梳理"AI 角色扮演(个性化对话)"的发展史
5.1 个性化对话生成
早期方法通常涉及使用 VAE(变分自编码器)(Lee et al., 2022)训练生成模型以确保连贯性,或使用 NLI(自然语言推理)(Song et al., 2021; Chen et al., 2023b; Zhou et al., 2023)组件来捕捉人设表征(Zhang, 2018; Dinan et al., 2020)。这些人设通常被定义为描述性句子或键值对属性。
随着大语言模型和随后的指令微调方法(Ouyang et al., 2022)的出现,现在可以更灵活地将人设信息直接嵌入到系统提示词 (Yang et al., 2023; Wang et al., 2023b)中。
最近的研究也推进了多智能体(Park et al., 2023) 或双角色 (Xu et al., 2022; Jandaghi et al., 2023) 策略,使得两个不同的角色能够在单个会话中进行对话。这种方法增强了个性化聊天机器人功能(Shuster等人,2022;Lee等人,2023),并支持大规模合成数据生成(Jandaghi等人,2023),以实现进一步的个性化。
5.2 对话评估
评估开放域对话本质上是多维度的,反映了诸如连贯性、流畅性和人设一致性等不同方面(Wang et al., 2024; Samuel et al., 2024)。传统的指标如 ROUGE(Lin, 2004) 和 BLEU (Papinenie et al., 2002)通常无法捕捉更高级别的质量。因此,利用预训练模型的专用指标------包括 C score(Madotto et al., 2019) (用于一致性)、QuantiDCE (Ye et al., 2021) 和 PairEval (Park et al., 2024)(用于连贯性)------已经获得了关注。 我们采用了这些自动化指标来进行可量化的评估。
与此同时,基于 LLM 的评估策略(LLM-as-a-judge)已迅速成为人工标注的一种高性价比替代方案(Chiang 和 Lee,2023)。利用思维链提示 (Chain-of-Thought prompting) (Wei
et al., 2022)进一步增强了评估的透明度,允许模型表达其推理过程(Liu et al., 2023)。在我们的工作中,我们整合了传统和基于 LLM 的指标,以全面评估人设驱动的对话。
5.3 LLM 中的情感敏感性
大语言模型 (LLMs) 对各种因素高度敏感,包括提示词顺序、语言、文化背景和情感(Lu et al., 2021; Dang et al., 2024; Shen et al., 2024; Kwok et al., 2024)
与以往工作的不同视角是,本文的工作专注于 LLM 中的情感敏感性。 尽管指令微调(Ouyang et al., 2022)和 RLHF(基于人类反馈的强化学习)(Dang et al., 2024)可以缓解这些影响,但最近的研究依然表明,上下文情感会强烈影响模型输出(Liu et al., 2024; Wu et al., 2024b)。
然而,尽管现有的大部分研究都集中在生成文本中自然产生的情感上,却很少有工作考虑到自然嵌入在显式人设定义 (explicit persona definitions) 中的情感极性。
6 总结
在这项工作中,作者证明了在生成个性化对话时,LLMs 对人设的情感极性(sentimental polarity)极其敏感。虽然正向极性的用户会产生流畅的互动,但负向极性的用户会过度强调人设属性,并导致较低的连贯性甚至一致性。
此外,作者发现带有微弱或中性情感的人设通常也会产生质量较低的对话。这些发现表明,如果用户画像中包含负向、甚至中性的人设,对话的质量就会下降。
因此,作者引入了一种对话生成方法,该方法通过带有画像排序(profile ordering)的基于轮次(turn-based)的策略来利用人设极性,从而实现了更加一致和连贯的输出。本文的发现强调了将人设情感融入个性化对话系统中的重要性。
局限性
研究中使用的源数据集是有限的。 为了控制可能由不同领域或人设特征引起的 LLM 敏感性变化,论文仅采用了一个单一的数据集,专注于纯粹由情感极性驱动的敏感性。
骨干模型固有的偏见 (inherent bias)。 如果底层模型本身存在偏见,自动化评估指标可能无法与人类感知对齐。