图模板
- 图分为有向图和无向图,入度是指向当前节点的边数,出度是当前节点指向其他节点的边数
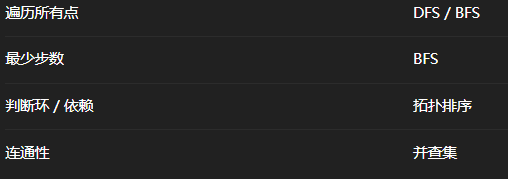
200.岛屿数量
关键信息一句话总结:
遍历网格,遇到陆地就用 DFS / BFS 把整块连通陆地淹掉,并计数
- 方法1:BFS
java
class Solution {
public int numIslands(char[][] grid) {
// bfs是这样的 联想我们之前的二叉树
// bfs一层一层是左右节点延申出去的
// 而这里的图是上下左右四个方向表示一层,所以bfs可以一层一层
int m = grid.length;
int n = grid[0].length;
int count = 0;
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(grid[i][j] == '1') {
bfs(grid, i, j);
count++;
}
}
}
return count;
}
private void bfs(char[][] grid, int i, int j) {
int m = grid.length;
int n = grid[0].length;
Queue<int[]> queue = new LinkedList<>();
queue.offer(new int[]{i, j});
grid[i][j] = '0';
while(!queue.isEmpty()) {
int[] cur = queue.poll();
int x = cur[0];
int y = cur[1];
int[][] dirs = {{1, 0}, {-1 ,0}, {0, 1}, {0, -1}};
for(int[] d : dirs) {
int nx = x + d[0];
int ny = y + d[1];
if(nx >= 0 && nx < m && ny >= 0 && ny < n && grid[nx][ny] == '1') {
queue.offer(new int[]{nx, ny});
grid[nx][ny] = '0';
}
}
}
}
}- 方法2:DFS
java
class Solution {
public int numIslands(char[][] grid) {
int count = 0;
int m = grid.length;
int n = grid[0].length;
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(grid[i][j] == '1') {
dfs(grid, i, j);
count++;
}
}
}
return count;
}
private void dfs(char[][] grid, int i, int j) {
int m = grid.length;
int n = grid[0].length;
if(i >= m || i < 0 || j >= n || j < 0 || grid[i][j] == '0') {
return;
}
// 把当前陆地淹没
grid[i][j] = '0';
// 四个方向搜索
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i + 1, j);
dfs(grid, i, j - 1);
}
}方法3:并查集
1.什么是并查集
并查集 = 用来判断两个东西是不是在同一个集合里,它解决了判断这两个点是不是连在一起的问题
java
class Solution {
public int numIslands(char[][] grid) {
int m = grid.length;
int n = grid[0].length;
UnionFind uf = new UnionFind(m * n);
int count = 0;
// 1.统计所有'1'
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(grid[i][j] == '1') {
count++;
}
}
}
// 2.合并相邻的'1'
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(grid[i][j] == '1') {
// 有i行 每行n个 所以 i * n 在j列 所以 i * n + j 二维变一维
int index = i * n + j;
// 向下和向右已经包括了所有的覆盖情况 因为我们是从高到低 从左到右遍历的 联想八皇后!
// 向下
if(i + 1 < m && grid[i + 1][j] == '1') {
// 将这个index所在的数 与它下面一个数进行合并
if(uf.union(index, (i + 1) * n + j)) {
count--;
}
}
// 向右
if(j + 1 < n && grid[i][j + 1] == '1') {
if(uf.union(index, i * n + j + 1)) {
count--;
}
}
}
}
}
return count;
}
class UnionFind {
// parent的index表示本身的值 value表示指向父集合 其实就是 index 最终属于 value
int[] parent;
public UnionFind(int n) {
parent = new int[n];
for(int i = 0; i < n; i++) {
parent[i] = i;
}
}
// 找到最终的父集合并且把路径全部指向最终的父集合
public int find(int x) {
if(parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// 合并两个集合
public boolean union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if(rootX == rootY) {
return false;
}
parent[rootX] = parent[rootY];
return true;
}
}
}- 反思:我没有想到图的遍历需要用dfs和bfs进行搜索,连通性问题、集合合并问题可以用并查集
994.腐烂的橘子
关键信息一句话总结:
多源 BFS,扩散一层就是一分钟
java
class Solution {
public int orangesRotting(int[][] grid) {
// 多源bfs 区别于岛屿对时间无要求 每个都bfs就好了
int count = -1;
int m = grid.length;
int n = grid[0].length;
Queue<int[]> queue = new LinkedList<>();
int fresh = 0;
for(int i = 0 ; i < m; i++) {
for(int j = 0; j < n; j++) {
if(grid[i][j] == 2) {
queue.offer(new int[]{i ,j});
}
if(grid[i][j] == 1) {
fresh++;
}
}
}
if(fresh == 0) {
return 0;
}
while(!queue.isEmpty()) {
int size = queue.size();
// 每一层算1分钟 刚开始不算 从0分钟开始
count++;
for(int i = 0; i < size; i++) {
int[] cur = queue.poll();
int x = cur[0];
int y = cur[1];
int[][] dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
for(int[] d : dirs) {
int nx = x + d[0];
int ny = y + d[1];
if(nx >= 0 && nx < m && ny >= 0 && ny < n && grid[nx][ny] == 1) {
grid[nx][ny] = 2;
fresh--;
queue.offer(new int[]{nx, ny});
}
}
}
}
if(fresh > 0) {
return -1;
}
return count;
}
}- 反思:我没有抓住它对时间的要求,需要同时多源进行bfs,而200题不需要多源进行,只需要延申就行了
207.课程表
关键信息一句话总结:
用拓扑排序判断有向图中是否存在环
java
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 本质:判断有向图是否存在环
// 1.建图
List<List<Integer>> graph = new ArrayList<>();
for(int i = 0; i < numCourses; i++) {
graph.add(new ArrayList<>());
}
// 2.入度数组
int[] indegree = new int[numCourses];
// 3.构建邻接表和入度
for(int[] p : prerequisites) {
int a = p[0];
int b = p[1];
// b这个节点是a的前置
graph.get(b).add(a);
// a的前置(入度: 指向该节点的边的数量) +1
indegree[a]++;
}
// 4.把所有入度为0的课程入队
Queue<Integer> queue = new LinkedList<>();
for(int i = 0; i < numCourses; i++) {
if(indegree[i] == 0) {
queue.offer(i);
}
}
// 5.拓扑排序
int count = 0;
while(!queue.isEmpty()) {
int cur = queue.poll();
count++;
for(int next : graph.get(cur)) {
indegree[next]--;
if(indegree[next] == 0) {
queue.offer(next);
}
}
}
return count == numCourses;
}
}- 反思:我没有建模成功,建模成判断图中是否存在环,应该用拓扑排序
208.实现Trie前缀树
关键信息一句话总结:
把字符串拆成路径存进树里,用共享前缀实现高效查找与前缀匹配
- 分析:isEnd用来标记是否是单词的结尾,因为app和apple有共享前缀
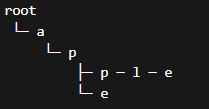
java
class Trie {
class Node {
Node[] children = new Node[26];
boolean isEnd;
}
private Node root;
public Trie() {
root = new Node();
}
public void insert(String word) {
Node node = root;
for(char c : word.toCharArray()) {
int index = c - 'a';
// 只要 new 过一次 这个 if 以后永远是 false
if(node.children[index] == null) {
node.children[index] = new Node();
}
node = node.children[index];
}
node.isEnd = true;
}
public boolean search(String word) {
Node node = find(word);
if(node != null && node.isEnd) {
return true;
}
return false;
}
public boolean startsWith(String prefix) {
if(find(prefix) != null) {
return true;
}
return false;
}
private Node find(String s) {
Node node = root;
for(char c : s.toCharArray()) {
int index = c - 'a';
if(node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/- 反思:我没有想到共享前缀这个关键点,我认为用一个数组或者链表就能完成,然而要保证前缀,所以有共享前缀,不同分支,所以就有了链表 + 哈希表