接到一个Golang后端工程师的面试邀请,对方是做IM消息相关的业务,在之前的工作项目里有消息队列中有相关经验,也整理了一些资料,重新回顾一下消息推送的整理架构方案,温故而知新。当时我的技术实现方案是swoole + websocket 设计和实践的,接下来我分别梳理有关的知识点,生产环境实际用户360w+ , 活跃PV 30w+ ,峰值集中在每晚20-24点之间,运行消息队列的服务器4c8g的云服务实例。
一、数据表设计
设计两个数据表,消息表(user_message_status)、用户消息状态表(user_message_status),为每个用户维护一个 已读系统消息的最大 ID,当用户上线或刷新时,根据该 ID 从数据库拉取所有未读的系统消息,也可以用来统计用户的未读消息数。
下面是消息表和消息用户消息状态表的数据表结构表:
sql
CREATE TABLE `system_message` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '消息ID',
`content` text NOT NULL COMMENT '消息内容',
`type` tinyint(4) NOT NULL COMMENT '消息类型:1-系统公告,2-用户',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '状态:1-有效,0-已删除',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_status_create_time` (`status`, `create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统消息表';
CREATE TABLE `user_message_status` (
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`last_read_sys_msg_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '已读的最大系统消息ID',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`user_id`),
KEY `idx_last_read_id` (`last_read_sys_msg_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户消息状态表';为什么这样设计?
system_message只存一份,节省大量存储空间,也避免修改内容时需要更新所有副本的难题。user_message_status只存有状态变更的记录。如果一条新消息发出,10万用户全是未读,那就不需要立即插入10万条"未读"记录,这是优化性能的关键。
二、消息模型
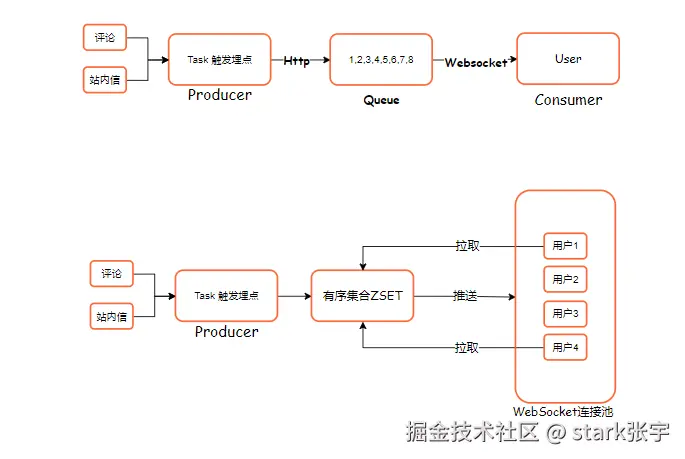
1、生产者-消费者模型(图1-上)
针对用户的个人提示,比较简单和易于实现,在用户的评论、作者动态、评论等操作下使用触发埋点任务,通过Swoole提供的Http部分,把消息存储在Redis的消息队列中,队列的数据结构保证了排列有序,在用WebSocket 推送给已经建立链接的用户,用户界面上有小红点提示,表示有更新。
还有一部分用户离线或者是断开的情况,断开的时候,用户主动重试进行数据拉取,读取未读的消息,以确保消息被成功接收。
设计特点:
- 在实际的工作中尽量使用最简单的架构实现方案,来实现业务要求,解决业务问题,降低后期维护成本。
- 服务都部署在云服务中,实现了局域网网络通信,以保证高性能、简单和安全,和Rpc通信比较类似。
- 这种业务场景对消息队列的实时性不高,做到性能和功能的平衡。
2、发布 - 订阅模型(图1-下)
在站内信类型中有一种特殊的业务场景,站内消息,发送一个站内消息,需要将一份消息数据分发给多个消费者,要求每个消费者都能收到全量的消息,我们不能把同一个消息发送300w次,既浪费了资源也造成了难以维护。
每当用户进行WebSocket进行连接成功时, WebSocket 连接池中的所有在线用户存储在Redis的有序集合(ZSET)中,这个有序集合(ZSET)就属于消息的订阅者,有序集合的特点在于数据结构中每个元素带一个 score(通常为时间戳),支持按分数范围操作,适用于需要按时间顺序处理、批量删除或分页扫描的场景,可维护性、扩展性都非常友好和便捷。
在Task任务中新增系统消息时,发送方就自然转换成发布者 角色,这里面的通信过程就是消息的 发布 - 订阅模型,多用户这种场景。
三、推拉策略
1、分批执行
当时使用的是 Crontab 来实现和执行定时脚本处理 消息队列中的数据,设计方案为快慢2条双队列结构,快队列主要处理当前最新的消息,如果用户超过1天不上线,放入延迟队列执行,用户超过超过15天未登录,消息释放。
WebSocket的心跳时间是300s,所以 Crontab 4min,执行一次,延迟队列6分钟执行一次,我们的redis使用的是链接池单节点特点,整个服务都在依赖,所以这样设计的方案,为了尽可能的节省资源,把时间窗口内的时间区域里对用户进行分组,避免相同消息进行重复推送。
2、实时推送 + 离线兜底
为了更好的优化性能,增强体验,在程序设计上线上实时推送给WebSocket 连接池中的所有在线用户,推荐采用 "推送 + 拉取" 模式:WebSocket 只推送一个轻量级的 {"event":"system_msg", "msg_id":123},客户端收到后自行请求 /api/messages/unread 获取完整内容。这样推送的负载极小,能轻松应对全量在线用户。
在用户打开App时,会主动连接WebSocket服务,进行未读消息拉取,已达到性能和功能的平衡。
四、可靠交付
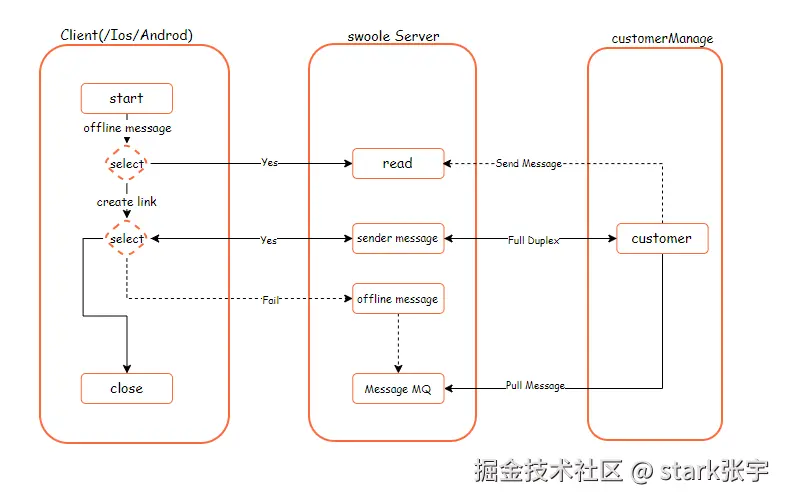
随着业务场景的升级和多样性,在我开发的消息系统里还有这样一个场景,一个是消息体形式丰富、一个是客服IM对话,需要保证服务数据的实时性和完整性,主要解决的数据包的可靠准确的传递,让我在Tcp协议上得到了启示,tcp的可靠交付主要有以下3点:
1.解决不丢包问题:Ack + 重试
网络丢包是一定会出现的,对上层应用来说,只有一个办法就是不停的重发,服务器每次收到一个包,就要对客户端进行确认,反馈给客户端已经收到了数据包,如果客户端在超时时间内没有收到Ack,则重发数据。
在确认的时候,Ack每个数据包都要一一确认,效率太低了,客户端对发送的每个数据包编一个号,编号由小到大单调递增,基于编号就能进行确认。
2.解决不重的问题
因为只要超过了约定时间,客户端还没有收到服务器的确定,客户端就会重发,顺序Ack,服务器给客户端回复Ack=6,意思是所有小于等于6的数据包都收到了,之后凡在收到这个范围的数据包,则判定为重复的包,服务器收到后丢弃即可。
3.解决时序错乱的问题
假设服务器收到了数据包1,2,3,回复客户端(Ack=3),之后接收到5,6,7,而数据包4迟迟没有收到,这个时候怎么办呢?
服务器会把数据包5,6,7暂时存放,直到数据包4的到来,再给客户端回复Ack=7,如果数据包不来,服务器的Ack进度会一直停在那(保持Ack=3),等客户端超时,会把数据包4,5,6,7,全部重新发送,这样服务器收到了数据包4,回复ack=7,同时数据包5,6,7重复了,通过上面说的判重的办法,丢弃到上面的5,6,7。
设计思路和实践:
- 唯一请求 ID序列号 :客户端为每个请求生成唯一 ID,服务端记录已处理的 ID,实现幂等性,防止重复处理。
- 同步 ACK 响应 :服务端处理成功后,必须返回一个明确的确认信息(如
{ "status": "ok", "requestId": "xxx", "resourceId": 123 })。客户端收到此 ACK 后,才认为数据已可靠送达。 - 超时重试:客户端在超时或收到非确认响应时,使用相同的请求 ID 重试,直到收到 ACK 或达到最大重试次数。
- 持久化存储:服务端在确认数据已安全存储(数据库、消息队列等)后才返回 ACK,确保数据不因服务重启而丢失。
五、紧急处理
一般在新服务上线后都需要磨合期,尤其是采用新技术后多注意观察,在服务上线半个小时后,因为推送把主站的Mysql干挂了,最主要是没有进行Redis缓存,在高并发的场景下,没有缓存等于裸奔,根本扛不住,我当时觉得Swoole具有异步、协程这种高级特性是可以顶住的,后果就是很严重,现在想想也特别感谢伙伴们对我的包容,让我有了飞速的成长。
1、并发锁 相同用户在同一时间有3s的锁定状态,用来防止关系错乱,在客户端发来请求时优先获取缓存,近少可能的访问数据库,提高服务的稳定性和性能。
php
//设置分布式锁,3s之内只能请求一次
$lock = RedisPool::invoke(function (Redis $redis) use ($toUid) {
return $redis->get(Category::$openLock . $toUid);
}, self::REDIS_CONN_NAME);
if ($lock) {
$msgErrorRet['code'] = 416;
$msgErrorRet['msg'] = 'Please try again';
return $this->response()->setMessage(json_encode($msgErrorRet));
}
//查询是否存在链接关系
$imUserRelation = RedisPool::invoke(function (Redis $redis) use ($toUid) {
$redis->setEx(Category::$openLockPrefix . $toUid, 3, $toUid);
return $redis->get(Category::$imUserRelationName . $toUid);
}, self::REDIS_CONN_NAME);2、网络异常处理,回收服务:针对App崩溃、网络异常断开的链接,主动监听断开的fd,进行关系处理,对所有断开链接的websocket,进行回收,清除关系。
php
static function onClose(\swoole_server $server, int $fd, int $reactorId)
{
$info = $server->getClientInfo($fd);
$fd = intval($fd);
if ($info && $info['websocket_status'] === WEBSOCKET_STATUS_FRAME) {
TaskManager::getInstance()->async(function () use ($fd) {
RedisPool::invoke(function (Redis $redis) use ($fd) {
//回收用户
$uid = $redis->hGet('PUSH_MSG_SOCKET_FD', $fd);
if (isset($uid) && !empty($uid) && is_numeric($uid)) {
$redis->zRem('PUSH_MSG_USER_LOGIN', $fd);
//检测是否有客服关系未断开
$redis->del(Category::$imUserRelationName . $uid);
$redis->hDel('PUSH_MSG_SOCKET_FD', $fd);
}
//回收客服管理用户
$cUid = $redis->hGet('PUSH_CUSTOMER_MSG_SOCKET_FD', $fd);
if (isset($cUid) && !empty($cUid)) {
$redis->zRem('PUSH_CUSTOMER_MSG_USER_LOGIN', $fd);
$redis->hDel('PUSH_CUSTOMER_MSG_SOCKET_FD', $fd);
}
}, 'redis');
});
}
}3、发散缓存,防止雪崩:为了防止缓存雪崩(雪崩就是指缓存同一时间到期),用户访问峰值是晚间21-24点这个时间段,峰值大概100w/请求,持续4个小时左右,但因为用户中心的缓存时间为7300s,在7300s的时间里分散释放缓存。
php
$uid = $redis->get($token);
$expireTime = 3650 + rand(1, 3000);
$uid = OAuth::getUserInfo($token);
if (!empty($uid) && intval($uid) > 0) {
//存入缓存时间,过期时间小于 7300s
$redis->setEx($token, $expireTime, $uid);
}
if($uid && $uid > 0){
$key = 'token_'.$uid;
$redis->setEx($key, $expireTime, $token);
}六、压力测试
编程的内核是数学,而测试的本质是计算,专业名词叫容量预估,而测试的大体就是用程序模拟程序,检测程序的正确性,有两个点需要注意,QPS最佳值和系统接收最大值,根据测试数据的反馈,针对测试的现象和反映进行优化。
1、Jmeter Thread Group 线程组设置
jmeter自带的thread group非常简单, 一个thread 代表一个vuser,那么我们如果需要多少用户并发,设置多少线程数即可。ramp-up period, 是多少时间从0个 vuser 上升到您指定的vusers数。从这些参数可以看,非常简单。但不能设置测试的时间,这一点不是特别善解人意。不过还好我们有jmeter plugins, 带的thread group 添加了这个功能。
2、数据准备
随机读取用户表里1000个用户,进行压力测试,构造测试需要的数据(10w条为例),查询最大链接数,检测服务器Mysql链接状态,主要的思考点在于用户访问具有随机性,模拟数据时尽量做到接近真实场景,代码如下:
php
$str = '62210,45783,36209,146502,24599,168338,166511,1917...';
$uidTestArr = explode(',',$str);
foreach ($uidTestArr as $uid){
if(isset($uid) && intval($uid) > 0){
$json = file_get_contents('http://open.stark.com/login/gettoken?uid='. $uid);
$json = json_decode($json,true);
$temp[] = [ 'uid' => $uid , 'token' => $json['token'] ];
}
}
$index = rand(0,count($temp) - 1);
$randData = $temp[$index];
//随机执行结果
/**
Array
(
[uid] => 166511
[token] => f46540f11a40afeb9998cbe76661ec8234a87054
)
*/Crontab的测试代码Demo,先灌入测试数据,考虑的是Crontab的实际吞吐能力,优化计划任务的执行间隔,使用Curl和shell_exec实现,执行结果,返回数据 {"code":200,"result":[],"msg":"OK"}
php
$str = "62210,45783,36209,146502,24599,168338,166511,1917,135799,8326...";
//去掉可能存在的换行和空格
$str = str_replace(array(PHP_EOL, ' ' ,'',$str));
$testUsers = explode(',',$str);
for ($i=0;$i<10000;$i++){
$index = rand(0,99);
$uid = $testUsers[$index];
$msg = '{
"rid": 225,
"uid": "",
"top_rid": 225,
"module": "novel_chapter",
"module_name": "1022 last dance 第13章",
"module_id": 1019712,
"module_nid": 163961,
"comment_uid": 268,
"comment_nickname": "测试小宝贝",
"content": "你好呀",
"gift_id": 0,
"gift_name": "",
"gift_number": 0
}';
$url = 'http://msgdev.stark.com/api/comment/message';
$json = shell_exec( "curl -d 'uid={$uid}&msg={$msg}' {$url} " );
echo 'i:'.$i.',json:'.$json.PHP_EOL;
}特殊说明有一点事特别需要强调的,不用被所谓的100w或者1000w流量的标题吓倒,比如1000w/h的访问量,Qps就变成了27777/s,每个用户请求的热门接口30个,这才是测试的真相,关键地方使用内存数据库进行加速,障碍就迎刃而解了:
bash
10000000 / 60 / 60 / 30 = 925/s成果
上线2年的时间里,进行了5次升级和优化,活跃用户10w+,最高峰值6w/s,130w/h访问量,是一个非常成功的实践结果。
用最简单的技术实现方式,节省企业成本,减少系统开发和维护成本,提高办公效率才是技术人应该做的事儿,做解决实际复杂业务解决方案并落地的技术人,En。
- 并发链接和并发查询:并发链接只是多消耗一点内存,并发查询才是CPU的杀手。
- 对系统的流量提前进行容量评估,归根结底为计算问题,不管多大的流量最后的解决办法都采用分而治之的策略。
- 手动的效率太低,用程序测试程序。
- 减少不必要的日志写入,以减少磁盘I/O的传输。
- 缓存和Mysql是一种平衡,需要去计算。