文章目录
MyBatis是一款持久层框架,用于简化JDBC的开发,有注解和配置XML文件两种使用方式
持久层:持久化操作的层,通常指数据访问层(DAO),用来操作数据库
连接配置
连接数据库
yaml
spring:
datasource:
url: jdbc:mysql://IP:Port/数据库名?characterEncoding=utf8&useSSL=false
username: 用户名
password: 密码
driver-class-name: com.mysql.cj.jdbc.Driver编写持久层代码
注解
添加Mapper接口
在mapper包中创建持久层接口,需要加上@Mapper注解
java
@Mapper
//程序运行时,框架自动生成接口的实现类对象,并交给Spring的IoC容器管理
public interface XXXMapper {
...
}- MyBatis的持久层接口规范一般都叫XXXMapper
- 在启动类使用
@MapperScan(com.example.project.mapper)可以代替mapper类中的@Mapper注解
XML
配置连接字符串和MyBatis
将.xml文件放到resource的mapper文件夹,并在配置文件中指定.xml文件路径
yaml
mybatis:
mapper-locations: classpath:mapper/*.xml添加mapper接口
java
@Mapper
public interface UserInfoMapperXML {
List<UserInfo> selectAll();
}配置.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mapper接口的全限定名">
...
</mapper>基础操作
打印日志
yaml
mybatis:
configuration: # 配置打印 MyBatis日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl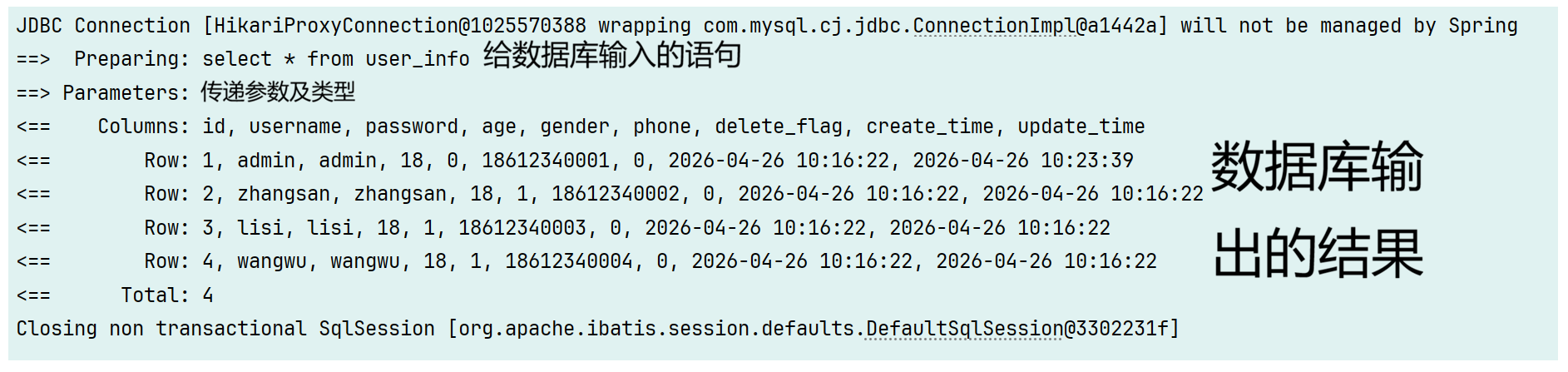
参数传递
使用#{参数名}来动态接收写入SQL语句的参数
java
@Select("select * from user_info where id=#{id}")
List<UserInfo> selectAll(int id); //数据库返回单个结果使用对象接收,返回多个结果使用List接收当方法中接收的对象使用@Param()设置别名时:
java
int insertUser(@Param("UserInfo") UserInfo info);- 接收对象使用#{别名.属性名}
- 接收基本类型
#{别名}
数据库字段与类字段映射
只有当数据库字段与类字段都相同时,才会自动进行映射,名称不相同时有三种映射方法
- 设置别名
- 结果映射
- 开启驼峰命名
使用类字段作为别名
sql
select delete_flag as deleteFlag,create_time as createTime from user_info;结果映射
注解
java
@Results(id = "set1",value = {
@Result(column = "delete_flag",property = "deleteFlag"),
@Result(column = "create_time",property = "createTime")
})后续使用@ResultMap(value = id名)可以对上述代码进行复用
XML
java
<resultMap id="映射的名字" type="类的全限定名">
<id column="字段名" property="属性名"></id> 主键字段
<result column="字段名" property="属性名"></result> 其他字段
</resultMap>
<select id= resultType= resultMap="映射的名字"></select>开启驼峰命名
自动将数据库字段的蛇形命名,转换为小驼峰命名
yaml
mybatis:
configuration:
map-underscore-to-camel-case: true #配置驼峰自动转换返回主键
注解
使用@Options(useGeneratedKeys = true,keyProperty = "参数名")
java
@Options(useGeneratedKeys = true,keyProperty = "id")
//加在@insert注解上方XML
设置useGeneratedKeys和KeyProperty属性
xml
<insert id="接口方法名" useGeneratedKeys="true" keyProperty="属性名">
</insert>CURD
注解
将正常SQL语句中的常量换成动态的参数#{参数名}
可以直接通过对象来传递参数,默认的返回值是受影响的行数
java
@Insert("INSERT INTO mybatis_test.user_info( username, `password`, age, gender, phone )values (#{username},#{password},#{age},#{gender},#{phone})
int insert(UserInfo info);
@Insert、@Delete、@Update、@Select对应的SQL语句使用对应的方法
- useGeneratedKeys:使用JDBC的useGeneratedKeys()方法获取数据库内部生成的主键
- keyProperty:指定Java 实体类中的属性名,将id保存其中
XML
在mapper标签内添加SQL语句,不同类型的语句使用不同类型的标签
xml
<select id="接口中的方法名" resultType="返回值类型,全限定名">
select * from user_info
</select>只有select标签有resultType属性
单元测试
java
@SpringBootTest
// 加上@SpringBootTest注解,该测试类运行时,会自动加载Spring环境
class UserInfoMapperTest {
@Autowired
...
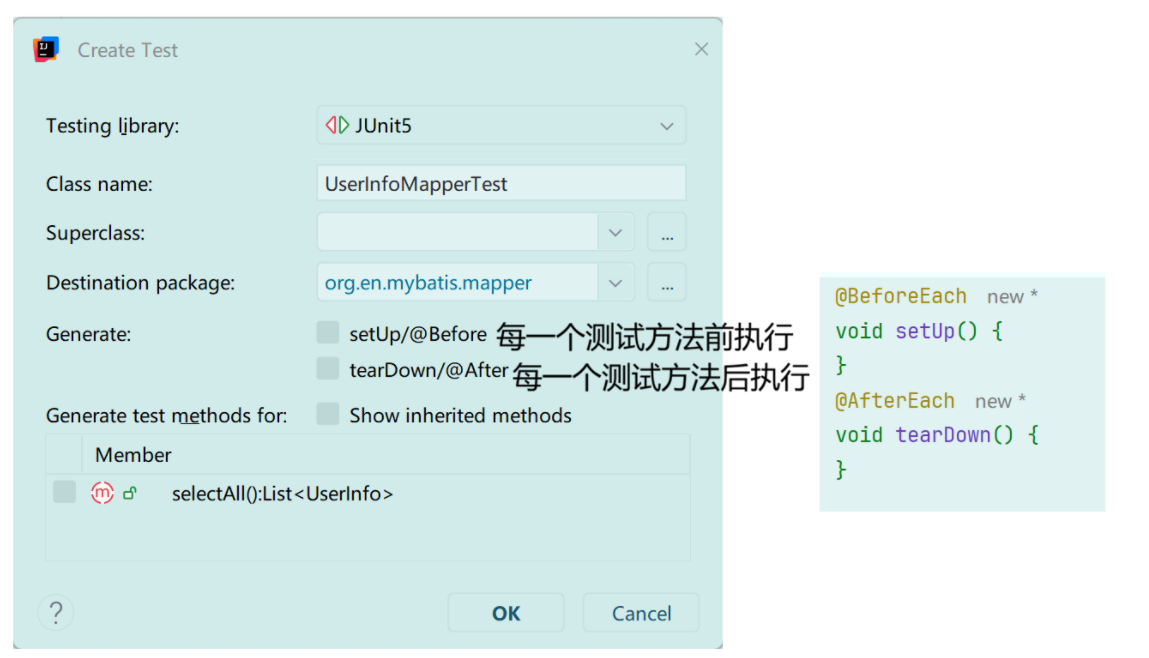
}IDEA自动生成测试用例(Alt+Insert):
#{}与${}
#{}预编译SQL
使用占位符,提前预留位置,会根据参数类型自动拼接引号

-
不是直接的参数拼接,不会发生SQL注入
-
使用like进行模糊查询,使用concat()对字符串进行处理
java
@Select("SELECT * from user_info where username like CONCAT('%',#{username},'%')")${}即时SQL
直接将字符进行替换,不会为字符串自动添加引号

-
直接拼接参数,易发生SQL注入(输入参数不可控)
-
进行排序时,指定排序方式使用
${}
java
@Select("Select * from user_info order by id ${set}")
List<UserInfo> selectUserInfoByDESC(String set);
// ==> Preparing: Select * from user_info order by id desc
// ==> Parameters:- 表名、字段名 作为参数时,使用
${},防止将参数解析成字符串
数据库连接池
每次执行SQL不需要创建新的连接对象,程序启动时会在数据库连接池创建一定数量的Connection对象,执行SQL语句时只需从池中拿取对象,用完后归还连接池
Mybatis默认的数据库连接池是Hikari
动态SQL
通过xml标签,动态拼接SQL
https://mybatis.net.cn/dynamic-sql.html
<if>
本质是SQL语句的拼接 ,当test内的条件为真时,将标签内的语句拼接到SQL内
java
INSERT INTO mybatis_test.user_info( username, `password`, age
<if test="gender!=null">,gender</if>, phone )values
(#{username},#{password},#{age}<if test="gender!=null">,#{gender}</if>,#{phone})test内的gender表示gender参数不为null,所以使用属性名,不能使用数据库字段名
<trim>
- prefix:设置整个语块的前缀
- suffix:设置整个语块的后缀
- prefixOverrides:整个语块要去掉的前缀
- suffixOverrides:整个语块要去掉的后缀
<where>
在子元素中有内容时拼接where,并自动删除整个语块的AND或OR标签。当子元素没有内容时,不会添加where
<set>
在子元素中有内容时拼接set,并自动删除多余逗号,用于update语句。当子元素没有内容时,不会添加set
<foreach>
用于遍历集合
- collection:方法中的参数名
- item:要遍历的对象,自定义名称,代表集合中的对象
- open:整个语句块的前缀
- close:整个语句块的后缀
- separator:每次遍历之间间隔的字符串
- index:当前迭代的序号
<include>
<sql id = "">:对重复片段进行抽取
:对抽取的重复片段进行拼接
xml
<sql id="selectAll">
select * from user_info
</sql>
<select id="" resultType="">
<include refid="selectAll"></include>
where ...
</foreach>
</select><choose><when><otherwise>
类似于Java中的switch-case-default当有多个条件时,只有其中第一个满足条件的生效
xml
<choose>
<when test="">
</when>
<when test="">
</when>
<otherwise>
</otherwise>
</choose><bind>
实现模糊查询时,使用${}易发生SQL注入。在SQL层面进行拼接时,不同数据库拼接字符串的语法不同,代码的可移植性差。使用<bind>可以解决这个问题
name:自定义的变量名
value:用于进行字符串拼接
java
List<UserInfo> selectByName(String name);
<select id="selectByName" resultType="org.en.mybatis.models.UserInfo">
<bind name="flag" value="'%'+name+'%'"/>
select * from user_info where username like #{flag};
</select>bind拿到参数name,拼装成"%name%",然后将"%name%"赋值给flag

缓存机制
MyBatis设计了两级缓存来减轻数据库的查询压力
一级缓存
- 状态:默认开启,且无法完全关闭
- 作用域:在同一个SqlSession中执行相同的SQL查询,第一次查完会将结果放到本地缓存中,第二次直接从数据库中拿
- 失效时机:这个SqlSession中执行了任何一次增删改,或者手动清理缓存
二级缓存
-
状态:默认关闭,在对应的XML文件中加上
<cache/>标签开启 -
作用域:同一个Mapper接口的查询共享这块缓存
开启二级缓存后,被缓存的实体类必须实现
Serializable序列化接口
分页查询
MyBatis原生支持的RowBounds分页是将所有数据都查到内存中在进行截取,数据量过大时会造成内存溢出。所以引入第三方插件PageHelper来实现物理分页(底层自动拼装limit)
依赖引入:
xml
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.6</version>
</dependency>使用:
在执行查询语句前,执行PageHelper.startPage(查询第n页, 每页m条数据),会自动在SQL语句末尾加上limit n,m
也可以将结果封装进PageInfo对象,里面包含总页数,总记录数,是否有上一页/下一页等详情信息
java
PageInfo<与查询记录匹配的类名> pageInfo = new PageInfo<>(查询结果);``xml
com.github.pagehelper
pagehelper-spring-boot-starter
1.4.6
**使用**:
在执行查询语句前,执行`PageHelper.startPage(查询第n页, 每页m条数据)`,会自动在SQL语句末尾加上`limit n,m`
也可以将结果封装进PageInfo对象,里面包含总页数,总记录数,是否有上一页/下一页等详情信息
```java
PageInfo<与查询记录匹配的类名> pageInfo = new PageInfo<>(查询结果);