先跑起来再说
在深入技术细节之前,你可以先花 1 分钟把 mini-cc 跑起来,亲手感受一下"自己的 Claude Code"是什么体验。
项目地址:github.com/Sunny-117/m... (欢迎 star)
前置要求
- Node.js >= 18
- Ollama 已安装并运行
安装 & 启动
bash
# 安装 Ollama 并拉取模型(macOS 示例)
brew install ollama
ollama serve
ollama pull qwen2.5
# 一行命令安装 mini-cc
npm install -g mini-cc
# 启动!
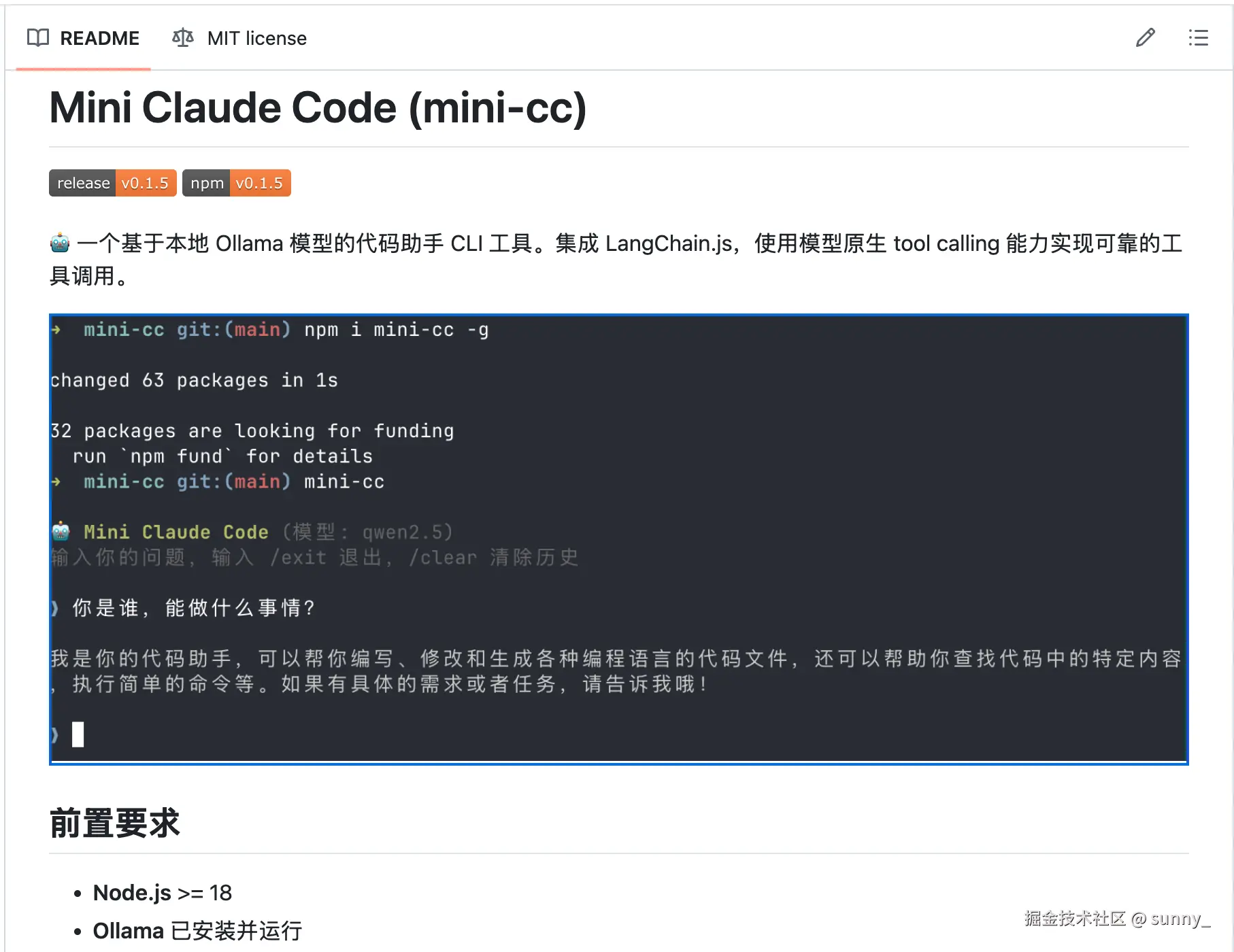
mini-cc启动后你会看到一个交互式终端:

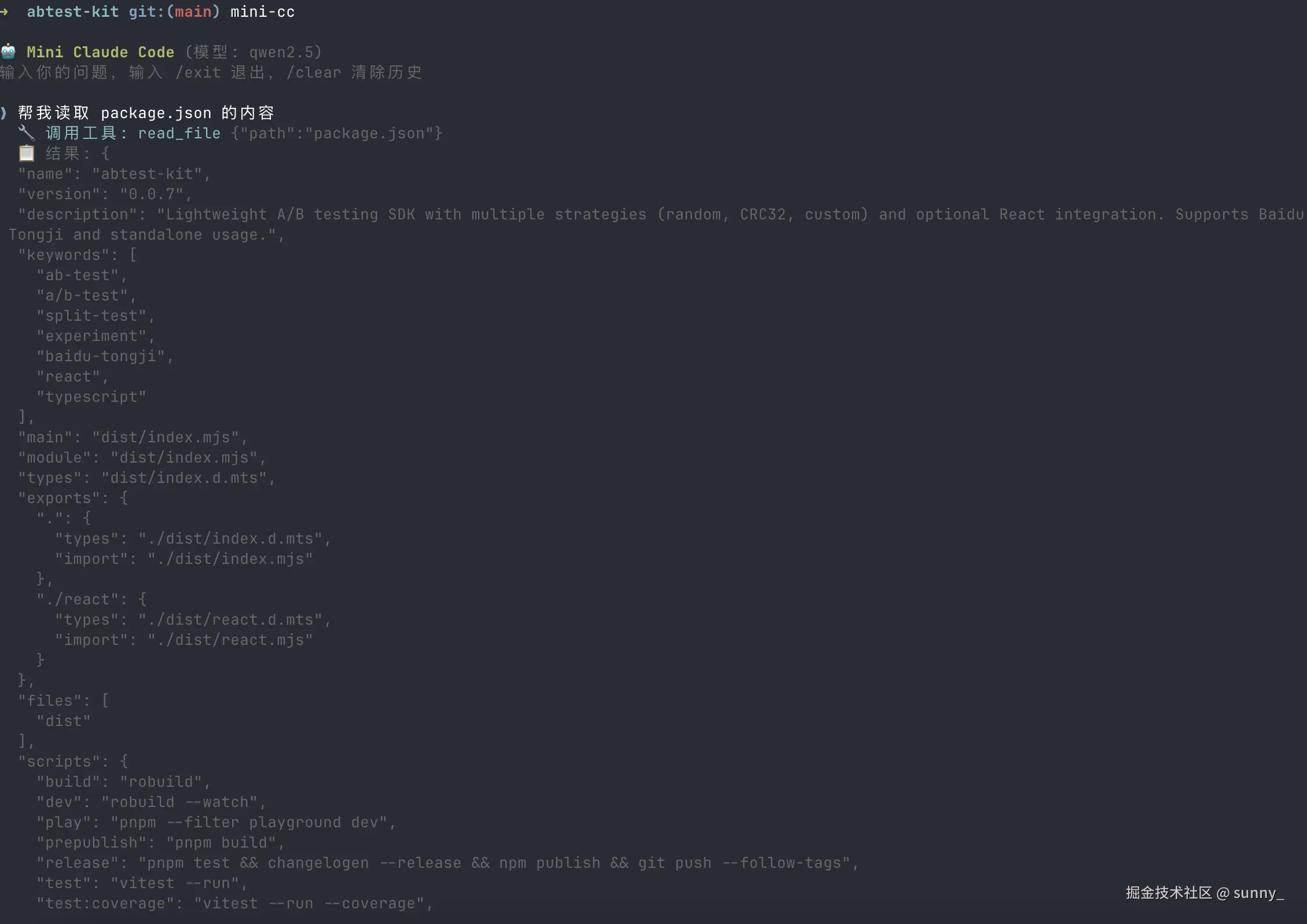
它能读文件、写文件、精准编辑代码、搜索代码、执行命令------和 Claude Code 的核心能力一致,只不过跑在你本地的 Ollama 模型上,完全免费、完全私有。
你也可以用单次提问模式,不进入交互:
bash
mini-cc ask "这个项目用了哪些依赖?"想切换模型?设个环境变量就行:
bash
MINI_CC_MODEL=qwen2.5:14b mini-cc
MINI_CC_MODEL=llama3.1 mini-cc好,跑起来之后,我们来聊聊这个东西是怎么一步步做出来的。
引子:为什么我要自己写一个 Claude Code
用了大半年 AI 编程工具之后,我开始对一件事感到不安------我每天都在用 Claude Code、Cursor 这些工具,但我完全不知道它们是怎么工作的。
表面上看,这些工具很神奇:你告诉它"帮我加个登录功能",它就能自己读代码、改文件、跑测试,一连串操作行云流水。但仔细想想,这背后一定有一套精密的调度系统。大模型本身只会"生成文本",它是怎么做到自主决策"该读哪个文件""该改哪行代码""该执行什么命令"的?
我试过去看一些 Agent 框架的源码,发现它们动辄几万行代码,抽象层套抽象层,看得我头大。AutoGPT、MetaGPT 这类项目更是走了另一条路------架构复杂到让我怀疑,搞一个 Agent 真的需要这么多东西吗?
与其在别人的代码里迷路,不如自己造一个。
于是我开始了这个项目------mini-cc(Mini Claude Code)。目标很简单:用最少的代码,实现一个能读写文件、搜索代码、执行命令的 AI 编程助手。不用云端 API,完全基于本地 Ollama 模型,跑在命令行里。
在这个过程中,我经历了两个大版本的架构迭代。第一版用纯手写的 ReAct 循环,踩了无数坑之后推翻重来;第二版切换到 LangChain + LangGraph,才真正做出了一个可用的系统。
这篇文章,就是把这段从零到一的过程完整记录下来。不是教程,是实战复盘。
核心问题只有一个:AI Agent 到底是怎么工作的?
第一版系统:基于 ReAct 的原始实现
ReAct 是什么
在动手之前,我先研究了 Agent 领域最基础的范式------ReAct(Reasoning + Acting)。这个概念来自 2022 年的一篇论文,核心思想极其简单:
- Thought(思考):模型先想一想当前该做什么
- Action(行动):基于思考,调用一个工具
- Observation(观察):拿到工具的执行结果
- 循环:把结果反馈给模型,回到第 1 步,直到模型认为任务完成
说白了,就是一个 while 循环。模型在循环里不断"想→做→看→想→做→看",直到它决定输出最终答案。
这个思路太对我胃口了------简单、直接、可控。于是我决定用最原始的方式来实现它。
架构设计
第一版的架构很直白:
scss
用户输入 (CLI / readline)
↓
Commander 命令解析
↓
Agent ReAct 循环 (自建,纯手写)
↓ ↑
↓ ↑ <tool_call> / <tool_result> XML 交互
↓ ↑
Ollama 客户端 (ollama npm 包)
↓
deepseek-r1 (本地模型)我选了 deepseek-r1 作为底座模型,因为它推理能力不错,而且有个很有意思的特性------它会在输出中用 <think> 标签包裹自己的思维过程。这天然适合 ReAct 模式中的 Thought 环节。
Prompt 设计
整个系统的灵魂在于系统提示词。我需要在 prompt 里告诉模型三件事:
- 你有哪些工具可以用
- 怎么调用工具(格式规范)
- 什么时候该调用工具,什么时候该直接回答
工具描述是从 Tool 接口自动生成的。我定义了一个 buildSystemPrompt(tools) 函数,它遍历所有注册的工具,拼出这样的提示词:
bash
## 可用工具
- **read_file**: 读取指定路径的文件内容。
参数:
- path (string, 必填): 要读取的文件路径
## 工具调用格式
<tool_call>
<name>工具名称</name>
<args>
{"参数名": "参数值"}
</args>
</tool_call>模型看到这个提示词后,如果它认为需要调用工具,就按 XML 格式输出一段 <tool_call>;如果它觉得可以直接回答,就输出普通文本。
ReAct 循环实现
核心逻辑在 agent.ts 的 runAgent() 函数里:
typescript
// 伪代码,展示核心逻辑
async function runAgent(userMessage, history, callback) {
const messages = [systemPrompt, ...history, userMessage];
for (let i = 0; i < 15; i++) { // 最多 15 轮
const output = await ollama.chat(messages);
const parsed = parseModelOutput(output);
if (!parsed.toolCall) {
// 没有工具调用 → 最终回答
return parsed.text;
}
// 有工具调用 → 执行工具
const tool = toolMap.get(parsed.toolCall.name);
const result = await tool.execute(parsed.toolCall.args);
// 把模型输出和工具结果都追加到消息列表
messages.push({ role: "assistant", content: output });
messages.push({ role: "user", content: `<tool_result>${result}</tool_result>` });
// 继续循环 →
}
}这就是一个最朴素的 ReAct 循环:调用模型 → 解析输出 → 有工具调用就执行 → 把结果喂回去 → 再调用模型。循环最多 15 轮,防止失控。
输出解析器
这是我花时间最多、也踩坑最多的部分。parser.ts 负责从模型的原始输出中提取结构化信息:
typescript
interface ParseResult {
thinking: string; // <think> 中的思维链
text: string; // 普通文本回复
toolCall: ParsedToolCall | null; // 解析出的工具调用
}解析步骤:
- 剥离
<think>...</think>标签(deepseek-r1 特有的思维链,不展示给用户) - 用正则匹配
<tool_call><name>...</name><args>...</args></tool_call> - 解析 args 里的 JSON 参数
听起来简单,实际上这是个噩梦。
致命问题:Prompt-based 工具调用的脆弱性
第一版能跑起来,简单的任务(读个文件、列个目录)也能完成。但当我开始用它做稍微复杂一点的事情时,问题就开始井喷了。
问题一:XML 格式不稳定
模型是概率性的文本生成器,它不保证每次都输出规范的 XML。我遇到过各种变体:
- 漏写
</tool_call>闭合标签 <args>里的 JSON 多了个逗号- 把
<tool_call>写成<tool_call >多了个空格 - 有时候 XML 和普通文本混在一起,一段话说到一半突然冒出个
<tool_call>
我的解析器不得不写得越来越"宽松"------先尝试严格 JSON.parse,失败了就尝试用正则提取 key-value,再失败就放弃工具调用当普通回答处理。整个解析逻辑越来越像一坨补丁代码。
问题二:HTML 内容写入是灾难
当用户让模型创建一个 HTML 文件时,模型需要在 <args> 的 JSON 里传入 HTML 内容。于是你会看到 XML 里面嵌套着 JSON,JSON 里面嵌套着 HTML,HTML 里面还有各种标签。解析器被折磨得死去活来------<div> 到底是 HTML 标签还是工具调用的一部分?XML 解析直接崩溃。
问题三:参数转义混乱
JSON 字符串里的引号需要转义,但模型经常忘记。一个包含双引号的文件内容,模型可能输出:
json
{"content": "console.log("hello")"}JSON.parse 直接报错。我加了各种修复逻辑,但总有新的边界情况冒出来。
问题四:对话历史管理的心智负担
对话历史由 CLI 层手动维护------每次调用 runAgent() 要传入 history,函数返回后再把新消息 append 到 history。听起来不复杂,但加上工具调用的多轮循环后,消息列表的结构就变得很混乱:
sql
[system, user1, assistant1(tool_call), user(tool_result), assistant2(tool_call), user(tool_result), assistant3(final)]哪些消息该保留,哪些该丢弃,上下文窗口超了怎么截断......每个都是问题。
第一版让我深刻理解了一件事:ReAct 的思想是对的,但 prompt-based 的工具调用在工程上是不可靠的。它在 demo 里跑得很开心,但一碰到真实场景就碎了一地。
遇到瓶颈:为什么 ReAct 不够用
停下来做了一次冷静的复盘。第一版的问题不是某个 bug,而是整个方向的问题。
可维护性:解析器是个无底洞
parser.ts 承担了太多不该承担的责任。一个正常的工具调用系统,参数解析应该是确定性的------输入是什么格式,输出就是什么结构。但 prompt-based 的方案完全依赖模型的"合作意愿",模型今天输出的格式和明天可能不一样。
我在解析器里写了十几个边界情况的处理逻辑,但每次换个模型或者换个任务场景,总有新的格式变体冒出来。这个模块永远改不完。
多工具调度:全靠模型自觉
第一版的工具调度逻辑完全依赖提示词。我在 prompt 里写了"每次只调用一个工具",但模型不一定听。有时候它会在一段输出里塞两个 <tool_call>,有时候它会先输出一段分析,然后才输出工具调用,导致文本和 XML 混在一起。
更根本的问题是,模型对工具的认知完全来自提示词里的文本描述。如果某个工具的描述写得不够精确,模型就会误用。而提示词的调试成本极高------改一个字可能影响所有工具的调用行为。
状态不可控
ReAct 循环的每一步,状态都存在 messages 数组里。这个数组既是对话历史,又是 Agent 的"工作记忆",还是工具调用的上下文。所有信息混在一起,没有任何结构化管理。
当循环跑到第 5、6 轮时,消息列表已经很长了,模型的注意力开始分散,回答质量明显下降。但我没有好的办法去做消息的裁剪或摘要------因为所有消息都是平等的字符串,我分不清哪些重要哪些不重要。
Debug:全靠 console.log
出了问题怎么排查?只能在代码里加 console.log 打印模型输出和解析结果。没有结构化的日志,没有事件系统,没有断点调试的可能。当循环跑了 10 轮然后给出了一个错误的结果,我得手动翻几十行日志,一步步追踪模型的"思路"在哪一步跑偏了。
这些问题加在一起,让我意识到:自建 ReAct 循环是一个很好的学习项目,但它不是一个可维护的工程方案。我需要一个更靠谱的基础设施。
第二版系统:基于 LangChain 的重构
为什么选择 LangChain
重构之前我评估了几个方案:
- 继续优化自建方案 --- 治标不治本,核心问题(prompt-based 工具调用)无解
- 用 Vercel AI SDK --- 轻量,但 Agent 编排能力偏弱
- 用 LangChain.js + LangGraph --- 生态成熟,Agent 编排是强项
选 LangChain 的决定性因素是:它解决了我最大的痛点------模型原生 tool calling。
第一版之所以痛苦,根源在于 deepseek-r1 不支持 Ollama 的 tool calling API,我只能用 XML 格式在提示词层面"假装"有工具调用能力。但很多模型(比如 qwen2.5、llama3.1)是原生支持 tool calling 的------模型会在 API 响应中直接返回结构化的工具调用请求,参数是确定性的 JSON,不需要任何解析。
换模型 + 换框架 = 从根本上消灭解析问题。
新架构
less
用户输入 (CLI / readline)
↓
Commander 命令解析
↓
createReactAgent (LangGraph)
↓ ↑
↓ ↑ 原生 tool calling(结构化 JSON,不是 XML)
↓ ↑
ChatOllama (@langchain/ollama)
↓
qwen2.5 (本地模型,原生支持 tool calling)对比第一版,变化是巨大的:
- Agent 循环 :从手写 for 循环 → LangGraph 的
createReactAgent自动编排 - 工具调用:从 XML 文本解析 → 模型原生 tool calling API
- 工具定义 :从自定义
Tool接口 → LangChaintool()+ Zod schema - 对话历史 :从手动传递
Message[]→ LangGraphMemorySaver自动管理 - 模型客户端 :从
ollamanpm 包 →@langchain/ollama的ChatOllama
代码量对比
第一版的 Agent 相关代码分散在三个文件里:
bash
src/agent/
├── prompt.ts # 系统提示词生成(~80 行)
├── parser.ts # XML 输出解析器(~120 行)
└── agent.ts # ReAct 循环(~100 行)第二版只剩一个文件:
bash
src/agent/
└── agent.ts # LangGraph Agent 封装(~120 行)parser.ts 被彻底删除------原生 tool calling 不需要解析。prompt.ts 也被删除------LangChain 根据 Zod schema 自动生成工具描述并注入提示词。系统提示词缩减为一个简单的字符串常量,只包含行为规则,不再需要拼接工具文档。
Agent 创建:四行代码
LangGraph 的 createReactAgent 让 Agent 的创建极其简洁:
typescript
const agent = createReactAgent({
llm: createLLM(), // ChatOllama 实例
tools, // LangChain tools 数组
prompt: SYSTEM_PROMPT, // 系统提示词
checkpointer, // MemorySaver,自动管理对话历史
});这四行代码背后,LangGraph 自动创建了一个状态图(StateGraph),包含:
- agent 节点:调用 LLM,决定下一步是调用工具还是直接回答
- tools 节点:执行工具调用,返回结果
- 条件边:根据 LLM 的输出自动判断走哪条路径
- 循环:自动重复"调用模型 → 执行工具 → 调用模型"直到结束
这正是我在第一版里手写的那个 for 循环,但 LangGraph 把它做得更优雅------用图的方式描述 Agent 的行为,每一步都是可追踪的事件。
工具定义:从手工 Interface 到 Zod Schema
第一版的工具定义用自定义 Tool 接口:
typescript
// 第一版:手工定义参数
interface Tool {
name: string;
description: string;
parameters: ToolParameter[];
execute: (args: Record<string, string>) => Promise<string>;
}参数全是 string 类型,没有验证,工具描述要手动拼接到提示词里。
第二版用 LangChain 的 tool() 函数 + Zod schema:
typescript
// 第二版:Zod schema,类型安全
export const readFileTool = tool(
async ({ path: filePath }) => {
const resolved = path.resolve(process.cwd(), filePath);
return await fs.readFile(resolved, "utf-8");
},
{
name: "read_file",
description: "读取指定路径的文件内容",
schema: z.object({
path: z.string().describe("要读取的文件路径"),
}),
}
);Zod schema 自动完成了三件事:参数类型校验、参数描述生成、工具文档注入到模型的 tool calling API。加一个新工具只需要写一个文件,然后在 index.ts 里 import 进来就行,不需要碰任何其他代码。
事件流:实时反馈
第二版用了 LangGraph 的 streamEvents API 来获取 Agent 执行过程中的实时事件:
typescript
const eventStream = agent.streamEvents(input, {
...config,
version: "v2",
});
for await (const event of eventStream) {
if (event.event === "on_chat_model_end") {
// 模型完成一次推理 → 检查是否有工具调用
}
if (event.event === "on_tool_end") {
// 工具执行完成 → 展示结果
}
}每个事件都有明确的类型和结构化数据,不需要再从一坨文本里用正则提取信息。CLI 层通过回调函数实时展示进度:思考中 → 调用工具 → 工具结果 → 继续思考 → 最终回答。
核心对比:ReAct vs LangChain
两个版本跑完之后,我做了一个系统性的对比:
| 维度 | 第一版(手写 ReAct) | 第二版(LangChain + LangGraph) |
|---|---|---|
| 架构 | 单文件 for 循环 + XML 解析 | LangGraph 状态图,节点化编排 |
| 工具调用 | prompt-based XML 格式,不可靠 | 模型原生 tool calling,结构化 JSON |
| 可扩展性 | 加工具要改 prompt 拼接逻辑 | 加工具只需新建文件 + import |
| 调试能力 | console.log 打日志 | 结构化事件流,每步可追踪 |
| 对话历史 | 手动维护 Message\[\] | MemorySaver + threadId 自动管理 |
| 工程复杂度 | 低起步,高维护 | 中起步,低维护 |
| 代码量 | agent 三文件 ~300 行 | agent 单文件 ~120 行 |
| 模型要求 | 任何模型(只要能生成文本) | 需支持原生 tool calling |
我的结论:
- 如果你是在学习 Agent 原理,手写 ReAct 是最好的方式。它逼你理解 Agent 的每一个环节,踩的坑都是认知的收益。
- 如果你要做一个可用的产品,用 LangChain/LangGraph。不是因为它更"先进",而是因为它解决了工程上的痛点------工具调用的可靠性、状态管理的自动化、事件流的结构化。
关键技术深挖
一、工具调度机制的设计演进
工具系统是整个 Agent 最核心的模块,它的设计直接决定了 Agent 的能力边界和可靠性。
第一版:XML 解析 + 手动分发
scss
模型输出文本 → 正则提取 <tool_call> → JSON.parse 提取参数 → toolMap.get(name) → tool.execute(args)这条链路上每一步都可能出错。正则可能匹配失败,JSON 可能格式不对,工具名可能拼错。我在 parser.ts 里写了大量的 fallback 逻辑来应对各种变体,但本质上是在跟概率做斗争。
第二版:原生 tool calling + LangGraph 自动分发
模型返回 tool_calls 数组 → LangGraph ToolNode 自动执行 → 结果自动注入回模型整条链路是确定性的。模型返回的 tool_calls 是结构化的 JSON 对象,参数是经过 Zod schema 校验的,工具执行由 LangGraph 的 ToolNode 自动完成。我不需要写任何分发逻辑。
一个关键的设计决策:edit_file 工具
在迭代过程中,我发现 write_file 工具有一个严重的缺陷:它是整体覆写文件。当模型要修改一个文件时,它需要先 read_file 读取全部内容,然后在回复中输出修改后的完整文件内容 ,再通过 write_file 写回去。
这对小模型来说几乎不可能做对------一个 200 行的文件,模型需要原封不动地复制 195 行不变的代码,只改其中 5 行。它经常会丢行、改错缩进、漏掉注释。
于是我参考 Claude Code 的做法,新增了 edit_file 工具------diff/patch 式编辑:
typescript
export const editFileTool = tool(
async ({ path: filePath, old_text, new_text }) => {
const content = await fs.readFile(resolved, "utf-8");
// 唯一性校验:old_text 必须在文件中只匹配一处
const occurrences = content.split(old_text).length - 1;
if (occurrences === 0) return "错误:未找到要替换的文本";
if (occurrences > 1) return "错误:找到多处匹配,请提供更多上下文";
const updated = content.replace(old_text, new_text);
await fs.writeFile(resolved, updated, "utf-8");
return `文件已编辑: ${filePath}`;
},
{
name: "edit_file",
description: "通过精准的文本替换来编辑文件...",
schema: z.object({
path: z.string(),
old_text: z.string().describe("要被替换的原始文本"),
new_text: z.string().describe("替换后的新文本"),
}),
}
);核心设计:
- 唯一性约束 :
old_text必须在文件中只匹配一处,多处匹配则报错要求提供更多上下文。这保证了替换的精确性。 - 错误反馈:匹配不到时,返回文件前 20 行内容帮助模型重新定位。这形成了一个自我修正的闭环------模型尝试 → 失败 → 拿到反馈 → 调整参数 → 重试。
- 最小改动:模型只需要传入需要替换的代码片段和新代码,不需要输出整个文件。这大幅降低了出错概率。
二、Prompt 工程的演进
系统提示词是 Agent 的"灵魂"。两个版本的提示词设计有本质区别。
第一版:重型提示词
第一版的提示词是一个巨大的模板,包含:
- 角色设定
- 工具列表(从代码自动生成)
- 工具调用的 XML 格式规范
- 各种行为约束(每次只调用一个工具、不要编造文件内容等)
这个提示词有 1000+ token,而且非常脆弱------改一个措辞可能导致模型不再正确输出 XML 格式。我花了大量时间在"提示词调试"上,本质上是在做自然语言编程,没有类型系统,没有编译器,改了不知道会不会 break。
第二版:轻量提示词 + 系统保障
第二版的提示词大幅精简,因为很多工作不再需要通过提示词来完成:
typescript
const SYSTEM_PROMPT = `你是一个强大的代码助手 Agent...
当前工作目录: ${process.cwd()}
核心原则:
- 修改现有文件时,必须使用 edit_file 工具进行精准替换
- 当用户要求执行命令时,必须使用 run_command 工具
- 永远不要建议用户自己去终端手动操作
修改文件的正确流程:
1. 先用 read_file 读取文件完整内容
2. 使用 edit_file 传入 old_text 和 new_text
3. 绝对不要用 write_file 来修改现有文件`;工具列表、参数格式、调用协议------这些全部由 LangChain 根据 Zod schema 自动生成。提示词只需要关注行为规则 ,而不是格式规范。
但这里有一个血泪教训:小模型对提示词的理解比你想象的更字面。
我最初在规则里写了一句"执行命令前要考虑安全性"。结果 qwen2.5 把这理解成了"不要执行命令"------每次用户要求执行 npm install,模型都会拒绝并建议用户"自己去终端手动执行"。
修复方式是把模糊的"考虑安全性"改成确定的"直接调用 run_command,安全确认由系统自动处理,你不需要担心安全问题"。对小模型来说,消除歧义比优雅措辞重要一万倍。
三、权限系统设计:Agent 的安全边界
当 Agent 拥有了 run_command 这种能力时,一个严肃的问题浮出水面:谁来决定 Agent 能做什么?
参考 Claude Code 的做法,我设计了一个两层权限机制:
第一层:配置文件白名单
用户可以在项目根目录创建 .mini-cc.json,配置允许自动执行的命令前缀:
json
{
"allowedCommands": ["ls", "cat", "git status", "git diff"]
}匹配逻辑是前缀匹配------白名单里的 "ls" 可以匹配 ls -la、ls src/。这样既安全又灵活。
第二层:交互式确认
不在白名单中的命令,工具会暂停 Agent 的执行,在终端弹出确认提示:
⚠️ 即将执行命令: npm install
是否允许执行?(y/N)这里有个有趣的工程问题:确认提示需要和 ora spinner 协调。Agent 在执行工具时,CLI 层正在显示一个旋转的 loading 动画。如果直接弹出 readline 提示,spinner 会不断刷新覆盖提示文本,用户根本看不到也输入不了。
解决方式是通过一个共享的 spinner 引用,在弹出确认前暂停 spinner,确认后恢复:
typescript
export function confirmCommand(command: string): Promise<boolean> {
return new Promise((resolve) => {
// 暂停 spinner
const wasSpinning = activeSpinner?.isSpinning ?? false;
if (wasSpinning) activeSpinner.stop();
rlInstance.question("是否允许执行?(y/N) ", (answer) => {
const allowed = answer.trim().toLowerCase() === "y";
// 恢复 spinner
if (wasSpinning) activeSpinner.start("执行中...");
resolve(allowed);
});
});
}这个设计体现了一个原则:Agent 的能力边界不应该由 Agent 自己决定,而应该由系统来强制执行。模型可以请求做任何事,但最终执行与否由系统的权限层把关。这比在提示词里写"不要执行危险命令"靠谱一万倍------因为提示词是可以被 prompt injection 突破的,但代码级别的权限检查不会。
我眼中的 Claude Code 架构
在自己实现了两个版本之后,回过头来看 Claude Code 这样的产品级系统,我对它的设计有了更深的理解(和合理的推测)。
Tool 使用方式
Claude Code 使用的是 Claude 模型的原生 tool use 能力(和我的第二版一样的思路),但它的工具集远比 mini-cc 丰富:
- Read --- 读取文件,支持分页(offset/limit),支持图片和 PDF
- Edit --- diff/patch 式编辑,和我实现的
edit_file思路一致,要求old_string在文件中唯一 - Write --- 创建新文件,和 Edit 分开是刻意的设计------语义不同,权限可以不同
- Bash --- 执行命令,但有细致的权限控制
- Glob/Grep --- 专门的搜索工具,而不是复用 Bash 的 find/grep
一个值得注意的设计:Claude Code 把"搜索文件"和"搜索代码内容"做成了独立工具(Glob、Grep),而不是让模型用 run_command 去跑 find 和 grep。这样做的好处是每个工具的参数和行为都是确定的,模型不需要记住 grep -r 的各种 flag。
上下文管理
Claude Code 最让我佩服的是它的上下文管理能力。我的 mini-cc 用 MemorySaver 把所有消息都存在内存里,对话长了就会超出模型的上下文窗口。
Claude Code 似乎做了几件事:
- 自动压缩:对话变长时,自动总结历史消息,用摘要替代原文
- 按需加载:不把所有文件内容都塞进上下文,用 Glob/Grep 先定位再精确读取
- Agent 隔离:子任务可以交给独立的 sub-agent 处理,子 agent 有自己的上下文窗口,完成后只返回结果摘要给主 agent
这种"分治"思路是处理长任务的关键。一个复杂的重构任务可能涉及几十个文件,全部塞进一个上下文窗口是不可能的。但如果拆成"先搜索→确定范围→逐个文件修改"的步骤,每步的上下文量就可控了。
和 mini-cc 的对比
| 方面 | mini-cc | Claude Code(推测) |
|---|---|---|
| 模型 | 本地 Ollama(qwen2.5 7B) | Claude 4 系列(远端 API) |
| 工具数量 | 6 个 | 10+ 个 |
| 权限系统 | 配置文件白名单 + 交互确认 | 多级权限(全自动/确认/拒绝) |
| 上下文管理 | MemorySaver(全量存储) | 自动压缩 + 按需加载 |
| 文件编辑 | 基础的字符串替换 | 更智能的 diff 策略 |
| 子任务 | 不支持 | Sub-agent 隔离执行 |
差距是明显的,但核心思路是一致的:Agent = 推理循环 + 工具系统 + 状态管理。mini-cc 是这个公式的最小实现,Claude Code 是这个公式的产品级实现。它们之间的差距不在于"思路不同",而在于"工程深度不同"。
总结:AI Agent 架构的本质
两个版本做下来,我对 AI Agent 有了一些自己的理解。
Agent ≠ Prompt
很多人以为 AI Agent 就是一个写得很好的提示词。确实,提示词很重要,但它只是 Agent 的"灵魂",不是 Agent 的全部。一个可用的 Agent 还需要:
- 确定性的工具调用协议(不是 prompt-based 的 XML 解析)
- 可靠的状态管理(不是手动传递的消息数组)
- 系统级的安全边界(不是提示词里的"注意安全")
- 结构化的事件系统(不是 console.log 调试)
Agent = 状态机 + 工具系统 + 推理循环
把概念剥干净,一个 Agent 就是三个东西的组合:
- 状态机:Agent 在"思考""执行""等待"等状态之间切换,LangGraph 用 StateGraph 来表达这一点
- 工具系统:Agent 通过工具与外部世界交互,工具的定义、发现、执行、权限管理构成了一个完整的子系统
- 推理循环:模型在循环中不断"观察→推理→行动",直到任务完成
这三个东西的质量决定了 Agent 的上限。模型能力决定了推理的质量,工具系统决定了行动的边界,状态管理决定了长任务的可行性。
工程化才是核心壁垒
从第一版到第二版,我最大的感受是:Agent 的难点不在于"让模型更聪明",而在于"让系统更可靠"。
模型会幻觉、会犯错、会输出格式不对的内容------这些都不可怕,可怕的是你的系统没有能力去检测和纠正这些错误。edit_file 工具的唯一性校验、命令执行的权限系统、工具结果的错误反馈------这些工程上的"小细节",加起来才构成了一个可用的 Agent。
一个写得再好的提示词,在 prompt injection 面前都是纸糊的。但一个权限系统硬编码的 isCommandAllowed() 检查,任何提示词注入都绕不过去。
这就是工程化的价值。
未来演进方向
mini-cc 目前是一个能跑的最小 Agent,但离一个真正好用的编程助手还有很长的路。以下是我思考的几个方向:
多 Agent 协作
当前的架构是单 Agent 模式------一个模型负责所有事情。但复杂任务往往需要不同角色的协作:
- Planner Agent:负责分解任务、制定计划
- Coder Agent:负责读写代码
- Reviewer Agent:负责检查代码质量
LangGraph 天然支持多 Agent 编排------每个 Agent 是图中的一个子图,通过消息传递协作。这是 mini-cc 下一步最值得做的事情。
Planning 能力
目前的 Agent 是"走一步看一步"的------拿到用户请求,直接开始行动。但复杂任务需要先规划再执行。
比如用户说"把这个项目从 JavaScript 迁移到 TypeScript",Agent 应该先列出所有需要改的文件、确定改动顺序、考虑类型定义的依赖关系,然后再逐步执行。
这需要在 ReAct 循环之外加一个 Planning 阶段,让模型先输出一个执行计划,用户确认后再执行。
长上下文与记忆
当前的 MemorySaver 把所有消息存在内存里,对话长了就会超出模型的上下文窗口。需要更智能的策略:
- 消息压缩:对历史消息做摘要,保留关键信息
- 向量检索:把历史消息做 embedding,按相关性检索而不是全部塞进去
- 外部存储:把文件内容的"快照"存在外部,只在需要时加载
自我反思(Reflection)
当前的 Agent 没有自我反思能力------如果工具执行失败,它只是看到错误信息然后尝试另一个方案。但更好的做法是在失败后做一次显式的反思:
- 为什么失败了?
- 是参数错了、还是工具选错了、还是前提假设有问题?
- 下一步应该怎么调整策略?
这可以通过在 LangGraph 的状态图中加一个"反思节点"来实现------当工具执行失败时,先进入反思节点做分析,再回到行动节点。
写在最后
整个项目做下来,我最大的收获不是代码本身,而是对 AI Agent 的认知从"黑盒"变成了"透明"。
Claude Code 不再是一个神秘的产品------它就是一个精心设计的状态机,配合一套可靠的工具系统和一个强大的推理模型。它的每一个能力,都对应着架构中的某个模块。它的每一个限制,也都能从架构设计中找到原因。
如果你也对 AI Agent 感兴趣,我的建议是:别只看论文和框架文档,自己写一个。从最简单的 ReAct 循环开始,踩完所有的坑,你就真正理解了。
项目开源地址:github.com/Sunny-117/m...
如果这篇文章对你有帮助,欢迎 star 🌟