文章目录
-
- 一、vLLM离线和在线部署推理、并测试在线服务性能
-
- [1.0 环境配置](#1.0 环境配置)
- [1.1 vLLM离线部署qwen](#1.1 vLLM离线部署qwen)
- [1.2 vLLM在线部署qwen](#1.2 vLLM在线部署qwen)
- [1.3 测试在线服务性能](#1.3 测试在线服务性能)
一、vLLM离线和在线部署推理、并测试在线服务性能
1.0 环境配置
- vLLM安装
shell
pip install vllm
若发现下载包速度过慢,可将 PyPI 源切换至国内镜像,例如:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 也可以直接在安装的时候临时性指定 -i
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完成后,执行验证脚本;若终端打印版本号(示例:0.10.1.1),即表明 vLLM 框架已就绪。
import vllm
print(vllm.__version__)- 参数解释
- 温度(temperature) :用于调节模型输出的概率分布多样性。温度越高,输出分布越平缓,随机性越强;温度越低,分布越尖锐,倾向于选择高概率词元。当温度趋近于 0 时,模型输出趋于确定性,几乎总是选择概率最高的词元。
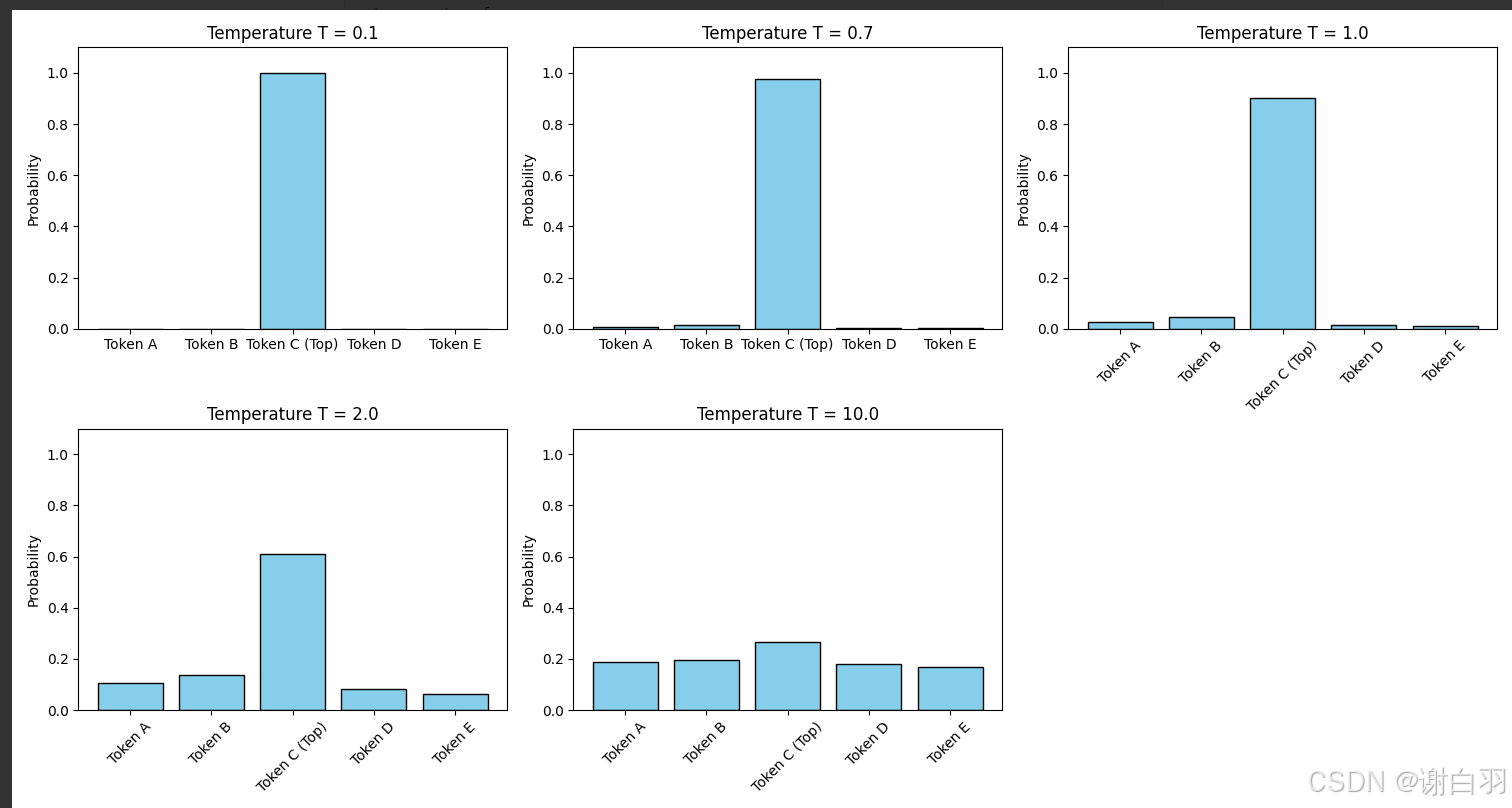
- op-p(nucleus sampling,p=0.95):与温度协同作用,仅保留累计概率达到或超过 p 值的最小词元集合。该策略在维持生成多样性的同时,有效排除低概率、语义不合理词元被选中的可能性,从而避免生成内容偏离逻辑或语义连贯性。
- llm = LLM(model="Qwen2.5-1.5B-Instruct") 会自动从 Hugging Face 模型仓库下载对应权重。如果网络问题的话可以考虑代理,或者先下载到某个文件夹再将文件夹的路径传入到model="xxx-dir"中。下载完成后,模型权重将被加载至 GPU 显存中。
模型显存占用约为 3 GB,计算依据为:1.5B 参数 × 2 字节(FP16 精度)。此外,还需额外预留显存空间用于存储 KV Cache(键值缓存),KV Cache的作用在于Transformer 自注意力计算时避免对历史 token 的键值对重复计算,从而提升推理效率。模型显存占用约为 3 GB,计算依据为:1.5B 参数 × 2 字节(FP16 精度)。此外,还需额外预留显存空间用于存储 KV Cache(键值缓存),KV Cache的作用在于Transformer 自注意力计算时避免对历史 token 的键值对重复计算,从而提升推理效率。
- 调试的launch.json配置
python配置填写对应启动文件路径
"python": "${workspaceFolder}/code/demo.py",
json
{
"version": "0.2.0",
"configurations": [
{
"name": "vLLM: API Server Debug",
"type": "debugpy",
"request": "launch",
"module": "vllm.entrypoints.openai.api_server",
"args": [
"--model",
"Qwen/Qwen3-1.7B",
"--dtype",
"float16",
"--max-model-len",
"4096",
"--gpu-memory-utilization",
"0.95",
"--max-num-batched-tokens",
"8192",
"--max-num-seqs",
"256",
"--port",
"13333",
"--tensor-parallel-size",
"2",
"--pipeline-parallel-size",
"1",
"--enforce-eager"
],
"env": {
// 可选:设置 CUDA_VISIBLE_DEVICES 控制 GPU 使用
// "CUDA_VISIBLE_DEVICES": "0,1",
// 开启 vLLM 调试日志
"VLLM_LOGGING_LEVEL": "DEBUG",
"PYTHONPATH": "${workspaceFolder}:${env:PYTHONPATH}"
},
"python": "${workspaceFolder}/code/demo.py",
"console": "integratedTerminal",
"justMyCode": false,
"cwd": "${workspaceFolder}",
"stopOnEntry": false
}
]
}1.1 vLLM离线部署qwen
-
两个进程分别在做什么
- 进程 0(收发用户输入的LLMEngine进程):用LLMEngine负责接收用户输入的文本提示(prompts),执行分词处理,并用类内变量EngineCoreClient将请求打包后通过 ZeroMQ(ZMQ)套接字通信机制发送至推理进程,在随后还需要接收结果。
- 进程 1(模型推理执行的EngineCore进程):通过 ZMQ 接收来自 LLMEngine 的请求,将其存入 EngineCore 的输入队列;调度器按既定策略取出请求并调度 GPU 执行推理(具体推理计算的过程还会委托给其他组件),计算结果写入 EngineCore 的输出队列,再经 ZMQ 回传至进程 0,最终将请求的推理结果返回给用户。具体如图中所示。
-
下载模型
python
from modelscope.hub.snapshot_download import snapshot_download
# 下载 Qwen3-1.7B 到指定目录(移除无效参数)
model_dir = snapshot_download(
model_id="qwen/Qwen3-1.7B", # ModelScope 上的模型ID
local_dir="/home/lixiang/models/Qwen3-1.7B" # 本地保存路径
)
print(f"模型已下载到:{model_dir}")- 离线推理
python
import os
os.environ["VLLM_USE_V1"] = "1" # 必须在 import vllm 之前!
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from vllm import LLM, SamplingParams
# 核心修复:把主逻辑包裹在 if __name__ == '__main__' 里
if __name__ == '__main__':
prompts = [
"Hello, my name is",
"The president of the United States is",
"Write a poem about China:",
"Who won the world series in 2020?",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=50) # 限制生成长度,减少CPU压力
# 加载本地模型(CPU模式)
llm = LLM(
model="/home/lixiang/models/Qwen3-1.7B",
enforce_eager=True
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
离线推理的典型特征:
- 输入 prompt 集合已知、固定,无需动态请求;
- 对单请求延迟不敏感,核心指标为吞吐率(throughput)。
在 GPU 显存允许范围内,推理系统需要最大化批处理规模,填满请求队列直至达到显存或序列长度上限
我们知道大模型推理由 Prefill 和 Decode 两个阶段组成,因此重点关注以下指标:
- TTFT(Time to First Token,首 Token 延迟):
从请求提交到返回第一个输出 token 的端到端延迟。主要由 Prefill 阶段耗时 构成,主要是完整 prompt 的处理时间。 - TPOT(每输出 Token 延迟,不含首 Token)
在 Decode 阶段中,每个后续 token 的平均生成延迟,TPOT反映自回归生成的持续性能,受 KV Cache 访问效率和显存带宽影响显著。 - 吞吐速率(Throughput):单位时间生成的 token 数(tokens/秒)