【机器学习-20】-数值计算误差、逻辑回归/Softmax的数值稳定性优化、以及TensorFlow实现细节
以下是基于5张图片核心内容的系统性解析与解决方案,涵盖数值计算误差、逻辑回归/Softmax的数值稳定性优化、以及TensorFlow实现细节:
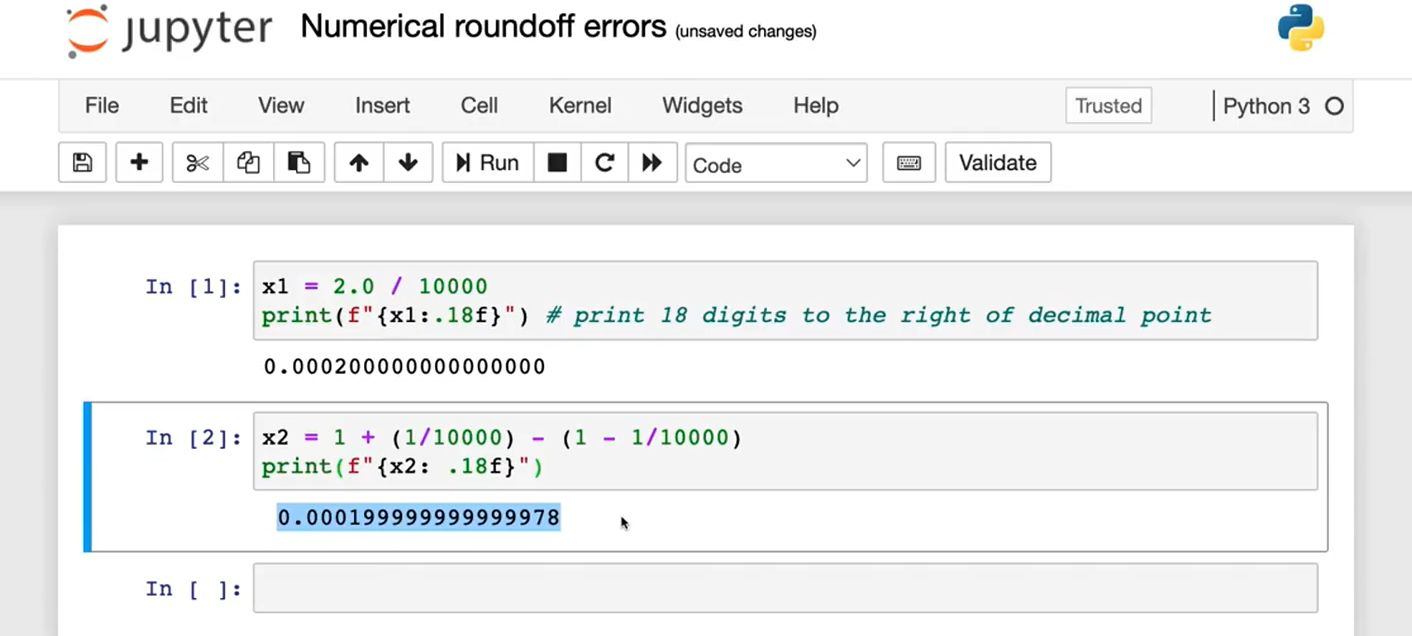
1. 数值舍入误差问题(图1)
问题现象
• 代码1 :2.0/10000 输出精确值 0.000200000000000000。
• 代码2 :(1 + 1/10000) - (1 - 1/10000) 输出 0.000199999999999978(理论应为 0.0002)。
原因与解决方案
• 原因 :浮点数运算的有限精度导致舍入误差累积。
• 解决方案 :
• 避免相近数相减(如重构公式)。
• 使用高精度库(如decimal)或数值稳定的实现(如图2-5的损失函数优化)。
2. 逻辑回归的数值稳定性优化(图2, 图5)
原始问题
• 传统实现(数值不稳定):
python
a = sigmoid(z) # a接近0或1时,log(a)可能溢出
loss = -y*log(a) - (1-y)*log(1-a)优化方案
• 合并计算 (图2):
• 直接使用logits(未激活的z),通过from_logits=True让损失函数内部合并Sigmoid和交叉熵计算:
python loss = BinaryCrossentropy(from_logits=True) # 内部优化避免数值溢出
• 代码实现(图5):
python
model = Sequential([
Dense(25, activation='sigmoid'),
Dense(15, activation='sigmoid'),
Dense(1, activation='linear') # 输出logits
])
model.compile(loss=BinaryCrossentropy(from_logits=True))
f_x = tf.nn.sigmoid(model(X)) # 预测时显式调用sigmoid3. Softmax回归的数值稳定性优化(图3, 图4)
原始问题
• 传统Softmax :
• 计算e^z可能导致数值溢出(尤其z较大时)。
• 损失函数直接计算log(softmax(z))会放大误差。
优化方案
• 合并计算 (图3):
• 使用SparseCategoricalCrossentropy(from_logits=True),内部优化避免显式计算e^z:
python loss = -log(softmax(z_y)) = -z_y + log(sum(e^z_k))
• 代码实现(图4):
python
model = Sequential([
Dense(25, activation='relu'),
Dense(15, activation='relu'),
Dense(10, activation='linear') # 输出logits
])
model.compile(loss=SparseCategoricalCrossentropy(from_logits=True))
logits = model(X)
f_x = tf.nn.softmax(logits) # 预测时显式调用softmax4. 综合解题思路与代码模板
题目示例
"设计一个MNIST分类模型,要求避免数值溢出并解释优化原理。"
解答步骤
- 数据预处理:归一化像素值到0,1。
- 模型设计 :
• 输出层使用linear激活,输出logits。
• 隐藏层根据任务选择relu(多分类)或sigmoid(二分类)。 - 损失函数配置 :
• 多分类:SparseCategoricalCrossentropy(from_logits=True)
• 二分类:BinaryCrossentropy(from_logits=True) - 预测处理 :对logits显式调用
softmax或sigmoid。
代码模板(MNIST多分类)
python
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(25, activation='relu'),
tf.keras.layers.Dense(15, activation='relu'),
tf.keras.layers.Dense(10, activation='linear') # logits
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model.fit(X_train, y_train, epochs=10)
# 预测时转换logits为概率
logits = model(X_test)
probs = tf.nn.softmax(logits)5. 关键总结
• 数值误差根源 :浮点数精度限制和指数运算溢出。
• 优化核心 :
• 逻辑回归 :合并Sigmoid与交叉熵计算。
• Softmax :合并Softmax与交叉熵计算,利用from_logits=True。
• 实践建议 :
• 输出层始终用linear,损失函数设置from_logits=True。
• 避免手动实现损失函数,依赖框架优化。
如需进一步探讨具体数学推导或调试方法,请提供更多细节!