
个人主页:
wengqidaifeng
✨ 永远在路上,永远向前走
个人专栏:
数据结构
C语言
嵌入式小白启动!
重要OJ算法题详解
文章目录
-
- (前言)写在前面
- 一、树:从线性到层次的跨越
-
- [1.1 什么是树?](#1.1 什么是树?)
- [1.2 树的基本术语](#1.2 树的基本术语)
- [1.3 有序树与无序树](#1.3 有序树与无序树)
- [1.4 有根树与无根树](#1.4 有根树与无根树)
- 二、树的存储:孩子表示法
-
- [2.1 用vector数组存储](#2.1 用vector数组存储)
- [2.2 用链式前向星存储](#2.2 用链式前向星存储)
- [2.3 两种方式的选择](#2.3 两种方式的选择)
- 三、树的遍历:深度优先与广度优先
-
- [3.1 深度优先遍历(DFS)](#3.1 深度优先遍历(DFS))
- [3.2 广度优先遍历(BFS)](#3.2 广度优先遍历(BFS))
- [3.3 DFS vs BFS:如何选择?](#3.3 DFS vs BFS:如何选择?)
- 四、二叉树:每个结点最多两个孩子
-
- [4.1 二叉树的定义](#4.1 二叉树的定义)
- [4.2 特殊的二叉树](#4.2 特殊的二叉树)
- [4.3 二叉树的存储](#4.3 二叉树的存储)
- 五、二叉树的遍历:三种深搜顺序
-
- [5.1 先序遍历(根左右)](#5.1 先序遍历(根左右))
- [5.2 中序遍历(左根右)](#5.2 中序遍历(左根右))
- [5.3 后序遍历(左右根)](#5.3 后序遍历(左右根))
- [5.4 层序遍历(BFS)](#5.4 层序遍历(BFS))
- [5.5 由两种遍历序列还原二叉树](#5.5 由两种遍历序列还原二叉树)
- 六、堆:优先级队列的底层实现
-
- [6.1 什么是堆?](#6.1 什么是堆?)
- [6.2 堆的存储](#6.2 堆的存储)
- [6.3 堆的核心操作](#6.3 堆的核心操作)
- [6.4 堆的基本操作](#6.4 堆的基本操作)
- [6.5 建堆:从无序数组构建堆](#6.5 建堆:从无序数组构建堆)
- 七、STL中的堆:priority_queue
-
- [7.1 基本使用](#7.1 基本使用)
- [7.2 创建小根堆](#7.2 创建小根堆)
- [7.3 存储自定义类型](#7.3 存储自定义类型)
- [7.4 常用操作总结](#7.4 常用操作总结)
- 八、算法题实战
-
- [8.1 二叉树深度](#8.1 二叉树深度)
- [8.2 堆模板题](#8.2 堆模板题)
- [8.3 第k小](#8.3 第k小)
- 九、总结与对比
-
- [9.1 树与线性结构的对比](#9.1 树与线性结构的对比)
- [9.2 二叉树 vs 堆](#9.2 二叉树 vs 堆)
- [9.3 选择建议](#9.3 选择建议)
- 写在最后
如果说线性结构是程序世界的"一维空间",那么树形结构就是通往"多维世界"的第一扇门。
(前言)写在前面
在上一篇文章中,我们学习了顺序表、链表、栈和队列------这些线性结构如同一根笔直的线条,数据之间只有"前驱"和"后继"两种关系。然而,现实世界中的数据关系远比这复杂得多。
想一想:
- 一个公司的组织架构,CEO下面有多个部门总监,每个总监下面又有多个经理...
- 一个文件夹系统,根目录下有多个子文件夹,每个子文件夹又可以包含更多文件...
- 一场比赛的对阵表,从总决赛不断向下拆分到各个小组...
这些场景中,数据之间呈现的是一对多 的层次关系------这正是树形结构所要解决的问题。
如果说线性结构是程序世界的"基础工具",那么树形结构就是构建复杂系统的"高级框架"。从文件系统的目录树,到数据库的索引结构,再到人工智能中的决策树,树形结构无处不在。
而在这些树形结构中,最基础、最重要的当属二叉树------每个结点最多有两个孩子的特殊树。它不仅是许多高级数据结构(如堆、二叉搜索树、AVL树、红黑树)的基石,更是算法竞赛中"分治思想"的最佳载体。
本文将带你走进树的世界,从最基础的树的存储与遍历,到二叉树的三种深度优先遍历,再到堆与优先级队列的实现与应用。通过手写代码+STL使用的双重讲解,让你不仅"会用",更能"懂其所以然"。
一、树:从线性到层次的跨越
1.1 什么是树?
树(Tree) 是一种非线性的数据结构,它由 n(n≥0)个结点组成,具有以下特点:
- 有一个特殊的结点称为根结点(root),它没有前驱
- 除根结点外,其余结点被分成 (m) 个互不相交的集合,每个集合又是一棵树,称为根结点的子树(subtree)
这个定义是递归 的------树由子树构成,子树又由更小的子树构成。递归,正是理解和操作树的核心思想。
1.2 树的基本术语
| 术语 | 含义 | 示例 |
|---|---|---|
| 结点的度 | 结点拥有的子树个数 | 一个结点有2个孩子,则度为2 |
| 树的度 | 树中所有结点度的最大值 | 树中最大结点度为3,则树的度为3 |
| 叶子结点 | 度为0的结点 | 没有孩子的结点 |
| 分支结点 | 度大于0的结点 | 有孩子的结点 |
| 孩子/双亲 | 结点的子树的根称为该结点的孩子,该结点称为孩子的双亲 | |
| 兄弟 | 同一双亲的孩子之间互称兄弟 | |
| 深度/高度 | 树中结点的最大层次数 | 根为第1层,最深为第4层,则深度为4 |
| 路径 | 从结点(u)到结点(v)经过的结点序列 | 路径长度为经过的边数 |
1.3 有序树与无序树
- 有序树:结点的子树有从左到右的顺序,不可互换(如二叉树)
- 无序树:结点的子树之间没有顺序关系
这个区分在二叉树中尤为重要------左右孩子是不能颠倒的,就像人的左手和右手,位置固定。
1.4 有根树与无根树
- 有根树:根节点是确定的,父子关系明确
- 无根树:根节点不确定,任意结点都可以作为根
在处理无根树时,我们通常需要存储双向的边关系(即(u)连接(v),(v)也连接(u)),然后指定一个根进行遍历。
二、树的存储:孩子表示法
在算法竞赛中,树最常见的存储方式是孩子表示法------每个结点维护一个列表,记录它的所有孩子(或所有相邻结点)。
2.1 用vector数组存储
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5 + 10;
vector<int> edges[N]; // edges[i] 存储与结点i相邻的所有结点
bool st[N]; // 标记是否访问过
int main() {
int n;
cin >> n;
// 读入n-1条边(树有n-1条边)
for(int i = 1; i < n; i++) {
int u, v;
cin >> u >> v;
edges[u].push_back(v);
edges[v].push_back(u); // 无根树需要双向存储
}
// 现在就可以从任意结点开始遍历整棵树了
return 0;
}优点 :代码简单直观,容易理解
缺点:动态数组有轻微的性能开销(但在竞赛中通常不会卡常数)
2.2 用链式前向星存储
链式前向星本质是用数组模拟链表,是静态实现的,效率更高。
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int h[N], e[N * 2], ne[N * 2], idx; // idx是当前分配的结点编号
bool st[N];
// 添加一条从a到b的边(头插法)
void add(int a, int b) {
idx++;
e[idx] = b; // 存储目标结点
ne[idx] = h[a]; // 指向a原来的第一个邻居
h[a] = idx; // 更新a的第一个邻居
}
int main() {
int n;
cin >> n;
for(int i = 1; i < n; i++) {
int u, v;
cin >> u >> v;
add(u, v);
add(v, u); // 无根树双向存储
}
// 遍历结点u的所有邻居
// for(int i = h[u]; i; i = ne[i]) {
// int v = e[i];
// // 处理v...
// }
return 0;
}为什么用N * 2? 因为每条边要存储两次(双向),所以数组大小需要开两倍。
2.3 两种方式的选择
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| vector数组 | 代码简洁,易调试 | 动态内存,略慢 | 一般题目,追求代码简洁 |
| 链式前向星 | 静态内存,速度快 | 代码稍复杂,易出错 | 大数据量,追求极致效率 |
建议:初学阶段两种都掌握,做题时选择自己熟悉的一种。绝大多数题目,vector数组完全够用。
三、树的遍历:深度优先与广度优先
树的遍历是许多算法的基础。遍历的核心是不重不漏地访问每个结点一次。
3.1 深度优先遍历(DFS)
深度优先遍历的思路是:一条路走到黑。从根结点出发,沿着一条路径一直往下走,直到无法继续,再回溯到上一个结点,走另一条路径。
用递归实现DFS非常自然:
cpp
// DFS遍历以u为根的子树
void dfs(int u) {
cout << u << " "; // 访问当前结点
st[u] = true; // 标记已访问
// 遍历所有邻居
for(auto v : edges[u]) {
if(!st[v]) {
dfs(v); // 递归访问子树
}
}
}时间复杂度 :(O(N)),每个结点访问一次,每条边遍历两次
空间复杂度:(O(N)),最坏情况(链状树)递归深度为(N)
3.2 广度优先遍历(BFS)
广度优先遍历的思路是:一层一层地扫。从根结点出发,先访问所有距离为1的结点,再访问距离为2的结点,以此类推。
用队列实现BFS:
cpp
#include <queue>
void bfs(int root) {
queue<int> q;
q.push(root);
st[root] = true;
while(!q.empty()) {
int u = q.front();
q.pop();
cout << u << " ";
for(auto v : edges[u]) {
if(!st[v]) {
q.push(v);
st[v] = true;
}
}
}
}时间复杂度 :(O(N))
空间复杂度:(O(N)),最坏情况所有结点在同一层,队列大小可达(N)
3.3 DFS vs BFS:如何选择?
| 特性 | DFS | BFS |
|---|---|---|
| 实现方式 | 递归/栈 | 队列 |
| 空间消耗 | 递归深度(可能栈溢出) | 队列大小(可能很大) |
| 适用场景 | 探索深度优先的问题、回溯、树形DP | 最短路径、层次遍历 |
四、二叉树:每个结点最多两个孩子
4.1 二叉树的定义
二叉树(Binary Tree) 是每个结点最多有两个子树的树结构。两个子树分别称为左子树 和右子树,顺序固定,不可颠倒。
二叉树的特点:
- 每个结点最多有两棵子树
- 左右子树有顺序之分
- 可以是空树(没有任何结点)
4.2 特殊的二叉树
满二叉树
所有非叶子结点都有左右孩子,且所有叶子结点在同一层。
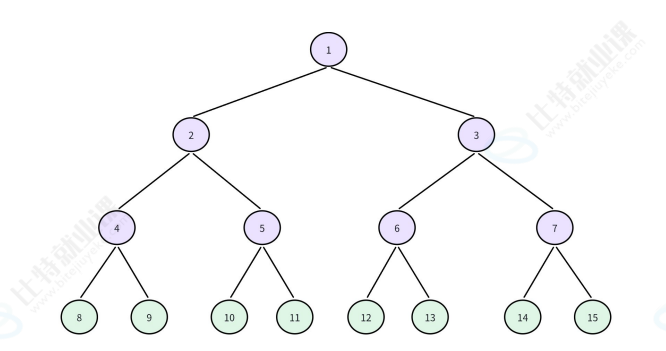
性质:深度为(k)的满二叉树,结点数为(2^k - 1)。
完全二叉树
在满二叉树的基础上,从最后一层的右侧开始连续删除若干个结点,剩下的就是完全二叉树。
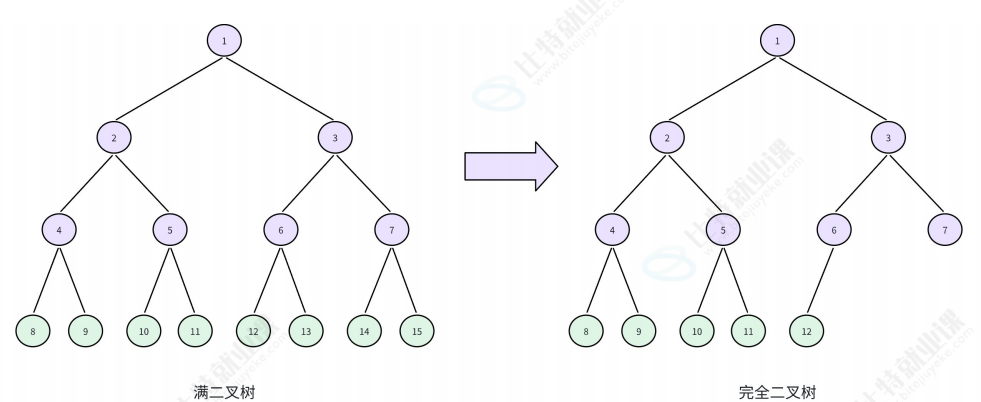
性质:
- 叶子结点只可能在最后两层
- 可以用数组顺序存储,父结点与子结点的下标关系固定
4.3 二叉树的存储
顺序存储(适用于完全二叉树)
对于完全二叉树,我们可以用数组存储,下标关系如下:
结点编号从1开始:
- 根结点:下标1
- 结点i的左孩子:下标 2*i
- 结点i的右孩子:下标 2*i+1
- 结点i的父结点:下标 i/2
cpp
const int N = 1e6 + 10;
int heap[N]; // 存储完全二叉树
// 访问结点i的左孩子
int left_child = heap[2 * i];
// 访问结点i的右孩子
int right_child = heap[2 * i + 1];
// 访问结点i的父结点
int parent = heap[i / 2];注意:普通二叉树用顺序存储会造成大量空间浪费,不适合。
链式存储(适用于一般二叉树)
用数组模拟链式存储,两个数组分别记录左右孩子:
cpp
const int N = 1e6 + 10;
int l[N], r[N]; // l[i]表示结点i的左孩子编号,r[i]表示右孩子编号
// 如果孩子不存在,则值为0
int main() {
int n;
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> l[i] >> r[i]; // 读入每个结点的左右孩子
}
return 0;
}五、二叉树的遍历:三种深搜顺序
二叉树最核心的遍历方式有三种:先序遍历 、中序遍历 、后序遍历 。它们的区别在于访问根结点的时机。
5.1 先序遍历(根左右)
顺序:根结点 → 左子树 → 右子树
cpp
void preorder(int root) {
if(root == 0) return; // 空结点
cout << root << " "; // 访问根
preorder(l[root]); // 遍历左子树
preorder(r[root]); // 遍历右子树
}5.2 中序遍历(左根右)
顺序:左子树 → 根结点 → 右子树
cpp
void inorder(int root) {
if(root == 0) return;
inorder(l[root]); // 遍历左子树
cout << root << " "; // 访问根
inorder(r[root]); // 遍历右子树
}5.3 后序遍历(左右根)
顺序:左子树 → 右子树 → 根结点
cpp
void postorder(int root) {
if(root == 0) return;
postorder(l[root]); // 遍历左子树
postorder(r[root]); // 遍历右子树
cout << root << " "; // 访问根
}5.4 层序遍历(BFS)
层序遍历就是广度优先遍历,按层从上到下、从左到右访问所有结点:
cpp
#include <queue>
void levelorder(int root) {
queue<int> q;
q.push(root);
while(!q.empty()) {
int u = q.front();
q.pop();
cout << u << " ";
if(l[u]) q.push(l[u]);
if(r[u]) q.push(r[u]);
}
}5.5 由两种遍历序列还原二叉树
这是一个经典问题:已知一棵二叉树的中序+前序(或中序+后序),可以唯一确定这棵树。
核心思路:
- 前序序列的第一个元素是根
- 后序序列的最后一个元素是根
- 在中序序列中找到根,左边是左子树,右边是右子树
- 递归处理左右子树
例题 :已知中序BADC,后序BDCA,求前序。
后序最后一个A是根
中序中A左边是B,右边是DC → 左子树有B,右子树有D、C
后序中左子树部分BD,右子树部分C
递归处理...
最终前序:ABCD
cpp
// 已知中序a和后续b,求先序
void dfs(int l1, int r1, int l2, int r2) {
if(l1 > r1) return;
char root = b[r2]; // 后序最后一个为根
cout << root; // 先输出根
int p = l1;
while(a[p] != root) p++; // 在中序中找到根的位置
// 左子树:中序[l1, p-1],后序[l2, l2+p-l1-1]
dfs(l1, p-1, l2, l2+p-l1-1);
// 右子树:中序[p+1, r1],后序[l2+p-l1, r2-1]
dfs(p+1, r1, l2+p-l1, r2-1);
}六、堆:优先级队列的底层实现
6.1 什么是堆?
堆(Heap) 是一种特殊的完全二叉树,它满足以下性质:
- 大根堆 :每个结点的值都大于等于其左右孩子的值
- 小根堆 :每个结点的值都小于等于其左右孩子的值
堆常用来实现优先级队列------每次取出的都是最大(或最小)的元素。
6.2 堆的存储
由于堆是完全二叉树,我们可以用数组顺序存储,下标关系与完全二叉树相同:
cpp
const int N = 1e6 + 10;
int heap[N]; // 堆数组,从下标1开始存储
int sz; // 当前堆中元素个数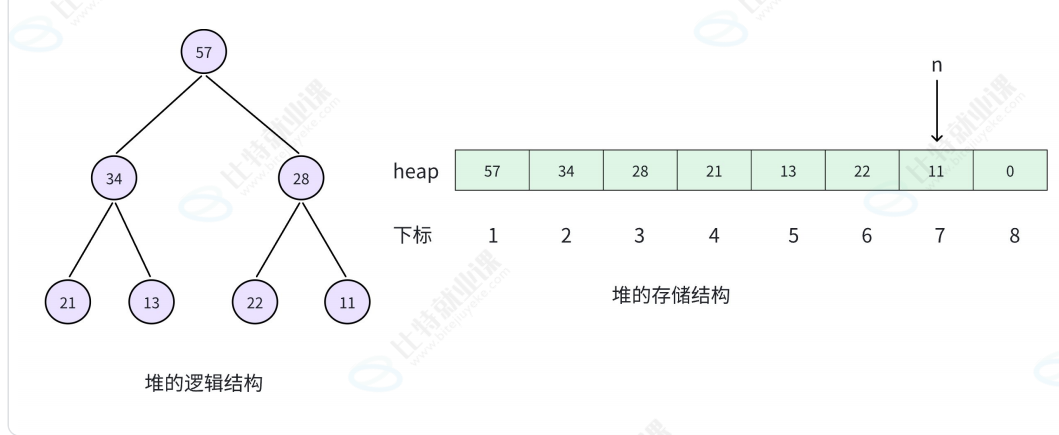
6.3 堆的核心操作
向上调整(up)
当在堆的末尾插入一个新元素时,需要向上调整,维持堆的性质。
cpp
void up(int child) {
int parent = child / 2;
while(parent >= 1 && heap[child] > heap[parent]) { // 大根堆
swap(heap[child], heap[parent]);
child = parent;
parent = child / 2;
}
}向下调整(down)
当删除堆顶元素后,将最后一个元素放到堆顶,需要向下调整。
cpp
void down(int parent) {
int child = parent * 2;
while(child <= sz) {
// 找出左右孩子中较大的(大根堆)
if(child + 1 <= sz && heap[child + 1] > heap[child]) {
child++;
}
if(heap[parent] >= heap[child]) break;
swap(heap[parent], heap[child]);
parent = child;
child = parent * 2;
}
}6.4 堆的基本操作
cpp
// 插入元素
void push(int x) {
heap[++sz] = x;
up(sz);
}
// 删除堆顶
void pop() {
heap[1] = heap[sz--];
down(1);
}
// 获取堆顶
int top() {
return heap[1];
}
// 堆的大小
int size() {
return sz;
}
// 判空
bool empty() {
return sz == 0;
}时间复杂度:所有操作均为(O(\log N))。
6.5 建堆:从无序数组构建堆
方法一:逐个插入,时间复杂度(O(N \log N))
方法二:从最后一个非叶子结点开始,依次向下调整,时间复杂度(O(N))
cpp
void buildHeap(int arr[], int n) {
// 先将数组复制到堆中
for(int i = 1; i <= n; i++) {
heap[i] = arr[i-1];
}
sz = n;
// 从最后一个非叶子结点开始向下调整
for(int i = n / 2; i >= 1; i--) {
down(i);
}
}七、STL中的堆:priority_queue
7.1 基本使用
priority_queue是C++标准库提供的优先级队列,底层就是用堆实现的。
cpp
#include <iostream>
#include <queue> // priority_queue的头文件
using namespace std;
int main() {
// 默认是大根堆
priority_queue<int> heap;
// 插入元素
heap.push(3);
heap.push(1);
heap.push(4);
heap.push(2);
// 获取堆顶(最大值)
cout << heap.top() << endl; // 输出: 4
// 删除堆顶
heap.pop();
// 遍历(边取边删)
while(!heap.empty()) {
cout << heap.top() << " ";
heap.pop();
}
// 输出: 3 2 1
return 0;
}7.2 创建小根堆
cpp
// 方法一:使用greater
priority_queue<int, vector<int>, greater<int>> minHeap;
// 方法二:存入负数(取巧)
priority_queue<int> minHeap; // 本质是大根堆
minHeap.push(-x); // 存入负数,取出来时再取反7.3 存储自定义类型
当堆中存储结构体时,需要重载<运算符。
cpp
struct Node {
int value;
int id;
// 重载<运算符,定义比较规则
bool operator<(const Node& other) const {
return value > other.value; // 小根堆:大的下沉
}
};
priority_queue<Node> heap;7.4 常用操作总结
| 操作 | 代码 | 时间复杂度 |
|---|---|---|
| 插入元素 | heap.push(x); |
(O(\log N)) |
| 删除堆顶 | heap.pop(); |
(O(\log N)) |
| 获取堆顶 | heap.top(); |
(O(1)) |
| 获取大小 | heap.size(); |
(O(1)) |
| 判空 | heap.empty(); |
(O(1)) |
八、算法题实战
8.1 二叉树深度
题目:给定一棵二叉树,求其深度(从根到叶子经过的最大结点数)。
思路:递归求解,深度 = 1 + max(左子树深度, 右子树深度)。
cpp
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int l[N], r[N];
int dfs(int root) {
if(root == 0) return 0;
return max(dfs(l[root]), dfs(r[root])) + 1;
}
int main() {
int n;
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> l[i] >> r[i];
}
cout << dfs(1) << endl;
return 0;
}8.2 堆模板题
题目:实现一个堆,支持插入、获取最小值、删除最小值。
思路 :手写小根堆或直接用priority_queue。
cpp
#include <iostream>
#include <queue>
using namespace std;
int main() {
priority_queue<int, vector<int>, greater<int>> heap;
int n;
cin >> n;
while(n--) {
int op, x;
cin >> op;
if(op == 1) {
cin >> x;
heap.push(x);
} else if(op == 2) {
cout << heap.top() << endl;
} else {
heap.pop();
}
}
return 0;
}8.3 第k小
题目:动态维护一个序列,支持插入和查询第k小的数。
思路:维护一个大根堆,始终保持堆的大小为k,堆顶就是第k小的数。
cpp
#include <iostream>
#include <queue>
using namespace std;
int main() {
int n, m, k;
cin >> n >> m >> k;
priority_queue<int> heap; // 大根堆
// 先插入n个初始元素
for(int i = 0; i < n; i++) {
int x;
cin >> x;
heap.push(x);
if(heap.size() > k) heap.pop();
}
while(m--) {
int op;
cin >> op;
if(op == 1) {
int x;
cin >> x;
heap.push(x);
if(heap.size() > k) heap.pop();
} else {
if(heap.size() == k) {
cout << heap.top() << endl;
} else {
cout << -1 << endl;
}
}
}
return 0;
}九、总结与对比
9.1 树与线性结构的对比
| 特性 | 线性结构 | 树形结构 |
|---|---|---|
| 关系类型 | 一对一 | 一对多 |
| 遍历方式 | 简单顺序 | DFS/BFS |
| 应用场景 | 列表、队列、栈 | 层次关系、分治问题 |
9.2 二叉树 vs 堆
| 特性 | 普通二叉树 | 堆 |
|---|---|---|
| 形态 | 任意形状 | 完全二叉树 |
| 性质 | 无特殊要求 | 父结点 >= 子结点(大根堆) |
| 存储 | 链式为主 | 顺序存储 |
| 用途 | 表达层次关系 | 优先级队列 |
9.3 选择建议
- 需要表达层次关系(如组织架构、文件系统)→ 树
- 需要快速获取最大/最小值 → 堆
- 需要快速查找、插入、删除 → 二叉搜索树(后续文章)
- 需要处理优先级队列 → priority_queue
写在最后
树形结构是算法竞赛中最重要的数据结构之一。从简单的树的遍历,到复杂的二叉搜索树、线段树、树状数组,再到树形DP,都离不开对树的理解。
本文我们学习了:
- 树的定义与基本术语
- 树的存储方式(vector数组、链式前向星)
- 树的遍历(DFS、BFS)
- 二叉树的三种深度优先遍历
- 堆的定义与实现
- STL中的priority_queue
下一篇预告:我们将深入探讨二叉搜索树与平衡树------如何让树在动态变化中保持高效查找。
练习建议:
- 用DFS和BFS分别遍历一棵树,理解两种方式的区别
- 手写二叉树的三种遍历,理解递归的本质
- 手写堆的所有操作,理解up和down的作用
- 用priority_queue完成洛谷P3378【模板】堆
树是递归思想的最佳载体。当你真正理解了树的递归遍历,你就打开了通往高级算法的大门。
祝你在蓝桥杯的备赛路上越走越远!🚀