云端 OpenClaw 远程执行本地进程原理机制详解:Gateway、approvals 与 system.run 到底谁在判定、谁在执行?
前言
在使用 OpenClaw 搭建"云端 Gateway + 本地 Windows 节点"的远程执行体系时,最容易混淆的一件事,不是命令本身怎么写,而是命令到底是谁决定能不能执行,谁又真正负责把它跑起来。
很多人在刚接触这套架构时,脑子里往往会把几个概念混在一起:
- 以为云端 Gateway 已经设置成
tools.exec.host=node,那命令就一定能直接在本地执行; - 以为
system.run既是执行器,也是审批器; - 以为白名单只要在云端配一次,就对所有节点通用;
- 以为
node.list能看到节点,就说明nodes run一定能成功; - 以为 SSH 隧道通了,就代表整条远程执行链路已经完全打通。
实际上,这些理解都只看到了局部,没有把 OpenClaw 的控制面、执行面、安全联锁、协议分层放在一个统一的框架里看。
这篇文章就围绕一个核心问题展开:
OpenClaw 的远程命令执行,到底是如何从"云端发起请求"一步步走到"本地机器真正启动进程"的?
如果要用一句最直白的话概括整套机制,那就是:
Gateway 负责调度和下令,node 负责暴露本机能力,本地 approvals 负责决定这台机器最后是否同意执行,而 system.run 负责真正把命令跑起来。
这四者不是一个东西,也不是同一层逻辑。只有把它们彻底拆开,很多现象才能解释得通。
一、先把最容易混淆的三层拆开
在 OpenClaw 的远程执行体系里,最值得先建立的不是某个具体命令,而是"分层思维"。
从原理上看,至少要把下面三层分开理解:
- 云端 Gateway 的默认执行策略层
- 本地执行主机上的 approvals / allowlist 层
- 真正落到主机上执行的 system.run 层
很多问题之所以越排越乱,根本原因就在于把这三层混成了一层,以为"能连上节点 = 节点一定能执行 = system.run 已经有权限跑命令"。
实际上并不是这样。
更准确地说,OpenClaw 的设计是一个典型的"控制平面与执行平面分离"架构:
- 控制面在 Gateway 一侧,负责决定请求该发给谁、按什么规则发、是否要求审批;
- 执行面在 node 一侧,负责把本机真实能力暴露给 Gateway;
- 主机侧安全联锁又独立存在于执行主机本机上,作为最后一道安全闸门;
- system.run 只是执行动作的最终落点,并不是前面所有策略判断的替代品。
所以,要真正读懂"再结合 approvals 去调用 system.run"这句话,首先就要知道:
system.run 不是先执行再审批,而是前面所有策略都通过之后,才有机会真正启动进程。
二、第一层:云端 Gateway 的默认执行策略到底在管什么
先看第一层,也就是最上层的Gateway 默认执行策略。
在你的这套部署中,像 tools.exec.host、tools.exec.security、tools.exec.ask、tools.exec.node 这几个配置,实际上都属于这一层。它们定义的不是"某台主机上的本地规则",而是控制面默认想怎么发起执行请求。
1.1 tools.exec.host:决定默认执行位置
这个配置决定的是:
- 到 sandbox 执行;
- 到 gateway 所在机器执行;
- 还是发给某台 node 执行。
也就是说,它解决的是一个最顶层的问题:
默认把执行请求发到哪里。
它只是"调度意图",不是最终执行结果。
1.2 tools.exec.security:决定默认安全模式
这个配置不是在本地机器上直接执行白名单,而是定义 Gateway 在形成执行请求时默认遵循什么安全策略,比如:
denyallowlistfull
它表达的是控制面对于执行请求的默认安全态度。
1.3 tools.exec.ask:决定默认是否弹审批
这个配置决定在控制面层面,遇到执行请求时要不要交互确认。例如:
- 始终不提示;
- 未命中规则时提示;
- 总是提示。
本质上它解决的是:
在请求进入执行面之前,控制面是否希望引入用户交互式审批。
1.4 tools.exec.node:决定默认目标节点
当执行目标是 node 时,这个配置负责指定默认发给哪一台节点。
它解决的不是权限问题,而是路由问题。
1.5 这一层的本质:定义"默认执行意图"
因此,把这几个配置合起来看,就能发现一个很重要的结论:
tools.exec.*本质上是在定义 Gateway 这一侧的默认执行意图,而不是对执行主机作最终裁决。
也就是说,即便你已经把云端 Gateway 配成"默认发到 node、默认走 allowlist、默认不 ask",它也只代表:
- 请求会优先往 node 发;
- 安全模型按 allowlist 预期处理;
- 控制面默认不额外交互。
但这还远远没有走到"命令一定会在 Windows 上成功执行"那一步。
三、第二层:什么是本地 approvals,它为什么才是主机侧最后一道闸门
理解了 Gateway 的默认策略之后,接下来要看第二层:执行主机本地的 approvals。
这是很多人第一次接触时最容易忽略,但实际上最关键的一层。
3.1 approvals 不是云端全局规则,而是执行主机本地规则
所谓"本地 approvals",最直接的理解就是:
真正负责执行命令的那台机器,自己本地保存的一份命令运行规则文件。
如果你的执行主机是 Windows 节点,那么这份文件通常就在 Windows 用户目录下,例如:
text
C:\Users\你的用户名\.openclaw\exec-approvals.json这说明一件非常重要的事:
approvals 不是放在云端 Gateway 上给所有机器通用的全局白名单,而是每一台执行主机各自持有的一份本地规则。
换句话说,谁负责真正落地执行,谁就有自己的审批文件。
3.2 approvals 管的不是"模型想不想执行",而是"这台机器愿不愿意执行"
这层的意义必须说透。
大模型、CLI、Gateway 都可以形成"执行请求",但真正承担风险的是执行主机本身。因为一旦命令落地,它影响的是那台机器上的:
- 文件系统;
- 用户目录;
- 桌面环境;
- 本地脚本;
- 系统命令;
- 甚至某些可访问的网络资源。
所以 approvals 的本质不是模型侧行为约束,而是资产拥有者视角下的主机安全联锁。
可以把它理解成一句非常白的话:
云端可以"建议执行",但本地机器有权说"这条命令我不接"。
3.3 为什么 approvals 必须放在执行主机本地
这是 OpenClaw 这套设计最值得理解的地方之一。
如果所有审批都只放在云端,那就意味着:
- 远端控制面一旦配置错误,可能直接影响所有执行主机;
- 本地主机对自己资产的最后控制权会被削弱;
- 安全边界会全部前移到远端,不符合"风险由资产拥有者最终把关"的原则。
而把 approvals 放在执行主机本地,就实现了一个非常典型、也非常合理的机制:
最后一道生死线不在控制面,而在实际承担风险的宿主机一侧。
这就是为什么说 approvals 是 node host 的 guardrail,是主机侧的 safety interlock。
3.4 approvals 里真正判定什么
这一层一般会包含类似下面这些维度:
securityaskaskFallbackallowlist- 按 agent 生效的规则
其中最敏感的,就是 allowlist。
因为它直接决定:
哪些命令入口、哪些脚本、哪些可执行程序,允许在这台机器上被远程触发。
如果一个命令没有命中 allowlist,又没有可用的审批 UI,那它就会停在 approvals 这一层,而不是继续往下进入真正的执行层。
这也就是很多人会碰到的那种现象:
text
approval required (approval UI not available)这个报错的真正含义不是"system.run 坏了",而是:
命令在本地 approvals 这一关被拦住了,根本还没有机会真正落到 system.run。
四、第三层:system.run 到底是什么,它是不是"最终权限拥有者"
讲到这里,才轮到第三层,也就是很多人最先注意到、但最容易误解的 system.run。
4.1 system.run 的本质:真实主机上的命令执行器
如果用一句话给它定性,那么最准确的说法是:
system.run 是执行器,不是裁判器。
它的职责非常单纯:
- 在节点主机上启动一个真实的本地进程;
- 把命令真正交给宿主机操作系统去运行;
- 返回执行结果、错误信息或运行状态。
你可以把它类比成"远程桌面环境里的启动程序动作",也可以把它理解成"节点主机暴露出来的 CreateProcess 接口入口"。
它负责的是把命令跑起来,不是负责决定"这条命令是否应当被允许跑起来"。
4.2 为什么说 system.run 很敏感
因为一旦它被真正调用,落地的就不再是 OpenClaw 自己的内部逻辑,而是宿主机上的真实命令执行。
它理论上可能启动的对象包括但不限于:
- 系统自带命令,如
where.exe; - 用户自己编写的批处理脚本,如
paper_scan.cmd; - PowerShell;
- 其他被允许的本地二进制程序;
- 依赖本地环境变量的命令入口。
这就是为什么 system.run 看似只是一个"命令执行能力",但它的权限边界非常敏感。因为它一旦真的被触发,本机真实资源就可能被访问或修改。
4.3 它不是"无限授权",而是"继承宿主机运行身份的能力"
这里必须纠正一个很常见的误区:
很多人会把 system.run 想象成一个天然拥有高权限的系统级执行器,仿佛只要通过了它,就等于自动拿到了这台机器的全部控制权。
这并不准确。
更严谨的理解应该是:
system.run 本身并不凭空创造权限,它继承的是 node host 运行账户在宿主机上的权限边界。
这意味着:
- 如果 node host 是以普通用户身份启动的,那么
system.run启动出来的进程通常也只是普通用户权限; - 如果 node host 可以访问当前用户目录、桌面、文献目录,那么
system.run在规则允许的前提下,原则上也可能访问这些位置; - 如果某些操作需要管理员权限,而 node host 当前没有提权能力,那
system.run也不会神奇地自动越权。
所以,system.run 的权限上限,大体上就等于:
启动 node host 的那个 Windows 用户本来能做什么。
4.4 为什么最佳实践不是直接放开 PowerShell,而是只放固定脚本入口
从工程实践角度看,最稳妥的做法通常不是 allowlist 一个功能极强的通用解释器,而是只允许固定用途的脚本入口,例如:
text
paper_scan.cmd
paper_rename.cmd
paper_classify.cmd这样做的好处非常明显:
- 把执行能力收敛到你自己定义过的流程入口;
- 降低远程任意命令拼接带来的风险;
- 便于审计、回放、排错;
- 更适合作为可控的自动化节点能力暴露给 Gateway。
所以,真正安全的思路从来不是"给 system.run 更多权力",而是:
让
system.run只被允许走你定义好的、边界清晰的受控入口。
五、把整句话讲透:什么叫"再结合 approvals 去调用 system.run"
这是最值得拆开讲透的一句话。
原话听起来容易让人误解成一种线性直觉:
- 先调用
system.run; - 再看 approvals;
- 不通过就拦掉。
但真实机制恰恰不是这样。
更准确的理解应该是:
控制面先决定原则上怎么发,本地主机再决定这条请求是否允许落地,只有两边都通过之后,system.run 才会被真正调用。
换句话说:
不是先跑了再审批,而是审批通过之后才真正执行。
六、按时序看完整判定链:一条命令是怎么一步步落地的
如果把整个过程按时间顺序展开,通常可以拆成下面 5 步。
第 1 步:模型、CLI 或自动化流程形成执行请求
一切的起点,都是某个控制面主体发起了一个"希望执行命令"的请求。这个主体可能是:
- 模型驱动的操作;
- CLI 命令,如
openclaw nodes run; - 自动化任务;
- UI 上的某次执行动作。
这一阶段还没有真正碰到执行主机,只是生成了一个执行意图。
第 2 步:Gateway 根据 tools.exec.* 看默认策略
接下来,Gateway 会先根据自己的默认配置来判断:
- 这条请求应该发到 sandbox、gateway 还是 node;
- 安全模式默认是什么;
- 遇到执行是否需要弹审批;
- 默认目标 node 是哪一台。
注意,这一步仍然只是控制面判断。
它解决的是"原则上应该怎么发 ",不是"执行主机是否最终同意执行"。
第 3 步:Gateway 把请求转发给目标 node
当目标是某台 node 时,Gateway 会把这条请求通过与 node 的连接通道发过去。
这一步体现的是控制面与能力宿主之间的转发关系。
也就是说,Gateway 并不是自己替 node 执行命令,而是:
把控制面形成的执行请求,交给具备相应能力的 node host。
第 4 步:node 在本机读取 exec-approvals.json 再判一次
到了这一步,事情才真正进入主机侧安全联锁。
node 会根据本机的 approvals 规则再做一次判断,包括:
- 这条命令是否符合本地
security策略; - 是否命中 allowlist;
- 是否需要
ask; - 未命中时是否走
askFallback; - 当前环境有没有可用审批 UI。
这一关非常关键,因为它代表的是:
即使 Gateway 愿意发,本地执行主机也仍然可以拒绝。
第 5 步:前面都通过后,node 才真正调用 system.run
只有在前面所有条件都通过后,才会真正落到最终执行层。
也就是:
- node 调用
system.run; - 宿主机启动本地进程;
- 返回真实执行结果。
这一步才叫"命令真正落地"。
因此,整条链路最准确的白话版可以概括成一句:
先在控制面决定原则上允不允许发,再在执行主机决定这台机器到底准不准跑,最后才真正启动进程。
七、为什么 node.list 能成功,不代表 nodes run 一定成功
这是远程执行场景里最常见、也最容易让人误判的问题之一。
很多人看到:
gateway call node.list能拿到节点;- 节点状态是 paired;
- 节点状态是 connected;
就会自然得出一个错误结论:
既然节点在线,那执行命令肯定没问题。
其实这个推理跳过了很多层。
7.1 node.list 成功,只能说明"节点注册与连接层"是通的
当 node.list 正常返回时,它最多只能说明:
- SSH 隧道大概率没问题;
- Gateway 本身在工作;
- 节点确实已经注册到 Gateway;
- 当前节点连接状态正常;
- Gateway 能看到节点的能力声明。
但这些都还只是"能看到节点",不等于"能成功调起节点能力执行命令"。
7.2 nodes run 失败,可能卡在更后的任意一层
nodes run 真正失败的位置,可能在后面很多层里:
- CLI 当前版本的节点命令调用通道本身存在不稳定;
- Gateway 到 node 的具体命令分发过程中断;
- 节点能力声明与调用不匹配;
- approvals 未命中 allowlist;
- 审批 UI 不可用导致卡在
approval required; - 本机命令入口不存在;
system.run启动目标进程失败。
因此,node.list 与 nodes run 根本不是同一个层次的成功标准。
一个是在看:
我能不能看到节点。
另一个是在看:
我能不能穿过整条执行链,最终让命令在主机上真的跑起来。
这两者之间隔着:
- 协议层;
- 角色层;
- 能力层;
- 主机审批层;
- 最终执行层。
所以,node.list 能成功,只能证明"前几层没问题",绝不能直接推出"命令执行链已经完全打通"。
八、所谓"远距离通信协议层级需要对应",到底是什么意思
很多人在排查远程节点问题时,会说一句很抽象的话:
协议层级需要对应。
这句话如果不拆开,很容易流于空泛。其实它背后讲的是一整套分层链路。
要把它说清楚,可以从下往上分成六层来看。
九、第一层:网络可达层------先解决"能不能连到"
这是最底层。
例如你的架构里,可能是这样的:
- 云端 Gateway 监听在云服务器
127.0.0.1:18789 - Windows 本地通过 SSH 隧道,把本地
18790映射到云端127.0.0.1:18789
这一层的职责只有一个:
让本地 node 看起来像是在连本地端口,实际上流量通过 SSH 转发到云端 Gateway。
注意,这一层只解决了"TCP 路能不能打通"。
它解决不了下面这些问题:
- Gateway 协议是否正确;
- WebSocket 是否握手成功;
- 鉴权是否通过;
- 角色是否匹配;
- 节点能力是否存在;
- approvals 是否放行。
所以网络通,不代表执行通。
十、第二层:WebSocket 连接层------不是裸 TCP,而是承载会话语义的连接
node host 并不是向某个随便的 TCP 端口发送字符串,而是要连接到 Gateway WebSocket。
这意味着 SSH 隧道里承载的,不是"裸 TCP 上随便发点字节",而是:
WebSocket over forwarded TCP
也就是说,网络可达只是基础,真正进入 OpenClaw 通信语义的起点是 WebSocket 连接建立成功。
如果这一层失败,哪怕端口是通的,node 也没法变成一个真正挂接到 Gateway 上的能力宿主。
十一、第三层:Gateway 协议层------连上了,不代表会说"同一种话"
即使 WebSocket 连上了,也还不够。
因为在 WebSocket 之上,OpenClaw 还有自己的一套消息协议。
从抽象上看,这一层会涉及类似这样的消息结构:
- Request:请求某个方法调用;
- Response:返回成功或失败;
- Event:推送某类状态事件。
也就是说,SSH 隧道和 WebSocket 只是通信管道,而 Gateway 协议层才是真正约定:
- 消息长什么样;
- 谁发请求;
- 谁回响应;
- 如何标识方法、参数、结果和错误;
- 初始握手时如何表明身份和能力。
所以,"协议层级需要对应"在这里的第一重含义就是:
链路打通了,不代表双方已经能用同一种协议语义正常通信。
十二、第四层:角色与作用域层------为什么 CLI 和 node 同样连着 Gateway,干的事却完全不同
继续往上,就进入角色层。
在这套体系中,虽然很多东西都连接到同一个 Gateway,但它们并不是同一种身份。
例如可以粗略区分为两类:
- operator:CLI、UI、automation 这类控制面客户端;
- node:暴露能力的宿主,例如 system、browser、screen 等。
这个区分非常关键,因为它决定了:
- 谁负责发请求;
- 谁负责提供能力;
- 谁拥有读取、写入、管理、配对等不同范围的操作权;
- 谁可以注册自身能力,谁只是去调用别人的能力。
所以,即使 CLI 和 node 同样都"连着 Gateway",两者在体系里的角色完全不同:
- CLI 更像调度者、管理者、调用者;
- node 更像资源宿主、能力提供者、执行者。
这也是为什么不能简单地把"连上 Gateway"理解成"所有连接对象都拥有同样的能力"。
十三、第五层:节点能力声明层------节点在线,不代表什么命令都能接
再往上,是很多人经常忽视的一层:节点能力声明。
node 被 Gateway 看到,只代表这台机器已经作为一个能力宿主接入了系统。但它真正能做什么,还要看它对外声明了哪些能力和命令。
例如某个节点可能声明:
caps: browser, systemcommands: browser.proxy, system.run, system.run.prepare, system.which
这表示 Gateway 不是"想给它发什么就发什么",而是只能调用它明确声明过的命令入口。
因此,如果某个节点只声明了浏览器代理能力,却没有声明 system.run,那它即使在线,也不具备执行本地命令的能力。
所以这里又出现一个非常关键的判断:
节点在线 ≠ 节点具备目标能力。
要真正能执行命令,还必须满足:
- 节点在线;
- 节点已配对;
- 节点声明了
system.run; - 命令分发正确到这台节点。
十四、第六层:主机审批层------这才是"能不能真的落地"的最后裁决
在前面所有层都通过后,最后仍然要回到主机本地 approvals。
这一步的意义可以总结成一句:
即使控制面通了、协议通了、角色对了、能力也存在,本地机器仍然保有最终拒绝权。
这是整套架构最稳的地方,也是最容易被忽略的地方。
因为在很多远程控制系统里,人们习惯把"控制面已经授权"理解成"执行面必然服从"。但 OpenClaw 这里并不是这样的逻辑。
它保留了一条非常明确的原则:
宿主机对自己的命令执行拥有最终同意权。
也正因为有这一层,系统才能做到在远程调度和本地主机安全之间取得平衡。
十五、把整条链浓缩成一句真正准确的话
如果把前面六层再压缩成一句最准确的话,那就是:
隧道层、WebSocket 层、Gateway 协议层、角色/作用域层、节点能力层、主机审批层,必须一层层都通过,最后 system.run 才会真正落地执行。
这句话看似长,但它恰恰解释了远程执行中最常见的误区:
- 不是"能连上"就等于"能执行";
- 不是"能看到节点"就等于"能下发命令";
- 不是"声明了 system.run"就等于"这台主机愿意执行";
- 不是"Gateway 默认允许"就等于"本地 approvals 会放行"。
只有把这些层分开,排障思路才会变得清晰。
十六、最容易出现的几个误区,一次讲透
误区 1:Gateway 配成 host=node 就等于节点一定能执行
错误原因在于把"调度目标"当成了"执行结果"。
host=node 只能说明默认往节点发,不代表本地 approvals 一定放行,也不代表节点一定声明了正确能力,更不代表目标命令一定存在。
误区 2:system.run 自己决定权限
system.run 不是自带无限权限的神秘接口。它只是在 node host 的宿主环境里启动进程,权限边界取决于运行 node host 的那个本地账户。
误区 3:云端安全策略能替代本地 approvals
不能。云端策略解决的是"控制面怎么发",本地 approvals 解决的是"宿主机愿不愿意接"。这两者不是重复关系,而是串联关系。
误区 4:SSH 隧道通了,远程执行就没问题了
SSH 隧道只解决网络可达,后面还有 WebSocket、协议、角色、能力、审批等层次。
误区 5:node.list 正常,nodes run 失败一定是架构错了
不一定。很多情况下更可能是:
- 节点命令调用链不稳定;
- 能力分发存在问题;
- approvals 未命中;
- 审批 UI 缺失;
- 本地命令入口未放行或不存在。
十七、从安全设计角度看,这套机制为什么合理
如果把 OpenClaw 这套设计放到更一般的软件架构视角去看,会发现它其实非常像成熟系统里常见的"多层联锁"思想。
17.1 控制面与执行面分离
这样做的好处是:
- 调度逻辑集中;
- 执行能力分布式暴露;
- 不同宿主机可以拥有不同能力与不同安全边界;
- 节点侧可以根据自己的风险暴露程度设置本地审批规则。
17.2 本地宿主机保有最终决定权
这避免了"远端控制面一旦出错,所有本地主机被一锅端"的风险。
17.3 白名单而不是全开放
从安全角度看,远程自动化系统最怕的不是"功能不够强",而是"边界不清"。
把 system.run 收缩为少量固定入口脚本,实际上是在把"通用执行器"改造成"受控流程触发器"。这比直接开放一个通用 shell 要稳得多。
17.4 多层串联比单层放权更可审计
当系统分成:
- 调度层;
- 协议层;
- 能力层;
- 审批层;
- 执行层;
每一层都可以成为排障点、审计点、日志点。这对线上系统稳定性和安全性都非常重要。
十八、实战建议:如何把 system.run 用得既稳又可控
如果目标是让 OpenClaw 在本地 Windows 节点上执行自动化流程,又不想把风险放大,比较推荐的思路不是"尽可能开放",而是"尽可能收敛"。
18.1 不要优先开放通用解释器
例如不要一上来就把 PowerShell、cmd 的任意执行能力完全放开。
因为这等于把 system.run 变成一个泛用远程 shell,安全边界会非常大。
18.2 优先只开放固定用途脚本
更好的做法是围绕任务设计稳定入口,例如:
text
paper_scan.cmd
paper_rename.cmd
paper_classify.cmd每个脚本只干一类事,参数也尽可能收敛。这样既方便 allowlist 管控,也方便后续扩展自动化流程。
18.3 把复杂逻辑放进脚本,不要放进远程拼接命令
让远端只触发入口,把真正复杂的业务逻辑固化在本地脚本里,会比远程拼接长命令稳定得多,也安全得多。
18.4 排障时一定分层看问题
不要一看到执行失败就只盯着 system.run。正确做法应该是按层往下排:
- 网络层通不通;
- WebSocket 是否已连上;
- Gateway 是否能看到节点;
- 节点是否已 paired / connected;
- 节点是否声明了目标 command;
- 本地 approvals 是否命中 allowlist;
- 目标命令入口在宿主机上是否真实存在;
- node host 运行身份是否具备足够权限。
只有这样,问题定位才会高效。
十九、一个帮助理解的总流程图
下面用一个简单的 ASCII 流程图,把这整套机制串起来:
text
[模型 / CLI / 自动化]
|
v
[Gateway 控制面]
- 读取 tools.exec.host
- 读取 tools.exec.security
- 读取 tools.exec.ask
- 读取 tools.exec.node
|
v
[将请求转发给目标 node]
|
v
[node host 本机]
- 读取 exec-approvals.json
- 校验 security / ask / allowlist
|
通过? |----------------------否-------------------->
| [approval required / reject]
v
[调用 system.run]
|
v
[Windows 本地真实进程启动]
|
v
[返回执行结果]这个图最重要的意义,是把"谁负责什么"彻底分开:
- Gateway 负责调度与默认策略;
- node 负责承接请求与暴露本机能力;
- approvals 负责主机侧最终放行;
- system.run 负责真正执行。
二十、结语:真正应该记住的不是命令,而是判定链
很多人学习远程执行系统时,最先关注的是命令怎么写、端口怎么转发、节点怎么配对。但从长期来看,真正决定你是否能把系统用稳、排障排准、边界管住的,不是这些表层操作,而是对整条执行判定链的理解。
OpenClaw 这套机制的关键,不在于某一个点多么复杂,而在于它把"调度""能力暴露""本地审批""真实执行"明确拆成了不同层。
也正因为这种分层足够清晰,它才具有两个非常重要的优点:
一方面,控制面可以统一调度云端与本地节点,具备良好的扩展性;另一方面,本地宿主机又始终保有最后一道安全控制权,不会因为远端一个配置就把执行权完全放飞。
所以,最后只需要记住一句最核心的话:
Gateway 负责"调度和下令",node 负责"暴露本机能力",本地 approvals 负责"这台机器最后是否同意执行",而 system.run 负责"真的把命令跑起来"。其中任意一层没过,命令都不会真正落地。
这句话理解透了,OpenClaw 远程执行的大部分原理和排障逻辑,基本也就通了。
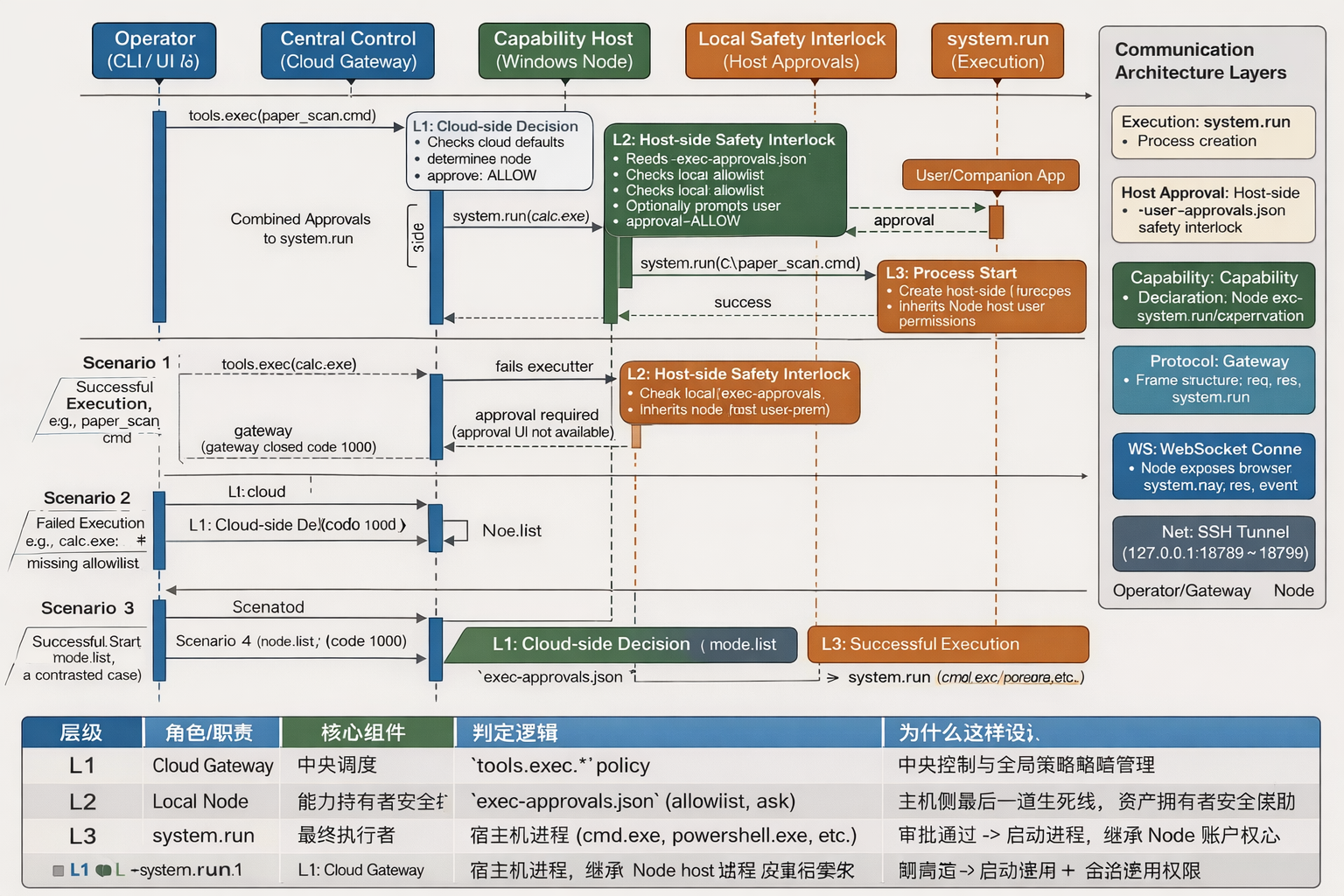
附:一段最简明的总结,适合作为文章摘要或开头导语
在 OpenClaw 的远程执行架构中,云端 Gateway 负责根据 tools.exec.* 配置形成默认执行策略,决定请求原则上发往哪里、按什么安全模式处理、是否需要审批;目标 node 负责作为能力宿主接收请求,并在本机读取 exec-approvals.json 做最后一道主机侧判定;只有当控制面策略与本地 approvals 同时放行后,节点才真正调用 system.run 在宿主机上启动本地进程。因此,system.run 是最终执行者而不是最终裁判者,SSH 隧道打通、节点在线、node.list 成功都不等于命令一定能落地执行,真正的执行链必须依次通过网络层、WebSocket 层、Gateway 协议层、角色/作用域层、节点能力层和主机审批层。