****论文题目:****MOMENT: A Family of Open Time-series Foundation Models(一组开放的时间序列基础模型)
会议:ICML2024
****摘要:****我们介绍MOMENT,这是一组用于通用时间序列分析的开源基础模型。在时间序列数据上预训练大型模型是具有挑战性的,因为:(1)缺乏一个大型的、有凝聚力的公共时间序列存储库;(2)时间序列特征的多样性使得多数据集训练变得繁重。此外,(3)评估这些模型的实验基准,特别是在资源、时间和监督有限的情况下,仍处于初级阶段。为了应对这些挑战,我们编译了一个庞大而多样的公共时间序列集合,称为时间序列堆,并系统地解决时间序列特定的挑战,以解锁大规模多数据集预训练。最后,我们以最近的工作为基础,设计了一个基准来评估有限监督设置下不同任务和数据集上的时间序列基础模型。在这个基准上的实验证明了我们的预训练模型在最小数据和特定任务微调下的有效性。最后,我们提出了一些关于大型预训练时间序列模型的有趣的经验观察结果。
预训练模型(AutonLab/MOMENT-1-large)和时间序列桩(AutonLab/Timeseries-PILE)可在https://huggingface.co/AutonLab上获得。
MOMENT:面向通用时序分析的开源基础模型家族
一、为什么需要时序基础模型?
在自然语言处理和计算机视觉领域,大规模预训练基础模型(Foundation Model)已经彻底改变了研究范式------BERT、GPT、ViT 只需少量下游数据微调,便能在各类任务上取得出色表现。
然而,时序分析领域至今缺乏类似的通用预训练模型。无论是预测天气、监测心律失常的 ECG,还是检测软件部署中的异常流量,现有方法几乎都需要针对每个数据集、每个任务单独从头训练------耗时、耗力,且在数据稀缺时效果堪忧。
MOMENT 正是为填补这一空白而生:它是首个面向通用时序分析的开源大规模预训练模型家族,一套模型覆盖预测、分类、异常检测、缺失值填补四大任务。
二、要解决的三大核心挑战
论文明确指出,预训练大型时序模型之所以长期停滞,根源在于三个相互交织的难题。
挑战 1:缺乏大规模统一的公开时序语料库
NLP 有 The Pile(800 GB 多样文本),CV 有 ImageNet-1K,而时序数据集的现状是:规模小、分散、高度任务专用。现有每个公开数据集几乎都只服务于一类任务,没有人将它们系统地整合在一起。
挑战 2:多数据集联合训练极为困难
文本和图像有相对一致的输入格式,而时序数据在以下维度上差异巨大:
- 时间分辨率:分钟级、小时级、日级......
- 通道数:单变量 vs. 几百个变量
- 序列长度:几十到几万个时间步
- 幅值:量纲和数量级天差地别
- 缺失值:部分数据集存在大量空洞
因此,"混合多个数据集一起训练"这件在 NLP 看来理所当然的事,在时序领域几乎是一片空白。
挑战 3:评估基准不完善
现有评测基准大多只比较在充分数据条件下全量微调的性能,缺乏对 zero-shot、few-shot、linear probing 等有限监督场景的系统考量------而这些场景恰恰是基础模型最应该发光的地方。
三、MOMENT 的解决方案
3.1 构建 Time Series Pile:首个大规模时序预训练语料库
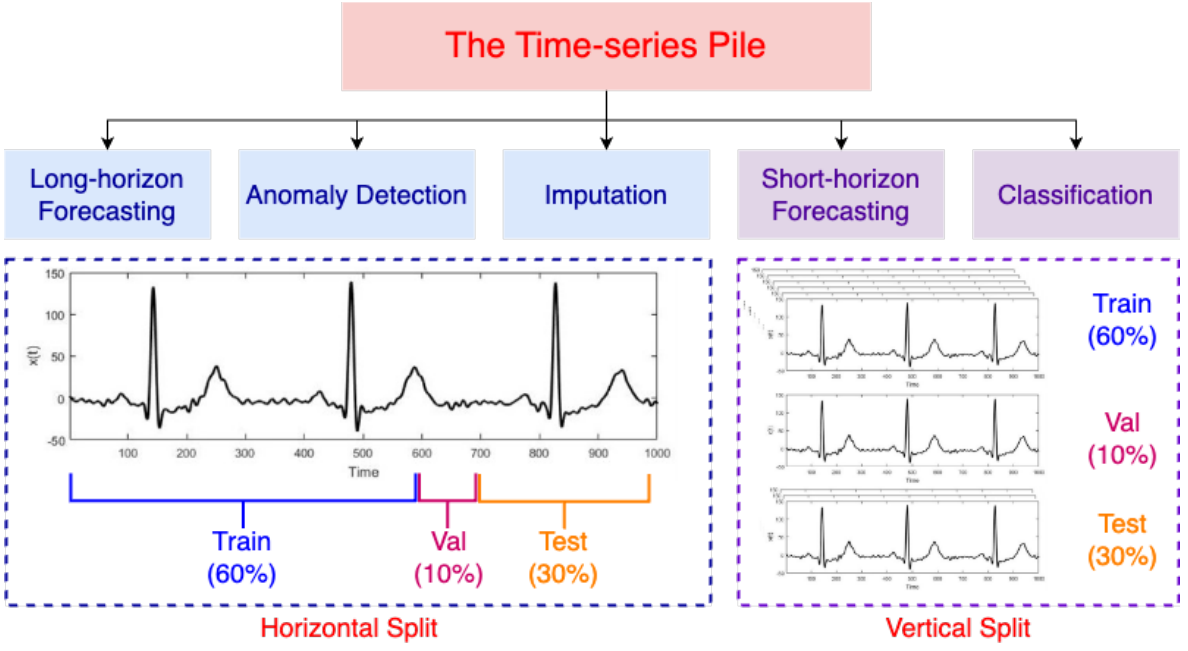
Figure 2(Time Series Pile 数据划分示意图):为了避免数据污染,我们仔细地将所有数据集划分为不相交的训练、验证和测试部分。我们遵循每个数据集创建者提供的预定义分割。在这种分割不可用的情况下,我们随机抽取60%的数据用于训练,10%用于验证,30%用于测试。我们只使用所有数据集的训练分割进行预训练。
为了解决数据匮乏问题,论文整合了 4 大主流公开时序数据库:
| 来源 | 说明 |
|---|---|
| Informer 长期预测数据集 | 9 个数据集,涵盖电力、气象、交通等 |
| Monash 短期预测档案 | 58 个数据集,共 10 万余条时序 |
| UCR/UEA 分类档案 | 159 个分类数据集,7 大类别 |
| TSB-UAD 异常检测基准 | 1980 条带标注异常的单变量时序 |
最终,Time Series Pile 覆盖 13 个领域 (医疗、工业、金融、气象、交通等),包含 1300 万条时序 、12.3 亿个时间戳,数据总量达 20 GB。
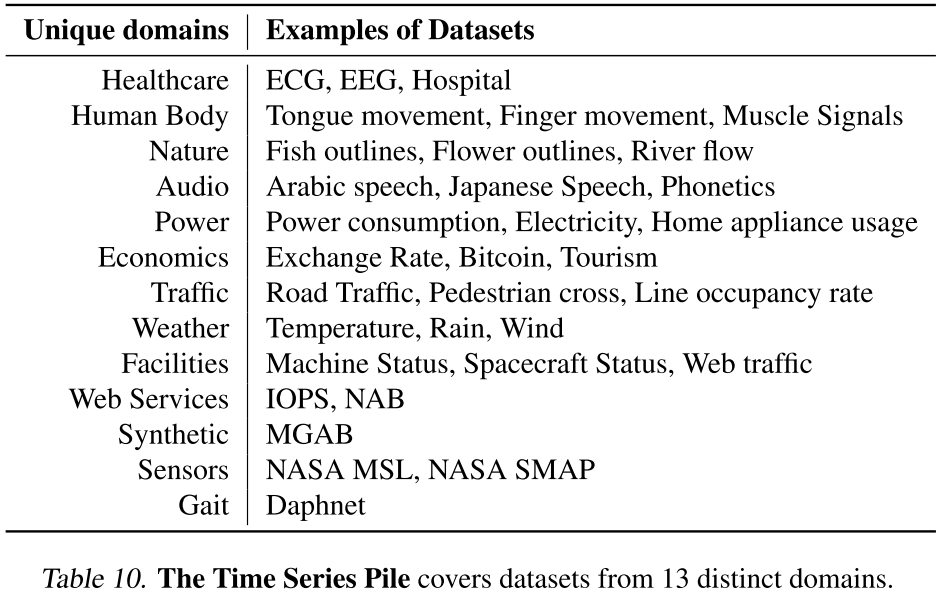
Table 10(Time Series Pile 13 个领域一览)
为防止数据污染,论文对每个数据集严格划分训练/验证/测试集。长时序按时间段水平切割,短时序按条垂直分配,预训练仅使用训练集部分,随机种子固定为 13 以保证可复现性。
3.2 MOMENT 模型架构
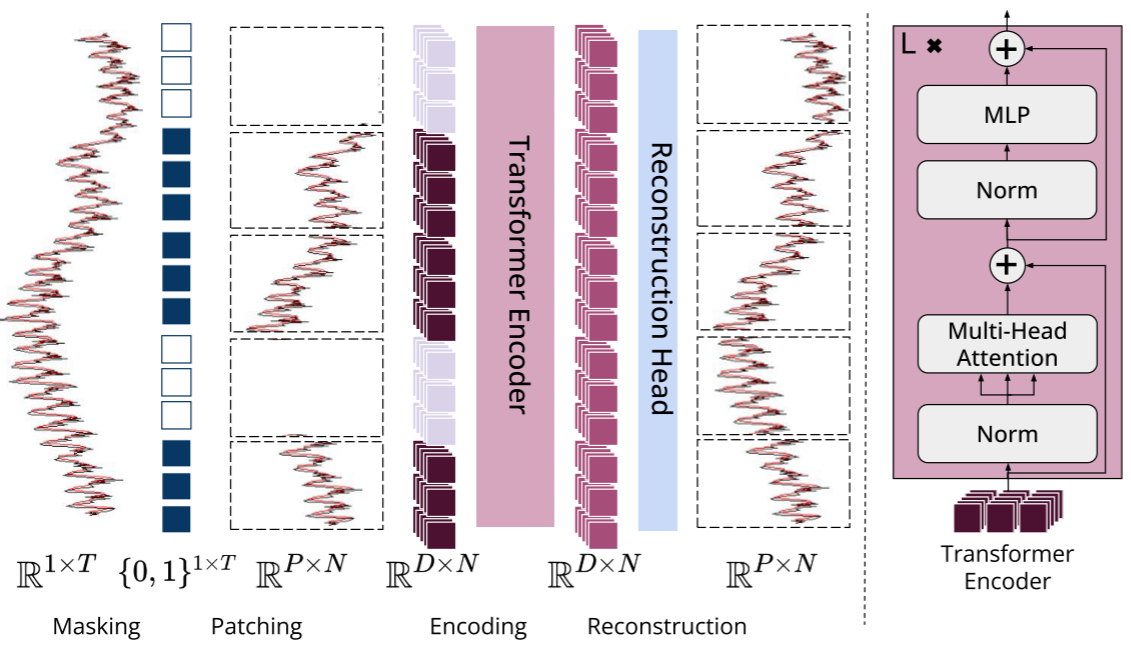
Figure 3(MOMENT 架构总览图)
MOMENT 的整体设计遵循"有意简洁"原则,核心思路是把时序问题尽量对齐到语言模型已经验证可行的范式上。
(1)Patching:把时序切成"词"
受 PatchTST 启发,MOMENT 将输入时序切分为长度 P = 8 的不重叠子序列(patch),每个 patch 作为一个 token 输入 Transformer。
这一操作带来两大好处:
- 计算复杂度从 O(T²) 降为 O((T/P)²),内存占用二次方级减少
- 输入序列的有效覆盖长度线性增加
(2)Masked Time Series Modeling:预训练任务
预训练采用掩码重建任务:随机遮蔽 30% 的 patch ,用可学习的 [MASK] embedding 替代(而非用零填充,论文专门验证零填充会引入信息偏差),让模型学习从上下文重建被遮蔽的时序片段,训练目标为被遮蔽区域的 MSE。
这一设计天然契合预测(预测未来 = 重建被遮蔽的未来段)和缺失值填补两类下游任务。
(3)其他关键设计
- Reversible Instance Normalization(RevIN):对每条输入时序做可逆的均值/方差归一化,再在输出侧还原,使模型能处理幅值差异悬殊的时序
- Channel Independence:多变量时序沿通道维度独立处理(每个通道单独过 Transformer),与 PatchTST 的结论一致,简单有效
- 绝对 + 相对位置编码:同时使用正弦绝对位置编码和相对位置编码,实验发现两者结合比单独使用更好(论文坦承这一组合最初是"意外引入"后发现有效的)
(4)三种规模
| 规模 | 层数 | 隐层维度 | 注意力头 | 参数量 |
|---|---|---|---|---|
| Small | 6 | 512 | 8 | ~40M |
| Base | 12 | 768 | 12 | ~125M |
| Large | 24 | 1024 | 16 | ~385M |
所有权重均从随机初始化开始预训练,在 1 台 NVIDIA RTX A6000 GPU(49 GB 显存)上训练 2 个 epoch,使用 AdamW 优化器 + Cosine 学习率调度。
3.3 针对下游任务的微调策略
MOMENT 提供三种使用姿态,无缝适配不同资源条件:
- MOMENT⁰(Zero-shot):保留预训练重建头,直接推理,适用于异常检测、缺失值填补
- MOMENT_LP(Linear Probing):冻结 Encoder 全部权重,只训练任务头,适用于预测、缺失值填补
- 端到端微调:解冻全部权重,适用于数据充足场景
四、评测基准设计
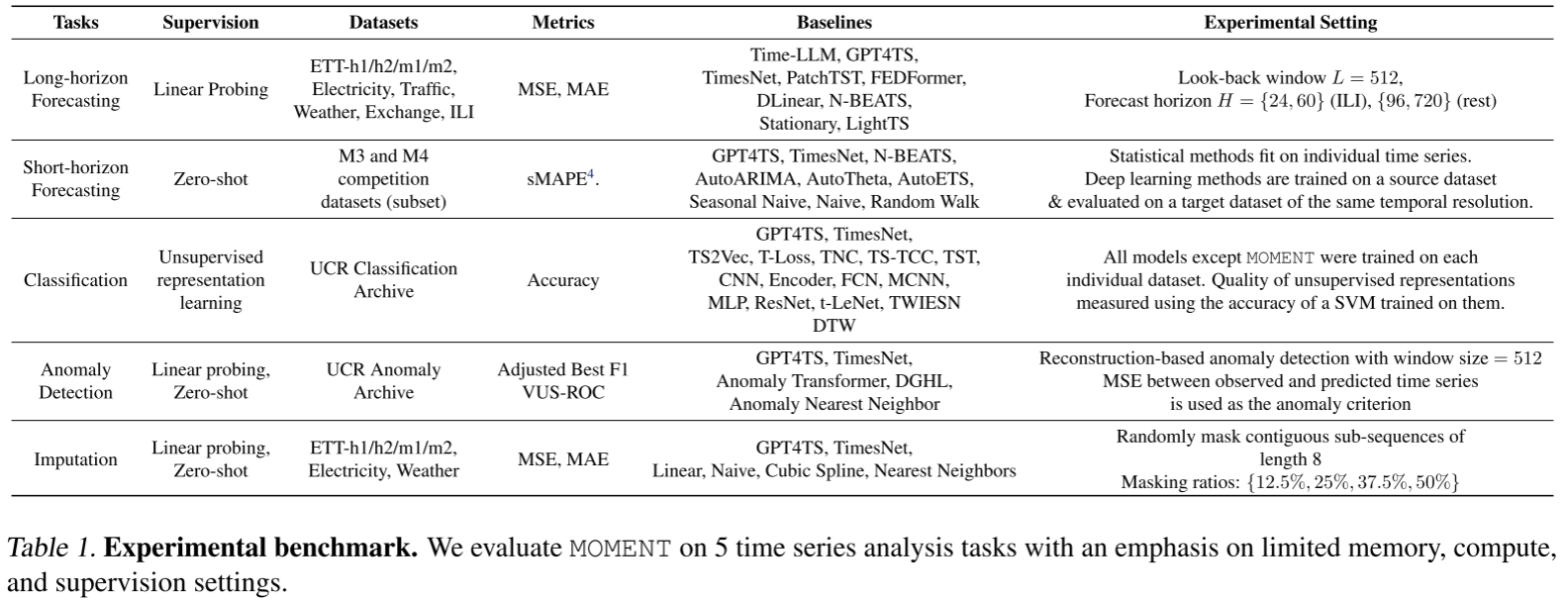
Table 1(实验基准总览,含 5 大任务的监督方式、数据集、评估指标、基线方法)
论文在 Wu et al.(2023)的 TimesNet 基准之上,从以下维度做了系统性扩展:
- 有限监督优先:所有实验都限定在 zero-shot 或 linear probing 场景,不允许全量微调,模拟真实世界中"标注数据稀缺"的情形
- 更多基线类型:不仅比较 Transformer 类方法,还纳入 ARIMA、N-BEATS、k-NN 等统计/浅层机器学习方法------这在以往深度学习论文中很少见
- 更严格的评估指标 :异常检测采用 Adjusted Best F1 和 VUS-ROC,而非许多论文使用的(被批评会高估性能的)vanilla F1
- 更大的数据集范围:分类实验在 91 个 UCR 数据集上进行,异常检测在 248 条 UCR 异常档案时序上进行
五、实验结果
5.1 长期预测:接近 SOTA,以极低的可训练参数量
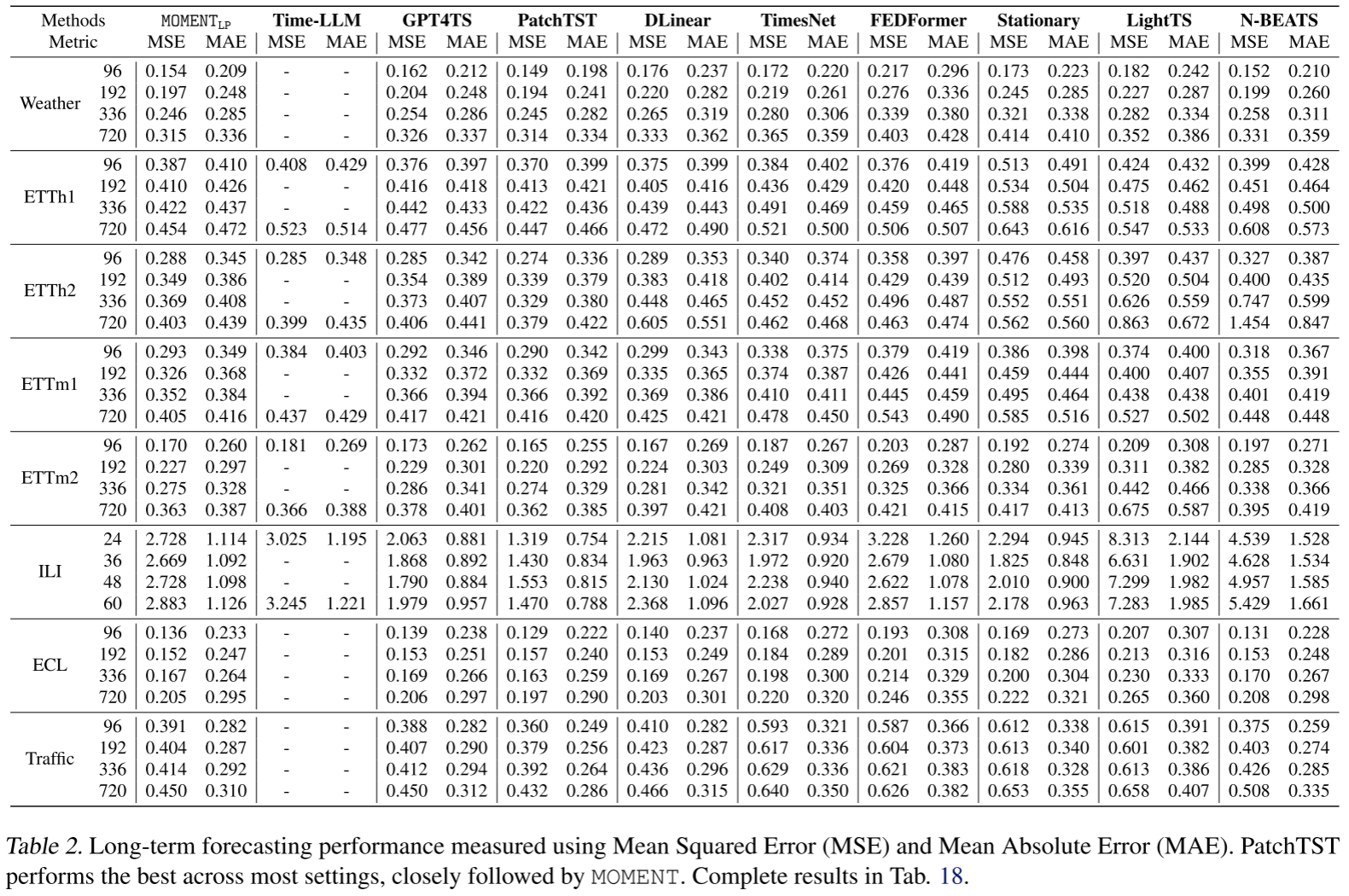
Table 2(长期预测 MSE/MAE 完整结果)
在 9 个数据集、4 个预测视野(96/192/336/720 步,ILI 用 24/36/48/60 步)的长期预测上,MOMENT_LP 的整体排名仅次于 PatchTST,且优于所有 LLM 改造方法(Time-LLM、GPT4TS)。
值得关注的是效率对比:
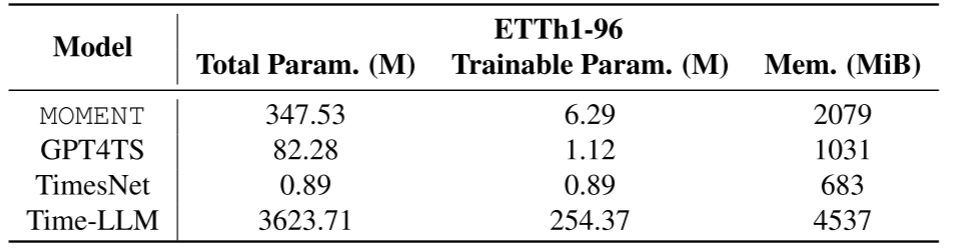
Table 33(效率对比,含总参数量、可训练参数量、显存占用)
在 ETTh1-96 任务上,MOMENT 的可训练参数仅 6.29M(整个模型冻结后只需训练线性头),显存 2079 MiB,远低于 Time-LLM(可训练参数 254M,显存 4537 MiB),却取得了更好的预测精度。
5.2 短期预测(Zero-shot):统计方法仍占优,但出现可喜苗头

Table 3(零样本短期预测 sMAPE 结果)
在 M3 和 M4 数据集的零样本短期预测上,统计方法(Theta、ETS)整体仍优于所有深度学习方法。这是论文承认的改进空间最大的任务。
不过,在部分子集(如 M3 Monthly、M4 Monthly)上,MOMENT、GPT4TS 和 N-BEATS 的 sMAPE 低于 ARIMA,说明大规模预训练确实为时序模型注入了一定的零样本泛化能力。
5.3 分类(无监督表示学习):超越绝大多数专用模型

Table 4(分类准确率汇总,91 个 UCR 数据集)
这是 MOMENT 表现最令人印象深刻的任务之一。在 91 个 UCR 数据集的无监督表示学习实验中:
- MOMENT⁰(完全不在目标数据集上做任何训练 )的均值准确率达 0.794 ,均值排名 7.2
- 作为对比,GPT4TS 和 TimesNet 尽管在每个数据集上单独训练,均值准确率分别只有 0.566 和 0.572,排名均为 13.3
- MOMENT 仅次于 TS2Vec(0.851,排名 3.5)等专为时序表示学习设计的方法
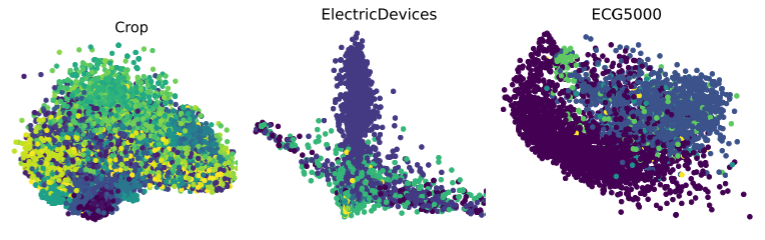
Figure 5(Crop / ElectricDevices / ECG5000 数据集的 PCA & t-SNE 可视化)
从 PCA 和 t-SNE 可视化可以清楚看到:即使没有任何针对性微调,MOMENT 学到的表示在不同类别之间已经形成了清晰的聚类结构。
5.4 异常检测:全面超越专用深度学习方法
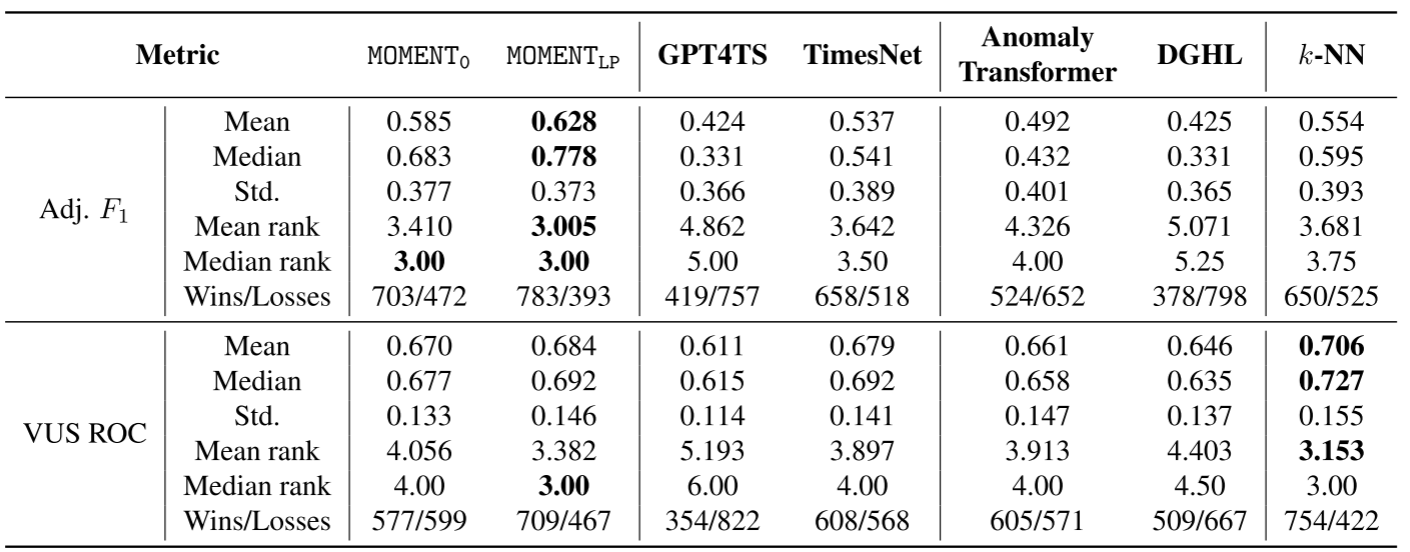
Table 7(异常检测性能汇总,248 条时序)
在 248 条来自 UCR 异常档案的时序上,MOMENT_LP 在 Adjusted Best F1 指标上表现最佳(均值 0.628),优于 Anomaly Transformer(0.492)、DGHL(0.425)以及 TimesNet(0.537)和 GPT4TS(0.424)。
在 VUS-ROC 指标上,k-NN 略优(0.706 vs. 0.684),但 MOMENT_LP 排名第二,且是所有深度学习方法中最好的。
5.5 缺失值填补:Linear Probing 在 ETT 数据集全面领先

Table 6(缺失值填补结果,6 个数据集均值)
MOMENT_LP 在所有 4 个 ETT 数据集上取得最低重建 MSE,在 zero-shot 场景下也超越了除线性插值外的所有统计插值方法(如 Cubic Spline、最近邻插值)。
六、MOMENT 学到了什么?
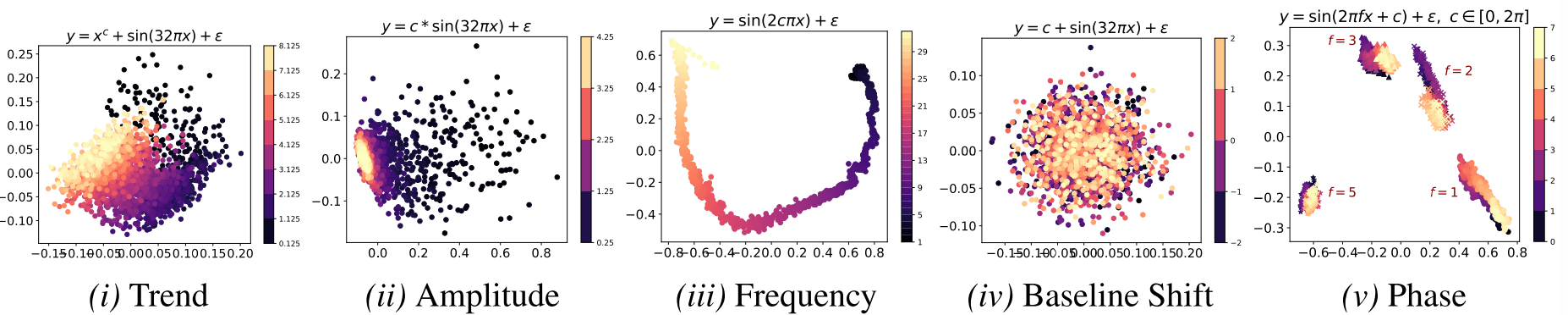
Figure 4(趋势/幅值/频率/基线偏移/相位的 PCA 可视化)
论文通过合成正弦波实验,系统地探究了 MOMENT 的表示空间中究竟编码了哪些时序特征。结论如下:
✅ 能感知的特征:趋势(polynomial trend)、幅值(amplitude)、频率(frequency)、相位(phase)------在 PCA / t-SNE 可视化中,不同参数值的嵌入形成连续且有规律的流形结构
❌ 无法区分的特征 :垂直平移(baseline shift) ------由于 MOMENT 在建模前对时序做了实例归一化(减均值),垂直偏移信息在预处理阶段就被消除了,这是一个已知局限性
七、大模型的三个"宏观规律"
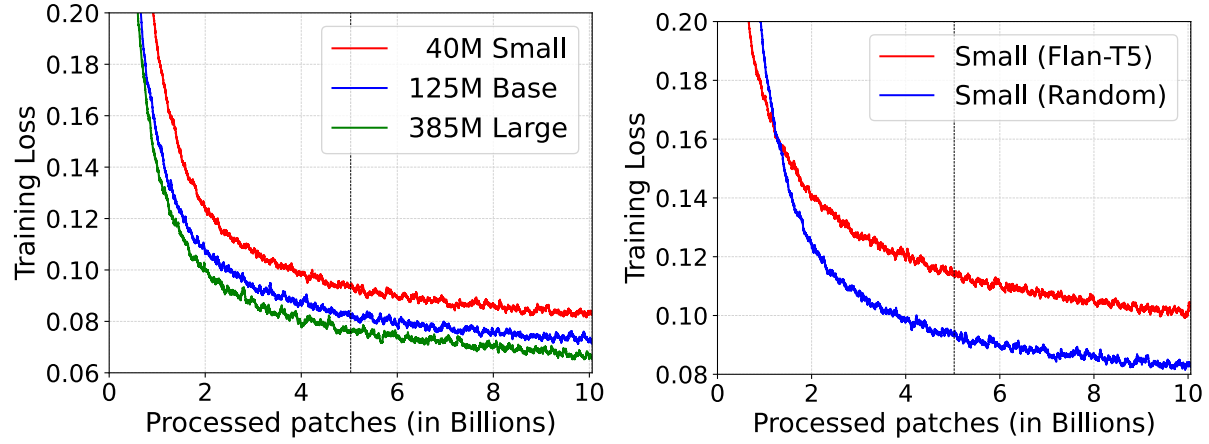
Figure 6(训练损失曲线:左图模型规模对比,右图随机初始化 vs. Flan-T5 初始化)
规律 1:模型越大,训练损失越低
Small(40M)、Base(125M)、Large(385M)三个规模的训练曲线清晰显示:模型规模越大,训练损失越低,且在第一个 epoch 开始之前这一差距就已形成。这与 LLM 领域的 scaling law 规律一致。
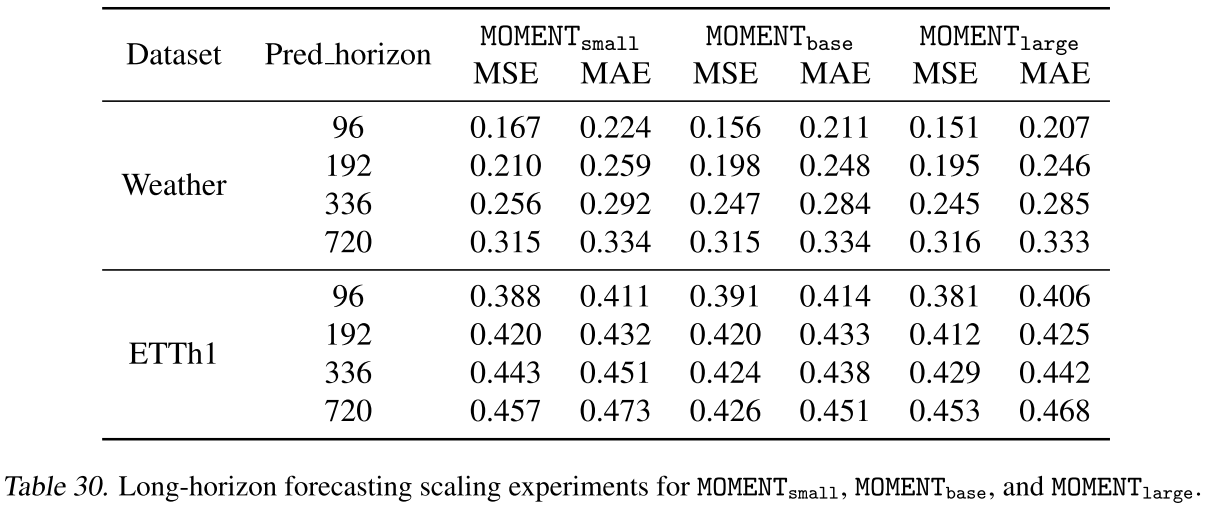
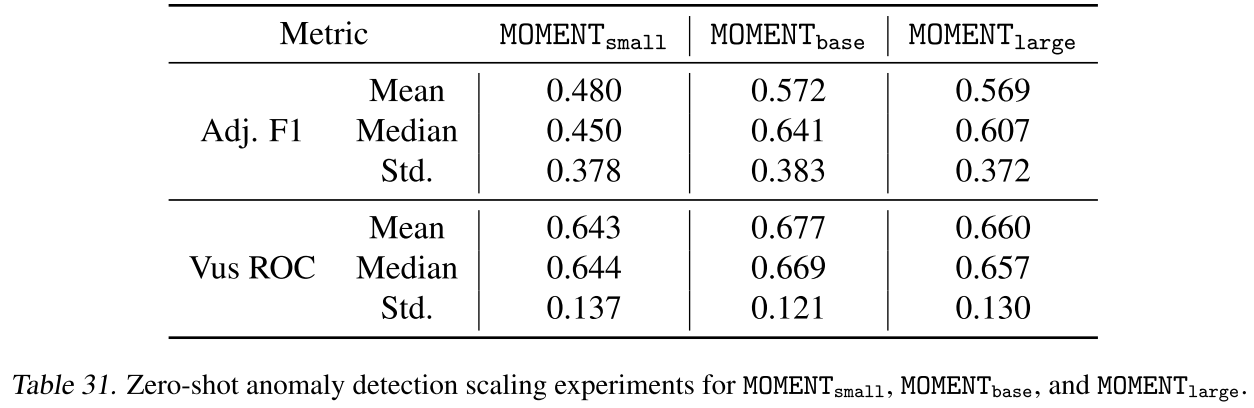
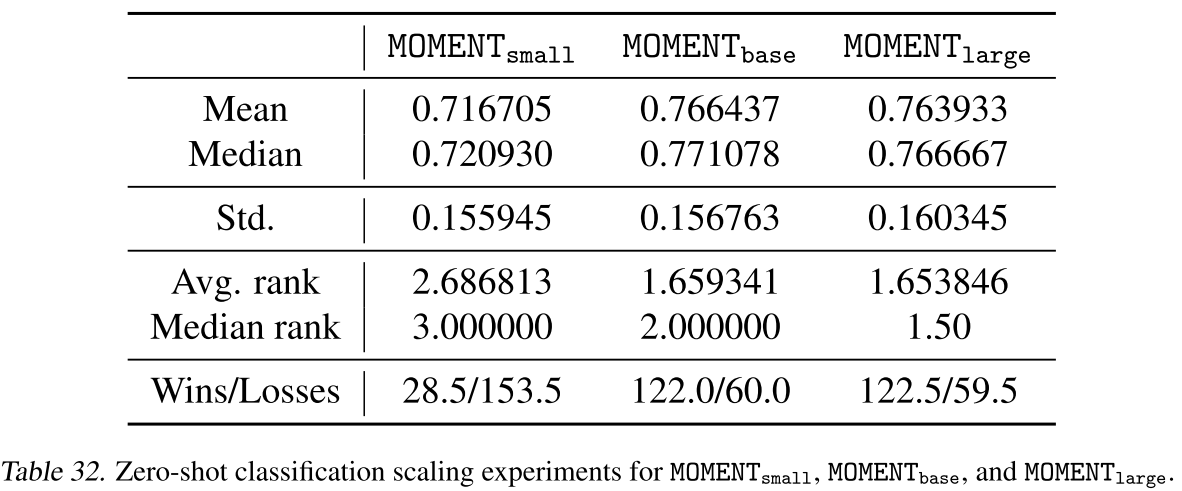
Table 30 & 31 & 32(不同规模在预测/异常检测/分类任务上的对比结果)
规律 2:时序数据量已足够,随机初始化优于语言模型初始化
论文对比了用 Flan-T5 权重初始化 vs. 随机初始化的 MOMENT-Small。结果显示,随机初始化最终收敛到更低的训练损失。
这说明:Time Series Pile 中已有足够多的时序数据,不需要借助语言模型的预训练知识作为"起点"------时序与文本之间的模态差异足够大,语言模型权重反而可能是一种干扰。
规律 3:时序预训练的 Transformer 同样能做跨模态迁移
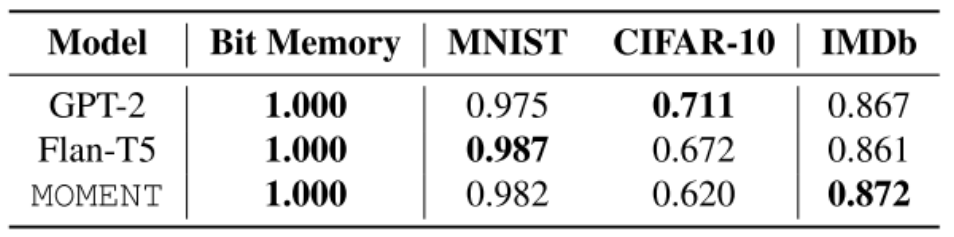
Table 5(跨模态迁移实验:MNIST / CIFAR-10 / IMDb)
冻结 MOMENT 的 self-attention 和 FFN 层后,只微调嵌入层和线性头,MOMENT 在图像分类(MNIST:0.982)、文本分类(IMDb:0.872)上的表现与相近规模的 GPT-2 和 Flan-T5 旗鼓相当。这表明:在时序上学到的 Transformer 权重同样具有跨模态通用序列建模能力,不只是语言或视觉的专属属性。
八、与同期工作的对比
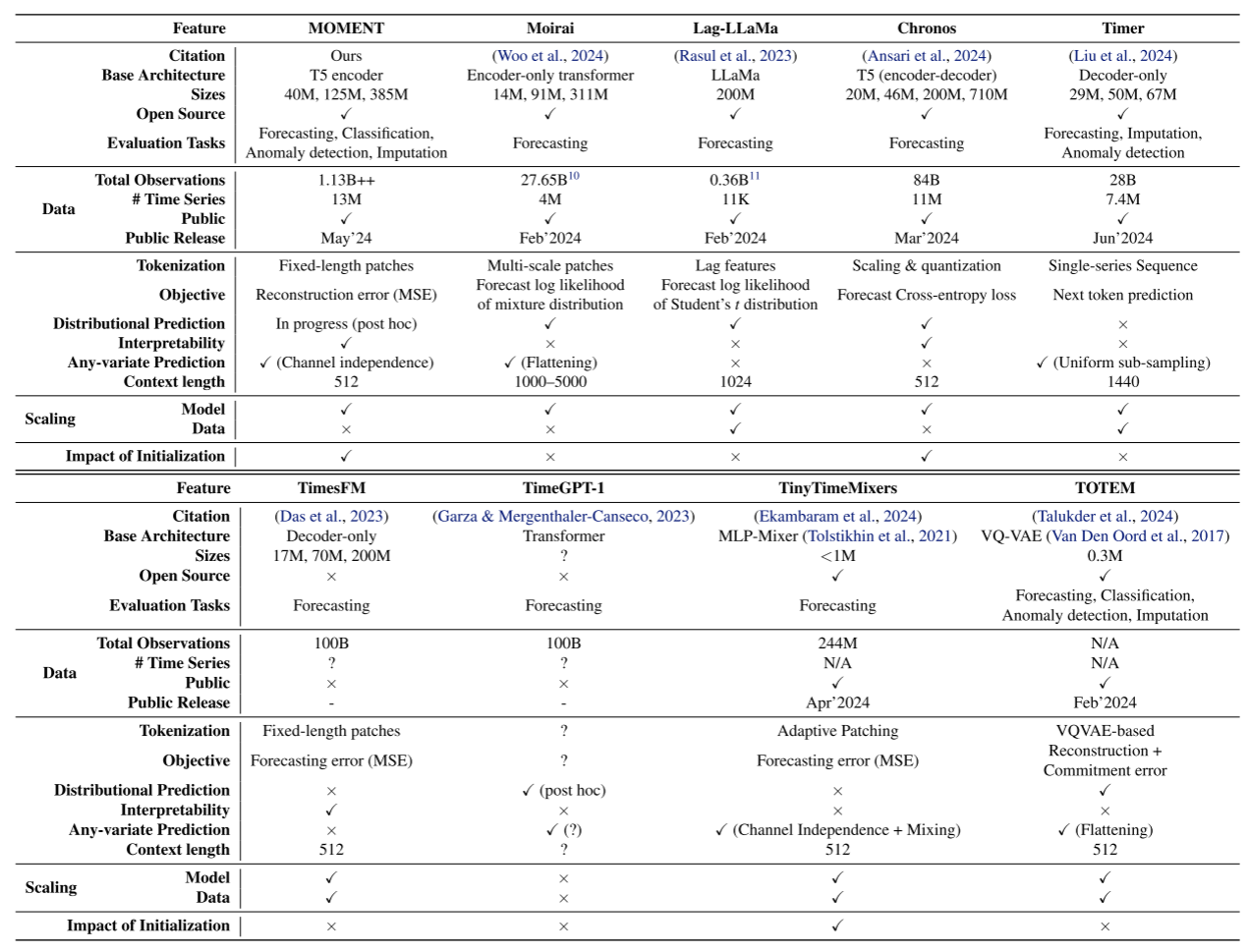
Table 9(同期时序基础模型对比:Moirai / Lag-LLaMa / Chronos / Timer 等)
2024 年前后出现了一批时序基础模型,MOMENT 与它们的主要差异在于:
- 任务覆盖最广:Moirai、Lag-LLaMa、Chronos、TimesFM 等基本只做预测,而 MOMENT 同时支持预测、分类、异常检测、缺失值填补
- 唯一公开研究了 cross-modal 迁移、环境影响和透明度评分的时序基础模型
- 数据规模相对适中:Chronos 使用 84B 观测量,MOMENT 的 Time Series Pile 约 1.13B++,但胜在数据多样性和任务覆盖广度
- 开源、开权重、开代码,具备高度透明性
九、局限性与未来方向
论文对自身局限性相当坦诚:
- 零样本短期预测仍弱于统计方法:Theta、ETS 在 M3/M4 数据集上仍是强劲对手
- 无法区分垂直平移:RevIN 的归一化操作消除了均值信息
- 分布预测能力尚未完善:仅输出点预测,distributional prediction 标注为"in progress"
- 高风险场景需谨慎:MOMENT 的预测可靠性依赖训练数据质量,在医疗等高风险场景使用前须用领域数据充分微调
论文提出的未来方向包括:多模态时序+文本联合建模、使用因果注意力 + 自回归目标进一步提升预测性能、数据增强与合成数据策略,以及探索更优的数据集混合配比。
十、总结
MOMENT 的贡献是多层次的:它不只是一个新模型,更是一套完整的基础设施------大规模时序语料库(Time Series Pile)+ 可扩展预训练架构 + 公平的有限监督评测基准。
对于时序分析领域而言,MOMENT 的意义在于:证明了"在足够多样的时序数据上预训练足够大的 Transformer"这条路是可行的,预训练带来的零样本/少样本泛化能力在分类、异常检测、填补等任务上尤为突出,为后续研究打开了新的空间。