Attention Residuals:把固定残差换成"跨层注意力"
这篇博客讲解论文 Attention Residuals,重点回答四个问题:
- 它在解决什么问题
- 它提出了什么核心设想
- 数学公式是什么样
- 如何用 PyTorch 手写一个教学版 demo,并用随机张量跑一遍流程
1. 论文想解决什么问题
在现代 Transformer / LLM 中,PreNorm 残差连接是标准做法。
最经典的写法是:
h l = h l − 1 + f l − 1 ( h l − 1 ) h_l = h_{l-1} + f_{l-1}(h_{l-1}) hl=hl−1+fl−1(hl−1)
这里:
- h l − 1 h_{l-1} hl−1 是上一层输入
- f l − 1 ( h l − 1 ) f_{l-1}(h_{l-1}) fl−1(hl−1) 是当前子层输出
- 最终通过固定加法把二者合并
问题在于,这种残差聚合方式是 固定的、内容无关的。
也就是说:
- 所有历史层输出都会被不断往后传
- 每一层的贡献默认是"直接相加"
- 没有"选择性读取历史层"的机制
论文指出,这会带来两个核心问题:
- hidden state 的尺度会随着层数加深而不断累积
- 各层贡献会被逐渐稀释,深层网络中的信息流不够灵活
于是作者提出一个问题:
既然 token 维度上已经有 self-attention,为什么深度维度上的信息流仍然只是固定残差相加?
2. 论文的核心设想
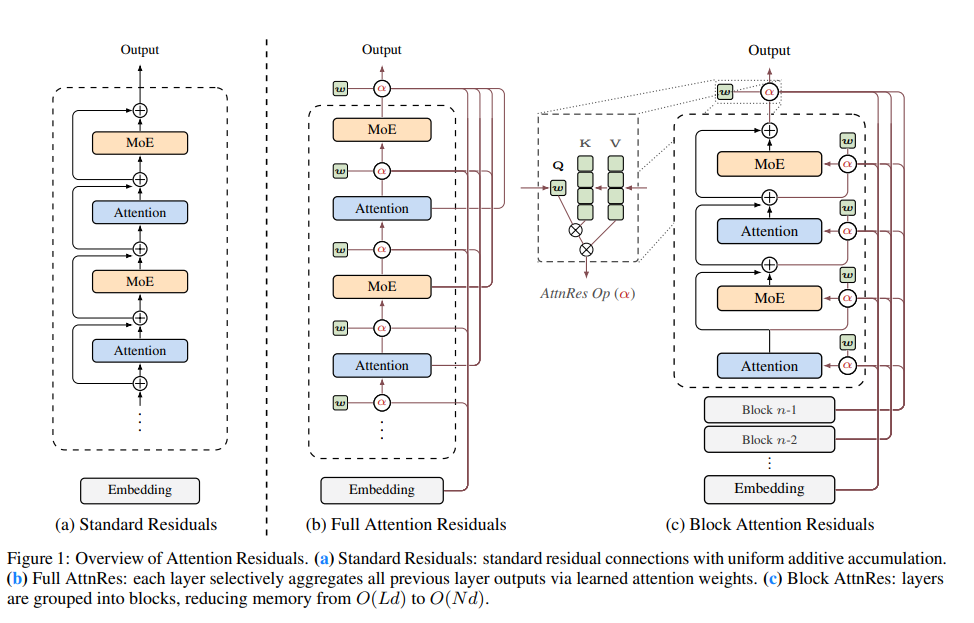
论文提出:
把标准残差里的固定加法,替换成对"历史层表示"的 attention 聚合。
也就是说,当前层不再只是拿:
h l − 1 + f l − 1 ( h l − 1 ) h_{l-1} + f_{l-1}(h_{l-1}) hl−1+fl−1(hl−1)
而是去看更长的历史:
x , v 0 , v 1 , ... , v l − 1 x, v_0, v_1, \dots, v_{l-1} x,v0,v1,...,vl−1
然后通过一组 attention 权重,动态决定:
- 当前层更应该依赖原始输入
- 还是更应该依赖较浅层输出
- 或者更应该依赖最近几层
这种方法就叫做 Attention Residuals(AttnRes)。
3. 标准残差 vs Attention Residuals
3.1 标准残差
标准 PreNorm 残差:
h l = h l − 1 + f l − 1 ( h l − 1 ) h_l = h_{l-1} + f_{l-1}(h_{l-1}) hl=hl−1+fl−1(hl−1)
如果不断展开,会发现它等价于一种"固定历史累加"。
可以把它直观理解为:
h l ≈ ∑ i = 0 l − 1 v i h_l \approx \sum_{i=0}^{l-1} v_i hl≈i=0∑l−1vi
其中:
- v 0 v_0 v0 可以看作原始输入
- v i v_i vi 表示第 i i i 层产生的增量信息
关键问题是:
这些历史项的权重本质上是固定的,不会根据内容动态调整。
3.2 Attention Residuals
论文把固定求和替换成注意力加权和:
h l = ∑ i = 0 l − 1 α i → l v i h_l = \sum_{i=0}^{l-1} \alpha_{i \to l} \, v_i hl=i=0∑l−1αi→lvi
其中:
∑ i = 0 l − 1 α i → l = 1 \sum_{i=0}^{l-1} \alpha_{i \to l} = 1 i=0∑l−1αi→l=1
这里:
- v i v_i vi 是历史层表示
- α i → l \alpha_{i \to l} αi→l 是当前层对第 i i i 个历史项的注意力权重
于是,当前层会对不同历史层进行"选择性读取"。
4. 核心数学公式
论文定义注意力权重为:
α i → l = ϕ ( q l , k i ) ∑ j = 0 l − 1 ϕ ( q l , k j ) \alpha_{i \to l} = \frac{\phi(q_l, k_i)} {\sum_{j=0}^{l-1}\phi(q_l, k_j)} αi→l=∑j=0l−1ϕ(ql,kj)ϕ(ql,ki)
其中,打分函数定义为:
ϕ ( q , k ) = exp ( q ⊤ R M S N o r m ( k ) ) \phi(q, k) = \exp \left(q^\top \mathrm{RMSNorm}(k)\right) ϕ(q,k)=exp(q⊤RMSNorm(k))
所以整体上就是一个 softmax attention。
4.1 Query
论文把当前层的 query 定义成一个可学习向量:
q l = w l q_l = w_l ql=wl
其中:
w l ∈ R d w_l \in \mathbb{R}^{d} wl∈Rd
也就是说,每层只有一个学习出来的伪 query。
4.2 Key / Value
论文里,历史 key / value 来自前面层的表示:
k i = v i k_i = v_i ki=vi
教学理解中可以直接认为:
- 原始输入作为第一个历史项
- 每一层的输出作为后续历史项
于是最终聚合公式是:
h l = ∑ i = 0 l − 1 α i → l v i h_l = \sum_{i=0}^{l-1} \alpha_{i \to l} \, v_i hl=i=0∑l−1αi→lvi
然后再通过当前层前馈网络得到:
v l = f l ( h l ) v_l = f_l(h_l) vl=fl(hl)
5. 这篇论文的直觉
这篇论文真正新颖的地方,不是再发明一种 token attention,
而是把"深度方向的信息流"也 attention 化。
你可以这样理解:
- 标准残差:所有历史层都一视同仁地加进来
- Attention Residuals:当前层像在"查询历史层记忆库",按相关性选择要读什么
所以它本质上是在回答:
当前层到底应该从哪些更早层取信息?
6. 为什么实现里需要 for 循环
很多人第一眼会问:
历史层不是都能
torch.stack起来吗,为什么还要for?
答案是:
torch.stack可以把已经存在的历史层表示拼起来- 但第 l l l 层输出 v l v_l vl 本身依赖前面各层结果
- 所以后层结果没有算出来之前,根本无法提前 stack
也就是说:
- 层内历史聚合 可以张量化
- 层与层之间递推生成历史 仍然必须有
for
这和 RNN 沿时间递推很像,只不过这里递推的维度是"网络深度"。
7. 纯手写 PyTorch 代码(逐行注释 + 维度注释)
python
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
"""
最小教学版 RMSNorm。
输入张量形状: [..., d_model]
输出张量形状: [..., d_model]
"""
def __init__(self, d_model: int, eps: float = 1e-8):
super().__init__() # 初始化父类 nn.Module
self.eps = eps # 数值稳定项,标量
self.weight = nn.Parameter(torch.ones(d_model)) # 可学习缩放参数,形状 [d_model]
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
x: [..., d_model]
return: [..., d_model]
"""
# 计算最后一维上的均方值,输出形状 [..., 1]
rms = torch.sqrt(torch.mean(x * x, dim=-1, keepdim=True) + self.eps)
# 归一化后仍然是 [..., d_model]
x_norm = x / rms
# 乘以可学习参数,广播后输出仍然是 [..., d_model]
return x_norm * self.weight
class FeedForwardBlock(nn.Module):
"""
一个简单的前馈网络,模拟论文里的 f_l(\cdot)。
输入: [B, T, d_model]
输出: [B, T, d_model]
"""
def __init__(self, d_model: int, d_hidden: int):
super().__init__() # 初始化父类
# 第一层线性映射: [B, T, d_model] -> [B, T, d_hidden]
self.fc1 = nn.Linear(d_model, d_hidden)
# GELU 激活: [B, T, d_hidden] -> [B, T, d_hidden]
self.act = nn.GELU()
# 第二层线性映射: [B, T, d_hidden] -> [B, T, d_model]
self.fc2 = nn.Linear(d_hidden, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
x: [B, T, d_model]
return: [B, T, d_model]
"""
# 线性映射到隐藏层,输出形状 [B, T, d_hidden]
x = self.fc1(x)
# GELU 激活,输出形状 [B, T, d_hidden]
x = self.act(x)
# 映射回模型维度,输出形状 [B, T, d_model]
x = self.fc2(x)
# 返回当前层的"增量表示"或"层输出" [B, T, d_model]
return x
class FullAttentionResidualLayer(nn.Module):
"""
单层 Full Attention Residual。
"""
def __init__(self, d_model: int, d_hidden: int):
super().__init__() # 初始化父类
# 当前层的可学习伪 query 向量 w_l,形状 [d_model]
self.query = nn.Parameter(torch.randn(d_model))
# 对历史 key 做 RMSNorm,输入输出都是 [..., d_model]
self.rmsnorm = RMSNorm(d_model)
# 当前层的前馈网络 f_l,输入输出都是 [B, T, d_model]
self.ffn = FeedForwardBlock(d_model, d_hidden)
def forward(self, history_values: list[torch.Tensor]):
"""
history_values: 长度为 l 的列表
每个元素形状都是 [B, T, d_model]
返回:
h_l: 当前层 attention residual 聚合后的输入,形状 [B, T, d_model]
v_l: 当前层 FFN 输出,形状 [B, T, d_model]
alpha: 深度方向注意力权重,形状 [num_history]
"""
# history_values[0] 的形状是 [B, T, d_model]
B, T, D = history_values[0].shape # 读取 batch、seq_len、hidden_dim
# 把历史 values 在新维度上堆叠起来
# 输入是 l 个 [B, T, d_model]
# 输出 stacked_values 形状 [l, B, T, d_model]
stacked_values = torch.stack(history_values, dim=0)
# 对历史 values 做 RMSNorm,形状仍是 [l, B, T, d_model]
normed_keys = self.rmsnorm(stacked_values)
# 当前层 query 原本形状 [d_model]
# 为了和历史 keys 做点积,扩成 [1, 1, 1, d_model]
q = self.query.view(1, 1, 1, D)
# 计算 depth 方向的打分 logits
# normed_keys: [l, B, T, d_model]
# q: [1, 1, 1, d_model]
# 输出 logits 形状 [l, B, T]
logits = torch.sum(normed_keys * q, dim=-1)
# 在 depth 维度 dim=0 上做 softmax
# alpha_full 形状 [l, B, T]
alpha_full = torch.softmax(logits, dim=0)
# 对 batch 和 token 做平均,只留下深度维上的平均权重
# alpha_mean 形状 [l]
alpha_mean = alpha_full.mean(dim=(1, 2))
# 扩维后做加权
# alpha_full.unsqueeze(-1): [l, B, T, 1]
# stacked_values: [l, B, T, d_model]
weighted_values = alpha_full.unsqueeze(-1) * stacked_values
# 沿 depth 维度求和,得到当前层输入 h_l
# h_l 形状 [B, T, d_model]
h_l = torch.sum(weighted_values, dim=0)
# 通过当前层 FFN,得到当前层输出 v_l
# v_l 形状 [B, T, d_model]
v_l = self.ffn(h_l)
# 返回结果
return h_l, v_l, alpha_mean
class FullAttentionResidualNetwork(nn.Module):
"""
一个完整的教学版 Full Attention Residual 网络。
"""
def __init__(self, num_layers: int, d_model: int, d_hidden: int):
super().__init__() # 初始化父类
# 保存层数
self.num_layers = num_layers
# 保存模型维度
self.d_model = d_model
# 多层 Attention Residual Layer
self.layers = nn.ModuleList(
[FullAttentionResidualLayer(d_model, d_hidden) for _ in range(num_layers)]
)
def forward(self, x: torch.Tensor):
"""
x: [B, T, d_model]
返回:
final_h: 最后一层聚合后的输入 [B, T, d_model]
final_v: 最后一层 FFN 输出 [B, T, d_model]
all_alpha: 每层的平均深度注意力权重
"""
# 初始输入 x 作为第一项历史表示
history_values = [x]
# 保存每层注意力权重
all_alpha = []
# 最终结果占位
final_h = None
final_v = None
# 逐层递推
for layer_idx, layer in enumerate(self.layers):
# 当前层读取全部历史表示
h_l, v_l, alpha_mean = layer(history_values)
# 保存当前层的平均深度注意力权重
all_alpha.append(alpha_mean)
# 当前层输出加入历史
history_values.append(v_l)
# 更新最终输出
final_h = h_l
final_v = v_l
# 打印中间结果
print(f"\\n================ Layer {layer_idx} ================")
print(f"history length before appending current v_l = {len(history_values) - 1}")
print(f"h_{layer_idx}.shape = {tuple(h_l.shape)}")
print(f"v_{layer_idx}.shape = {tuple(v_l.shape)}")
print(f"alpha_mean.shape = {tuple(alpha_mean.shape)}")
print(f"alpha_mean = {alpha_mean.detach()}")
# 返回最后一层结果
return final_h, final_v, all_alpha
def demo():
"""
随机张量跑一遍教学版 Attention Residuals。
"""
# 固定随机种子
torch.manual_seed(42)
# batch size
B = 2
# sequence length
T = 4
# hidden size
D = 8
# FFN hidden size
d_hidden = 16
# 网络层数
num_layers = 3
# 构造随机输入
# x 形状 [B, T, D] = [2, 4, 8]
x = torch.randn(B, T, D)
# 打印输入
print("================ Input ================")
print(f"x.shape = {tuple(x.shape)}")
print(f"x =\\n{x}")
# 实例化模型
model = FullAttentionResidualNetwork(
num_layers=num_layers,
d_model=D,
d_hidden=d_hidden
)
# 前向传播
final_h, final_v, all_alpha = model(x)
# 打印最终结果
print("\\n================ Final Output ================")
print(f"final_h.shape = {tuple(final_h.shape)}")
print(f"final_v.shape = {tuple(final_v.shape)}")
print(f"final_h =\\n{final_h}")
print(f"final_v =\\n{final_v}")
# 打印各层深度注意力权重
print("\\n================ All Layer Attention Weights ================")
for i, alpha in enumerate(all_alpha):
print(f"Layer {i} alpha shape = {tuple(alpha.shape)}")
print(f"Layer {i} alpha = {alpha.detach()}")
if __name__ == "__main__":
demo()8. demo 输出该怎么理解
这次配置是:
python
B = 2
T = 4
D = 8
d_hidden = 16
num_layers = 3随机种子固定为:
python
torch.manual_seed(42)1)输入张量 x
python
x.shape = (2, 4, 8)
x =
tensor([[[ 1.9269, 1.4873, 0.9007, -2.1055, 0.6784, -1.2345, -0.0431,
-1.6047],
[-0.7521, 1.6487, -0.3925, -1.4036, -0.7279, -0.5594, -0.7688,
0.7624],
[ 1.6423, -0.1596, -0.4974, 0.4396, -0.7581, 1.0783, 0.8008,
1.6806],
[ 1.2791, 1.2964, 0.6105, 1.3347, -0.2316, 0.0418, -0.2516,
0.8599]],
[[-1.3847, -0.8712, -0.2234, 1.7174, 0.3189, -0.4245, 0.3057,
-0.7746],
[-1.5576, 0.9956, -0.8798, -0.6011, -1.2742, 2.1228, -1.2347,
-0.4879],
[-0.9138, -0.6581, 0.0780, 0.5258, -0.4880, 1.1914, -0.8140,
-0.7360],
[-1.4032, 0.0360, -0.0635, 0.6756, -0.0978, 1.8446, -1.1845,
1.3835]]])2)Layer 0
这一层历史里只有 x,所以深度注意力权重只能是 1。
python
history length before appending current v_l = 1
h_0.shape = (2, 4, 8)
v_0.shape = (2, 4, 8)
alpha_mean.shape = (1,)
alpha_mean = tensor([1.])
v_0 为:
tensor([[[ 0.2741, -0.2352, -0.2489, 0.0094, -0.2525, 0.4293, -0.2075,
0.2216],
[ 0.2692, 0.0189, -0.4173, 0.0271, 0.0868, 0.2390, 0.0784,
0.4914],
[ 0.2096, -0.0219, -0.1126, 0.1011, 0.1793, 0.1994, 0.2117,
0.4257],
[ 0.0422, 0.0354, -0.2447, -0.0129, 0.1916, 0.1683, -0.0965,
0.3999]],
[[ 0.3338, 0.0980, -0.5013, -0.1016, -0.1173, -0.1388, -0.7407,
-0.0586],
[ 0.3510, -0.0333, -0.5273, 0.3814, 0.1975, 0.2993, -0.1860,
0.3246],
[ 0.2236, 0.0072, -0.4600, 0.2855, 0.1582, 0.2072, -0.3656,
0.2289],
[ 0.3130, 0.1445, -0.4403, 0.2125, 0.2654, 0.1389, -0.0781,
0.4350]]])3)Layer 1
这一层历史里有两项:
原始输入 x
上一层输出 v_0
python
history length before appending current v_l = 2
h_1.shape = (2, 4, 8)
v_1.shape = (2, 4, 8)
alpha_mean.shape = (2,)
alpha_mean = tensor([0.6249, 0.3751])这里的平均深度权重大概表示:
- 62.49% 依赖更早的历史项
- 37.51% 依赖上一层输出
v_1 为:
python
tensor([[[ 0.0716, -0.2335, 0.0812, -0.1091, 0.3522, -0.0764, -0.2171,
0.1945],
[-0.0509, -0.0230, 0.1270, -0.2430, 0.3987, -0.2186, -0.1951,
0.2251],
[-0.0576, -0.0582, 0.0089, 0.0792, 0.2586, -0.0725, -0.1659,
0.1221],
[-0.0538, -0.0940, 0.1491, -0.0818, 0.2712, -0.0109, -0.0526,
0.2495]],
[[-0.0247, -0.0031, 0.1508, -0.0758, 0.2737, 0.0061, -0.0530,
0.1869],
[-0.0307, -0.0789, 0.4091, -0.2161, 0.3591, -0.0159, -0.0540,
0.2814],
[-0.0995, -0.1159, 0.2357, -0.0457, 0.2620, 0.0321, 0.1224,
0.2447],
[-0.1434, 0.0301, 0.3736, -0.0892, 0.1791, 0.0893, 0.1036,
0.2760]]])4)Layer 2
这一层历史里有三项:
- x
- v_0
- v_1
python
history length before appending current v_l = 3
h_2.shape = (2, 4, 8)
v_2.shape = (2, 4, 8)
alpha_mean.shape = (3,)
alpha_mean = tensor([0.6445, 0.2387, 0.1168])这个结果很有意思,说明在这次随机初始化下,第 2 层对最早历史项的平均依赖最大。
5)最终输出
python
final_h
final_h.shape = (2, 4, 8)
final_h =
tensor([[[ 0.3630, -0.1397, -0.1807, -0.1094, -0.1927, 0.3303, -0.1985,
0.1200],
[-0.6759, 1.5244, -0.3918, -1.2959, -0.6644, -0.5008, -0.7056,
0.7405],
[ 1.4239, -0.1390, -0.4384, 0.3883, -0.6158, 0.9437, 0.7093,
1.4889],
[ 1.0914, 1.1041, 0.4942, 1.1313, -0.1660, 0.0554, -0.2271,
0.7867]],
[[-0.2900, -0.2258, -0.2358, 0.4607, 0.1242, -0.1859, -0.2307,
-0.2091],
[-1.4387, 0.9222, -0.8203, -0.5549, -1.1655, 1.9839, -1.1566,
-0.4329],
[-0.5075, -0.4016, 0.0412, 0.3256, -0.1748, 0.7096, -0.4776,
-0.3083],
[-0.9823, 0.0387, 0.0439, 0.4431, -0.0058, 1.2854, -0.7799,
1.0358]]])
final_v
final_v.shape = (2, 4, 8)
final_v =
tensor([[[-0.1752, 0.0491, -0.0801, -0.0787, -0.1814, 0.0389, -0.1972,
-0.1995],
[-0.2397, -0.1214, -0.0865, -0.0452, -0.3188, -0.0352, -0.0774,
-0.2735],
[-0.1034, -0.0589, -0.0271, 0.0491, -0.1226, 0.0988, -0.2010,
-0.2827],
[ 0.0825, 0.1005, -0.1582, -0.1077, -0.0095, -0.0083, -0.0857,
-0.3503]],
[[-0.1902, 0.1719, -0.1485, -0.1148, -0.2115, 0.0373, -0.2473,
-0.2264],
[-0.1818, -0.5633, 0.6620, 0.2759, -0.0522, -0.1305, -0.0082,
-0.3593],
[-0.2128, -0.0298, 0.1194, 0.0714, -0.1631, -0.0033, -0.2451,
-0.2436],
[-0.1639, -0.2346, 0.4744, 0.3995, -0.2150, -0.2271, -0.3343,
-0.2381]]])8.1 第 0 层
因为历史里只有输入 x,所以:
α = 1 \alpha = 1 α=1
这很合理,因为它没有别的历史项可以选。
8.2 第 1 层
第 1 层历史里已经有两项:
x , v 0 \] \[x, v_0\] \[x,v0
这时平均注意力权重大概是:
0.6249 , 0.3751 \] \[0.6249, 0.3751\] \[0.6249,0.3751
说明在当前随机初始化下,这层更偏向读取原始输入。
8.3 第 2 层
第 2 层历史里有三项:
x , v 0 , v 1 \] \[x, v_0, v_1\] \[x,v0,v1
平均权重大概是:
0.6445 , 0.2387 , 0.1168 \] \[0.6445, 0.2387, 0.1168\] \[0.6445,0.2387,0.1168
这表示:
- 当前层最依赖最早历史项
- 对最近层输出反而依赖更少
当然,这只是随机初始化下的现象;真正训练后,这些权重会随着任务和数据学出来。