一个学习视频:https://www.bilibili.com/video/BV1v1421Q73e
JEPA 全称是 Joint Embedding Predictive Architecture(联合嵌入预测架构),是图灵奖得主、Meta首席AI科学家 Yann LeCun(杨立昆) 从2022年开始大力推动的一种全新自监督学习架构。
它被很多人视为是"下一代AI范式"的重要候选之一,尤其被认为是通往真正理解物理世界、具备规划和推理能力的 世界模型(World Model) 的关键技术路径。
为什么需要 JEPA?
当前主流大模型主要靠两种方式学习:
- 自回归生成(下一个token/像素预测)
- 掩码重建(像MAE、扩散模型那样填空)
LeCun 认为这两种方式都有致命问题:
- 生成式方法被迫预测所有细节(包括噪声、背景、光照、纹理等无关信息),非常浪费计算
- 学到的表示不够抽象,很难直接用于规划、推理、多模态长期预测
- 难以处理物理世界的不确定性、多模态可能性(同一个动作可能有多种合理结果)
JEPA 的核心思路非常简洁粗暴:
不在像素/单词层面做精确重建,而是在高度抽象的表征(embedding)空间里做预测。
一、JEPA 家族:以预测驱动的人类式理解
JEPA 家族的核心定位是预测能力:模型通过预测被遮蔽、被未来、或被其他视角的部分,来强制学习场景的内在结构、因果关系和物理规律,而不是死记硬背像素或单词。
主要成员发展时间线如下:
- 2022 年 6 月:Yann LeCun 发布《A Path Towards Autonomous Machine Intelligence》,首次系统定义"世界模型"概念,并提出 JEPA 作为非生成式预测架构的核心。
- 2023 年 4 月:Meta 推出 I-JEPA(图像版 JEPA),第一个落地实现,证明了在抽象表征空间预测的有效性。
- 2024 年 2 月:V-JEPA(视频版 JEPA)发布,正好在 Sora 公布次日,展示了 JEPA 在动态世界理解上的潜力。
- 2024 年 3 月:发布 IWM(Image World Model),进一步强化图像世界模型能力。
- 2025 年及以后:V-JEPA 2、VL-JEPA、LLM-JEPA 等迭代版本陆续出现,逐步向多模态、语言、机器人规划方向扩展。
JEPA 强调:不追求像素级/ token 级完美重建,而是捕获可预测的语义本质。这让它在噪声鲁棒性、多模态一致性、长期预测上天然具有优势。
二、强化学习经典框架:试错中的最大化奖励
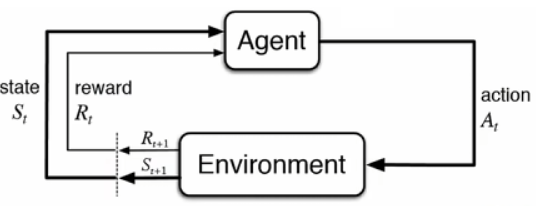
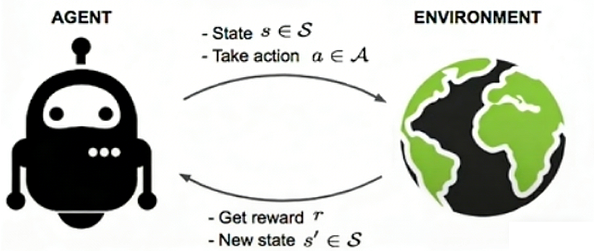
要理解 JEPA 如何走向自主智能,先回顾经典强化学习(RL)交互框架:
-
Agent(智能体) 与 Environment(环境) 不断循环交互。
-
-
每一步:
- Agent 观测当前状态
- 根据策略选择动作
- 环境转移到新状态
,并给出即时奖励
- Agent 根据经验更新策略
- Agent 观测当前状态
-
最终目标:通过大量试错,最大化长期累积奖励(expected discounted return)。
传统 RL 面临"样本效率低""探索-利用困境""奖励稀疏"等难题,而 JEPA 试图通过强大的世界模型来大幅缓解这些问题。
三、JEPA 的自主智能世界模型架构
LeCun 提出的完整自主智能架构包含六大核心模块,JEPA 主要充当"World Model"角色:
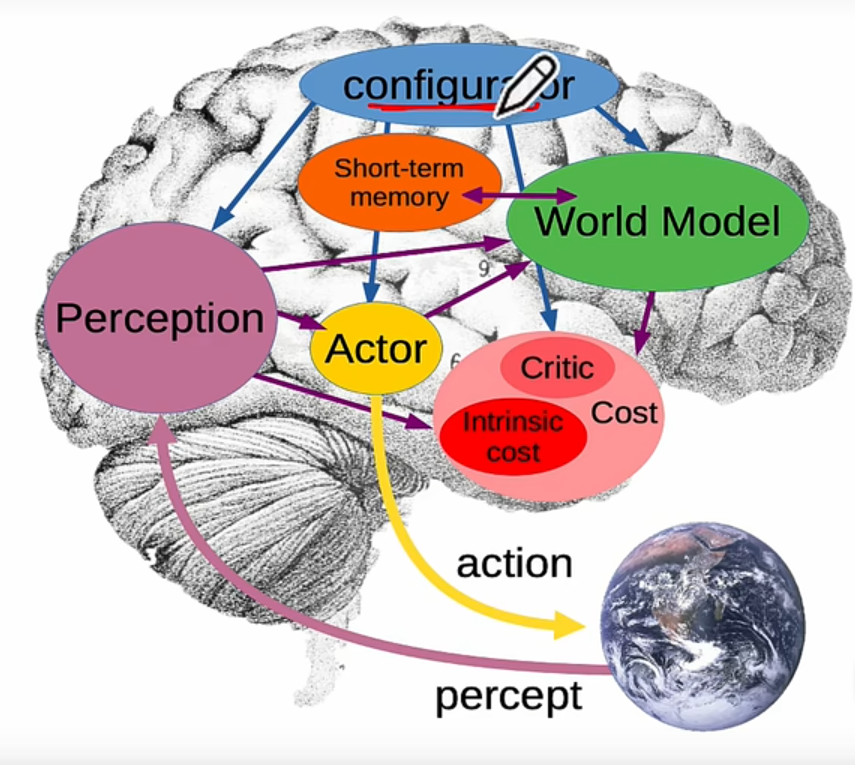
- Configurator(配置器):任务级大脑,根据当前目标动态配置其他模块。
- Perception(感知模块):从原始输入提取当前世界状态表征。
- World Model(世界模型):核心是 JEPA,预测未来可能的状态。
- Cost(代价模块):计算状态/动作的"能量",包括 Intrinsic Cost和 Critic Cost。
- STM(短期记忆):记录最近的历史轨迹,支持时序推理。
- Actor(行动模块):根据世界模型预测 + 代价评估,输出最优动作序列。
模块闭环逻辑:感知 → 短期记忆 → 世界模型预测 → 代价评估 → 行动输出 → 配置器调整,形成完整自主决策循环。
四、Mode-1:基础反应式感知-动作循环
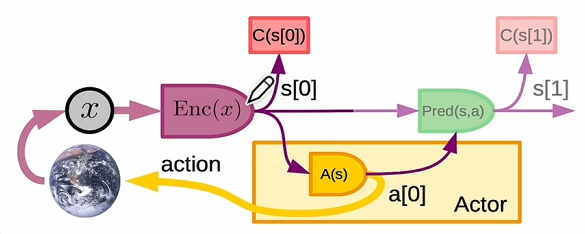
最基本的单步交互
:
- 感知编码:
- 动作决策:
- 代价计算:
- 世界模型前向预测:
定位:即时、反应式智能,适合快速响应任务。
五、Mode-2:规划式多步感知-动作序列
在 Mode-1 基础上扩展为多步时序链:
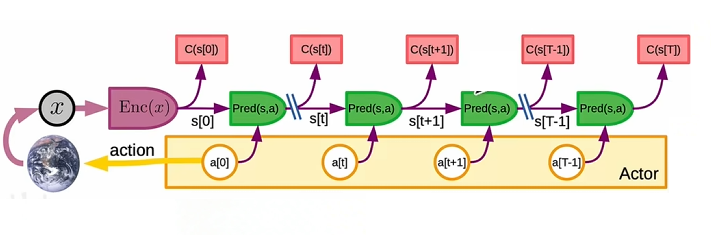
- 将单步循环视为马尔可夫决策过程(MDP)。
- 使用贝尔曼方程(Bellman Equation)求解价值函数。
- 通过梯度优化或搜索,在抽象表征空间中寻找低代价的动作序列。
- 端到端深度学习优化整个预测-代价-行动链。
定位:长期规划智能,适合需要前瞻、权衡未来多步后果的任务。
六、JEPA 的核心贡献与架构本质
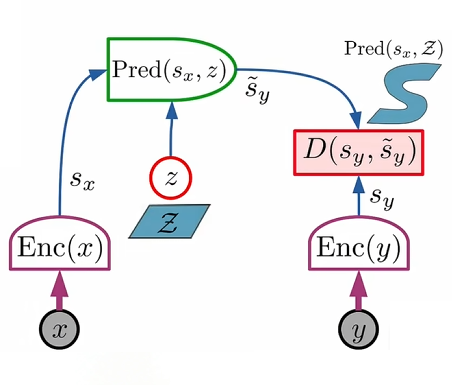
JEPA 直指当前 AI 最大瓶颈------世界模型的架构与训练范式。其主要创新包括:
- 自监督学习(SSL):无需人工标注,从海量数据中通过预测学习。
- 隐变量建模不确定性:显式引入潜在变量 z,捕获"一因多果"的随机性。
- 能量模型(EBM)训练:用预测误差作为能量,结合熵正则化,学习合理状态分布。
- 联合嵌入预测架构:核心非生成式设计------不直接生成 y,只捕获 x 与 y 的依赖关系。
核心流程(以视频为例):
- 输入 x(上下文)、y(目标),分别编码 →
- 采样潜在变量 z
- 预测器:Pred(
- 最小化距离 D(
七、I-JEPA 与 V-JEPA:落地验证世界模型潜力
- I-JEPA(图像世界模型的起点)
- 创新:不生成像素,只预测遮蔽区域的语义表征。
- 借鉴 MAE 的大块掩码 + 上下文预测。
- 结果:学到高度语义化的表示,直接适配分类、检测、深度估计等下游任务。
- V-JEPA(动态世界理解的关键)
- 扩展到视频:用历史片段表征预测未来/遮蔽片段表征。
- 采用 EMA 更新目标编码器 + stop-gradient 稳定训练。
- 结果:时空语义强大,在动作识别、未来预测、因果推理上表现出色。
- V-JEPA 2 进一步实现零样本机器人控制,展示规划能力。
目前主流的 JEPA 家族成员(Meta 主推)
| 名字 | 主要处理模态 | 发布年份 | 核心特点 | 论文/arxiv |
|---|---|---|---|---|
| I-JEPA | 图像 | 2023 | 最早落地的图像版JEPA | https://arxiv.org/abs/2301.08243 |
| V-JEPA | 视频 | 2024 | 非生成式视频理解世界模型 | https://arxiv.org/abs/2404.08471 |
| V-JEPA 2 | 视频 | 2025 | 更强的物理世界预测 & 规划能力 | Meta 最新版(VivaTech 展示) |
| LLM-JEPA | 语言 | 2025 | 把JEPA思想用到大语言模型上 | https://arxiv.org/abs/2509.14252 |
| LeJEPA | 通用 | 2025 | 更理论化、无需大量trick、可证明的版本 | https://arxiv.org/abs/2511.08544 |