老铁们,欢迎来到MyBatis的XML世界!不管你有没有了解过注解方式,都没关系,因为XML方式是MyBatis最原始、最强大的形式,也是我个人最喜欢的方式。为什么喜欢?因为XML把SQL语句独立出来,清晰、灵活,尤其是面对复杂查询时,那种掌控感简直不要太爽。今天我们就从零开始,彻底掌握XML方式,并且会给大家把每一个细节、每一个为什么都掰开揉碎了讲清楚。
1. 使用XML的准备条件:让MyBatis知道去哪找XML
1.1 数据库连接配置
首先,我们需要告诉MyBatis如何连接到数据库。在 application.yml 中配置:
yaml
spring
# 配置数据源
datasource:
url: jdbc:mysql://localhost:3306/javaee_test?useSSL=false&characterEncoding=utf8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver #这个在新版本下可以不用设置
# 配置mybatis的日志(可选)
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl这几行配置的作用是:
url:告诉MyBatis要连接哪个数据库(mybatis_demo),以及一些连接参数(如编码、是否使用SSL)。格式是固定的:jdbc:mysql://主机:端口/数据库名?参数。username/password:验证你的身份,只有提供正确的用户名密码才能登录数据库。driver-class-name:指定使用哪个JDBC驱动。MySQL 8.x使用com.mysql.cj.jdbc.Driver,5.x使用com.mysql.jdbc.Driver。
1.2 配置MyBatis的XML文件路径(关键)
这是XML方式最关键的一步 :你必须告诉MyBatis,你的XML映射文件放在哪里。在 application.yml 中添加:
yaml
mybatis:
mapper-locations: classpath:mapper/**Mapper.xml这个配置是什么意思呢?
classpath:表示从编译后的classes目录下找(也就是resources目录下的文件编译后会放到classes里)。你可以把它理解为"项目的根目录"。mapper/**Mapper.xml是一个路径通配符:**表示任意多级目录(包括子文件夹)这里面使用一个* 或者两个 *都是可以的。*Mapper.xml表示文件名以Mapper.xml结尾。
举个例子:如果你的XML文件放在 resources/mapper/student/StudentMapper.xml,它也能被扫描到。如果放在 resources/mybatis/xml/StudentMapper.xml,那就要把配置改成 classpath:mybatis/xml/*.xml。
为什么需要这个配置?
因为MyBatis启动时,需要去加载所有XML文件,解析里面的SQL语句。如果不告诉它路径,它就会像无头苍蝇一样找不到文件,你调用Mapper接口时就会报错(说找不到对应的SQL)。所以这一步是必须的!
疑问:如果我不配置这个会怎样?
那你就会得到一个经典的错误:Invalid bound statement (not found)。意思是MyBatis找到了你的Mapper接口,但是找不到对应的SQL语句(因为没加载XML)。
2. 写持久层代码:接口和XML文件
MyBatis的XML方式需要两部分:
- Mapper接口:定义方法(告诉MyBatis你要做什么操作)。
- XML映射文件:写具体的SQL语句(告诉MyBatis怎么操作)。
2.1 创建Mapper接口(加@Mapper注解)
我们创建一个 StudentMapper 接口:
java
package com.example.mapper;
import com.example.model.Student;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper // 这个注解非常重要!
public interface StudentMapper {
List<Student> findAll(); // 查询所有学生
}为什么需要加 @Mapper 注解?
这个注解是告诉Spring:这是一个MyBatis的Mapper接口,需要在容器中为它创建代理对象 。如果不加这个注解,Spring就不会扫描到这个接口,也就不会生成代理对象,你后面就无法通过 @Autowired 注入它。
加了 @Mapper 后,MyBatis帮我们做了什么?
- 在Spring启动时,MyBatis会扫描所有带
@Mapper的接口。 - 为每个接口创建一个动态代理对象(实现了该接口的类)。
- 将这个代理对象注册到Spring容器中,成为一个Bean。
- 这样,你才能在Service层通过
@Autowired注入这个接口。
2.2 创建XML映射文件
在 resources/mapper 目录下创建一个XML文件,命名为 StudentMapper.xml(文件名可以任意,但建议和接口名一致)。文件内容如下:
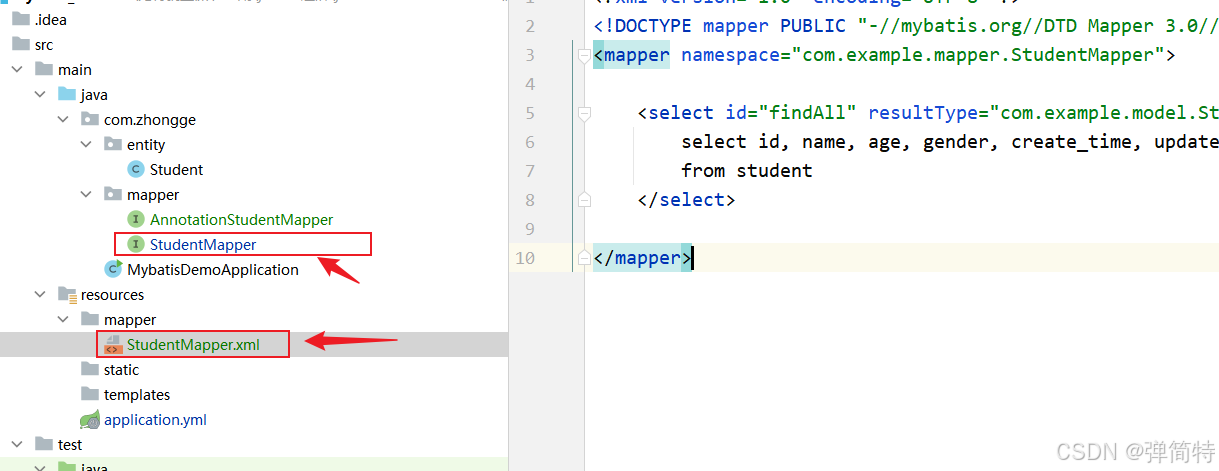
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zhongge.mapper.StudentMapper">
<select id="findAll" resultType="com.zhongge.entity.Student">
select id, name, age, gender, create_time, update_time
from student
</select>
</mapper>逐行解释:
- 第一行:XML声明,指定版本和编码,没什么特别的。
- 第二行 :
<!DOCTYPE ...>是文档类型定义,告诉XML解析器这个文件遵循MyBatis的DTD规范。你可以把它理解为"这个XML的语法规则说明书"。没有它,一些标签可能无法被正确识别。 <mapper>标签 :根标签,有两个重要属性:namespace:命名空间。它的值必须是接口的全限定名 (包名+接口名),比如这里的com.zhongge.mapper.StudentMapper。这个属性是用来绑定接口的,告诉MyBatis这个XML文件是为哪个接口服务的。
<select>标签 :代表一个查询操作。id:这条SQL语句的唯一标识。它的值必须等于接口中的方法名 ,比如这里的findAll。resultType:返回结果的类型。这里写的是实体类的全限定名com.zhongge.entity.Student。MyBatis会自动把查询结果的每一行映射成Student对象。- 标签中间就是SQL语句。
2.3 单元测试验证
写一个测试类来验证是否成功:
java
@SpringBootTest
class StudentMapperTest {
@Autowired
private StudentMapper studentMapper;
@Test
void findAll() {
List<Student> all = studentMapper.findAll();
System.out.println(all);
}
}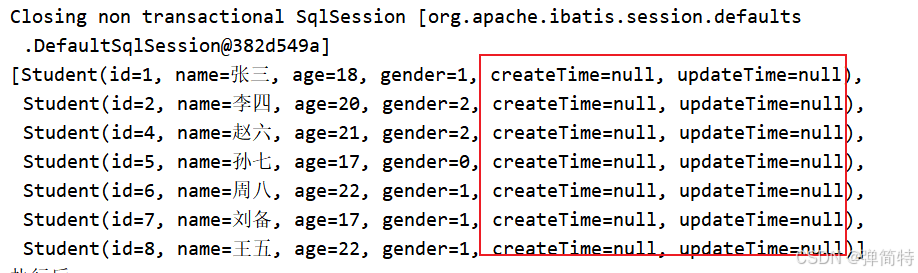
如果一切正常,你会看到查询出的学生列表。但注意:你会发现 createTime 和 updateTime 属性是 null(因为列名和属性名不一致)。这个我们后面会解决。
3. 四大约定:为什么MyBatis能找到对应的SQL?
现在我们来解答你心中的四大疑问。这些问题搞清楚了,你就能彻底理解XML方式的工作原理。
约定一:XML文件必须放在和接口同一个包下吗?
答案:不一定!
我们可以在 mapper-locations 中任意指定路径。比如:
yaml
mybatis:
mapper-locations: classpath:mybatis/xml/*.xml这样,只要XML文件放在 resources/mybatis/xml 下,不管接口在哪个包,MyBatis都能找到。
但是,很多人习惯把XML和接口放在同一个包下(比如接口在 com.example.mapper,XML放在 resources/com/example/mapper)。这样做的好处是:一眼就能看出哪个XML对应哪个接口,方便维护。不过需要你在 resources 下建立同样的包结构,稍微麻烦一点。
结论 :位置可以灵活配置,但为了方便,建议统一放在一个文件夹下(比如 mapper),然后用配置指定。
约定二:XML文件名必须和接口名一致吗?
答案:不一定!
MyBatis并不会自动根据文件名去匹配接口,它完全依赖 namespace 来定位。所以理论上你可以把XML文件命名为 abc.xml,只要 namespace 写对了,一样能工作。
但是,强烈建议文件名和接口名一致 ,比如 StudentMapper.java 对应 StudentMapper.xml。这样团队协作时,别人一看就知道哪个文件对应哪个接口,省去很多麻烦。
结论:文件名不是必须一致,但为了可维护性,建议一致。
约定三:为什么 namespace 必须等于接口的全限定名?
这是硬性要求 ,必须满足!
namespace 的作用是告诉MyBatis:这个XML文件是为哪个接口服务的。当调用 studentMapper.findAll() 时,MyBatis会做以下事情:
- 拿到接口的全限定名:
com.zhongge.mapper.StudentMapper。 - 在内部维护的一个Map中,以这个全限定名为key,找到对应的
namespace的XML文件。 - 然后在那个
namespace下,根据方法名findAll找到对应的SQL标签。
如果 namespace 写错了,MyBatis就找不到这个XML,就会报错。
打个比方:
namespace就像公司的部门名称。你要找某个部门的员工(SQL语句),必须先知道部门名称(接口全限定名)。- 如果部门名称写错了,你就找不对人。
结论 :namespace 必须等于接口全限定名,这是MyBatis的硬性规定。
约定四:为什么SQL标签的 id 必须等于接口的方法名?
这也是硬性要求。
在同一个 namespace 下,每个SQL标签的 id 必须与接口中的方法名一致。这样,当调用 studentMapper.findById(1) 时,MyBatis就知道要执行 com.zhongge.mapper.StudentMapper 下 id=findById 的那个SQL。
如果 id 不一致,MyBatis就找不到对应的SQL,报错 Invalid bound statement。
打个比方:
id就像部门里的工号。你要找一个具体的人(SQL语句),必须知道他的工号(方法名)。- 如果工号写错了,你就找不到这个人。
结论 :id 必须等于方法名,这也是硬性规定。
完成约定后,MyBatis帮我们做了什么?

当所有约定都满足(特别是 namespace 和 id),MyBatis在启动时会:
- 扫描接口 :根据
@Mapper注解找到所有Mapper接口。 - 生成代理对象:为每个接口创建一个动态代理对象(实现了该接口),并放入Spring容器。
- 解析XML :根据
mapper-locations找到所有XML文件,解析出每个<select>、<insert>等标签,创建MappedStatement对象(包含了SQL语句、参数映射、返回值类型等信息),并以namespace.id为key缓存起来。 - 建立关联 :将接口方法和对应的
MappedStatement关联起来。
当你调用接口方法时:
- 代理对象拦截调用。
- 根据接口全限定名和方法名,从缓存中找到对应的
MappedStatement。 - 执行SQL,并处理结果。
4. 参数传递原理
无论你用哪种方式写SQL,MyBatis处理参数的底层机制都是一样的。下面我们通过几种常见情况,一步步拆解参数传递的完整流程。
4.1 参数传递的核心:参数容器
MyBatis会把方法传入的参数统一管理起来,这个"管理者"我们可以抽象为参数容器/参数源。它可以是:
- 单个简单值(如 Integer、String)
- 一个 Java 对象(如 Student)
- 一个 Map(称为
ParamMap)
整个流程如下:

下面我们结合具体案例,画出每一步的细节。
4.2 情况一:单个简单参数
场景:根据ID查询学生。
java
Student findById(Integer id);XML:
xml
<select id="findById" resultType="com.zhongge.entity.Student">
select * from student where id = #{id}
</select>调用:findById(1)
结果:

流程图:

关键点 :单个简单参数时,无论 #{} 里写什么名字,都取这个唯一的参数值。
4.3 情况二:多个参数(无@Param)
场景:根据姓名和年龄查询学生。
java
Student findByNameAndAge(String name, Integer age);XML:
xml
<select id="findByNameAndAge" resultType="com.zhongge.entity.Student">
select * from student where name = #{name} and age = #{age}
</select>调用:findByNameAndAge("张三", 18)
这个写法能工作吗?------取决于编译参数
情况 A:编译时保留了参数名(如 Spring Boot 默认)
如果项目编译时开启了 -parameters(Spring Boot 默认开启),那么 MyBatis 能获取到参数的真实名称 name 和 age。它会构建一个 ParamMap,其中包含 key name、age 以及 param1、param2 等通用 key。此时 XML 中写 #{name} 和 #{age} 可以正确取值。
情况 B:编译时未保留参数名
如果编译器没有保留参数名,MyBatis 只能拿到默认的 arg0、arg1 等。此时 XML 中写 #{name} 会报错(因为 Map 中没有 name),必须写成 #{arg0} 和 #{arg1} 或 #{param1} 和 #{param2} 才能工作。
实际运行结果
下面是一个错误示例,如果在 Spring Boot 项目中 XML 里写成了 #{arg0}:
xml
<select id="findByNameAndAge" resultType="com.zhongge.entity.Student">
select * from student where name = #{arg0} and age = #{arg1}
</select>运行测试会报错:
org.apache.ibatis.binding.BindingException: Parameter 'arg0' not found.
Available parameters are [name, param1, age, param2]错误信息明确告诉你:可用的参数名是 name、age、param1、param2,没有 arg0。所以正确的写法应该是使用 #{name} 和 #{age}。
结论
- 在 Spring Boot 项目中(默认保留参数名) ,无
@Param的多参数方法,XML 中应直接使用参数的真实名称(如#{name}),或使用通用名称#{param1}、#{param2}。 - 如果希望代码在任何编译环境下都能工作 ,强烈建议使用
@Param注解,这样无论是否保留参数名,都能用你自己定义的名称。
MyBatis 内部处理步骤(以保留参数名为例):
- 方法调用 :传入
"张三"和18。 - 参数解析 :
ParamNameResolver发现有多个参数,且没有@Param,但因为开启了-parameters,它能获取到真实参数名name和age。于是它创建ParamMap,放入:"name" → "张三""age" → 18- 同时为了兼容性,还会放入
"param1" → "张三"、"param2" → 18
- SQL 解析 :解析
#{name}时,从 Map 中取 key"name"得到"张三";#{age}取"age"得到18。 - 设置参数:MyBatis 设置到 PreparedStatement。
图示:
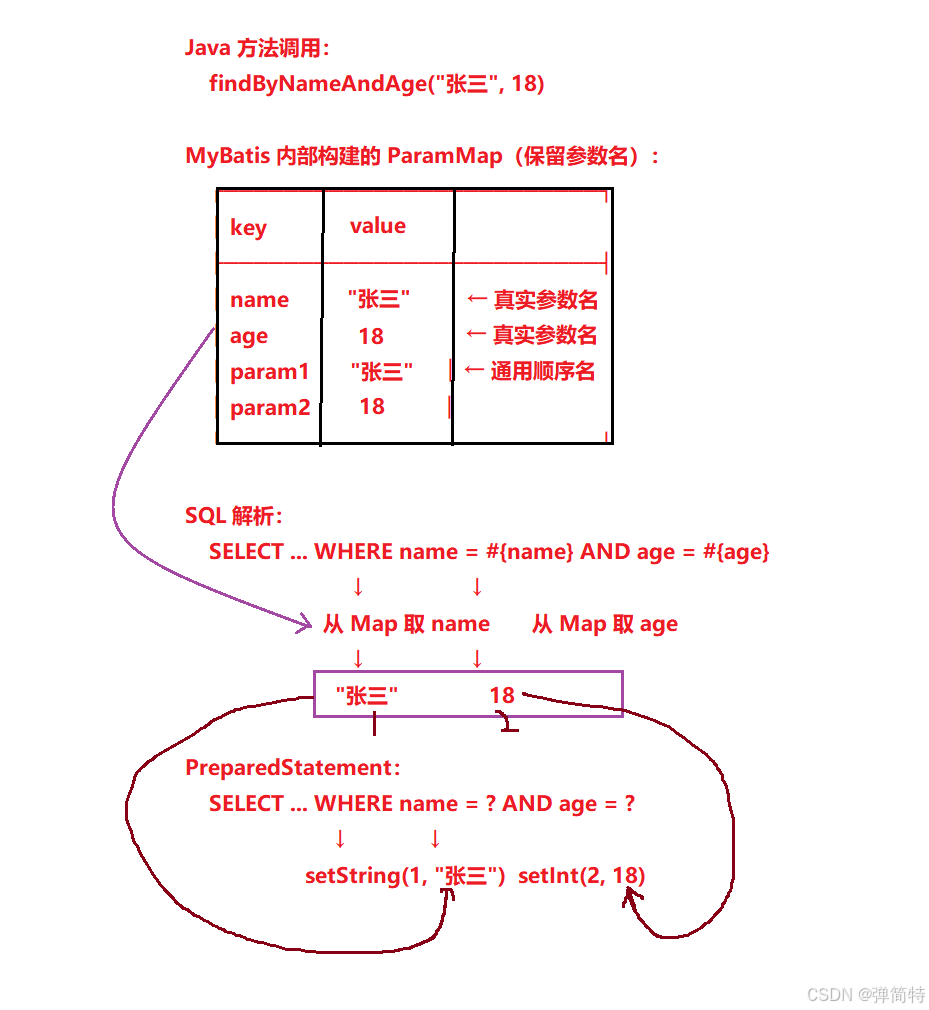
关键点:
- 无
@Param的多参数,是否能用#{name}取决于编译时是否保留了参数名。 - Spring Boot 默认保留了参数名,所以可以直接使用真实参数名。
- 为了代码的健壮性和可移植性,强烈推荐始终使用
@Param注解,这样你可以自定义参数名,不再依赖编译选项。
4.4 情况三:多个参数(使用 @Param)
场景 :使用 @Param 明确指定参数名。
java
Student findByNameAndAge(@Param("name") String name, @Param("age") Integer age);XML:
xml
<select id="findByNameAndAge" resultType="com.example.model.Student">
select * from student where name = #{name} and age = #{age}
</select>调用:findByNameAndAge("李四", 20)
实际运行结果
如果在 XML 中误用了 #{arg0} 和 #{arg1},会得到如下错误:
org.apache.ibatis.binding.BindingException: Parameter 'arg0' not found.
Available parameters are [name, param1, age, param2]错误信息告诉我们:可用的参数名是 name、age、param1、param2,并没有 arg0 或 arg1。这说明在使用了 @Param 的情况下,MyBatis 构建的 ParamMap 中只包含:
@Param指定的 key(如name和age)- 通用顺序 key:
param1、param2(始终存在,用于兼容)
为什么没有 arg0、arg1?
因为当方法参数上使用了 @Param 注解,MyBatis 认为开发者已经明确指定了参数名称,就不再生成基于索引的默认名称(arg0、arg1),避免 Map 中 key 过多造成混乱。仅保留 param1、param2 作为通用备用名称,方便在动态 SQL 中引用。
MyBatis 内部处理步骤
- 方法调用 :传入
"李四"和20。 - 参数解析 :
ParamNameResolver发现有多个参数,且都带有@Param注解。它创建一个ParamMap,放入以下键值对:"name" → "李四"(来自@Param("name"))"age" → 20(来自@Param("age"))"param1" → "李四"(自动添加的通用名)"param2" → 20(自动添加的通用名)
- SQL 解析 :解析
#{name}时,从 Map 中取 key"name"得到"李四";#{age}取"age"得到20。 - 设置参数:MyBatis 设置到 PreparedStatement。
图示
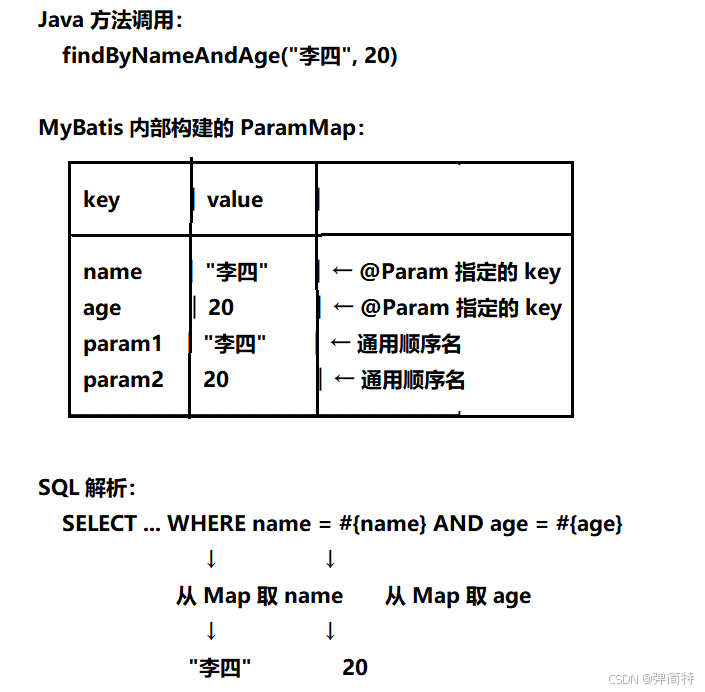
关键点
@Param明确指定了参数在 Map 中的 key ,所以 SQL 中应该使用这些 key(如#{name}、#{age})。param1、param2始终存在,作为备用名称,但一般不建议使用,因为可读性差。- 不会生成
arg0、arg1,避免 Map 膨胀。如果需要使用索引名称,应使用param1、param2。 - 使用
@Param是最佳实践,它让你的代码清晰、不依赖编译参数,且在任何环境下都能稳定运行。
4.5 情况四:单个对象参数(无@Param)
场景:插入一个学生对象。
java
int insert(Student student);XML:
xml
<insert id="insert">
insert into student(name, age, gender) values(#{name}, #{age}, #{gender})
</insert>调用:
java
Student stu = new Student("王五", 22, 1);
insert(stu);流程图 :
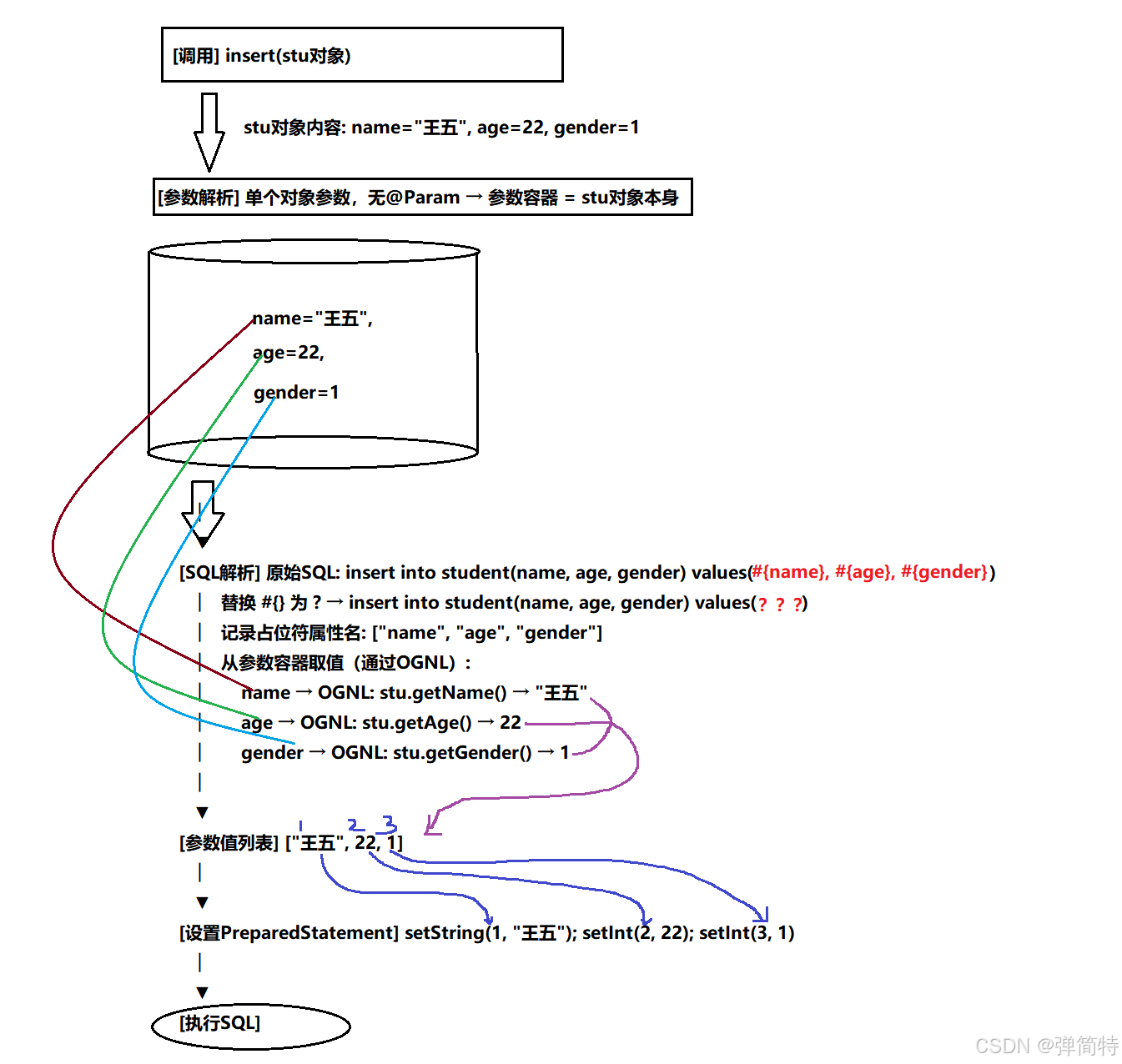
关键点 :无@Param时,对象本身作为参数源,#{} 里直接写属性名,MyBatis通过OGNL自动调用对应的getter方法。
4.6 情况五:单个对象参数(有 @Param)
场景:插入一个学生对象,但加了 @Param。
java
int insert(@Param("stu") Student student);XML:
xml
<insert id="insert">
insert into student(name, age, gender) values(#{stu.name}, #{stu.age}, #{stu.gender})
</insert>调用:
java
Student stu = new Student("赵六", 25, 2);
insert(stu);实际运行结果
如果在 XML 中误用了 #{arg0.name} 这样的写法:
xml
<insert id="insert">
insert into student(name, age, gender) values(#{arg0.name}, #{arg0.age}, #{arg0.gender})
</insert>会得到如下错误:
org.apache.ibatis.binding.BindingException: Parameter 'arg0' not found.
Available parameters are [stu, param1]错误信息告诉我们:可用的参数名是 stu 和 param1,并没有 arg0。这说明在使用了 @Param 的情况下,MyBatis 构建的 ParamMap 中只包含:
@Param指定的 key(如stu)- 通用顺序 key:
param1(始终存在,用于兼容)
为什么没有 arg0?
因为当方法参数上使用了 @Param 注解,MyBatis 认为开发者已经明确指定了参数名称,就不再生成基于索引的默认名称(arg0),避免 Map 中 key 过多造成混乱。仅保留 param1 作为通用备用名称,方便在动态 SQL 中引用。
MyBatis 内部处理步骤
- 方法调用 :传入一个 Student 对象,里面有
name="赵六",age=25,gender=2。 - 参数解析 :
ParamNameResolver发现只有一个参数,但带有@Param注解。它创建一个ParamMap,放入以下键值对:"stu" → student对象(来自@Param("stu"))"param1" → student对象(自动添加的通用名)
- SQL 解析 :解析
#{stu.name}时,先从 Map 中取 key"stu"得到 student 对象,然后通过 OGNL 从该对象中取name属性(即student.getName())。类似地,#{stu.age}和#{stu.gender}依次取值。 - 设置参数:MyBatis 将取出的值设置到 PreparedStatement。
图示
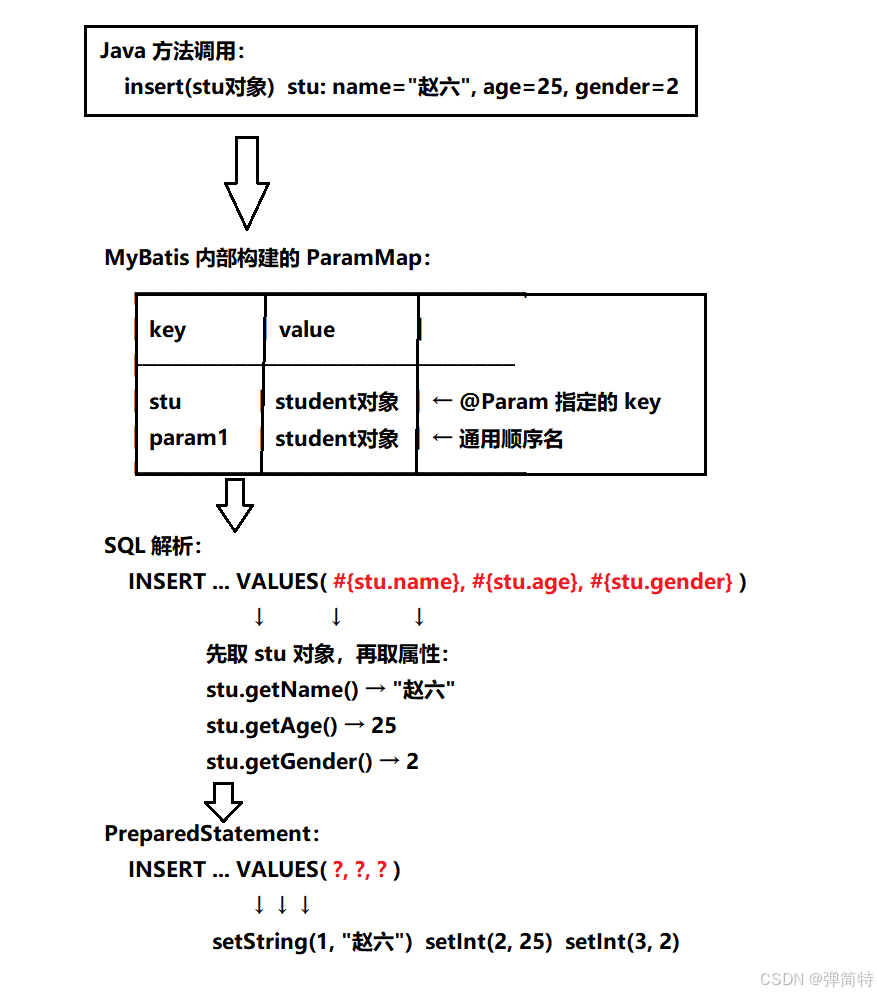
关键点
- 加了
@Param后,对象被放入 Map ,SQL 中必须用#{key.属性名}的形式取值。 - 可用 key 只有
@Param指定的值(如stu)和param1,没有arg0、arg1等基于索引的 key。 - 如果直接用
#{name}或#{arg0.name}都会报错 ,因为 Map 中没有name或arg0这些 key。
对比:
- 无 @Param:直接写
#{属性名},对象本身作为参数源。 - 有 @Param:必须写
#{key.属性名},其中key是@Param指定的值(或param1)。
5. 结果映射原理:从数据库行到Java对象
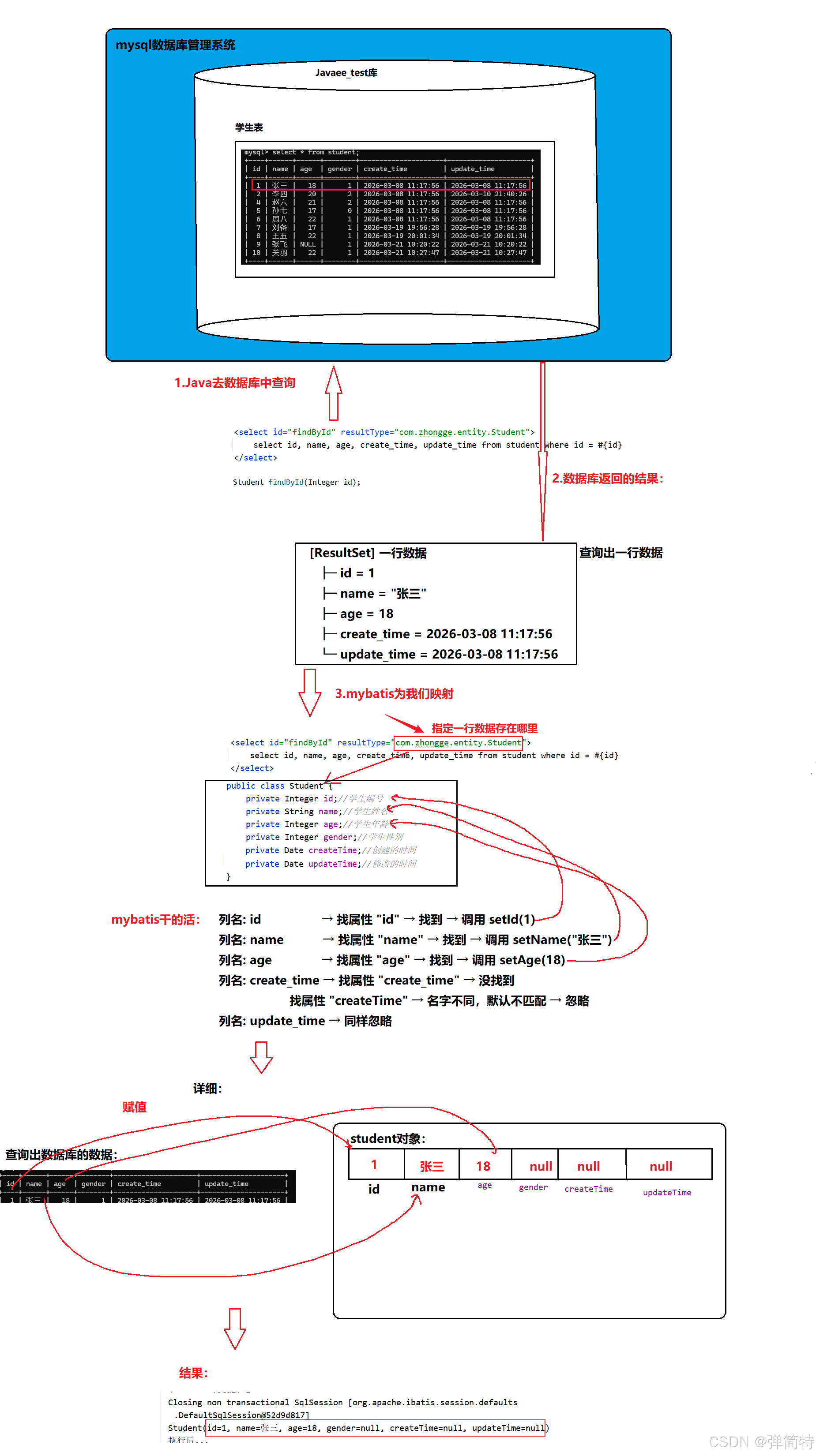
5.1 默认映射过程
当我们执行一条查询SQL后,数据库会返回一个 ResultSet (结果集),可以想象成一个表格,有行有列。MyBatis需要把每一行数据转换成一个Java对象,这个过程叫结果映射。
默认的映射规则非常简单:
- 遍历结果集的每一列,获取列名(如
id、name、create_time)。 - 在目标Java类中查找同名属性(忽略大小写)。
- 如果找到了,就通过反射调用该属性的
setter方法,将这一列的值赋进去。 - 如果没找到,这一列就被忽略,属性保持默认值(如
null)。
举个例子 :

假设SQL返回的列名是 id、name、age、create_time、update_time,而 Student 类有属性 id、name、age、createTime、updateTime。
id→ 找到id属性,调用setId()name→ 找到name属性,调用setName()age→ 找到age属性,调用setAge()create_time→ 在类中找create_time属性,没有;找createTime属性,有,但名字不一样(下划线 vs 驼峰),默认匹配失败,所以createTime保持null。update_time同理。
结果:

这就是为什么我们之前看到 createTime 和 updateTime 是 null。
流程图(默认映射):
5.2 解决方法一:SQL别名
在SQL中给列起别名,让别名等于Java属性名。
xml
<select id="findAll" resultType="com.zhongge.entity.Student">
select
id,
name,
age,
gender,
create_time as createTime,
update_time as updateTime
from student
</select>原理 :数据库返回的列名变成了 createTime 和 updateTime,MyBatis就能直接匹配了。
流程图:

5.3 解决方法二:使用 <resultMap> 手动映射
xml
<resultMap id="BaseResultMap" type="com.zhongge.entity.Student">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="age" property="age"/>
<result column="gender" property="gender"/>
<result column="create_time" property="createTime"/>
<result column="update_time" property="updateTime"/>
</resultMap>
<select id="findAll" resultMap="BaseResultMap">
select id, name, age, gender, create_time, update_time
from student
</select>原理 :MyBatis不再自动匹配,而是按照 resultMap 中定义的规则,将指定列的值赋给对应的属性。
流程图:

5.4 解决方法三:开启驼峰命名自动转换(推荐)
在 application.yml 中配置:
yaml
mybatis:
configuration:
map-underscore-to-camel-case: true原理 :开启后,MyBatis在自动匹配时,会将列名中的下划线去掉,并将下划线后的字母大写,然后再去匹配属性。例如 create_time → createTime,update_time → updateTime。
流程图:

强烈推荐这种方法,一次配置,全局生效,代码最简洁。
6. 增删改查操作
现在我们来完整实现增删改查
6.1 插入数据(Insert)
6.1.1 基本插入
接口:
java
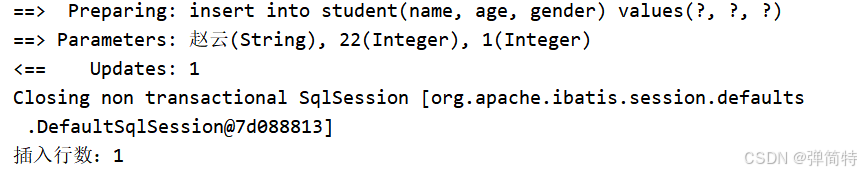
int insert(Student student);XML:
xml
<insert id="insert">
insert into student(name, age, gender) values(#{name}, #{age}, #{gender})
</insert>测试:
java
Student stu = new Student();
stu.setName("赵云");
stu.setAge(22);
stu.setGender(1);
int count = studentMapper.insert(stu);
System.out.println("插入行数:" + count);结果
6.1.2 获取自增主键(为什么要获取?怎么获取?)
为什么需要获取自增主键?
在很多业务场景中,插入一条数据后,我们需要知道这条数据在数据库中生成的唯一ID,以便进行后续操作。例如:
- 订单系统:下单后需要拿着订单ID去通知库存、物流、支付等系统。
- 社交系统:发布文章后需要返回文章ID给前端,用于跳转到详情页。
- 关联操作:插入主表后,需要在子表中引用新生成的主键(如用户注册后,需要创建关联的账户信息)。
如果插入后拿不到ID,我们就得再用查询语句去查一遍(比如根据唯一业务字段查询),既浪费资源又麻烦,而且还可能因为并发导致查错数据。所以MyBatis提供了直接获取自增主键的功能,让你在插入后能立刻拿到ID。
怎么获取?
使用 useGeneratedKeys 和 keyProperty 属性:
xml
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into student(name, age, gender) values(#{name}, #{age}, #{gender})
</insert>useGeneratedKeys="true":useGeneratedKeys译为使用自动生成的键值,告诉MyBatis,我们想要数据库自动生成的主键。这个属性的名字翻译过来就是"使用生成的主键"。keyProperty="id":keyProperty译为关键属性,指定将生成的主键赋值给传入对象的哪个属性(这里是id属性)。MyBatis会通过反射调用setId()方法把主键值设置进去。
测试代码:
java
Student stu = new Student();
stu.setName("赵六");
stu.setAge(25);
stu.setGender(2);
int count = studentMapper.insert(stu);
System.out.println("插入行数:" + count);
System.out.println("生成的主键:" + stu.getId()); // 这里就能拿到数据库生成的id了底层原理(通俗解释):
- JDBC层面 :Java的JDBC API中,
PreparedStatement有一个特殊的方法,可以在执行插入时告诉数据库:"我要插入数据,并且插入后请把自动生成的主键返回给我。"这个是通过在创建PreparedStatement时指定一个标志Statement.RETURN_GENERATED_KEYS实现的。执行插入后,可以通过getGeneratedKeys()方法获取一个包含主键的结果集。 - MyBatis层面 :当我们在XML中设置了
useGeneratedKeys="true",MyBatis在内部创建PreparedStatement时就会自动加上RETURN_GENERATED_KEYS标志。插入执行完毕后,MyBatis会立即调用getGeneratedKeys()拿到数据库返回的主键值,然后通过反射找到你传入的student对象的setId()方法,把主键值设置进去。这样,你原来的stu对象里的id就不再是null了。
注意 :即使获取了主键,int insert( Student student);这个方法的返回值依然是 int 类型,代表受影响的行数。主键是通过传入的对象属性带回来的,不是通过返回值。
6.2 删除数据(Delete)
接口:
java
int deleteById(Integer id);XML:
xml
<delete id="deleteById">
delete from student where id = #{id}
</delete>测试:
java
int count = studentMapper.deleteById(5);
System.out.println("删除行数:" + count);开发中,删除参数一般传递什么?
- 最常见:根据主键ID删除。因为ID是唯一标识,能精准定位要删除的记录,避免误删。
- 有时:也会根据其他唯一字段删除,比如根据用户账号删除,或者根据业务ID删除。
- 极少 :根据组合条件删除(如
where name = ? and age = ?),但这种情况风险较高,可能删除多条数据,通常需要谨慎处理,或配合事务使用。
删除操作的返回值 :int 类型,代表实际删除的行数。如果返回0,说明没有符合条件的记录;返回1表示删除了一条;返回大于1表示删除了多条(如果是根据非唯一条件删除)。在业务中,常常根据返回值判断删除是否成功。
6.3 更新数据
接口:
java
int update(Student student);XML:
xml
<update id="update">
update student
set name = #{name}, age = #{age}
where id = #{id}
</update>测试:
java
Student stu = new Student();
stu.setId(1);
stu.setName("张三丰");
stu.setAge(108);
int count = studentMapper.update(stu);
System.out.println("更新行数:" + count);开发中,更新参数一般怎么传递?
- 传递对象:最常用。将需要更新的数据封装成一个对象(通常包含ID和要修改的字段),然后根据对象中的ID去更新其他字段。这样代码简洁,语义清晰。
- 传递多个参数 :有时也会用
@Param传递多个参数,例如只更新某个字段,可以写updateNameById(@Param("id") Integer id, @Param("name") String name)。这种方式适合简单更新,不需要创建完整的对象。 - 传递Map :动态更新时,可能会把字段名和值放入Map,然后在SQL中用
<foreach>动态拼接,但这种情况较少见。
更新操作的返回值 :int 类型,代表实际更新的行数。如果返回0,说明ID不存在或没有数据被更新;返回1表示更新了一条。在业务中,可以根据返回值判断更新是否生效,例如如果更新了0条,可能需要提示用户"数据不存在"或"没有变化"。
7. 注解和XML的对比(简单了解)
虽然老铁们可能只学XML方式,但以后工作中可能会遇到其他项目用注解,简单了解一下两者的区别:
| 对比项 | XML方式 | 注解方式 |
|---|---|---|
| SQL位置 | 写在独立的XML文件中 | 写在Java接口的方法上 |
| 可读性 | 复杂SQL可以格式化,清晰 | 复杂SQL挤在一起,难看 |
| 动态SQL | 支持 <if>、<foreach> 等,功能强大 |
需要用 <script> 包裹,体验一般 |
| 维护性 | 所有SQL集中管理,方便DBA审查 | SQL分散在各处,不易管理 |
| 修改后 | 修改XML无需重新编译(需热部署) | 修改注解需重新编译 |
| 学习曲线 | 需要学习XML语法和标签 | 简单直观,上手快 |
我的建议:
- 简单的单表CRUD,用注解就够了。
- 涉及复杂查询、动态SQL、多表关联,强烈推荐XML方式。
- 一个项目里可以同时使用两种方式,不冲突。
我个人偏爱XML,因为它把SQL和代码彻底分离,看着舒服,维护起来也方便。而且当你需要复制SQL到数据库客户端测试时,直接从XML里复制出来就能用,不需要去掉注解里的引号,爽得很!
老铁们,如果你觉得这篇文章的整理对你有帮助,别忘了👍点赞、⭐收藏、👀 关注,你的支持是我持续输出的最大动力!我们下期见!