在做多门店IT运维的过程中,Redis是出问题最多、但监控最少的组件之一。
原因很直接:Redis平时太稳了,大家默认它不会挂。结果一旦出问题------内存打满被OOM、缓存雪崩导致DB被打爆、连接数耗尽报错------发现的时候往往已经影响业务了。
这篇文章给出我们实际用的Redis监控方案:从INFO命令采集→Zabbix自定义监控项→告警分级→Grafana看板,整条链路都是可落地的配置,不只讲思路。
一、先明确:Redis的哪些指标值得监控?
Redis内置的INFO命令能返回大量数据,但真正需要监控的核心指标只有三类:
1.1 内存类
| 指标 | INFO字段 | 含义 |
|---|---|---|
| 已用内存 | used_memory |
当前Redis实际使用的内存字节数 |
| 内存使用率 | used_memory / maxmemory |
需要计算,maxmemory为0表示无限制 |
| 内存碎片率 | mem_fragmentation_ratio |
>1.5说明内存碎片严重 |
| 最大内存 | maxmemory |
配置的内存上限 |
为什么重要 :内存打满会触发Redis的maxmemory-policy(如allkeys-lru),大量Key被驱逐,缓存命中率暴跌,DB被打爆。
1.2 命中率类
| 指标 | INFO字段 | 含义 |
|---|---|---|
| 命中次数 | keyspace_hits |
累计命中次数 |
| 未命中次数 | keyspace_misses |
累计未命中次数 |
| 命中率 | hits/(hits+misses) |
实时计算,正常应>95% |
为什么重要:命中率突然下跌通常意味着缓存穿透、Key大量过期或内存驱逐------这是业务请求打穿到DB的前兆。
1.3 连接与响应类
| 指标 | INFO字段 | 含义 |
|---|---|---|
| 当前连接数 | connected_clients |
当前活跃客户端连接数 |
| 最大连接数 | maxclients |
配置的最大连接上限 |
| 阻塞客户端数 | blocked_clients |
被BLPOP等命令阻塞的客户端 |
| 慢查询数 | slowlog_len(需单独获取) |
累计慢命令数量 |
为什么重要 :连接数耗尽直接导致新请求报ERR max number of clients reached;阻塞客户端数增加通常是业务逻辑问题。
二、监控链路设计
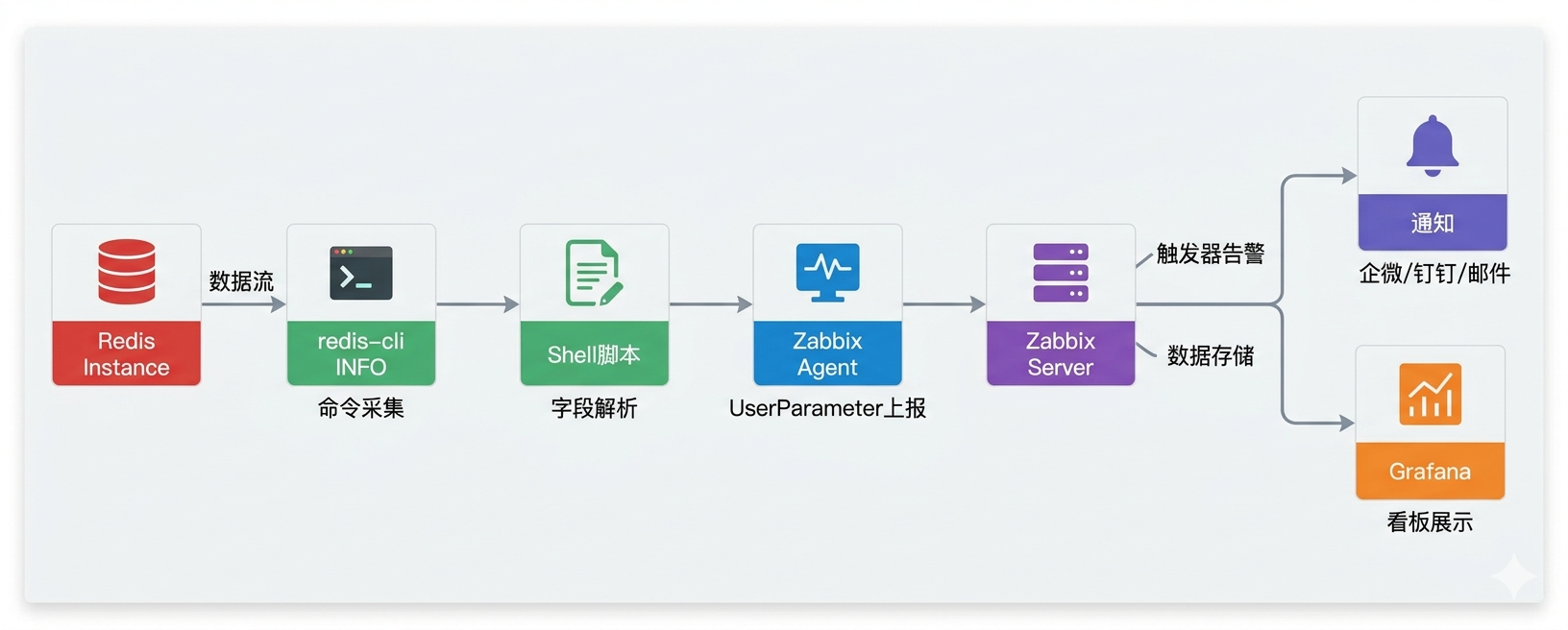
整体链路如下:
Redis实例
└─ redis-cli INFO 命令采集
└─ Shell脚本解析字段
└─ Zabbix Agent UserParameter 上报
├─ Zabbix Server 触发器告警 → 企微/钉钉/邮件通知
└─ Zabbix历史数据 → Grafana看板展示为什么用Shell脚本+UserParameter,而不是直接用Zabbix的Redis模板?
官方Redis模板依赖redis-cli直接返回值,对于需要计算的指标(如命中率、内存使用率百分比)无法直接支持。用Shell脚本做一层解析,可以把复杂指标算好再上报,触发器里直接用阈值判断,不需要在Zabbix里写复杂的计算表达式。
三、采集脚本配置
3.1 Redis INFO采集脚本
在Zabbix Agent所在的服务器(或Redis宿主机)上创建采集脚本:
bash
#!/bin/bash
# /usr/local/bin/redis_monitor.sh
# 用途:采集Redis关键指标并输出为Zabbix可读值
# 用法:./redis_monitor.sh <metric_name> [redis_host] [redis_port] [redis_password]
METRIC=$1
HOST=${2:-"127.0.0.1"}
PORT=${3:-"6379"}
PASS=${4:-""}
if [ -n "$PASS" ]; then
CLI="redis-cli -h $HOST -p $PORT -a $PASS"
else
CLI="redis-cli -h $HOST -p $PORT"
fi
INFO_ALL=$($CLI INFO all 2>/dev/null)
if [ -z "$INFO_ALL" ]; then
echo "ERROR: Cannot connect to Redis"
exit 1
fi
get_field() {
echo "$INFO_ALL" | grep "^$1:" | awk -F: '{print $2}' | tr -d '\r'
}
case "$METRIC" in
used_memory)
get_field "used_memory"
;;
maxmemory)
get_field "maxmemory"
;;
memory_usage_pct)
USED=$(get_field "used_memory")
MAX=$(get_field "maxmemory")
if [ "$MAX" = "0" ] || [ -z "$MAX" ]; then
# 无限制时用系统总内存估算
echo "0"
else
echo "scale=2; $USED * 100 / $MAX" | bc
fi
;;
mem_fragmentation_ratio)
get_field "mem_fragmentation_ratio"
;;
connected_clients)
get_field "connected_clients"
;;
blocked_clients)
get_field "blocked_clients"
;;
keyspace_hits)
get_field "keyspace_hits"
;;
keyspace_misses)
get_field "keyspace_misses"
;;
hit_rate)
HITS=$(get_field "keyspace_hits")
MISSES=$(get_field "keyspace_misses")
TOTAL=$((HITS + MISSES))
if [ "$TOTAL" = "0" ]; then
echo "100"
else
echo "scale=2; $HITS * 100 / $TOTAL" | bc
fi
;;
rejected_connections)
get_field "rejected_connections"
;;
evicted_keys)
get_field "evicted_keys"
;;
rdb_last_bgsave_status)
STATUS=$(get_field "rdb_last_bgsave_status")
if [ "$STATUS" = "ok" ]; then echo "1"; else echo "0"; fi
;;
uptime_in_seconds)
get_field "uptime_in_seconds"
;;
*)
echo "Unknown metric: $METRIC"
exit 1
;;
esac赋予执行权限:
bash
chmod +x /usr/local/bin/redis_monitor.sh
# 验证脚本是否正常工作
/usr/local/bin/redis_monitor.sh used_memory
/usr/local/bin/redis_monitor.sh hit_rate
/usr/local/bin/redis_monitor.sh connected_clients
/usr/local/bin/redis_monitor.sh memory_usage_pct 127.0.0.1 6379 yourpassword3.2 Zabbix Agent配置(UserParameter)
在Zabbix Agent配置文件(通常是/etc/zabbix/zabbix_agentd.conf或/etc/zabbix/zabbix_agentd.d/redis.conf)中添加:
ini
# Redis监控UserParameter配置
# 格式:UserParameter=key[*],command $1 $2 $3 $4
UserParameter=redis.metric[*],/usr/local/bin/redis_monitor.sh $1 $2 $3 $4
# 使用示例(在Zabbix Server侧用zabbix_get验证):
# zabbix_get -s 127.0.0.1 -k "redis.metric[used_memory]"
# zabbix_get -s 127.0.0.1 -k "redis.metric[hit_rate]"
# zabbix_get -s 127.0.0.1 -k "redis.metric[memory_usage_pct,127.0.0.1,6379,yourpass]"重启Zabbix Agent:
bash
systemctl restart zabbix-agent
# 验证连通性
zabbix_get -s <agent_ip> -k "redis.metric[connected_clients]"四、告警分级规则
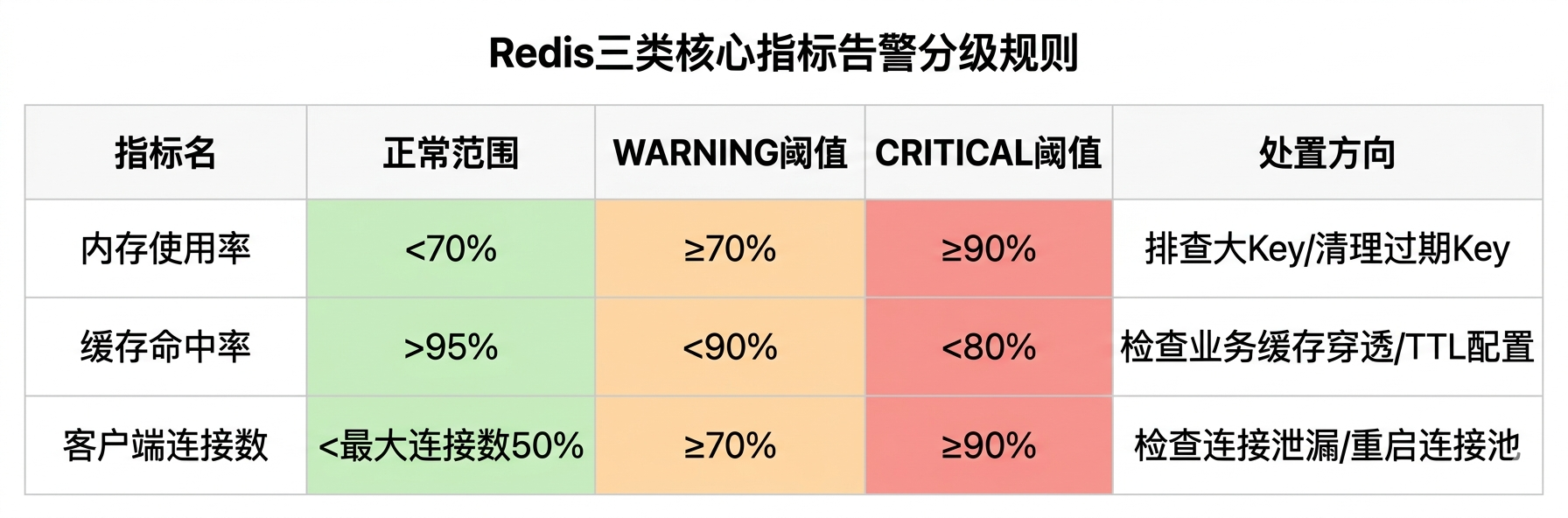
4.1 三类核心指标阈值
| 指标 | 监控Key | 正常范围 | WARNING阈值 | CRITICAL阈值 | 处置方向 |
|---|---|---|---|---|---|
| 内存使用率 | redis.metric[memory_usage_pct] |
<70% | ≥70% | ≥90% | 查大Key / 调maxmemory / 清过期Key |
| 缓存命中率 | redis.metric[hit_rate] |
>95% | <90% | <80% | 查缓存穿透 / TTL配置 / 内存驱逐 |
| 客户端连接数(占比) | redis.metric[connected_clients] |
<最大连接50% | ≥70% | ≥90% | 查连接泄漏 / 重启连接池 |
| 内存碎片率 | redis.metric[mem_fragmentation_ratio] |
1.0~1.5 | >1.5 | >2.0 | 执行MEMORY PURGE或滚动重启 |
| 驱逐Key数增速 | redis.metric[evicted_keys] |
0 | 持续增加 | 快速增加 | 紧急扩内存或降TTL |
| RDB持久化状态 | redis.metric[rdb_last_bgsave_status] |
1(成功) | - | =0(失败) | 检查磁盘空间 / BGSAVE错误日志 |
4.2 Zabbix触发器配置示例
在Zabbix Web界面,为对应监控项配置触发器。以内存使用率为例:
触发器:Redis内存使用率 WARNING
- 名称:
Redis内存使用率超过70%({HOST.NAME}) - 表达式:
last(/Template_Redis/redis.metric[memory_usage_pct])>=70 - 严重性:Warning
触发器:Redis内存使用率 CRITICAL
- 名称:
Redis内存使用率超过90%({HOST.NAME}) - 表达式:
last(/Template_Redis/redis.metric[memory_usage_pct])>=90 - 严重性:High
触发器:Redis命中率下跌告警
- 名称:
Redis缓存命中率低于90%({HOST.NAME}) - 表达式:
last(/Template_Redis/redis.metric[hit_rate])<90 and last(/Template_Redis/redis.metric[hit_rate])>0 - 严重性:Warning
触发器:Redis连接数告警(需先配置maxclients参考值)
- 名称:
Redis客户端连接数超过阈值({HOST.NAME}) - 表达式:
last(/Template_Redis/redis.metric[connected_clients])>500(按实际maxclients设置) - 严重性:Warning
五、Grafana看板配置
5.1 数据源配置
Grafana侧需先添加Zabbix数据源(使用grafana-zabbix插件):
数据源类型:Zabbix
URL:http://your-zabbix-server/zabbix
Username:Admin
Password:yourpassword5.2 关键Panel配置(JSON片段)
内存使用率 Gauge Panel:
json
{
"type": "gauge",
"title": "Redis内存使用率 (%)",
"fieldConfig": {
"defaults": {
"min": 0,
"max": 100,
"unit": "percent",
"thresholds": {
"steps": [
{"color": "green", "value": null},
{"color": "orange", "value": 70},
{"color": "red", "value": 90}
]
}
}
},
"targets": [
{
"application": "Redis",
"item": "redis.metric[memory_usage_pct]",
"host": "$host"
}
]
}命中率趋势 Time Series Panel:
json
{
"type": "timeseries",
"title": "Redis缓存命中率 (%)",
"fieldConfig": {
"defaults": {
"unit": "percent",
"min": 0,
"max": 100,
"thresholds": {
"steps": [
{"color": "red", "value": null},
{"color": "orange", "value": 80},
{"color": "green", "value": 90}
]
},
"custom": {
"thresholdsStyle": {"mode": "line+area"}
}
}
}
}六、常见问题与踩坑记录
6.1 redis-cli连接被拒绝
现象 :脚本执行报Could not connect to Redis at 127.0.0.1:6379: Connection refused
排查步骤:
bash
# 确认Redis进程是否运行
ps aux | grep redis-server
# 确认监听地址(bind配置)
redis-cli CONFIG GET bind
# 如果bind只有127.0.0.1,从其他机器连接会被拒绝
# 确认端口
ss -tlnp | grep 6379注意 :如果Zabbix Agent和Redis不在同一台机器,需要在Redis的redis.conf里调整bind配置,同时配置防火墙规则只允许特定IP访问6379端口,不要对外暴露Redis端口。
6.2 命中率始终为100%或始终为0
原因 :keyspace_hits和keyspace_misses是累计值,Redis重启后归零,重启后短时间内统计会失真。
处理方式 :Zabbix采集命中率时建议用delta类型监控项(记录增量而非绝对值),或在脚本里实现增量计算。对于刚重启的Redis,命中率数据在前5分钟内不具参考价值,告警规则里可增加uptime_in_seconds > 300的前提条件。
6.3 memory_usage_pct返回0,但内存实际已用很多
原因 :maxmemory配置为0(表示不限制),脚本直接返回0。
处理方式:
bash
# 检查maxmemory配置
redis-cli CONFIG GET maxmemory
# 如果返回 "maxmemory" "0",说明未设置上限建议生产环境一定配置maxmemory:
bash
# 临时设置(重启失效)
redis-cli CONFIG SET maxmemory 4gb
# 永久生效:在redis.conf中设置
# maxmemory 4gb
# maxmemory-policy allkeys-lru6.4 evicted_keys持续增加但命中率看起来正常
原因:evicted_keys增加说明内存触顶,Redis在持续驱逐Key。但如果被驱逐的Key恰好是冷数据,短期内命中率不会明显下跌。等热数据也开始被驱逐,命中率才会骤降。
处理方式 :evicted_keys增速是内存问题的早期信号,要在命中率下跌之前就告警处理。我们实际项目里用的是冠服云EMS平台接收Zabbix告警事件,对evicted_keys增速告警自动创建工单并指派DBA处理,比等命中率下跌再响应至少快20分钟。
七、快速验证清单(上线前用)
bash
# 1. 脚本连通性验证
/usr/local/bin/redis_monitor.sh used_memory # 应返回数字(字节数)
/usr/local/bin/redis_monitor.sh hit_rate # 应返回0-100之间的数
/usr/local/bin/redis_monitor.sh memory_usage_pct # 应返回0-100(maxmemory=0时返回0)
/usr/local/bin/redis_monitor.sh connected_clients # 应返回连接数
/usr/local/bin/redis_monitor.sh rdb_last_bgsave_status # 应返回1
# 2. Zabbix Agent验证
zabbix_get -s <agent_ip> -k "redis.metric[used_memory]"
zabbix_get -s <agent_ip> -k "redis.metric[hit_rate]"
zabbix_get -s <agent_ip> -k "redis.metric[connected_clients]"
# 3. 告警触发验证(模拟)
# 临时把Zabbix触发器阈值改低,触发告警,确认通知渠道收到消息
# 验证完成后改回正常阈值
# 4. Grafana看板验证
# 打开看板,确认各Panel有数据,时间范围选"最近1小时"验证实时性
# 5. Redis持久化状态验证
redis-cli LASTSAVE # 查看最后一次RDB时间
redis-cli DEBUG SLEEP 0 # 触发INFO刷新(不影响业务)总结
Redis监控落地的核心卡点不是"哪些指标重要"------大家都知道内存和命中率要看------而是从知道到真正能告警这条链路打通。
三个关键动作:
- Shell脚本做指标计算层:把需要计算的指标(命中率、内存使用率百分比)在采集层算好,Zabbix侧只做阈值判断
- 分级告警要分开配:WARNING和CRITICAL对应不同处置响应,不要把所有告警都设成高优先级
- evicted_keys是早期信号:比命中率下跌至少早20分钟,要优先告警
附录速查表也可以直接打印贴在值班室墙上:
| 指标 | WARNING | CRITICAL | 第一步处置 |
|---|---|---|---|
| 内存使用率 | 70% | 90% | redis-cli --bigkeys 找大Key |
| 命中率 | <90% | <80% | 查evicted_keys增速 |
| 连接数占比 | 70% | 90% | 查应用侧连接池配置 |
| 内存碎片率 | 1.5 | 2.0 | MEMORY PURGE |
| evicted_keys | 持续增加 | 快速增加 | 立即扩maxmemory |
觉得有用的话点个赞/收藏,这类配置细节手边能查到比看文档快多了。
往期文章:
MySQL慢查询监控:https://blog.csdn.net/weixin_70758133/article/details/161278856?spm=1011.2415.3001.5331
多源告警统一接入:https://blog.csdn.net/weixin_70758133/article/details/161214549?spm=1011.2415.3001.5331
Zabbix vs Prometheus选型:https://blog.csdn.net/weixin_70758133/article/details/160626929?spm=1011.2415.3001.5331