起因
有一个PDF文件《美文晨读》,里面有文字和拼音,俺想把内容整理出来。

得到每个汉字和对应的拼音,形成新的文档。
结果
解析了PDF的汉字和拼音,生成了HTML

<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">qiū</span><span class="hanzi" style="cursor: pointer;">秋</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">fēng</span><span class="hanzi" style="cursor: pointer;">风</span></span>
html
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">qiū</span><span class="hanzi" style="cursor: pointer;">秋</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">fēng</span><span class="hanzi" style="cursor: pointer;">风</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">jiàn</span><span class="hanzi" style="cursor: pointer;">渐</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">jiàn</span><span class="hanzi" style="cursor: pointer;">渐</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">liáng</span><span class="hanzi" style="cursor: pointer;">凉</span></span>
<span class="char-group" style="cursor: pointer;"><span class="pinyin" style="cursor: pointer;">le</span><span class="hanzi" style="cursor: pointer;">了</span></span>
分析
这个PDF 是Searchable PDF,所以可以直接选择文本进行复制。似乎 好像很容易的 可以把文字和拼音整理出来:
nǐ 冷 lěng 吗 ma ?让 ràng 我 wǒ 捧 pěng 起 qǐ 你 nǐ 的 de 小 xiǎo 手 shǒu ,为 wéi 你 nǐ 呵 hē 出 chū 一 yì 些 xiē 暖 nuǎn
但是尝试了几个文本之后发现,经常有 文字和拼音的错位。所以直接解析文本的方式问题很多。于是就分析PDF的文字区域。
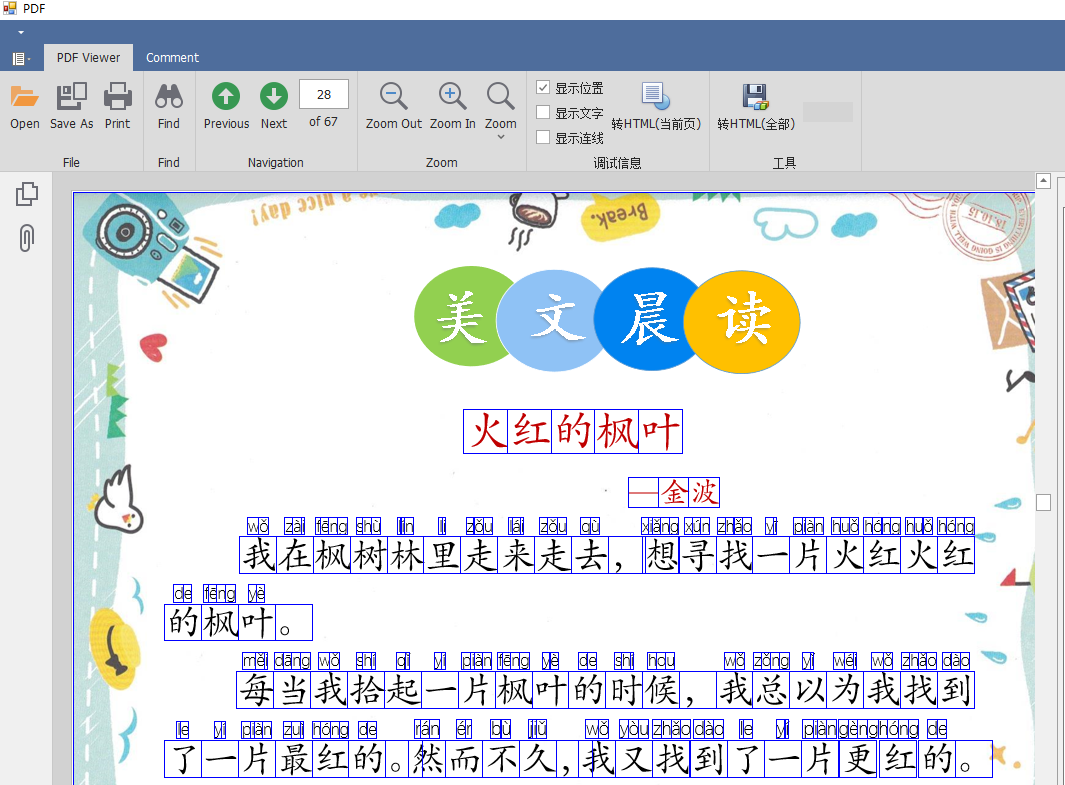
然后根据 根据位置 确定每个字和拼音之间的关系,如图所示:
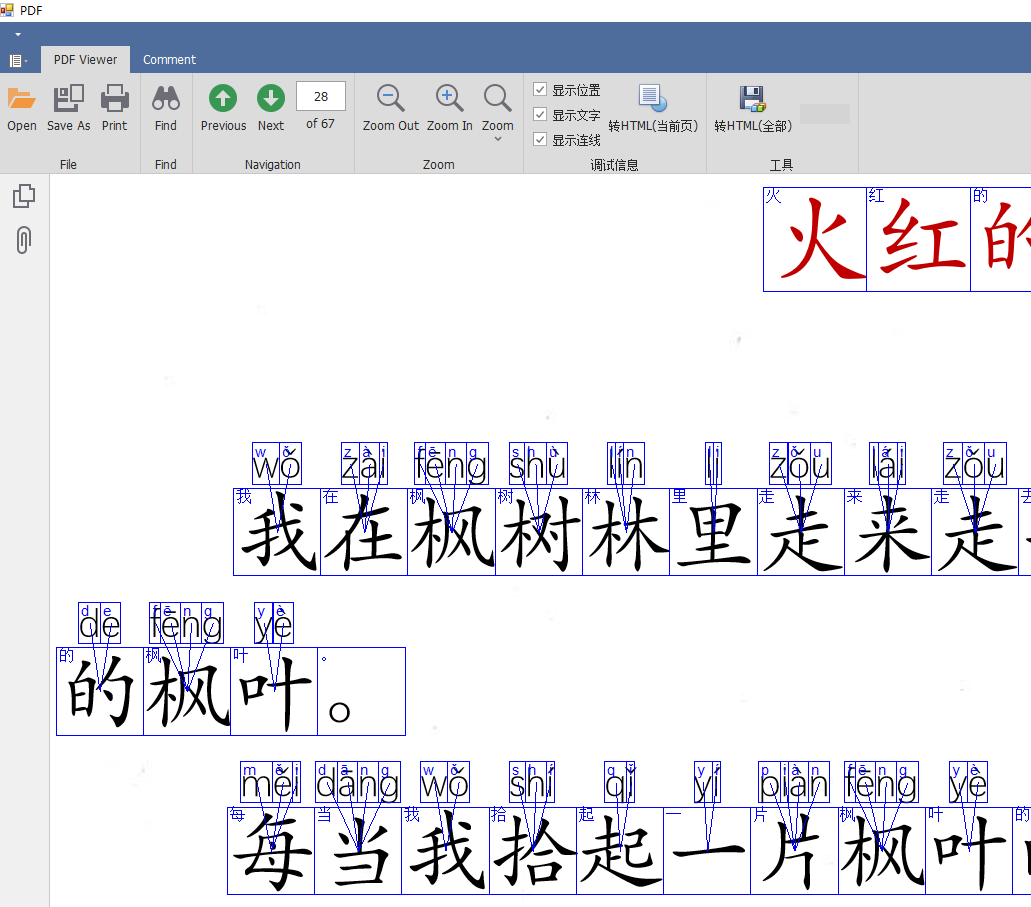
然后就得到了数据。
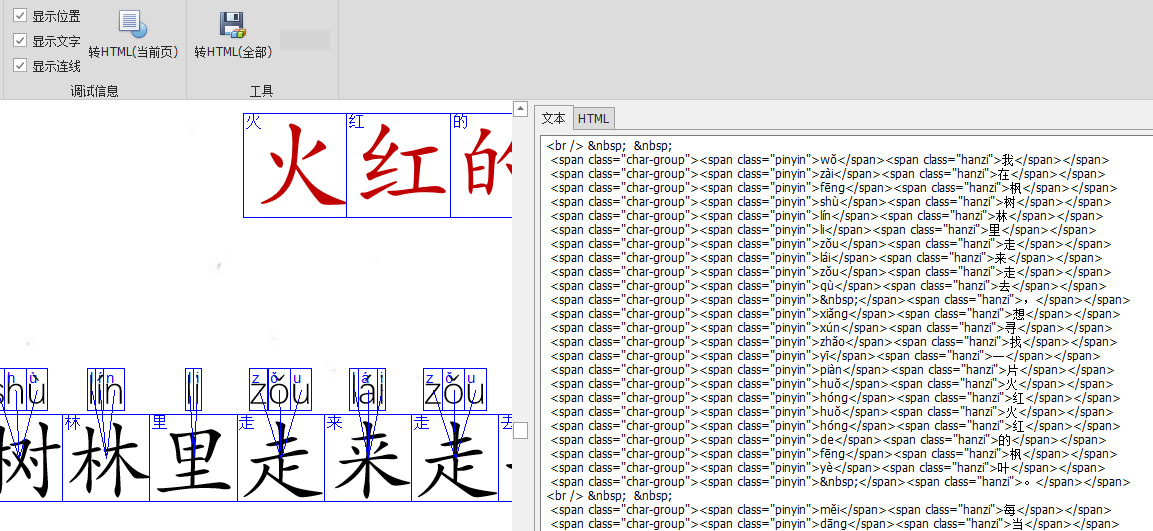
动手
启动Microsoft Visual Studio。
控件使用 DevExpress.XtraPdfViewer.PdfViewer。
然后左手右手一个慢动作 ,搞定。
代码分析见下一篇文章。
核心代码
使用LinesMgr 对PDF的每一页的元素 ,进行分行。再根据每行的内容判断是"拼音"?还是"汉字"行?然后再把每一行的拼音,对应到下方的汉字上。对应时, 使用就近原则。对应到距离最近的汉字上。代码实现:
for (int i = 0; i < lm.Lines.Count; i++)
{
Line line = lm.Linesi;
if (line.item_w_AVG < lm.line_item_w_AVG)
{
if (i < lm.Lines.Count - 1)
{
Line line2 = lm.Linesi + 1;
if ((line2.Rect.Top + line2.Rect.Height) > (line.Rect.Top - line2.Rect.Height))
{
foreach (PDFWord w2 in line2.Words)
{
w2.PinYin = "";
w2.PinYinWord.Clear();
}
foreach (PDFWord w in line.Words)
{
float d_min = 0;
float i_min = -1;
float x = w.TextRect.Rect.X + w.TextRect.Rect.Width / 2;
float y = w.TextRect.Rect.Y - w.TextRect.Rect.Height / 2;
PDFWord w_txt = null;
foreach (PDFWord w2 in line2.Words)
{
float x2 = w2.TextRect.Rect.X + w2.TextRect.Rect.Width / 2;
float y2 = w2.TextRect.Rect.Y - w2.TextRect.Rect.Height / 2;
float d = (x2 - x) * (x2 - x) + (y2 - y) * (y2 - y);
if (w_txt == null)
{
d_min = d;
w_txt = w2;
}
else if (d < d_min)
{
d_min = d;
w_txt = w2;
}
}
if (w_txt != null)
{
w_txt.PinYin = w_txt.PinYin + w.Text;
w_txt.PinYinWord.Add(w);
}
}
}
}
}
else
{
if (line.Rect.Left > lm.line_x_MIN + lm.line_item_w_AVG)
sb.AppendLine(@"<br /> ");
foreach (PDFWord w2 in line.Words)
{
if (w2.PinYin == "")
sb.AppendLine(@" <span class=""char-group""><span class=""pinyin""> </span><span class=""hanzi"">" + w2.Text + @"</span></span>");
else
sb.AppendLine(@" <span class=""char-group""><span class=""pinyin"">" + w2.PinYin + @"</span><span class=""hanzi"">" + w2.Text + @"</span></span>");
}
}
}
cs
public class LinesMgr
{
public List<Line> Lines = new List<Line>();
public void add(PDFWord word)
{
Line line = find(word.TextRect.Rect);
if (line == null)
{
line = new Line();
Lines.Add(line);
}
line.add(word);
}
public Line find(RectangleF Rect) //最下边是 y=0;
{
int y = (int)(Rect.Y - Rect.Height / 2);
foreach (Line line in Lines)
{
if (y > line.Rect.Y)
continue;
if (y < line.Rect.Y- line.Rect.Height)
continue;
return line;
}
return null;
}
public float line_item_w_AVG = 0;
public float line_x_MIN = 0;
public void sort_sum()
{
if (Lines.Count <= 0)
return;
line_x_MIN = Lines[0].Rect.Left;
foreach (Line line in Lines)
{
line.sort_sum();
if (line.Rect.Left < line_x_MIN)
line_x_MIN = line.Rect.Left;
}
Lines = Lines.OrderBy(line => -line.Rect.Top).ToList();
var validWidths = Lines
.Select(line => line.item_w_AVG)
.ToList();
line_item_w_AVG = validWidths.Sum() / validWidths.Count;
}
public string get_text()
{
StringBuilder sb = new StringBuilder();
foreach (Line line in Lines)
{
sb.AppendLine(line.get_text());
}
return sb.ToString();
}
}
public class Line
{
public List<PDFWord> Words = new List<PDFWord>();
public RectangleF Rect;
public float item_w_AVG = 0;
public void add(PDFWord word)
{
if (Words.Count == 0)
{
Words.Add(word);
Rect = word.TextRect.Rect;
}
else
{
Words.Add(word); //最下边是 y=0;
RectangleF r = word.TextRect.Rect;
float left = Math.Min(r.Left, Rect.Left);
float top = Math.Min(r.Top, Rect.Top);
float right = Math.Max(r.Right, Rect.Right);
float bottom = Math.Max(r.Bottom, Rect.Bottom);
Rect = new RectangleF(left, top, right - left, bottom - top);
}
}
public string get_text()
{
StringBuilder sb = new StringBuilder();
foreach (PDFWord word in Words)
{
sb.Append(word.Text);
}
return sb.ToString();
}
public void sort_sum()
{
Words = Words.OrderBy(word => word.TextRect.Rect.Left).ToList();
var validWidths = Words
.Where(word => word != null && word.TextRect != null)
.Select(word => word.TextRect.Rect.Width)
.ToList();
item_w_AVG = validWidths.Sum() / validWidths.Count;
}
}