前言
前面学习了 什么是 RAG 评估 以及相关指标。在相关 Demo 中也看到有些指标比较低,那么实际开发中该怎么去提升这些指标呢?
经验性指标值
指标的理想值并非一成不变,需结合业务场景的风险和需求来设定。
| 指标 | 通用阈值/目标 | 应用场景与具体要求 |
|---|---|---|
| Context Precision | ≥ 0.7 通常是好的起点。高风险场景要求更高。 | 客服/电商/咨询 (效率与体验) |
| Context Recall | ≥ 0.7-0.8 是常见目标。知识密集型场景要求更高。若允许部分信息缺失,可降至 0.6。 | 医疗/法律 (高风险) : 要求 ≥ 0.9,对信息遗漏的容忍度极低;通用问答/内容生成 (平衡型) : 要求 ≥ 0.7。 |
| Faithfulness | ≥ 0.85 是行业普遍追求的目标。低于 0.7 可能存在严重幻觉。 | 医疗/法律 (高风险) : 要求 ≥ 0.9。任何事实错误或信息遗漏都可能导致严重后果。 |
| Answer Relevancy | ≥ 0.8 保证较好的用户体验,低于 0.6 用户可能难以接受。开放域问答 ≥ 0.7 也可接受。 | 客服/电商/咨询 (效率与体验) : 要求 ≥ 0.8。回答需直接解决问题,避免冗余信息干扰用户; 通用问答/内容生成 (平衡型) : 要求 ≥ 0.7。关注在开放域中保持答案相关性和信息覆盖面的平衡。 |
chunk_size 优化
角色
文档分块是 RAG 工程的第一步,这一步的 chunk_size 是一个相对简单,但容易被忽视的基础参数问题。
- 核心问题:
- chunk_size 越小,产生的知识块越多、粒度越小。尽管知识块越小,语义越精确,但是风险是携带的上下文越少 ,可能导致单块信息不完整(上下文碎片化 ),进而无法支撑生成答案,影响答案相关性(特别是当 top_K 比较小时)。
- chunk_size 越大,携带的上下文越完整,但块内可能包含大量与查询无关的噪声信息,虽然召回关键信息的概率高,但会稀释向量表示的焦点,降低检索精度 ,并增加后续 token 成本。
经验值
换句话说,在RAG流水线中,chunk_size直接决定了存入向量数据库的知识颗粒度。所以,首先可以通过优化 chunk_size 来提高 Context Precision 和 Answer Relevancy。那么该怎么选择合适的 chunk_size 呢?
| 典型取值/区间 | 适用场景与考量 | 分块逻辑与原因 |
|---|---|---|
| 128 - 512 tokens (常见区间) | 通用场景的基准选择。 | 在上下文完整性 和检索效率之间寻求平衡。较小的块(如128)可提升精准度,512 tokens是广泛采用的基准。 |
| 512 tokens (重叠256) | 长上下文、复杂问答场景。 (参考:Databricks 实验) | 固定大小分块配合重叠策略,可缓解边界效应,在长文档中捕获更完整的语义关联。 |
| 1024 tokens | 需要大量上下文的复杂分析任务。 (参考:LlamaIndex 测试) | 在响应时间 与回答质量(忠实度、相关性)间取得最佳平衡,为模型提供更丰富的推理依据。 |
| 200 - 300 tokens | 技术文档、学术论文等专业性强、逻辑紧密的文档。 | 确保专业术语 和逻辑结构的完整性。分块过大会导致关键术语被稀释,影响检索准确性。 |
| 500 - 1000 tokens | 长叙事文本(如小说、报告)。 | 减少分块数量,以保留完整的情节、论证或叙述流程,避免因碎片化破坏核心信息的连贯性。 |
| 100 - 200 tokens | 社交媒体帖子、即时消息等碎片化短文本。 | 适配内容本身长度较短、信息密度高的特点,避免将多个不相关主题强行合并到同一个块中。 |
实践
分块
ini
chunk_size = 512
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=int(chunk_size * 0.20),
)
split_docs = text_splitter.split_documents(docs)
print("分块个数:", len(split_docs))FAISS
FAISS 是一个专注于底层相似性搜索计算的高性能库。
- 核心:近似最近邻搜索算法
- 目标:在十亿级别向量中实现毫秒级响应
而我们之前常用的 Chroma 则是一个面向应用层、提供完整数据管理能力 的向量数据库。FAISS 关注极致性能,Chroma 则小而全。这里核心只用到了检索功能本身,所以选择了 FAISS。
基础用法:
- 准备工作
ini
index_folder_path = "../data/faiss_index"
# index_name = "c_default_"+str(chunk_size)
index_name = f"rag_index_c{chunk_size}"
index_file_path = os.path.join(index_folder_path, - 基本使用:加载向量数据库
python
# 检查索引文件是否存在
if os.path.exists(index_file_path):
print("索引文件已存在,直接加载...")
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name, allow_dangerous_deserialization=True)
else:
print("索引文件不存在,创建并保存索引...")
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
# 保存索引
vectordb.save_local(index_folder_path, index_name)
print("向量化完成....")QAEvaluator
QAEvaluator 是一个质检员,主要有两个核心作用:
- 和 LLM 交互生成 answers
- 执行 "质检",得出评估结果
初始化
ini
def __init__(self, retriever):
# 创建文档链
document_chain = create_stuff_documents_chain(llm, prompt_template)
# 创建检索链
self.chain = create_retrieval_chain(retriever,document_chain)
self.retriever = retriever答案生成
python
def generate_answers(self, questions):
answers = []
contexts = []
for question in questions:
print("问题:", question)
response = self.chain.invoke({"input": question})
print("大模型答复:", response["answer"], "\n")
answers.append(response["answer"])
# 获取上下文
contexts.append([doc.page_content for doc in response["context"]])
print("大模型回答时参考的上下文:", contexts, "\n")
print("=="*35)
return answers, contextsRAGAs 评估
ini
def evaluate(self, questions, answers, contexts, ground_truths):
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_result = evaluate(
evaluate_dataset,
llm=vllm,
embeddings=vllm_e,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
return evaluate_result简单封装
scss
def exec_eval(retriever):
qa_evaluator = QAEvaluator(retriever)
answers, contexts = qa_evaluator.generate_answers(questions)
return qa_evaluator.evaluate(questions, answers, contexts, ground_truths)F1分数计算
python
def calc_f1(evaluate_result):
context_precisions = evaluate_result["context_precision"]
context_recalls = evaluate_result["context_recall"]
print("context_precisions=",context_precisions)
print("context_recalls=",context_recalls)
context_precision_score = sum(context_precisions) / len(context_precisions)
context_recall_score = sum(context_recalls) / len(context_recalls)
f1_score = (2 * context_precision_score * context_recall_score) / (context_precision_score + context_recall_score)
return round(f1_score,4)Run
我们以 512 为基准,然后尝试在 512 附近修改参数来比较 RAGAs 结果。
ini
# 修改 chunk_size,分别运行比较 RAGAs 结果
chunk_size = 512
# chunk_size = 1024
# chunk_size = 256
# chunk_size = 128评估类封装
我们发现前面代码需要不断修改 chunk_size 重新运行代码来看结果比对,而且代码也比较分散。我们按工程化的思想将上述代码封装一下,同时在后续实验中能够运行一次,产出批量对比结果。
我们采取 "配置即实验 " 的设计思想,通过chunk_size, bm25_weight, use_rerank等少数几个"旋钮",把RAG链路中最影响效果的几个可变环节进行封装,使得系统比对变得非常高效。
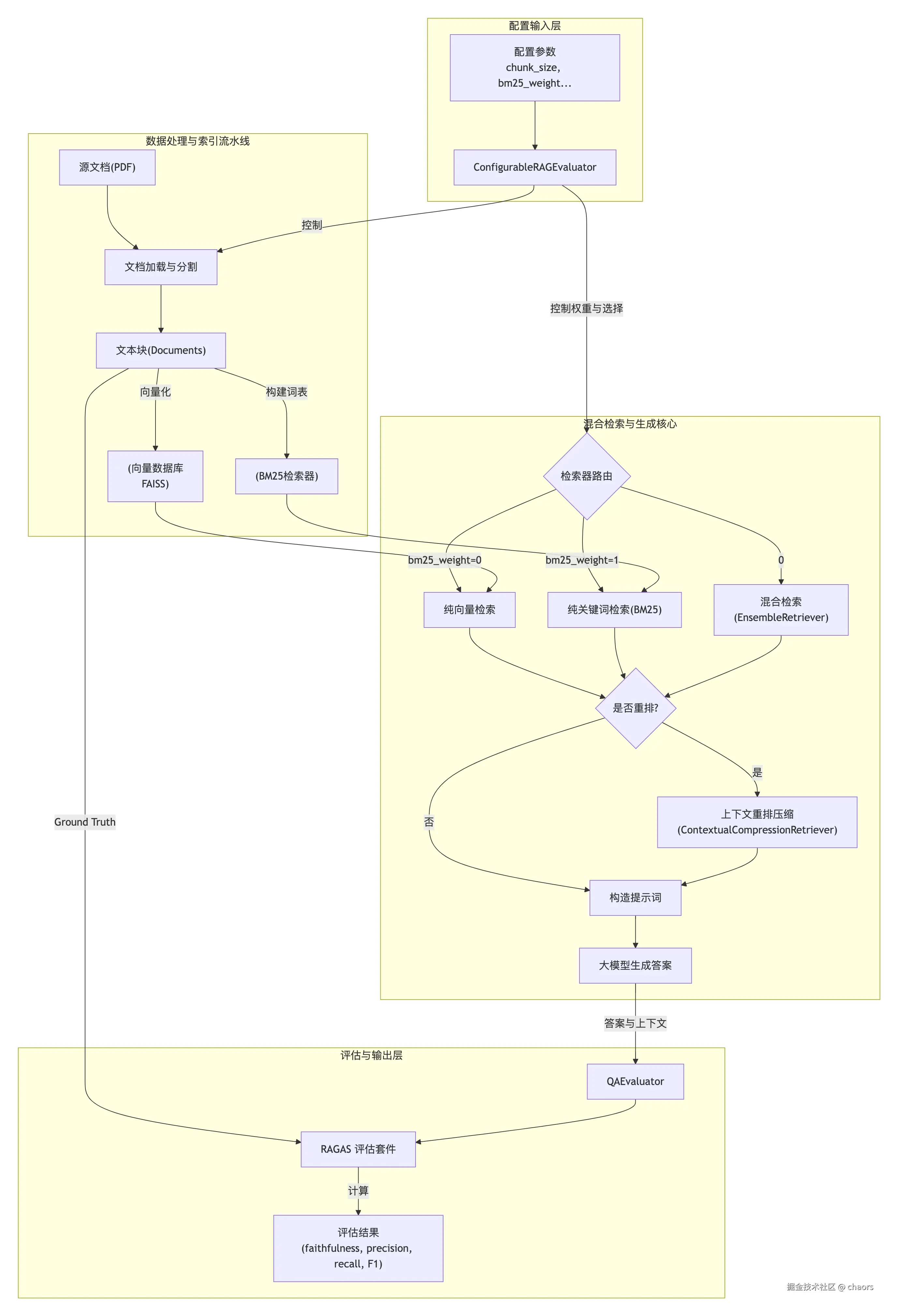
QAEvaluator
首先是 QAEvaluator,本着 "单一职责" 的设计原则,他本身只负责评估答案的生成。
python
class QAEvaluator:
def __init__(self, retrieval_chain):
self.chain = retrieval_chain
def generate_answers(self, questions: List[str]):
"""对问题列表生成答案,并收集使用的上下文"""
answers = []
contexts = []
for i, q in enumerate(questions, 1):
print(f"\n问题 {i}/{len(questions)}: {q}")
response = self.chain.invoke({"input": q})
answers.append(response["answer"])
contexts.append([doc.page_content for doc in response["context"]])
print(f"答案: {response['answer'][:150]}...") # 预览前150字符
return answers, contextsConfigurableRAGEvaluator
ConfigurableRAGEvaluator 是一个高度可配置的RAG系统评估器。
类级别默认值
ini
DEFAULT_CHUNK_SIZE = 512
DEFAULT_BM25_WEIGHT = 0.0
DEFAULT_USE_RERANK = False初始化
参数验证
css
if not 0 <= bm25_weight <= 1:
raise ValueError("bm25_weight 必须在 [0.0, 1.0] 区间内")
if chunk_size <= 0:
raise ValueError("chunk_size 必须为正整数")
if chunk_overlap_ratio < 0 or chunk_overlap_ratio >= 1:
raise ValueError("chunk_overlap_ratio 必须在 [0, 1) 区间内")核心配置
ini
self.pdf_path = pdf_path
self.llm = llm_client or get_ali_model_client(temperature=0)
self.embeddings = embeddings_model or get_ali_embeddings()
self.chunk_size = chunk_size
self.chunk_overlap = int(chunk_size * chunk_overlap_ratio)
self.bm25_weight = bm25_weight
self.use_rerank = use_rerank
self.rerank_top_n = rerank_top_n
self.vector_top_k = vector_top_k
self.index_folder = index_folder
self.index_name = f"rag_index_c{chunk_size}_b{int(bm25_weight*100)}"内部状态和组件
python
# 内部状态
self._vectorstore: Optional[FAISS] = None
self._retriever: Optional[BaseRetriever] = None
self._evaluator: Optional['QAEvaluator'] = None
self._split_docs = None
# 初始化核心组件
self._text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
)
self._prompt_template = self._create_prompt_template()提示词模板
python
def _create_prompt_template(self):
system_prompt = """
您是问答任务的助理。使用以下的上下文来回答问题,
上下文:<{context}>
如果你不知道答案,不要其他渠道去获得答案,就说你不知道。
"""
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
])文档加载和分割
python
def _load_and_split_documents(self):
print(f"[步骤1] 加载文档: {self.pdf_path}")
loader = PyPDFLoader(self.pdf_path)
raw_docs = loader.load()
print(f" 原始文档数: {len(raw_docs)}")
print(f"[步骤2] 分割文本 (chunk_size={self.chunk_size}, overlap={self.chunk_overlap})")
self._split_docs = self._text_splitter.split_documents(raw_docs)
print(f" 分块后文档数: {len(self._split_docs)}")
return self._split_docs向量存储
python
def _create_vector_store(self, force_rebuild=False):
"""创建或加载FAISS向量存储"""
index_file_path = os.path.join(self.index_folder, f"{self.index_name}.faiss")
if not force_rebuild and os.path.exists(index_file_path):
print(f"[步骤3] 加载现有向量索引: {self.index_name}")
self._vectorstore = FAISS.load_local(
self.index_folder,
self.embeddings,
self.index_name,
allow_dangerous_deserialization=True
)
else:
print(f"[步骤3] 创建新向量索引: {self.index_name}")
if self._split_docs is None:
self._load_and_split_documents()
self._vectorstore = FAISS.from_documents(self._split_docs, self.embeddings)
self._vectorstore.save_local(self.index_folder, self.index_name)
print(" 向量化完成并已保存")
return self._vectorstore检索器
这里会根据 bm25_weight 参数来决定返回的检索器,默认纯向量检索器。
python
def _create_retriever(self):
"""
根据配置创建检索器(纯向量、纯BM25或混合)
"""
if self._vectorstore is None:
self._create_vector_store()
# 1. 向量检索器
vector_retriever = self._vectorstore.as_retriever(
search_kwargs={"k": self.vector_top_k}
)
# 2. 纯向量检索
if self.bm25_weight == 0.0:
print(f"[步骤4] 使用纯向量检索 (top_k={self.vector_top_k})")
self._retriever = vector_retriever
return self._retriever
# 3. 准备BM25检索器
if self._split_docs is None:
self._load_and_split_documents()
bm25_retriever = BM25Retriever.from_documents(self._split_docs)
bm25_retriever.k = self.vector_top_k
# 4. 纯BM25检索
if self.bm25_weight == 1.0:
print(f"[步骤4] 使用纯BM25检索 (top_k={self.vector_top_k})")
self._retriever = bm25_retriever
return self._retriever
# 5. 混合检索
print(f"[步骤4] 使用混合检索 (向量权重={1 - self.bm25_weight:.2f}, BM25权重={self.bm25_weight:.2f})")
self._retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[1 - self.bm25_weight, self.bm25_weight]
)
return self._retrieverChain
python
def _create_rerank_chain(self, retriever):
"""在检索链中加入重排模型"""
if not self.use_rerank:
return create_retrieval_chain(retriever, self._create_document_chain())
print(f"[步骤5] 启用结果重排 (top_n={self.rerank_top_n})")
# 使用您提供的函数
reranker = get_ali_rerank(top_n=self.rerank_top_n)
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=retriever
)
return create_retrieval_chain(compression_retriever, self._create_document_chain())文档创建
python
def _create_document_chain(self):
"""创建文档问答链"""
return create_stuff_documents_chain(self.llm, self._prompt_template)初始化
python
def initialize(self):
"""初始化评估器,创建所有必要的组件"""
self._create_retriever()
final_chain = self._create_rerank_chain(self._retriever)
self._evaluator = QAEvaluator(final_chain)
print("[系统] 评估器初始化完成。")
return self运行评估
这里着重看一下整体输出的设计,这样我们在每次结果不仅能看到评估结果,还能看到档次评估的一些基础信息。
- config:配置
- questions:问题
- answers:答案
- contexts:检索到的上下文
- ragas_metrics:ragas 评估结果
- f1_score:F1 分数
python
def run(
self,
questions: List[str],
ground_truths: List[str],
verbose: bool = True
) -> Dict[str, Any]:
"""
执行完整的RAG评估流程。
返回包含答案、上下文和评估结果的字典。
"""
if self._evaluator is None:
self.initialize()
print(f"\n{'=' * 60}")
print(f"开始评估 [chunk_size={self.chunk_size}, bm25_weight={self.bm25_weight}, rerank={self.use_rerank}]")
print(f"{'=' * 60}")
# 生成答案
answers, contexts = self._evaluator.generate_answers(questions)
# RAGAS评估
evaluate_dataset = Dataset.from_dict({
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
})
vllm = LangchainLLMWrapper(self.llm)
vllm_e = LangchainEmbeddingsWrapper(self.embeddings)
evaluation_result = evaluate(
evaluate_dataset,
llm=vllm,
embeddings=vllm_e,
metrics=[faithfulness, answer_relevancy, context_recall, context_precision],
)
# 计算F1分数
f1_score = self._calc_f1_score(evaluation_result)
result_summary = {
"config": {
"chunk_size": self.chunk_size,
"bm25_weight": self.bm25_weight,
"use_rerank": self.use_rerank,
"vector_top_k": self.vector_top_k,
},
"questions": questions,
"answers": answers,
"contexts": contexts,
"ragas_metrics": dict(evaluation_result),
"f1_score": f1_score,
}
if verbose:
print(f"\n评估结果: {dict(evaluation_result)}")
print(f"综合F1分数: {f1_score:.4f}")
print(f"{'=' * 60}")
return result_summarychunk_size 示例
以上面的 chunk_size 为例,如果使用 ConfigurableRAGEvaluator,则代码为:
css
configs = [ {"chunk_size": 512}, {"chunk_size": 1024}, {"chunk_size": 256}, {"chunk_size": 128}]
all_results = []
for config in configs:
chunk_size = config.get("chunk_size")
print(f"------------ chunk_size = {chunk_size} ------------")
evaluator = ConfigurableRAGEvaluator(
pdf_path="../data/领克汽车使用手册.pdf",
**config
)
result = evaluator.run(
questions=questions,
ground_truths=ground_truths,
)
evaluator.format_evaluation_result(show_details=False)
all_results.append(result)如果要优中选优,chunk_size=1024 的指标组表现最优。F1 分数最高,说明上下文质量综合最优,在信息完整性(Recall)和纯净度(Precision)之间达到最佳平衡,
| chunk_size | faithfulness | answer_relevancy | context_recall | context_precision | f1分数 |
|---|---|---|---|---|---|
| 128 | 0.8807 | 0.6593 | 0.8889 | 0.1111 | 0.1975 |
| 256 | 0.7756 | 0.7117 | 0.5833 | 0.5208 | 0.5503 |
| 512 | 0.8889 | 0.7003 | 0.9167 | 0.6167 | 0.7373 |
| 1024 | 0.8746 | 0.7024 | 0.9167 | 0.6587 | 0.7666 |
其他优化方式
ini
# 批量实验不同配置
configs = [
{"chunk_size": 1024, "bm25_weight":0.5}, # 混合检索
{"chunk_size": 1024, "use_compress":True}, # 压缩上下文
{"chunk_size": 1024, "bm25_weight":0.5, "use_compress":True}, # 混合检索 + 压缩上下文
{"chunk_size": 1024, "use_rerank":True}, # 检索结果重排
]除了 chunk_size,我们还可以使用前面讲过的Hybird_search、rerank、上下文压缩等。
总结
其实在实际项目中优化 RAG 指标的思路就是,先有一个基准,然后基于此不断尝试周围的指标变化。同时结合前面 AdvancedRAG 优化方式来不断提高RAG 指标。核心是检索和生成调优,以及过程中的相关参数调优。