开始上难度了朋友,这篇老师给了三天时间,本来我以为是四天时间,留到了现在,开始框框赶进度,这习惯确实不好,也没人来帮忙一起写作业 😂;现在才写了一半太难受了~~~
初级分词技术
- 把连续不断的文本"敲碎",变成一块块有意义 的"积木":这个过程就是分词(Tokenization)
- 分词任务的质量,将决定上层建筑(如信息检索、机器翻译、情感 分析等)的稳固程度。
jieba
作为一个经 典、简单、代码开源的中文分词库,仍是理解传统分词思想、学习NLP基础工程实践的重 要工具;
基于规则与词典
基于一个前缀词典(Trie树),高效地构建出一个包含句子中所有可能词语组合的有向无环图(DAG)。接着动态规划算法寻找一条概率最大的路径,作为最终分词结果;
假设一个分词路径由一个词语序列组成,将 其表示为 w1 , w2 , . . . , wn,其中 wi 代表序列中的第 i 个词。那么这条路径的概率可以近似为:

Log概率与动态规划
将大量小于 1 的概率值直接相乘,很容易导致结果趋近于 0,造成浮点数下 溢,无法比较路径优劣,为此jieba 采用了对数概率技术,利用对数函数 log 的性质 ,将概率的累乘转换为 log 概率的累加。寻找概率最大值就等价于寻找 log 概率之和的最大值;
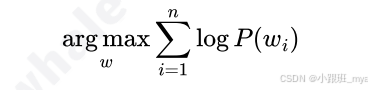
还引入了动态规划思想。它会从句子的末尾开始,从后向前递推计算到每个位置的最优切分路径及其 log 概率之和,并记录下来:
- 从句子开头出发,根据记录好的最优路径信息,就能反推出整个句子的最优分词结果
Jieba实践
基于词典找最优路径(经常出现的比较稳定),新的词容易被拆成更小的片段
通过自定义词典把新词加入词表
自定义字典 user_dict.txt :
九头虫
奔波儿灞
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 未加载词典前的错误分词
text = "九头虫让奔波儿灞把唐僧师徒除掉"
print(f"精准模式: {jieba.lcut(text, cut_all=False)}")
# 加载自定义词典
jieba.load_userdict("./user_dict.txt")
print(f"加载词典后: {jieba.lcut(text, cut_all=False)}")
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
精准模式: ['九头', '虫', '让', '奔波', '儿', '灞', '把', '唐僧', '师徒', '除掉']
加载词典后: ['九头虫', '让', '奔波儿灞', '把', '唐僧', '师徒', '除掉']
未登录词(OOV, Out-Of-Vocabulary)是一个"相对概念"------相对某个词典/词表未被收录的词。
对词典法来说:词典里没有,典型表现是本该作为一个整体的词因未被收录而被错误地切碎成单字或无关的片段。精确模式工作流程
将分词问题转化为了一个**"图论中的最短路径问题"**(或者说是最大概率路径)
(1)文本预处理与分块 ( cut 方法)
- cut 函数作为总调度用正则表达式 re_han_default 将整个句子切分成连续的汉字区块和非汉字部分(直接输出)
(2)构建有向无环图 ( get_DAG 方法)
- 扫描句子,要找出所有可能的走法,看每个字能组成哪些词
- 我在梦里收到清华大学录取通知书
- 从"我"(第 0 字)开始,查词典发现能组成"我"(到第 1 字结束)
- 当扫描到"清"(第 6 字)时,查词典发现能组成"清"、"清华"、"清华大学"等
以此类推
- 当扫描到"清"(第 6 字)时,查词典发现能组成"清"、"清华"、"清华大学"等
- 从"我"(第 0 字)开始,查词典发现能组成"我"(到第 1 字结束)
字和字之间就建立起了各种连接(边),我们只能从前向后走,不会回头,也不会绕圈子,所以这张由字(节点)和词(边)构成的网络图,就被称为有向无环图;
(3)计算最优路径 ( calc 方法)
calc 方法采用动态规划的思想,它从句子的末尾向前反向计算,算法会计算每个候选词的路径"分数"(由当前词的 log 概率与该词之后剩余句子的最优 log 概率相加而成),并将从每个位置出发的总分最高词语及其结束位置记录在 route 表中
(4)从路由表中重建结果 ( __cut_DAG_NO_HMM 方法)
根据计算好的路线输出结果,__cut_DAG_NO_HMM 方法根据 route 表中记录的"路标"进行路径回溯:
- 从起点"我"开始,最佳路标指向下一个位置,因此切分出 '我' 。随着处理的推进,当遍历到"清"字时,最佳路标指示直接跳过 4 个字(因为"清华大学"作为整体的概率更高),于是切分出 '清华大学' 。最终,系统结合所有切分结果,输出'我', '在', '梦里', '收到', '清华大学', '录取', '通知书';
统计学习时代的方法
把分词看作一个序列标注问题,即为句子中的每个字打上一个位置标签!
- 我们可以用 B (Begin) 表示词的开始, M (Middle) 表示词的中间, E (End) 表示词的结束, S (Single) 表示单字成词。在这种当扫描到"清"(第 6 字)时,查词典发现能组成"清"、"清华"、"清华大学"等。 在标注体系下,"我爱北京"会被标注为 S S B E
HMM对未登录词的识别
-
它学习到字与标签之间的对应关系(发射概率)以及标签与标签之间的转移关系(转移概率)
-
来识别词典中不存在的 OOV
-
当基于词典的图算法在句子中遇到无法切分的、连续的未登录字串时,就会调用 HMM 模块对该局部子句进行二次分词! 发现词典外的新词
默认开启的__cut_DAG 方法采用了**"**单字缓冲,二次加工 **"**的混合策略 -
遍历动态规划生成的路径 时,不会立即输出结果,而是设置一个缓冲区
- 路径上的单字,都先扔进缓冲区攒着;一旦遇到多字词或句子结束,就说明一段由单字组成的"未登录区域"结束了
用统计规律把这些被切碎的字重新"粘"回成词。
- 路径上的单字,都先扔进缓冲区攒着;一旦遇到多字词或句子结束,就说明一段由单字组成的"未登录区域"结束了

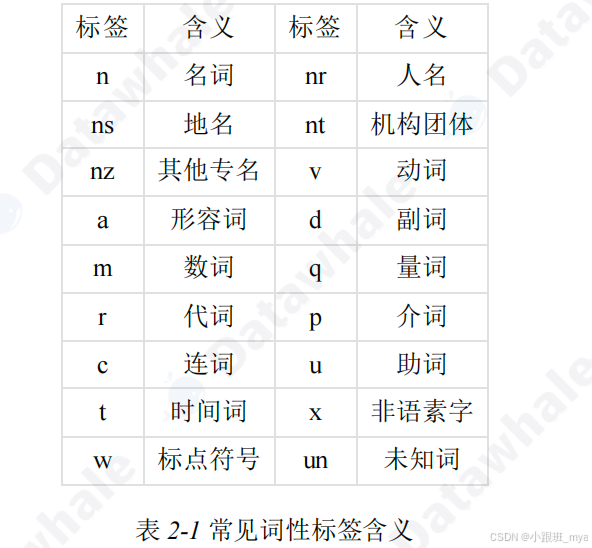
词性标注
- 词典查询与隐马尔可夫模型相结合的混 合策略,来识别出每个词语的语法属性(名词、动词、形容词等)
- jieba.posseg 模块
从**"分词"到"分块"**
现代 NLP 模型更倾向于采用**"无分词"或"弱分词"**的 策略,将文本处理成更基础的、数据驱动的单元,主要分为字粒度和子词粒度两种流派;
(1)字粒度分词
- 以 BERT 模型为代表,在处理中文时分词策略是字粒度,直接将每个汉字视为一个独立的 Token
- 因为常用汉字的数量是有限的,模型可以轻松构建一个全覆盖的"字表",摆脱对庞大词典的依赖
- 词汇语义的丢失,消耗更多资源去重新学习它们之间的组合关系;字的序列长度会显著增加,这加大了模型的计算负担。
(2)子词分词
- GPT采用更灵活的子词(Subword )切分方案,最主流的算法是 BPE(BytePair Encoding)
- 在原始语料上迭代合并高频相邻字节对(或字符对)成一个新的、更大的单元,并将其加入词表
- 如果 "deep" 和 "er" 经常相邻出现,BPE 就会将它们合并,最终可能将 "deeper" 作为一个整体加入词表,在"词"和"字"之间取得了有效平衡;高频词被完整保留,低频词或新词则被拆解为更小的有意义单元(如字或字节组合)
基于统计频率而非语言学规则(如词根词缀),结果可解释性较差,且对训练语料有较强依赖,遇到领域外文本时可能会因过度切分而导致效果下降
- 如果 "deep" 和 "er" 经常相邻出现,BPE 就会将它们合并,最终可能将 "deeper" 作为一个整体加入词表,在"词"和"字"之间取得了有效平衡;高频词被完整保留,低频词或新词则被拆解为更小的有意义单元(如字或字节组合)
- 在原始语料上迭代合并高频相邻字节对(或字符对)成一个新的、更大的单元,并将其加入词表
词向量表示
将分词后得到的词元序列(如 "国足", "爱", "吃", "海参" ),整体转换成模型能够处理的一个或一组有意义的数字。这个将符号转换为数字的过程,统称为词向量表示**(Word Representation)**
二、离散表示
将每 个词视为一个独立的、不可再分的单元,生成的向量因此也被称为离散向量(Discrete
Vector);
2.1独热编码(One-Hot Encoding)
- 独热编码,也称"哑编码",是最直观、基础的词元级别表示方法
- 构建词典,从整个语料库中收集所有出现过的唯一词语,构成一个词典
- 分配索引,为词典中的每 个词语分配一个从 0 开始的唯一整数索引
创建向量,用一个长度等于词典大小的向量 来表示每个词,向量中该词对应索引的位置为 1 ,其余所有位置均为 0
- 分配索引,为词典中的每 个词语分配一个从 0 开始的唯一整数索引
(2)优点与缺陷
- 实现简单,能够清晰地将词语区分开
- 维度灾难,如果词典中有数万个词,每个词的向量维度就高达数万,造成数据极其稀疏,
浪费计算和存储资源;
- 维度灾难,如果词典中有数万个词,每个词的向量维度就高达数万,造成数据极其稀疏,
- 语义鸿沟,任意两个不同词的独热向量都是正交的(点积为 0);点积是通过将两个向量的对应元素相乘再求和来计算的;在独热编码中每个向量只有一个位置是 1 ,其余都是 0 ,对于任意两个不同词,值为 1 的位置必然错开。
2.2词袋模型(Bag-of-Words, BoW)
- 哑编码表示的是单个词,但实际通常需要表示整个句子或文档。
- 词袋模型正是为此而生,它是表示文档级别特征最常用的方法之一。
2.2.1基本思想与实现
基本思想是忽略文本中的词序和语法,将其仅仅视作一个装满词的**"袋子"**,用袋子中每个词出现的统计量来表示整个文档。
2.2.2余弦相似度计算
计算两个向量夹角的余弦值来衡量它们的相似性。
对于非负向量(如词袋模型产生的向量),其值范围在 0, 1 之间,值越接近 1 ,表示两个向
量越相似。

2.2.3不同统计方式
向量中每一维的值可以采用不同策略
- 使用频数,也就是单词在文档中出现的次数,但这会导致长文章的计数值普遍偏高。使用频率,即用单词次数除以文档总词数(词频)
- 是二进制,仅关注单词是否出现, 若出现记为 1 ,否则为 0 ,忽略具体出现次数。
缺点:
- 是丢失词序,导致如"我 爱 你"和"你 爱 我"的词袋表示完全相同,无法区分语义差异
- 未考虑词的重要性,像"的"、"是"这类在所有文档中都频繁出现的停用词会获得很高频次
2.3 TF-IDF
- 提升文档在向量空间中的区分度,解决"常见词权重过高"导致文档混淆的问题
- 词的重要性与其在当前文档中出现的次数成正比,而与其在整个语料库中出现的频率成反比
(1)算法组成
第一部分是词频(Term Frequency, TF),用于衡量一个词在当前文档中出现的频繁程度。

2.4 N-gram模型
最早引入了预测下一个词的思想
2.4.1预测下一个词
关心的是"词的顺序",基于前文预测后续内容,常被视为生成式AI的雏形
基于马尔可夫假设,一个词出现的概率只取决于它前面N-1个词
指数级爆炸,词典有 10,000 个词,Bigram 就有 10^8 种组合,Trigram 则高达 10^12种
三、序号化表示
把文本转换成最基础的整数ID序列,然后把"学习词语的含义和重要性"这个更复杂的任务,交给模型自己去完成
3.1序号化过程
整数编码,是将分词后的词元序列转换为深度学习模型能够处理的整数序列的核心步骤。
(1)构建词典:首先从训练语料中构建一个词典。这个词典通常是字级别的(如 BERT),或是子词级别的(如 GPT),而不是词级别的。
(2)增加特殊词元:在词典中加入一些有特殊功能的 Token,至少包括 PAD (Padding) 和 UNK (Unknown)。 PAD 的 ID 通常为 0 ,用于将短句子填充至同一批次内的最长长26 / 599度,以满足批处理需求; UNK 的 ID 通常为 1 ,用于表示所有词典中未出现过的词。根据任务需求,还可能加入 CLS (分类)、 SEP (分隔)等其他特殊词元。
(3)ID映射:将文本序列中的每个词元(字/子词)直接映射为其在词典中的整数ID
3.2序号化实例

从主题模型到 Word2Vec
一、寻找理想的词向量
上面说的是无法表达词与词之间的语义关系;
分布式表示(Distributed Representation)被提出,目的是将词语映射到一个低维、稠密、且蕴含丰富语义信息的连续向量空间中;
语义蕴含要求向量之间的距离能够度量词语之间的语义相似度:两个词经常在相似的上下文中共同出现,他们的向量在空间上应该是彼此靠近的。
低维稠密词向量的维度应该是一个较小的、可控的超参数,向量中的每一维都应是有意义的浮点数
二、主题模型
基于机器学习和传统数学思想的经典方法,分析大量文档的词语共现统计,来发现词语间的潜在语义关联;
- 是一篇文档由多个**"主题"** 按一定比例混合而成,而一个主题又由多个**"词语"**按一定概率组成
- 词语一同出现在某篇文档中,是因为它们都在共同描述这篇文章所包含的某个或某些潜在主题
2.1 SVD矩阵分解
将获取词向量的过程,巧妙地转化成了一个矩阵分解问题
(1)构建**"词-文档"矩阵:以整个语料库为基础,构建一个巨大的词-**文档矩阵 X。这个矩阵的每一行代表一个词,每一列代表一篇文档,矩阵中 X(i, j) 的值是词 i 在文档 j 中的重要性权重,可以使用 TF-IDF值来填充。这个矩阵通常是巨大且高度稀疏的。
(2)矩阵分解:从线性代数的角度,这个稀疏矩阵 X 可以被近似分解为两个更小的、更稠密的矩阵的乘积。最常用的分解技术之一是 奇异值分解(SVD)

(3)获取词向量:分解完成后,我们关心 **"词-主题"**矩阵 Wtopic。这个矩阵的每一 行,是我们需要的词向量,将原来 m 维的 One-Hot 编码,降维到了 k 维,还是一个稠密向量,每个维度都代表了与某个主题的关联强度。这个矩阵蕴含了语义信息。如果两个词(如"CPU"和"GPU")经常在描述"硬件"这个主题的文档中共同出现,那么SVD分解的结果会使它们在对应"硬件"主题的那个维度上都有很高的值,从而使它们的最终词向量在空间上非常接近。
2.2主题模型的局限性
主题模型本质上是聚类算法,文档主题矩阵 Htopic 将 n 篇文档聚成 k 个主题类别,每篇文档都有一个 k 维向量,表示它属于各个主题的置信度或软分配;
比如虽然"番茄"和"西红柿"写法完全不同,但因为它们都高频出现在"烹饪"或"蔬菜"相关的主题中,它们在 Wtopic 矩阵中的向量表示就会非常相似:
- 在一定程度上减弱了"同义词"问题
- 描述同 一主题的词语会在相同的主题维度上有较高的权重,它们的词向量才会在空间中彼此靠近,从而实现语义信息的捕捉
缺点:
- 对一个大型语料库进行 SVD 分解,计算量和内存开销都极大,导致计算代价高昂
- 依赖的是全局的、粗粒度的文档级别共现信息,忽略了词语在句子中的局部上下文和词序信息;难以捕捉更精细的语义关系
- "先统计,再分解"的流程,很难与现代的深度学习模型进行端到端的联合训练,难以集成
三、Word2Vec
浅层神经网络模型(Shallow Neural Network)
- 直接将投影层与输出层相连:计算非常高效,能够在大规模语料库上进行训练。
- 最终目标是获取一个高质量的词向量查询表;巨大的矩阵 Win
- 每一行对应单词稠密向量
- 根据上下文预测中心词(或反之)
将词向量查询表作为模型参数进行训练和优化
- 根据上下文预测中心词(或反之)
- 每一行对应单词稠密向量
聚焦于词语的局部上下文:即一个词的含义,由其上下文中的词语所决定
- 两个词的上下文经常是相似的,那么这两个词的语义就是相近的。
3.2可学习的词向量矩阵

在实践中:根据输入的单词 ID,直接从 Win矩阵中获取对应的行向量
- 参数矩阵 Win 本身就是学习的目标,被随机初始化,通过 CBOW 或 Skip-gram 这样的预测任务不断地被优化和调整
嘿嘿 没懂,再读一遍 步骤二懂了,三是什么玩意
3.3模型架构与实现原理
3.3.1两种经典模型
(1)CBOW模型详解
根据上下文预测中心词

例子:
批大小 B = 2,上下文窗口大小 S = 6,词典大小 |V | = 10000,词向量维度 D = 128
- 输入层,输入一个形状为 (2, 6) 的整数张量,例如 \[1, 8, ..., 8, 5, ...] ,代表两个句子片段的上下文词 ID
2. 步词向量转换,通过查表(Win 矩阵,大小 10000 × 128),将这 12 个单词 ID 全部转换
为对应的 128 维向量,相当于公式中的 vc−k = Winwc−k,数据形状变为 (2, 6, 128) - 上下文聚合,对每个样本中的 6 个词向量求平均
4. 输出得分,将这两个上下文向量与输出矩阵 Wout(大小 128 × 10000)相乘,计算每个样本在词典中 10000 个词上的预测得分,数据形状变为 (2, 10000)
损失计算将得分通过 Softmax 将得分转换为概率分布,并与真实的中心词计算交叉熵损失,通过反向传播驱动模型参数 Win 和 Wout 的更新。
(2)Skip-gram模型详解
预测模型,根据中心词预测上下文,将一个预测任务,分解成了多个独立的子任务
为了更高效地学习稠密词向量,强迫模型学习到词语的语义特征,从而彻底解决了传统 N-gram 面临的稀疏性和维度灾难问题。

例子:假设批大小 B = 2,上下文窗口大小 S = 6,词典大小 |V | = 10000,词向量维度 D = 128
-
输入层,输入中心词的 ID,数据形状为 (2, 1)
2. 进行词向量转换,将中心词 ID 通过查表(输入矩阵 Win,大小 10000 × 128)转换为对应的128 维词向量 vwc,数据形状变为 (2, 1, 128)- 进行输出得分计算,将 128 维的中心词向量与输出矩阵 Wout(大小 128 × 10000)相乘,计算在词典中 10000 个词上的得分,数据形状变为 (2, 10000)
- 损失计算环节与 CBOW 不同,目标是利用中心词预测 6 个上下文单词,这一个形状为 (2, 10000) 的得分向量将被复用6次,分别与6 个真实的上下文词(标签)计算交叉熵损失;
- 会将这 6 个位置的损失全部相加, 作为最终的损失值进行反向传播,同时更新 Win 和 Wout。
- 本质上是一个多标签分类问题,在实际实现中,通常将其分解为 6 个独立的单标签分类任务,对每个上下文位置都进行一次 Softmax 预测并求和损失
3.3.2滑动窗口的直观理解
滑动窗口机制如何生成大量高度重叠的训练样本,设窗口大小为 k = 7(中心词左右各 7 个词),通过在文本上滑动该窗口可以生成大量训练样本。
- 对于 CBOW 任务,当窗口中心位于第 8 个单词时,模型使用上下文 w1,..., w7 与 w9,..., w15 预测 w8
- 随后窗口右移一格,中心变为第 9 个单词,模型使用新的上下文 w2,..., w8 与 w10,..., w16 预测 w9
优化算法(如梯度下降)会找到一个"捷 径",也就是当 w8 和 w9 的词向量本身就足够接近时,模型就能用一个相似的上下文向量同时很好地预测出它们俩。
- 整个语料库中不断重复,当两个不同的词(如"笔记本"和"电脑")因语言习惯而频繁出现在相似的上下文(如与"键盘"、"屏幕"、"CPU"等共现)时,为了降低总体损失,模型会将它们的词向量在空间中推向彼此靠近的位置,形成语义相似性
- 模型的最终目标是让 |V | 维得分向量中,对应真实目标词的那个维度的值最大化

两个向量的点积是余弦相似度公式的分子部分。所以,最大化这个点积得分,在几何上就是在 促使上下文向量 x 和目标词向量 utarget 的夹角尽可能小,即让它们在空间上更接近。
四、Word2Vec的局限
静态词向量
(1)上下文无关:对于词典中的任意一个词,Word2Vec 只会生成一个固定的向量表示:无法解决一词多义的问题
(2)静态的本质:Word2Vec 的输出是一个巨大的查询表,训练完成后表固定,使用时根据单词 ID查找对应的行向量,不涉及上下文动态分析
第四节 基于Gensim的词向量实战
功能强大且高效的Python库;处理原始的、非结构化的纯文本文档,它内置了多种主流的词向量和主题模型算法;如 Word2Vec、TF-IDF、 LSA、LDA 等
- 语料库:这是 Gensim 处理的主要对象,可以简单理解为训练数据集,每个子列表代表一篇独立的文档
- 词典:这是一个将词语(token)映射到唯一整数ID的词汇表
- 向量:在 Gensim 中,一篇文档最终会被转换成一个数学向量
- 稀疏向量:为了节省内存,高效表示法:One-Hot 或词袋 模型这样维度巨大且绝大多数值为0的向量,Gensim 不会存储所有0
- 模型:实现向量转换的算法
二、Gensim工作流
(1)准备语料:将原始的文本文档进行分词,并整理成 Gensim 要求的由列表构成的列表
listlist\[str] 格式,其中每个子列表代表一篇独立的文档
(2)创建词典:遍历所有分词后的文档,创建一个词典,将每个唯一的词元映射到一个从 0
开始的整数 ID
(3)词袋化:使用创建好的词典,将每一篇文档转换为其稀疏的词袋(BoW)向量。这个向
量只记录文档中出现的词的 ID 及其频次,格式为 (token_id, frequency), ...
以上三步适用于 TF-IDF、LSA、LDA、NMF 等基于 BoW 的模型;不适用于Word2Vec/FastText/Doc2Vec 等神经网络词向量模型
import jieba
from gensim import corpora
# Step 1: 准备分词后的语料 (新闻标题)
raw_headlines = [
"央行降息,刺激股市反弹",
"球队赢得总决赛冠军,球员表现出色"
]
tokenized_headlines = [jieba.lcut(doc) for doc in raw_headlines]
print(f"分词后语料: {tokenized_headlines}")
# Step 2: 创建词典
dictionary = corpora.Dictionary(tokenized_headlines)
print(f"词典: {dictionary.token2id}")
# Step 3: 转换为BoW向量语料库
corpus_bow = [dictionary.doc2bow(doc) for doc in tokenized_headlines]
print(f"BoW语料库: {corpus_bow}")分词后语料: \['央行', '降息', ',', '刺激', '股市', '反弹', '球队', '赢得', '总决赛', '冠军', ',', '球员', '表现出色']
词典: {'刺激': 0, '反弹': 1, '央行': 2, '股市': 3, '降息': 4, ',': 5, '冠军': 6, '总决赛': 7, '球员': 8, '球队': 9, '表现出色': 10, '赢得': 11}
BoW语料库: \[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1)]
三、TF-IDF与关键词权重
衡量一个词在文档中重要性的经典加权方法
import jieba
from gensim import corpora, models
# 1. 准备语料 (新闻标题,包含财经和体育两个明显主题)
headlines = [
"央行降息,刺激股市反弹",
"球队赢得总决赛冠军,球员表现出色",
"国家队公布最新一期足球集训名单",
"A股市场持续震荡,投资者需谨慎",
"篮球巨星刷新历史得分记录",
"理财产品收益率创下新高"
]
tokenized_headlines = [jieba.lcut(title) for title in headlines]
# 2. 创建词典和BoW语料库
dictionary = corpora.Dictionary(tokenized_headlines)
corpus_bow = [dictionary.doc2bow(doc) for doc in tokenized_headlines]
# 3. 训练TF-IDF模型
tfidf_model = models.TfidfModel(corpus_bow)
# 4. 将BoW语料库转换为TF-IDF向量表示
corpus_tfidf = tfidf_model[corpus_bow]
# 辅助函数:把 (token_id, weight) 转成 (token, weight),并按权重降序展示
def tfidf_with_words(tfidf_vec, id2word):
pairs = [(id2word[token_id], weight) for token_id, weight in tfidf_vec]
return sorted(pairs, key=lambda x: x[1], reverse=True)
# 打印第一篇标题的TF-IDF向量
first_tfidf = list(corpus_tfidf)[0]
print("第一篇标题的TF-IDF向量:")
print(first_tfidf)
print("第一篇标题的TF-IDF向量(带词语):")
print(tfidf_with_words(first_tfidf, dictionary))
# 5. 对新标题应用模型
new_headline = "股市大涨,牛市来了"
new_headline_bow = dictionary.doc2bow(list(jieba.cut(new_headline)))
new_headline_tfidf = tfidf_model[new_headline_bow]
print("\n新标题的TF-IDF向量:")
print(new_headline_tfidf)第一篇标题的TF-IDF向量:
(0, 0.44066740566370055), (1, 0.44066740566370055), (2,
0.44066740566370055), (3, 0.44066740566370055), (4, 0.44066740566370055),
(5, 0.1704734229377651)
第一篇标题的TF-IDF向量(带词语):
("刺激", 0.44066740566370055), ("反弹", 0.44066740566370055), ("央行",
0.44066740566370055), ("股市", 0.44066740566370055), ("降息",
0.44066740566370055), (",", 0.1704734229377651)
新标题的TF-IDF向量:
(3, 0.9326446771245245), (5, 0.360796211497975)
原始的 BoW 向量只包含词频(整数),而 TF-IDF 向量则包含浮点数权重。像","这样在多篇文档中都出现的词,其 TF-IDF 权重会较低;而在特定财经新闻中出现的"股市"、"降息"等词,权重会相对较高。这个 TF-IDF 向量后续可用于计算文档相似度或作为机器学习模型的输入特征
词典外的新词会被忽略,新文本的向量仅由词典中已有词构成。本示例中标点","进入了词典并具有非零权重;如不希望其影响权重或相似度,建议在构建词典前移除标点/停用词。此外,新标题的 TF-IDF 仅包含"股市"和","两项,这是因为其他词为 OOV 被忽略。
四、LDA与文档主题挖掘
主题模型(如 LDA)能从大量文档中自动发现隐藏的、无监督的主题。它的输入同样是词典
和 BoW 语料库。
from gensim import corpora, models
# 1. 准备语料
headlines = [
"央行降息,刺激股市反弹",
"球队赢得总决赛冠军,球员表现出色",
"国家队公布最新一期足球集训名单",
"A股市场持续震荡,投资者需谨慎",
"篮球巨星刷新历史得分记录",
"理财产品收益率创下新高"
]
tokenized_headlines = [jieba.lcut(title) for title in headlines]
# 2. 创建词典和BoW语料库
dictionary = corpora.Dictionary(tokenized_headlines)
corpus_bow = [dictionary.doc2bow(doc) for doc in tokenized_headlines]
# 3. 训练LDA模型 (假设需要发现2个主题)
lda_model = models.LdaModel(corpus=corpus_bow, id2word=dictionary,
num_topics=2, random_state=100)
# 4. 查看模型发现的主题
print("模型发现的2个主题及其关键词:")
for topic in lda_model.print_topics():
print(topic)
# 5. 推断新文档的主题分布
new_headline = "巨星詹姆斯获得常规赛MVP"
new_headline_bow = dictionary.doc2bow(jieba.lcut(new_headline))
topic_distribution = lda_model[new_headline_bow]
print(f"\n新标题 '{new_headline}' 的主题分布:")
print(topic_distribution)模型发现的2个主题及其关键词:
(0, '0.045*"," + 0.040*"公布" + 0.039*"一期" + 0.039*"名单" + 0.039*"足球" +
0.039*"最新" + 0.038*"集训" + 0.038*"国家队" + 0.037*"A股" + 0.037*"市场"')
(1, '0.066*"," + 0.039*"篮球" + 0.039*"刷新" + 0.039*"历史" + 0.039*"记录" +
0.038*"得分" + 0.038*"巨星" + 0.037*"刺激" + 0.036*"降息" + 0.036*"反弹"')
新标题 '巨星詹姆斯获得常规赛MVP' 的主题分布:
(0, np.float32(0.27243596)), (1, np.float32(0.72756404))
将一篇文档表示为一个主题概率分布(Gensim 默认以稀疏列表返回;例如 90% 体育、10% 财经),还能清晰地看到每个主题由哪些核心词构成。若新文本在词典中几乎无重叠词( doc2bow 为空),推断出的主题分布可能接近均匀(例如 2 个主题时约为0.5/0.5)
五、Word2Vec模型实战
输入直接是分词后的句子列表,根据上下文学习每个词语本身内在的、稠密的语义向量。
- 练结束后, 神经网络本身通常会被丢弃
- 最终目标是获得那个高质量的词向量查询表,存储在model.wv 属性中
5.1模型训练与核心参数
难点是如何根据语料特点调整超参数(如窗口大小、最小词频等),这些设置直接决定了词向量的质量:
from gensim.models import Word2Vec
# 1. 准备语料
headlines = [
# 财经
"央行降息,刺激股市反弹",
"A股市场持续震荡,投资者需谨慎",
"理财产品收益率创下新高",
"证监会发布新规,规范市场交易",
"创业板指数上涨,科技股领涨大盘",
"房价调控政策出台,房地产市场降温",
"全球股市动荡,影响资本市场信心",
"分析师认为,当前股市风险与机遇并存,市场情绪复杂",
# 体育
"球队赢得总决赛冠军,球员表现出色",
"国家队公布最新一期足球集训名单",
"篮球巨星刷新历史得分记录",
"奥运会开幕,中国代表团旗手确定",
"马拉松比赛圆满结束,选手创造佳绩",
"电子竞技联赛吸引大量年轻观众",
"这支球队的每位球员都表现出色",
"球员转会市场活跃,多支球队积极引援"
]
tokenized_headlines = [jieba.lcut(title) for title in headlines]
# 2. 训练Word2Vec模型
model = Word2Vec(tokenized_headlines, vector_size=50, window=3, min_count=1,
sg=1)-
sentences : 输入的语料库(对应代码中的 tokenized_headlines ),必须是listlist\[str] 格式。
-
vector_size : 词向量的维度。维度越高,能表达的语义信息越丰富,但计算量也越大。 通常在 50-300 之间选择。
-
window : 上下文窗口大小。表示在预测一个词时,需要考虑其前后多少个词。
-
min_count : 最小词频过滤。任何在整个语料库中出现次数低于此值的词将被直接忽略,这是非常关键的一步,可以过滤掉大量噪音(如错别字、罕见词),并显著减小模型体积。
-
sg : 选择训练算法。 0 表示 CBOW (根据上下文预测中心词); 1 表示 Skip-gram (根据中心词预测上下文)。
-
hs : 选择优化策略。 0 表示使用 Negative Sampling (负采样); 1 表示使用 Hierarchical
Softmax。 -
negative : 当 hs=0 使用负采样时,为每个正样本随机选择多少个负样本。通常在 5-20 之间
-
sample : 高频词二次重采样阈值。这是一个控制高频词(如"的"、"是")被随机跳过的机制,目的是减少它们对模型训练的过多影响,并加快训练速度
5.2使用词向量
模型训练完成后,所有的操作都围绕 model.wv 展开,用于探索词语间的语义关系。小语料示例下,相似度数值通常较低且不稳定,仅作演示参考。
# 1. 寻找最相似的词
# 在小语料上,结果可能不完美,但能体现出模型学习到了主题内的关联
similar_to_market = model.wv.most_similar('股市')
print(f"与 '股市' 最相似的词: {similar_to_market}")
# 2. 计算两个词的余弦相似度
similarity = model.wv.similarity('球队', '球员')
print(f"\n'球队' 和 '球员' 的相似度: {similarity:.4f}")
# 3. 获取一个词的向量
market_vector = model.wv['市场']
print(f"\n'市场' 的向量维度: {market_vector.shape}")
输出如下:
与 '股市' 最相似的词: [('名单', 0.3699544370174408), ('央行',
0.3554984927177429), ('年轻', 0.24192844331264496), ('联赛',
0.23673078417778015), ('马拉松', 0.20006775856018066), ('证监会',
0.19390541315078735), ('每位', 0.17580750584602356), ('积极',
0.16841839253902435), ('球队', 0.16585905849933624), ('理财产品',
0.16510605812072754)]
'球队' 和 '球员' 的相似度: -0.1552
'市场' 的向量维度: (50,)5.3模型的持久化
如果后续不再进行增量训练,推荐只保存KeyedVectors 对象 ( model.wv )。
完整的模型对象包含了哈夫曼树、梯度累积量等仅在训练阶段需要的中间状态,去除这些冗余信息不仅能节省存储空间,更能降低内存占用并提升加载速度,保障线上服务的稳定性
from gensim.models import KeyedVectors
# 保存词向量到文件
model.wv.save("news_vectors.kv")
# 从文件加载词向量
loaded_wv = KeyedVectors.load("news_vectors.kv")
# 加载后可以执行同样的操作
print(f"\n加载后,'球队' 和 '球员' 的相似度: {loaded_wv.similarity('球队', '球
员'):.4f}")
输出:
加载后,'球队' 和 '球员' 的相似度: -0.1552方便地训练自己的 Word2Vec 模型,并利用其强大的语义捕捉能 力进行相似度计算、语义类比等 NLP 任务。