老铁们,前三篇我们学会了 MyBatis 的基本操作,从注解到 XML,从参数传递到结果映射,可以说已经能独立完成大部分单表 CRUD 了。但真实项目中,数据往往分散在多张表中,比如用户表、文章表、订单表......很多时候我们需要一次性把多张表的数据查出来。
今天我们就来聊聊 多表查询 ,以及 MyBatis 中两个非常重要的符号:
#{}和${}。另外,我们还会学习数据库连接池的配置,以及一些企业级开发规范。
1. 多表查询:当数据来自多张表
1.1 为什么需要多表查询?
在实际业务中,数据往往不是孤立存在的。比如:
- 一篇文章属于一个作者,我们想同时查出文章内容和作者信息。
- 一个订单关联了用户、商品、地址等多张表。
如果分别查询,代码会变得冗长,而且需要多次数据库交互。多表查询可以一次 SQL 把相关数据都取出来,减少数据库访问次数。
1.2 准备工作:创建用户表和文章表的关联关系
sql
-- 创建表[用户表]
drop table if exists user_info;
create table `user_info` (
id int ( 11 ) not null primary key auto_increment,
username varchar ( 127 ) not null,
password varchar ( 127 ) not null,
age tinyint ( 4 ) not null,
gender tinyint ( 4 ) default '0' comment '1-男 2-女 0-默认',
phone varchar ( 15 ) default null,
delete_flag tinyint ( 4 ) default 0 comment '0-正常, 1-删除',
create_time datetime default now(),
update_time datetime default now() on update now()
);
-- 添加用户信息
insert into user_info( username, `password`, age, gender, phone )
values ( '管理员', '管理员123', 18, 1, '18612340001' );
insert into user_info( username, `password`, age, gender, phone )
values ( '张三', '张三123', 18, 1, '18612340002' );
insert into user_info( username, `password`, age, gender, phone )
values ( '李四', '李四123', 18, 1, '18612340003' );
insert into user_info( username, `password`, age, gender, phone )
values ( '王五', '王五123', 18, 1, '18612340004' );
-- 创建文章表
drop table if exists article_info;
create table article_info (
id int primary key auto_increment,
title varchar ( 100 ) not null,
content text not null,
uid int not null,
delete_flag tinyint ( 4 ) default 0 comment '0-正常, 1-删除',
create_time datetime default now(),
update_time datetime default now()
);
-- 插入测试数据
insert into article_info ( title, content, uid ) values ( 'Javaee', 'Javaee知识介绍', 1 );用户表

文章表

1.3 sql查询结果

SQL 要求:我在查询文章表的时候 需要将用户表中的用户名和年龄给查询出来,此时涉及到我们的多表查询,那么连接条件就是我们的用户id,如图所示:

结果:

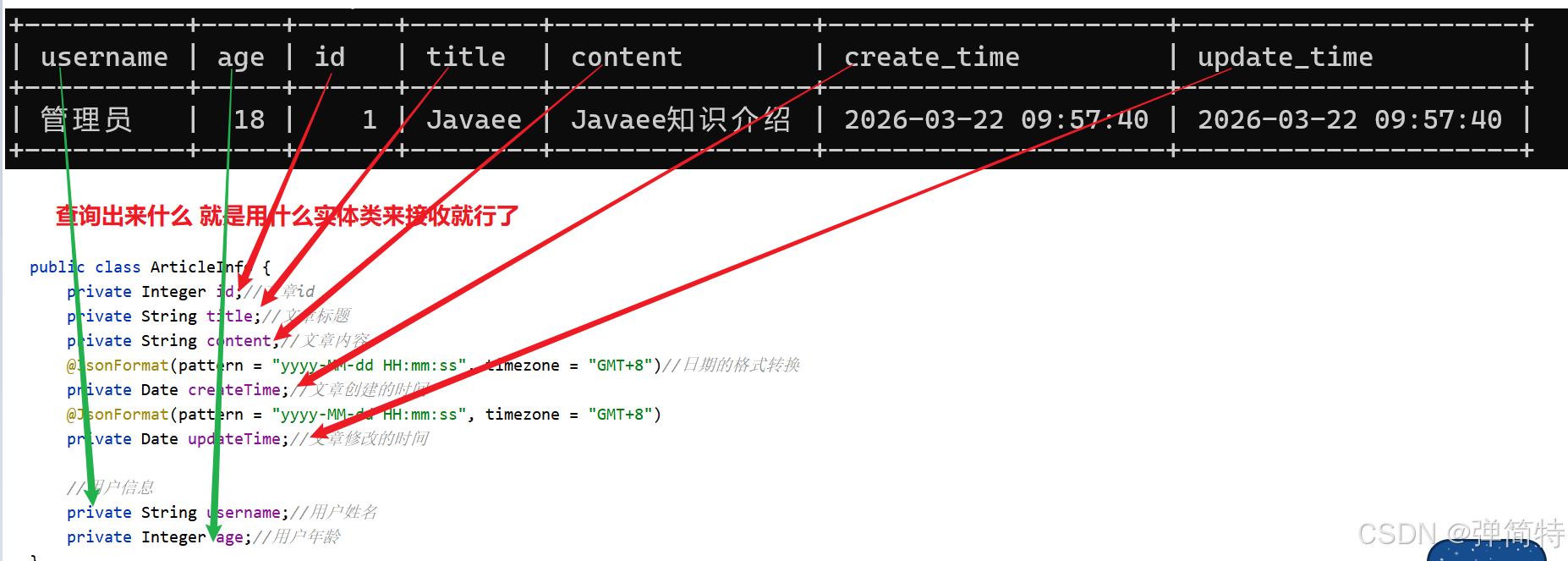
1.4 编写多表查询的 实体类
根据我们查询出来的中间表的字段写一个对应的实体类就行了,比如:
java
package com.zhongge.entity;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import java.time.LocalDate;
/**
* @ClassName ArticleInfo
* @Description TODO 文章实体类
* @Author 笨忠
* @Date 2026-03-22 10:14
* @Version 1.0
*/
@Data
public class ArticleInfo {
private Integer id;//文章id
private String title;//文章标题
private String content;//文章内容
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")//日期的格式转换
private LocalDate createTime;//文章创建的时间
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDate updateTime;//文章修改的时间
//用户信息
private String username;//用户姓名
private Integer age;//用户年龄
}
1.5 编写mapper接口和xml文件
java
package com.zhongge.mapper;
import com.zhongge.entity.ArticleInfo;
import org.apache.ibatis.annotations.Mapper;
/**
* @InterfaceName ArticleInfoMapper
* @Description TODO 文章操作接口
* @Author 笨忠
* @Date 2026-03-22 10:20
* @Version 1.0
*/
@Mapper
public interface ArticleInfoMapper {
//查询文章
ArticleInfo getArticleInfoByUserId(Integer id);
}
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zhongge.mapper.ArticleInfoMapper">
<select id="getArticleInfoByUserId" resultType="com.zhongge.entity.ArticleInfo">
select u.username, u.age, a.id, a.title, a.content, a.create_time, a.update_time
from user_info as u
left join article_info as a
on u.id = a.uid
where u.id = #{id}
</select>
</mapper>测试:
结果:

1.6 小结:多表查询的本质
MyBatis 处理多表查询和单表查询在底层没有任何区别------它只关心 SQL 执行后返回的列名,然后根据列名去映射 Java 对象的属性。因此,我们只需要把查询结果需要的列都列出来,然后在实体类中定义对应的属性,就能轻松接收多表数据。
2. #{} 和 ${} 的区别:安全与性能
我们一直在用 #{} 传参,比如 #{name}、#{id}。其实 MyBatis 还有一种传参方式:${}。这两者到底有什么区别?什么时候该用哪个?
2.1 先看现象
2.1.1 数字类型参数
java
@Select("select * from student where id = #{id}")
Student findById(Integer id);执行时,MyBatis 会输出:
==> Preparing: SELECT * FROM student WHERE id = ?
==> Parameters: 1(Integer)SQL 中是 ? 占位符,参数单独传入,这叫 预编译 。如果换成 ${}:
java
@Select("select * from student where id = ${id}")
Student findById(Integer id);输出:
==> Preparing: SELECT * FROM student WHERE id = 1
==> Parameters: 参数直接拼接到 SQL 中,没有占位符,这叫 字符串替换。
2.1.2 字符串类型参数
java
@Select("select * from student where name = #{name}")
Student findByName(String name);正常输出,参数被安全设置。
如果换成 ${}:
java
@Select("select * from student where name = ${name}")
Student findByName(String name);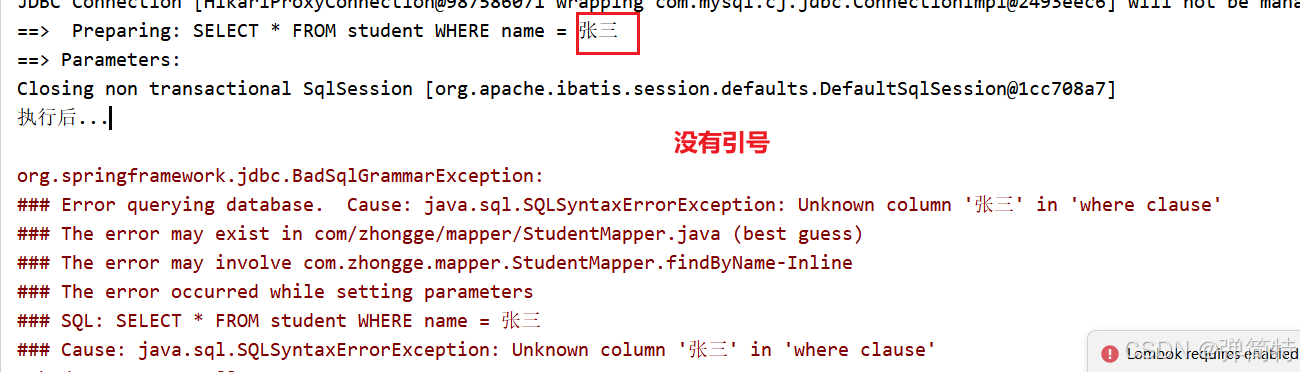
会报错,因为拼接后的 SQL 变成 WHERE name = 张三,缺少引号。必须手动加引号:
java
@Select("select * from student where name = '${name}'")
Student findByName(String name);但这样仍然有安全问题。
2.2 本质区别:预编译 vs 字符串拼接
sql执行流程:
- 语法解析
- sql优化
- sql编译
- sql执行
#{}:MyBatis 会将其替换为?,然后通过PreparedStatement的setXXX方法赋值。SQL 在数据库端先被编译(解析、优化),再填充参数,称为 预编译。${}:直接将参数值拼接到 SQL 字符串中,然后发送完整 SQL 给数据库,称为 即时编译(Immediate Statement)。【${}这个东西在编程中一般就是取值的意思】
2.3 为什么 #{} 更安全?
SQL 注入攻击:攻击者在输入中嵌入 SQL 关键字,使拼接后的 SQL 改变原意。例如:
java
@Select("select * from student where name = '${name}'")
List<Student> findByName(String name);正常调用:findByName("张三") → SQL: SELECT * FROM student WHERE name = '张三'
攻击者输入:" ' or '1'='1 " → SQL 变成:
sql
select * from student where name = '' or '1'='1'因为 '1'='1' 永远为真,这个查询会返回所有学生,造成数据泄露甚至登录绕过。
如果改用 #{}:
java
@Select("select * from student where name = #{name}")
List<Student> findByName(String name);即使输入 " ' or '1'='1 ",也会被当作一个完整的字符串值去匹配 name 字段,不会改变 SQL 语义。
所以,#{} 可以防止 SQL 注入,是安全的;${} 存在注入风险,必须谨慎使用。
2.4 为什么 ${} 还要存在?【排序】
有些场景下,#{} 无法胜任,因为 #{} 会自动给字符串加引号,而 SQL 的某些部分不能加引号。
场景1:排序字段
java
@Select("select * from student order by id #{order}")
List<Student> orderBy(String order);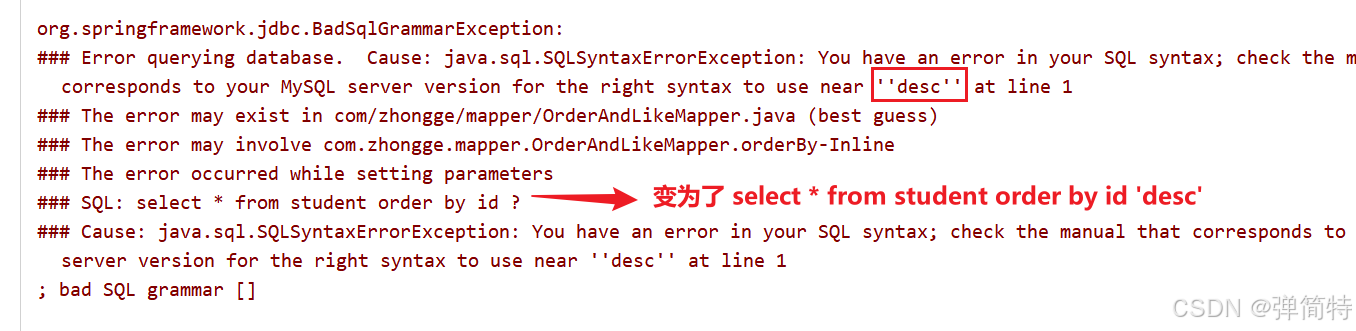
执行时会变成 order by id 'desc',语法错误。必须用 ${}:
java
@Select("select * from student order by id ${order}")
List<Student> orderBy(String order);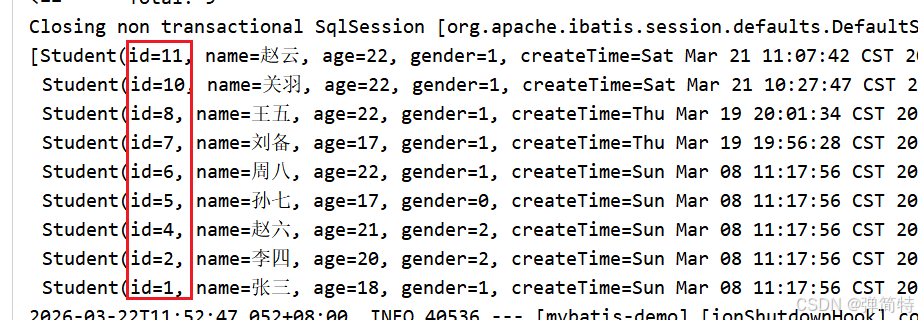
然而使用{}是会有风险的,那么基于这个风险的话,我们怎么做呢?此时我们就做一个参数校验\[使用Controller层校验\]就行了,你看 {order}中order就只有两个值:降序desc 和升序 asc 那么你就校验一下这个参数只允许是这两个就行了。
场景2:表名动态传入
java
@Select("select * from ${tableName}")
List<Student> queryTable(String tableName);但是还是为了解决sql注入的问题,我们要做参数校验。
场景3:某些数据库函数参数
比如 limit 后面不能用 #{},因为会被加引号,导致错误。
在这些场景下,只能使用 ${},但要严格控制输入,比如用枚举限制排序字段,不允许用户随意传值。
2.5 模糊查询的正确姿势
我们经常写 like '%#{key}%',但这样会报错。因为 #{} 会被替换成 ?,最终变成 like '%'? '%',语法错误。
错误写法:
java
@Select("select * from student where name like '%#{key}%'")
List<Student> search(String key);被加了引号
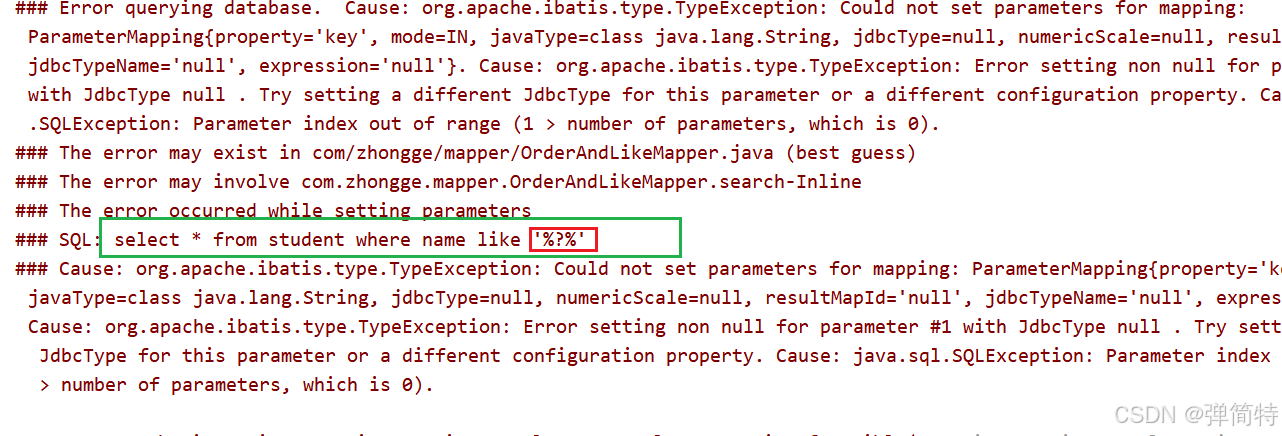

如果使用${}的话那么此时可以查出来,但是存在SQL注入问题,那么怎么解决呢?
答:正确写法 :用 MySQL 的 concat 函数拼接,确保 #{} 被正确预编译:


java
@Select("select * from student where name like concat('%', #{key}, '%')")
List<Student> search(String key);这样既避免了 SQL 注入,又能正常模糊查询。
2.6 总结对比
| 特性 | #{} |
${} |
|---|---|---|
| 处理方式 | 预编译占位符 ? |
直接字符串替换 |
| SQL 注入 | 防止 | 存在风险 |
| 自动加引号 | 字符串自动加 | 不加,需手动加 |
| 适用场景 | 绝大多数参数 | 排序字段、表名、动态列名 |
| 性能 | 高(可缓存执行计划) | 低(每次重新编译) |
原则 :能用 #{} 的地方绝不用 ${},只有在非用不可时才用 ${},并且要做好输入校验(比如用白名单限制)。
3. 数据库连接池:为什么需要它?
3.1 没有连接池会怎样?
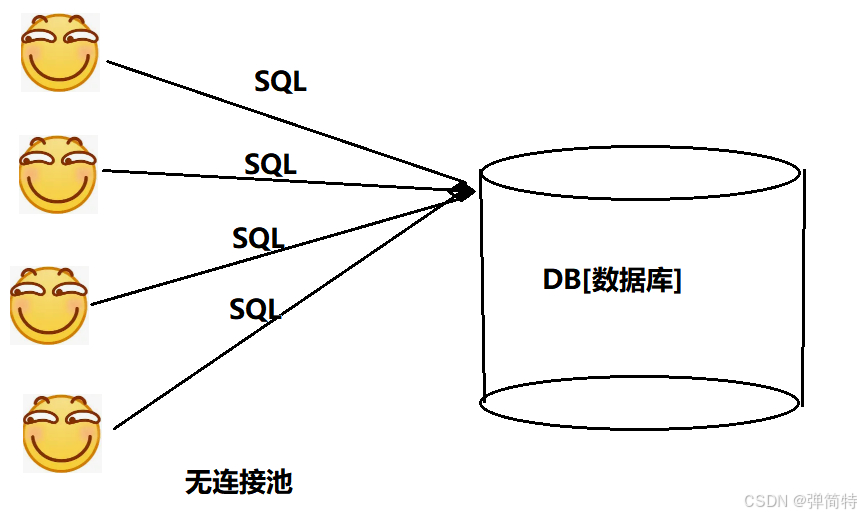
每次执行 SQL 都需要:
- 建立 TCP 连接(三次握手)
- 数据库认证用户名密码
- 执行 SQL
- 断开连接(四次挥手)
这个过程开销极大,尤其是在高并发场景下,频繁创建销毁连接会成为系统瓶颈。
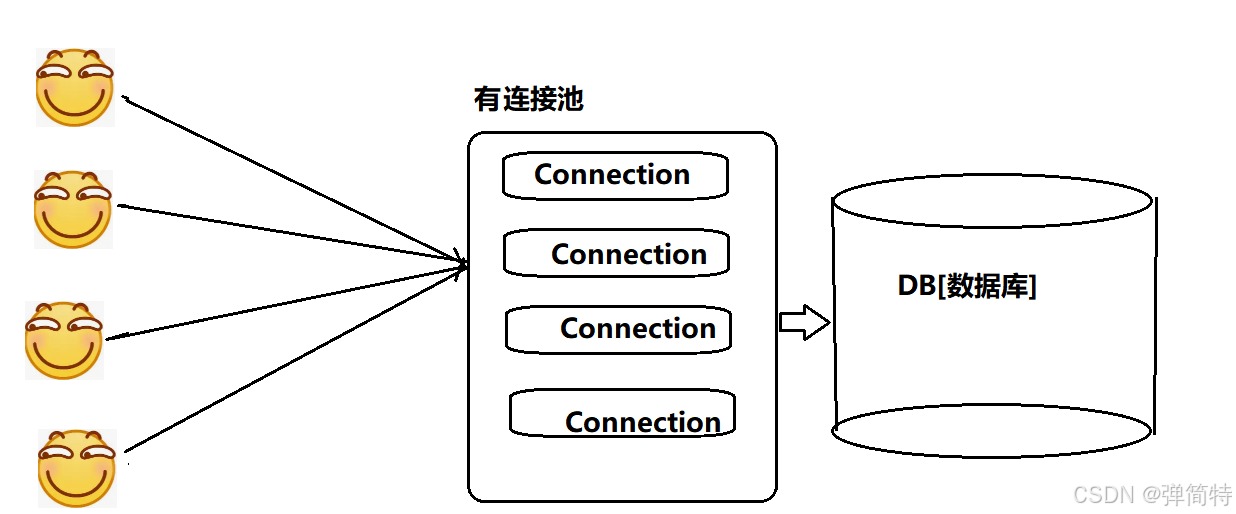
3.2 连接池的工作原理
连接池在程序启动时创建一批连接(比如 10 个),放在一个"池子"里。需要操作数据库时,从池子借 一个连接,用完归还到池子。如果池子满了,请求就排队等待。这样就避免了反复创建销毁连接,大幅提升性能和并发能力。
3.3 常见的数据库连接池
- HikariCP:Spring Boot 2.x 以后默认的连接池,性能极高,号称"光速"(Hikari 是日语"光"的意思)。
- Druid:阿里巴巴开源的连接池,功能强大,支持监控、统计、SQL 防火墙等,在国内使用广泛。
- C3P0、DBCP:老牌连接池,现在使用较少。
3.4 如何切换连接池?
Spring Boot 默认使用 HikariCP,如果我们想切换到 Druid,只需引入依赖即可【其他什么都不用刚干】:
Spring Boot 3.x:
xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>1.2.21</version>
</dependency>Spring Boot 2.x:
xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>引入后,Spring Boot 会自动配置 Druid 数据源,无需额外配置。启动时日志会显示 DataSource: DruidDataSource,说明切换成功。
Druid 还提供了监控页面,可以实时查看 SQL 执行情况、连接池状态等,非常适合生产环境。具体配置可以参考官方文档。
4. 企业开发规范与总结
4.1 MySQL 开发规范
-
表名、字段名全小写+下划线
因为 MySQL 在 Windows 下不区分大小写,但在 Linux 下区分,全小写可以避免环境差异。例如:
user_info、create_time。 -
表必备三字段
id:主键,通常用bigint unsigned auto_incrementcreate_time:创建时间,类型datemite default now()update_time:更新时间,类型datemite default now() on update now()
-
查询避免
SELECT *- 只查需要的字段,减少网络传输。
- 避免因表结构变化导致
resultMap映射不一致。 - 对大字段(如
text)尤其要谨慎。
4.2 #{} 和 ${} 使用总结
- 优先使用
#{},安全且高效。 - 只有排序、表名、动态列名等无法使用
#{}的场景,才考虑${},并严格控制输入【做参数校验】。 - 模糊查询使用
concat('%', #{key}, '%')。
4.3 多表查询建议
- 简单关联(如一对一、一对多)可以用 SQL 的
JOIN一次查完。 - 复杂关联(多表 join,大表关联)建议拆成多次单表查询,在业务层用代码组装,减轻数据库压力。
- 扩展实体类来接收关联字段,这是 MyBatis 中最常用的方式。
5. 预告:动态SQL
到此,我们已经学习了 MyBatis 的几乎所有基础操作。下一篇我们将进入 动态SQL 的世界,实现按条件查询、批量操作、复杂判断等高级功能,让 SQL 真正"活"起来!
老铁们,如果你觉得这篇文章对你有帮助,别忘了
👍 点赞
⭐ 收藏
👀 关注
我们下期见!