本篇笔记是博主自己项目实现的一个简易版的bm25检索方式,大家可以跳着阅读,本篇是接上一篇ES泄露的笔记。此外很多部分的细节代码,没有粘贴出来,太多了不好全部展示,这篇笔记更相当于博主自己写给自己看的,用来梳理思路流程的。
这里需要说明一下:用ES实现此功能的话,一定要提前安装ik分词器到ES的plungin目录下,同时他的版本要和你的ES版本一致,不然没办法进行
一:为什么需要bm25检索
纯向量检索只懂 "语义相似度",不懂 "关键词精准命中" ;BM25 补的就是:精准词条、专有名词、专业术语、代码报错、固定配置字段的精确匹配短板。
下面把传统向量检索的致命缺陷 + 为什么必须加 BM25 讲解一下
一、先搞懂:两种检索的底层逻辑
1. 向量检索(Embedding + 余弦相似度)
把句子 / 文档压成高维向量,越像、语义越接近,距离越近。擅长:
- 同义改写、口语转述、模糊语义
- 概念类、知识类问答
天生短板:不看重字面关键词,只看整体语义分布
2. BM25(倒排索引 + 词频权重)
按分词、词出现频率、词稀有度、文档长度打分。擅长:
- 精确词条、接口名、字段名、错误码、版本号、专业术语
- 字面包含查询关键词的文档优先置顶
天生短板:不懂语义,只能字面匹配
二、传统纯向量检索,有 4 个致命问题
问题 1:容易「语义跑偏」,漏掉精准含关键词的文档
举个例子:用户提问:java 报 NullPointerException 怎么解决
- 纯向量检索 会召回很多讲 Java 异常、空指针原理 的科普文章(语义很像)反而漏掉直接包含
NullPointerException报错代码片段的文档
因为向量看的是整体语义氛围,不在乎有没有精确包含这个报错词。
- 加了 BM25 只要文档字面包含 NPE 关键字,直接拉高分数,精准文档排前面。
问题 2:对专有名词、ID、编码、字段名极不敏感
业务里大量这种内容:
- 错误码:
50012、ERR_CONN_REFUSED - 接口字段:
user_id、token_expire、pg_hba.conf - 版本号、工单号、设备编号
纯向量的毛病 :Embedding 会把这些编码、编号当成普通无意义字符 ,语义相似度拉不开,匹配很乱。BM25 的优势 :分词后把这些稀有词条权重拉满,谁包含谁高分。
问题 3:长文档稀释关键词权重
一篇很长的技术文档,里面只提了一次你要的关键词。
- 纯向量:整篇文档语义被其他内容稀释,相似度不高,召回不到
- BM25:按词独立打分,只要稀有关键词出现,就能上榜
问题 4:容易召回「看似像、实际无关」的垃圾结果
向量是模糊语义匹配:问 A,给你召回主题相似但完全不解决问题的 B、C、D。比如问「Redis 过期淘汰策略」纯向量可能给你召回「Redis 集群、Redis 持久化」这类主题相近但无关的内容。
BM25 可以强行约束:必须命中核心关键词,过滤语义碰瓷的垃圾结果。
三、总结:为什么 RAG/ES 一定要 向量 + BM25 混合
| 维度 | 纯向量检索 | BM25 | 组合后解决的问题 |
|---|---|---|---|
| 语义理解 | 强 | 弱 | 向量负责找「意思对的」 |
| 关键词精准匹配 | 弱 | 极强 | BM25 负责找「词对的」 |
| 错误码 / 接口 / 字段匹配 | 差 | 极好 | 解决专业词条匹配乱 |
| 长文档关键词定位 | 差 | 好 | 不怕长文档稀释权重 |
| 结果垃圾召回 | 多 | 少 | 过滤语义碰瓷无关文档 |
最通俗大白话
- 纯向量:只看「大概说的是不是一回事」,不抠字眼;
- BM25:专门抠「关键专业词、报错、字段、编码」有没有精确命中;
- 所以 ES 里必须做向量召回兜底语义 + BM25 精排控精准度,缺一不可。
这里博主结合自己的理解,解释一下就是我们传统只用向量数据库根据相似度查询rag知识库,他返回的全是和用户的问题语义相近的知识片段,比如用户问"Mysql数据的工作原理,工作方式,索引",他可能经过检索后返回类似于"postgres数据库的工作原理是xxxxx,orcale的工作原理",我们不能直接说向量检索结果有问题,他返回的内容确实和我们问题语义很近 ,但是却没有把我我们的专用名词"Mysql",他没办法做到精确的查询,这就是向量数据库检索的缺点,把我不到我们的关键词信息。这时就需要引入bm25检索了,他和我们的向量检索有区别,他只看中关键字有没有出现,而不是语义,比如还是我们上文提及的用户问题,他会根据我们的关键字"Mysql",去查询所有包含"Mysql"关键字的rag知识片段,包括"Mysql索引,Mysql工作原理",他可能会违背用户语义,检索到和问题不一致的答案,但是他能确保检索的片段包含"Mysql"
不知道看到这里,脑子里会不会有一种思路,就是结合向量检索与bm25检索,我们先通过向量检索查询所有与用户问题语义相近的rag知识片段,然后通过用户问题的关键字,用bm25检索来精确为rag知识片段进行过滤和打分,包含关键字的文档分数越高,重排就会排的越靠前,这就是"混合检索"
混合检索做法做法 :向量召回 → BM25 精排
java
1. **第一步:向量检索**
- 用 Embedding 把 Query 转向量
- 向量库召回 Top N(比如 Top 100)**语义相似**的候选文档
1. **第二步:BM25 重排序(Rerank)**
- 对这 100 篇候选,用 **BM25 重新算相关性**
- 按 BM25 分数重新排,取 Top K(比如 Top 10)给用户
**目的**:
- 先用向量保证**语义相关**,不漏掉意思对的文档
- 再用 BM25 把**关键词精准、专有名词匹配强**的文档顶到前面 二: 什么是bm25,为什么ES可以用来实现
1. 本质
BM25 是全文关键词相关性打分算法 ,是搜索引擎用来判断:用户查询 和 这篇文档到底有多匹配 的核心公式。是 TF-IDF 的工业级升级版,现在所有检索系统默认都用它。
2. 核心原理(3 个关键因子)
-
TF 词频:关键词在文档里出现次数越多,分越高;
- 但不会无限涨,到一定次数就封顶,避免堆砌关键词作弊。
-
IDF 逆文档频率:词越稀有,权重越高;
- 比如专业报错码、接口字段 > "的、是、和" 这种烂大街虚词。
-
文档长度归一化:
- 不会因为文章写得长,就天然占便宜;短文档精准命中关键词反而更吃香。
3. BM25 能干啥
只认字面分词 ,精准匹配:专业术语、错误码、接口名、字段名、编号、配置参数;缺点:不懂语义、不懂同义词,只能字面匹配。
为什么 ES 天生就能实现 BM25?
4. ES 底层基石就是倒排索引
ES 存储文本时,会做:
- 文本分词(IK、标准分词器等)
- 构建倒排索引:记录每个词出现在哪些文档、出现多少次
而 BM25 算法运行必须依赖倒排索引 + 分词词频数据,ES 原生自带这套存储结构。
5. ES 默认全文检索底层就是 BM25
你写的普通查询:match、multi_match、query_string底层默认打分算法就是 BM25(ES 5 之后默认就是 BM25,之前是 TF-IDF)。不用自己写公式,开箱即用。
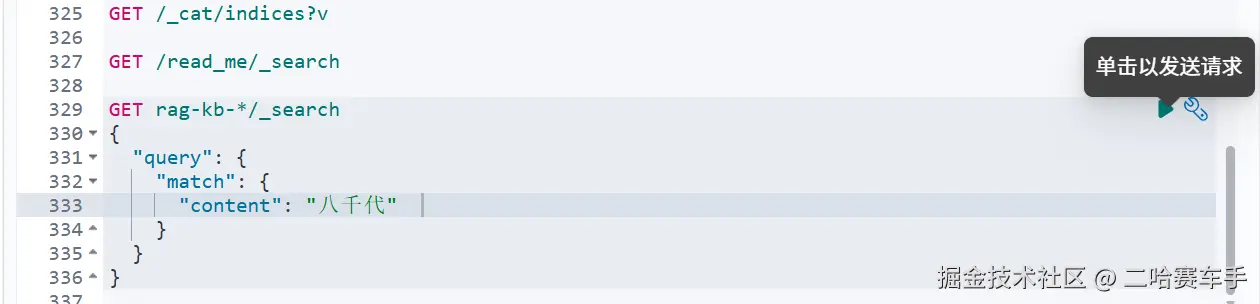

这里博主就不解释底层更深层的内容了,直接演示一下具体es是怎么打分的,当我们触发全文检索时才会触发打分,就像我们执行的**
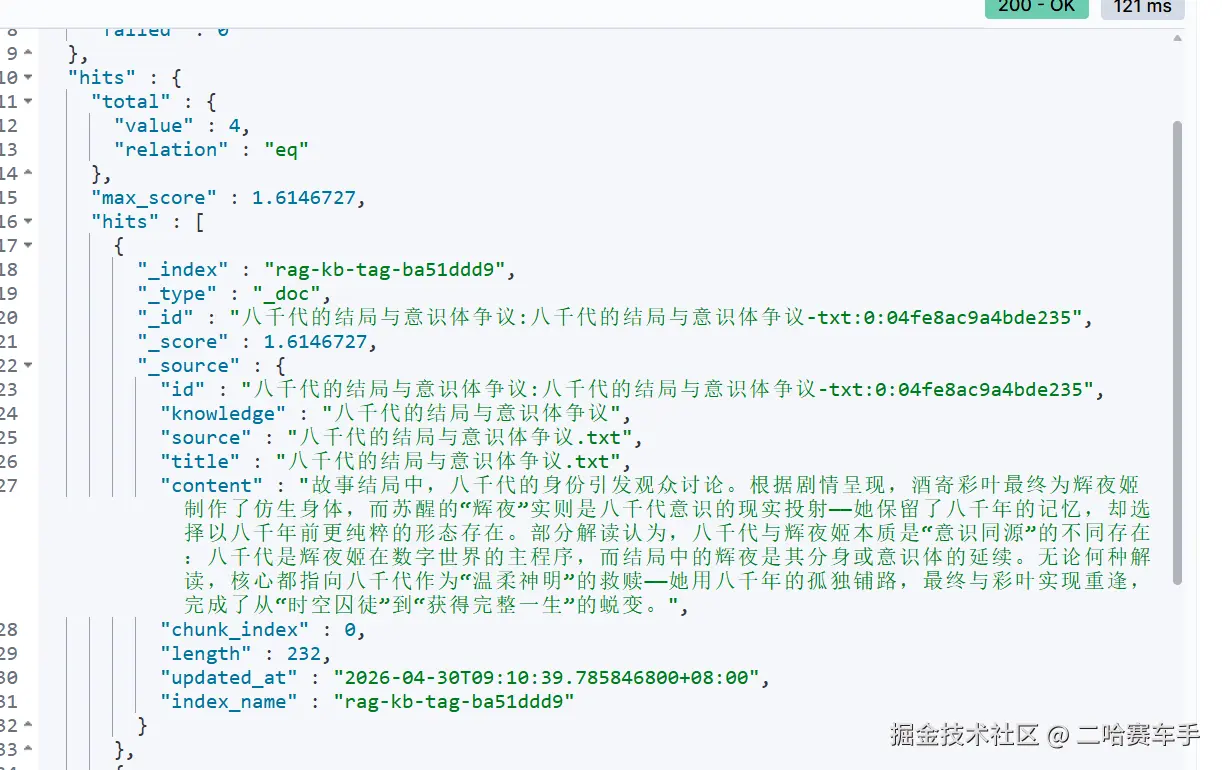
match:{content:"八千代"}**, 他会检索我们索引:rag-kb-*下的所有文档,通过分词检索所有词在文档中出现的频率,来为每个文档打分,图片中的score字段就是打分的分数
上面的查询语法到底做了什么?
java
GET rag-kb-*/_search
{
"query": {
"match": {
"content": "八千代" // 这是 match 查询!
}
}
}ES 会执行这几步:
- 把 "八千代" 分词 → 拆成:
八、千、代(或按你们分词器拆) - 去倒排索引里找 :只要 content 里包含任意一个字 / 词,就会被查出来
- 按 BM25 算分 :包含越多、越相关,
_score越高
✅ 能查到:
- 八千代
- 八千代产品
- 八千代配置
- 八千... 代...(中间有字也能命中)
❌ 不是必须整句完全一样才出来
6.解释疑惑:ES精确查询会打分吗,是不是触发查询就会打分,有哪些查询语法(博主自己对于ES打分机制的疑惑)
1. 核心结论(最重要)
只要是【全文检索查询】,就会触发 BM25 打分,就有 _score
只要是【精确过滤查询】,不打分,_score = 1.0 或者不计算
2. 精确查询会打分吗?
不会!
精确查询(比如
term/terms)不做相关性计算 ,它们只做:有 或 没有 ,匹配 或 不匹配。
所以:
- term 查询 = 不打分 = _score 固定为 1.0
- terms 查询 = 不打分 = _score 固定为 1.0
3. 什么查询才会触发 BM25 打分?
只有 全文检索(Full-text queries) 才会打分!
也就是你最常用的这些:会触发 BM25 打分(有 _score)
matchmulti_matchmatch_phrasequery_stringsimple_query_string
这些的特点:
- 会对输入文本分词
- 会计算相关性
- 会返回 _score 分数
- 底层 = BM25 算法
4. 哪些查询 不打分?(精确匹配类)
不打分(_score = 1.0)
term(精确等值)termsrangeexistsidsprefixwildcardregex
这些属于 过滤(filter) ,只判断是否符合条件,不做相关性排序。
5. 一句话区分:打不打分
分词 = 打分 = BM25
不分词 = 不打分 = 精确匹配
6. 你能用的所有查询语法(分类整理好)
🔥 会 BM25 打分(全文检索)
java
// match
{ "match": { "content": "八千代" } } #content字段包含"八千代","八","千" ...
// multi_match
{ "multi_match": { "query":"八千代", "fields":["title","content"] } }
// match_phrase(短语精确,但是会打分)
{ "match_phrase": { "content": "八千代" } }
// query_string
{ "query_string": { "default_field":"content", "query":"八千代 AND 配置" } }❌ 不打分(精确 / 过滤类)
java
// term 精确匹配
{ "term": { "content.keyword": "八千代" } }
// terms
{ "terms": { "content.keyword": ["八千代","八千代产品"] } }
// range
{ "range": { "createTime": { "gte": "2025-01-01" } } }
// wildcard
{ "wildcard": { "content": "*八千代*" } }7. 核心表
| 查询类型 | 例子 | 分词? | 打分? | 底层 |
|---|---|---|---|---|
| 全文检索 | match | ✅ | ✅ BM25 | 相关性搜索 |
| 全文检索 | multi_match | ✅ | ✅ BM25 | 相关性搜索 |
| 全文检索 | match_phrase | ✅ | ✅ BM25 | 短语搜索 |
| 全文检索 | query_string | ✅ | ✅ BM25 | 语法搜索 |
| 精确匹配 | term | ❌ | ❌ _score=1 | 过滤 |
| 精确匹配 | terms | ❌ | ❌ _score=1 | 过滤 |
| 过滤 | range | ❌ | ❌ _score=1 | 过滤 |
这里需要插上一嘴,所谓的
全文检索本质就是模糊查询,就是那些配备了ES分词器的字段,我们通过这些字段查询文本,就会触发全文检索
三.bm25机制具体实现
上面介绍完bm25的一些概念和ES的一些基本使用,现在来解释一下我们项目中是怎么实现的,能力有限,只能做个简陋版的(゚∀。)
1.先来介绍一下整体流程
java
┌─────────────────────────────────────────────────────────┐
│ RAG 检索流程 │
├─────────────────────────────────────────────────────────┤
│ Step 1: 向量相似度检索 │
│ - 使用 pgvector 进行语义检索 │
│ - 召回 Top-K 候选文档 │
│ │
│ Step 2: BM25 评分增强 │
│ - 使用 Elasticsearch 计算 BM25 分数 │
│ - 对候选文档重新排序 │
│ │
│ Step 3: 质量过滤 │
│ - 多样性控制 │
│ - 上下文装箱 │
│ - 返回最终文档 │
└─────────────────────────────────────────────────────────┘这里我是实现了整个RAG检索过滤策略,我们当前笔记只聚焦于BM25评分部分
2.引入依赖
java
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.17.28</version>
</dependency>我们使用的是ES较为底层的依赖,需要手动构建ES请求,后续好像是有封装好的高级依赖,但是注意这里面的依赖版本要与你的ES版本相同
3.配置ES的客户端工具
对于ES连接信息我们统一配置在配置文件中,方便管理
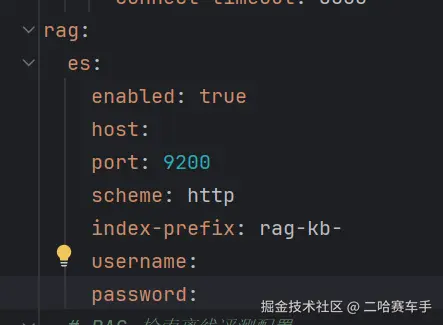
创建一个配置类,用于读取我们配置文件的数据,以后我们直接哪里需要,注入这个类即可,避免直接用@Value注解直接读取配置文件,而不好统一管理
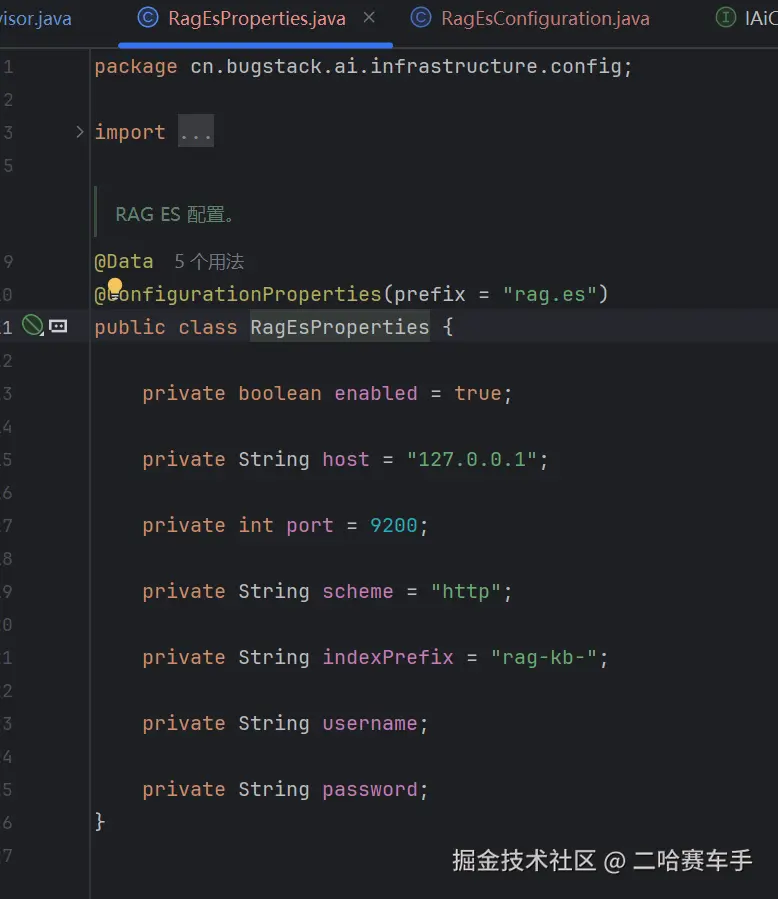
构建ES的客户端工具,我们在这里需要配置ES连接的一些信息,比如地址,端口号,如果ES设置了,这里也要配置密码,通过RestClient,我们就能通过java直接操作ES(这里面需要注入我们刚才的配置类来读取配置文件的配置)
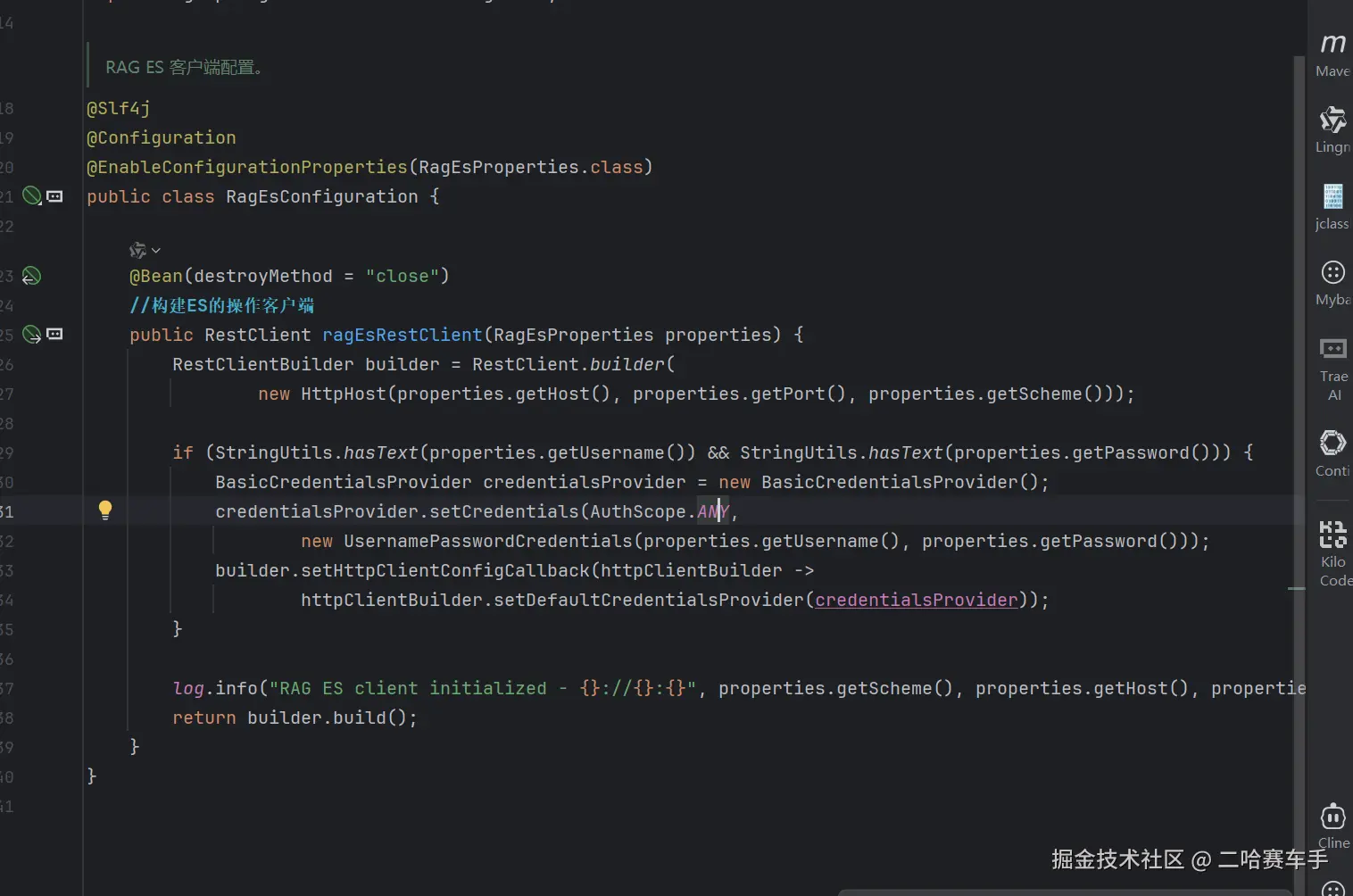
一句话总结
这段代码就是:创建一个连接 ES 的客户端工具,带账号密码、用完自动关闭。
1. 注解
java
@Bean(destroyMethod = "close")@Bean:交给 Spring 管理,项目一启动就创建这个对象destroyMethod = "close":项目停止时自动关闭 ES 连接,防止连接泄漏
2. 方法定义
java
public RestClient ragEsRestClient(RagEsProperties properties)- 返回值:
RestClient→ 就是你那个 elasticsearch-rest-client 客户端 - 参数:
RagEsProperties→ 存了 ES 的地址、端口、账号、密码
3. 创建连接
java
RestClientBuilder builder = RestClient.builder(
new HttpHost(
properties.getHost(), // ES IP
properties.getPort(), // ES 端口 9200
properties.getScheme() // http / https
)
);作用:告诉客户端要连哪个 ES 服务器。
4. 如果有账号密码,就加上登录验证
java
if (有用户名和密码) {
创建账号密码验证器
放进客户端
}你们 ES 设了密码,这里就自动带上登录。
5. 打印日志
java
log.info("RAG ES client initialized - {}://{}:{}", ...);启动时告诉你:ES 客户端已启动,连接的是哪个地址
6. 返回客户端
java
return builder.build();返回一个可以用的 ES 连接对象,全局共用这一个。
这里需要提一嘴,我们的RestClient注意一下不要注入错依赖了,我们这里指定注入的是ElasticSearch包下的依赖

4.创建专门的ES操作的接口(适配器)
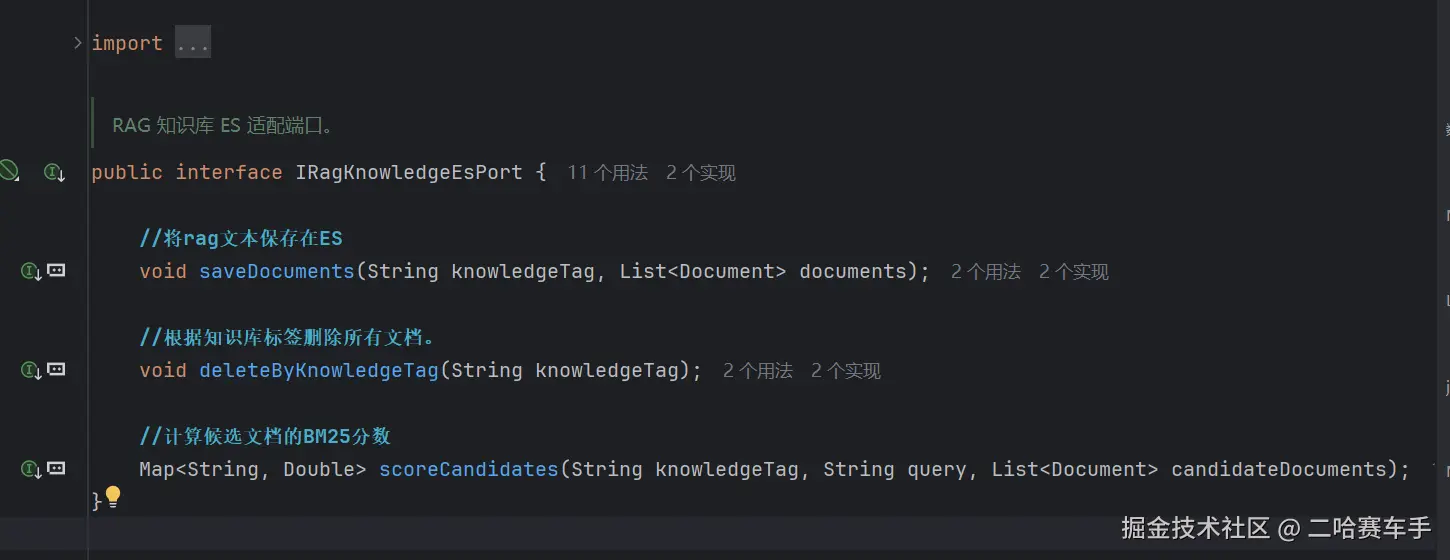
因为我们聚焦于bm25打分环节,所以后续会重点解释scoreCandidates方法
5.创建专门的ES评分类Bm25ScoringService
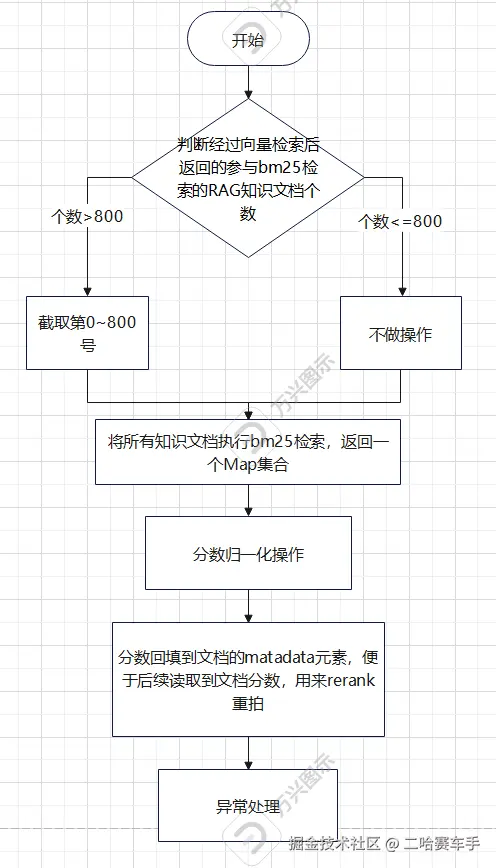
因为这部分代码交错纵横,直接展示源码不太好理解,所以我这里尽可能展示整个流程思维,主要还是理解思路,具体代码,目前都可以交给AI去解决,重要的还是把思路理解了
(1)我们先明确一下这个类的输入参数

- document:经过我们向量检索过滤的文档,简单说就是向量检索后符合用户问题的知识库文档,后续需要将这些文档进行bm25检索,为每个文档打分,后续rerank重排就是依据这些分数重排序的
- query:用户的问题,他是用来bm25检索的依据,比如用户问"八千代喜欢什么",他就会分词为"八千代","喜欢"等分词结果去我们的ES文档中去全文检索文档,然后给文档打分
- knowledgeTag(可跳过),这个可能不好理解,也是博主不想直接展示源码的原因,每个人的项目实现不一样,我这里介绍一下即可,他就是我们RAg知识库的向量文本的一个matadata标签元素,核心是快速过滤不同知识库的,下面我用几张图片展示一下,可以直接跳过,这里还是博主为了让自己理解自己项目的一下实现细节,防止忘记
首先我们项目每次上传rag知识库文档是需要注明文档的knowledgeTag属性的
对应的知识库的metedata元素,可以看见里面的knowledge字段,用于区分不同rag文档,比如RAG文档1上传后,不管切分成多少块,所有他切分成并存入知识库的RAG片段,他们的knowledge都指向RAG文档1,用于表明这些文档都是属于这个RAG知识库的
我们配置的顾问角色,会关联多个RAG知识库,这样只要一个client配备了该顾问,就有了检索多个RAG知识库的方式
对应的数据库的顾问表,本质还是通过关联knowledge的方式
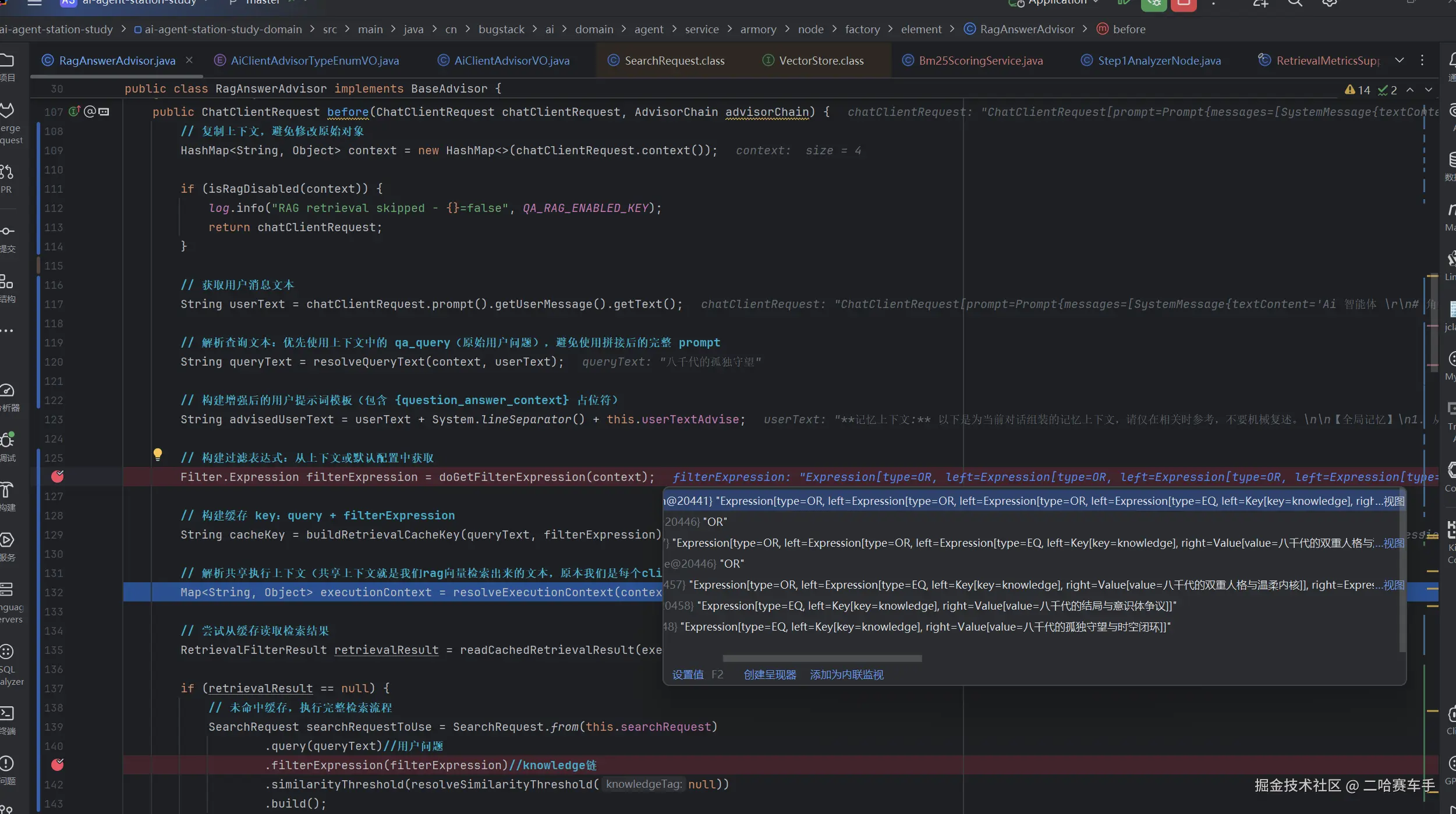
我们自定义的
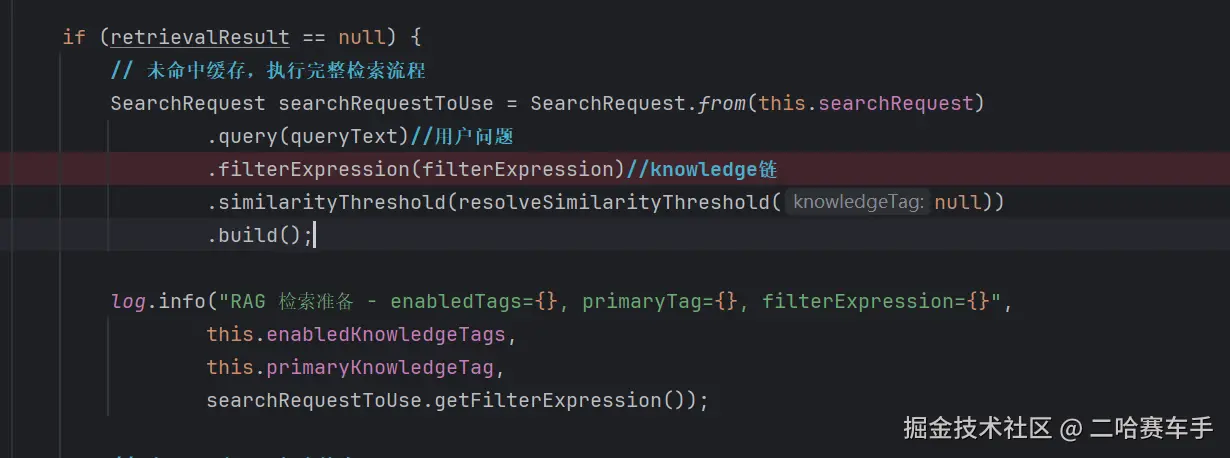
顾问类RAGAnwserAdvisor中实现自己的顾问创建,他会读取我们当前选中的client的对应的顾问表的ext_param字段,然后将所有关联的knowledge字段构建成一个filterExpression,然后封装到SearchRequest ,这里需要说明一下filterExpression设置的是要过滤的元标签属性,在进行向量检索时他会优先通过要筛出的元标签属性提前过滤掉一部分向量文本

将searchRequest注入到vector.similaritySearch方法中,进行相似度检索,他会优先通过filterExpression进行元标签metedata级别的过滤,过滤出我们当前client所关联的所有knowledge对应的RAG知识库,然后在这些知识库内进行相似度检索

向量检索后就会进行bm25检索,底层就会调用我们的
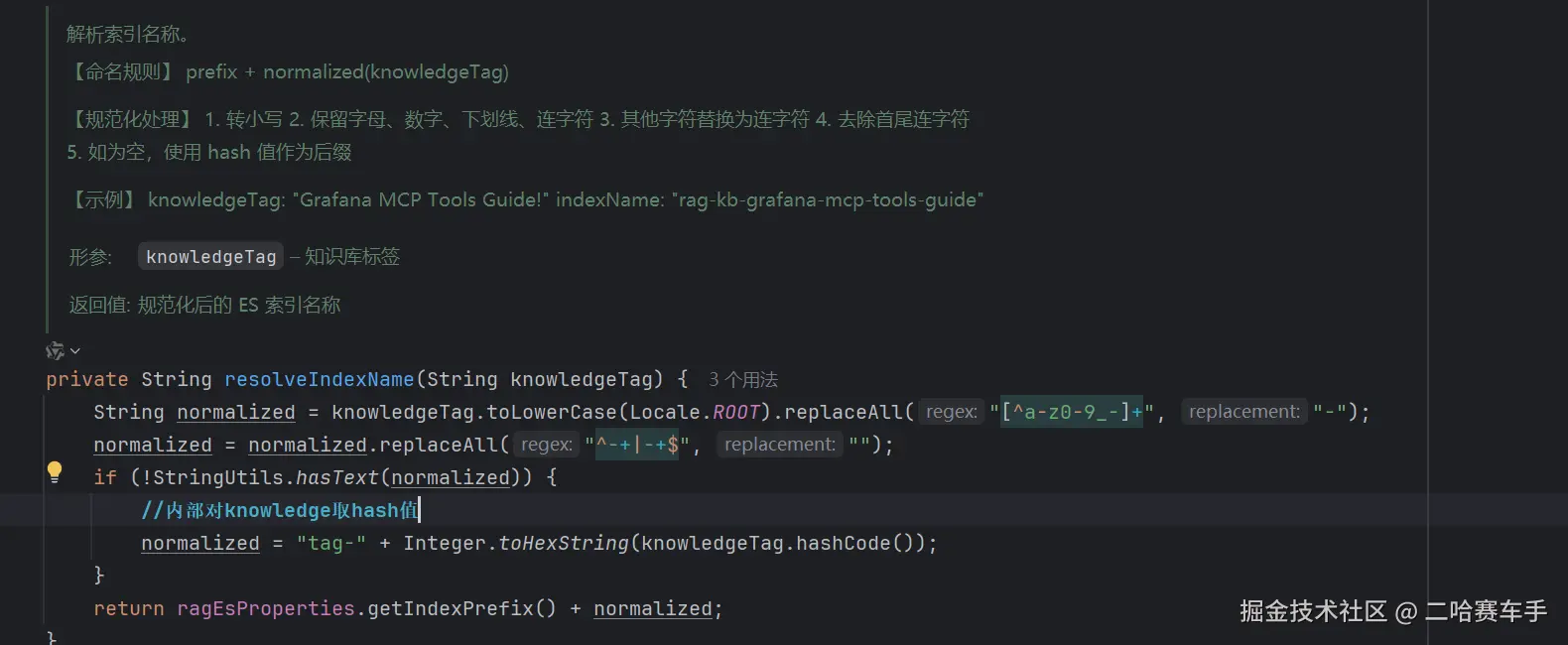
Bm25ScoringService,传递knowledge,至于为什么还需要传递knowledge参数,因为我们的ES文档的索引名命名规则是knowledge取Hash值进行命名的,核心原因还是为了让ES存储的文档与向量库中RAG文档通过knowledge字段进行关联,我们的RAG文档是一份存储在ES,一份存储在向量数据库,优点是我们要对向量检索的文档进行bm25打分时,我们只需要取出knowledge字段,进行Hash运算,就能快速查询到对应的ES的索引,从而取出内部的文档,进行全文索引

可以看见发送请求时需要指定要操作的索引名indexName

indexName是通过knowledge字段,调用resolveIndexName方法生成
(2)输入参数讲解完了,解释一下过滤逻辑
这很好理解,我们限制参与评分的RAG检索的向量知识片段,核心是避免太多rag文本一股脑塞给ai,以及减少ES的负担,为所有文档进行ES检索打分太耗费性能
(3)bm25检索逻辑
内部会调用我们的
RagKnowledgeEsAdapterES适配器类,它实现了我们上文提及的ES接口,是他的实现类,这里就会调用scoreCandidates方法进行打分
java
@Override
public Map<String, Double> scoreCandidates(String knowledgeTag, String query, List<Document> candidateDocuments) {
// 前置校验:ES 未启用、参数非法、候选文档为空时直接返回空 Map
if (!ragEsProperties.isEnabled() || !StringUtils.hasText(knowledgeTag) || !StringUtils.hasText(query) || CollectionUtils.isEmpty(candidateDocuments)) {
return Map.of();
}
String indexName = resolveIndexName(knowledgeTag);
try {
// 确保索引存在,如不存在则自动创建
ensureIndexExists(indexName);
// ========== 步骤1:提取候选文档 ID ==========
// 遍历候选文档,提取每个文档的唯一标识
// 文档 ID 用于 ES 查询的 ids filter,限定查询范围
List<String> candidateIds = new ArrayList<>();
for (Document document : candidateDocuments) {
String documentId = resolveDocumentId(document, knowledgeTag);
if (StringUtils.hasText(documentId)) {
candidateIds.add(documentId);
}
}
// 无有效文档 ID 时返回空 Map
if (candidateIds.isEmpty()) {
return Map.of();
}
// ========== 步骤2:构建 ES 查询请求体 ==========
Map<String, Object> queryBody = new LinkedHashMap<>();
// 设置返回文档数量上限(等于候选文档数,确保能返回所有命中文档)
queryBody.put("size", candidateIds.size());
// 指定返回的字段列表(减少网络传输,只取必要字段)
queryBody.put("_source", List.of(
RagDocumentMetadataKeys.KNOWLEDGE,
RagDocumentMetadataKeys.SOURCE,
RagDocumentMetadataKeys.TITLE,
RagDocumentMetadataKeys.CHUNK_INDEX,
RagDocumentMetadataKeys.LENGTH
));
// ========== 步骤3:构建 bool 查询 ==========
// bool 查询包含两部分:filter(过滤,不评分)和 should(评分,不做强门禁)
Map<String, Object> bool = new LinkedHashMap<>();
// filter 子句:限定查询范围,不计算相关性分数,可缓存,性能优化
List<Object> filters = new ArrayList<>();
// filter 1:按知识库标签过滤,确保只在目标知识库中查询
// 使用 match 查询替代 term,避免中文分词问题
filters.add(Map.of("match", Map.of(RagDocumentMetadataKeys.KNOWLEDGE, knowledgeTag)));
// filter 2:按文档 ID 列表过滤,实现"候选集后过滤"模式
filters.add(Map.of("ids", Map.of("values", candidateIds)));
bool.put("filter", filters);
// should 子句:计算 BM25 相关性分数,允许部分命中
List<Object> shoulds = new ArrayList<>();
shoulds.add(Map.of("multi_match", Map.of(
"query", query,
"fields", List.of(
RagDocumentMetadataKeys.TITLE + "^3",
"content^1",
"tags^2"
),
"type", "best_fields",
"operator", "or"
)));
shoulds.add(Map.of("match_phrase", Map.of(
"content", Map.of(
"query", query,
"boost", 2.0
)
)));
bool.put("should", shoulds);
// 【关键设计】minimum_should_match: 0
// 原因:BM25 只负责"候选集内加分",不做强门禁
// 中文分词后,查询词可能被拆分,要求至少命中一个词容易误杀语义相关但关键词不完全匹配的文档
// 改为 0 后:完全匹配得高分,不完全匹配得 0 分但不会被过滤,最终由启发式重排综合决定
bool.put("minimum_should_match", 0);
queryBody.put("query", Map.of("bool", bool));
// 强制返回 _score 字段(ES 默认在某些情况下可能不返回)
queryBody.put("track_scores", true);
// ========== 步骤4:执行 ES 查询 ==========
Request request = new Request("POST", "/" + indexName + "/_search");
request.setJsonEntity(JSON.toJSONString(queryBody));
Response response = execute(request);
String body = readResponse(response);
// ========== 步骤5:解析响应并提取分数 ==========
JSONObject jsonObject = JSON.parseObject(body);
JSONObject hits = jsonObject.getJSONObject("hits");
if (hits == null) {
return Map.of();
}
JSONArray hitArray = hits.getJSONArray("hits");
if (hitArray == null || hitArray.isEmpty()) {
return Map.of();
}
// 提取每个命中文档的 ID 和 BM25 分数
Map<String, Double> scores = new LinkedHashMap<>();
for (int i = 0; i < hitArray.size(); i++) {
JSONObject hit = hitArray.getJSONObject(i);
if (hit == null) {
continue;
}
String id = hit.getString("_id"); // 文档唯一标识
Double score = hit.getDouble("_score"); // ES 计算的 BM25 分数
if (StringUtils.hasText(id) && score != null) {
scores.put(id, score);
}
}
return scores;
} catch (Exception e) {
// 异常处理:记录警告日志,返回空 Map,不阻断主流程
log.warn("RAG ES bm25 scoring failed - knowledgeTag={}, index={}", knowledgeTag, indexName, e);
return Map.of();
}
}这里还是不好理解,其实这一步我们就是在层层构建ES的查询请求,最终构建的形式类似于
java
【ES 查询 DSL 结构】
{
"size": candidateCount,
"_source": ["knowledge", "source", "title", "chunk_index", "length"],
"query": {
"bool": {
"filter": [
{"term": {"knowledge": "grafana-mcp-tools-guide"}},
{"ids": {"values": ["doc1", "doc2", ...]}}
],
"should": [
{"multi_match": {"query": "如何配置", "fields": ["title^3", "content^1"], "operator": "or"}},
{"match_phrase": {"content": "如何配置"}}
],
"minimum_should_match": 0
}
},
"track_scores": true
}
这里演示了一下我们是如何构建出来上方的请求格式的,其实只要记住每一层
{}对应一个Map,每一层[]对应一个List
JSON 本质就是「键值对 + 嵌套键值对」,而 Java 里的 Map(尤其是 HashMap)就是天然的键值对容器,两者的结构完全对齐:
| 概念 | JSON | Java Map |
|---|---|---|
| 键值对 | "key": "value" |
map.put("key", "value") |
| 嵌套对象 | "query": { "bool": { ... } } |
Map query = new HashMap();``Map bool = new HashMap();``query.put("bool", bool); |
| 数组 | "filter": [ { ... }, { ... } ] |
List filter = new ArrayList();``filter.add(对象1);``filter.add(对象2); |
所以这段 DSL,本质上就是一层一层的 Map + List 嵌套。
当我们们把层级关系构建好后,直接通过是 JSON 序列化工具(Jackson/Gson)就可以自动转换成上图的json格式
java
JSONObject jsonObject = JSON.parseObject(body);其实理解了上一步,就已经讲解完了构造请求的方式,这里解释一下ES语法构造
"size": candidateCount
返回多少条结果(比如 5、10、20)
"_source": [xxx]
只返回需要的字段,不返回大段 content
- 快
- 省流量
- 安全
"bool"(多条件查询)
组合查询:filter + should 一起用
最重要:filter 干什么?(精确过滤,不打分)
java
"filter": [
{"term(精确查询)": {"knowledge": "grafana-mcp-tools-guide"}},
{"ids": {"values": ["doc1", "doc2"]}}
]作用:
先把范围缩小(先查询出符合文档id范围与knowledge字段的ES文档,作用是提前进行ES过滤)!
- 只查这个知识库:grafana-mcp-tools-guide
- 只查这些文档 ID:doc1、doc2......
特点:
- 精确匹配
- 不打分
- 速度极快
- 先过滤,再检索
这里需要讲解一下我们我们的RAG的向量文档元数据metedata中存储了一份ES对应的RAG文档id
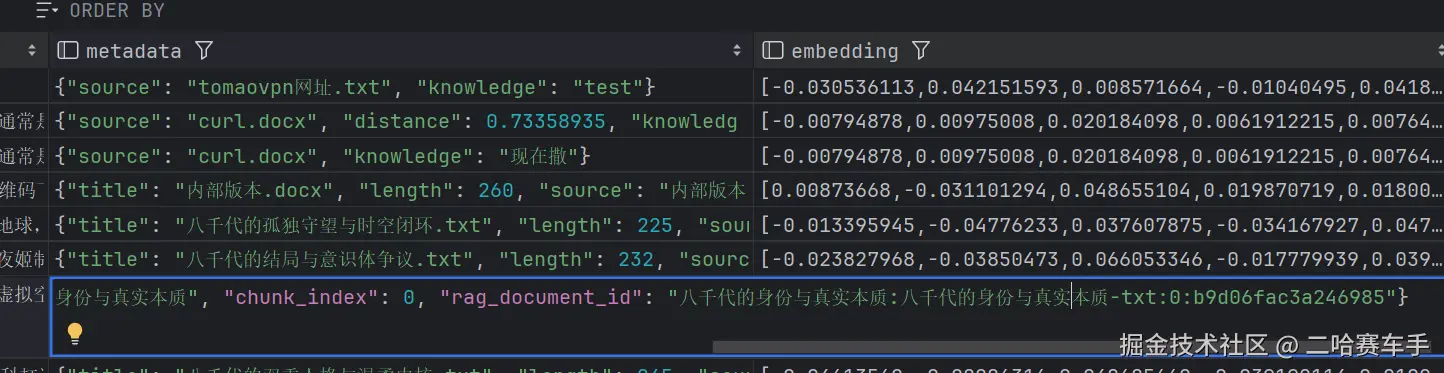
又因为该ES文档的索引与knowledge字段相同,所以我们可以通过取出当前打分向量的knowledge字段与文档id,来快速限定参与打分的ES文档,避免ES全索引扫描

具体的ES的RAG文档存储结构
第二重要:should 干什么?(BM25 打分,OR 逻辑)
- 第一个条件:
multi_match
java
{
"multi_match": {
"query": "如何配置",
"fields": ["title^3", "content^1"],
"operator": "or"
}
}这是多字段加权的模糊匹配,是你们 BM25 打分的核心:
-
"query": "如何配置":要匹配的关键词。 -
"fields": ["title^3", "content^1"]:- 同时在
title和content两个字段里搜索; ^3/^1是权重:标题命中的分数权重是 3,内容命中是 1。也就是说:标题里出现 "如何配置",比内容里出现,分数要高 3 倍,会被优先排前面。
- 同时在
-
"operator": "or":只要分词后的词(如 "如何" 或 "配置")有任意一个命中,就算匹配,就会给分。
这里涉及的加分规则原因是,如果我们的ES文档的
title标题选项分词后符合用户的原始问题,那么就说明整个文档与用户的相似度比较高,类似于如果用户问"Mysql机制",ES的文档title为"Mysql机制与工作原理",那么我们通过title标题就可以判断出该文档内容更加偏向于用户问题,ES加的分自然就会更多
作用:给文档做一个 "基础的 BM25 相关性打分",标题权重更高,符合用户习惯 ------ 标题命中的内容通常更相关。
- 第二个条件:
match_phrase
java
{
"match_phrase": {
"content": "如何配置"
}
}这是短语精确匹配:
- 要求
content字段里,必须连续、按顺序出现完整的 "如何配置" 这四个字,中间不能有其他字隔开。 - 比如 "如何配置 Grafana" 可以命中,但 "如何安装并配置 Grafana" 就不会命中。
作用 :给那些完全命中用户原始提问短语的文档额外加分,把 "字面完全匹配" 的文档顶到最前面。
为什么要两个条件一起写?
| 查询方式 | 特点 | 作用 |
|---|---|---|
multi_match |
模糊匹配 + 标题加权 | 做基础的相关性排序,兼顾语义和字段权重 |
match_phrase |
精确短语匹配 | 给完全命中关键词的文档额外加分,提升精准度 |
- 文档标题命中 → 基础分就很高;
- 内容里还连续出现完整短语 → 再加一次分,总分更高;
- 既兼顾了 "标题优先" 的用户习惯,又给了 "完全命中" 的文档更高权重。
满足任意一个就加分,满足越多分数越高
解释一下如何将构建好的ES请求发送给ES

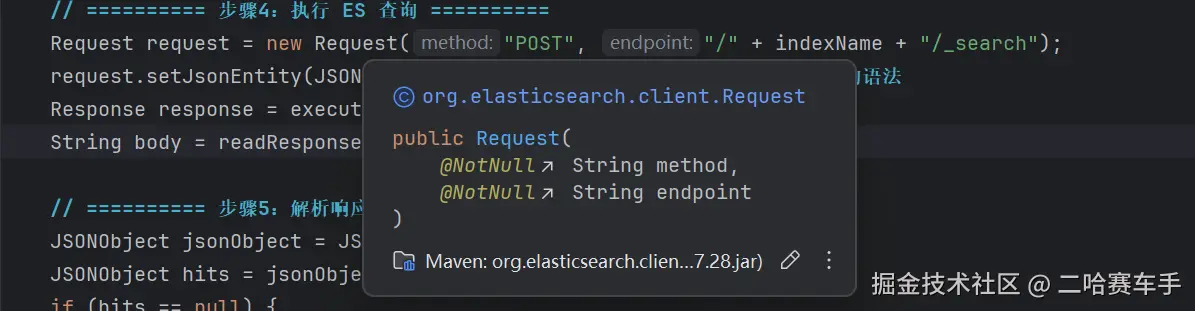
这里是需要先构建Request,可以看见我们的Request来自ES依赖,他需要指定我们ES的请求方式与endpoint,然后将我们设置好的ES的语法
queryBody,通过request.setJsonEntity(JSON.toJSONString(queryBody))封装到request,执行我们的execute方法
ES 的 endpoint 是什么?
一句话:**ES 的 endpoint = 你要访问 ES 的哪个 "接口地址"**就像网站的 URL 地址。
- 解释
java
POST /_bulk
GET /rag-kb-*/_search
GET /_cat/indices
PUT /my-index斜杠 / 后面的这一串,就是 endpoint
它告诉 ES:你要干什么?
- 你们项目里最常见的 4 个 endpoint(必须记住)
1)/_search
查询数据(你们 RAG 检索用得最多)
java
GET rag-kb-*/_search作用:查 BM25、向量检索、混合检索
2)/_bulk
批量写入 / 更新 / 删除
java
POST /_bulk作用:知识库文档批量导入
3)/{index}/_doc/{id}
单条写入 / 查询
java
PUT rag-kb-test/_doc/14)/_cat/indices
查看索引
java
GET /_cat/indices- endpoint 格式固定规律
java
/索引名/操作名例如:
java
/rag-kb-*/_search
→ 索引:rag-kb-*
→ 操作:_search 查询
java
/_bulk
→ 索引:无(全局批量)
→ 操作:_bulk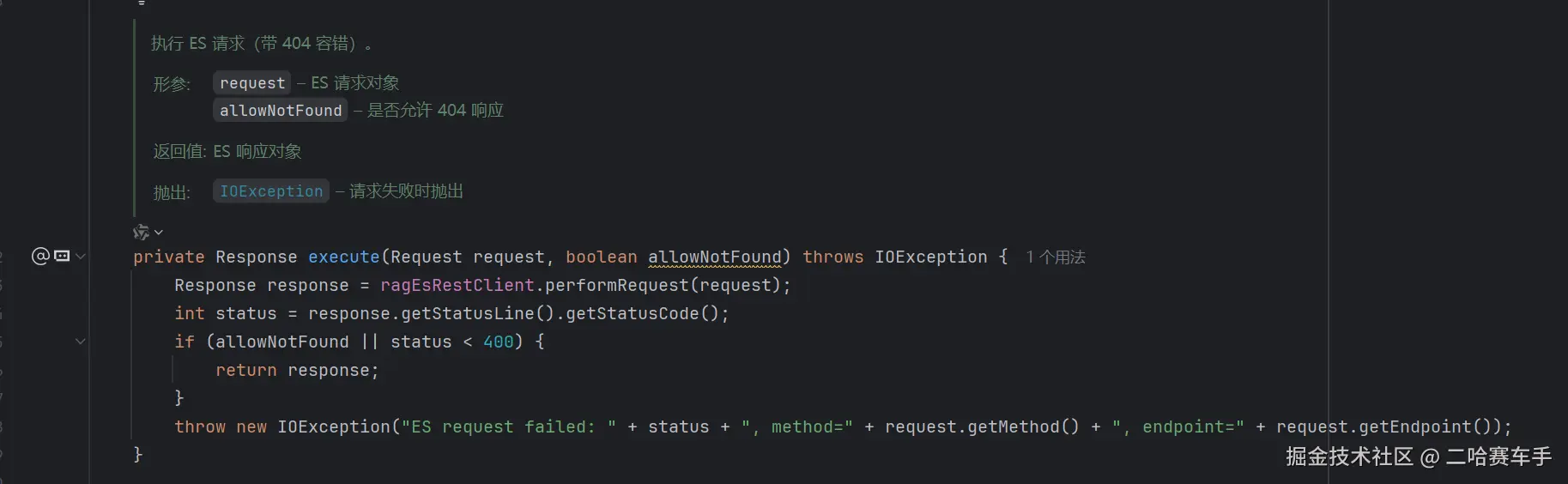
可以看见我们的execute方法底层就会调用
ragEsRestClient的performRequest()方法,传递我们封装好的ES的请求参数request,就会发送ES请求,这里需要说明一下这里的ragEsRestCLient就是我们上面构建好的ES的RestCLient
这里解释一下ES的Request和Restclient的关系
-
RestClient = 快递员(负责送信)
-
Request = 信件 / 包裹(里面写了你要干嘛)
- RestClient 是干啥的?
RestClient = 快递员
- 它负责和 ES 建立连接
- 负责把信送过去
- 负责把包裹拿回来
- 它不写内容,只管运输
java
RestClient ragEsRestClient就是全局唯一的快递员,项目启动就创建,一直用它。
- Request 是干啥的?
Request = 你写给 ES 的一封信 / 一个包裹信上必须写 3 件事:
- 用什么方式送(GET/POST)
- 送到 ES 哪个窗口(endpoint:_search/_bulk)
- 信里写了什么内容(JSON/DSL)
java
Request request = new Request("GET", "/rag-kb-*/_search");
request.setJsonEntity(你的查询DSL);- 它们俩配合起来干啥?
快递员(RestClient)拿着信件(Request)去 ES 办事!
流程:
- 你写好 Request(信)
- 交给 RestClient(快递员)
- 快递员发给 ES
- ES 执行(查询 / 写入)
- 快递员拿回 Response(回信 / 结果)
代码就是:
java
Response response = restClient.performRequest(request);简单说就是restclient用来封装要连接的ES的端口,密码,账号等等,与ES建立连接,接受request封装的ES请求语法,执行,并且取回ES的返回数据,封装在response中,而request就是用来封装具体的ES的请求,包括请求方式(post),请求语法,endpoint
最后一步就是解析ES的响应结果并且取出score
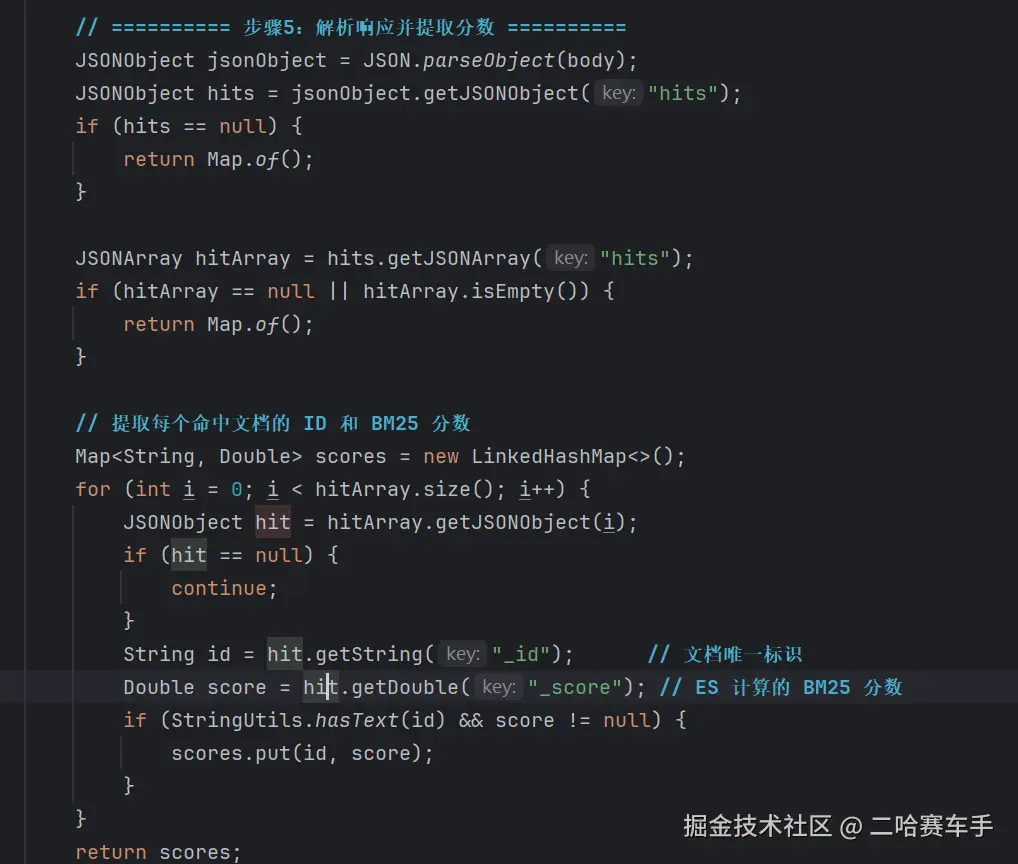
这一段不好理解,我们层层解释
- 把 ES 返回的字符串 → 转成 JSON 对象
java
JSONObject jsonObject = JSON.parseObject(body);body= ES 返回的原始 JSON 字符串- 转成
JSONObject= 方便一层一层取数据
- 取出外层的
hits(所有命中结果的大容器)
java
JSONObject hits = jsonObject.getJSONObject("hits");ES 返回格式固定长这样:
java
{
"took": 1,
"hits": { <-- 就是取这一层
"total": ...,
"hits": [ ... ]
}
}- 如果没有 hits,直接返回空
java
if (hits == null) {
return Map.of();
}- 取出真正的文档数组
hits.hits
java
JSONArray hitArray = hits.getJSONArray("hits");这就是你查到的所有文档列表:
java
"hits": {
"hits": [ <-- 就是这个数组
{ "_id": "xxx", "_score": 1.2, "_source": { ... } },
{ "_id": "yyy", "_score": 1.0, "_source": { ... } }
]
}对应的ES结构
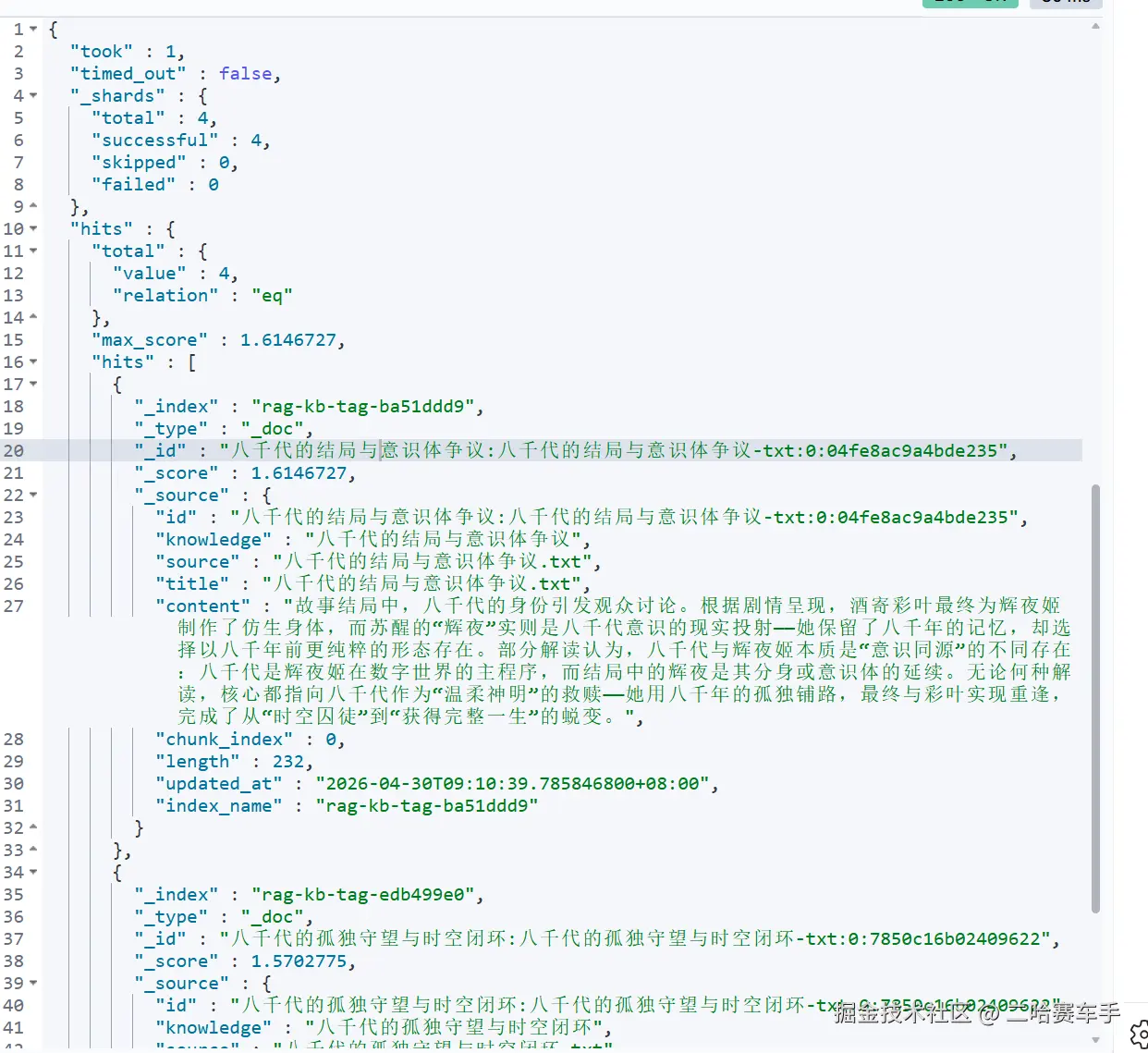
就是先取出最外层的hits字段,再取出他内部的hits字段(是一个数组,包括所有参与评分的ES文档),我们需要调用
JSONArray hitArray = hits.getJSONArray("hits");来获取这个数组,取出内部的_score字段,将他连同文档_id,封装成一个MAP集合,返回调用方,后续通过MAP集合就能快速查到该文档的bm25检索分数
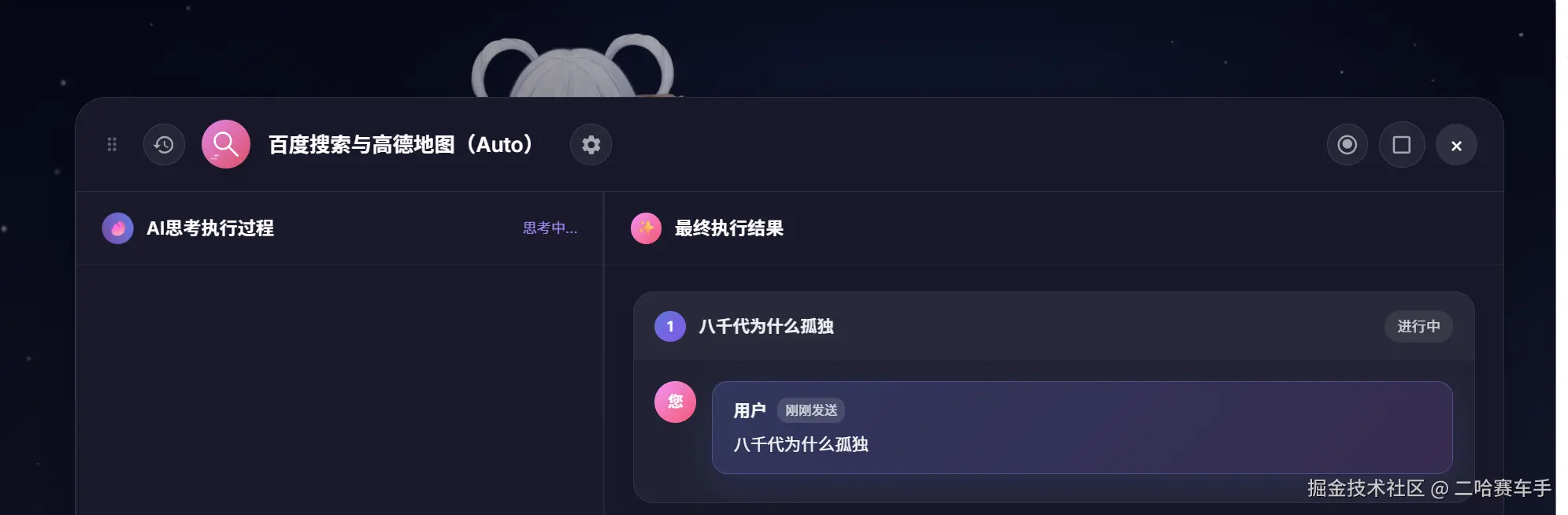

做个测试:这里可以看见,当博主询问"八千代为什么孤独",我们可以看见"八千代的孤独守望与时空闭环"文档的评分明显比其他文档高
(4)分数归一化操作
核心问题:分数不可比
| 场景 | bm25评分 |
|---|---|
| 查询A | 2.5 |
| 查询b | 7.5 |
我们ES打分机制与向量不一样,ES是文档越精准,分数越高,不局限于0-1分,而我们向量相似度是局限于0-1,如果不归一化,无法与向量分数(0~1)融合!,比如我们文档A的向量分数0.6,ES评分7.5,文档B分别为0.4和11.2,如果直接累加,那么文档B分数更高,这是有问题的,ES分数与向量分数他们本身区别就很大,就像上面的文档B,即使向量分数低,但是ES分数足够高那就完全可以忽略向量分数,对于后续的rerank按照分数重排的影响很大
具体原因
1. 向量分数范围
java
// pgvector 相似度
double vectorScore = 0.85; // 范围:0 ~ 12. BM25 分数范围
java
// ES 返回的 BM25 分数
double bm25Score = 5.23; // 范围:不确定,可能是 0 ~ 100+3. 直接融合的问题
java
// 错误:0.6 * 0.85 + 0.4 * 5.23 = 2.602
// BM25 分数太大,主导了最终结果!
// 正确:0.6 * 0.85 + 0.4 * 0.75 = 0.81
// 两个分数都在 0~1 范围,权重才有效解释一下我们归一化怎么操作的
场景:4 个文档的 BM25 分数
java
文档ID 原始分数
─────────────────────
doc-001 2.5
doc-002 5.0
doc-003 10.0
doc-004 7.5步骤 1:找 min 和 max
java
min = 2.5 (doc-001)
max = 10.0 (doc-003)
range = max - min = 10.0 - 2.5 = 7.5步骤 2:逐个计算归一化分数
公式 : normalized = (rawScore - min) / range
| 文档 ID | 原始分数 (ES _score) | 计算过程:(分数 - 最小分) / (最大分 - 最小分) |
归一化结果 |
|---|---|---|---|
| doc-001 | 2.5 | (2.5 - 2.5) / (10.0 - 2.5) = 0 / 7.5 | 0.0 |
| doc-002 | 5.0 | (5.0 - 2.5) / (10.0 - 2.5) = 2.5 / 7.5 | 0.333 |
| doc-003 | 10.0 | (10.0 - 2.5) / (10.0 - 2.5) = 7.5 / 7.5 | 1.0 |
| doc-004 | 7.5 | (7.5 - 2.5) / (10.0 - 2.5) = 5.0 / 7.5 | 0.667 |
java
文档ID 原始分数 归一化分数
─────────────────────────────────
doc-003 10.0 1.0 ← 最高分
doc-004 7.5 0.667
doc-002 5.0 0.333
doc-001 2.5 0.0 ← 最低分特殊情况:所有分数相同
java
原始分数:{doc1: 5.0, doc2: 5.0, doc3: 5.0}
range = 5.0 - 5.0 = 0 ← 触发特殊情况
结果:{doc1: 0.5, doc2: 0.5, doc3: 0.5}原因 :避免除以 0,同时不放大同分候选的差异。
与向量分数融合
java
文档 向量分数(0-1) BM25归一化(0-1) 融合(6:4)
─────────────────────────────────────────────────
doc-003 0.80 1.0 0.6*0.80 + 0.4*1.0 = 0.88
doc-004 0.85 0.667 0.6*0.85 + 0.4*0.667 = 0.
767
doc-002 0.75 0.333 0.6*0.75 + 0.4*0.333 = 0.
583
doc-001 0.70 0.0 0.6*0.70 + 0.4*0.0 = 0.42我们这里可以手动设置bm25,向量分数的加权比例,比如bm25占3成,那么bm25分数再
x0.3,这样可以手动控制总分的计算
对应项目源码
java
private Map<String, Double> normalizeCandidateScores(Map<String, Double> scores) {
// 步骤1:计算候选集内的 min 和 max
double min = Double.POSITIVE_INFINITY;
double max = Double.NEGATIVE_INFINITY;
for (Double value : scores.values()) {
if (value == null || Double.isNaN(value) || Double.isInfinite(value)) {
continue;
}
min = Math.min(min, value);
max = Math.max(max, value);
}
double range = max - min;
// 步骤2:处理特殊情况(所有分数相同)
if (range <= 1.0e-9D) {
// 同分情况返回 0.5,避免放大差异
for (Map.Entry<String, Double> entry : scores.entrySet()) {
Double value = entry.getValue();
if (value != null && !Double.isNaN(value) && !Double.isInfinite(value)) {
normalized.put(entry.getKey(), value > 0D ? 0.5D : 0D);
}
}
return normalized;
}
// 步骤3:标准 min-max 归一化
// 公式:(value - min) / (max - min)
for (Map.Entry<String, Double> entry : scores.entrySet()) {
Double value = entry.getValue();
if (value != null && !Double.isNaN(value) && !Double.isInfinite(value)) {
double normalizedValue = (value - min) / range;
// 确保结果在 [0, 1] 范围内
normalized.put(entry.getKey(), Math.max(0D, Math.min(1D, normalizedValue)));
}
}
return normalized;
}(5)分数回填到文档metedata元素
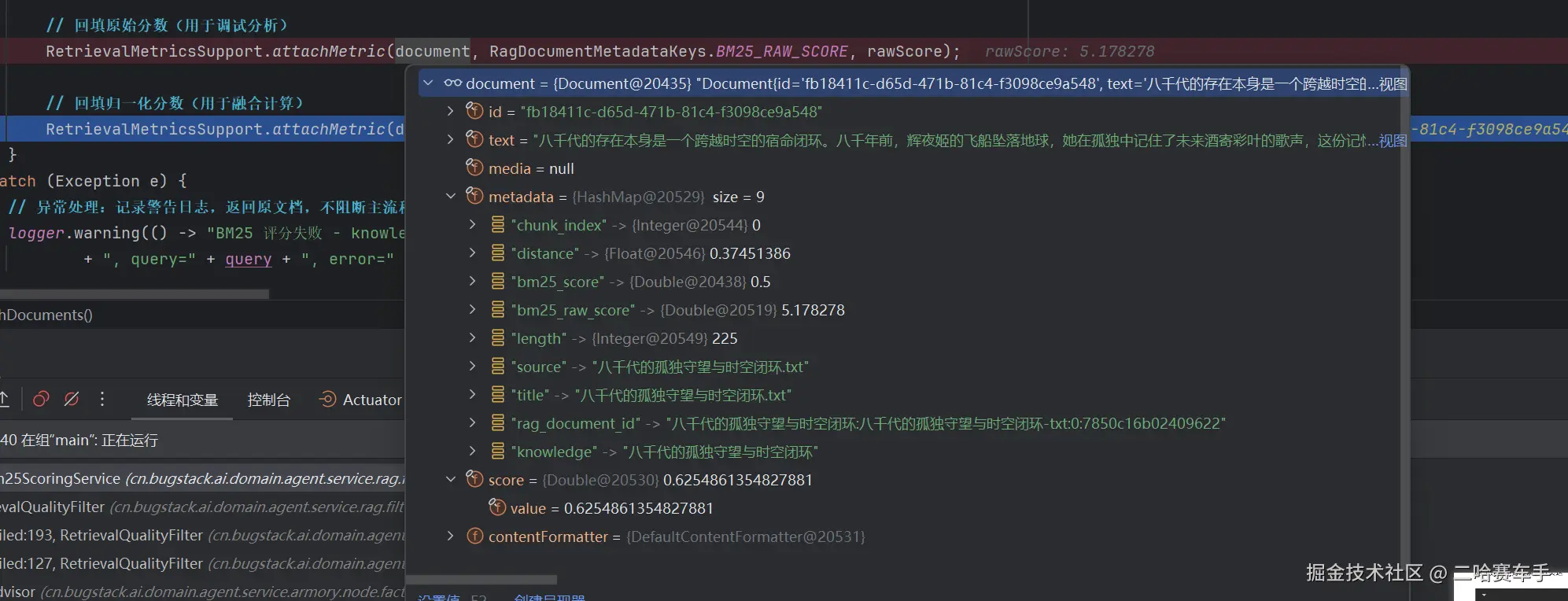
可以看见文档metadata属性成功填入原始bm25分数(
bm25_raw_score)与归一化的分数(bm25_score),这样做的好处还是后续rerank重排时直接从文档中就可以提取分数了,不过这一部分是博主自己项目的实现,实际做起来有很多种存放分数的方法,这里只是提供思路,至此bm25环节结束
四:补充点(可忽略,关于ES文档思路上传方面内容)
java
用户上传文档
│
▼
┌─────────────────────────────────────────┐
│ 1. 文档解析(RagService) │
│ - 读取文件内容 │
│ - 分块(Chunking) │
│ - 生成 embedding │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 2. 双写存储 │
│ ├──→ pgvector(向量存储) │
│ │ - 存储:id, content, embedding, metadata
│ │ - metadata 包含:knowledge, source, title...
│ │ │
│ └──→ Elasticsearch(BM25 索引) │
│ - 存储:id, content, tags, title...
│ - 索引名:rag-kb-tag-{hash}
│ - 用于 BM25 评分
└─────────────────────────────────────────┘我们项目是在RAG上传时,会统一调用
RagService这个类,内部的storeRagFile方法就是用来切割RAG文本,存储到ES和向量数据库
java
@Override
public RagUploadResultVO storeRagFile(String name, String tag, List<MultipartFile> files) {
int totalDocumentCount = 0;
String ragId = "rag_" + java.util.UUID.randomUUID().toString().replace("-", "").substring(0, 12);
// 处理文件上传(如果有文件)
if (files != null && !files.isEmpty()) {
for (MultipartFile file : files) {
// 解析文档内容
TikaDocumentReader documentReader = new TikaDocumentReader(file.getResource());
List<Document> documentList = tokenTextSplitter.apply(documentReader.get());
// 噪音过滤 - 根据文件类型智能清洗
int originalCount = documentList.size();
documentList = noiseFilter.filterNoise(documentList, file.getOriginalFilename());
int filteredCount = documentList.size();
// 创建知识库文档元数据,供 pgvector 与 ES 双写共享
for (int i = 0; i < documentList.size(); i++) {
// 为每个文档片段添加知识库标签
RagDocumentMetadataSupport.applyBaseMetadata(documentList.get(i), tag, file.getOriginalFilename(), i);
}
// RAG文件存储到向量数据库
vectorStore.accept(documentList);
// RAG文件存储到ES数据库
ragKnowledgeEsPort.saveDocuments(tag, documentList);
totalDocumentCount += documentList.size();
log.info("知识库文件上传完成 - 名称: {}, 标签: {}, 文件: {}, 原始片段: {}, 过滤后: {}",
name, tag, file.getOriginalFilename(), originalCount, filteredCount);
}
} else {
log.info("创建空知识库配置 - 名称: {}, 标签: {}", name, tag);
}我需要说明一下,我们RAG文档是需要同步上传到ES的,原因是我们向量数据库检索返回文档时,我们ES需要依次找到对应的向量文档,这就需要我们在ES也存储一份,我们通过向量文本的元数据标签
rag-document-id来快速与ES文档建立联系,后续我们需要为向量文本打分时,也是通过该字段定位到ES文档,这样ES才能对文档打分
java
用户查询:"八千代为什么孤独"
│
▼
┌─────────────────────────────────────────┐
│ Step 1: pgvector 向量检索 │
│ - 用 embedding 找语义相似的文档 │
│ - 返回 Top-K 候选文档 │
│ - 包含 metadata(knowledge, source...) │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 2: ES BM25 评分 │
│ - 用候选文档的 ID 列表查询 ES │
│ - 计算 query 与文档的 BM25 分数 │
│ - 只在这 K 个文档中评分(候选集后过滤) │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 3: 融合排序 │
│ - 向量分数(40%)+ BM25 分数(20%) │
│ - 其他启发式因子(40%) │
│ - 返回最终排序结果 │
└─────────────────────────────────────────┘具体上传到ES的代码贴出来了,仅供参考!,这只是一部分,大家了解一下即可
java
@Override
public void saveDocuments(String knowledgeTag, List<Document> documents) {
// 【前置校验】检查 ES 是否启用、知识库标签是否有效、文档列表是否非空
// 任一条件不满足直接返回,避免不必要的处理
if (!ragEsProperties.isEnabled() || !StringUtils.hasText(knowledgeTag) || CollectionUtils.isEmpty(documents)) {
return;
}
// 【解析索引名】根据知识库标签生成 ES 索引名(规范化处理 + 前缀拼接)
// 例如:knowledgeTag="Grafana Guide" → indexName="rag-kb-grafana-guide"
// 索引名:rag-kb-<knowledgeTag>(自动规范化)(类似于数据库表名,通过索引模式快速查询)
String indexName = resolveIndexName(knowledgeTag);
try {
// 【确保索引存在】如索引不存在则自动创建,避免 bulk 操作失败
ensureIndexExists(indexName);
// 【构建 bulk 请求体】使用 StringBuilder 拼接 NDJSON 格式数据
// ES bulk API 要求格式:{"index":{...}}\n{文档内容}\n{"index":{...}}\n{文档内容}\n
StringBuilder bulkBody = new StringBuilder();
for (Document document : documents) {
// 【单文档校验】跳过 null 或空内容文档,保证数据质量
if (document == null || !StringUtils.hasText(document.getText())) {
continue;
}
// 【生成文档 ID】优先从 metadata 读取,不存在则基于内容哈希生成
// 确保与 pgVector 中的文档 ID 一致,支持跨存储关联
String documentId = resolveDocumentId(document, knowledgeTag);
// 【构建索引源数据】将 Spring AI Document 转换为 ES 索引字段
// 包含:knowledge, source, title, content, tags, chunk_index 等
Map<String, Object> source = buildIndexSource(document, knowledgeTag, indexName, documentId);
// 【拼接 index 元数据行】指定索引名和文档 ID,先拼接操作指令
bulkBody.append(JSON.toJSONString(Map.of("index", Map.of("_index", indexName, "_id", documentId)))).append('\n');
// 【拼接文档内容行】实际的索引数据
bulkBody.append(JSON.toJSONString(source)).append('\n');
}
// 【空数据检查】如所有文档都被过滤,无需发送请求
if (bulkBody.isEmpty()) {
return;
}
// 【执行 bulk 请求】使用 ES _bulk API 批量索引文档
// 相比单条索引,bulk 可大幅减少网络往返,提升写入性能
Request request = new Request("POST", "/_bulk");
request.setJsonEntity(bulkBody.toString());//传递我们构建好的ES语法
//发送ES批量索引请求,将所有文档的索引操作打包成一个请求,发送到ES
execute(request);
log.info("RAG上传到ES文档索引成功 - knowledgeTag={}, index={}, count={}", knowledgeTag, indexName, documents.size());
} catch (Exception e) {
// 【异常处理】记录警告日志但不抛异常,避免影响主流程(向量存储已成功)
log.warn("RAG上传到ES文档索引失败 - knowledgeTag={}, index={}", knowledgeTag, indexName, e);
}
}做个功能测试
这里我们上传产品手册的RAG文档
日志显示文档上传成功
向量数据库显示有数据,因为该文档太长,他文档切分时会切成两个子文档存放,这涉及到不同的RAG切分策略了,我们用的是按照token切分

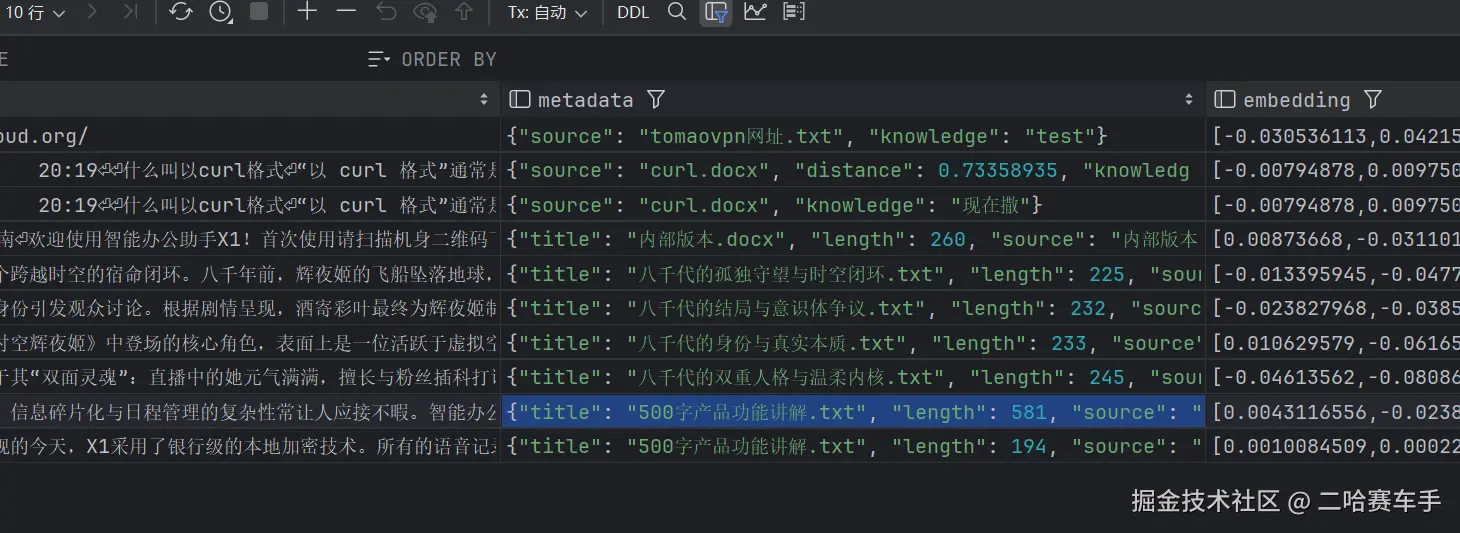
对应ES也上传成功了
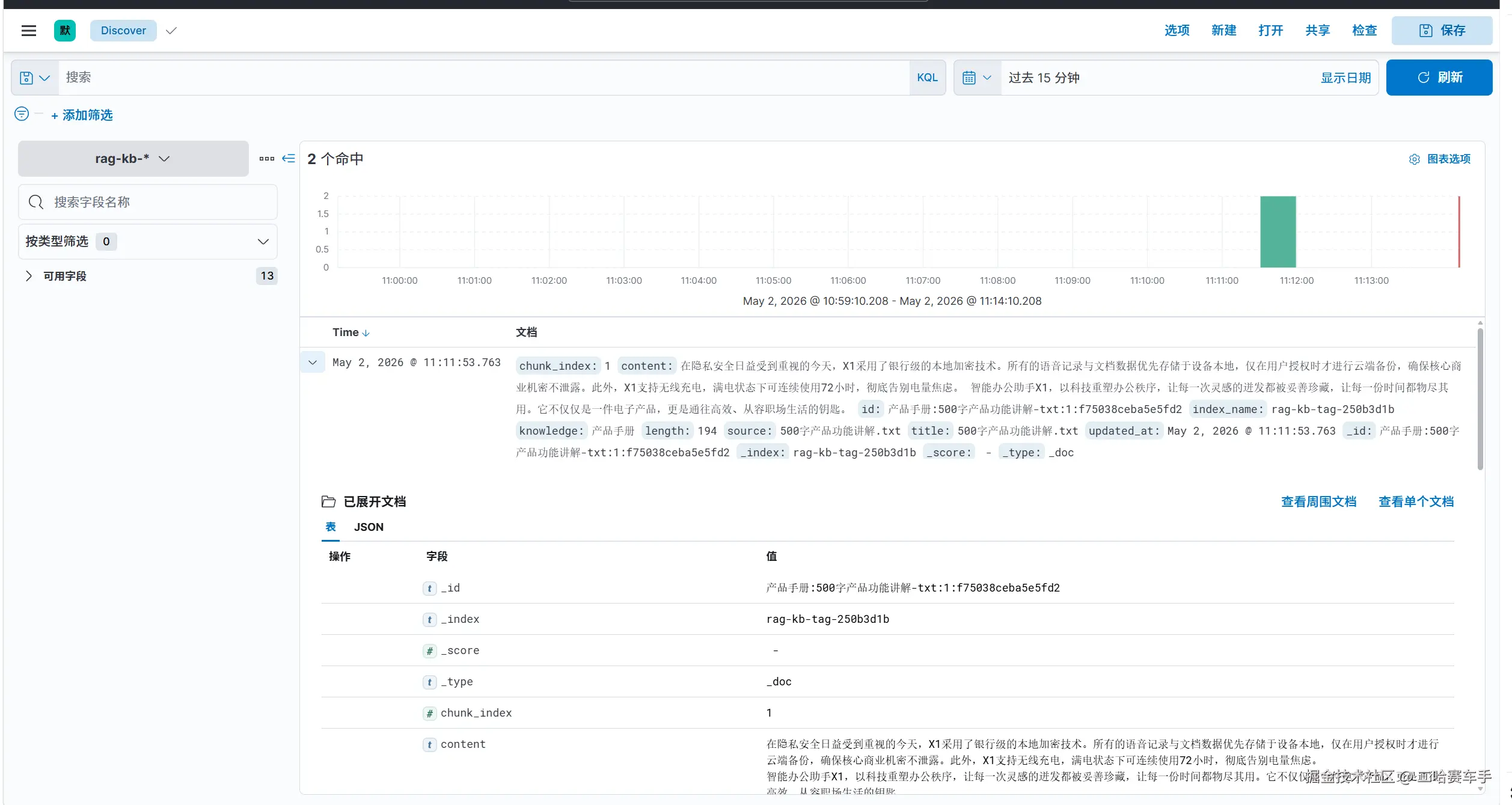
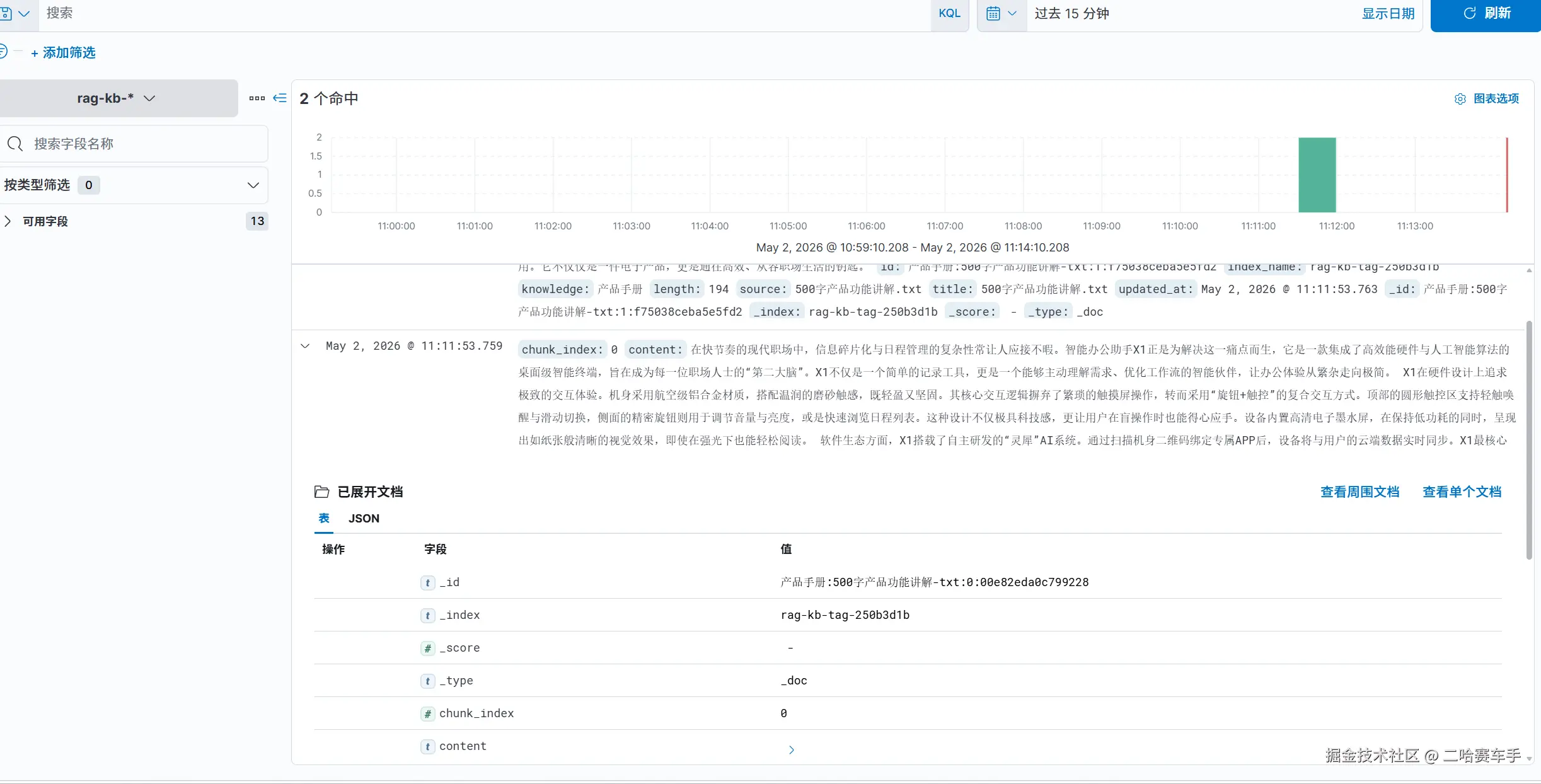
关联的knowledge字段和rag_document_id也能对的上


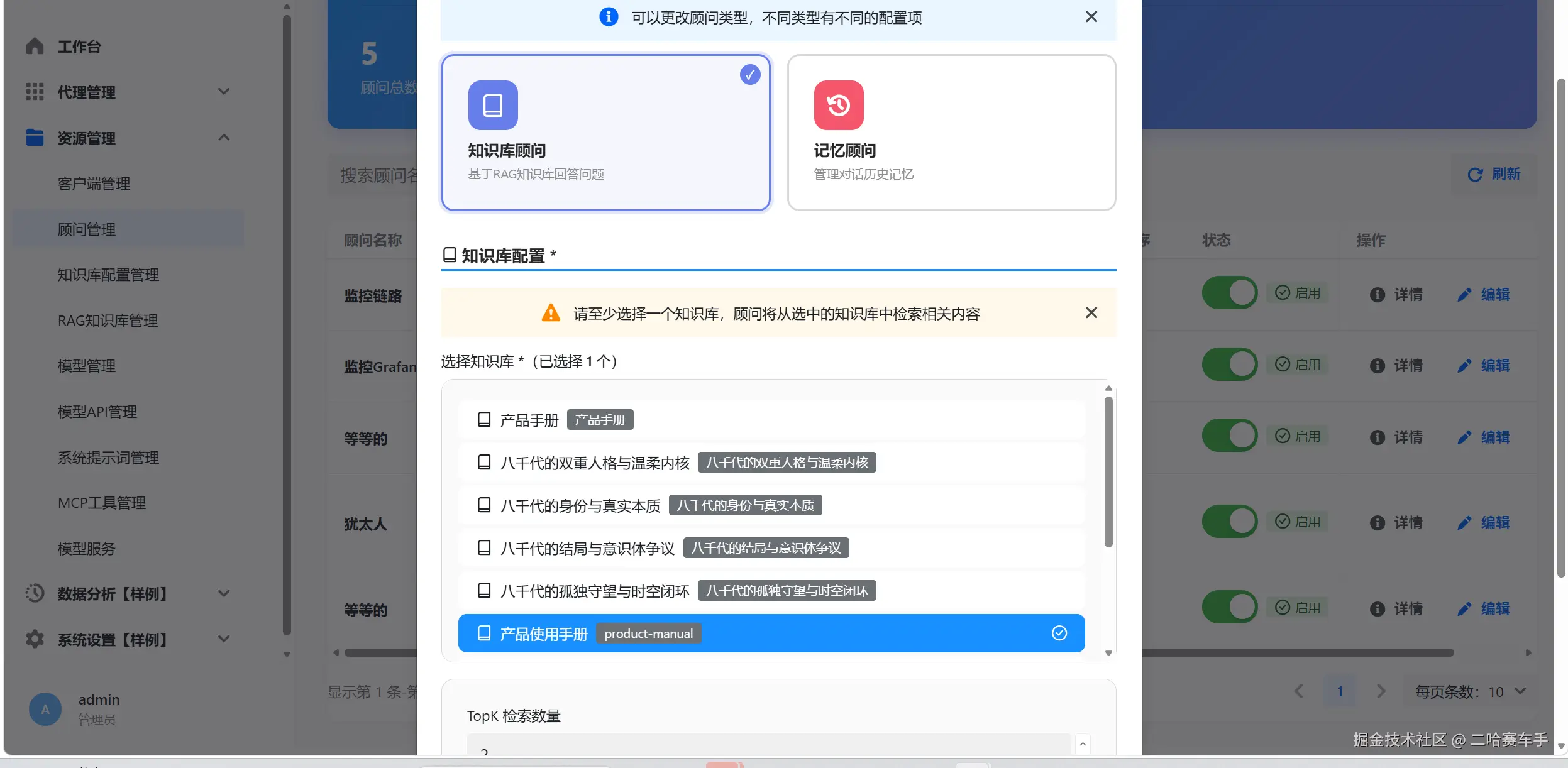
对应的前端管理页面也能查询和使用新上传的文档
五:总结(可忽略,关于博主的一些心得)
其实对于RAG知识库检索策略这一块,博主其实一开始也是个新手,不了解这些,只会背八股文,博主也才是个入门玩家,但是在看八股文的时候,我就发现他们的这些RAG处理确实好,就像bm25和向量检索的结合,确实妙,博主想到为什么不用在自己的项目呢,但是太太太难了,对于一个什么都不了解的新手,要接触ES,kibana,配置等等,语法连接,具体实现思路,但是博主不会的就一点一点问AI,去了解,查Bug,一点一点去结合AI去完善,中间也出现了一些ES的泄密问题,最后也终于实现了这个功能。对于哪些像博主的新人,我挺推荐大家将八股文中的一些好的思路融入项目的,不会的一点一点去让AI教你,或者查文档,一点一点调试,最后其实都能做好的,不过可能会耗费很多时间,博主做这篇笔记的原因也是为了梳理一下整个项目的思路,大家如果也想实现类似功能肯定也能做好的(ง๑ •̀_•́)ง