导读
本周,美团基础研发平台发布了《美团 BI 在指标平台和分析引擎上的探索和实践》一文,详细披露了其BI平台基于云器Lakehouse的引擎升级探索与实践。作为国内头部互联网公司的核心数据基础设施,美团的这一技术选型与实践经验,对于整个行业具有较高的参考价值。
本文将系统解读此次实践的完整技术图谱。读完本文,您将收获:
- 顶级BI平台的演进逻辑
看懂美团BI平台从Lambda架构向统一引擎演进的真实路径------一个支撑万亿级数据量的平台,在面对数据不一致、资源利用率低、架构臃肿三大痛点时,核心的架构思考与取舍。 - 生产级数据Infra的破局思路
当开源组件无法满足生产级的稳定性、性能与成本要求时,如何找到出路?本文将剖析云器Lakehouse如何以"湖上原地加速"为核心,结合Kappa架构、Virtual Cluster虚拟集群共享等新技术,在美团生产环境中实现规模化落地。 - 可量化的"三个三分之一"
- 性能翻三倍:同等资源下,关键查询与分析场景性能提升至原来的3倍;
- 架构精简三分之二:三套异构引擎整合为一套统一引擎,运维复杂度显著下降;
- 可插拔零改造升级:不搬数据、不改SQL、不迁任务,平台升级不再是"伤筋动骨",而是"按需插拔"。
无论您正在主导数据架构升级,还是持续关注湖仓一体、实时分析的前沿实践,本文都将提供一份来自一线的深度参考。
当前BI平台的架构现状与核心痛点
很多企业的BI平台⻓期处在⼀种"离线数仓 + 多套分析/查询引擎 + 上层⼯具拼接"的状态:离线侧⽤Spark/Hive 做⽣产,交互侧⽤ Presto/Trino 做联邦与即席查询,低延迟侧再叠⼀套 OLAP/ClickHouse 之类 MPP 引擎来顶住看板与报表。
这类架构在业务规模不⼤时能跑起来,但⼀旦进⼊"指标平台(Metrics Platform)驱动"的阶段,痛点会被显著放⼤。
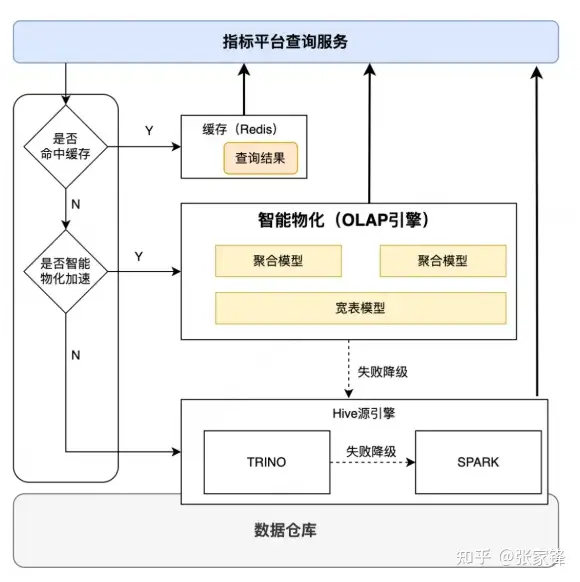
传统BI+指标平台的典型架构
1.1 多引擎同步导致的数据一致性问题
- 同⼀份数据在多引擎间复制/同步,导致⼝径、时效、数据版本难以统⼀。
- 回刷、补数、重算时,多链路同步会把"⼯程问题"变成"组织问题"(谁负责、谁兜底)。
1.2 Serving与Ad-hoc的负载冲突:为何一套引擎难以兼顾
- Serving(运营看板、固定⼝径报表)追求亚秒到秒级延迟,典型靠 MPP/Pipeline、预聚合、缓存。
- Ad-hoc(分析师探索、复杂Join、多维下钻)追求规模与灵活性,传统依赖 BSP/Stage(Spark⼀类)兜底。
- 两类负载在性能⽬标、资源形态、容错⽅式上天然冲突,导致"不得不多引擎"。
Serving场景和Ad-hoc场景查询特征对比:
|-----------|-----------|----------|
| 对比纬度 | Serving场景 | Ad-hoc场景 |
| 指标组合和筛选条件 | 固定 | 灵活 |
| 数据规模 | 小(GB级别) | 大(GB~TB) |
| SQL逻辑复杂度 | 简单 | 复杂 |
| 响应时间要求 | 亚秒~秒 | 秒~分钟 |
| 调度架构 | MPP | MPP/BSP |
1.3 多引擎并存的运维成本与开发负担
- 各引擎采用独立的技术体系和 SQL 方言,业务团队需要针对不同引擎维护多套查询逻辑、UDF 函数,开发效率大幅降低;
- 技术团队需同时掌握多种引擎的运维知识,每月投入大量人力维护多引擎集群,且故障定位时需分别排查各引擎状态,问题处理效率低;
- 为适配多引擎,企业还需额外开发查询转发适配层
- 针对BI终端用户,需要屏蔽不同引擎语法差异,需要团队实现统一的语法转换层。
1.4 资源孤岛、潮汐效应与稳定性风险
- 业务负载具有明显"潮汐效应",但传统实例化集群往往按峰值预留资源,低峰浪费严重。
- MPP 在⾼并发临界点容易出现"性能悬崖";同时⼤查询可能打满资源影响整体 SLA。
1.5 指标平台转型驱动下的新增计算压力
- **复杂 JOIN 计算:**原子指标定义在数仓明细层,复杂指标拆解后,查询 SQL 需面向海量数据,事实表与维表的频繁关联导致大量 JOIN 操作;
- **自动生成 SQL 性能差:**查询 SQL 由语义服务自动生成,逻辑正确但结构冗余、嵌套层次深,无人工优化空间,执行效率低;
- 计算量指数级增加: 同环比、占比等常用分析语义由查询服务即时生成,而非传统 BI 中的固化结果,大幅增加了引擎的实时计算压力。
1.6 存量SQL资产与迁移成本:引擎升级的隐性门槛
BI平台沉淀的是"业务资产",主要以 SQL/UDF/权限模型存在。引擎升级若需要⼤规模改写,会直接让升级不可推进。
下图⽤"个性化数据集驱动"与"指标平台驱动"对⽐,能直观看到:指标平台试图把上层消费统⼀ 到"指标层",但同时也意味着查询形态更复杂、Join更多、SQL更像机器⽣成代码,对底座提出更极端的要求。
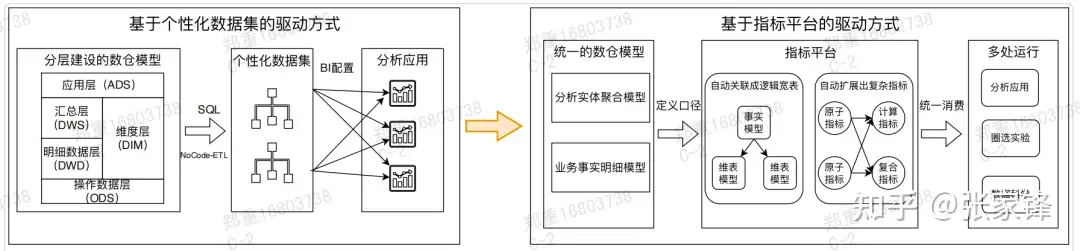
指标平台驱动 vs 个性化数据集驱动
新一代BI平台对底层引擎的核心诉求
如果把新⼀代BI平台理解为"⾯向⽤数"的基础设施,那么它对底层引擎的理想诉求可以概括成⼀句话: ⼀份存储、⼀套元数据、⼀个引擎、⼀套资源池、⼀套语法,⽀撑多场景应⽤,同时保障平台升级的平滑性和业务连续性。
将这句话拆开,会得到⼀组可落地的"理想型"能⼒清单(也是美团实践中被反复验证的关键点):
|----|---------------------------------|---------------------|--------------------------------------|
| 序号 | 新一代 BI 平台核心解决的问题 / 需求 | 底层引擎核心能力要求 | 核心技术支撑 |
| 1 | 兼顾 Serving+Ad-hoc 双模看数场景,消除场景割裂 | 具备双模执行能力,一套引擎支持多场景 | 双模执行引擎 + 自适应调度 |
| 2 | 彻底解决多引擎数据不一致、口径不统一问题 | 统一存储 + 统一元数据管理+统一计算 | 开放表格式 + 元数据标准 + 数据版本+Single-Engine |
| 3 | 保障生产环境稳定性,实现查询失败 / 超时的无缝切换 | 完善的自动降级能力 | 同源降级 + 异构降级 + 智能 Fallback |
| 4 | 解决资源孤岛问题,实现高并发下的资源隔离与弹性 | 资源弹性及稳定性保障 | Virtual Cluster(虚拟集群)+ 智能路由 |
| 5 | 应对复杂计算、大计算量挑战,提升执行效率 | 高性能引擎支撑多 workload | C++ 向量化执行 + 通用增量计算 + 存储优化 |
| 6 | 不中断业务、不增加迁移成本,实现平台平滑升级 | 嵌入式架构,原地提速 | 外表机制 + 标准生态对接 + 不搬数据 / 不改 SQL / 不迁任务 |
新一代 BI 平台的底层引擎,本质上需要从 "多引擎堆叠"向"一体化统一引擎"转型,同时具备场景适配性、性能效性、资源弹性、升级平滑性 四大特征,成为支撑企业 "用数" 的核心基础设施。
云器Lakehouse的技术方案:六项核心能力如何逐一应对
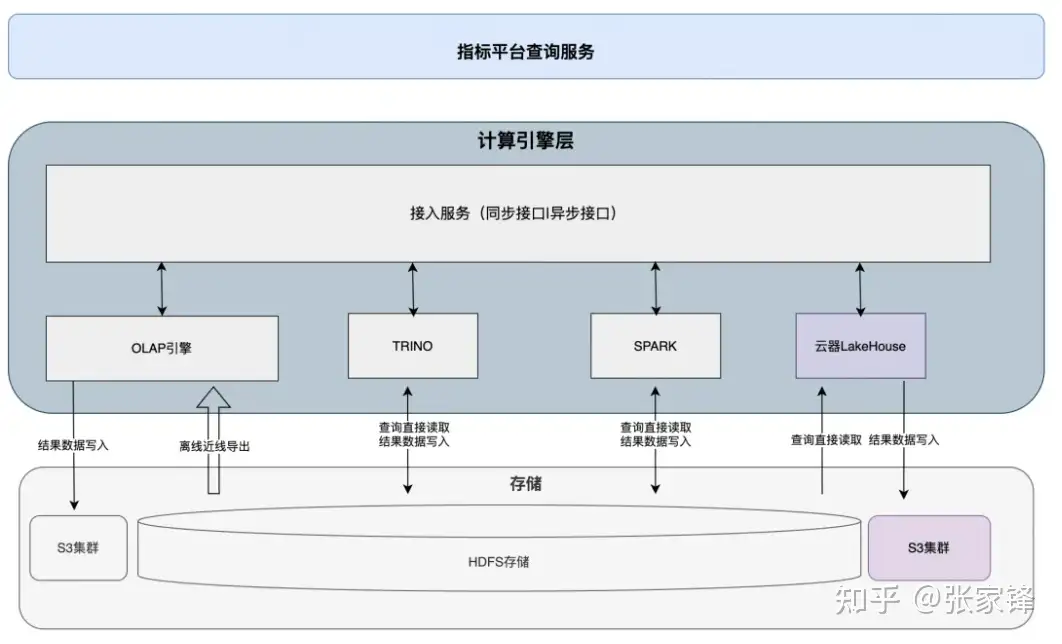
云器 Lakehouse 以Single-Engine 单引擎架构 为核心,通过支持双模执行、高性能向量化计算、通用增量计算、自动降级策略、嵌入式架构、Virtual Cluster 虚拟集群 六大核心技术创新,全面满足新一代 BI 平台对底层引擎的所有能力要求,从根本上解决传统 Lambda 架构的痛点,实现了计算范式和架构设计的双重突破。以下重点解读单一引擎支持多模执行、自动降级策略、高性能引擎、嵌入式架构等核心技术领域。
3.1 Single-Engine :统一引擎支持多场景,消除双模割裂
- 云器LH 一个引擎内内置两种执⾏模式,可自由选择及切换:
- BSP/DAG:⾯向批处理、实时加工与复杂作业等场景,强调容错与吞吐。
- MPP/Pipeline:⾯向交互查询,强调低延迟。
- **关键不在"两种执行模式",⽽在同⼀套系统内的⾃适应调度与统⼀治理:**同一张表,同一个元数据,同一个引擎,同一个SQL,⽤⼾提交的是同⼀类查询接⼝,系统按特征选择执⾏路径。
3.2 高性能引擎:向量化计算与增量计算的协同优化
云器 Lakehouse 打造了全链路优化的高性能计算引擎 ,以C++ 向量化 执行为核心,结合通用增量计算、分层多级自适应存储、编译优化等技术,从计算、存储、执行三个维度实现性能提升,可高效应对指标平台的复杂计算、大计算量挑战,相比传统 Java 引擎,性能实现数量级提升,是开源 Spark 的 10 倍,完美解决了自动生成 SQL 性能差、复杂 JOIN 计算效率低的问题。
1、C++ 向量化执行引擎:硬件能力的极致利用
向量化执行是现代分析型数据库的核心技术,云器 Lakehouse 采用全 C++ Native 实现的列式向量化引擎,彻底摒弃传统 Java 引擎的设计,从根本上解决 JVM 性能瓶颈,实现三大核心优化:
- **批处理替代逐行处理:**摒弃传统火山模型的逐行处理方式,每个算子一次处理 1024/4096 行的批量数据,大幅减少函数调用开销,提升 CPU 利用率;
- **列式存储适配 SIMD 指令:**数据以列式格式存储,同类型数据连续排列,可原生支持 AVX-512 等 CPU SIMD 指令集,一条指令可同时处理多个数据元素,充分利用现代硬件的并行计算能力;
- **消除 JVM 性能损耗:**C++ 引擎可直接操作内存,消除了 JVM 的 GC 停顿、JNI 调用开销,对于文件读写、内存分配等底层操作,性能优势显著。
2、通用增量计算(GIC):全新计算范式,大幅减少计算量
通用增量计算 是云器 Lakehouse 的核心技术创新,代表了一种全新的计算范式,区别于传统的全量批处理和特化流处理,实现了 "批流一体" 的增量计算能力。
- **传统计算的缺陷:**全量批处理每次查询都需处理所有相关数据,即使数据仅更新 1%,也需全量重算,资源浪费严重;流处理虽为增量计算,但仅能处理预定义的计算逻辑,不支持即席查询,灵活性差;
- 通用增量计算的核心原理: 在执行计划(Plan)层面 处理增量,针对 JOIN、聚合、窗口函数等复杂操作生成通用增量执行计划,复用历史计算结果,仅对新增 / 修改 / 删除的数据进行增量计算,最后将增量结果与历史结果合并,生成完整结果;
- **核心优势:**既具备批处理的灵活性(支持即席查询),又具备流处理的高效性(增量计算,减少计算量)。
3、分层多级自适应存储引擎:从存储层面加速查询
云器 Lakehouse 打造了 **"对象存储 + SSD 分布式缓存 + 服务器内存"**的分层多级自适应存储引擎,从数据读取层面实现性能优化:
- **低成本持久化:**通过低成本、高可靠的对象存储实现数据的持久化存储,保障数据安全性;
- **多级缓存加速:**借助 SSD 分布式缓存和服务器内存实现数据的多级 Cache,减少对象存储的冷读访问,大幅提升数据读取速度;
- **自定义预加载缓存:**针对流式摄入、频繁变化的数据,突破传统 LRU 缓存策略的局限,支持用户自定义 Cache 规则(表名、表分区范围),系统主动预加载新数据,保障实时分析的性能稳定性,避免查询抖动。
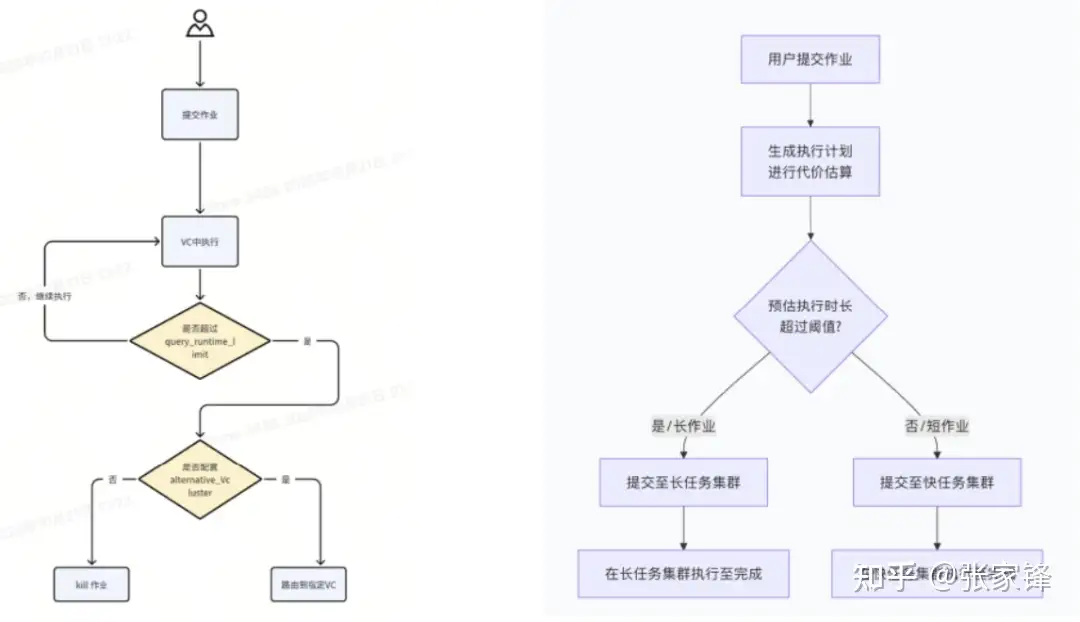
3.3 自动降级策略:大任务自动路由
在传统Lambda架构下,任务的路由只能等任务失败后,由上层再次触发提交发到另一个引擎之心,云器Lakehouse 在Virtual Cluster基础能力上,执行前预判与跨VC调度,实现大任务自动路由;
彻底解决一个SQL把集群自由打满问题,影响集群稳定性,同时这条SQL本身也跑不出来。
Virtual Cluster:
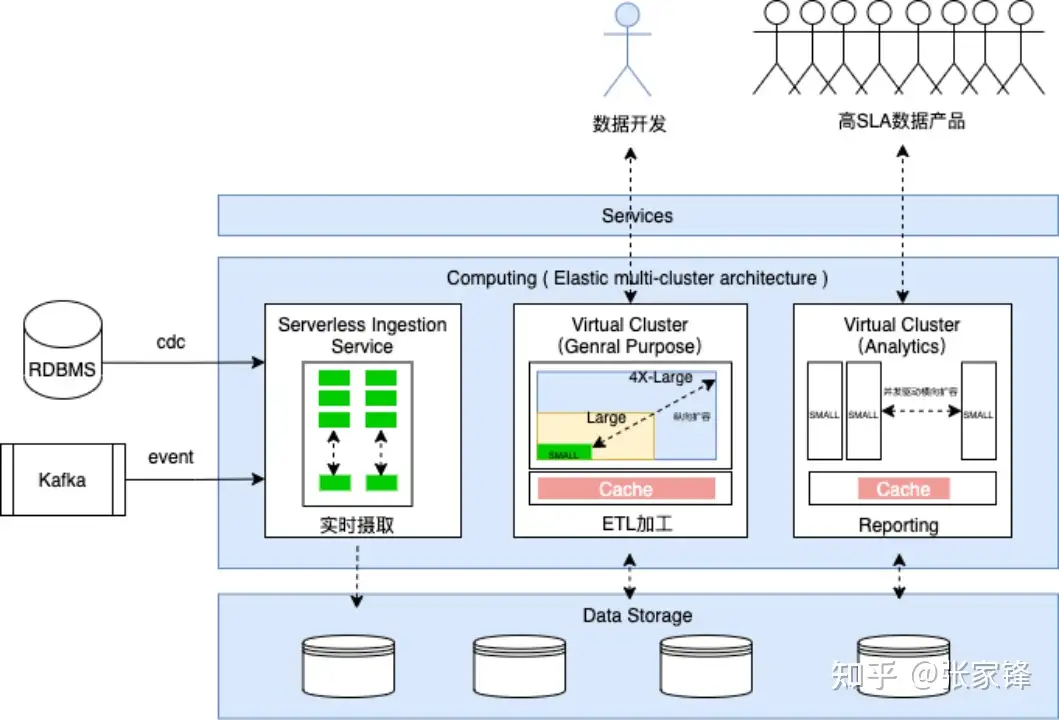
大作业自动路由:将VC上的大作业转移到另一个VC上
- 执行时长路由:设置一个阈值,比如60s,执行超过这个时间自动将作业路由到另一个VC
- 预估时长路由:尚未开始执行,生成执行计划阶段,预估执行时长,超过一个阈值路由到另一个VC
3.4 Virtual Cluster 虚拟集群:统一资源池下的弹性隔离与共享
云器 Lakehouse 基于存算分离架构 ,设计了Virtual Cluster(虚拟集群)技术,实现了资源的弹性伸缩和隔离共享 ,从根本上解决了传统架构的资源孤岛问题,打造了一套统一的资源池,支撑多业务、多场景的资源按需分配。
- Virtual Cluster 的双维度弹性伸缩
Virtual Cluster 实现了横向扩展和纵向扩展 的双维度弹性伸缩,且伸缩过程可在秒级完成,完美适配业务负载的 "潮汐效应":- **横向扩展:**根据查询 QPS 动态调整计算实例的数量,支持从 0 到 100 + 实例的动态调整,查询高峰时自动扩容,低峰时自动缩容,避免资源闲置;
- **纵向扩展:**根据查询复杂度动态调整单实例的规格,简单查询(点查)使用 2core 的小规格实例,复杂分析查询使用 64core 的大规格实例,实现资源的精准匹配。
- 资源隔离与共享:兼顾稳定性与利用率
Virtual Cluster 支持细粒度的资源隔离 ,可将统一的资源池划分为多个虚拟集群,为不同业务、不同场景分配独立的资源配额,避免跨业务的资源争抢;同时,虚拟集群的资源可动态调剂,当某一业务的资源闲置时,可临时分配给其他资源紧张的业务,实现资源的共享利用,大幅提升整体资源利用率。
3.5 湖上原地加速:以"三不做"原则降低迁移门槛
湖上原地加速 是云器 Lakehouse 为解决企业级数据平台升级 "迁移成本高、业务中断风险大"问题而设计的核心技术,遵循**"不搬数据、不改 SQL、不迁任务"的 "三不做" 原则,**可无缝接入企业现有数据架构,让平台升级从 "伤筋动骨" 变为 "按需插拔",大幅降低企业的迁移门槛和风险。
数据不搬:湖上原地加速
企业数据规模达 PB 级时,数据搬迁意味着巨大的时间、带宽和风险成本。云器 Lakehouse 通过**外表(External Table)**机制实现数据不搬迁,核心逻辑是:
- 复用企业现有 HDFS /S3作为主存储,不改变现有数据湖的架构和数据存储方式;
- 通过外表方式直接读写现有数据表,支持 Parquet 等主流文件格式,无需将数据导入云器 LH 的存储;
核心价值:数据仍存储在企业原有存储集群,离线 ETL、Ad-hoc查询等其他使用该数据的系统不受任何影响,实现**"湖上原地加速"。**
SQL不改:语法兼容
云器 Lakehouse 遵循,"适配现有生态" 的设计哲学,而非让用户适应新的标准,实现对现有 SQL、任务、权限体系的全面兼容:
- SQL 方言兼容:全面支持 Spark SQL、Presto、Doris 等企业主流的 SQL 方言,包括数组下标、正则表达式、bitmap、类型转换等特殊特性,企业现有 SQL 语句无需任何修改,可直接在云器 LH 上运行;
- **UDF / 任务兼容:**支持企业现有业务 UDF/UDAF 函数直接运行,无需重新开发;
- **元数据与权限体系兼容:**遵循 Hive Metastore(HMS)元数据标准,可直接读取企业现有库表元数据(表定义、分区策略、统计信息等),无需重新定义;同时兼容 Kerberos(KDC)等主流认证体系,接入企业现有数据账号和授权体系,访问元数据和数据时均采用授权认证方式,确保数据安全。
任务不迁:标准协议对接开发平台
现有调度任务可通过python/java SDK 通过标准JDBC协议轻松对接云器Lakehouse;
- SQL查询及离线开发通过 jdbc 发到云器 lakehouse 执行,结果返回
- 周期调度在自研开发平台上,通过 sdk 到点下发任务给云器Lakehouse执行,调度上线、执行完返回结果
美团BI平台结合云器Lakehouse的落地效果
美团BI平台作为承载数千名内部分析师、覆盖履约分析、运营监控、医药业务等核心场景、日查询量百万级、数据规模PB级 的企业级 BI 平台,在与云器科技的合作实践中,基于上述核心技术,达成了**"三个三分之一"的核心业务价值验证。**
4.1 架构从三套收敛为一套,架构复杂度下降三分之二
从原先的OLAP、Presto、Hive/Spark三套异构引擎 ,各引擎独立运行、数据冗余、资源孤岛;优化为基于云器 Lakehouse 的Single-Engine 单引擎架构 ,将三套异构引擎整合为一套统一的一体化引擎,实现了 "一份存储、一套元数据、一个引擎、一套资源池、一套语法" 的核心目标。
核心价值:
- 从根本上消除了多引擎带来的数据不一致、口径不统一问题,所有业务、所有场景基于同一套数据和引擎,指标口径 100% 统一;
- 运维复杂度指数级下降,技术团队无需再维护多套引擎集群和适配层,每月可节省大量的运维人力,故障定位效率提升数倍;
- 更加灵活的降级策略,不存在异构降级,BI+指标平台无需开发复杂的降级策略
- 统一开发语言,BI+指标平台无需开发多种语言转换的机制
- 资源弹性及大任务自动路由,提升资源利用率的同时,提升稳定性
4.2 同等资源下整体查询性能提升至原来的3倍
在同等资源池 的前提下,云器 Lakehouse 的高性能引擎,基于外表能力 让美团BI平台的**关键查询与分析场景性能整体提升 2 倍(是原来的3倍),**核心指标实现显著优化:
- 自动生成 SQL、复杂 JOIN 等场景的查询延迟大幅降低,平均响应时间从 344.3 秒降至 122.8 秒;
- Serving 场景的亚秒级响应率提升,运营人员的实时看数体验显著改善,从平均650毫秒提升到350毫秒左右;
- Ad-hoc 场景的大规模数据处理能力增强,分析师可实现对历史海量数据的灵活探索,无需担心引擎性能瓶颈。
性能提升的核心原因,在于云器 Lakehouse 的C++ 向量化执行、通用增量计算、双模执行引擎等技术的协同作用,实现了计算效率的极致提升,完美适配了美团指标平台的计算特征。
注: 需要说明的是,云器Lakehouse内表性能 可以在前面外表性能 基础上再有2-3倍性能提升。
4.3 插拔式升级实践,灰度切流与业务零中断
基于云器 Lakehouse 的湖上加速方案 ,美团BI平台实现了 "不搬数据、不改 SQL、不迁任务" 的**"三不"**式升级,整个升级过程未对核心业务造成任何中断,实现了业务无感知的平滑演进。
核心实践:
- 数据层面:复用原有 HDFS 存储,通过外表机制实现湖上原地加速,无需进行任何数据搬迁,避免了 PB 级数据迁移的风险和成本;
- 业务层面:现有 SQL 语句、UDF 函数、调度任务无需任何修改,可直接在云器 LH 上运行,业务人员的操作习惯无需改变;
- 升级层面:通过渐进式切流、灰度放量、线上双跑 的工程方法,逐步将流量从原有引擎切换到云器 LH,同时借助自动降级策略,确保升级过程中的业务稳定性,即使新引擎出现问题,也可无缝切回原有引擎。
4.4 升级后:基于云器Lakehouse的BI+指标平台整体架构
基于云器Lakehouse实现:一份存储、一套元数据、一个引擎、一套资源池、一套语法支持多场景应用。
行业展望:BI与AI融合下的智能用数平台演进方向
在 BI+AI 深度融合的时代,新一代BI+指标平台将不再只是简单的 "数据查询和分析工具",**而是将进化为企业的"智能用数平台",实现从 "看数" 到 "用数" 再到 "预测数" 的升级,**为企业提供端到端的智能用数能力。核心发展方向包括:
- 智能查询: 支持自然语言交互(NL2SQL) ,业务人员无需掌握 SQL 语法,只需通过自然语言描述查询需求,系统即可自动生成 SQL 并执行,大幅降低用数门槛,实现 "全民用数";
- 智能优化: 基于Lakehouse中内置的AI 模型/AI Agent能力实现查询计划的自动优化、资源的智能调度、执行模式的自适应选择,根据历史查询数据和业务特征,提前预判查询需求,实现 "预判式优化",进一步提升平台性能;
- 智能分析: 结合机器学习和大数据分析,实现指标的异常检测、根因分析、趋势预测,为企业提供主动的分析建议,从 "被动看数" 升级为 "主动用数",支撑企业的精细化运营和科学决策;
- 智能治理: 基于AI 技术实现元数据的自动提取、数据质量的实时监控、数据血缘的自动分析、数据安全的智能防护,实现数据治理的自动化和智能化,大幅降低数据治理的人力成本,保障数据的质量和安全。
以上AI相关能力已经在云器Lakehouse产品落地,并内置到产品能力中,欢迎试用,包括:
- Data Engineering Agent:面向智能优化、智能治理等方向
- DataGPT(Analytics Agent):面向智能查询、智能分析方向
结语
美团BI平台基于云器 Lakehouse 的升级实践,为企业级 BI 平台的架构演进提供了可复制的技术路径和工程方法论。
当数据规模持续增长、实时化需求不断提升、BI与AI走向融合,传统的 Lambda 架构已难以为继,以AI Ready、Single-Engine 、多模执行、高性能向量化计算、通用增量计算、资源弹性等为核心的 Lakehouse 技术路线,正在成为下一代企业级数据平台的主流选择------最终实现数据的统一、计算的高效、资源的弹性、用数的智能,支撑企业从 "数据驱动" 迈向 "智能驱动" 。
云器 Lakehouse 作为这一技术路线的代表,已通过核心技术创新与规模化工程验证,为企业构建新一代数据平台提供了坚实的技术底座。