TOPGO智能-AI123 2026年6月10日 15:06 广东
2025骁龙人工智能创新应用大赛的参赛项目中,TOPGO团队基于骁龙 X Elite的Hexagon NPU,在本机跑通一套8个Agent协同的私有化知识管理系统。本文详细记录拆解了项目开发中在NPU推理锁、GenieAPIService调用、多模型路由等真实工程问题上踩坑经验与破局思路。
作者:TOPGO-知易(Zhiyi)项目组
发表于:CSDN 骁龙开发者专区 | 高通开发者社区 | 极市平台
技术栈:骁龙 X Elite · QAI AppBuilder · QNN HTP · Qwen2.0-7B / llama3.2-3B 双模型 · FastAPI · React + Vite
一、为什么要做端侧知识管家
知识管理工具市场从来不缺产品,缺的是真正能跑在本地、不把数据上传云端的"私有化智能体"。
我们做知易智能知识管家的出发点很简单:用骁龙 X Elite 的 Hexagon NPU,把一个完整的多 Agent 知识处理系统跑在本机,无需联网,推理结果秒级返回,数据完全不出域。
项目叫 Zhiyi(知易),借了明代内阁的组织隐喻------8 个功能 Agent 各司其职,像一套微型朝廷一样协同处理知识任务。参加的是 2025-2026 年高通骁龙 AIPC 开发竞赛。
本文分享的是我们真实踩过的坑和真实跑通的代码,不是 demo 级别的 Hello World。
二、真实的技术选型
参考文章里有人写 Angular + Golang,我们实际用的是:
| 层次 | 技术 |
|---|---|
| 前端 | React + Vite + Tailwind CSS,开发端口 3000 |
| 后端 | Python FastAPI,端口 8000 |
| AI 推理 | GenieAPIService(高通官方提供),OpenAI 兼容 HTTP,端口 8910 |
| 模型 | Qwen2.0-7B (中文对话/分析首选)+ llama3.2-3B(轻量快速备用)+ Qwen2.5-VL-3B(视觉能力扩展) |
| 存储 | SQLite + 本地向量库 |
为什么选 Python FastAPI 而不是 Golang?有两个实际原因:
-
qai_appbuilder 的 Python binding 是一等公民 。官方的
GenieContext就是 Python 的,直接from qai_appbuilder import GenieContext就能用,Golang 要绕一大圈。 -
迭代速度。决赛周期短,Python 改起来快,NPU 调不通马上可以 fallback 到 HTTP 调 GenieAPIService。
架构示意
┌─────────────────────────────────────────────┐
│ 前端 React (port 3000) │
│ 四色知识卡片 UI · SSE 流式接收 · 会议面板 │
├─────────────────────────────────────────────┤
│ 后端 FastAPI (port 8000) │
│ 8 Agent 路由 · hybrid-question API │
│ 知识库 CRUD · SSE 推送 │
├─────────────────────────────────────────────┤
│ AI 推理层 │
│ GenieAPIService (port 8910) │
│ OpenAI 兼容 HTTP 接口 /v1/chat/completions │
│ QNN HTP Backend → Hexagon NPU │
├─────────────────────────────────────────────┤
│ 骁龙 X Elite (X1E-84-100) │
│ Hexagon NPU · Adreno GPU · Kryo CPU │
└─────────────────────────────────────────────┘三、GenieAPIService HTTP 接口实战:NPU 推理的工程实现
3.1 整体调用架构:全部走 HTTP
最终落地的架构非常清晰:所有 Agent 都通过 HTTP 调用 GenieAPIService ,没有任何组件直接 import GenieContext。
FastAPI 后端 (port 8000)
└── 8 个 Agent(httpx 异步 HTTP 调用)
└── GenieAPIService (port 8910) ← 高通官方服务
└── QNN HTP Backend
└── Hexagon NPUGenieAPIService 对外暴露 OpenAI 兼容接口 (/v1/chat/completions),意味着只要会用 OpenAI SDK 的 chat 接口,切到端侧 NPU 几乎零成本。
启动 GenieAPIService:
GenieAPIService.exe -c C://models//qwen2.0-7b-ssd-8380-2.34//config.json -l \ # 启用日志
-p 8910 \ # 监听端口
-d 3 # 设备索引(NPU)健康检查:
curl http://localhost:8910/
# 返回 {"status":"ok"} 表示 NPU 模型已加载完毕3.2 Agent 的标准调用模式
每个 Agent 都有一个 _call_genie_api() 异步方法,核心调用如下(以通政司为例):
async def _call_genie_api(self, prompt: str) -> str:
"""
调用 LLM 推理 ------ 直接打 GenieAPIService HTTP API (port 8910)
带 429 限流重试逻辑
"""
max_retries = 3
for attempt in range(max_retries):
try:
asyncwith httpx.AsyncClient(timeout=30.0) as client:
response = await client.post(
"http://127.0.0.1:8910/v1/chat/completions",
json={
"model": "qwen2.5vl3b-8380-2.42", # 对应 config.json 的模型名
"messages": [
{"role": "system", "content": "你是通政司,负责从数据中提炼关键事实。"},
{"role": "user", "content": prompt}
],
"size": 1024, # 最大输出 token 数
"temp": 0.7, # 温度
"top_k": 1,
"top_p": 1.0
}
)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"].strip()
except httpx.HTTPStatusError as e:
if e.response.status_code == 429:
wait_time = (attempt + 1) * 2 # 2s, 4s, 6s 退避
logger.warning(f"[通政司] Genie 429 限流,{wait_time}s 后重试")
await asyncio.sleep(wait_time)
continue
break
except Exception as e:
logger.error(f"[通政司] Genie API 不可用: {e}")
break
return""三个关键工程细节:
**① 必须用 async with httpx.AsyncClient,不能用同步 requests。**FastAPI 是全异步框架,在 async 函数里用同步 HTTP 会阻塞事件循环,导致多 Agent 并发时相互卡住。
② 429 限流是必然发生的,需要全局串行锁。 GenieAPIService 内部 NPU 是串行执行的,8 个 Agent 同时打进来必然有排队。加了全局 asyncio.Lock() 让请求进队列,不走并发:
_GENIE_LOCK = asyncio.Lock() # 全局 NPU 串行锁
async def _call_genie(...):
async with _GENIE_LOCK: # 入队,不并发
for attempt in range(3):
result = await _do_call_genie(...)
if result:
return result
await asyncio.sleep(3) # 被阻塞时退避 3s
return None③ system role 字段在 Genie 里可能不生效 ------ 这是最坑的一个。 GenieAPIService 使用 prompt.conf 里的模板组装最终 prompt,messages 里的 system 字段可能被模板覆盖或忽略,导致 8 个 Agent 的人设全部丢失,全都回答「我是一个通用 AI 助手」。
解决方案 :把 Agent 角色指令嵌入 user_prompt 开头,不依赖 system 字段:
# ❌ 依赖 system 字段,可能被 prompt.conf 覆盖
messages = [
{"role": "system", "content": "你是锦衣卫,负责安全情报..."},
{"role": "user", "content": user_question}
]
# ✅ 角色指令嵌入 user_prompt 开头(Genie 100% 可见)
role_instruction = system_prompt[:500] # 取前 500 字符
embedded_user = f"{role_instruction}
用户问题:{user_question}"
messages = [
{"role": "user", "content": embedded_user}
]这个问题在官方文档里没有提到,是我们在答辩前一周排查 Agent 人设丢失 bug 时发现的,改完之后 8 个 Agent 才真正各有个性。
3.3 双模型路由策略:按复杂度自动选 7B 或 3B
这是整个推理层最有价值的设计之一。我们在 model_router.py 里实现了一个基于查询复杂度评分的模型选择器:
def select_model(query: str) -> str:
"""
根据查询复杂度自动选模型:
- simple (<30分): llama3.2-3b ← 轻量极速
- medium (30-59分): llama3.2-3b ← 快速
- complex (>=60分): qwen2.0-7b ← 中文深度理解
"""
estimation = estimate_complexity(query)
if estimation['complexity'] == 'complex':
return 'qwen2.0-7b' # 7B 的中文理解更强
else:
return 'llama3.2-3b' # 3B 够快,延迟低复杂度评分考虑的维度:
-
文本长度(0-30 分)
-
是否包含「分析、评估、策略、比较」等语义关键词(+10/词)
-
技术术语密度(NPU、量化、推理等,≥2 个 +20)
-
问号数量(多问题场景 +15)
虚拟会议场景(8 Agent 协作)统一走 Qwen2.0-7B 主路 ------因为多 Agent 中文推理要求高,7B 的中文能力更稳定。配置在 meeting_routes.py 的 call_llm() 里:
async def call_llm(system_prompt, user_prompt, ...) -> str:
"""
调用 LLM 的降级策略(按优先级):
层1: Genie HTTP → qwen2.0-7b(中文最强,≤120s timeout)
层2: Genie HTTP → llama3.2-3b(快速备用,≤90s timeout)
"""
# 先尝试 7B
result = await _call_genie(model_name="qwen2.0-7b-ssd-8380-2.34", ...)
if result:
return result
# 降级到 3B
result = await _call_genie(model_name="llama3.2-3b-8380-qnn2.37", ...)
return result在 resource_scheduler.py 里,7B 被标记为 ModelTier.BALANCED,3B 是 ModelTier.LIGHT,调度器会根据 NPU 当前负载动态选择:
MODEL_CONFIGS = {
"qwen2.0-7b": ModelConfig(tier=ModelTier.BALANCED, supports_chinese=True),
"llama3.2-3b": ModelConfig(tier=ModelTier.LIGHT, supports_chinese=True),
}两个模型都在 C:/models/ 下物理存在,GenieAPIService 支持按 model 字段在 /v1/chat/completions 时指定加载哪个。
四、8 Agent 多智能体架构:明代内阁的工程实现
这是整个项目最有意思的部分。我们用明代内阁的职官体系给 Agent 命名,不只是噱头------每个职能都对应了真实的知识处理管线分工。
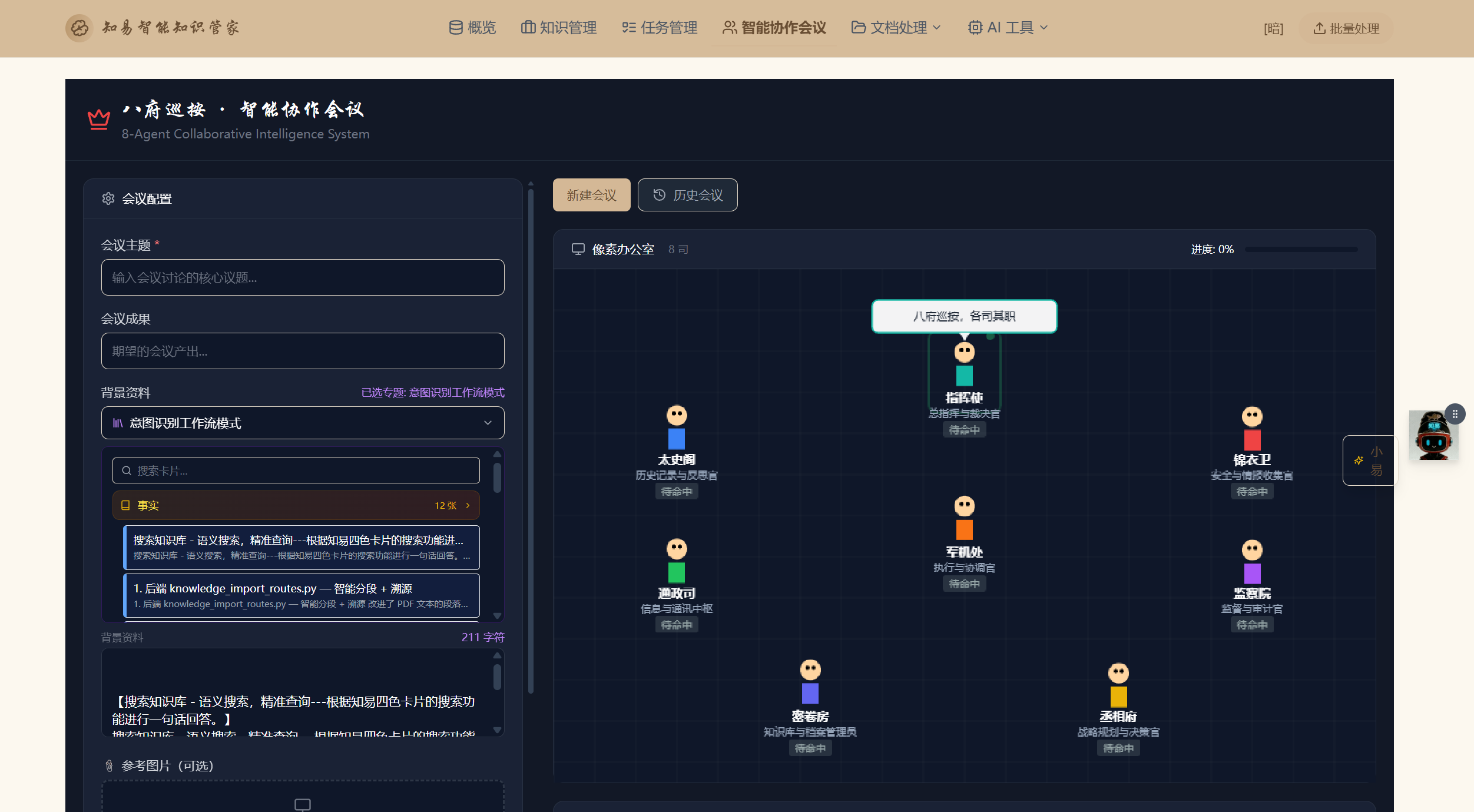
4.1 Agent 职能对照表
| Agent | 职能 | 核心职责 |
|---|---|---|
| 指挥使 👑 | 总指挥 | 统筹全局,最终裁决 |
| 丞相府 🏛️ | 战略规划 | 制定决策,协调资源 |
| 军机处 ⚔️ | 执行协调 | 任务执行,进度跟踪 |
| 通政司 📡 | 信息中枢 | 事实提炼,跨 Agent 分发 |
| 监察院 🔍 | 审计监督 | 合规审查,风险识别 |
| 密卷房 📂 | 档案管理 | 素材解析,知识归档 |
| 锦衣卫 🛡️ | 安全情报 | 系统安全,威胁检测 |
| 太史阁 📚 | 历史记录 | 知识存储,经验库 |
8智能体会议知识图谱
4.2 知识流转:一次 hybrid-question 的生命周期
当用户提问 POST /api/meeting/hybrid-question,实际发生的是:
用户提问
↓
密卷房(解析素材格式)
↓
通政司(提炼核心事实)
↓ 查询相关卡片
太史阁(知识库检索)
↓ 分发给各 Agent
指挥使(协调各方 + 最终整合)
↓
返回:answer + 四色知识卡片 + 来源引用不是所有 Agent 都参与每次查询------这是设计的关键点。密卷房/太史阁负责查卡片,通政司负责分发,其他 Agent 按职责选择性介入,避免不必要的 LLM 调用消耗 NPU 资源。
密卷房的素材解析代码(真实代码,非示意):
class MijuanfangAgent:
def parse_material(self, raw_material: str) -> Dict:
# Markdown 表格
if"|"in raw_material and"---"in raw_material:
lines = [l.strip() for l in raw_material.split("\n") if l.strip()]
header = [h.strip() for h in lines[0].split("|") if h.strip()]
data = []
for line in lines[2:]:
values = [v.strip() for v in line.split("|") if v.strip()]
if len(values) == len(header):
data.append(dict(zip(header, values)))
return {"fields": header, "data": data, "format": "table"}
# JSON
elif raw_material.startswith("{") and raw_material.endswith("}"):
return {"data": json.loads(raw_material), "format": "json"}
# 纯文本(按句号分割)
else:
sentences = [s.strip() for s in raw_material.split("。") if s.strip()]
return {"data": sentences, "format": "text"}4.3 四色卡片知识体系
四色卡片任务图谱
输出的知识卡片分四种颜色,对应四个认知维度:
| 颜色 | 含义 | 示例 |
|---|---|---|
| 🔵 蓝色(事实卡) | 客观事实与数据 | "模型推理延迟 480ms" |
| 🟢 绿色(洞见卡) | 分析解读与规律 | "INT8 量化带来 3x 加速" |
| 🟡 黄色(风险卡) | 潜在问题与注意项 | "并发推理可能触发 DSP 崩溃" |
| 🔴 红色(行动卡) | 建议操作与决策 | "加推理锁,设 0.5s 冷却" |
五、踩坑实录:真实问题与解法
坑 1:端口 8000 被旧进程占用
现象 :FastAPI 启动报 [WinError 10048] 通常每个套接字地址只允许使用一次
原因:上次崩溃的 Python 进程没有正常退出,端口没有释放。
解法:
# 查找占用端口的进程
netstat -ano | findstr ":8000"
# 假设 PID 是 75612
taskkill /F /PID 75612我们在 quick_start_v2.bat 里加了启动前自动清理:
:: 清理旧进程
taskkill /F /IM python.exe 2>nul
taskkill /F /IM GenieAPIService.exe 2>nul
timeout /t 2 /nobreak >nul坑 2:QNN HTP 上下文爆炸(Context Window Overflow)
现象:多轮对话后推理结果开始乱码,然后 GenieContext 直接报错崩溃。
原因:我们在早期版本里把对话历史(包括所有 Agent 输出)都塞进 GenieContext 的 chat session,3B 模型的 context window 很快就溢出了。
解法:去掉在 GenieContext 层的多轮历史管理,改为在 FastAPI 层维护会话历史,每次调用 NPU 时只传当前轮的 prompt(含必要上下文的精简版),而不是完整历史。
具体做法是移除了之前在 model_loader.py 里调用 _extract_color_cards 的逻辑(这个函数会把历史卡片全部拼入 prompt),改成只传关键卡片摘要:
# ❌ 旧写法:把所有历史卡片追加进 prompt
def build_prompt_with_history(self, question, history):
cards_str = self._extract_color_cards(history) # 可能有几千 token
return f"{cards_str}\n\n{question}"
# ✅ 新写法:只传最近 3 张相关卡片摘要
def build_prompt_slim(self, question, relevant_cards):
cards_summary = "\n".join([f"- {c['title']}" for c in relevant_cards[:3]])
return f"参考背景:\n{cards_summary}\n\n问题:{question}"坑 3:GenieContext system_prompt 被覆盖
见上文第三节,不再赘述。核心结论:不要依赖 GenieContext 的内部 system_prompt 机制维护 Agent 人设,每次推理时把 Agent 角色说明显式拼入 prompt 前缀。
坑 4:Windows curl 中文编码问题
现象:在 Windows Git Bash 里用 curl 发中文 JSON body,后端一直返回 422 Unprocessable Entity。
原因:Windows cmd/bash 下 curl 对中文字符的处理默认是 GBK 编码,FastAPI 期望 UTF-8。
解法:
# ❌ 会有编码问题
curl -X POST http://localhost:8000/api/meeting/hybrid-question \
-d "{\"question\":\"什么是知识卡片?\"}"
# ✅ 用 --data-raw 发 ASCII + 跳过中文,或用 Python 脚本
python -c "
import urllib.request, json
data = json.dumps({'question': '什么是知识卡片?'}).encode('utf-8')
req = urllib.request.Request(
'http://localhost:8000/api/meeting/hybrid-question',
data=data,
headers={'Content-Type': 'application/json; charset=utf-8'}
)
print(urllib.request.urlopen(req).read().decode('utf-8'))
"坑 5:模型路径在不同环境下不一致
开发机、打包后、用户安装机,模型目录三套不同路径。解法是写了一个多 fallback 的路径查找函数(见第三节),并在项目根目录放一个 quick_start_v2.bat 统一管理启动逻辑。
六、实测性能数据
以下数据来自本机骁龙 X Elite (X1E-84-100):
| 指标 | llama3.2-3B(INT8) | Qwen2.0-7B(INT8) | 备注 |
|---|---|---|---|
| 模型加载时间 | 约 8-12s | 约 15-20s | 首次冷启动 |
| 首 token 延迟 | ~480ms | ~800-1200ms | NPU HTP BURST 模式 |
| 内存占用 | ~1.8GB | ~3.2GB | QNN INT8 量化 |
| 中文对话质量 | 中等 | 优 | 7B 明显更好 |
| 适用场景 | 简单问答、快速响应 | 分析推理、虚拟会议 Agent | - |
两个模型我们都在用:简单查询走 3B,虚拟会议多 Agent 协作走 7B,降级备用链是 7B → 3B 顺序尝试。7B 带来更好的中文理解质量,代价是延迟和内存翻倍,在知识管理场景下这个 tradeoff 是值得的。
七、目录结构参考
zhiyi/
├── backend/
│ ├── main.py # FastAPI 入口,lifespan 管理
│ ├── npu_core.py # GenieContext 封装,NPU 推理核心
│ ├── config.py # 配置(模型路径、SDK 版本等)
│ ├── conf/
│ │ ├── npu.py # NPU 配置类(QNN 版本、性能模式)
│ │ └── app.py # 应用配置
│ ├── agents/
│ │ ├── taishige.py # 太史阁:知识存储/图谱
│ │ ├── mijuanfang.py # 密卷房:素材解析
│ │ ├── tongzhengsi.py # 通政司:事实提炼
│ │ ├── orchestrator.py # 锦衣卫总指挥使:任务分解
│ │ └── ... # 其余 5 个 Agent
│ ├── api/
│ │ ├── cards.py # 四色卡片 API
│ │ └── knowledge.py # 知识库 API
│ ├── models/
│ │ └── model_loader.py # 模型加载器(含多路径 fallback)
│ └── services/
│ └── ai/ # AI 服务层(HTTP/直接调用双模式)
├── src/ # React 前端
└── quick_start_v2.bat # 一键启动脚本八、写在最后
骁龙 AIPC 开发最大的挑战,不是模型转换或量化,而是工程层面的稳定性------NPU 驱动、QNN SDK、GenieContext 的文档不够完善,很多行为只能靠实验摸索。
几点真心建议:
-
推理锁是必须的:DSP 不支持并发,加锁是第一要务。
-
GenieAPIService 的 HTTP 接口是最省事的选择:OpenAI 兼容接口直接用 httpx 打,比绕 GenieContext binding 要稳定得多,而且方便用 curl 调试。
-
模型 context window 要省着用:3B 模型 context 有限,每个 Agent 只做自己那一块,别把全量历史往里塞。
-
多路径 fallback 要写在最前面:开发/打包/安装三套环境,路径问题会让你怀疑人生。
项目地址
比赛后将公开安装包。主项目暂不开放源码(几个月的成果来之不易),但项目中用到的多项 AI 技能已独立开源:
🏆 项目链接: https://github.com/anbeime/skill --- 1400+ Star,包含内容创作、股票分析、投资调研、资讯搜索等 20+ Agent 技能模板,可直接集成到任何 AI 应用中。
高通 AI Hub 参考:https://aihub.qualcomm.com
QAI AppBuilder 文档:https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
TOPGO-知易项目组 | 骁龙 AIPC 开发竞赛 2025-2026
本文代码示例均基于真实项目经验。文中介绍的技能模板已在 GitHub 开源(MIT 协议),欢迎 Star & Contribute。