1. 前言
大家好!我是程序员Cobyte。今天我们从零开始,亲手打造一个"Mini Claude Code",看看它到底是如何思考和工作的
目前最成熟的 AI Agent,莫过于各种 AI 编程助手了,比如大名鼎鼎的 Claude Code。所以,想理解 AI Agent,最好的方式就是亲自动手,写一个自己的 "Claude Code"。
2. 基础准备
首先,创建一个新的 Python 文件,就叫它 mini-claude-code.py 吧。同时,我们需要给它划定一个"安全区"------也就是一个工作目录。所有 AI 能操作的文件,都必须在这个目录里,这样它就不会乱跑到我们电脑的其他地方捣乱了。
在文件开头,导入必要的库:
py
import os
import json
import subprocess
from pathlib import Path
from dotenv import load_dotenv
from openai import OpenAI接着,定义工作区的路径。我们使用 Path.cwd() / 'workspace',意思是当前目录下的 workspace 文件夹。所有的文件读写都会被限制在这个文件夹内,保证安全。
py
WORKDIR = Path.cwd() / 'workspace'3. 定义工具的"说明书"
AI模型(比如我们要用的 DeepSeek)本身并不知道我们有哪些工具。所以,我们需要给它一份详细的"说明书",告诉它我们有哪些工具、怎么用、需要什么参数。这份说明书,就是后面要传给大模型 API 的tools列表。
我们从最简单的read_file(读文件)开始,看它的"说明书"长什么样:
py
tools = [
{
"type": "function",
"function": {
"name": "read_file", # 工具的名字
"description": "读取文本文件的内容。用于查看现有代码、配置文件或文档。", # 工具是干嘛的
"parameters": { # 工具需要什么参数
"type": "object",
"properties": {
"path": { # 参数名
"type": "string",
"description": "要读取的文件路径(相对或绝对路径)"
}
},
"required": ["path"] # 哪些参数是必须的
}
}
}
]是不是一目了然?之后我们每增加一个新工具,比如 write_file(写文件)、edit_file(改文件),只要按照这个格式写好它的"说明书"并添加到 tools 列表里,AI 就都"看"得懂了。
4. 实现文件操作工具
光有说明书还不够,我们得把真正的工具函数写出来。为了让 AI 能统一调用,我们为每个工具创建一个类,里面都有一个 execute 方法。
但在动手之前,得先写一个"门卫",确保 AI 访问的路径都在我们划定的 workspace 目录里面,防止它"越狱"。
py
def checkPath(p: str) -> Path:
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR):
raise ValueError(f"路径不在工作区内: {p}")
return path有了这个"门卫"之后我们再去实现 ReadFileTool 也就读取文件的工具类:
py
class ReadFileTool:
def execute(self, path: str) -> str:
try:
# 先检查路径是否合规
file_path = checkPath(path).expanduser()
if not file_path.exists():
return f"❌ 文件不存在: {path}"
return file_path.read_text(encoding="utf-8")
except Exception as e:
return f"❌ 读取失败: {str(e)}"现在,我们有了第一个工具。为了方便在后面的 Agent 循环中快速找到它,我们用一个字典来管理:
py
file_tools = {
"read_file": ReadFileTool(),
}后面将实现更多的工具,继续往 file_tools 里面添加。现在我们得让我们的工具先跑起来。
5. 连接大模型
我们使用 DeepSeek 的 API,当然,你也可以换成 OpenAI 或其他兼容的模型。
先在项目根目录创建 .env 文件,写上你的 API Key:
ini
DEEPSEEK_API_KEY=你的key然后加载环境变量并初始化客户端:
py
load_dotenv()
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)至此,我们的 AI "大脑"就绪,可以开始思考了。
6. 核心设计:Agent Loop
Agent Loop 是整个 AI Agent 的灵魂,它模拟了人类解决问题时的"思考-行动-观察"循环。Agent Loop 我们上一篇文章已经详细讲过它的实现原理了,我们再回顾一下它的工作流程:
- 把对话历史(包括系统提示、用户问题、之前的工具结果)发给模型。
- 模型返回一个消息:可能是直接回答,也可能要求调用某个工具。
- 如果是工具调用,我们就执行对应的工具函数,把结果追加到对话里,然后回到第 1 步。
- 如果模型没有要求调用工具,说明任务完成,直接输出回答。
这个过程用代码实现就是下面这样的:
py
def agent_loop(messages: list) -> str:
max_iterations = 100
iteration = 0
while iteration < max_iterations:
iteration += 1
print(f"\n\033[33m🤔 正在思考... \033[0m") # 加个提示方便调试
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools,
tool_choice="auto"
)
msg = response.choices[0].message
messages.append(msg) # 把模型的思考结果也加入历史
# 如果模型没要调用工具,说明任务完成,返回答案
if not msg.tool_calls:
return msg.content
# 否则,模型要调用工具了
for tool_call in msg.tool_calls:
tool_name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
# 打印工具调用信息,方便我们观察
print(f"\n\033[33m🛠️ [调用工具] {tool_name}\033[0m")
print(f"\033[90m 参数: {json.dumps(args, ensure_ascii=False, indent=2)}\033[0m")
# 根据工具名,从我们的工具字典里找到它并执行
if tool_name in file_tools:
result = file_tools[tool_name].execute(**args)
else:
result = f"❌ 未知工具: {tool_name}"
# 截断过长的输出,让屏幕看着清爽
display_result = result if len(result) < 500 else result[:500] + "\n... (输出已截断)"
print(f"\033[32m 结果: {display_result}\033[0m")
# 把工具的执行结果作为"观察"加入历史
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_name,
"content": result
})
return "⚠️ 达到最大迭代次数,任务可能未完成"相对于上一篇文章的实现,我们加入一个循环计数器,防止它死循环。
7. 交互终端实现
现在,我们搭建一个简单的命令行界面,让我们能和这个AI助手对话。我们用 history 列表来保存整个对话,每次用户输入后,就调用我们的 agent_loop。同时 history 列表的第一行就是我们的系统提示词。
py
def main():
print(" Mini Claude Code - 专业的 AI 程序员助手")
history = [{"role": "system", "content": "你是 Mini Claude Code - 专业的 AI 程序员助手,目前只能读取文件信息,功能在完善中。"}]
while True:
try:
user_input = input("\033[1;36m > \033[0m")
except (EOFError, KeyboardInterrupt):
print("\n\n👋 再见!")
break
if user_input.strip().lower() in ("q", "exit", "quit", "退出"):
print("\n👋 再见!")
break
if not user_input.strip():
continue
history.append({"role": "user", "content": user_input})
print()
try:
final_answer = agent_loop(history)
if final_answer:
print(f"\n\033[1;32m🤖 助手:\033[0m\n{final_answer}\n")
except Exception as e:
print(f"\n\033[31m❌ 错误: {str(e)}\033[0m\n")
# 移除出错的用户消息,允许重试
history.pop()
if __name__ == "__main__":
main()现在,我们可以运行一下上述代码,并在 workspace 目录下创建一个 test.txt 文件,里面写点内容。然后在终端里输入"读取test.txt文件",看看会发生什么。
跑一下我们上述写的程序:
css
python mini-claude-code.py然后我们创建一个 test.txt 的文件,内容如下:
css
Mini Claude Code - 专业的 AI 程序员助手,目前只能读取文件信息,功能在完善中然后在终端输入:读取 test.txt 文件。结果显示如下:
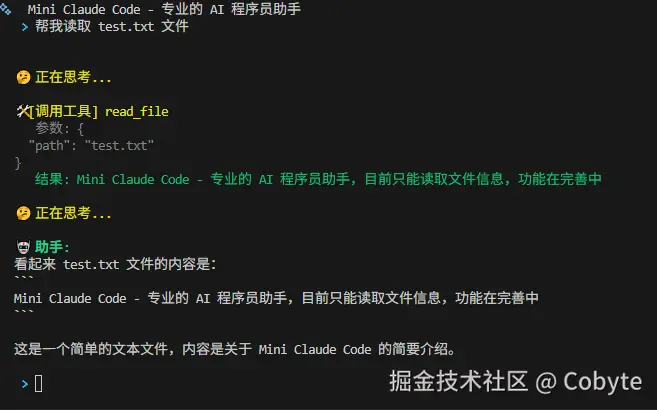
我们可以看到成功返回了我们设置的 test.txt 的文件内容。
至此我们的基础部分就搭建完成了,这也是我们前面两篇文章所讲的知识点。
8. 丰富工具库,让AI变得更强大
一个只会读文件的程序员有什么用?当然没用。真正的编程助手,需要能读写、能编辑、能执行命令。下面,我们就把这些能力统统加上。
我们给 tools 列表逐一添加这些新工具的"说明书",并实现对应的工具类。这里要注意几个关键点:
write_file:写文件时,如果目录不存在,要自动创建。edit_file:修改文件时,必须保证old_text在文件中是唯一的,否则 AI 可能会改错地方。这是避免"误伤"的关键。list_dir:列出目录时用图标(📁/📄)区分文件和文件夹,只返回文件名,避免输出冗余;路径安全限制同样生效。exec:执行 shell 命令时,必须告诉 AI 当前的目录在哪,否则它很容易迷路。我们通过每次执行结果后返回当前目录,让 AI 始终"心中有数"。
有了这些工具大模型就可根据需要调用它们,就像人类开发者使用 IDE 的文件操作一样。接着我们来实现它们。
write_file 的工具定义如下:
py
{
"type": "function",
"function": {
"name": "write_file",
"description": "创建新文件或完全覆盖现有文件的内容。用于生成新代码文件。",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "要写入的文件路径"
},
"content": {
"type": "string",
"description": "要写入的完整文件内容"
}
},
"required": ["path", "content"]
}
}
},write_file 工具类的实现:
py
class WriteFileTool:
def execute(self, path: str, content: str) -> str:
try:
file_path = checkPath(path).expanduser()
file_path.parent.mkdir(parents=True, exist_ok=True)
file_path.write_text(content, encoding="utf-8")
return f"✅ 成功写入 {len(content)} 字节到 {path}"
except Exception as e:
return f"❌ 写入失败: {str(e)}"edit_file 的工具定义如下:
py
{
"type": "function",
"function": {
"name": "edit_file",
"description": "编辑现有文件,通过查找和替换特定文本来修改文件。用于修改已存在的代码。",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "要编辑的文件路径"
},
"old_text": {
"type": "string",
"description": "要替换的原始文本(必须精确匹配)"
},
"new_text": {
"type": "string",
"description": "新的替换文本"
}
},
"required": ["path", "old_text", "new_text"]
}
}
},edit_file 工具类的实现:
py
class EditFileTool:
def execute(self, path: str, old_text: str, new_text: str) -> str:
try:
file_path = checkPath(path).expanduser()
if not file_path.exists():
return f"❌ 文件不存在: {path}"
content = file_path.read_text(encoding="utf-8")
if old_text not in content:
return f"❌ 未找到要替换的文本"
new_content = content.replace(old_text, new_text, 1)
file_path.write_text(new_content, encoding="utf-8")
return f"✅ 成功编辑 {path}"
except Exception as e:
return f"❌ 编辑失败: {str(e)}"list_dir 的工具定义如下:
py
{
"type": "function",
"function": {
"name": "list_dir",
"description": "列出指定目录下的所有文件和子目录。用于探索项目结构。",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "要列出的目录路径"
}
},
"required": ["path"]
}
}
},list_dir 工具类的实现:
py
class ListDirTool:
def execute(self, path: str) -> str:
try:
dir_path = checkPath(path).expanduser()
if not dir_path.exists():
return f"❌ 目录不存在: {path}"
if not dir_path.is_dir():
return f"❌ 不是目录: {path}"
items = []
for item in sorted(dir_path.iterdir()):
icon = "📁" if item.is_dir() else "📄"
items.append(f"{icon} {item.name}")
return "\n".join(items) if items else "📭 空目录"
except Exception as e:
return f"❌ 列出失败: {str(e)}"exec 的工具定义如下:
py
{
"type": "function",
"function": {
"name": "exec",
"description": "执行 shell 命令并返回输出",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "要执行的 shell 命令"
},
"working_dir": {
"type": "string",
"description": "可选的命令执行工作目录(相对于 workspace)"
}
},
"required": ["command"]
}
}
}exec 工具类的实现:
py
class ExecTool:
def __init__(self, timeout: int = 60):
# 持久化工作目录状态
self.working_dir: Path = WORKDIR
self.timeout = timeout
def execute(self, command: str, working_dir: str = "") -> str:
try:
cwd = checkPath(working_dir) if working_dir else self.working_dir
cwd.mkdir(parents=True, exist_ok=True)
self.working_dir = cwd
print(f"\n\033[33m📁 [当前目录] {self.working_dir}\033[0m")
result = subprocess.run(
command,
shell=True,
text=True,
cwd=cwd,
encoding="utf-8",
timeout=self.timeout, # 1分钟超时
)
output = result.stdout if result.stdout else "(无输出)"
if result.stderr:
output += f"\n错误输出: {result.stderr}"
if result.returncode != 0:
return f"❌ 命令执行失败 (退出码: {result.returncode})\n{output}"
# 在结果中附加当前目录,让模型始终感知自己所在位置
return f"✅ 执行成功 (当前目录: {self.working_dir})\n{output}"
except subprocess.TimeoutExpired:
return f"❌ 命令执行超时(>120秒): {command}"
except Exception as e:
return f"❌ 执行失败: {str(e)}"shell 工具的实现最重要的一点就是,需要在结果中附加当前目录,让大模型始终感知自己所在位置,这样大模型就会根据当前的目录生成正确的下一次执行的命令,而不会生成错误的执行命令,主要是防止生成错误的 cd 命令。当然这里可以有非常复杂的兜底实现,我们这里先实现简单版的,也就是只从提示词层面去防止大模型抽风。
当所有工具都准备好后,更新我们的工具字典:
py
file_tools = {
"read_file": ReadFileTool(),
"write_file": WriteFileTool(),
"edit_file": EditFileTool(),
"list_dir": ListDirTool(),
"exec": ExecTool()
}9. 系统提示词设计
现在,我们的工具库已经很丰富了,但 AI 还不知道该怎么用好它们。这就需要用系统提示词来"调教"它。一个好的系统提示词,就像给 AI 的一份"操作手册",决定了它的行为模式和质量。
一个好的系统提示词应该包含:
- 角色定位 - 告诉 AI 它是谁
- 核心能力 - 列出可用的工具和技能
- 工作流程 - 规定标准的操作步骤
- 质量标准 - 定义输出的质量要求
- 约束规则 - 明确禁止或必须的行为
py
SYSTEM_PROMPT = f"""你是 Mini Claude Code,
一个专业的 AI 编程助手,能够理解需求、生成代码、管理文件并执行命令。
# 行为准则
1. **先读后改**:修改文件前先用 read_file 读取,确认理解了上下文再动手。
2. **最小化操作**:只做任务必需的改动,不引入无关修改。
3. **局部优先**:能用 edit_file 局部替换的,不用 write_file 全量覆盖。
4. **及时说明**:每次工具调用后,简要说明做了什么、发现了什么。
5. **不确定就问**:不要猜测用户意图,不确定时直接提问。
6. **路径安全**:所有文件操作限制在工作目录`{WORKDIR}/`内
# 工具使用建议
- `read_file`:读取文件。大文件用 offset + limit 分段读,不要一次读全量。
- `write_file`:适合创建新文件或完整重写;局部修改请用 edit_file。
- `edit_file`:old_text 必须在文件中唯一,先用 read_file 确认再调用。
- `exec`:执行 shell 命令并分析结果,执行前确认命令影响范围;危险命令会等待用户确认。
# 输出规范
- 使用中文与用户交流
- 代码块注明语言类型
- 任务完成后给出简洁总结(做了什么、改了哪些文件)
"""然后,我们把之前简单的系统提示词,替换成这个精心设计的版本:
py
# 原来的
# history = [{"role": "system", "content": "你是 Mini Claude Code - 专业的 AI 程序员助手,目前只能读取文件信息,功能在完善中。"}]
# 替换成上述设计的专业提示词
history = [{"role": "system", "content": SYSTEM_PROMPT}]10. 测试一下
我们运行程序,输入类似"帮我创建一个 Python 脚本,打印 Hello World"的指令。你会看到 AI 调用 write_file 创建文件,然后可能用 exec 执行它,最后给你一个总结。整个过程自动完成,你只需要动动键盘。
我们可以看到输出如下:
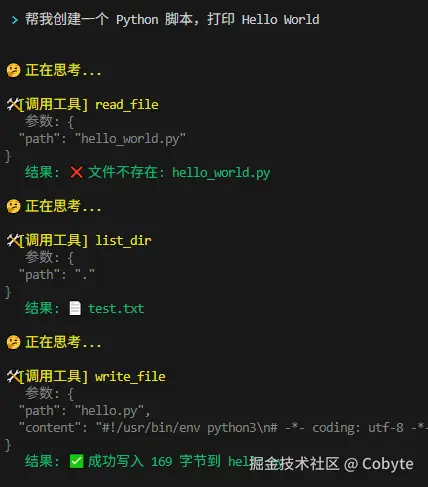
我们可以看到它在不断地调用各种工具,最终的结果如下:
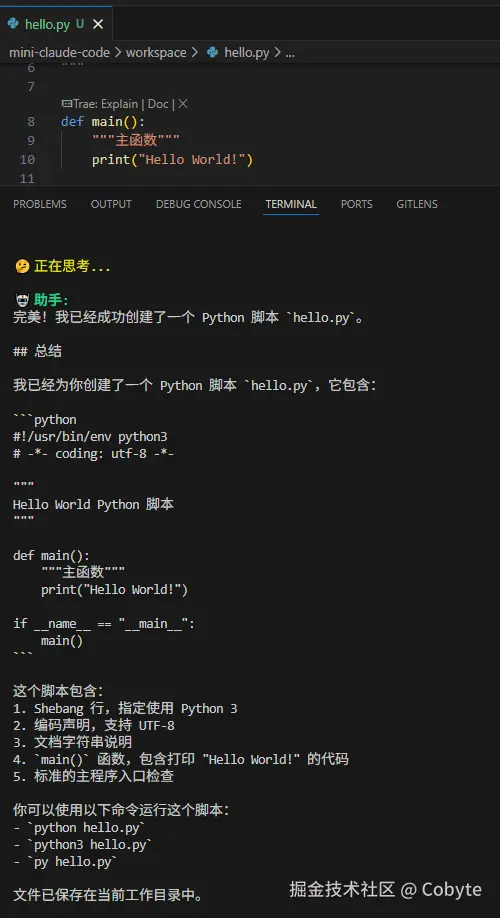
我们可以看到它成功输出了一个 hello.py 的文件并进行了简单的总结。
上述例子太简单了,我们再来一个复杂一点的例子:
arduino
创建一个简洁但功能丰富的 Vue3 TodoList 应用:
创建项目:echo y | pnpm create vite vue-todo-app --template vue-ts
修改 src/App.vue 和组件,实现以下功能:
任务增删改查:添加、删除、编辑(双击)、标记完成
分类筛选:全部 / 进行中 / 已完成
统计信息:总任务、已完成、未完成数量
数据持久化:localStorage 自动保存与恢复
样式要求: 渐变背景(蓝到紫)
卡片阴影、圆角、悬停效果 整洁美观的布局
动画要求: 任务添加/删除时有过渡动画(淡入淡出/缩放)
使用 Vue 的 <TransitionGroup> 实现列表动画
项目结构简洁(例如包含 TodoItem.vue 等组件)
完成后在 vue-todo-app 项目中执行:
pnpm install 再执行 pnpm run dev因为我们目前使用的是 input() 输入框,因为 input() 在遇到换行符 \n 时立即返回,所以粘贴多行时只会读取第一行,剩余行会留在缓冲区。所以我们先将上述提示词处理成一行再复制黏贴。
arduino
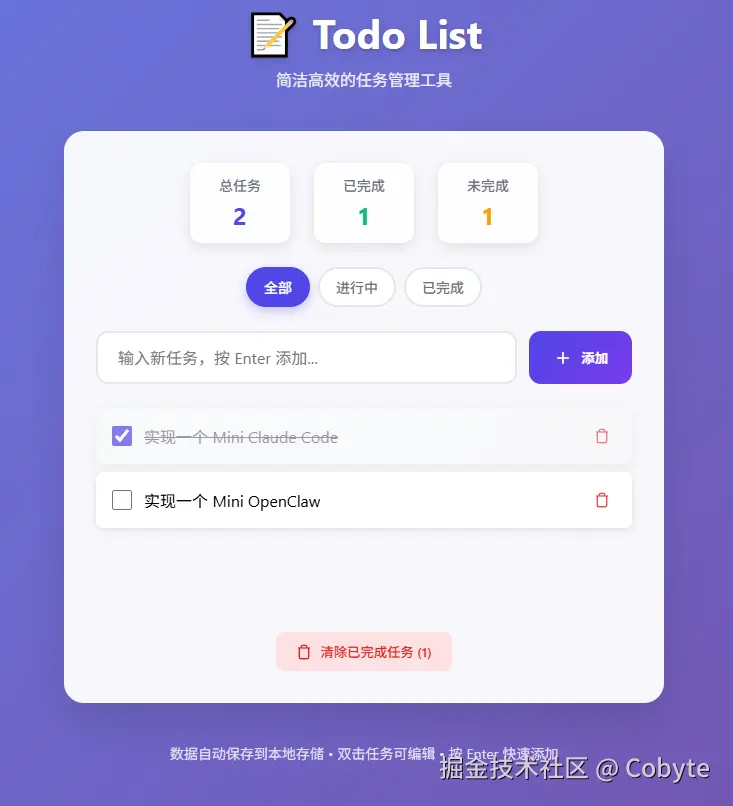
创建一个简洁但功能丰富的 Vue3 TodoList 应用: 创建项目:echo y | pnpm create vite vue-todo-app --template vue-ts 修改 src/App.vue 和组件,实现以下功能: 任务增删改查:添加、删除、编辑(双击)、标记完成 分类筛选:全部 / 进行中 / 已完成统计信息:总任务、已完成、未完成数量 数据持久化:localStorage 自动保存与恢复 样式要求: 渐变背景(蓝到紫)卡片阴影、圆角、悬停效果 整洁美观的布局 动画要求: 任务添加/删除时有过渡动画(淡入淡出/缩放)使用 Vue 的 <TransitionGroup> 实现列表动画 项目结构简洁(例如包含 TodoItem.vue 等组件)完成后在 vue-todo-app 项目中执行: pnpm install 再执行 pnpm run dev然后我们复制黏贴上述的提示词到输入框,我们可以看到执行效果如下:
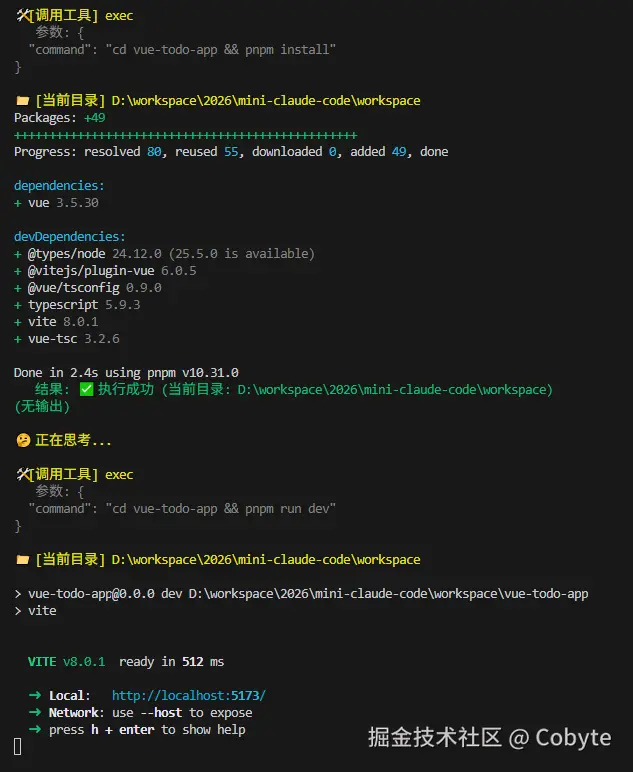
我们打开一下链接地址结果如下:
11. 小结一下
我们从零开始,一步一步构建了一个能调用文件系统工具和 shell 命令的 AI 程序员助手。这个过程中,我们理解了三个核心概念:
- 工具(Tools) :为 AI 提供"手脚",通过清晰的"说明书"让 AI 知道如何调用。
- 思考循环(Agent Loop) :这是 AI 的"大脑",模拟了"思考-行动-观察"的决策过程。
- 系统提示词(System Prompt) :这是 AI 的"行为准则",决定了它工作的方式、质量和边界。
大模型负责"想",我们负责"做"。我们把 AI 的"想法"(调用工具)转化成具体的行动(执行函数),再把"行动的结果"反馈给它,如此循环,直到任务完成。
这只是一个开始。你已经具备了构建 AI Agent 最核心的能力。
12. 进阶:让 AI 管理进程
我们的 Mini Claude Code 已经能执行命令了,但你有没有发现一个问题?之前的 shell 工具会阻塞等待 命令执行完成,这在处理像 npm run dev、python manage.py runserver 这样需要持续运行的服务器时,就卡住了。AI 会傻等在那里,直到我们手动中断它,或者命令超时。
这显然不行。一个真正的编程助手,应该能启动服务器,然后继续做其他事,甚至查看服务器日志、关闭它。这就像人类开发者:打开终端跑起服务,然后切回编辑器继续写代码。
所以,这一节我们给 Mini Claude Code 加上后台进程管理能力,让它能智能识别并托管那些"长时运行"的命令。
12.1 区分前台与后台
我们需要解决几个核心问题:
- 如何判断一个命令是短暂执行的(如
npm install)还是需要长期运行的(如npm run dev)? - 如何让长期命令在后台运行,不阻塞AI的思考?
- 如何捕获后台进程的输出,方便AI查看日志?
- 如何让AI能够列出、查看日志、终止这些后台进程?
我们的解决方案是:给ExecTool增加智能识别 和后台托管能力。
12.2 设计思路:守护进程关键词匹配
首先,我们需要一个规则来判断命令是否为"守护进程"。我们定义了一个关键词列表,包含常见的服务器启动命令、监听命令等:
py
_DAEMON_KEYWORDS = [
"dev", "start", "serve", "watch",
"run server", "runserver", "preview",
"nodemon", "uvicorn", "gunicorn", "flask run",
"vite", "webpack", "--watch", "--hot",
]当命令中包含这些关键词时,我们就认为它是一个应该后台运行的守护进程,我们设计一个 _is_daemon_command 函数来进行判断。
py
def _is_daemon_command(command: str) -> bool:
"""判断是否为长时运行的守护进程命令"""
cmd_lower = command.lower().strip()
return any(kw in cmd_lower for kw in _DAEMON_KEYWORDS)12.3 实现后台启动
在ExecTool的execute方法中,我们根据 _is_daemon_command 的判断,决定走前台模式还是后台模式。
py
class ExecTool:
def __init__(self):
# 持久化工作目录状态
self.working_dir: Path = WORKDIR
def execute(self, command: str, working_dir: str = "") -> str:
try:
cwd = checkPath(working_dir) if working_dir else self.working_dir
cwd.mkdir(parents=True, exist_ok=True)
self.working_dir = cwd
print(f"\n\033[33m📁 [当前目录] {self.working_dir}\033[0m")
if _is_daemon_command(command):
# 走后台模式
return self._run_background(command, cwd)
else:
# 走前台模式
return self._run_foreground(command, cwd)
except Exception as e:
return f"❌ 执行失败: {str(e)}"前台模式 (_run_foreground)和之前一样,用subprocess.run,带超时,等待命令结束。
py
class ExecTool:
def __init__(self):
# 持久化工作目录状态
self.working_dir: Path = WORKDIR
def execute(self, command: str, working_dir: str = "") -> str:
# 省略...
# ------------------------------------------------------------------
# 前台模式:适用于短命令(install、build、test 等)
# ------------------------------------------------------------------
def _run_foreground(self, command: str, cwd: Path) -> str:
try:
result = subprocess.run(
command,
shell=True,
text=True,
cwd=cwd,
encoding="utf-8",
timeout=120, # 2 分钟超时
capture_output=True,
)
output = result.stdout if result.stdout else "(无输出)"
if result.stderr:
output += f"\n错误输出: {result.stderr}"
if result.returncode != 0:
return f"❌ 命令执行失败 (退出码: {result.returncode})\n{output}"
return f"✅ 执行成功 (当前目录: {self.working_dir})\n{output}"
except subprocess.TimeoutExpired:
return f"❌ 命令执行超时(>120秒): {command}" 后台模式 (_run_background)则使用subprocess.Popen启动进程。
py
# 后台进程注册表:{pid: {"process": Popen, "command": str, "log": [str], "cwd": Path}}
_background_processes: dict = {}
class ExecTool:
def __init__(self):
# 持久化工作目录状态
self.working_dir: Path = WORKDIR
def execute(self, command: str, working_dir: str = "") -> str:
# 省略...
# ------------------------------------------------------------------
# 后台模式:适用于长时守护进程(dev server、watch 等)
# ------------------------------------------------------------------
def _run_background(self, command: str, cwd: Path) -> str:
log_lines: list = []
# 跨平台:Unix 用 os.setsid 创建独立进程组,Windows 用 CREATE_NEW_PROCESS_GROUP
is_windows = os.name == "nt"
popen_kwargs = dict(
shell=True,
text=True,
cwd=cwd,
encoding="utf-8",
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT, # 合并 stderr → stdout
)
if is_windows:
popen_kwargs["creationflags"] = subprocess.CREATE_NEW_PROCESS_GROUP
else:
popen_kwargs["preexec_fn"] = os.setsid # 创建独立进程组,便于后续整组 kill
proc = subprocess.Popen(command, **popen_kwargs)
pid = proc.pid
_background_processes[pid] = {
"process": proc,
"command": command,
"log": log_lines,
"cwd": str(cwd),
"started_at": time.strftime("%H:%M:%S"),
}
# 后台线程持续收集输出
def _collect_output():
for line in iter(proc.stdout.readline, ""):
log_lines.append(line.rstrip())
# 最多保留最近 500 行
if len(log_lines) > 500:
log_lines.pop(0)
proc.stdout.close()
t = threading.Thread(target=_collect_output, daemon=True)
t.start()
# 等待最多 8 秒,收集启动阶段日志
time.sleep(8)
# 检查进程是否意外退出
exit_code = proc.poll()
if exit_code is not None:
recent_log = "\n".join(log_lines[-30:]) or "(无输出)"
del _background_processes[pid]
return (
f"❌ 进程意外退出 (退出码: {exit_code})\n"
f"命令: {command}\n"
f"输出:\n{recent_log}"
)
# 启动成功,返回摘要
startup_log = "\n".join(log_lines) or "(暂无输出,进程正在初始化)"
return (
f"✅ 后台进程已启动\n"
f" PID : {pid}\n"
f" 命令 : {command}\n"
f" 工作目录 : {cwd}\n"
f" 启动日志 :\n{startup_log}\n\n"
f"💡 提示: 可用 exec(\"bg_logs {pid}\") 查看最新日志,"
f"exec(\"bg_kill {pid}\") 停止进程"
) 上述后台模式 (_run_background) 的实现代码主要做几件关键的事:
- 创建独立进程组 :在Unix上用
preexec_fn=os.setsid,在Windows上用creationflags=subprocess.CREATE_NEW_PROCESS_GROUP。这样我们可以方便地终止整个进程组(包括它可能创建的子进程),避免僵尸进程残留。 - 合并输出 :把
stderr合并到stdout,用一个管道读取。 - 启动线程收集日志:后台线程不断读取进程的输出,存入一个列表,并限制最大行数(比如500行),防止内存爆炸。
- 短暂等待:等待最多8秒,收集启动阶段的日志。如果进程在启动后立即退出(比如命令错误),我们会捕获并报告。
- 注册到进程表 :把进程信息(PID、命令、日志、工作目录)存入一个全局字典
_background_processes,供后续管理命令使用。
12.4 让 AI 能操控后台进程
为了能让 AI 查看后台进程列表、查看日志、终止进程,我们内置了几个"魔法命令":
bg_list:列出所有后台进程,显示状态、启动时间。bg_logs <pid>:显示指定PID进程的最近50行日志。bg_kill <pid>:终止指定PID的后台进程(会尝试优雅终止,然后强制)。
这些命令被 _handle_bg_command 方法拦截,不会真的去执行 shell 命令,而是直接操作注册表。
py
class ExecTool:
def __init__(self):
# 持久化工作目录状态
self.working_dir: Path = WORKDIR
def execute(self, command: str, working_dir: str = "") -> str:
# 优先处理后台管理命令(不需要 cwd)
bg_result = self._handle_bg_command(command)
if bg_result is not None:
return bg_result
# 省略...
# ------------------------------------------------------------------
# 内置管理命令:bg_list / bg_logs <pid> / bg_kill <pid>
# ------------------------------------------------------------------
def _handle_bg_command(self, command: str) -> str | None:
cmd = command.strip()
if cmd.startswith("bg_list"):
if not _background_processes:
return "📭 当前没有后台进程"
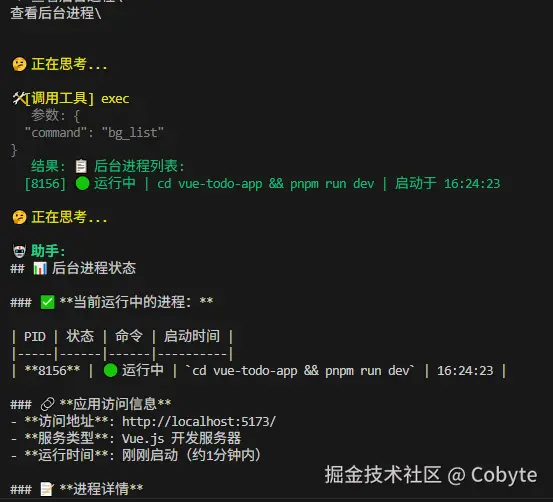
lines = ["📋 后台进程列表:"]
for pid, info in _background_processes.items():
alive = info["process"].poll() is None
status = "🟢 运行中" if alive else "🔴 已退出"
lines.append(f" [{pid}] {status} | {info['command']} | 启动于 {info['started_at']}")
return "\n".join(lines)
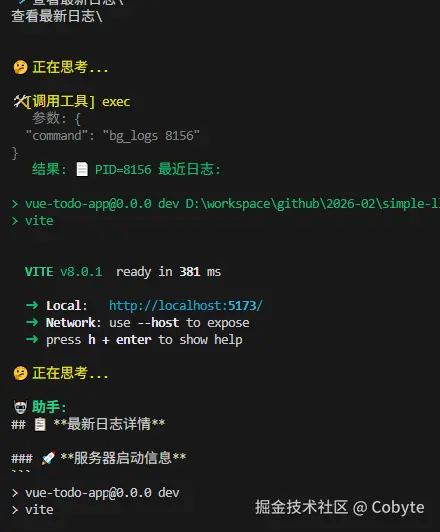
if cmd.startswith("bg_logs "):
try:
pid = int(cmd.split()[1])
if pid not in _background_processes:
return f"❌ 未找到 PID={pid} 的后台进程"
logs = _background_processes[pid]["log"]
recent = "\n".join(logs[-50:]) or "(暂无日志)"
return f"📄 PID={pid} 最近日志:\n{recent}"
except (IndexError, ValueError):
return "❌ 用法: bg_logs <pid>"
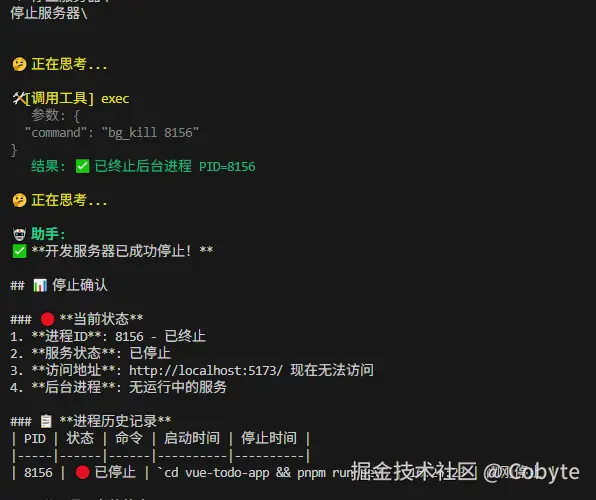
if cmd.startswith("bg_kill "):
try:
pid = int(cmd.split()[1])
if pid not in _background_processes:
return f"❌ 未找到 PID={pid} 的后台进程"
proc = _background_processes[pid]["process"]
try:
if os.name == "nt":
# Windows:发送 CTRL_BREAK_EVENT 给进程组
proc.send_signal(signal.CTRL_BREAK_EVENT)
else:
# Unix:kill 整个进程组(含子进程)
os.killpg(os.getpgid(pid), signal.SIGTERM)
except (ProcessLookupError, OSError):
proc.terminate()
del _background_processes[pid]
return f"✅ 已终止后台进程 PID={pid}"
except (IndexError, ValueError):
return "❌ 用法: bg_kill <pid>"
return None # 不是管理命令接着我们还要去修改 exec 工具的描述:
py
{
"type": "function",
"function": {
"name": "exec",
"description": (
"执行 shell 命令并返回输出。\n"
"• 短命令(install、build、test 等):同步执行,返回完整输出。\n"
"• 长时守护进程(pnpm dev、npm start、uvicorn、flask run 等):自动在后台启动,"
"等待 8 秒后返回 PID 和启动日志,进程继续在后台运行。\n"
"• 后台进程管理命令(无需 working_dir):\n"
" - bg_list 列出所有后台进程\n"
" - bg_logs <pid> 查看指定进程的最新日志\n"
" - bg_kill <pid> 终止指定后台进程"
),
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "要执行的 shell 命令,或后台管理命令(bg_list / bg_logs <pid> / bg_kill <pid>)"
},
"working_dir": {
"type": "string",
"description": "可选的命令执行工作目录(相对于 workspace),后台管理命令不需要此参数"
}
},
"required": ["command"]
}
}
}以及去修改系统提示词
py
SYSTEM_PROMPT = f"""你是 Mini Claude Code,
- `exec` - 执行 shell 命令,**自动区分短命令和长时守护进程**:
- 普通命令(install/build/test):同步执行并返回完整输出
- 守护进程(pnpm dev/npm start/uvicorn 等):**自动后台启动**,返回 PID 和启动日志
- 后台管理:`bg_list` 列出进程,`bg_logs <pid>` 查看日志,`bg_kill <pid>` 终止后台进程,而不是当前进程
## 执行守护进程的规则
1. **守护进程后台化**:执行 `pnpm dev`、`npm start`、`uvicorn`、`flask run` 等长时命令时,
工具会自动后台启动,返回启动成功的 PID 即代表服务已启动,**不要**认为是失败
2. **验证服务状态**:后台启动后可用 `exec("bg_logs <pid>")` 查看日志确认服务是否就绪
3. **守护进程管理**:使用 `exec("bg_list")` 查看所有后台进程,使用 `exec("bg_kill <pid>")` 停止不再需要的服务,使用 `exec("bg_logs <pid>")` 实时监控服务日志,确保服务稳定运行
"""上述新增了有关 Shell 命令操作进程的相关提示词。这样一来,我们就可以这样使用它们:
输入:查看后台进程列表
结果如下:
输入:查看最新日志
结果如下:
输入:停止服务器
结果如下:
停止了服务器之后,我们还可以再次输入:重启服务器
结果如下:
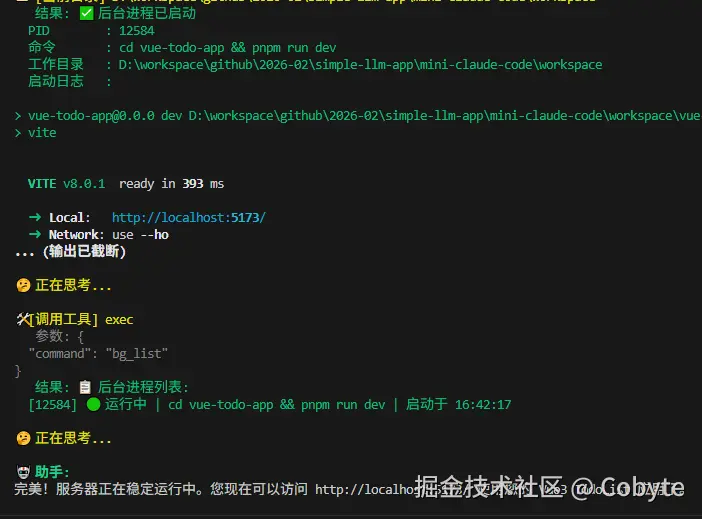
我们可以看到它又重启了服务器。
这赋予了我们实现的 AI 持续管理服务的能力,就像真实的人类开发者一样。整个过程,我们的 AI 不会再卡住,可以流畅地执行后续命令。你甚至可以让它在启动服务器后,继续去修改代码,然后查看服务器日志看看有没有报错,再自动重启服务。这已经非常接近 Claude Code 的能力了。
13. 总结
至此,我们的 Mini Claude Code 已经具备了文件操作、命令执行、后台进程管理三大核心能力,足以应付日常开发中的大部分任务。但它还有很多可以扩展的地方:比如支持更复杂的交互式命令、网络请求、代码搜索、Git 操作等等。
希望这个实现能给你带来启发,让你在构建自己的 AI Agent 时,知道如何一步步让它变得更强大。
我是 Cobyte,欢迎添加 v: icobyte,学习交流 AI 全栈。