从"文字接龙"到"超级管家":大模型全栈技术通关指南
如果你最近被各种大模型名词轰炸得晕头转向------今天听说GPT-4o又进化了,明天看到Claude在写代码,后天又冒出个Agent要取代程序员------别慌。其实,剥去那些高大上的外衣,大模型的世界并没有那么神秘。
今天,我们将基于最核心的技术图谱,带你从底层的"砖块"一路搭建到顶层的"智能大厦"。我们将穿越八个关卡:LLM(大语言模型)、Token(数据单元)、Context(记忆)、Prompt(指令)、Tool(工具)、MCP(标准)、Agent(智能体)以及Agent Skill(技能定制) 。
准备好了吗?我们要开始这场从"人工智障"到"人工智能"的进化之旅了。
第一关:底层引擎------大语言模型(LLM)
"本质上,它就是一个读过很多书的文字接龙高手。"
1.1 核心定义:它是怎么思考的?
大语言模型(Large Language Model,简称LM或LLM),你可以把它想象成一个超级博学的鹦鹉。所有的大模型都是基于Transformer这套架构训练出来的。
2017年,Transformer这套架构最早是由Google团队在《Attention is All You Need》这篇论文提出来的,这就像是AI界的"创世纪"。在此之前,AI读文章是像我们读书一样从左到右一个个字读(RNN/LSTM),效率低且记不住前面的内容。Transformer的出现,让AI可以"一眼看全"整句话,通过注意力机制(Attention)捕捉词与词之间的关系。
工作原理极简版 :
LLM 的生成本质,就是不断把自己输出的词,再喂给自己去预测下一个词。
举个最简单的例子:你问:"xiaoxue 的文章怎么样?"
- 模型先算出第一个概率最高的词:特别
- 它不会停,而是把「特别」追加到原来的输入后面,变成:"xiaoxue 的文章怎么样 特别"
- 再把这一整段重新输入模型 ,预测下一个词:得
- 再把「得」追加进去,继续预测:好
- 当模型判断内容已经完整,就会输出一个结束符(EOS) ,停止生成。
最终我们看到的完整回答:特别得好 ,就是这样一步一个 token、逐词接龙算出来的。
这就是大语言模型最底层、最核心的生成原理。
1.2 发展里程碑:从单挑到群殴
- 2017年:Transformer架构提出,奠定了技术地基。
- 2022年底:GPT-3.5发布。这是AI界的"iPhone时刻",首个达到可用级别的大模型横空出世,聊天机器人开始像人一样说话。
- 2023年3月:GPT-4发布。能力天花板被大幅拉升,不仅能聊天,还能通过高难度的律师考试、写代码。
- 2023年后:百家争鸣。Claude、Gemini等模型涌现,AI赛道从OpenAI的"独角戏"变成了"诸神黄昏"的多强竞争。
第二关:数据原子------Token
"在AI眼里,'你好'不是一个词,而是两块积木。"
2.1 什么是Token?
大模型看不懂人类的语言,它只认识数字。Token就是大模型处理文本的最小单位。
这就好比乐高积木。人类看到的是"一座城堡",但在AI眼里,这是由一个个具体的积木块(Token)拼起来的。
- 编码过程:文本 -> 切分为Token -> 映射为Token ID(数字)。
- 解码过程:Token ID -> 还原为文本。
2.2 Token与自然语言的"爱恨情仇"
Token和我们在语文课上学到的"词语"并不是一一对应的,这经常让新手感到困惑。
- 中文词语:经常被拆分。比如"程序员",在AI眼里是"程序"+"员"两个Token。这是因为中文没有空格,分词比较麻烦。
- 英文单词:常见词通常对应1个Token。比如"hello"就是一个Token。
- 复杂单词:会被拆解。比如"helpful"被拆成"help"+"ful"。
- 特殊字符:甚至一个表情符号可能占用3个Token。
OpenAI提供了一个把文本转化为Token和Token ID的页面,大家可以去试一下:
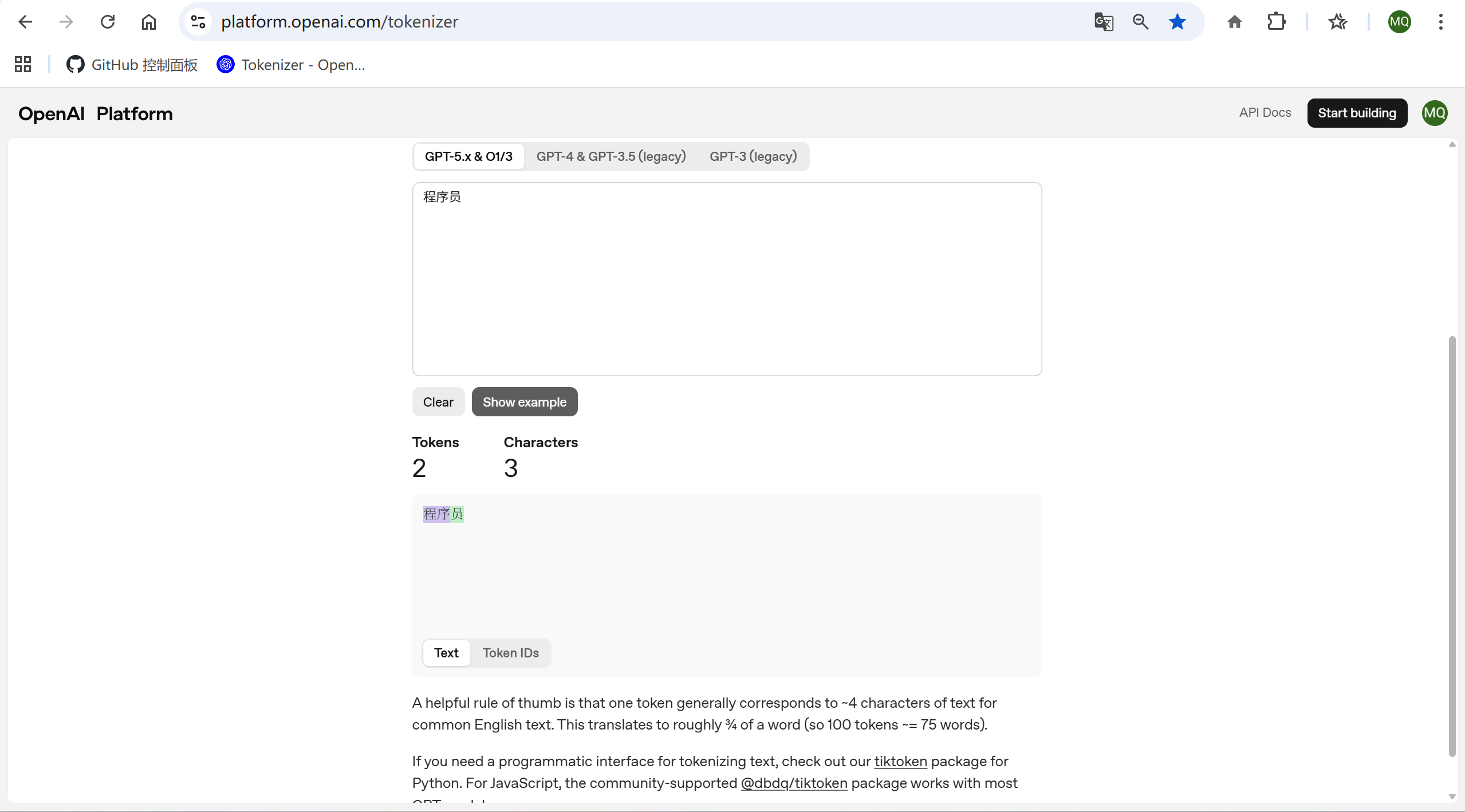
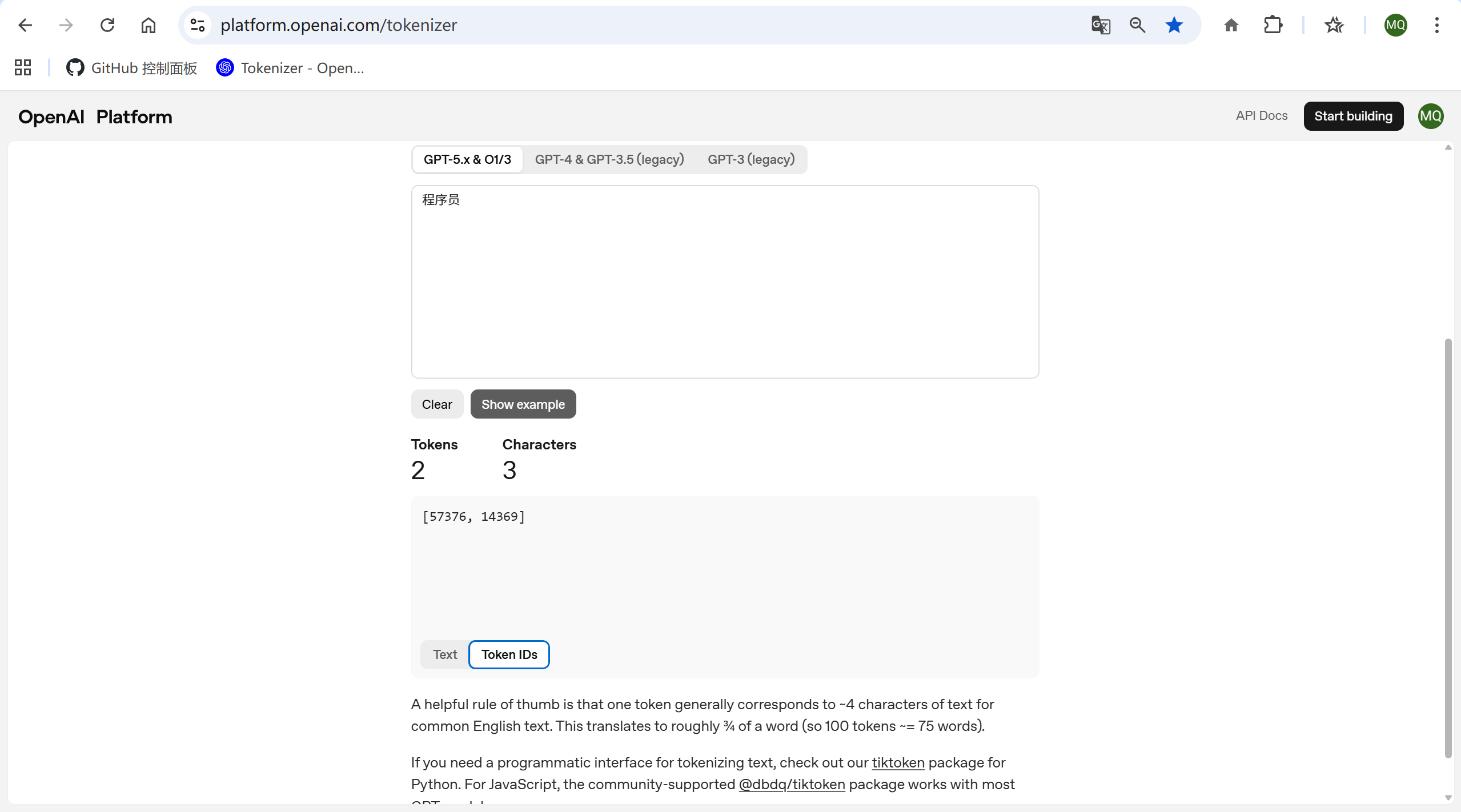
2.3 量化参考:你的钱包还好吗?
很多大模型是按Token收费的,所以了解换算关系很重要(大致估算):
- 1个Token ≈ 0.75个英文单词
- 1个Token ≈ 1.5 - 2个汉字
- 40万Token ≈ 60-80万汉字(这大概是一本《红楼梦》的厚度)
第三关:临时记忆体------Context
"金鱼只有7秒记忆,而大模型有'上下文窗口'。"
3.1 核心概念:什么是Context?
Context(上下文)是大模型每次处理任务时接收的信息总和。你可以把它理解为模型的 "短期记忆" 或者 "工作台" 。
这个工作台上放着什么?
- 用户的问题
- 之前的对话历史
- 当前输出的Token
- 工具列表
- System Prompt(系统指令)
在实际开发中(尤其是调用 OpenAI、Anthropic 等主流大模型 API 时),这些上下文信息正是被组织成一个 messages 数组(列表),这是行业通用的最佳实践。
# javascript
// 引入 OpenAI SDK
const OpenAI = require('openai');
// 1. 初始化客户端(推荐把密钥放在环境变量,而非硬编码)
const openai = new OpenAI({
apiKey: '你的API密钥', // 实际开发中用 process.env.OPENAI_API_KEY
});
// 2. 定义核心的 messages 数组(Context 上下文)
const messages = [
// System Prompt:模型的全局规则
{ role: 'system', content: '你是一个简洁的助手,只回答核心问题。' },
// 历史对话:用户提问 + 模型回答
{ role: 'user', content: 'xiaoxue的文章怎么样?' },
{ role: 'assistant', content: '特别得好' },
// 当前用户新问题
{ role: 'user', content: '那他的文章好在哪里?' },
];
// 3. 调用模型并获取回答(使用 async/await 处理异步)
async function getModelAnswer() {
try {
// 调用 Chat Completion API
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo', // 模型版本
messages: messages, // 传入所有上下文
temperature: 0.7, // 可选:生成随机性,0-2 之间
});
// 4. 提取并打印回答
const answer = response.choices[0].message.content;
console.log('模型回答:', answer);
return answer;
} catch (error) {
// 异常处理(网络错误、密钥错误、额度不足等)
console.error('调用失败:', error.message);
}
}
// 执行函数
getModelAnswer();3.2 容量限制:Context Window
这个"工作台"的大小是有限的,被称为Context Window(上下文窗口) 。一旦信息量超过了这个窗口,模型就会"失忆",忘掉最早期的对话内容。
主流模型大比拼(截至当前) :
- GPT-4o / Gemini 1.5 Pro / Claude 3.5 :这些顶级模型的上下文窗口已经达到了100万 - 200万Token级别。
- 这意味着什么? 这意味着你可以把几十本小说、长达数小时的会议录音转录稿一次性扔给它,让它帮你总结。它真的能"读完"整本书。
3.3 突破限制的方案:RAG技术
如果内容实在太多,超过了窗口怎么办?
这时候就需要RAG(检索增强生成) 技术。
- 原理:就像"开卷考试"。模型不需要把整本书背下来(放入Context),而是先去知识库(图书馆)里检索与问题最相关的片段,只把这些关键信息送入模型。
- 好处:既降低了Token消耗(省钱),又解决了长文本遗忘的问题。
RAG(检索增强生成)的完整流程通常可以拆解为两个主要阶段:数据准备阶段(离线) 和 查询响应阶段(在线) 。
为了让你更直观地理解,我们可以把这个流程想象成一个 "图书馆管理员协助专家答题" 的过程。
第一阶段:数据准备(建库)
这是"离线"过程,通常在系统上线前或定期后台运行。目的是把杂乱的文档变成模型能看懂、能快速查找的"索引卡片"。
-
数据加载 (Data Loading)
- 动作:收集各种来源的数据(PDF、Word、网页、数据库、Markdown等)。
- 比喻:图书馆采购员把买来的书搬进仓库。
-
数据清洗 (Data Cleaning)
- 动作:去除乱码、HTML标签、无关广告、统一格式。
- 比喻:图书管理员把书上的灰尘擦干净,撕掉封面上的价格标签,确保内容整洁。
-
文本切片 (Chunking) ------ 关键步骤
- 动作:将长文档切分成小的片段(Chunks)。不能太大(超出模型窗口或包含太多噪音),也不能太小(丢失上下文语义)。通常按字符数、段落或语义边界切割,并保留一定的重叠(Overlap)来保证各个Chunk 之间语义的连贯。
- 比喻:把厚厚的书拆成一张张独立的"知识卡片",每张卡片讲清楚一个具体的知识点。如果一张卡片切断了一个句子,就稍微多留几个字到下一张(重叠)。
-
向量化 (Embedding)
- 动作:使用嵌入模型(Embedding Model)将每个文本片段转化为一串数字向量(Vector)。这串数字代表了文本的"语义含义"。
- 比喻 :给每张"知识卡片"打上唯一的语义标签码。意思相近的卡片,它们的标签码在数学空间里距离就很近。
-
存入向量数据库 (Vector Store)
- 动作:将这些向量及其对应的原始文本片段存储到专门的向量数据库(如Milvus, Pinecone, Chroma, Faiss等)中。
- 比喻:把这些打好标签的卡片整齐地归档到特殊的"语义书架"上,方便以后通过标签码快速定位。
第二阶段:查询响应(推理)
这是"在线"过程,当用户提问时实时发生。
-
用户提问 (User Query)
- 动作:用户输入自然语言问题。
- 例子:"公司去年的差旅报销政策有什么变化?"
-
查询向量化 (Query Embedding)
- 动作 :使用与建库时相同的嵌入模型,将用户的问题也转化成一串数字向量。
- 比喻:管理员把用户的问题也转换成一个"搜索标签码"。
-
相似度检索 (Retrieval 检索阶段)
- 动作:在向量数据库中,计算"问题向量"与所有"文档片段向量"的距离(相似度)。找出距离最近(最相似)的 Top-K 个片段。
- 比喻:拿着"搜索标签码"去"语义书架"上快速扫描,找出标签码最接近的几张"知识卡片"。哪怕用户没用到原文的词(比如用户说"出差费",原文是"差旅报销"),因为语义相近,也能被找出来。
-
构建提示词 (Prompt Construction / Augmentation 增强阶段)
-
动作:将检索到的相关片段(Context)与用户的原始问题(Query)组合,按照特定的模板组装成一个新的提示词(Prompt)。
-
结构示例:
你是一个助手。请根据以下参考信息回答问题。 如果参考信息中没有答案,请直接说不知道,不要编造。 【参考信息】: {检索到的片段1} {检索到的片段2} ... 【用户问题】: {用户原始问题} -
比喻:管理员把那几张找到的"知识卡片"递给专家(LLM),并附言:"请看这些资料,然后回答这个问题。"
-
-
生成回答 (Generation 生成阶段)
- 动作:大语言模型(LLM)阅读组装好的 Prompt,结合参考信息和自身能力,生成最终答案。
- 比喻:专家阅读了管理员提供的资料,组织语言,给出了准确、有依据的回答。
-
返回结果 (Response)
- 动作:将生成的答案展示给用户。通常还可以附带引用来源(Citation),告诉用户答案出自哪篇文档的哪一段。
流程图示总结
在线查询
离线建库
相似度检索
原始文档
清洗 & 切片
Embedding 模型
向量向量
向量数据库
用户提问
Embedding 模型
问题向量
Top-K 相关片段
组装 Prompt: 片段 + 问题
大语言模型 LLM
最终回答
第四关:指令交互------Prompt
"你给它的指令越清晰,它给你的惊喜就越大。"
4.1 Prompt是什么?
Prompt(提示词)就是给大模型的问题或指令。它是人机交互的接口,直接决定了模型输出的质量。
这就好比你给下属派活。如果你说"做个PPT",下属可能一脸懵;如果你说"做一个关于Q3销售分析的PPT,风格要商务蓝,包含图表",下属就能精准交付。
4.2 Prompt的分类
-
User Prompt:用户输入的具体任务。例如:"帮我写一首关于秋天的诗。"
-
System Prompt:开发者后台配置的人设与规则。这是模型的"灵魂"。
- 例子:"你是一个耐心的数学老师。当学生问你问题时,不要直接给答案,而是要一步步引导他们思考。"
- 有了这个System Prompt,哪怕用户问"1+1等于几",模型也会回答:"让我们想想,如果你有一个苹果,再拿一个苹果,现在你有几个呢?"
4.3 Prompt Engineering(提示词工程)
曾经,如何写出完美的Prompt是一门显学。大家研究各种框架(如CO-STAR, BROKE等)。
现状:随着模型越来越聪明,Prompt Engineering的重要性在下降。
- 原因1:门槛低了。现在的模型能听懂"人话",不需要像写代码一样写Prompt。
- 原因2:模型能力强了。它能推测你的模糊意图。
- 核心原则 :依然保持不变------清晰、具体、明确。把话说清楚,永远是沟通的第一法则。
第五关:外部能力扩展------Tool
"大模型是博学的书呆子,Tool给了它一双手。"
5.1 核心痛点
大模型虽然博学,但它有两个致命弱点:
- 无法获取实时信息:它的知识截止于训练结束那天。它不知道今天北京的天气,也不知道刚才发生的新闻。
- 计算能力有限:让大模型算"12345 * 67890",它可能会一本正经地胡说八道,因为它本质是预测文字,不是计算器。
5.2 Tool的作用
Tool(工具)就是大模型调用的外部函数。通过Tool,模型可以感知和影响外部世界。
- 定义:大模型的大脑 + 外部工具的手脚 = 全能助手。
- 解决痛点:想查天气?调用天气API。想算数?调用计算器代码解释器。想画图?调用DALL-E。
5.3 工作流程
这是一个典型的"外包"流程:
- 用户提问:"明天北京天气怎么样?"
- 平台(千问、豆包)转发:把问题连同"工具列表"(里面有天气查询工具)发给大模型。
- 大模型分析 :模型心想:"我不知道天气,但我看到列表里有个
get_weather工具,我调用它!" -> 生成工具调用指令返回给平台。 - 平台执行:平台真的去调用天气API,获取结果"晴,25度"。
- 大模型整理:拿到结果后,模型组织语言:"明天北京天气晴朗,气温25度,适合出游。" -> 输出给用户。
5.4 角色分工
- 大模型:CEO。负责决策,选择用什么工具,生成参数,归纳结果。
- 工具:员工。负责执行具体功能(查天气、发邮件)。
- 平台:秘书。负责转发信息,执行工具调用。
第六关:工具标准化------MCP
"就像Type-C统一了充电口,MCP想统一AI的工具接口。"
6.1 什么是MCP?
全称:Model Context Protocol(模型上下文协议) 。
这是一个比较新的概念,旨在解决"工具接入规范不统一"的问题。
6.2 为什么要搞MCP?
在 MCP 出现之前(2024年以前),AI 工具开发确实是一场噩梦,正如你所说:
-
混乱现状:如果你想开发一个"查询天气"的工具让 AI 使用:
- 为 ChatGPT (OpenAI) 开发,你要写一套符合
Functions/Tools规范的代码。 - 为 Claude (Anthropic) 开发,你要适配它的
Tool Use格式。 - 为 Gemini (Google) 开发,你又得重写一套
Function Calling逻辑。 - 如果是本地运行的 Llama 或 Ollama,可能又是另一套插件系统。
- 为 ChatGPT (OpenAI) 开发,你要写一套符合
-
后果:开发者需要维护多套代码库(N个模型 × M个工具 = N×M 的工作量)。这就像以前出门旅行要带一堆不同形状的充电头,既浪费资源又容易出错。
6.3 MCP 的解决方案:真正的"一次开发,到处运行"
MCP 的核心逻辑是将 "模型层" 和 "数据/工具层" 解耦,中间通过标准协议连接。
-
架构角色:
- MCP Host (宿主) :即 AI 模型客户端(如 Claude Desktop, Cursor, Windsurf 等)。它们现在只需要学会一种语言:MCP 协议。
- MCP Server (服务器) :即你的工具或服务(如连接数据库、读取本地文件、调用谷歌搜索、操作 Jira)。开发者只需按 MCP 标准写一次代码。
- MCP Client (客户端) :通常内置在 Host 中,负责与 Server 通信。
MCP Client 是 Host(编辑器,如cursor)内部自带的一个"驱动程序" 。你不需要安装它,也不需要编写它,你只需要通过配置文件告诉它 "驱动哪个设备(Server,各种工具tools)" ,它就会自动帮你完成所有的连接和沟通工作。
-
实际效果:
- 你开发了一个 MCP 文件系统服务器。
- 结果:它不仅能被 Claude 直接调用,也能被集成了 MCP 协议的 Cursor 编辑器、或者任何支持 MCP 的开源模型框架(如 LangChain 新版)直接识别。
- 无需修改:你不需要为每个 AI 平台单独打包或修改代码。
第七关:自主决策系统------Agent
"从'问答机器'进化为'项目经理'。"
7.1 Agent定义
Agent(智能体)是能够自主规划、自主调用工具(在现代架构中通常基于MCP协议以实现解耦,早期或特定场景下也可通过硬编码实现)、持续工作直至完成用户任务 的系统。
如果说普通的大模型是"问答机器"(你问它答),那么Agent就是"项目经理"(你给目标,它自己拆解任务去干)。
7.2 核心能力
- 多步骤推理:能把一个大任务拆解成小任务。
- 工具选择:知道什么时候该用什么工具。
- 流程控制:如果第一步失败了,知道怎么重试或者换条路走。
7.3 典型构建模式
-
ReAct (Reasoning + Acting) :这是最经典的模式。模型在输出结果前,会先进行"思考"(Reasoning),然后决定"行动"(Acting),观察结果,再思考,再行动,循环往复。
- 内心戏:"用户要查苹果股价(思考)-> 调用搜索工具(行动)-> 得到结果150美元(观察)-> 用户还要对比微软(思考)-> 调用搜索工具(行动)..."
-
Plan and Execute:先制定一个完整的计划列表,然后逐个执行。
7.4 代表产品
Claude Code, Codex, Gemini CLI等,都是Agent的雏形或具体应用。它们不仅能聊天,还能直接在终端里帮你写代码、运行代码、修改文件。
第八关:任务定制------Agent Skill
"给Agent发一本'员工手册'。"
8.1 核心功能
Agent Skill是给Agent的说明文档。
就像新员工入职需要看员工手册一样,Agent也需要知道它的任务规则、执行步骤、输出格式等。
- Skill 等于可复用的AI 专业能力包(Prompt + 规划 + 工具 + 资源),是instructions + scripts + resources 的组合。
- Skill 解决了传统Prompt 不可复用的问题,它稳定、不用每次都重复写、需要可直接调用。
- Skill 可以使团队的开发标准化,促进团队开发速率。
- Skill 可组合 多个Skill 组成Agent。
8.2 结构
-
元数据层:名称(name)、描述(description)。告诉Agent"我是谁,我能干嘛"。
-
指令层:目标、执行步骤、判断规则、输出格式、示例。告诉Agent"具体怎么干"。
- 技能名称:日期查询Skill
- 技能ID:skill_date_query_001
- 版本号:v1.0.0
- 作者:Agent开发组
- 适用Agent类型:通用办公Agent
功能描述
用于响应用户的日期查询需求,可查询当前日期、指定日期所属星期,支持公历日期格式输入,不支持农历查询;可快速返回清晰的日期信息,适配日常办公场景的基础日期查询需求。
触发规则
- 关键词触发:包含"今天日期""今天是几号""查询日期""星期几"等关键词
- 意图匹配:用户意图为"日期查询"时触发
- 触发优先级:中等(低于紧急任务Skill,高于娱乐类Skill)
执行步骤
- 接收用户输入,提取查询关键词(如"今天""2026-03-22");
- 校验输入格式,若为非公历日期格式,触发异常处理;
- 调用系统时间接口(若查询当前日期)或日期处理工具(若查询指定日期);
- 解析返回结果,整理为"日期+星期"的格式;
- 按输出规范返回结果。
输出规范
正常输出
格式:当前日期:{年}-{月}-{日},星期{X}
示例:当前日期:2026-03-22,星期日异常输出
提示:"请输入正确的公历日期(格式如2026-03-22),或输入'今天日期'查询当前日期~"
8.3 技术实现细节(以Claude Code为例)
- 存储形式 :Markdown文档(文件名必须为
SKILL.md)。 - 存放位置 :特定目录(如
.claude/skills文件夹)。 - 加载机制:懒加载。仅在用户问题与技能名称/描述相关时,才加载完整指令。这既节省了Token,又提高了响应速度。
高级特性:支持运行代码、引用资源,采用渐进式披露机制(一步步展示信息),进一步节省Token。
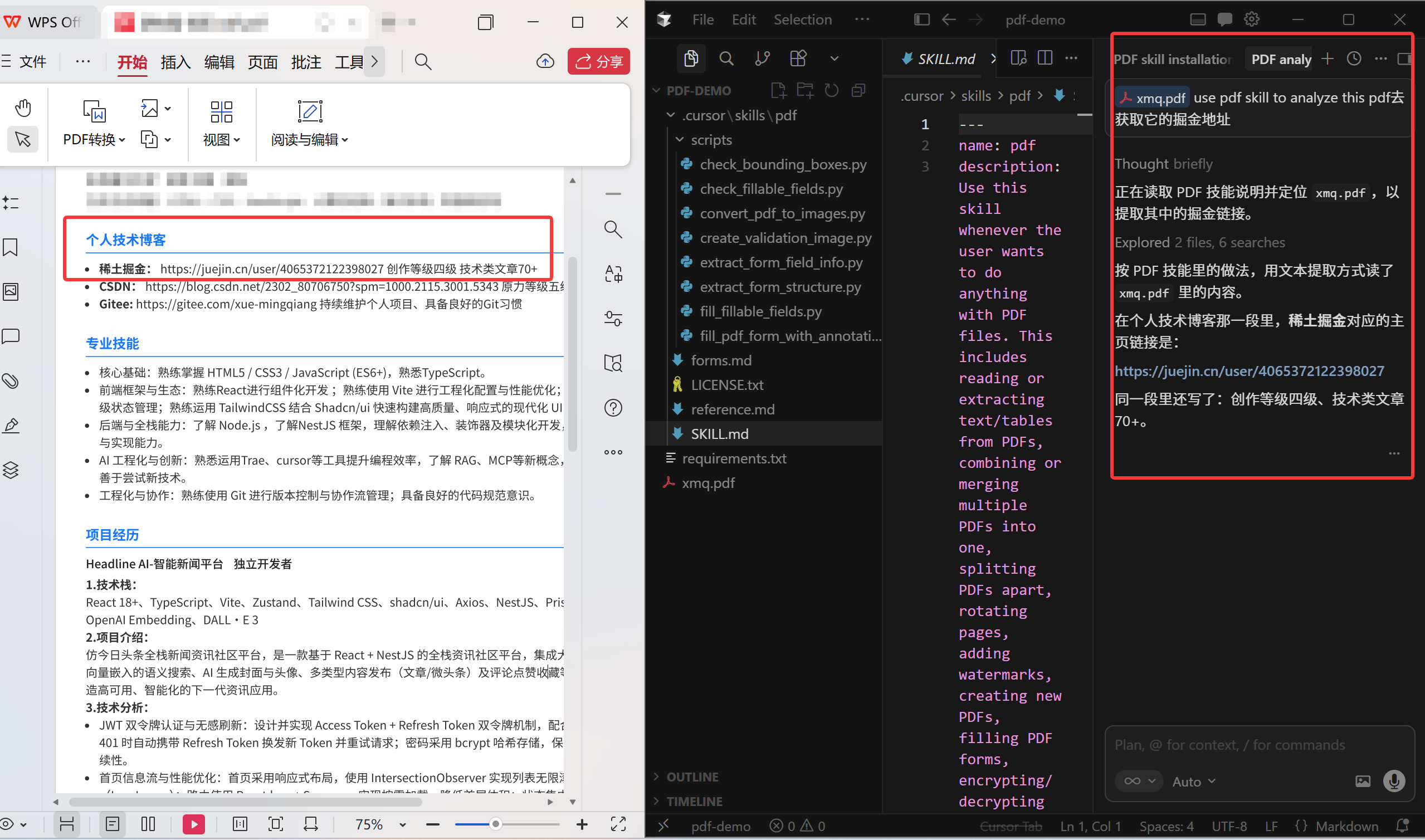
下面我们用pdf Skill 进行演示:
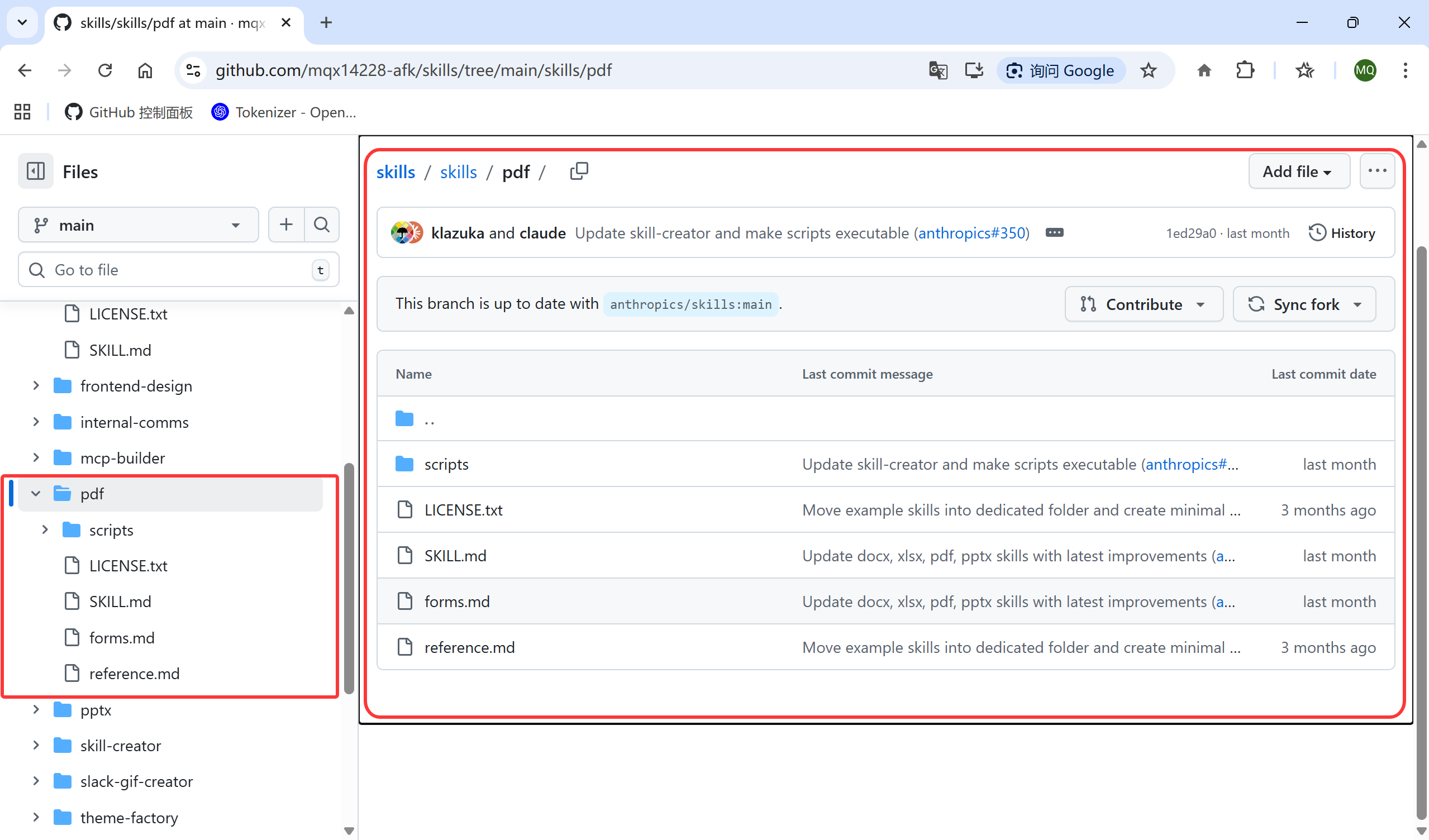
我们可以用MCP 的形式导入Skill,也可以直接从github:https://github.com/mqx14228-afk/skills/tree/main/skills/pdf 上导入SKill到我们项目的文件夹中。
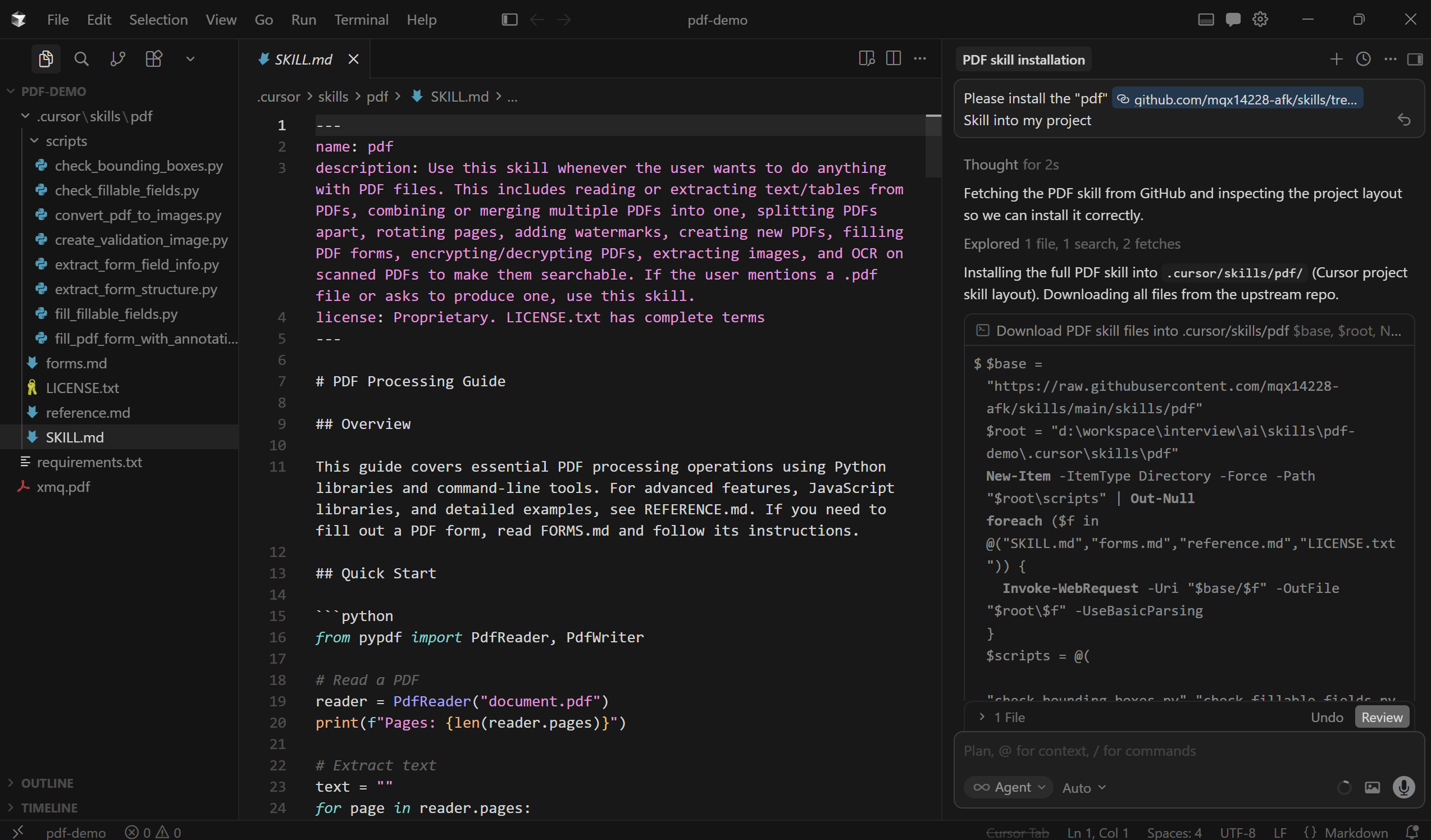
接着利用项目中的pdf skill 去解析xmq.pdf 文件。
终极总结:概念体系关联
让我们把这八大金刚串起来,形成一个完整的大模型技术闭环:
- LLM(核心引擎) :这是大脑,基于Transformer架构,负责思考。
- Token(数据单位) :这是血液,模型处理的最小颗粒。
- Context(记忆空间) :这是工作台,决定了模型能同时处理多少信息。
- Prompt(交互接口) :这是嘴巴和耳朵,人类通过它下达指令。
- Tool(外部能力) :这是手脚,弥补模型无法联网和计算的缺陷。
- MCP(工具标准) :这是插座标准,让手脚能方便地接在大脑上。
- Agent(决策系统) :这是人格,让模型从被动问答变成主动干活。
- Agent Skill(任务定制) :这是技能书,让Agent具备特定领域的专业能力。
结语
从2017年Transformer的横空出世,到如今Agent自主智能体的百花齐放,我们仅仅用了不到7年时间。
现在的AI,已经不再满足于仅仅做一个"陪聊"的机器人。通过Tool 和Agent的结合,它正在变成我们的副驾驶、程序员、分析师甚至是生活管家。
理解这些基础概念,不是为了让你成为算法工程师,而是为了让你在这个AI时代,知道如何更好地"驾驶"这台超级引擎。毕竟,未来不属于AI,而属于那些善用AI的人。
希望这篇指南能帮你打通任督二脉,在AI的世界里游刃有余!