Xiaowen Zhang1^11, Zijie Yue1^11, Yong Luo2^22, Cairong Zhao3^33, Qijun Chen1^11, Miaojing Shi1,4∗^{1,4*}1,4∗
1^11 同济大学电子与信息工程学院
2^22 武汉大学计算机学院
3^33 同济大学计算机学院
4^44 自主智能无人系统全国重点实验室
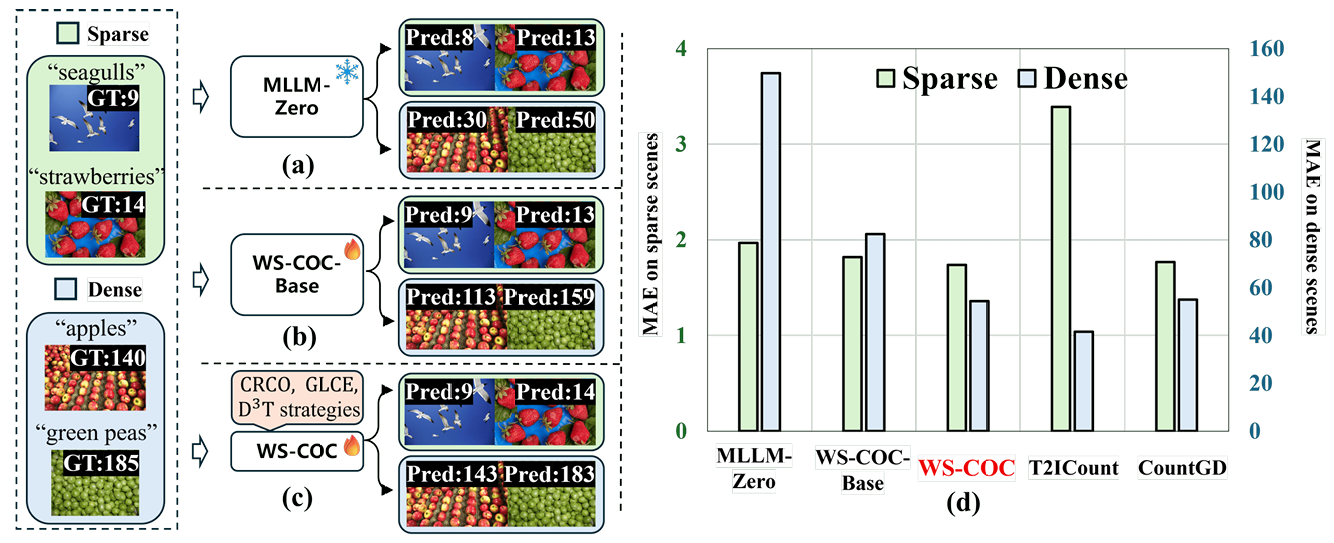
图 1: (a)- ( c) MLLM-Zero、WS-COC-Base 和 WS-COC 的可视化结果。(d) MLLM-Zero、WS-COC-Base、WS-COC 以及两种最先进的全监督计数方法(T2ICount (Qian et al., 2025) 和 CountGD (Amini-Naieni et al., 2024))在稀疏(每张图像最多 20 个实例)和密集(每张图像超过 100 个实例)物体场景上的 MAE 结果。WS-COC 显著优于 MLLM-Zero 和 WS-COC-Base,并产生了与 T2ICount 和 CountGD 具有竞争力的性能。实验基于 FSC-147 (Ranjan et al., 2021),MLLM 为 LLaVA-OneVision-7B (Li et al., 2024)。
https://arxiv.org/pdf/2602.12774
摘要
物体计数是计算机视觉中的一项基本任务,在许多现实世界场景中具有广泛的适用性。全监督计数方法需要每个物体昂贵的点级标注。少数弱监督方法仅利用图像级物体计数作为监督,并取得了相当有希望的结果。然而,它们通常仅限于计数单一类别,例如人。在本文中,我们提出了 WS-COC,这是第一个由多模态大语言模型(MLLM)驱动的弱监督类无关物体计数框架。我们没有直接微调 MLLM 来预测物体计数(由于模态差距,这可能具有挑战性),而是结合了三种简单而有效的策略来在训练和测试中引导计数范式:首先,提出了一种**分而辨之对话微调(divide-and-discern dialogue tuning, D3^33T)策略,引导 MLLM 判断物体计数是否落在特定范围内,并通过多轮对话逐步缩小范围。其次,引入了一种 比较与排序计数优化(compare-and-rank count optimization, CRCO)策略,训练 MLLM 根据物体计数优化多个图像的相对排序。第三,一种全局与局部计数增强(global-and-local counting enhancement, GLCE)**策略聚合并融合局部和全局计数预测,以提高密集场景中的计数性能。在 FSC-147、CARPK、PUCPR+ 和 ShanghaiTech 上的大量实验表明,WS-COC 匹配甚至超越了许多最先进的全监督方法,同时显著降低了标注成本。代码 available at https://github.com/viscom-tongji/WS-COC。
*通讯作者:mshi@tongji.edu.cn
1 引言
物体计数是指估计给定图像内目标实例数量的任务。传统方法 (Radford et al., 2021; Liu et al., 2022a; Amini-Naieni et al., 2023) 主要估计图像的密度图,其中对密度图的积分给出物体总数。密度图是通过用图像中每个物体的点标注卷积高斯核获得的。尽管这些全监督方法在各种计数基准 (Ranjan et al., 2021; Hsieh et al., 2017; Mundhenk et al., 2016) 上取得了强大的性能,但获取点级标注是劳动密集型和耗时的,特别是在数百或数千个物体共存甚至相互遮挡的密集场景中。
为了减轻高昂的标注成本,少数研究 (Wang et al., 2024; Yang et al., 2020; Lei et al., 2021) 探索了弱监督学习范式。他们利用图像级物体计数作为真值,学习从图像视觉特征到图像中目标实例总数的映射。现有的弱监督计数方法仍处于早期阶段,通常局限于单一物体类别,即人 (Yang et al., 2020; Lei et al., 2021; Xiong et al., 2022)。受益于视觉 - 语言对的大规模预训练,多模态大语言模型 (MLLMs) 的最新进展为以文本提示方式的类无关物体计数提供了新的机会,其中文本提示指定感兴趣的目标类别,然后转换为适当的指令。结合相应的图像,这些多模态指令被输入到 MLLM 中以自回归方式预测物体计数。这呈现了一个基于 MLLM 的基本物体计数流程。我们首先在一个标准物体计数基准 FSC-147 (Ranjan et al., 2021) 上评估此流程(即 MLLM-Zero), without any fine-tuning。如图 1(a) 所示:我们观察到它确实在稀疏场景中产生了合理的估计,但其性能在密集场景中显著下降。这可以直观地解释为 MLLM 在其预训练语料库中主要见到的是稀疏而非密集的物体分布。鉴于 MLLM 潜在的计数能力,本研究旨在探索如何以最小的微调成本将这种潜力扩展到准确的类无关物体计数。
在本文中,我们引入了一个弱监督类无关物体计数网络 WS-COC,它仅使用图像级计数监督来引导 MLLM 进行物体计数。一个朴素的基线(即 WS-COC-Base)是直接微调 MLLM 以从给定图像预测物体计数。然而,如图 1(b) 所示,由于缺乏物体分布监督,学习直接映射是困难的;特别是在密集场景中,这仍然导致明显的低估。为了解决这个问题,我们引入了三种简单而有效的策略:
- 首先,我们不一次性回归确切计数,而是引入了一种分而辨之对话微调 (D3^33T) 策略,引导 MLLM 判断计数是否落在某个范围内,并逐步从大到小分解范围。这种多步推理帮助 MLLM 从易到难学习计数。当范围足够小时,我们要求模型预测实际物体计数;
- 其次,由于视觉和文本之间的模态差距,直接针对真值优化预测计数仍然具有挑战性。相反,引导 MLLM 判断图像之间的相对计数差异可以在视觉上更容易探测。受此启发,我们引入了一种比较与排序计数优化 (CRCO) 策略,训练 MLLM 根据物体计数预测多个图像的相对排序。
- 最后,在推理过程中,为了进一步减轻密集人群中的计数偏差,我们引入了一种全局与局部计数增强 (GLCE) 策略。我们首先预测给定图像的全局计数,然后将输入图像划分为更小的子图像,独立查询每个子图像以获得局部计数。融合全局和局部计数以获得最终计数。
如图 1(d) 所示,通过实施这些策略,我们显著增强了 MLLM 的数量意识,导致计数误差大幅减少,特别是在密集条件下。我们在四个广泛使用的基准上进行了大量实验:FSC-147 (Ranjan et al., 2021)、CARPK (Hsieh et al., 2017)、PUCPR+ (Hsieh et al., 2017) 和 ShanghaiTech (Zhang et al., 2016)。我们的方法作为第一个 MLLM 驱动的弱监督物体计数方法,在与最先进的全监督物体计数方法 (Pelhan et al., 2024; Zhu et al., 2024; Hui et al., 2024) 相当的水平上产生了令人惊讶的好结果。
2 相关工作
2.1 物体计数
现有的计数方法大致可分为类特定和类无关方法,取决于它们是否可以计数任意物体类别。
类特定物体计数旨在预测特定类别的物体数量,例如人 (Ranasinghe et al., 2024; Guo et al., 2024; Peng & Chan, 2024; Wu & Yang, 2023; Du et al., 2023; Liu et al., 2022b; Shi et al., 2019)、车辆 (Hsieh et al., 2017; Mundhenk et al., 2016)、细胞 (Xie et al., 2018)、鱼 (Sun et al., 2023) 等。传统方法通常是基于检测的 (Liu et al., 2023; Liang et al., 2022; Liu et al., 2019) 或基于回归的 (Ranasinghe et al., 2024; Guo et al., 2024; Peng & Chan, 2024; Wu & Yang, 2023; Li et al., 2023; Wang et al., 2020)。前者检测每个单独实例的边界框,并将物体计数获得为边界框的数量;后者估计给定图像的密度图,并通过在密度图上积分像素值获得物体计数。总体而言,类特定方法固有地局限于某些物体类别,限制了它们的应用。
最近,提出了类无关计数 (Chattopadhyay et al., 2017; Lu et al., 2019; Xu et al., 2023) 方法来计数图像内任意类别的物体。常见的做法是提供视觉示例来指示目标类别 (Lu et al., 2019; Liu et al., 2022a; Pelhan et al., 2024),如 CounTR (Liu et al., 2022a),它融合图像和示例特征进行密度图估计。然而,由于手动选择示例需要大量的标注成本,一种新兴的方式是用使用类别名称指定目标物体类别的文本提示替换它们 (Xu et al., 2023; Amini-Naieni et al., 2024; Jiang et al., 2023; Kang et al., 2024; Zhu et al., 2024; Hui et al., 2024; Dai et al., 2024; Qian et al., 2025; Zhai et al., 2025; Shi et al., 2025)。例如,VLPG (Zhai et al., 2025) 利用 CLIP (Radford et al., 2021) 从给定图像中提取视觉嵌入,从文本提示中提取文本嵌入,然后通过交叉注意力融合它们进行密度图估计。
到目前为止,大多数物体计数方法采用全监督学习范式,其中模型使用点级标注进行训练。为了降低标注成本,少数方法 (Yang et al., 2020; Meng et al., 2021; Lei et al., 2021; Xiong et al., 2022; Wang et al., 2024) 探索了弱监督学习范式,其中仅提供图像级物体计数作为真值。例如,Xiong et al. (2022) 利用视觉变换器 (ViT) 从图像中提取多尺度视觉特征,并将它们直接映射到人计数。GCNet (Wang et al., 2024) 利用预训练的 ResNet (He et al., 2016) 计数图像中出现最频繁的物体类别。这些基于 CNN 或 ViT 的初步探索局限于类特定物体计数;而我们新颖地利用 MLLM 实现类无关物体计数。
2.2 多模态大模型
早期的多模态大模型,通常称为视觉 - 语言模型 (VLMs),如 CLIP (Radford et al., 2021) 和 BLIP (Li et al., 2022),通过在视觉 - 语言对上的大规模预训练学习跨模态表示。它们通常执行视觉 - 语言对比学习和视觉 - 语言匹配以对齐视觉和文本模态,并已广泛用于多模态下游任务 (Jiang et al., 2023; Kang et al., 2024; Monsefi et al., 2024)。
近年来,多模态大语言模型 (MLLMs) (Liu et al., 2024a; Li et al., 2024; Bai et al., 2025) 作为 VLMs 的升级版出现,具有多模态推理和生成能力。通过 Incorporating 大语言模型 (LLMs) 作为核心语义理解和推理引擎,MLLMs 在广泛的任务中取得了显著成功,例如视觉问答 (Goyal et al., 2017) 和图像字幕 (Agrawal et al., 2019)。
几项研究 (Jiang et al., 2023; Qharabagh et al., 2024) 利用多模态大模型以文本提示方式解决物体计数问题。例如,CLIP-Count (Jiang et al., 2023)、VLPG (Zhai et al., 2025) 和 VLCounter (Kang et al., 2024) 微调预训练的 VLM,即 CLIP Radford et al. (2021),用于类无关计数。CLIP 和其他 VLMs 主要是判别模型,其中物体计数必须通过设计额外的计数头获得。我们的 WS-COC 则完全依赖 MLLM,其中物体计数可以自回归生成。值得注意的是,一些基于 VLM 的计数方法,如 CrowdCLIP (Liang et al., 2023),采用了一种看似与我们提出的比较与排序计数优化策略相似的排序策略,但存在关键差异。首先,Liang et al. (2023) 通过将单个图像裁剪成不同大小的子图像来构建图像集,假设较大的裁剪包含更多物体。相比之下,WS-COC 在同一类别内采样具有不同物体计数的不同图像。其次,Liang et al. (2023) 依赖于对比优化,而 WS-COC 直接使用语言建模损失生成排序。
3 预备知识
在本节中,我们首先提供 MLLM 的简要背景,然后在此基础上设计一个用于弱监督物体计数的基线模型。
多模态大语言模型。 针对视觉和语言的 MLLM 由视觉编码器、投影模块和 LLM 组成。它们接受图像 III 和文本指令 TinstT_{inst}Tinst 作为输入,并输出文本响应 TresT_{res}Tres。具体而言,视觉编码器从 III 中提取视觉特征。投影模块将这些特征转换为可以输入到 LLM 的特征。然后,LLM 基于投影的视觉特征和 TinstT_{inst}Tinst 的指令令牌执行语义理解和推理,以自回归方式生成 TresT_{res}Tres。MLLM 使用语言建模损失进行训练,该损失最小化 TresT_{res}Tres 和真值响应 TgtT_{gt}Tgt 之间的交叉熵。
基线。 我们设计了一个基线模型(即 WS-COC-Base),其中我们微调一个 MLLM,默认为 LLAVA-OneVision (Li et al., 2024),用于弱监督物体计数。具体而言,对于每个图像 III 及其全局物体计数 ccc,我们使用固定模板构建文本指令 TinstT_{inst}Tinst 和真值响应 TgtT_{gt}Tgt。TinstT_{inst}Tinst formulated as "How many obj are there in the image?"(图像中有多少个 obj?),而 TgtT_{gt}Tgt 遵循 "a photo of num obj"(一张 num 个 obj 的照片),其中 [num] 令牌被替换为 ccc,[obj] 令牌表示特定的物体类别。然后我们遵循基于 LoRA 的微调范式 (Hu et al., 2022) 来优化 MLLM。WS-COC-Base 的性能如图 1(d) 所示。
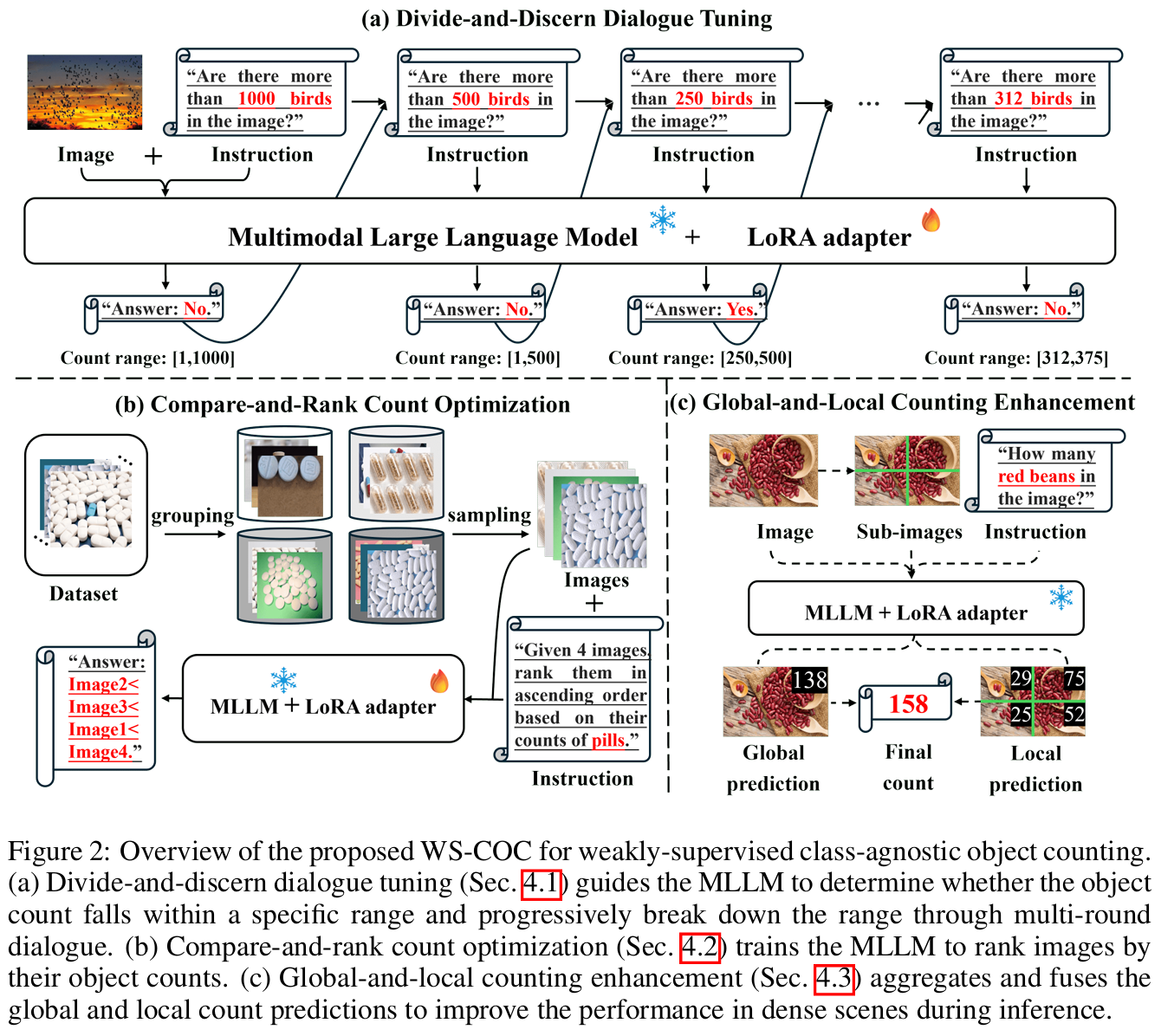
4 方法
图 2 说明了我们提出的 WS-COC 的框架,其中我们仅使用图像级计数监督来引导 MLLM 进行弱监督物体计数。在基线模型的基础上,我们引入了三种简单而有效的策略:分而辨之对话微调、比较与排序计数优化和全局 - 局部计数增强。
4.1 分而辨之对话微调 (Divide-and-Discern Dialogue Tuning)
从图像学习预测绝对物体计数对于 MLLM 来说是困难的,特别是没有对单个物体的明确监督。为了应对这一点,我们将计数预测任务重新 formulat 为一系列范围判断任务:我们不一次性回归确切计数,而是引导模型通过多轮对话迭代地确定计数是否落在特定范围内。通过从粗到细逐步分解范围,模型能够以课程方式学习计数,从易到难。
具体而言,给定图像 III 及其全局物体计数 ccc,我们为第一轮对话设置初始范围 L1,U1L_1, U_1L1,U1,例如 FSC-147 数据集 (Ranjan et al., 2021) 中的最小和最大物体计数 1,20001, 20001,2000。我们计算该范围的中点 τ1=⌊L1+U12⌋\tau_1 = \lfloor \frac{L_1 + U_1}{2} \rfloorτ1=⌊2L1+U1⌋ 并使用模板 "Are there more than τ1\tau_1τ1 obj in the image?"(图像中是否有超过 τ1\tau_1τ1 个 obj?)构建文本指令 Q1Q_1Q1,其中 [obj] 令牌被替换为目标物体类别。如果 c>τ1c > \tau_1c>τ1,则真值响应 R1gR^g_1R1g 设置为 "yes",否则为 "no"。然后我们使用 III 和 Q1Q_1Q1 查询 MLLM 以预测响应 R1R_1R1,并使用语言建模损失针对 R1gR^g_1R1g 进行优化。
我们逐步将范围减半并重复上述过程多轮。例如,在第 ttt 轮,我们根据第 (t−1)(t-1)(t−1) 轮的真值响应 Rt−1gR^g_{t-1}Rt−1g 更新 Lt,UtL_t, U_tLt,Ut:
Lt,Ut={τt−1+1,Ut−1,if Rt−1g=Yes,Lt−1,τt−1,if Rt−1g=No.(1) L_t, U_t = \begin{cases} \\tau_{t-1} + 1, U_{t-1}, & \text{if } R^g_{t-1} = \text{Yes}, \\ L_{t-1}, \\tau_{t-1}, & \text{if } R^g_{t-1} = \text{No}. \end{cases} \quad (1) Lt,Ut={τt−1+1,Ut−1,Lt−1,τt−1,if Rt−1g=Yes,if Rt−1g=No.(1)
当 Ut−LtU_t - L_tUt−Lt 低于 δ=0.2×c\delta = 0.2 \times cδ=0.2×c 时,对话终止。然后,要求 MLLM 预测实际物体计数。
4.2 比较与排序计数优化 (Compare-and-Rank Count Optimization)
视觉特征是高维表示,而真值计数是表示为文本令牌的离散标量。由于模态差距,直接针对真值优化预测计数可能具有挑战性。这使得模型难以建立鲁棒的映射。相反,引导模型判断图像之间的相对计数差异可以直观地更容易访问。因此,我们提出了一种比较与排序计数优化策略,训练模型比较多个图像并根据物体计数优化它们的相对排序。
首先,我们需要采样多个图像进行计数比较。由于计数数据集通常表现出物体计数的长尾分布,具有大物体计数的密集场景是罕见的,并且不太可能通过随机采样采样到。因此,我们引入一个简单的方案根据计数对图像进行聚类。具体而言,我们获得训练集中每个物体类别的最小和最大计数(即 cmin,cmaxc_{min}, c_{max}cmin,cmax),然后将 cmin,cmaxc_{min}, c_{max}cmin,cmax 划分为 KKK(默认为 4)个等长区间。因此,每个类别的图像根据其物体计数落入的区间分为四组。在每次训练迭代中,我们从每组中随机采样一个图像以构建图像集 I={I1,I2,I3,I4}\mathcal{I} = \{I_1, I_2, I_3, I_4\}I={I1,I2,I3,I4},其中相应的计数固有地满足 c1<c2<c3<c4c_1 < c_2 < c_3 < c_4c1<c2<c3<c4。通过这种方式,我们确保稀疏和密集场景都可以被覆盖。我们随机打乱 I\mathcal{I}I 中图像的顺序为 I~\tilde{\mathcal{I}}I~ 并将其视为 MLLM 的视觉输入。
接下来,我们使用模板 "Given four images, rank them in ascending order based on their counts of obj"(给定四张图像,根据它们的 obj 计数按升序对它们进行排序)构建关联的文本指令 TTT,真值响应 TgT^gTg 以 "Image i<⋯<Image ji < \cdots < \text{Image } ji<⋯<Image j" 的形式指定正确的排序,其中 "Image iii" 和 "Image jjj" 分别表示 I~\tilde{\mathcal{I}}I~ 中的第 iii 个和第 jjj 个图像。我们使用 TTT 和 I~\tilde{\mathcal{I}}I~ 查询 MLLM 以获得响应 TrT_rTr,然后使用语言建模损失针对 TgT^gTg 对其进行优化。
4.3 全局与局部计数增强 (Global-and-Local Counting Enhancement)
一旦模型微调完成,我们观察到它仍然倾向于低估密集场景中的物体计数,尽管其性能比微调前有了很大提高。因此,在推理阶段,为了进一步减轻密集人群中的计数偏差,我们建议将具有密集场景的图像划分为更小的子图像,并在每个子图像上独立查询 MLLM。聚合局部预测并与全局预测结合以产生最终输出。
具体而言,我们首先查询 MLLM 以预测给定图像 III 的全局计数 cgc_gcg。如果 cgc_gcg 低于阈值 chc_hch,我们直接将 cgc_gcg 视为最终预测。否则,图像 III 被视为密集场景。在这种情况下,我们将 III 均匀划分为 L×LL \times LL×L(默认为 2×22 \times 22×2)个不重叠的子图像,并通过分别查询每个子图像从 MLLM 获得局部预测 {ck}k=1L2\{c_k\}_{k=1}^{L^2}{ck}k=1L2。然后我们求和局部预测以获得 clc_lcl。由于聚合子图像时的边缘效应,与 cgc_gcg 相比,clc_lcl 通常会高估总计数。根据经验,我们通过简单地平均 clc_lcl 和 cgc_gcg 来获得最终预测。通过这种方式,它们在估计密集场景中的最终计数时互补(见 5.3 节:GLCE)。
4.4 训练和推理
在基线(第 3 节)之上,分而辨之对话微调和比较与排序计数优化仅在训练期间额外应用,而全局与局部计数增强仅在推理期间激活。推理的文本指令 formulated as "How many obj are there in the image?",其中 [obj] 令牌表示目标物体类别。
5 实验
5.1 实验细节
数据集。 我们的实验主要在 FSC-147 数据集 (Ranjan et al., 2021) 上进行,该数据集包含跨越 147 个物体类别的 6,135 张图像。我们在 FSC-147 的验证集和测试集上报告模型性能。遵循 prior works (Jiang et al., 2023; Kang et al., 2024),我们还通过在 CARPK (Hsieh et al., 2017)、PUCPR+ (Hsieh et al., 2017) 和 ShanghaiTech (Zhang et al., 2016) 上测试来自 FSC-147 的训练模型来调查跨数据集泛化性能。CARPK 由通过无人机从四个停车场捕获的近 90,000 个标注汽车组成,而 PUCPR+ 包含恶劣天气下的 16,456 个汽车实例。ShanghaiTech 数据集分为 SHA(482 张互联网图像)和 SHB(716 张来自上海的街景图像),涵盖 diverse crowd densities and scene layouts。
实现细节。 我们采用 LLaVA-OneVision-7B (Li et al., 2024) 作为默认 MLLM,并遵循 MM-RAIT (Liu et al., 2025) 使用基于 LoRA 的微调范式对其进行优化:LoRA 适配器的秩设置为 128,缩放因子为 256。计数阈值 chc_hch 设置为 100。我们在全局与局部计数增强策略中设置 L=2L=2L=2。批量大小为 4,训练在 NVIDIA L20 GPU 上进行。
评估指标。 遵循 (Jiang et al., 2023; Kang et al., 2024) 中的常见做法,我们使用平均绝对误差 (MAE) 和均方根误差 (RMSE) 评估性能。
5.2 与最先进方法的比较
如表 1 所示,我们将提出的方法与 FSC-147 数据集上的八种全监督文本提示物体计数方法和三种弱监督计数方法进行了比较。标记为 "*" 的方法表示我们从其全监督对应物改编的弱监督变体:我们将解码器的最后一层(原本预测密度图)替换为用于直接计数预测的线性层。此外,我们将 MLLM-Zero 表示为在零样本设置中直接评估 MLLM 的变体。值得注意的是,我们提出的 WS-COC 实现了一些最近全监督方法的可比甚至 superior 性能。例如,WS-COC 超过了两种非常最近的方法 CountDiff (Hui et al., 2024) 和 VLPG (Zhai et al., 2025)。它还实现了优于弱监督方法的性能,例如,它在测试集上将 GCNet (Wang et al., 2024) 的 MAE 降低了 -3.92,RMSE 降低了 -5.61。此外,WS-COC 显著优于 MLLM-Zero 和基线模型 WS-COC-Base。值得注意的是,如图 1(d) 所示,WS-COC 大幅减少了密集场景(每张图像超过 100 个实例)中的计数误差 (MAE),从 149.69 (MLLM-Zero) 和 82.44 (WS-COC-Base) 降至 54.37 (WS-COC)。图 3 中显示的一些示例进一步说明 WS-COC 可以产生准确的预测。
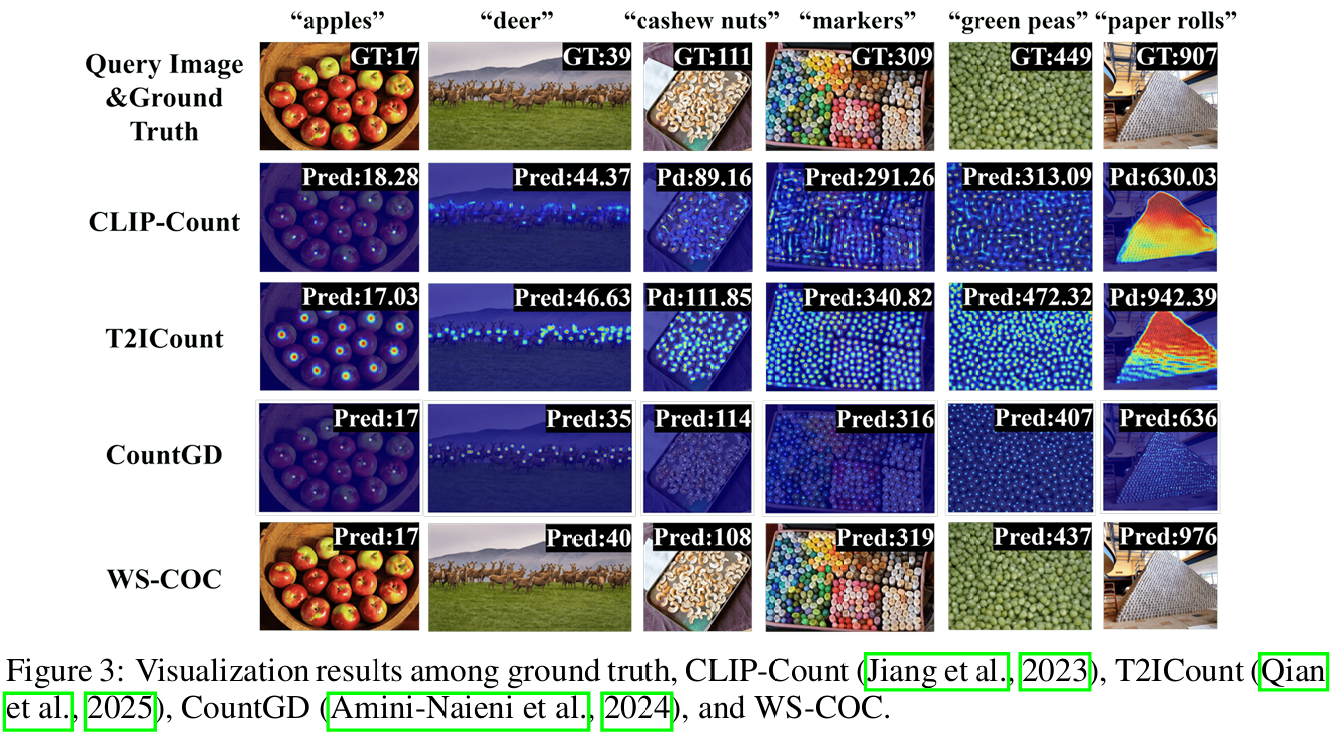
接下来,我们遵循 previous methods (Jiang et al., 2023; Zhai et al., 2025; Hui et al., 2024) 在 CARPK、PUCPR+ 和 ShanghaiTech 数据集上进行跨数据集验证。如表 2 和表 3 所示,WS-COC 在 PUCPR+ 和 SHA 上取得了最佳结果,并在 CARPK 和 SHB 上表现出与大多数全监督方法具有竞争力的性能。这些结果证明了我们方法在未知场景中的强泛化性。
最后,我们在表 4 中比较了 WS-COC 与一些最先进方法 (Jiang et al., 2023; Amini-Naieni et al., 2024; Qian et al., 2025) 之间的训练和推理成本,确保通过使用相同的 GPU(即 NVIDIA L20)进行公平比较。虽然 MLLM 通常很大,但我们采用基于 LoRA 的微调范式,这有助于显著降低训练成本。我们 WS-COC 的训练时间仅为 3.44 小时, substantially lower than that of CountGD and T2ICount。注意 WS-COC 的主要计算成本是由于 MLLM 骨干网络 (WS-COC-Base) 的固有成本,而不是我们提出的组件。在实践中,人们也可以采用模型压缩技术,如剪枝和蒸馏,以进一步减少计算开销。
表 1: FSC-147 上的定量比较。 最佳全监督方法 marked in shadow,而最佳弱监督方法 marked in bold。标记为 "*" 的方法表示我们从其全监督对应物改编的弱监督变体。
| 方法 | 监督 | 验证集 MAE↓ RMSE↓ | 测试集 MAE↓ RMSE↓ |
|---|---|---|---|
| ZSOC (Xu et al., 2023) | point-level | 26.93 88.63 | 22.09 115.17 |
| CLIP-Count (Jiang et al., 2023) | point-level | 18.79 61.18 | 17.78 106.62 |
| VLCounter (Kang et al., 2024) | point-level | 18.06 65.13 | 17.05 106.16 |
| CountDiff (Hui et al., 2024) | point-level | 15.50 54.33 | 14.83 103.15 |
| GroundingREC (Dai et al., 2024) | point-level | 10.06 58.62 | 10.12 107.19 |
| CountGD (Amini-Naieni et al., 2024) | point-level | - - | 14.76 120.42 |
| T2ICount (Qian et al., 2025) | point-level | - - | 11.76 97.86 |
| VLPG (Zhai et al., 2025) | point-level | 12.14 53.49 | 17.60 97.66 |
| GCNet (Wang et al., 2024) | image-level | 19.50 63.13 | 17.83 102.89 |
| CLIP-Count* (Jiang et al., 2023) | image-level | 29.86 81.68 | 30.01 124.93 |
| T2ICount* (Qian et al., 2025) | image-level | 26.64 83.00 | 28.55 131.52 |
| MLLM-Zero | × | 38.92 119.26 | 38.19 145.42 |
| WS-COC-Base | image-level | 21.70 87.53 | 21.08 122.18 |
| WS-COC | image-level | 14.77 54.24 | 13.91 97.28 |
表 2: 在 CARPK 和 PUCPR+ 上的跨数据集评估。
| 方法 | 监督 | CARPK MAE↓ RMSE↓ | PUCPR+ MAE↓ RMSE↓ |
|---|---|---|---|
| CLIP-Count (Jiang et al., 2023) | point-level | 11.96 16.61 | - - |
| VLCounter (Kang et al., 2024) | point-level | 6.46 8.68 | 48.94 69.08 |
| CountDiff (Hui et al., 2024) | point-level | 10.32 12.92 | - - |
| VLPG (Zhai et al., 2025) | point-level | 10.14 13.79 | - - |
| T2ICount (Qian et al., 2025) | point-level | 8.61 13.47 | - - |
| CLIP-Count* (Jiang et al., 2023) | image-level | 24.90 29.12 | 63.28 86.63 |
| T2ICount* (Qian et al., 2025) | image-level | 19.42 23.48 | 58.43 77.24 |
| MLLM-Zero | × | 26.24 55.11 | 82.40 133.50 |
| WS-COC-Base | image-level | 14.06 27.60 | 60.40 84.64 |
| WS-COC | image-level | 10.39 15.83 | 42.30 54.06 |
表 3: 在 ShanghaiTech 上的跨数据集评估。
| 方法 | 监督 | SHA MAE↓ RMSE↓ | SHB MAE↓ RMSE↓ |
|---|---|---|---|
| RCC (Hobley & Prisacariu, 2023) | point-level | 240.1 366.9 | 66.6 104.8 |
| CLIP-Count (Jiang et al., 2023) | point-level | 192.6 308.4 | 45.7 77.4 |
| VLPG (Zhai et al., 2025) | point-level | 178.9 284.6 | 42.4 71.6 |
| GCNet (Wang et al., 2024) | image-level | 148.9 260.7 | 38.6 53.9 |
| CLIP-Count* (Jiang et al., 2023) | image-level | 237.4 355.5 | 52.3 73.8 |
| T2ICount* (Qian et al., 2025) | image-level | 222.2 367.6 | 48.9 76.9 |
| MLLM-Zero | × | 336.8 486.6 | 75.7 108.0 |
| WS-COC-Base | image-level | 190.4 343.0 | 43.6 71.8 |
| WS-COC | image-level | 128.9 232.9 | 34.2 57.0 |
表 4: 训练和推理成本比较。
| 方法 | 可训练参数 (M) | 训练时间 (小时) | GFLOPs | 内存使用 (GB) | FPS |
|---|---|---|---|---|---|
| CLIP-Count (Jiang et al., 2023) | 17.30 | 2.43 | 78.72 | 1.94 | 15.50 |
| CountGD (Amini-Naieni et al., 2024) | 37.00 | 11.73 | 3589.03 | 8.12 | 1.13 |
| T2ICount (Qian et al., 2025) | 908.42 | 23.84 | 1100.75 | 6.77 | 2.47 |
| WS-COC-Base | 339.94 | 1.84 | 1845.09 | 18.70 | 2.16 |
| WS-COC | 339.94 | 3.44 | 1845.09 | 18.70 | - |
5.3 消融研究
我们在 FSC-147 数据集的验证集和测试集上进行消融研究。
分而辨之对话微调 (D3^33T)。 在表 5 中,我们将 WS-COC w/o D3T 表示为从 WS-COC 中移除 D3T 的变体。结果显示 MAE 显著增加,在验证集上上升了 +3.36,在测试集上上升了 +3.21,表明 D3T 策略的有效性。
接下来,我们在 D3T 中改变停止阈值 δ\deltaδ,从 0.1 到 0.3。如图 4(a) 所示,默认 δ=0.2\delta = 0.2δ=0.2 在验证集上表现最佳,同时在测试中也是最佳。

最后,我们在测试阶段应用 D3T 策略,命名为 WS-COC w/ D3T-T。如表 5 所示,此变体表现明显较差,甚至不如 WS-COC w/o D3T。这是因为,在训练期间,我们基于真值计数构建多轮对话。然而,在测试时,中间轮次中的任何错误判断都可能误导 MLLM 进入完全错误的方向,导致性能严重下降。
比较与排序计数优化 (CRCO)。 在表 5 中,我们将 WS-COC w/o CRCO 表示为移除 CRCO 的变体。结果显示 MAE 显著增加,在验证集上上升了 +2.62,在测试集上上升了 +2.84,表明该策略的有效性。
接下来,我们将 WS-COC w/ SCRCO 表示为一个变体,其中我们裁剪图像的中心区域,大小对应于原始维度的 34\frac{3}{4}43、24\frac{2}{4}42 和 14\frac{1}{4}41。这就像俄罗斯套娃,类似于 CrowdCLIP (Liang et al., 2023) 中使用的想法。连同原始图像,这些裁剪形成一个大小为 K=4K=4K=4 的图像集 I\mathcal{I}I,其固有地按保留区域排序。如表 5 所示,此变体表现不如我们的 WS-COC,甚至接近 WS-COC w/o CRCO。这可能是因为这样的排序任务 (SCRCO) 对于 MLLM 来说比跨不同图像的排序任务 (CRCO) 容易得多。
此外,我们在此策略中将 KKK 从 3 变化到 7。如图 4(b) 所示,我们默认设置 K=4K=4K=4,因为它产生最佳性能。
最后,我们调查了我们提出的采样策略的有效性。我们将 WS-COC w/ CRCOrnd 表示为一个变体,其中 I\mathcal{I}I 中的图像是通过从给定类别的所有图像中随机采样获得的。如表 5 所示,与 WS-COC w/o CRCO 相比,WS-COC w/ CRCOrnd 产生了一定的性能增益,但结果仍然不如我们的默认设置,突出了在样本选择期间确保物体计数广泛覆盖的好处。

全局与局部计数增强 (GLCE)。 在表 5 中,我们将 WS-COC w/ GLCE(cgc_gcg/clc_lcl) 表示为从 WS-COC 中移除 GLCE 但仅利用全局预测/聚合局部预测的变体。对于仅全局变体 (cgc_gcg),结果显示 MAE 清晰增加,在验证集上上升了 +1.87,在测试集上上升了 +1.81,表明 GLCE 的有效性;对于仅局部变体 (clc_lcl) 也可以发现类似的观察。
接下来,我们将 WS-COC w/ GLCE(L=iL=iL=i) 表示为一个变体,其中输入图像被划分为 i×ii \times ii×i 网格用于局部增强。如表 5 所示,我们的默认 L=2L=2L=2 在验证集上表现最佳,同时在测试中也是最佳。
我们进一步对 GLCE 中的全局和局部预测计数进行详细分析。我们发现大约 81.2% 的全局预测 cgc_gcg 低估了物体计数,而局部聚合预测 clc_lcl,受聚合 {ck}k=1L2\{c_k\}_{k=1}^{L^2}{ck}k=1L2 期间的边缘效应影响,倾向于高估物体计数(约 79.4%)。这种互补特性使我们的解决方案能够平均它们以改进最终计数。
最后,我们在此策略中改变阈值 chc_hch,从 80 到 120。如图 4 所示,我们默认设置 ch=100c_h = 100ch=100,鉴于它在验证集和测试集上表现最佳。
MLLM 的选择。 表 6 展示了 WS-COC 在不同 MLLM 骨干网络和模型大小上的性能,包括 LLaVA-OneVision-7B (Li et al., 2024)、LLaVA-OneVision-0.5B、Qwen3-VL-4B (Yang et al., 2025)、Qwen3-VL-8B、DeepSeek-VL2-3B (Wu et al., 2024) 和 DeepSeek-VL2-16B。结果显示 WS-COC 在不同 MLLM 骨干网络上泛化良好:与我们的默认 LLaVA-OneVision-7B 相比,具有相似模型大小的 Qwen3-VL-8B 产生了可比的性能;另一方面,更大规模的 DeepSeek-VL2-16B 实现了更好的性能。考虑到效率和准确性的权衡,我们默认选择 LLaVA-OneVision-7B。
注意力图可视化。 为了更好地理解不同模型的计数行为,我们可视化了 MLLM-Zero、WS-COC-Base 和 WS-COC 的计数相关文本令牌与图像块令牌之间的注意力图。如图 5 所示,模型逐步细化其对要计数的物体的关注,导致从 MLLM-Zero 到我们的 WS-COC 更精确的计数预测。
表 5: 关于 D3T、CRCO 和 GLCE 的消融研究。
| 方法 | 验证集 MAE↓ RMSE↓ | 测试集 MAE↓ RMSE↓ |
|---|---|---|
| WS-COC w/o D3T | 18.13 71.35 | 17.12 109.82 |
| WS-COC w/ D3T-T | 28.90 80.58 | 37.07 123.70 |
| WS-COC w/o CRCO | 17.39 65.23 | 16.75 107.45 |
| WS-COC w/ SCRCO | 17.24 64.83 | 16.63 103.57 |
| WS-COC w/ CRCOrnd | 16.77 69.58 | 16.04 105.23 |
| WS-COC w/ GLCE(cgc_gcg) | 16.64 65.08 | 15.72 105.25 |
| WS-COC w/ GLCE(clc_lcl) | 17.35 58.16 | 16.52 99.34 |
| WS-COC w/ GLCE(L=3L=3L=3) | 15.28 57.64 | 14.34 99.93 |
| WS-COC w/ GLCE(L=4L=4L=4) | 15.99 59.70 | 15.49 101.85 |
| WS-COC | 14.77 54.24 | 13.91 97.28 |
表 6: 关于 WS-COC 不同 MLLM 骨干网络的消融研究。
| 方法 | 验证集 MAE↓ RMSE↓ | 测试集 MAE↓ RMSE↓ |
|---|---|---|
| WS-COC (DeepSeek-VL2-3B) | 16.47 59.23 | 16.26 103.23 |
| WS-COC (DeepSeek-VL2-16B) | 14.45 56.71 | 13.67 95.51 |
| WS-COC (Qwen3-VL-4B) | 16.68 58.75 | 15.51 99.21 |
| WS-COC (Qwen3-VL-8B) | 15.18 55.90 | 14.13 97.23 |
| WS-COC (LLaVA-OneVision-0.5B) | 17.05 60.87 | 17.32 105.89 |
| WS-COC (LLaVA-OneVision-7B) | 14.77 54.24 | 13.91 97.28 |
图 4: 变化 (a) D3T 中 δ\deltaδ 的比例,(b) CRCO 中的 KKK,和 © GLCE 中的密集阈值 chc_hch 时,FSC-147 验证集和测试集上的 MAE。
图 5: MLLM-Zero、WS-COC-Base 和 WS-COC 的注意力图比较。
6 结论
在这项工作中,我们提出了 WS-COC,这是第一个用于类无关物体计数的 MLLM 驱动的弱监督框架。该框架通过三种策略解决了 MLLM 计数性能在密集场景中的退化问题。首先,分而辨之对话微调策略将计数预测重新 formulat 为一系列计数判断,通过多轮对话从粗到细逐步分解预测范围。其次,比较与排序计数优化策略训练模型对具有不同物体计数的图像进行排序。第三,全局与局部计数增强策略结合了全局预测与来自划分子图像的聚合局部预测,以减轻推理期间密集场景中的计数偏差。跨四个基准的实验证明了 WS-COC 的强大性能。
7 致谢
这项工作得到了中央高校基本科研业务费的支持。
参考文献
(此处保留原文参考文献列表,因数量众多且为标准引用格式,通常翻译论文时保留原文以确保准确性,以下仅列出部分示例结构)
- Harsh Agrawal, et al. nocaps: novel object captioning at scale. In Proceedings of the IEEE International Conference on Computer Vision, pp. 8948--8957, 2019.
- N. Amini-Naieni, et al. Open-world text-specified object counting. In British Machine Vision Conference, 2023.
- ... (其余参考文献略,保持原文) ...
附录
本附录提供了 1) 关于 WS-COC 组件设计选择、MLLM 骨干网络选择等的额外消融研究,以及 2) 关于跨数据集评估和失败案例分析的额外分析。
A 额外消融研究
本节提供额外结果,除非另有说明,均在 FSC-147 的验证集和测试集上。
分而辨之对话微调 (D3T) 中的多轮对话。 我们提出的 D3T 策略引导 MLLM 确定物体计数是否落在特定范围内,并通过多轮对话以课程方式逐步分解范围,从易到难。我们提出了一个变体,用单轮对话替换多轮对话,即初始范围 (1,20001, 20001,2000) 直接划分为多个子范围,间隔为 Δ\DeltaΔ。例如,对于 Δ=200\Delta = 200Δ=200,子范围为 1,200,201,400,...,1801,20001, 200, 201, 400, \dots, 1801, 20001,200,201,400,...,1801,2000。然后使用文本指令 "Given the image, please determine into which range the number of obj falls: {1, 200, 201, 400, ..., 1801, 2000}." 查询 MLLM 以预测给定图像的正确子范围。我们变化 Δ\DeltaΔ 并在图 A 中报告性能。最佳性能 obtained with Δ=300\Delta = 300Δ=300,其仅比 WS-COC w/o D3T 产生轻微改进(见表 5),并且仍然明显不如我们的 D3T。这些结果证明了我们在 D3T 中多轮对话的有效性。
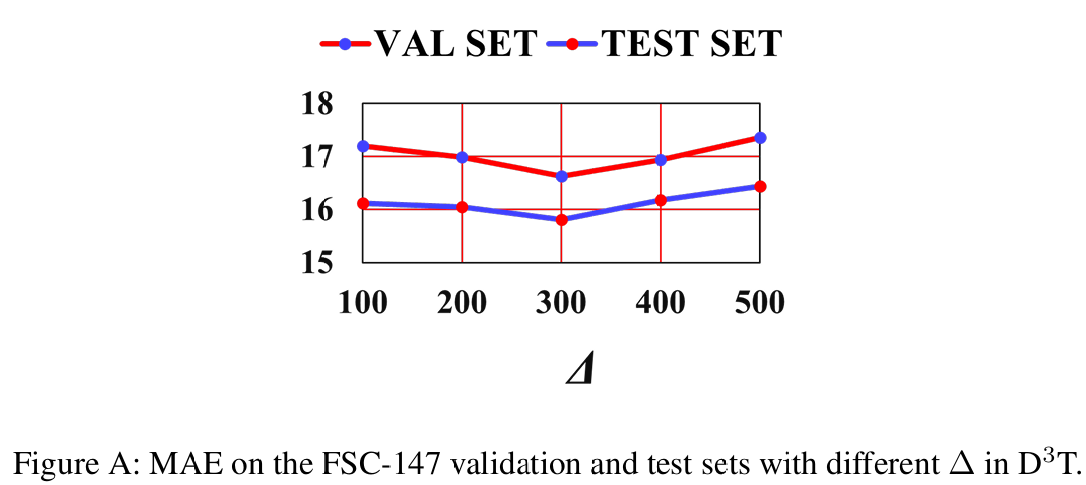
图 A: 不同 D3T 中 Δ\DeltaΔ 时,FSC-147 验证集和测试集上的 MAE。
比较与排序计数优化 (CRCO) 中的图像采样机制。 在我们的 CRCO 策略中,用于计数比较的图像是从同一物体类别采样的,以确保排序期间一致的视觉语义。我们进一步提出了一个变体,表示为 WS-COC w/ CRCOcross,其中我们遵循 CRCO 中的类似策略,但从训练集中的所有类别采样图像。如表 A 所示,此变体比 WS-COC w/o CRCO 实现了一定的增益,但其性能仍然不如我们的 CRCO。这是因为我们的 CRCO 保留了语义一致性,引导模型专注于学习图像之间的计数差异。相比之下,跨类别采样引入了语义方差,降低了性能。
我们还引入了另一个采用半跨类别采样策略的 CRCO 变体。具体而言,我们使用 GPT-5 使用以下提示将训练集中的物体类别划分为语义相似的组:"Divide these categories into different groups, ensuring that categories within each group share semantic similarities: categories"。分组结果报告在表 B 中。然后我们从每组中采样图像用于 CRCO。我们将此变体表示为 WS-COC w/ CRCOsemi-cross,其性能报告在表 A 中。我们发现它的表现略优于完全跨类别采样变体 WS-COC w/ CRCOcross,但仍然不如 CRCO 中默认使用的单类别采样机制。虽然同一组内的类别在语义上相关,但它们仍然表现出巨大的外观差异(例如,苹果、梨和橙子的颜色差异很大),这可能会分散 MLLM 学习计数的注意力。
最后,我们说明了模型在 FSC-147 测试集中每个单独类别上的性能,如图 B 所示,我们观察到 WS-COC w/ CRCOcross 和 WS-COC w/ CRCOsemi-cross 在绝大多数类别上表现不如 WS-COC。
全局与局部计数增强 (GLCE) 中的图像划分机制。 我们谈到了 GLCE 中局部预测引起的边缘效应:简单的网格划分可能会在边界处分割物体,可能导致位于网格边缘的物体被高估。相比之下,全局预测倾向于低估密集场景中的物体。基于这两者的互补性质,我们引入 GLCE 利用全局和局部预测进行准确物体计数。缓解这种边缘效应的一种方法是利用 SAM (Kirillov et al., 2023) 生成的分割掩码来构建划分,希望确保每个物体仅包含在一个划分内。我们将此变体表示为 WS-COC w/ GLCESAM_{SAM}SAM。此外,LVLM-COUNT (Qharabagh et al., 2024) 采用分治方法来缓解这种效应。它依赖额外的预训练模型 (GroundingDINO (Liu et al., 2024b) 和 SAM) 生成区域提议和物体掩码以划分图像进行计数。这导致更复杂的流程和对检测及分割质量的强依赖,其中错误可以直接传播到最终计数结果。我们将此变体表示为 WS-COC w/ GLCELVLM_{LVLM}LVLM。如表 A 所示,两个变体都比 WS-COC w/o GLCE 实现了微不足道的增益,但仍然不如 WS-COC。我们的 GLCE 总体简单、高效且有效。
最后,为了检查 GLCE 的通用性,我们将它集成到 MLLM-Zero 和 WS-COC-Base 中。如表 A 所示,GLCE 一致地提高了这些模型的性能,证明了其作为通用策略的有效性。
全局与局部计数增强 (GLCE) 的数据集敏感性。 GLCE 是基于跨数据集的一致观察提出的:MLLM 倾向于低估密集场景中的物体计数。这是由于 MLLM 主要在具有稀疏人群和少量物体的图像上预训练的性质。因此,GLCE 可以被视为经验上数据集不敏感的。为了验证这一点,我们在表 C 中对各种数据集进行了 GLCE 的详细消融研究,我们观察到每个数据集都有清晰的改进。我们进一步变化 GLCE 中的划分网格大小 LLL。虽然 GLCE 与 L=3L=3L=3 在 SHA 和 PUCPR+ 上表现略优于 L=2L=2L=2,但总体增益是边际的,并伴随着计算成本的显著增加。相比之下,GLCE 与 L=2L=2L=2 在 FSC-147、SHB 和 CARPK 上一致表现最佳(FSC-147 的结果报告在论文的表 5 中),实现了效率和有效性之间的有利平衡。
表 A: 更多消融研究。
| 方法 | 验证集 MAE↓ RMSE↓ | 测试集 MAE↓ RMSE↓ |
|---|---|---|
| WS-COC w/o CRCO | 17.39 65.23 | 16.75 107.45 |
| WS-COC w/ CRCOcross | 16.74 63.58 | 16.33 104.56 |
| WS-COC w/ CRCOsemi-cross | 16.86 65.34 | 16.25 102.76 |
| WS-COC w/o GLCE | 16.64 65.08 | 15.42 105.25 |
| WS-COC w/ GLCESAM_{SAM}SAM | 16.59 70.18 | 15.34 103.14 |
| WS-COC w/ GLCELVLM_{LVLM}LVLM | 16.28 63.17 | 15.19 104.30 |
| MLLM-Zero | 38.92 119.26 | 38.19 145.42 |
| MLLM-Zero w/ GLCE | 33.49 102.83 | 32.65 128.70 |
| WS-COC-Base | 21.70 87.53 | 21.08 122.18 |
| WS-COC-Base w/ GLCE | 19.36 75.96 | 18.85 111.53 |
| WS-COC | 14.77 54.24 | 13.91 97.28 |
表 B: FSC-147 训练集中 89 个类别的分组结果。
| 组 | 类别 |
|---|---|
| 主食和糕点 | buns, bread rolls, biscuits, cupcake tray, macarons, cupcakes, naan bread, croissants, baguette rolls, instant noodles, spring rolls |
| 水果和蔬菜 | oranges, potatoes, tomatoes, peppers, watermelon, bananas |
| 零食和预制食品 | ice cream, goldfish snack, chewing gum pieces, m&m pieces, meat skewers, onion rings, calamari rings |
| 豆类和谷物 | kidney beans, coffee beans, cereals, rice bags, nuts |
| 动物和生物 | pigeons, fishes, crows, geese, penguins, goats, swans, buffaloes, people, cows, bees, zebras, clams |
| 家居和建筑材料 | windows, mini blinds, roof tiles, bricks, cement bags, stairs, polka dot tiles, mosaic tiles, supermarket shelf |
| 交通和机械 | cars, boats, cranes |
| 工具和消耗品/文具 | stapler pins, cartridges, matches, lighters, nails, screws, pencils, pens, crayons, coins, cassettes |
| 个人物品和配件/日常用品 | jeans, shoes, lipstick, caps, kitchen towels, pearls, jade stones, gemstones, beads, candles, birthday candles, cotton balls, balls |
| 餐具、容器和杂项休闲 | cups, plates, bowls, spoon, bottles, cans, boxes, alcohol bottles, chopstick, straws, go game |
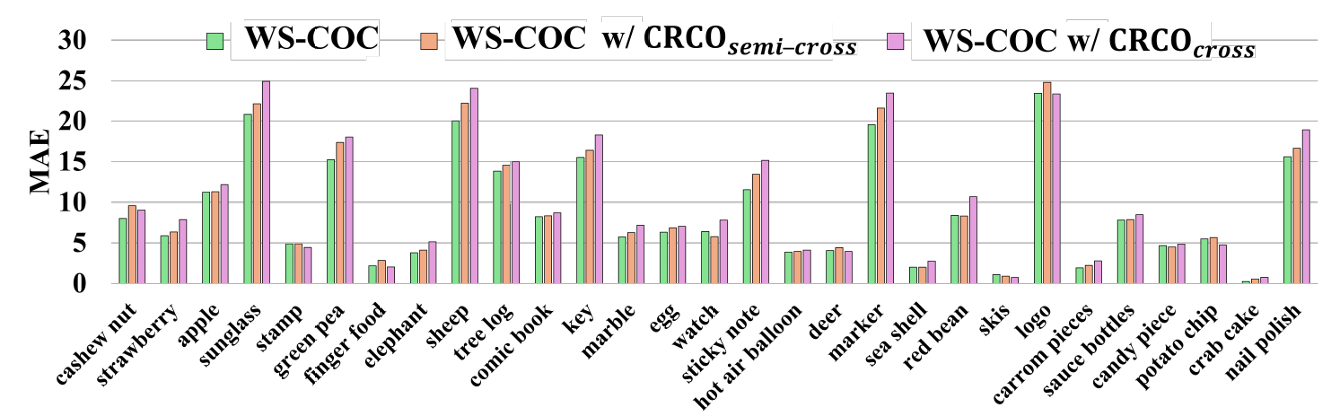
图 B: 不同 CRCO 采样策略下 WS-COC 的每类别 MAE 性能比较。
B 额外分析
额外跨数据集评估。 除了表 2 和表 3 中报告的跨数据集评估外,我们还在 IOCfish5K (Sun et al., 2023) 和 PASCAL VOC 2007 (Everingham et al., 2015) 数据集上进行了实验,这些数据集涉及视觉模糊和严重遮挡的物体。如表 D 所示,WS-COC 在这两个数据集上都取得了 superior 性能,证明了其在处理视觉模糊和遮挡方面的强泛化性。特别是,WS-COC 在 PASCAL VOC 2007 数据集上显著优于其他全监督方法。这种优势可能归因于类似数据的存在,这些数据已经纳入 LLaVA-OneVision 的预训练语料库中。
失败案例分析。 在图 C(a) 和 (b) 中,我们展示了 FSC-147 上的一些代表性失败案例。模型可能在极端密集场景(见图 C(a))和严重遮挡(见图 C(b))下挣扎,其中单独实例难以区分。
为了进一步调查模型在密集场景中的行为,我们分别从 FSC-147 的验证集和测试集中提取所有"极端密集场景"(计数 >300> 300>300)。这两个子集在表 E 中表示为 VALEDS_{EDS}EDS SET 和 TESTEDS_{EDS}EDS SET。接下来,我们在它们上重新评估 WS-COC 和几种代表性方法 (Jiang et al., 2023; Amini-Naieni et al., 2024; Qian et al., 2025)。我们可以观察到所有方法在这些子集上表现不佳,表明困难并非特定于我们的方法;相反,大多数现有方法(甚至是全监督方法)在这种极端密集条件下都在空间理解上挣扎。
为了阐明 underlying cause,我们分析了物体大小和计数误差之间的相关性。当场景包含数百个物体时,每个物体通常只占据几个像素,使得单个物体彼此之间或与背景纹理几乎无法区分。
为了定量验证这一观察,我们计算 FSC-147 测试集中每个图像的平均物体大小:在每个图像中,最初标注了三个物体的边界框以供潜在使用。由于在大多数图像中透视变化不显著,我们简单地通过平均三个边界框面积(以像素为单位)来估计每个图像的平均物体大小。如图 D 所示,具有较小平均物体大小的图像通常导致较大的计数误差。
鉴于上述,我们研究了更细粒度的 GLCE 划分(即将输入图像划分为 3×33 \times 33×3 或 4×44 \times 44×4 网格)是否可以改善模型在这两个子集上的性能。在表 E 中,我们可以看到两个变体(WS-COC w/ GLCE(L=3L=3L=3) 和 WS-COC w/ GLCE(L=4L=4L=4))都显示了一些性能改进,特别是 WS-COC w/ GLCE(L=3L=3L=3)。然而,这些改进仅在这些"极端密集场景"子集上,而在完整验证集和测试集上它们没有增加太多 benefit。具体而言,我们实施了另一个变体,根据预测的全局计数选择不同的网格大小:对于预测全局计数落在 [0,100)[0, 100)[0,100) 内的图像,我们直接使用全局计数;对于 [100,300)[100, 300)[100,300),我们使用 2×22 \times 22×2 网格 (L=2L=2L=2) 融合全局计数与局部预测;对于高于 300 的全局计数,我们采用 3×33 \times 33×3 网格 (L=3L=3L=3)。与 GLCE 相比,此变体实现了微不足道的性能增益,例如 FSC-147 完整验证集上的 -0.13 MAE。由于性能 benefit 非常边际,而设计引入了 much additional complexity,我们选择保持 GLCE 的当前形式。
此外,我们探索了数据增强是否可以缓解这一限制。我们手动连接 FSC-147 训练集中同一类别的多个图像以生成新图像,每个包含超过 300 个物体。此过程共生成了 472 张图像。在将这些增强图像集成到原始训练集中并重新训练 WS-COC 后,我们观察到在 VALEDS_{EDS}EDS SET 和 TESTEDS_{EDS}EDS SET 上都有非常轻微的性能增益(见表 E 中的 WS-COC w/ SynEds 与 WS-COC)。然而,与 WS-COC 相比,此变体导致在完整验证集和测试集上的性能下降(即分别为 +0.45 和 +0.38 MAE)。
表 C: GLCE 变体在 SHA、SHB、CARPK 和 PUCPR+ 上的性能比较。
| 方法 | SHA MAE↓ RMSE↓ | SHB MAE↓ RMSE↓ | CARPK MAE↓ RMSE↓ | PUCPR+ MAE↓ RMSE↓ |
|---|---|---|---|---|
| WS-COC w/o GLCE | 147.1 263.9 | 41.7 64.3 | 13.78 20.99 | 52.76 67.32 |
| WS-COC w/ GLCE(L=2L=2L=2) | 128.9 232.9 | 34.2 57.0 | 10.39 15.83 | 42.30 54.06 |
| WS-COC w/ GLCE(L=3L=3L=3) | 138.2 258.9 | 38.5 57.7 | 11.14 15.64 | 41.64 53.95 |
| WS-COC w/ GLCE(L=4L=4L=4) | 127.4 227.7 | 38.4 59.5 | 13.12 17.15 | 46.35 58.14 |
表 D: 在 IOCfish5K 和 PASCAL VOC 2007 上的跨数据集评估。
| 方法 | 监督 | IOCfish5K MAE↓ RMSE↓ | PASCAL VOC 2007 MAE↓ RMSE↓ |
|---|---|---|---|
| CLIP-Count (Jiang et al., 2023) | point-level | 82.1 155.2 | 12.5 32.7 |
| VLCounter (Kang et al., 2024) | point-level | 78.0 154.9 | 11.3 28.9 |
| CountGD (Amini-Naieni et al., 2024) | point-level | 67.4 144.8 | 8.7 21.7 |
| T2ICount (Qian et al., 2025) | point-level | 63.3 136.1 | 9.9 23.5 |
| WS-COC | image-level | 48.1 112.7 | 0.9 1.4 |
表 E: FSC-147 极端密集场景(每张图像超过 300 个物体)中的定量评估。
| 方法 | 监督 | VALEDS_{EDS}EDS SET MAE↓ RMSE↓ | TESTEDS_{EDS}EDS SET MAE↓ RMSE↓ |
|---|---|---|---|
| CLIP-Count (Jiang et al., 2023) | point-level | 219.59 348.80 | 227.14 684.11 |
| CountGD (Amini-Naieni et al., 2024) | point-level | 174.37 283.62 | 269.87 745.52 |
| T2ICount (Qian et al., 2025) | point-level | 205.07 315.80 | 212.35 666.94 |
| WS-COC | image-level | 185.97 297.95 | 226.96 647.36 |
| WS-COC w/ GLCE(L=3L=3L=3) | image-level | 180.28 291.10 | 221.48 638.62 |
| WS-COC w/ GLCE(L=4L=4L=4) | image-level | 183.14 293.06 | 237.33 649.25 |
| WS-COC w/ SynEds | image-level | 181.57 295.81 | 224.35 651.81 |

图 C: (a) 和 (b) 表示代表性失败案例。
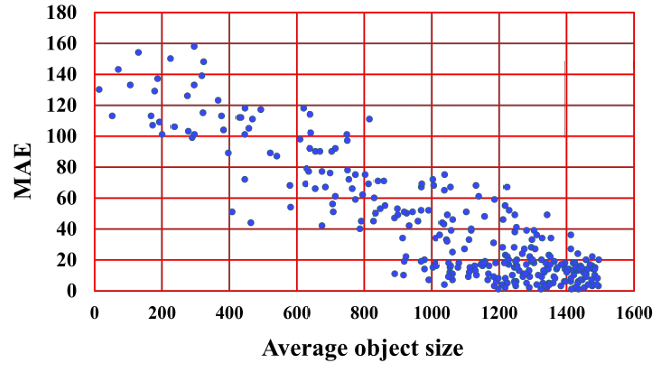
图 D: FSC-147 测试集上每张图像 MAE 与平均物体大小(以像素为单位)的散点图。