一、先说 Transformer 的两半
原版 Transformer(2017 年)是为机器翻译设计的,天然分两半:
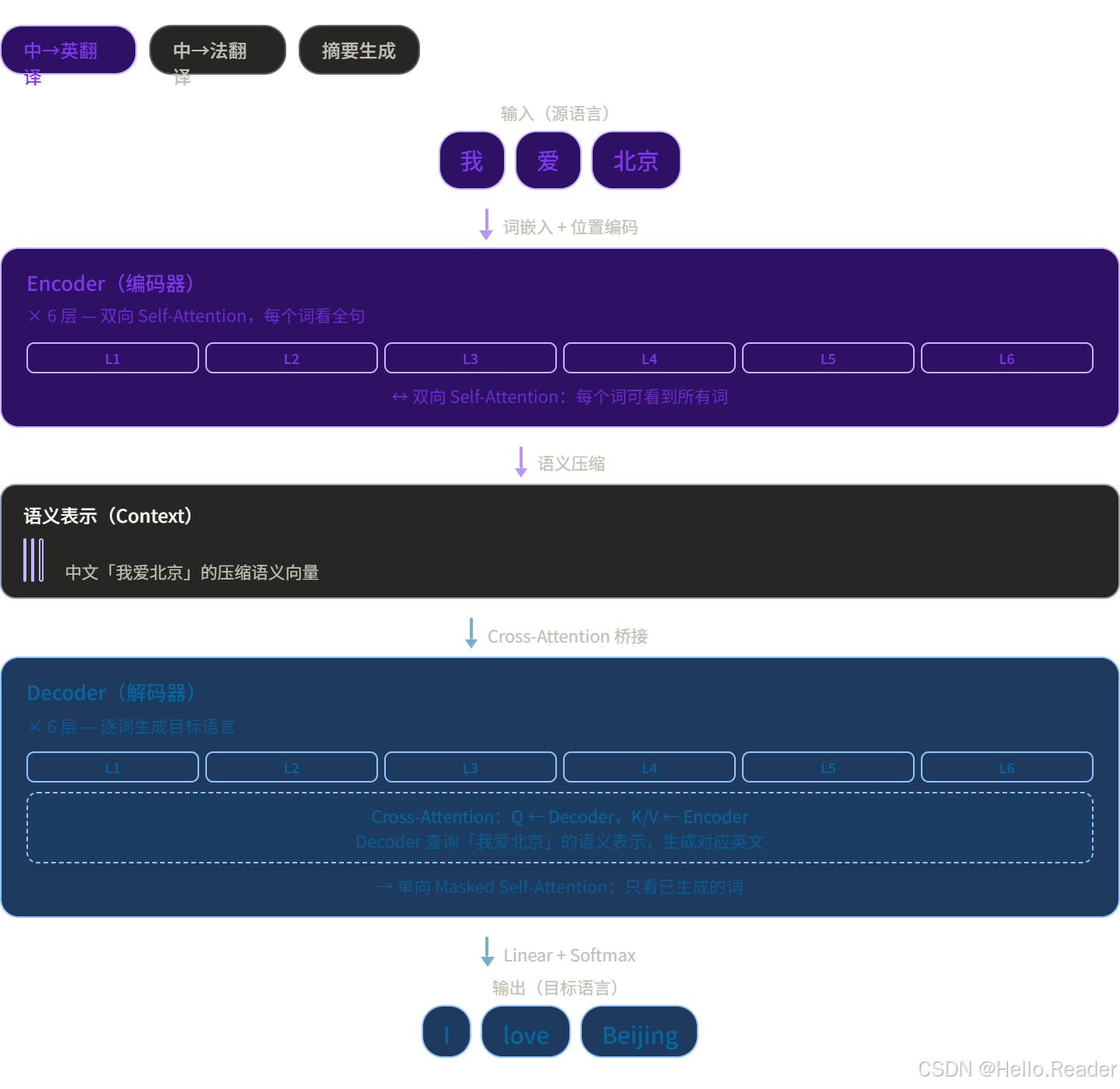
- Encoder(编码器):读懂输入,把它压缩成一个富含语义的"理解结果"
- Decoder(解码器):拿着理解结果,一个词一个词地生成输出
后来的模型发现:很多任务根本不需要两半都用。
- 只需要"读懂"?用 Encoder Only → BERT
- 只需要"生成"?用 Decoder Only → GPT
- 既要读又要写?用 Encoder-Decoder → T5、翻译模型
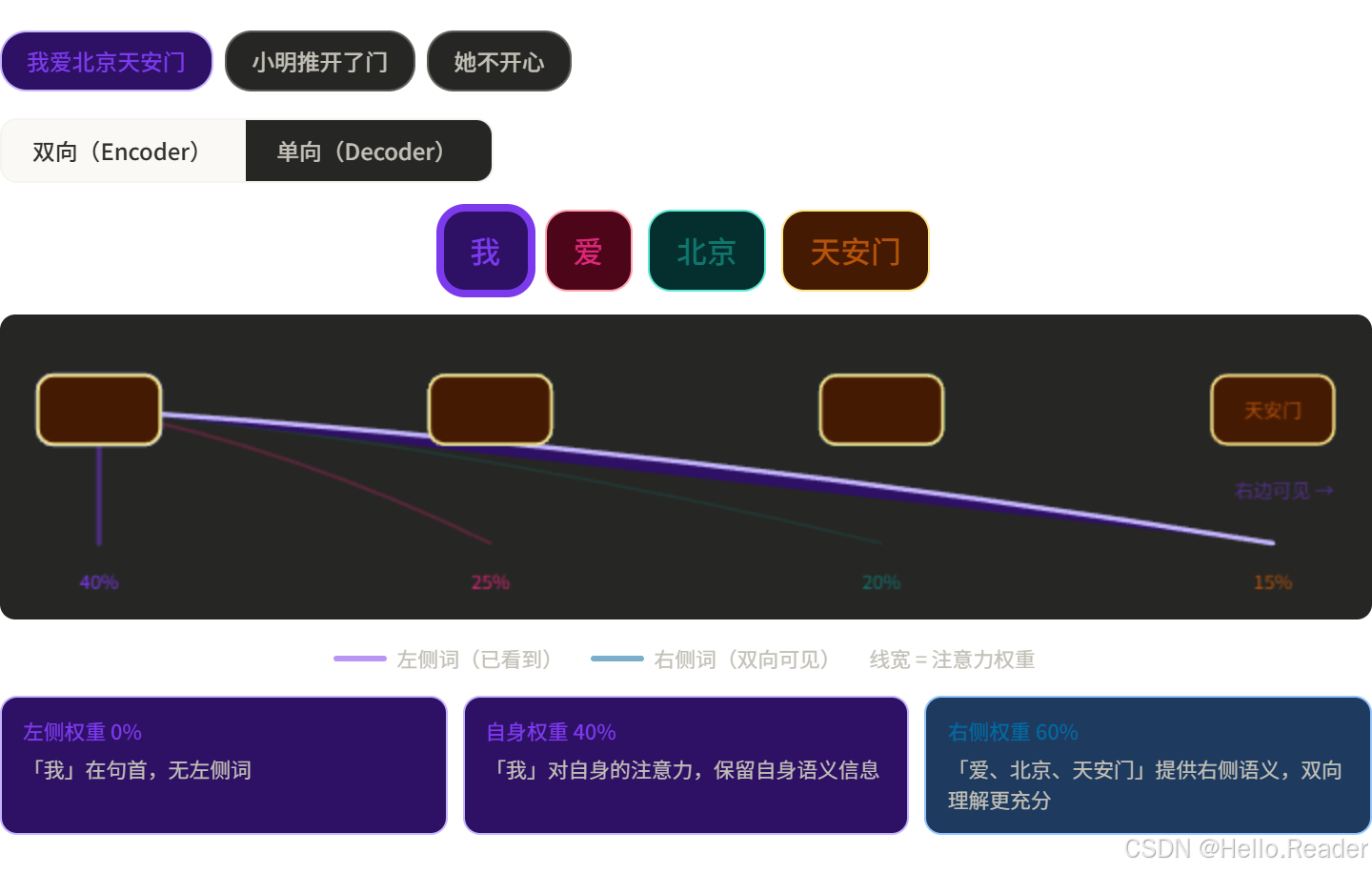
二、Encoder:双向阅读,全局理解
核心特征:双向 Self-Attention
Encoder 在做 Self-Attention 时,每个词可以同时看到整句话------左边的词和右边的词都能看。
结构组成(单层)
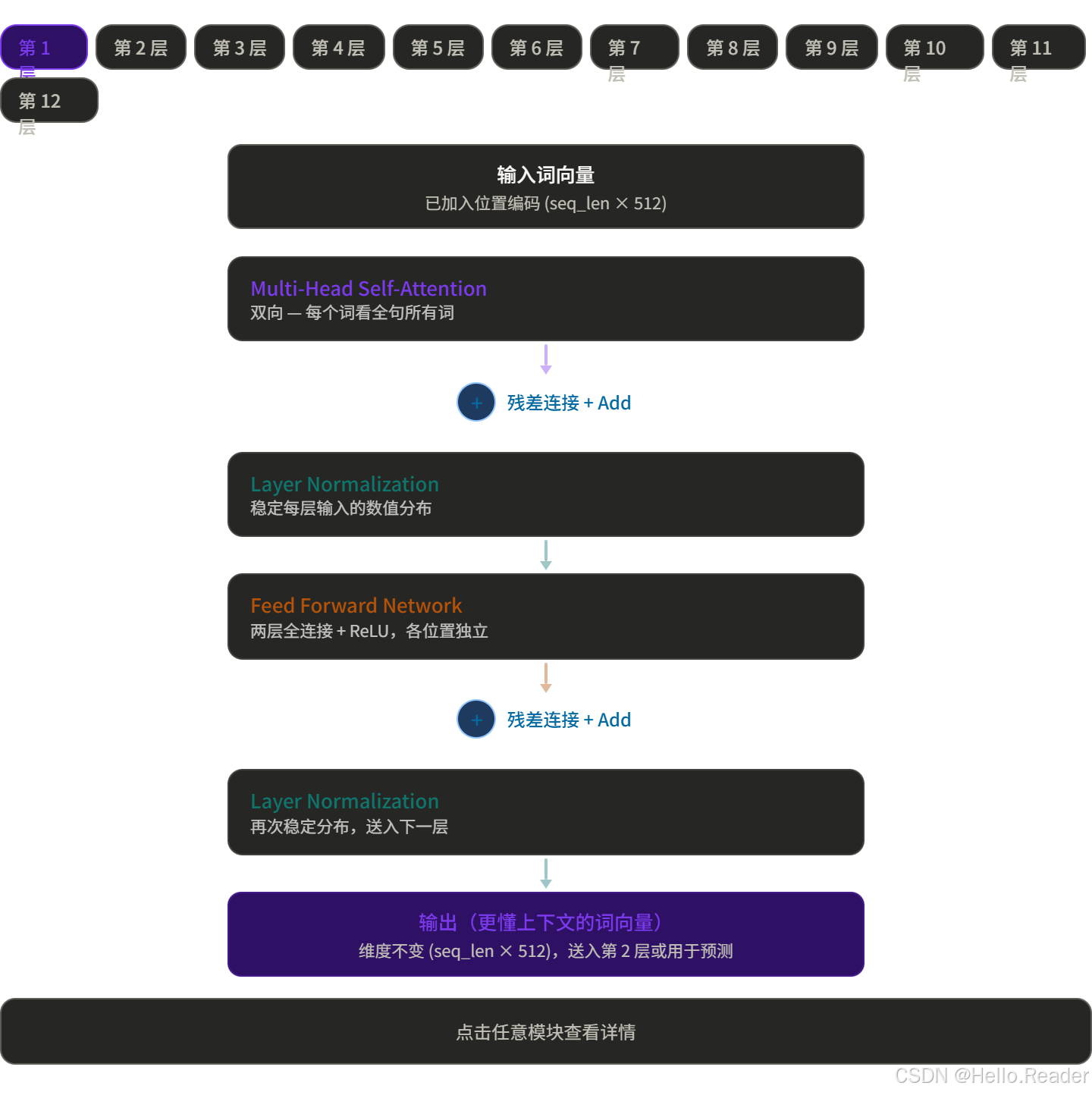
叠 N 层(BERT-base 叠 12 层),每层都进一步提炼语义表示。
残差连接是什么?
每个子层的输出不是直接替换输入,而是加上原始输入:
output = LayerNorm ( x + Sublayer ( x ) ) \text{output} = \text{LayerNorm}(x + \text{Sublayer}(x)) output=LayerNorm(x+Sublayer(x))
好处有两个:
- 梯度可以直接"走捷径"流回去,解决深层网络训练困难的问题
- 即使某一层学到的东西不好,原始信息也不会丢失
典型代表:BERT
BERT 只用了 Encoder,训练方式是完形填空(Masked Language Model):
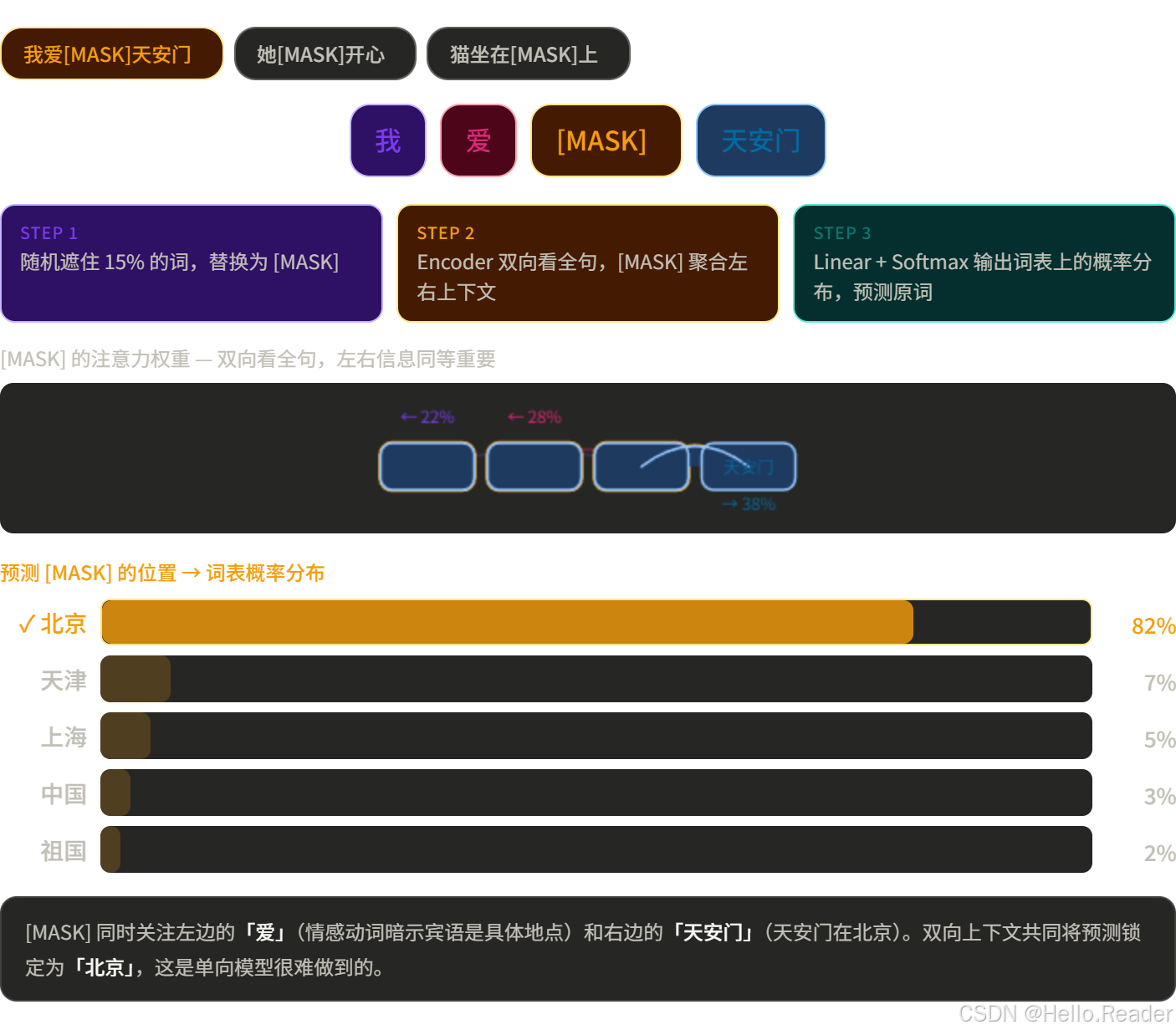
因为要预测被盖住的词,模型必须同时理解左右两边的上下文------这正好对应双向 Attention 的优势。
BERT 的用途:文本分类、情感分析、命名实体识别、问答系统......一切需要"读懂"的任务。
三、Decoder:单向生成,逐词输出
核心特征:Masked Self-Attention(因果掩码)
Decoder 在生成时,每个词只能看到它之前的词,不能"偷看"未来。
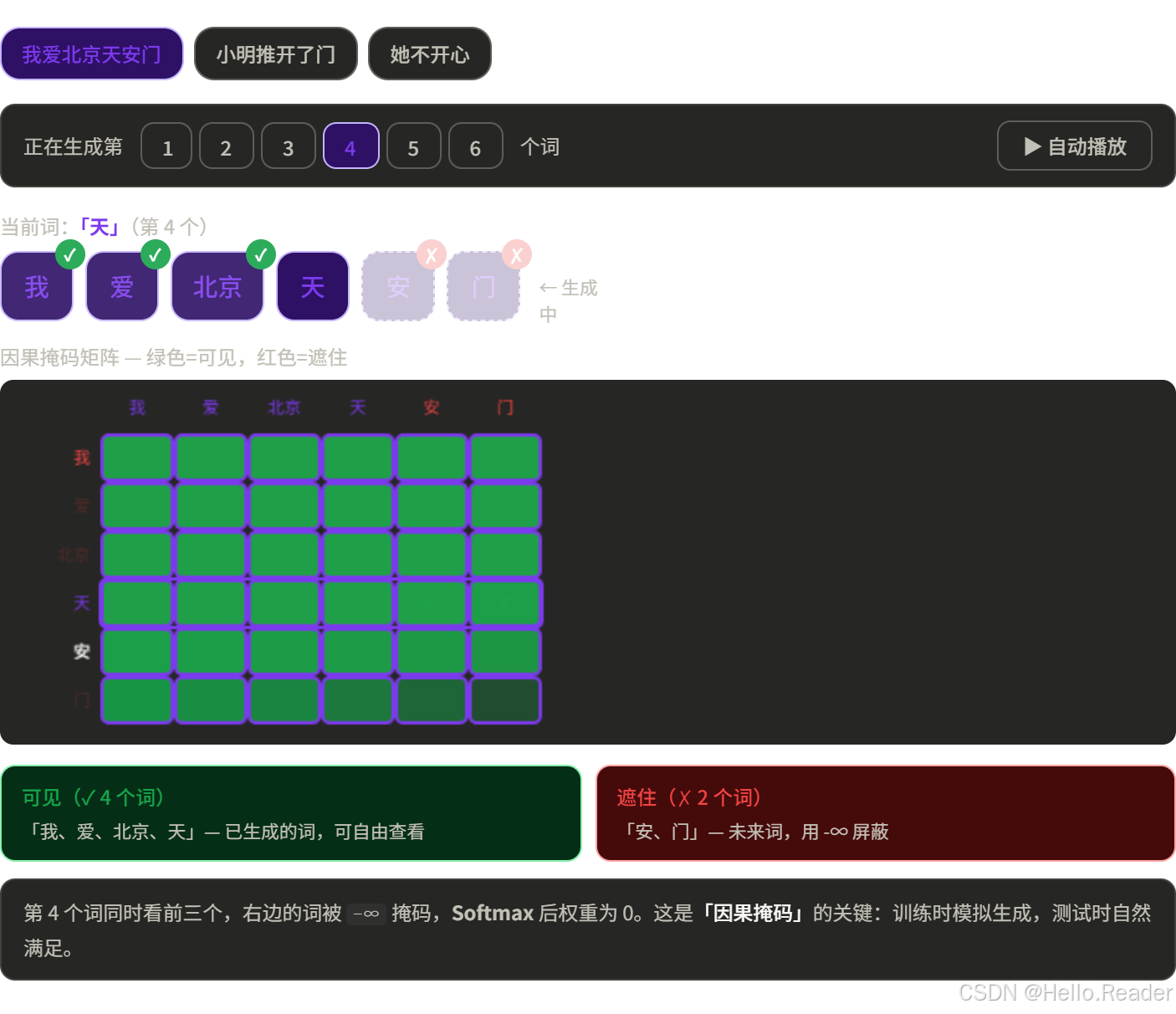
为什么要遮住?因为生成是逐步进行的------你在生成第 4 个词时,第 5、6 个词还不存在。训练时用掩码模拟这个约束,测试时自然满足。
这个掩码叫 Causal Mask (因果掩码),实现方式是在注意力分数矩阵的右上角填上 − ∞ -\infty −∞,Softmax 后变成 0。
score i j = { Q i ⋅ K j T / d k if j ≤ i − ∞ if j > i \text{score}_{ij} = \begin{cases} Q_i \cdot K_j^T / \sqrt{d_k} & \text{if } j \leq i \\ -\infty & \text{if } j > i \end{cases} scoreij={Qi⋅KjT/dk −∞if j≤iif j>i
结构组成(原版 Decoder,单层)
原版 Decoder 比 Encoder 多一个 Cross-Attention 层:
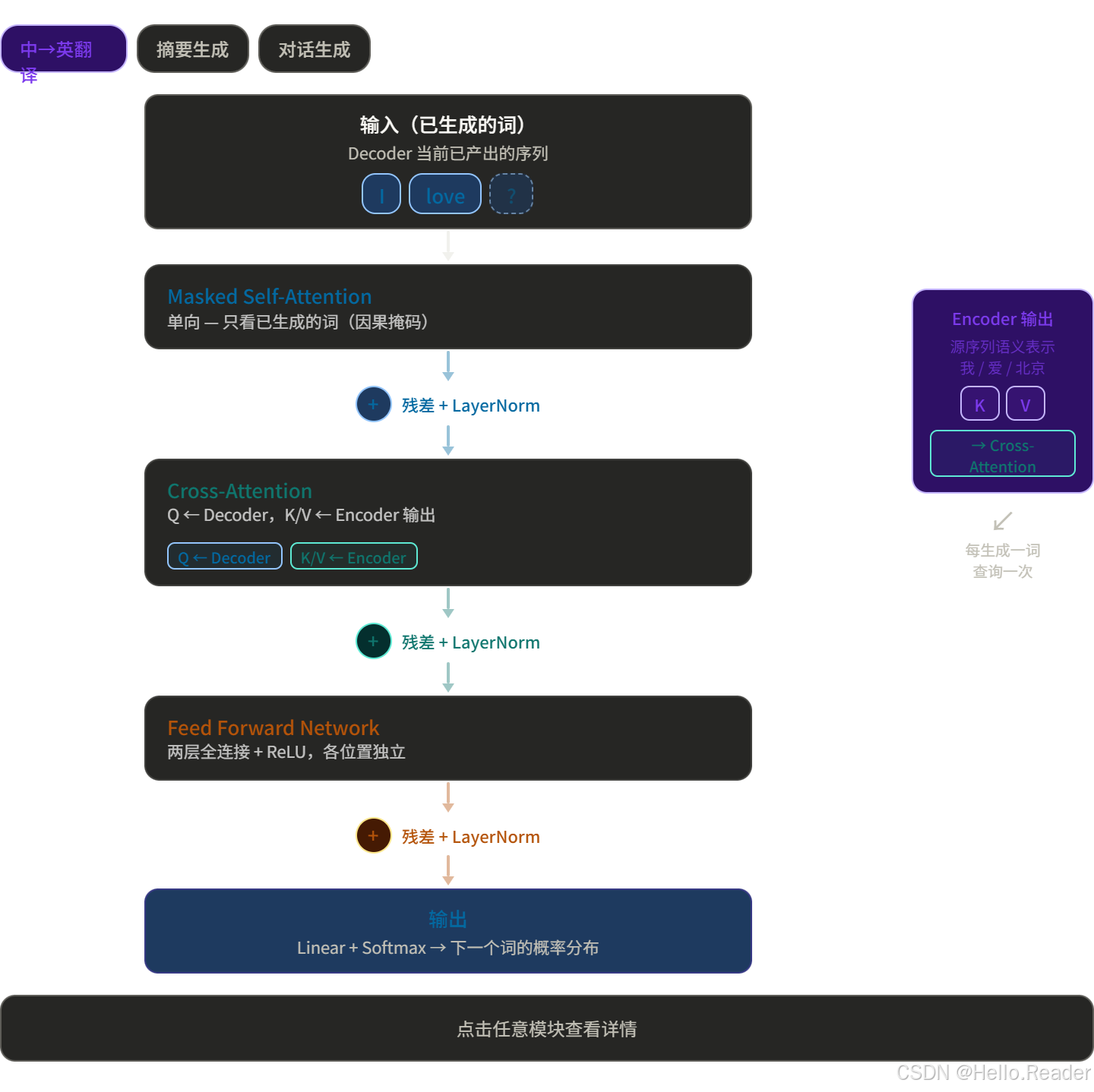
Cross-Attention 是 Encoder 和 Decoder 的"桥梁"------Decoder 用它去"查询"Encoder 的理解结果。
典型代表:GPT
GPT 只用了 Decoder,但去掉了 Cross-Attention(因为没有 Encoder),只保留 Masked Self-Attention 和 FFN。
训练方式是下一词预测:
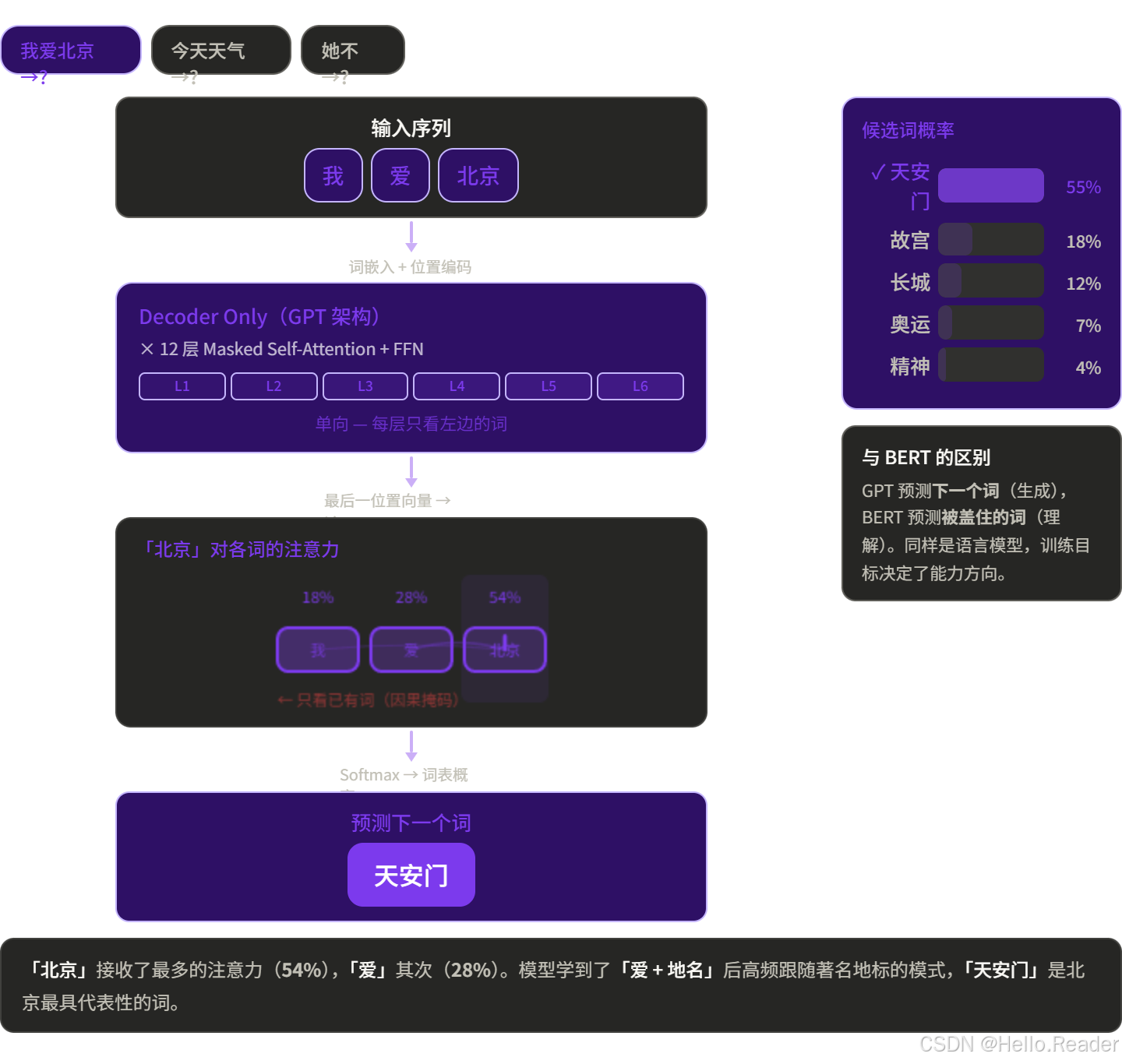
GPT 的用途:文本续写、对话、代码生成、摘要......一切需要"生成"的任务。
四、Encoder vs Decoder 一表对比
| 对比项 | Encoder | Decoder |
|---|---|---|
| Attention 方向 | 双向(看全句) | 单向(只看左边) |
| 掩码 | 无 | Causal Mask(遮住未来) |
| 额外结构 | --- | Cross-Attention(连接Encoder) |
| 训练目标 | 完形填空(MLM) | 下一词预测(CLM) |
| 代表模型 | BERT、RoBERTa | GPT 系列、LLaMA |
| 擅长任务 | 理解、分类、抽取 | 生成、续写、对话 |
五、Cross-Attention:Encoder 和 Decoder 怎么对话?
这是原版 Transformer 里最精妙的设计之一。
在翻译任务里,Decoder 生成英文时需要不断"回头看"中文原文。Cross-Attention 的工作原理:
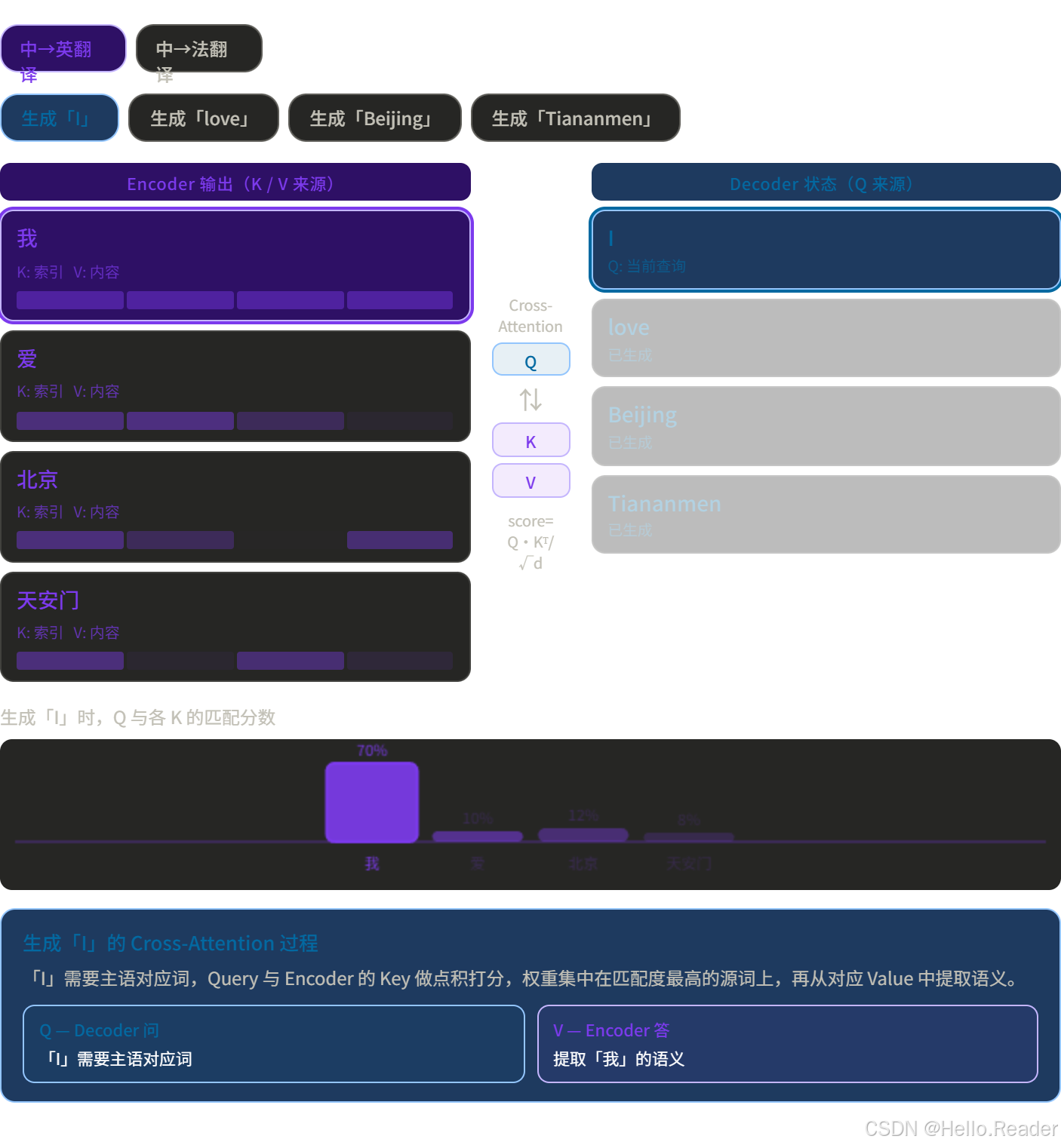
用翻译举例:
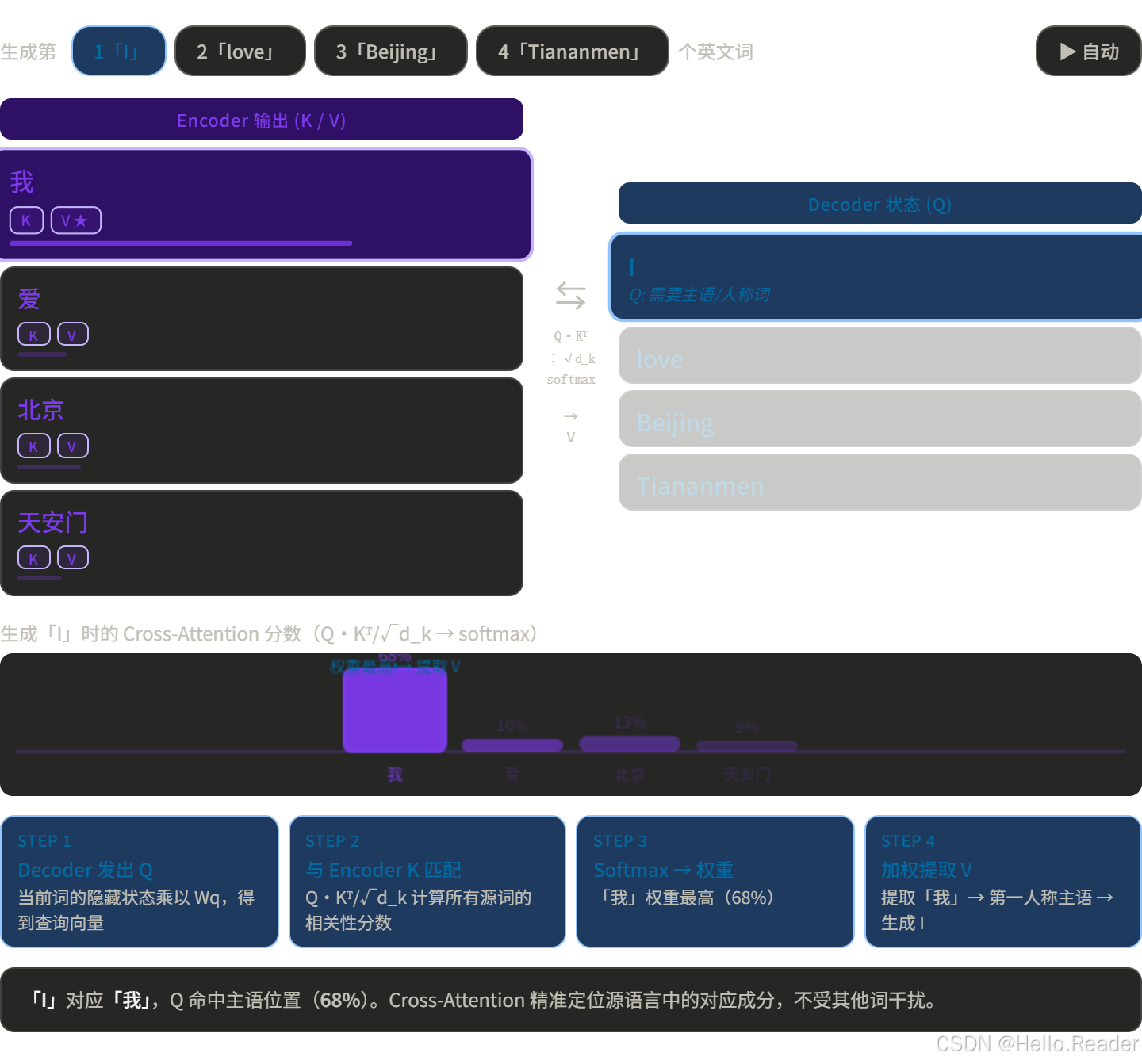
这就是为什么翻译模型知道把"爱"翻译成"love"而不是随便生成一个动词。
六、Feed Forward Network:被忽视的重要组件
每个 Attention 层后面都跟着一个 FFN,公式很简单:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0,\ x W_1 + b_1)\ W_2 + b_2 FFN(x)=max(0, xW1+b1) W2+b2
两层全连接 + ReLU 激活,对每个位置独立计算。
看起来很简单,但研究发现 FFN 承担了大量的"事实记忆"功能------模型记住的知识(比如"巴黎是法国首都")很大一部分存储在 FFN 的权重里,而不是 Attention 里。
Attention 负责"找关系",FFN 负责"存知识"------两者分工协作。
七、Layer Normalization:训练稳定的秘诀
每个子层后面都有 LayerNorm:
LayerNorm ( x ) = x − μ σ ⋅ γ + β \text{LayerNorm}(x) = \frac{x - \mu}{\sigma} \cdot \gamma + \beta LayerNorm(x)=σx−μ⋅γ+β
它对同一个样本的不同维度做归一化(Batch Norm 是对不同样本的同一维度),让每层的输入分布保持稳定,避免梯度爆炸或消失。
γ \gamma γ 和 β \beta β 是可学习的缩放/偏移参数,让模型可以恢复它认为合适的分布。
八、完整的 Transformer 流程
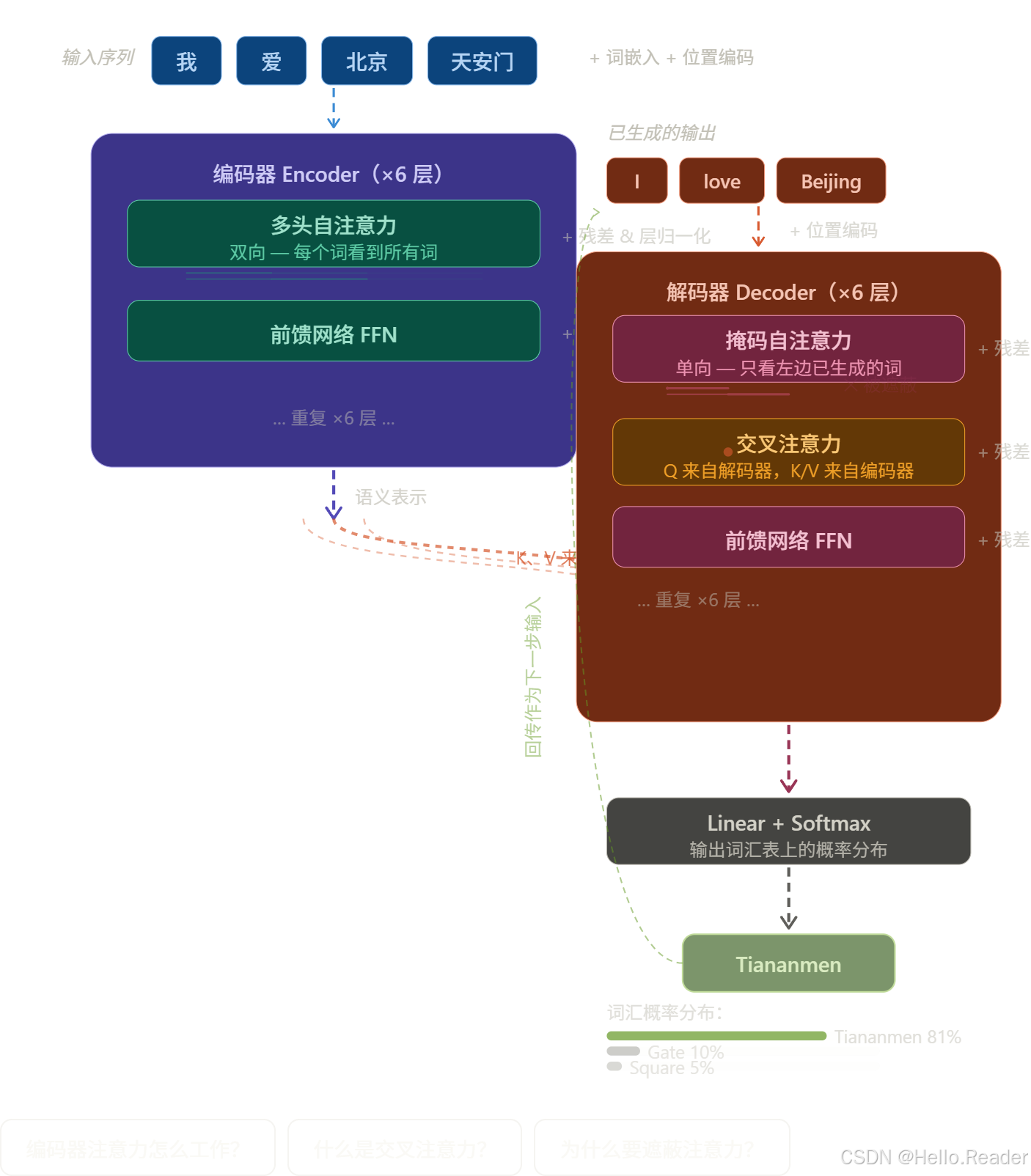
九、现代大模型都用什么?
原版 Encoder-Decoder 现在主要用于翻译和摘要。
绝大多数现代大语言模型 (GPT-4、Claude、LLaMA、Qwen、Gemini 等)都是 Decoder Only 架构,原因有三:
- 统一性:一个架构可以处理所有任务(生成本身包含了理解)
- 可扩展性:Decoder Only 在超大规模时表现更稳定
- 涌现能力:足够大的 Decoder 模型会涌现出 Encoder 模型才有的理解能力
BERT 类的 Encoder Only 模型在需要高效部署、小模型场景(分类、NER、搜索排序)中仍然大量使用。
十、三句话总结
-
Encoder = 双向阅读:每个词看全句,适合"理解"任务,代表是 BERT。
-
Decoder = 单向生成:每个词只看左边,适合"生成"任务,代表是 GPT。
-
现代大模型几乎全是 Decoder Only:统一架构 + 超大规模,已经能同时做到理解和生成。
延伸阅读
- 📄 原论文:Attention Is All You Need(2017)--- 完整的 Encoder-Decoder 架构
- 📄 BERT 论文:BERT: Pre-training of Deep Bidirectional Transformers(2018)
- 📄 GPT 论文:Improving Language Understanding by Generative Pre-Training(2018)
- 🔬 可视化:The Illustrated BERT