本节:第3章:快速入门SpringAI Alibaba
下一节:待更新
第3章:快速入门 Spring AI Alibaba
前两章,我们已经分别完成了两件很重要的事情:
- 先在云端把大模型调用链路跑通
- 再在本地把 Qwen3 跑起来
到了这一步,一个更贴近 Java 开发者的问题自然就出现了:
如果我要在 Spring Boot 项目里真正接入大模型,到底该怎么做?
很多人第一反应会想到 Spring AI。但当你真正开始接国内模型、接阿里云百炼、接本地 Ollama 时,很快就会发现:光知道 Spring AI 还不够,真正更顺手的,往往是 Spring AI Alibaba。
这一章,我们就用一个最小可跑通的例子,快速上手 Spring AI Alibaba,把云端模型、本地模型、同步对话、日志记录和流式输出这几件事串起来。
Spring AI 和 Spring AI Alibaba 到底有什么区别
先说结论:
Spring AI 更像是一套通用的大模型接入标准,而 Spring AI Alibaba 则是在这个基础上,针对阿里云百炼和国内模型生态做了更贴近实战的增强。
官方网站:
如果只用一句话来理解两者的关系,可以这样看:
Spring AI:标准能力框架Spring AI Alibaba:更适合国内模型接入场景的落地方案
对很多国内开发者来说,真正的痛点并不是"不会写 Java 代码",而是"接模型的时候总有各种兼容细节"。比如模型配置方式、平台适配、调用体验、生态整合等,这些问题一旦叠加,就会让一个本来很简单的 Demo 变得不再简单。
而 Spring AI Alibaba 的价值,恰恰就在于它把这些接入成本往下压了一层。
你可以把它的优势理解为三点:
- 兼容
Spring AI的整体标准 - 对阿里云百炼的支持更自然
- 同时也方便接入本地模型能力,例如
Ollama
这意味着,我们既可以保留 Spring 体系里的开发习惯,又能更顺畅地把国内云模型和本地模型接进同一个项目里。
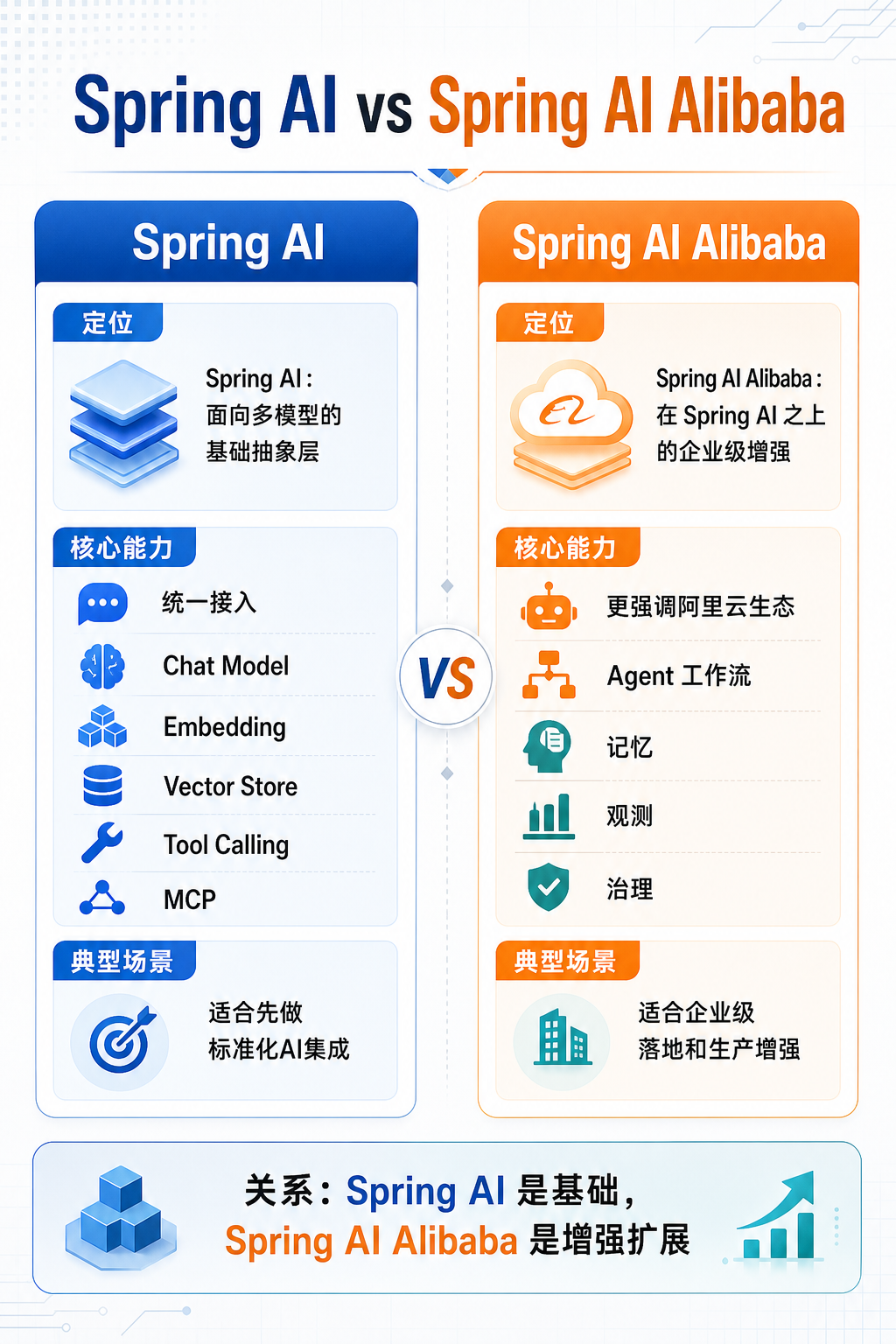
图1:Spring AI Alibaba 官网首页
第一步:完成项目初始化和依赖准备
真正开始写代码之前,先把基础环境搭好。
这一部分的目标很明确:让 Spring Boot 项目同时具备三类能力:
- 接入阿里云百炼模型
- 接入本地 Ollama 模型
- 具备后续扩展记忆、RAG 等能力的基础依赖
下面是示例依赖配置:
xml
<properties>
<java.version>21</java.version>
<spring-ai.version>1.0.0</spring-ai.version>
<spring-ai-alibaba.version>1.0.0.2</spring-ai-alibaba.version>
<spring-boot.version>3.4.5</spring-boot.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>如果你第一次看这段依赖,不需要一上来就把每个包都研究透。先抓住最关键的几项就够了:
spring-ai-alibaba-starter-dashscope:用于接入阿里云百炼spring-ai-starter-model-ollama:用于接入本地 Ollamaspring-ai-alibaba-starter-memory-redis:为后续记忆能力预留扩展空间
也就是说,这个工程从一开始就不是只为"跑一个聊天接口"准备的,而是已经具备继续往更复杂 AI 应用演进的基础。
第二步:完成基础配置
依赖准备好之后,下一步就是配置模型连接信息。
这里建议使用 application.yml,而不是把模型相关参数散落在代码里。这样后续切换模型、切换环境、切换云端或本地服务时,都会轻松很多。
示例配置如下:
yaml
spring:
application:
name: SpringAIAlibaba-RAG-Milvus
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
chat:
model: qwen-plus
options:
temperature: 0.7
ollama:
enabled: true
base-url: http://localhost:11434
chat:
model: qwen3:1.7b
options:
temperature: 0.7
server:
port: 8080这里有一个对外发布时必须注意的点:
不要在文章或代码仓库里直接暴露真实 API Key。
所以在正式分享时,更推荐像上面这样写成环境变量形式:
yaml
api-key: ${DASHSCOPE_API_KEY}这样既保留了配置结构,也避免把敏感信息直接暴露出去。
如果你从理解配置的角度来读这段内容,可以重点关注三件事:
- 云端模型这里使用的是
qwen-plus - 本地模型这里接的是
qwen3:1.7b - 两套模型都被纳入了同一个 Spring Boot 配置体系中
这一步做完,其实就意味着:你的项目已经同时具备了调用"云模型"和"本地模型"的基础能力。
第三步:创建 ChatClient 配置
有了依赖和配置之后,接下来要做的,就是把模型真正封装成项目里可直接使用的 ChatClient。
这一步的意义在于:后面的控制器、服务层、工作流逻辑,都不需要直接关心底层模型初始化细节,而是直接面向 ChatClient 编程。
示例配置类如下:
java
@Configuration
public class ChatConfig {
@Bean
public ChatClient dashscopeChatClient(@Qualifier("dashscopeChatModel") ChatModel dashscopeChatModel) {
return ChatClient.builder(dashscopeChatModel)
.build();
}
@Bean
public ChatClient ollamaChatClient(@Qualifier("ollamaChatModel") ChatModel ollamaChatModel) {
return ChatClient.builder(ollamaChatModel)
.build();
}
}如果你把它翻译成人话,其实就是:
- 给云端 DashScope 模型创建一个
ChatClient - 给本地 Ollama 模型创建一个
ChatClient
这样后面我们就可以像调用普通组件一样,分别去调用云端模型和本地模型,而不需要在业务代码里重复写初始化逻辑。
第四步:先写出第一个同步对话接口
环境和配置都准备好之后,最自然的下一步,就是先把最基础的聊天接口跑起来。
下面是一个最小示例:
java
@RestController
@RequestMapping("/api/ai")
public class SimpleAiController {
@Autowired
private ChatClient dashscopeChatClient;
@Autowired
private ChatClient ollamaChatClient;
/**
* 云端模型聊天接口
*/
@GetMapping("/chat/alibaba")
public String chat(@RequestParam("question") String question) {
return dashscopeChatClient.prompt(question).call().content();
}
/**
* 本地模型聊天接口
*/
@GetMapping("/chat/ollama")
public String ollamaChat(@RequestParam("question") String question) {
return ollamaChatClient.prompt(question).call().content();
}
}这段代码虽然简单,但它已经完成了一件非常有价值的事情:
同一个 Spring Boot 项目,同时暴露了云端模型和本地模型的调用入口。
从工程视角看,这一步能帮助我们快速回答两个问题:
- 云端模型能不能正常调用
- 本地模型能不能在同一套项目结构里正常接入
很多时候,真正的开发节奏不是一开始就追求复杂能力,而是先把最短调用链路跑通。只要这一步通了,后面的上下文管理、日志记录、流式输出和 RAG 才有继续往上叠加的基础。
第五步:用 Advisor 给 AI 对话加日志
当最基础的聊天接口跑通之后,接下来非常值得做的一件事,就是把日志接进来。
因为在 AI 应用开发里,很多问题都不是"接口有没有返回",而是:
- 请求到底发了什么
- 模型到底怎么回的
- 参数是否符合预期
- Token 消耗是否合理
这时候,Advisor 就很有用了。
你可以把它理解成 AI 对话流程里的"拦截增强器"。在请求发送前后,它可以自动插入额外逻辑,例如日志记录、审查、监控等。
一句话理解:
Advisor 可以看作 AI 调用链路中的拦截器,用来在请求前后自动附加额外逻辑。
示例配置如下:
java
@Configuration
public class AIClientConfig {
/**
* 配置本地 Ollama 的 ChatClient(带日志记录)
*/
@Bean(name = "ollamaChatClient")
public ChatClient ollamaChatClient(OllamaChatModel ollamaChatModel) {
return ChatClient.builder(ollamaChatModel)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
/**
* 配置云端 DashScope 的 ChatClient(带日志记录)
*/
@Bean(name = "dashscopeChatClient")
@Primary
public ChatClient dashscopeChatClient(DashScopeChatModel dashscopeChatModel) {
return ChatClient.builder(dashscopeChatModel)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}这一步做完之后,最大的价值不是"代码更炫了",而是你的 AI 调试能力会明显提升。
因为从这一刻开始,你不再只是看到一个最终回复,而是能看到:
- 请求消息内容
- 模型参数
- 返回结果结构
- Token 使用情况
这些信息对于后续做提示词优化、问题排查、性能分析,都会非常有帮助。
第六步:日志结果到底该怎么看
当 SimpleLoggerAdvisor 生效之后,你会在日志里看到完整的请求和响应信息。
下面是一段典型的返回示例:
json
2026-05-02T08:34:36.384+08:00 DEBUG ... request: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='你是什么模型?', ...}], modelOptions=DashScopeChatOptions: {"model":"qwen-plus","temperature":0.7,...}}, context={}]
2026-05-02T08:34:38.235+08:00 DEBUG ... response: {
"metadata": {
"usage": {
"promptTokens": 12,
"completionTokens": 67,
"totalTokens": 79
}
},
"results": [ {
"output": {
"text": "我是通义千问(Qwen),由通义实验室研发的超大规模语言模型。..."
}
} ]
}对外写文章时,其实没必要把整段完整日志一股脑贴出来。更适合读者的方式,是告诉他们应该重点看什么:
- 请求里真正发给模型的内容是什么
- 本次调用使用的是哪个模型
usage里记录了多少 Token 消耗- 返回文本是否符合预期
换句话说,日志最重要的价值不是"展示信息很多",而是帮我们快速定位调用过程中的关键信号。
这也是为什么在 AI 工程实践里,日志常常不是可选项,而是基础能力。
第七步:再补一个流式接口
同步对话跑通之后,下一步通常就是流式输出。
因为很多真实场景里,我们并不希望模型把整段内容生成完再一次性返回,而是更希望它像聊天产品一样边生成边输出。这样用户的体感会更自然,交互也会更流畅。
示例代码如下:
java
/**
* 流式聊天接口
*/
@GetMapping(value = "/stream/chat/ollama", produces = "text/html;charset=utf-8")
public Flux<String> streamChat(@RequestParam("question") String question, HttpServletResponse response) {
return ollamaChatClient.prompt(question).stream().content();
}这段代码的核心并不复杂,关键点只有一个:
call() 适合同步结果,stream() 适合流式返回。
也就是说,当你从:
java
.call().content()切换到:
java
.stream().content()你的接口能力就从"一次性返回结果"变成了"持续输出生成内容"。
对于后面做聊天界面、流式问答、长文本生成来说,这一步会非常关键。
写在最后
如果说前两章解决的是"模型能不能用",那么这一章解决的就是:
如何把模型真正接进一个 Spring Boot 工程。
通过 Spring AI Alibaba,我们不仅能更自然地接入阿里云百炼,也能把本地 Ollama 模型一起纳入同一个项目体系中。再往上叠加 Advisor 日志和流式接口之后,一个最基础但已经很有实战味道的 AI 应用骨架,其实就已经搭起来了。
更重要的是,当你亲手把这些代码跑通后,你对 AI Java 开发的理解就会从"知道概念"进入"会搭工程"的阶段。