目录
[一 进程等待](#一 进程等待)
[1 为什么?](#1 为什么?)
[2 是什么?](#2 是什么?)
[3 结论](#3 结论)
[4 进程等待的方式](#4 进程等待的方式)
[2. 阻塞等待(李四攥着电话不挂那种)](#2. 阻塞等待(李四攥着电话不挂那种))
[二 进程程序替换](#二 进程程序替换)
[1 理解](#1 理解)
[2 替换原理](#2 替换原理)
[3 父子进程版本](#3 父子进程版本)
[4 替换函数](#4 替换函数)
一 进程等待
1 为什么?
父进程提供wait/waitpid这样的系统调用,来等待子进程
2 是什么?
status是输出型参数,可以通过传递一个整数的形式,来获得子进程的退出信息
3 结论
结论:
- 1、原则上,一般都是要保证父进程最后退出;
- 2、父进程要通过wait等待子进程;
- 3、如果子进程不退出,父进程就会阻塞在wait这里,等待子进程死亡。
4 进程等待的方式
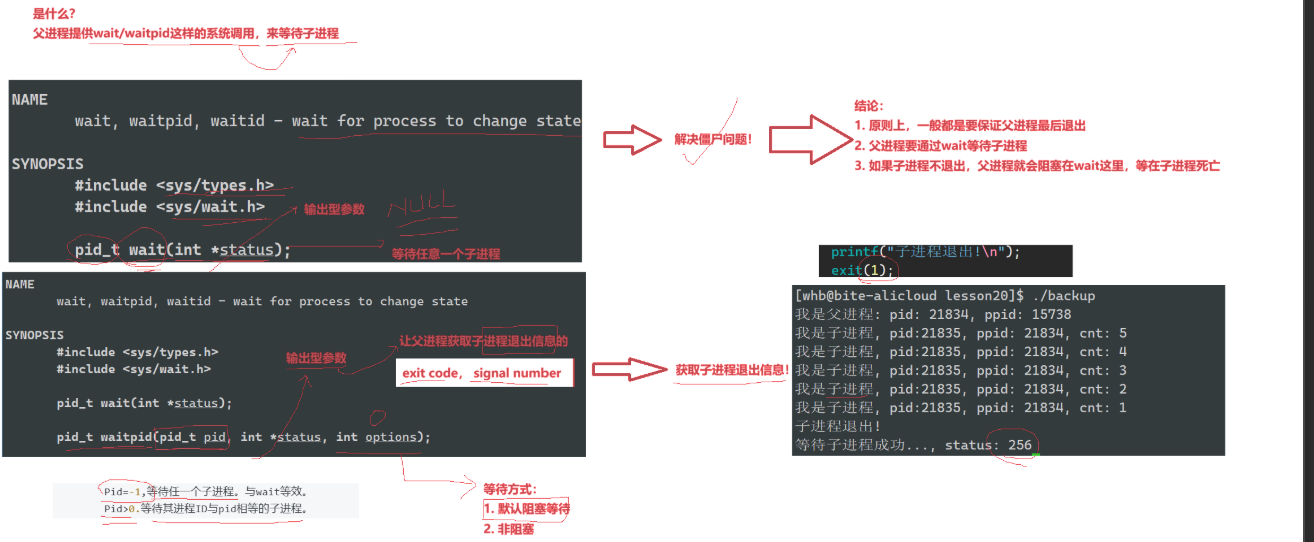
(1)wait方法
bash
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取⼦进程退出状态,不关⼼则可以设置成为NULL(2)waitpid方法
bash
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的⼦进程的进程ID;
如果设置了选项WNOHANG,⽽调⽤中waitpid发现没有已退出的⼦进程可收集,则返回0;
如果调⽤中出错,则返回-1,这时errno会被设置成相应的值以指⽰错误所在;
参数:
pid:
Pid=-1,等待任⼀个⼦进程。与wait等效。
Pid>0.等待其进程ID与pid相等的⼦进程。
status: 输出型参数
WIFEXITED(status): 若为正常终⽌⼦进程返回的状态,则为真。(查看进程
是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED⾮零,提取⼦进程退出码。(查看进程
的退出码)
options:默认为0,表⽰阻塞等待
WNOHANG: 若pid指定的⼦进程没有结束,则waitpid()函数返回0,不予以等
待。若正常结束,则返回该⼦进程的ID。如果子进程已经退出,调用 wait/waitpid 时,wait/waitpid 会立即返回,并且释放资源,获得子进程退出信息。
如果在任意时刻调用 wait/waitpid,子进程存在且正常运行,则进程可能阻塞。
如果不存在该子进程,则立即出错返回。
(3)获取子进程status
当前进程的退出信息叫做status
• wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
• 如果传递NULL ,表示不关心子进程的退出状态信息。
• 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程 。
• status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16比特位):
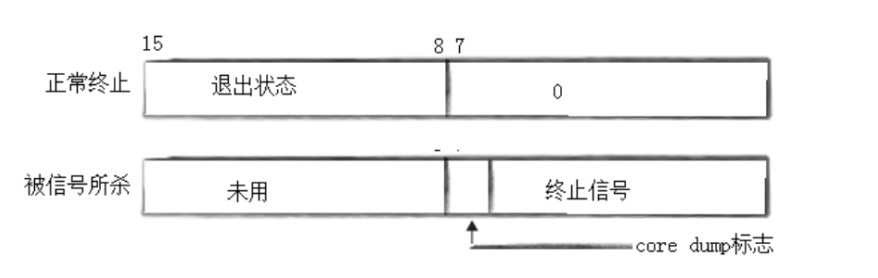
status是一个int类型,所以它有32位比特位,但其实它的高16位是不用的,只使用低16位。
在低16位中,低8位和次低8位代表的内容是不一样的,如下图所示
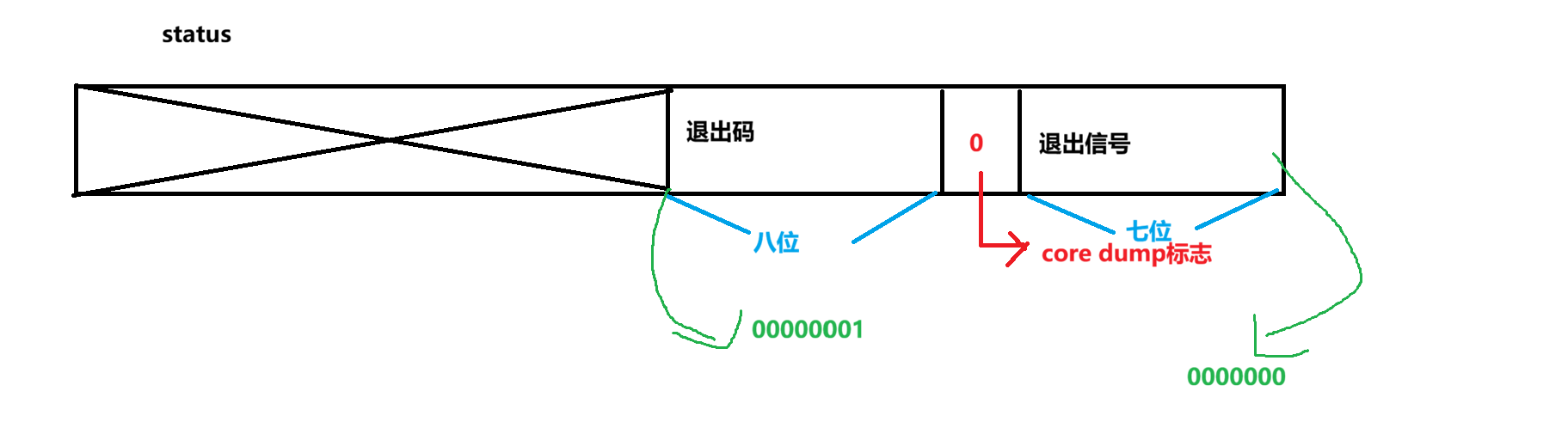
上述这对应一个正常退出的场景:
终止信号 = 0 → 不是被信号杀死,是正常 exit()/return 退出
退出码 = 1 → 子进程调用了 exit(1) 或 return 1
core dump 标志 = 0 → 没有 core dump(正常退出本来就不会有)
这个时候有些uu可能就会疑问了,退出信号不是没有0吗,为什么这里的退出信号是0?

因为退出码占据8位,而2^8=256,所以退出码的范围是【0,255】
退出信号没有0:因为0表示正常退出,非0表示不正常退出
父进程获取子进程的退出信息=退出码+退出信号
问题:wait/waitpid 是怎样获取子进程的退出信息的?
(1)子进程退出,退出信息是维护在PCB中的,包括将自己设置为僵尸
(2)父进程wait子进程,本质就是去读取子进程PCB内部的退出信息
结论:通过检查子进程Z状态,获取子进程task_struct 内部记录的子进程退出信息数据的
我们在上面看到waitpid的第三个参数为:options-->0表示阻塞等待
那什么是阻塞等待,什么是非阻塞等待?
(4)阻塞等待和非阻塞等待

WNOHANG宏:非阻塞等待(字面意思是 "No Hang"(不挂起 / 不阻塞))
我们使用wait/waitpid的时候:

用一个故事解释阻塞等待和非阻塞等待:
非阻塞等待(李四打电话催张三那种)
你点了一份外卖,没选 "准时宝":
- 你不会一直盯着手机等,该追剧追剧、该看书看书、该打游戏打游戏;
- 每隔一会儿,你就打开外卖 App 看一眼:「到哪了?取餐了吗?快到了吗?」
- 要是外卖还没到,你立刻切回自己的事,继续做自己的;
- 直到看到「已送达」,你才起身去拿餐。
对应到计算机里:
- 你 = 父进程(李四)
- 外卖小哥 = 子进程(张三)
- 打开 App 看一眼 = 调用
waitpid+WNOHANG(非阻塞轮询) - 特点:你不傻等,该干嘛干嘛,只是定期 "查岗"。
2. 阻塞等待(李四攥着电话不挂那种)
你点了一份外卖,选了 "必须当面签收":
- 你放下手里所有事,坐在门口 / 电话旁,眼睛盯着手机、耳朵听着门铃;
- 期间你什么都干不了,既不追剧也不看书,就死等外卖敲门;
- 直到外卖小哥按门铃,你开门拿餐,这段时间才算结束。
对应到计算机里:
- 你 = 父进程(李四)
- 外卖小哥 = 子进程(张三)
- 坐在门口死等 = 调用
wait/waitpid(不带WNOHANG) - 特点:你完全卡住,啥也干不了,直到子进程完事。
一句话总结
- 非阻塞等待 :我不傻等,我该干嘛干嘛,抽空看看你完事没;
- 阻塞等待 :我啥也不干了,就盯着你,等你完事我再动。
waitpid的返回值:

成功:返回值>0,返回的是子进程的pid
失败:返回值<0 ,返回-1
状态没有改变:返回0
非阻塞轮循最明显的特点:父进程不会卡在那
结论: 最佳实践--->目前阻塞等待是最佳实践
进程的阻塞等待方式:
bash
int main()
{
pid_t pid;
pid = fork(); // 创建子进程,父进程返回子进程PID,子进程返回0
if(pid < 0){ // fork失败
printf("%s fork error\n",__FUNCTION__);
return 1;
} else if( pid == 0 ){ // 子进程分支
printf("child is run, pid is : %d\n",getpid());
sleep(5); // 子进程睡眠5秒,模拟业务逻辑
exit(257); // 子进程退出,传入257(超出0-255范围)
} else{ // 父进程分支
int status = 0;
// 阻塞等待任意子进程(-1表示等待所有子进程)退出,等待5秒
pid_t ret = waitpid(-1, &status, 0);
printf("this is test for wait\n");
// WIFEXITED(status):判断子进程是否正常退出;ret == pid:确认是目标子进程
if( WIFEXITED(status) && ret == pid ){
printf("wait child 5s success, child return code is :%d.\n",WEXITSTATUS(status));
}else{
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
运⾏结果:
[root@localhost linux]# ./a.out
child is run, pid is : 45110
this is test for wait
wait child 5s success, child return code is :1.传入 exit(257) 时,系统会对数值做 模 256 运算(即取低 8 位):257 % 256 = 1,所以 WEXITSTATUS(status) 解析出的结果就是 1
进程的非阻塞等待方式:
bash
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <vector>
// 函数指针类型定义
typedef void (*handler_t)();
// 函数指针数组(使用std命名空间,避免编译错误)
std::vector<handler_t> handlers;
// 临时任务1
void fun_one() {
printf("这是⼀个临时任务1\n");
}
// 临时任务2
void fun_two() {
printf("这是⼀个临时任务2\n");
}
// 注册任务到数组中
void Load() {
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
// 执行所有注册的临时任务
void handler() {
// 首次调用时加载任务,后续无需重复加载
if (handlers.empty()) {
Load();
}
// 遍历执行所有任务
for (auto iter : handlers) {
iter();
}
}
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) { // 子进程逻辑
printf("child is run, pid is : %d\n", getpid());
sleep(5); // 子进程睡眠5秒模拟业务
exit(1); // 子进程退出,退出码1
} else { // 父进程逻辑
int status = 0;
pid_t ret = 0;
// 非阻塞轮询等待子进程退出
do {
// WNOHANG:非阻塞,子进程运行时返回0,退出时返回子进程PID
ret = waitpid(-1, &status, WNOHANG);
if (ret == 0) {
printf("child is running\n");
// 执行临时任务
handler();
// 关键:添加1秒休眠,避免CPU空转
sleep(1);
}
} while (ret == 0); // 子进程未退出则继续轮询
// 检查子进程是否正常退出,且等待的是目标子进程
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is :%d.\n",
WEXITSTATUS(status));
} else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}二 进程程序替换
fork() 之后,父子进程各自执行父进程代码的一部分。如果子进程想执行一个全新的程序,就需要通过进程的程序替换来完成这个功能!
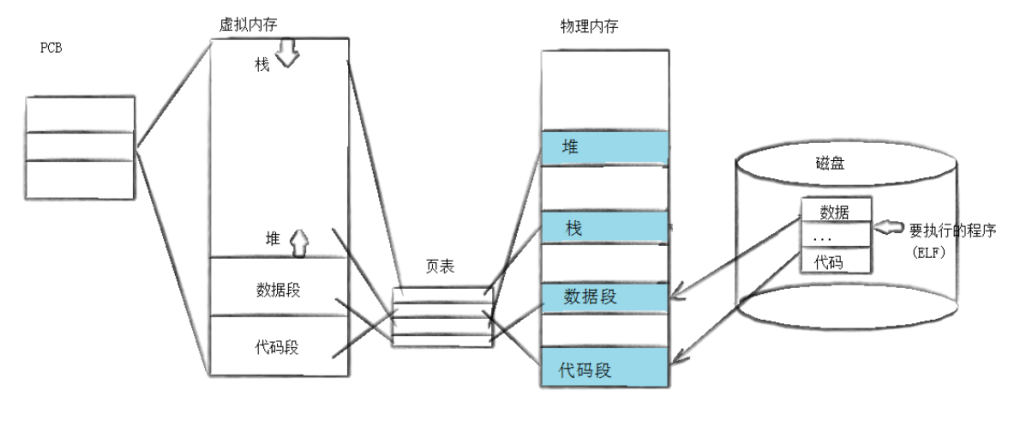
程序替换是通过特定的接口,加载磁盘上的一个全新的程序(代码和数据),并将其加载到调用进程的地址空间中!
1 理解
进程程序替换就是让程序执行一个全新的程序,把当前程序的代码和数据段,用新程序的代码和数据段替换掉。修改页表,改页表的映射关系,之后让原来进程的PCB,从新进程的main函数从0开始运行
相当于用了原来进程的壳,换了代码和数据,这个工作就叫做程序替换
程序替换不会创建新进程,它的目标是让进程执行一个全新的代码
我们通过一段代码来理解一下:
bash
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 printf("我是父进程: pid: %d,ppid: %d\n",getpid(),getppid());
7 execl("/usr/bin/ls","ls","-a","-l",NULL);
8 printf("我正常退出了...\n");
9 return 0;
10 }运行结果为:
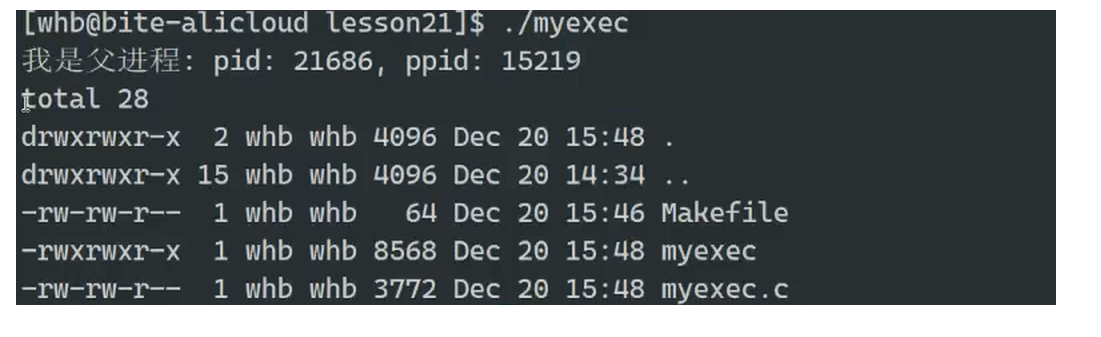
execl是替换函数,如果execl使用成功,那么就不会执行execl之后的所有代码,我们上面的运行结果也证明了这一点
创建一个进程,是先创建内核数据结构,还是先加载具体程序的代码和数据?
先创建内核数据结构
可以把进程理解为 "运行中的程序",创建进程的过程就像 "开一家新店":
先建壳(创建内核数据结构):先去工商局注册(创建进程内核结构体)、租店面(分配 PID、内存空间、CPU 调度资源等)------ 这一步完成后,"进程" 这个 "空架子" 已经存在,但还没有具体的业务(程序代码);
再填内容(加载代码和数据):等店面 / 资质都搞定了,再把商品、设备、员工(程序的代码和数据)搬进去 ------ 这一步完成后,进程才真正具备执行逻辑。
用子进程进行程序替换,不会影响父进程
一旦程序替换成功,就会执行新程序的代码,原来的代码就会被直接覆盖,不会被执行
程序替换成功没有返回值,只有失败才会有返回值
2 替换原理
用 fork 创建子进程后,子进程执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种 exec 函数以执行另一个程序。
当进程调用一种 exec 函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。
调用 exec 并不创建新进程,所以调用 exec 前后该进程的 ID 并未改变
3 父子进程版本

4 替换函数
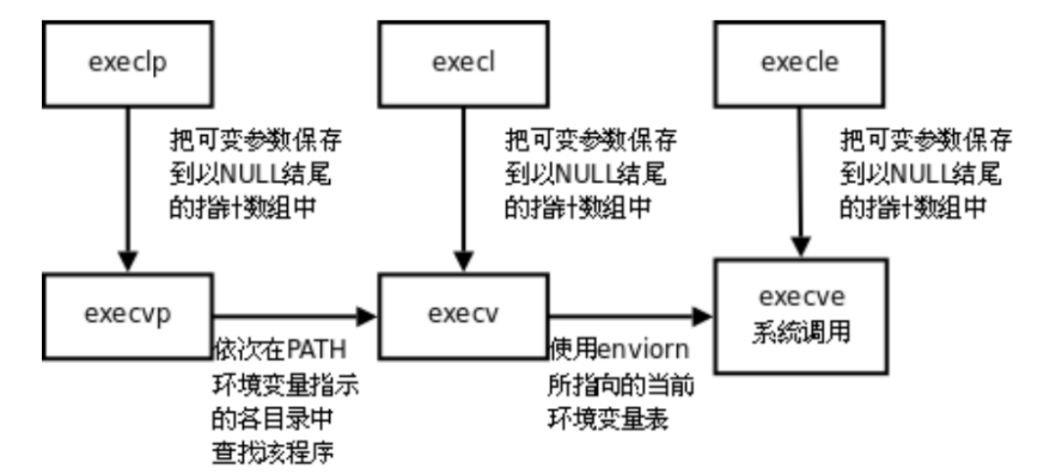
其实有六种以exec开头的函数,统称exec函数:
cs
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);要执行一个程序,需要做什么?
1 找到对应二进制文件的磁盘位置
2 执行程序需要什么选项,要怎么执行
对execl函数参数的解释:
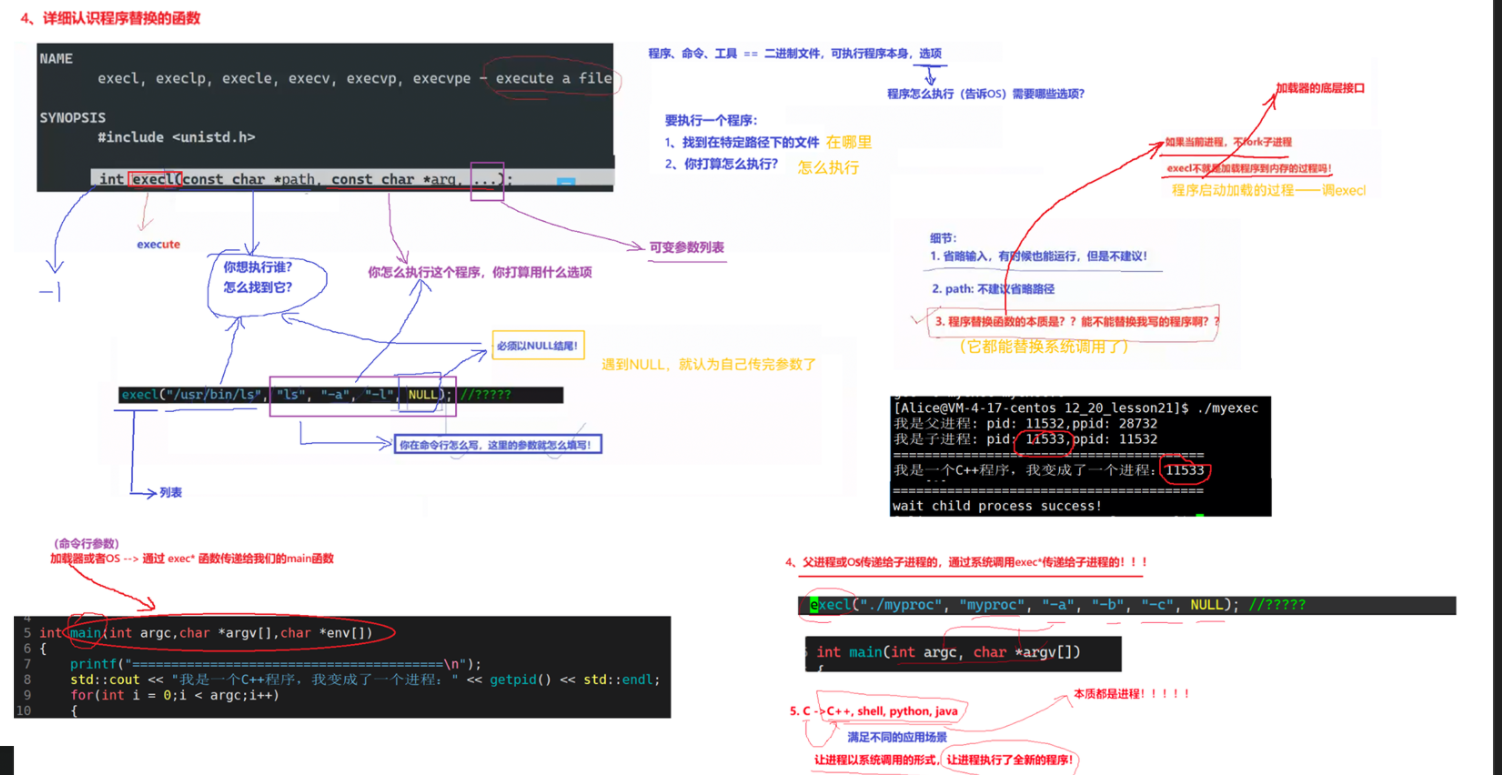
几个细节:
1 省略输入,有时候也能运行,但是不建议这么做
2 execl的path参数:不建议省略路径
3 程序替换的本质:如果当前进程不fork子进程,execl不就是加载程序到内存的过程,所以execl是加载器的底层接口
程序替换能替换系统命令,也能替换自己写的程序
4 命令行参数通过父进程或者操作系统传递给子进程的,通过exec传递给子进程
5 c程序替换,能把C++调用起来,那能调用shell脚本,python,Java吗?
任何程序,只要能跑起来,就是进程,只要是进程,c/c++就能把它跑起来,和是什么语言无关
命名解释:
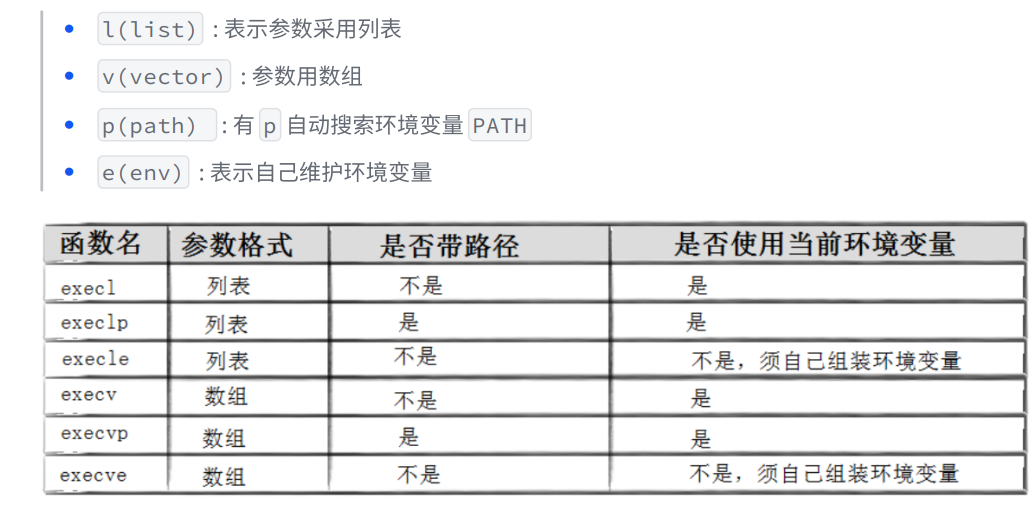
| 函数名 | 参数传递方式 | 是否自动搜索 PATH | 环境变量处理方式 | 核心特点 |
|---|---|---|---|---|
| execl | 列表(l) | ❌ 不搜索(必须传完整路径) | ✅ 继承当前环境变量 | 固定参数列表、需完整路径 |
| execlp | 列表(l) | ✅ 搜索 PATH(可传文件名) | ✅ 继承当前环境变量 | 固定参数列表、自动找路径 |
| execle | 列表(l) | ❌ 不搜索(必须传完整路径) | ❌ 自定义环境变量(需自己传) | 固定参数列表、自定义环境 |
| execv | 数组(v) | ❌ 不搜索(必须传完整路径) | ✅ 继承当前环境变量 | 动态参数数组、需完整路径 |
| execvp | 数组(v) | ✅ 搜索 PATH(可传文件名) | ✅ 继承当前环境变量 | 动态参数数组、自动找路径 |
| execve | 数组(v) | ❌ 不搜索(必须传完整路径) | ❌ 自定义环境变量(需自己传) | 系统调用底层实现,动态参数数组、自定义环境 |
v表示vector,p表示PATH,l表示列表,表示参数用列表传递
如果不想使用默认的环境变量,想搭建全新的变量,可以使用带'e'的环境变量
进行程序替换的时候,即便我们没有显式传递环境变量表信息,但是子进程依旧能够获得对应的环境变量信息。
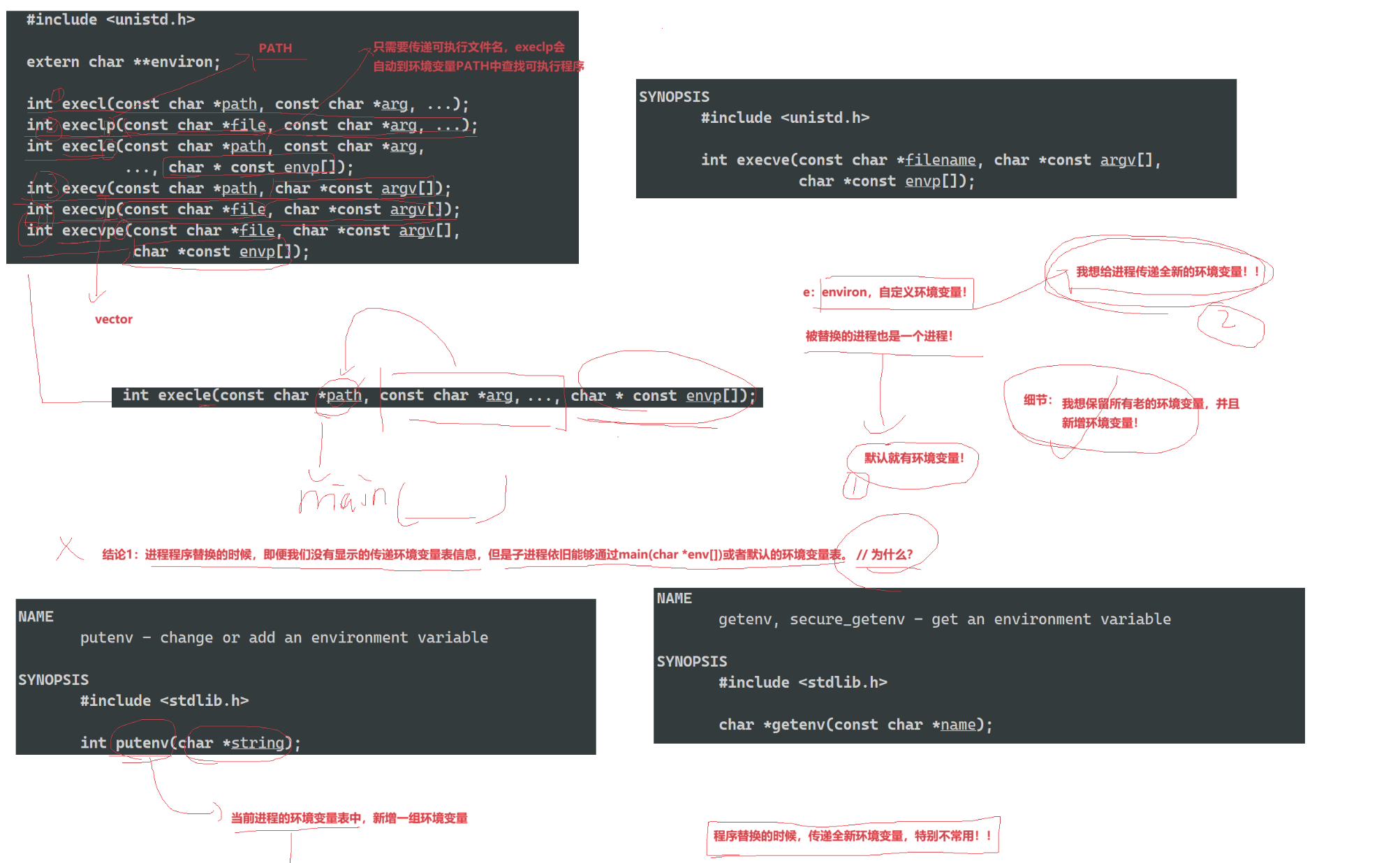
环境变量表也以NULL结尾
exec调用举例如下:
cs#include <unistd.h> int main() { char *const argv[] = {"ps", "-ef", NULL}; char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL}; execl("/bin/ps", "ps", "-ef", NULL); // 带p的,可以使⽤环境变量PATH,⽆需写全路径 execlp("ps", "ps", "-ef", NULL); // 带e的,需要⾃⼰组装环境变量 execle("ps", "ps", "-ef", NULL, envp); execv("/bin/ps", argv); // 带p的,可以使⽤环境变量PATH,⽆需写全路径 execvp("ps", argv); // 带e的,需要⾃⼰组装环境变量 execve("/bin/ps", argv, envp); exit(0); }
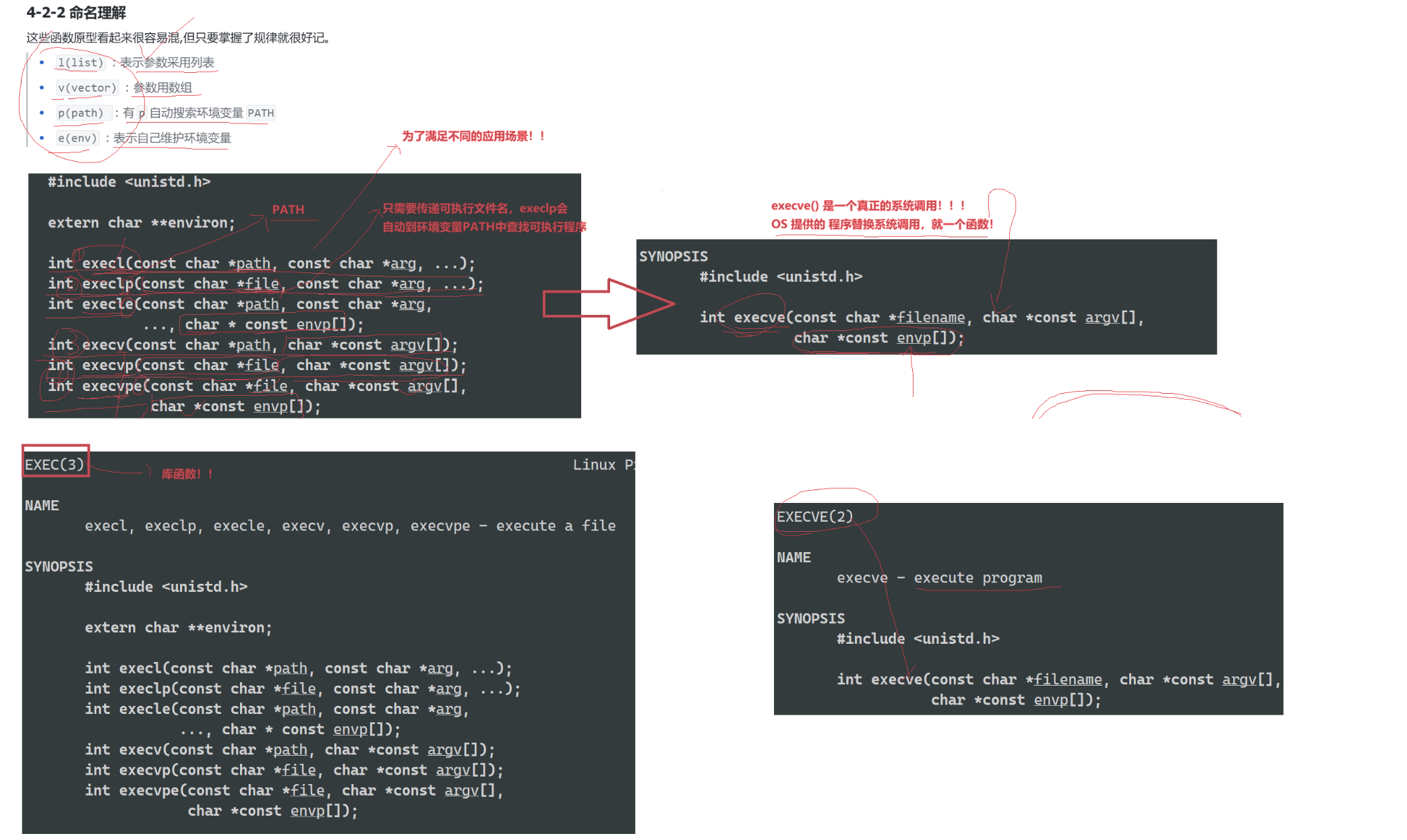
事实上,只有 execve 是真正的系统调用,其它五个函数最终都调用 execve,所以 execve 在 man 手册第 2 节,其它函数在 man 手册第 3 节。这些函数之间的关系如下图所示。
下图为 exec 函数簇一个完整的例子: