前言
人工智能浪潮正以前所未有的速度重塑全球产业格局。在这场技术革命的底层,神经网络处理器(Neural Processing Unit,NPU)扮演着极为关键的角色。从智能手机中每日无声处理亿万次推理请求的端侧芯片,到为超大规模语言模型训练提供算力支撑的数据中心加速卡,NPU已经成为数字经济时代最重要的基础设施之一。

从技术背景、基本原理、发展脉络、核心性能指标、体系结构设计、重要里程碑以及与大型语言模型的深度协同等七个维度,对NPU进行系统性、全景式的分析。力求兼顾学术严谨性与工程实用性。
第一章 背景:NPU 诞生的驱动力
1.1 通用计算架构的困境
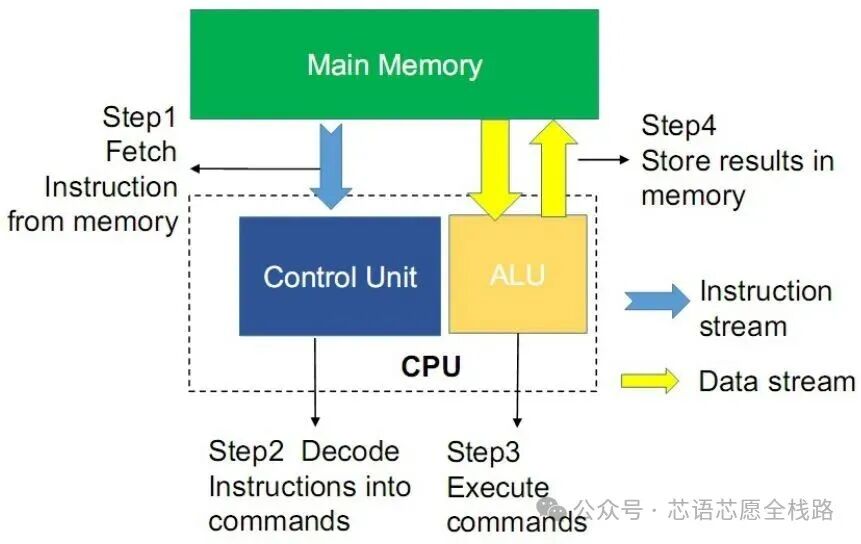
现代计算机体系结构发展六十余年,冯·诺依曼架构以其通用性和灵活性统治了绝大多数计算领域。然而,以CPU为代表的通用处理器在应对深度学习工作负载时面临严峻挑战。深度神经网络的训练与推理过程本质上是大规模矩阵乘法、卷积运算和激活函数的组合,这些操作具有高度规则性、极强的数据并行性,但对通用CPU的利用效率极低。
典型的深度学习模型推理过程中,矩阵乘法占据了80%至90%的计算量,而CPU的流水线设计、分支预测、乱序执行等机制对矩阵运算几乎没有加速效果,大量晶体管资源被用于控制逻辑而非计算单元。以Intel Xeon系列服务器CPU为例,其FP32峰值算力通常在1至2 TFLOPS区间,而同代NVIDIA数据中心GPU则可达到数十至数百TFLOPS,差距高达两个数量级。
https://picture.iczhiku.com/weixin/message1583992285873.html
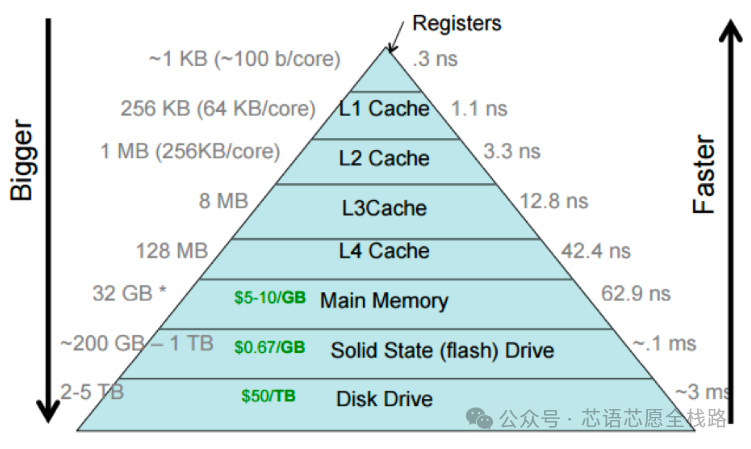
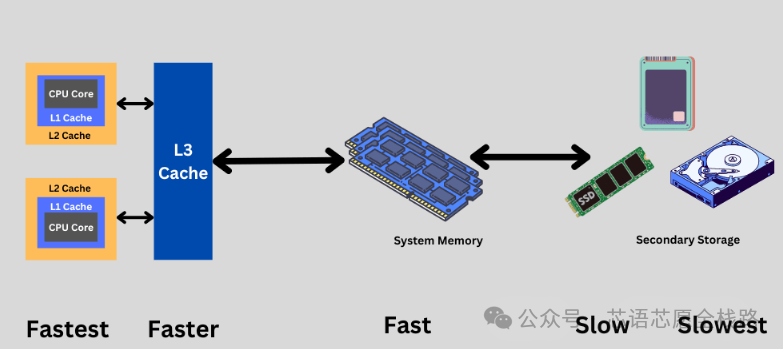
内存带宽瓶颈是另一个核心困境。CPU架构的内存层次结构(L1/L2/L3 Cache → DRAM)针对随机访问和程序局部性优化,而神经网络推理需要将大量权重参数从主存载入计算单元,访存模式更接近流式访问。神经网络模型规模的持续膨胀使"内存墙"问题日趋严重:GPT-3拥有1750亿参数,以FP16精度存储需约350GB内存;最新一代超大模型(如GPT-4o、Gemini Ultra)规模更大,推理时的内存带宽需求远超通用CPU/GPU体系所能提供的极限。
https://www.alibabacloud.com/blog/the-mechanism-behind-measuring-cache-access-latency_599384
https://storedbits.com/cpu-cache-l1-l2-l3/
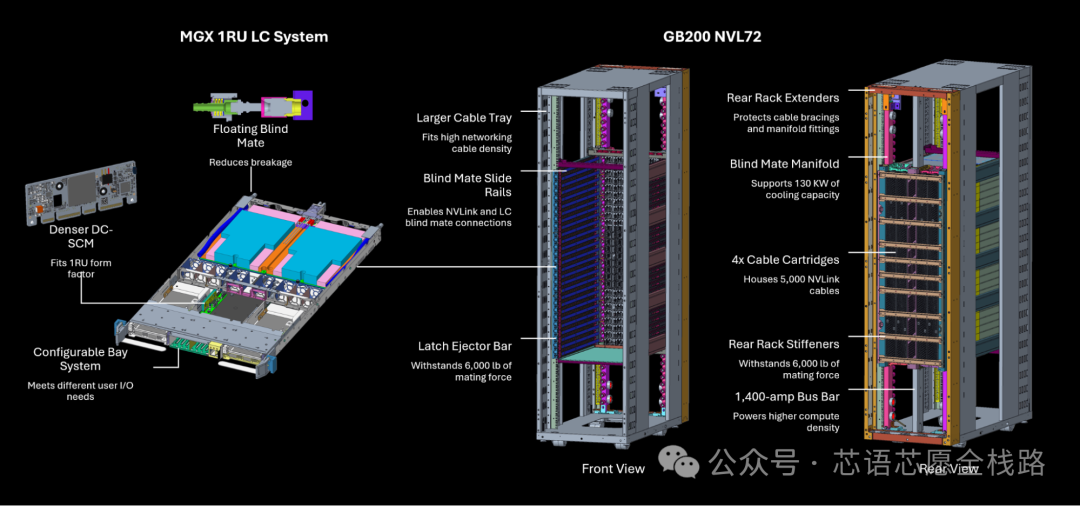
功耗效率是第三维度的挑战。数据中心能耗已成为全球重要的碳排放来源之一,尤其是2025年以来,NVIDIA Blackwell系列单卡TDP高达700---1000W,大规模集群(如GB200 NVL72系统72卡合计功耗超140kW)已超出传统数据中心散热设计的极限,液冷成为必要基础设施。
1.2 从 GPU 到专用 NPU 的演进逻辑
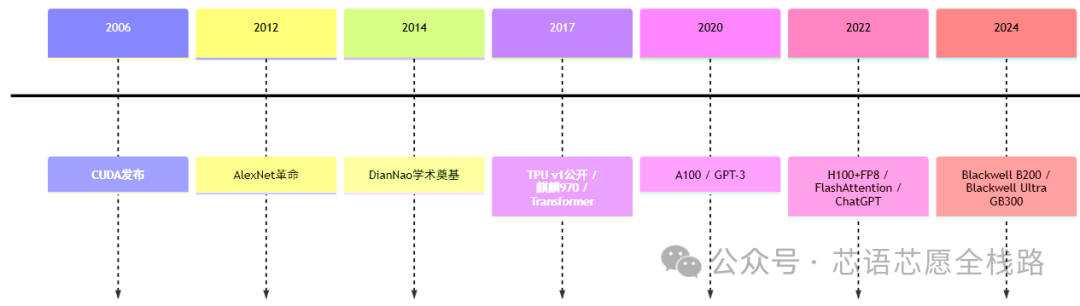
GPU因其数千个简单并行计算核心,成为深度学习加速的第一选择。NVIDIA于2006年推出CUDA并行计算平台,使GPU从图形专用硬件演变为通用并行计算平台(GPGPU),深度学习社区随即将训练任务大规模迁移至GPU。2012年,AlexNet在ImageNet竞赛上的突破性表现,正是依托两块GTX 580 GPU实现的。
https://viso.ai/deep-learning/alexnet/
专用NPU的价值逻辑由此清晰:通过面向神经网络计算的定制化架构设计,在算力/功耗/面积(PPA)三维度实现对通用处理器的全面超越。值得注意的是,到2025---2026年,"NPU"与"AI GPU"之间的界限已日益模糊------NVIDIA的Blackwell、Rubin系列虽名为GPU,实质上已是深度面向Transformer与MoE架构优化的专用加速器,其通用图形渲染能力已退居次要地位。
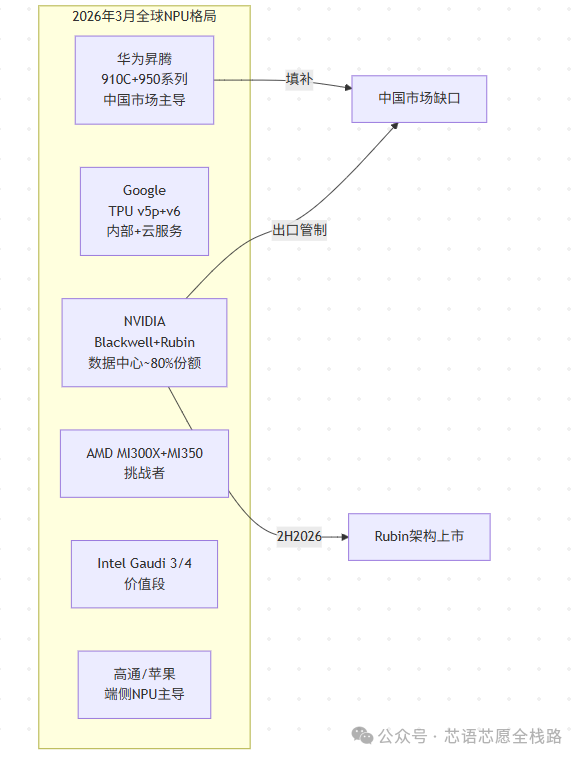
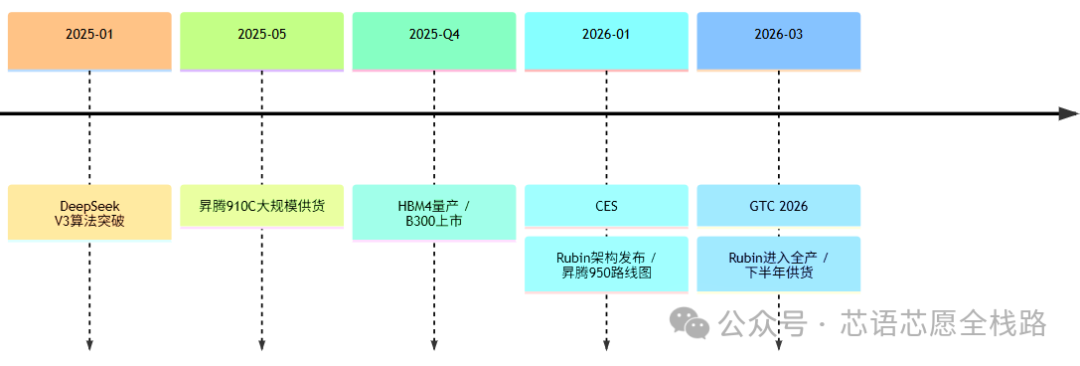
1.3 全球产业竞争格局(更新至2026年3月)
截至2026年3月,NVIDIA以Blackwell系列(B200/B300/GB200 NVL72)牢牢占据全球数据中心AI芯片市场约80%份额,Blackwell芯片订单积压360万颗(截至2025年12月),已售罄至2026年中。NVIDIA于2026年1月CES发布下一代Vera Rubin架构(7款新芯片),2026年下半年开始向AWS、Google Cloud、Microsoft Azure供货,并于2026年3月GTC 2026大会进一步宣布Rubin平台已进入全面生产。

https://benchlife.info/nvidia-intro-more-vera-rubin-platform-details/
华为昇腾于2025年5月起大规模供货910C,2026年产量目标约60万颗(同比翻倍),并在华为Connect 2025大会披露昇腾950系列路线图(950PR:Q1 2026,1 PFLOPS FP8;950DT:Q4 2026,4TB/s HBM带宽),以及昇腾960(2027年)和970(2028年)的远期规划,目标在2028年通过百万卡集群实现1 ZettaFLOPS计算能力。
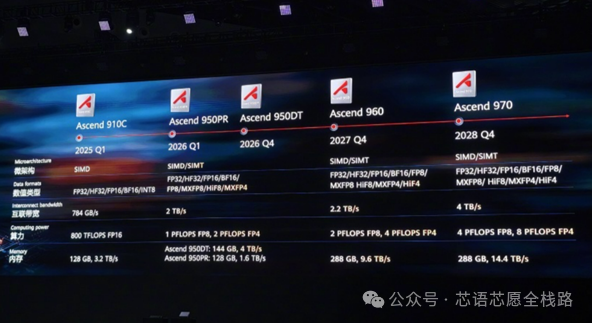
https://www.eet-china.com/mp/a439260.html
端侧NPU竞争同样激烈。CES 2026上,Intel发布Panther Lake(Core Ultra Series 3),集成50 TOPS NPU,预计驱动200款以上OEM笔记本产品;高通发布Snapdragon X2 Plus,NPU达80 TOPS;AMD Ryzen AI 400("Gorgon Point")作为对标产品同期发布,进一步拉低AI PC的算力基线。Ceva-NeuPro-Nano NPU在2026 embedded world大会斩获AI类最佳创新奖,体现了边缘端NPU生态的持续成熟。
第二章 技术原理:NPU 的计算基础
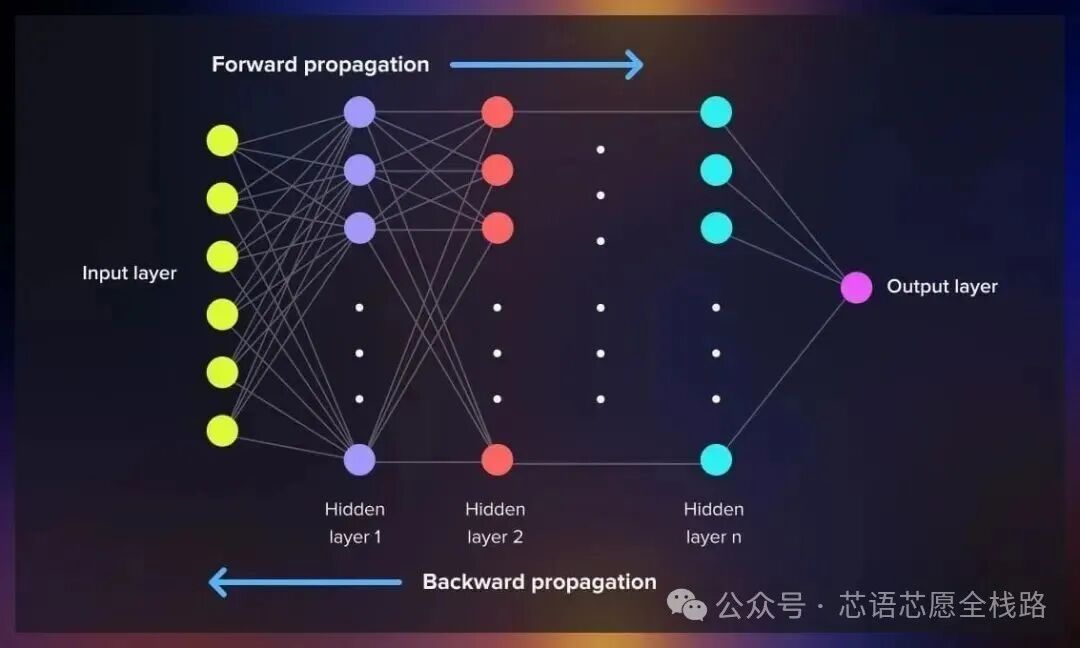
2.1 神经网络计算的数学本质
深度神经网络的前向传播本质上是一系列线性变换与非线性激活的复合。最基础的全连接层计算为 Y = W·X + b,其中 W 为权重矩阵,X 为输入特征向量,b为偏置向量,运算核心是通用矩阵乘法(GEMM,General Matrix Multiply)。统计表明,大型神经网络超过85%的计算量源于矩阵乘法,这是NPU设计专注于矩阵运算加速的根本依据。
https://developer.aliyun.com/article/1650427
https://www.anmou.me/20170813-Forward_Propagation_and_Backpropagation_in_Neural_Networks/
反向传播(训练阶段)进一步增加了计算量:每个参数的梯度计算涉及与前向传播对称的矩阵运算,训练时计算量约为推理的2---3倍。大规模模型训练还需要混合精度(AMP)策略:前向/反向传播使用FP16/BF16,参数更新使用FP32主拷贝,以在保持数值稳定性的同时提升吞吐量。至2025---2026年,FP8甚至FP4精度训练已从研究走向产业实践,NVIDIA Blackwell Ultra的Transformer Engine已支持NVFP4精度。
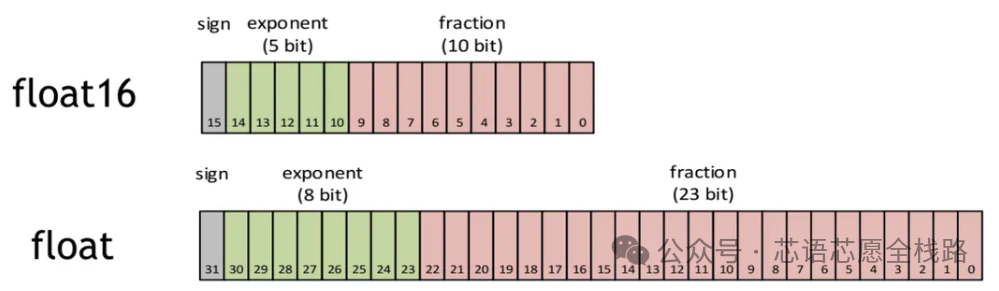
https://developer.aliyun.com/article/1081448
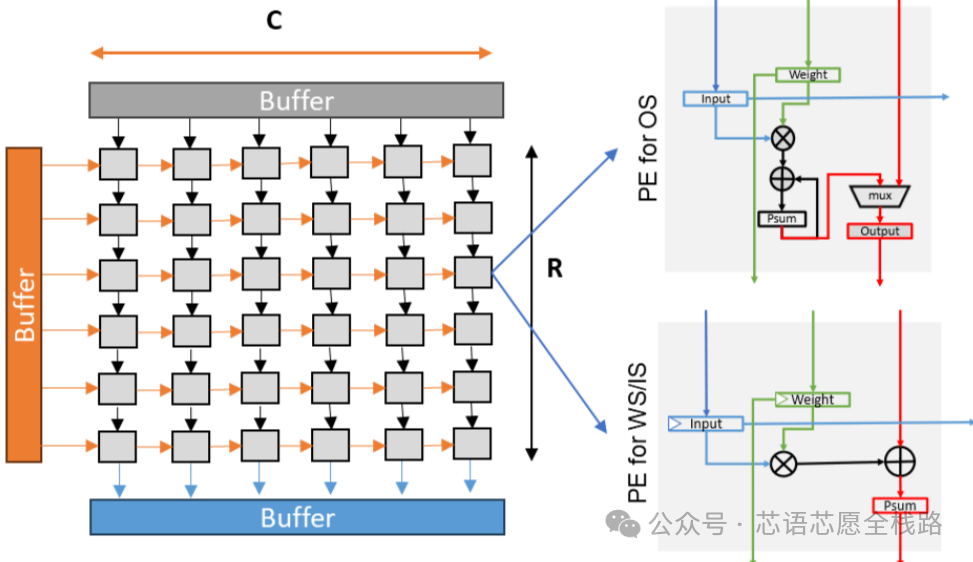
2.2 脉动阵列与 Tensor Core:两种主流加速引擎
脉动阵列(Systolic Array)是谷歌TPU采用的经典矩阵乘法加速结构,数据在PE阵列间按节拍脉冲式传播,每个PE在接收数据后完成乘加(MAC)运算并传递结果。谷歌TPU v1的256×256 INT8脉动阵列每周期可完成65536次MAC运算,奠定了专用NPU的设计范式。
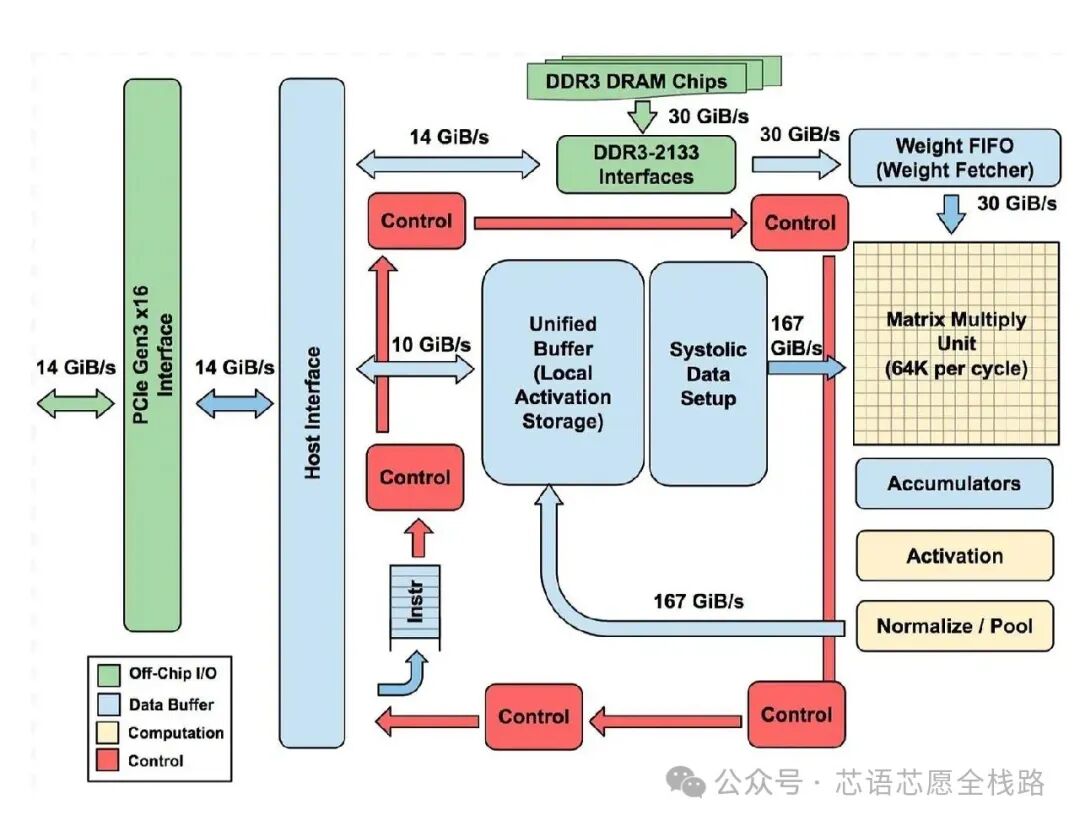
https://thechipletter.substack.com/p/googles-first-tpu-architecture
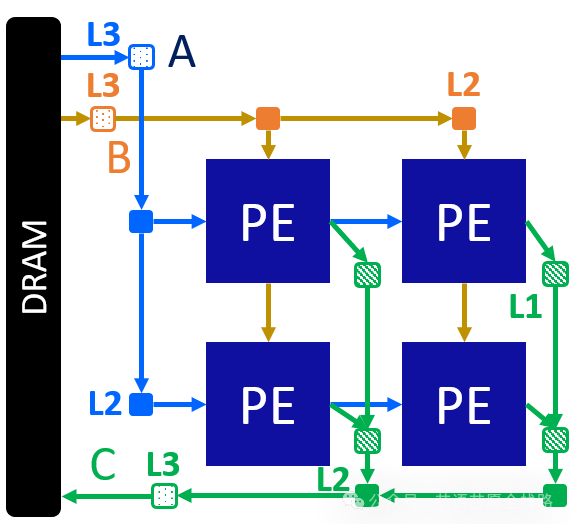
https://autosa.readthedocs.io/en/latest/tutorials/matrix_multiplication.html
Tensor Core是NVIDIA在Volta架构(V100,2017年)中引入的混合精度矩阵乘法加速单元,经历了五代演进:第一代支持FP16→FP32累加;第二代(A100)引入BF16/TF32;第三代(A100)增加INT8/INT4;第四代(H100)支持FP8 E4M3/E5M2,引入Transformer Engine;第五代(Blackwell)支持NVFP4及微张量缩放(Micro-Tensor Scaling),至Blackwell Ultra已达15 PFLOPS NVFP4算力。
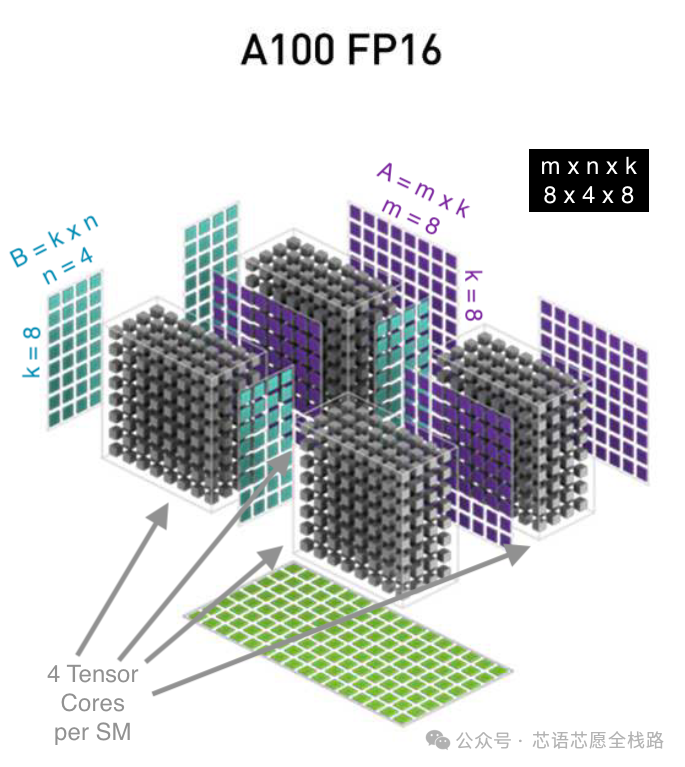
https://www.glennklockwood.com/garden/tensor-cores
华为昇腾达芬奇架构的Cube Engine在单个时钟周期内完成16×16×16的三维矩阵乘法(4096次MAC/cycle),是脉动阵列理念的立体延伸,对卷积和矩阵乘法均有深度优化。
2.3 数值精度演进:从 BF16 到 NVFP4
| 精度格式 | 位宽 | 典型用途 | 代表产品支持 | 相对BF16算力 |
|---|---|---|---|---|
| FP32 | 32位 | 参数主拷贝存储 | 全部产品 | 1×基准 |
| BF16 | 16位 | 训练前/反向传播主流 | A100/H100/B200/昇腾 | 16× |
| FP16 | 16位 | 训练/推理通用 | 全部产品 | 16× |
| TF32 | 19位 | NVIDIA训练加速 | A100/H100/B200 | 8× |
| FP8 E4M3/E5M2 | 8位 | 训练推理(H100+) | H100/B200/B300/昇腾950 | 32× |
| NVFP4 | 4位 | Blackwell Ultra推理 | GB300/Rubin | 64× |
| INT8 | 8位 | 推理量化主流 | 全部产品 | 32× |
| INT4 | 4位 | 端侧极致压缩 | 高通/苹果/联发科 | ~64× |
2.4 存储层次与数据流优化
内存访问效率是NPU性能的决定性因素之一。根据Roofline模型,芯片的实际可达算力取决于峰值算力(Compute Bound)和内存带宽(Memory Bound)两个约束。计算密度(Arithmetic Intensity,FLOP/Byte)决定了工作负载落在哪个约束区间。
HBM(High Bandwidth Memory)技术代际演进是NPU内存瓶颈改善的主要路径。2024年的H200搭载HBM3e,带宽达4.8TB/s;2025年的Blackwell B200搭载HBM3e,带宽8TB/s;预计2026年的Rubin架构将搭载HBM4,带宽达22TB/s。SK海力士于2025年Q4开始量产HBM4,三星与NVIDIA的HBM4供应合同谈判亦在2025年底进入尾声。HBM4单栈带宽相比HBM3e提升约2.75倍,是Rubin架构内存性能跃升的核心支撑。

2.5 稀疏计算、MoE 与 Adaptive Compression
NVIDIA在A100中引入的2:4结构化稀疏性(每4个连续权重中有2个非零)在H100/B200上得到延续,理论提供2倍稀疏算力。Blackwell Ultra引入的微张量缩放(Micro-Tensor Scaling,MTS)技术进一步优化了NVFP4精度下的量化误差,使模型在4位精度下保持高准确率。
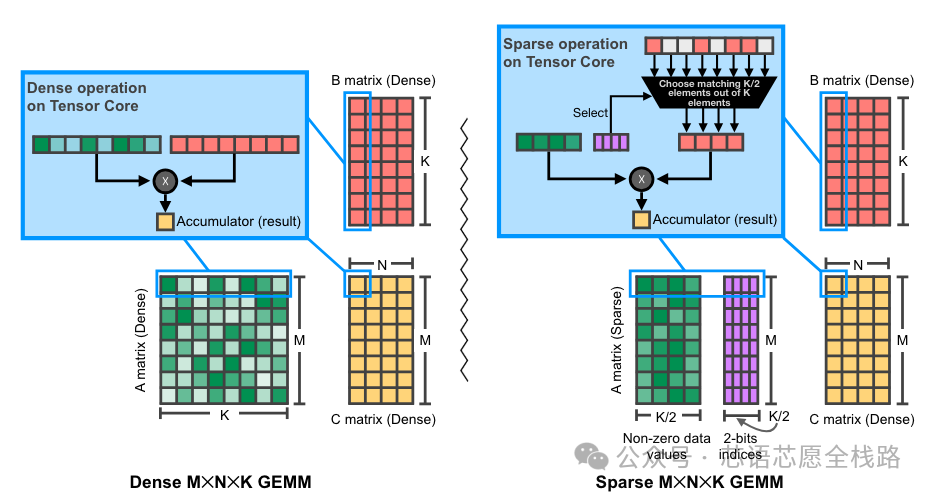
https://pytorch.ac.cn/blog/accelerating-neural-network-training/
MoE(专家混合)架构在2025---2026年已成为主流大模型范式:DeepSeek-V3(671B总参/37B激活)、Mixtral 8×22B、Qwen2.5-72B-MoE等均采用MoE设计。NVIDIA Rubin架构针对MoE训练进行了深度优化,宣称相比Blackwell可将训练同等MoE所需的GPU数量减少4倍,推理token成本降低10倍,体现了硬件与MoE算法协同设计的深远价值。
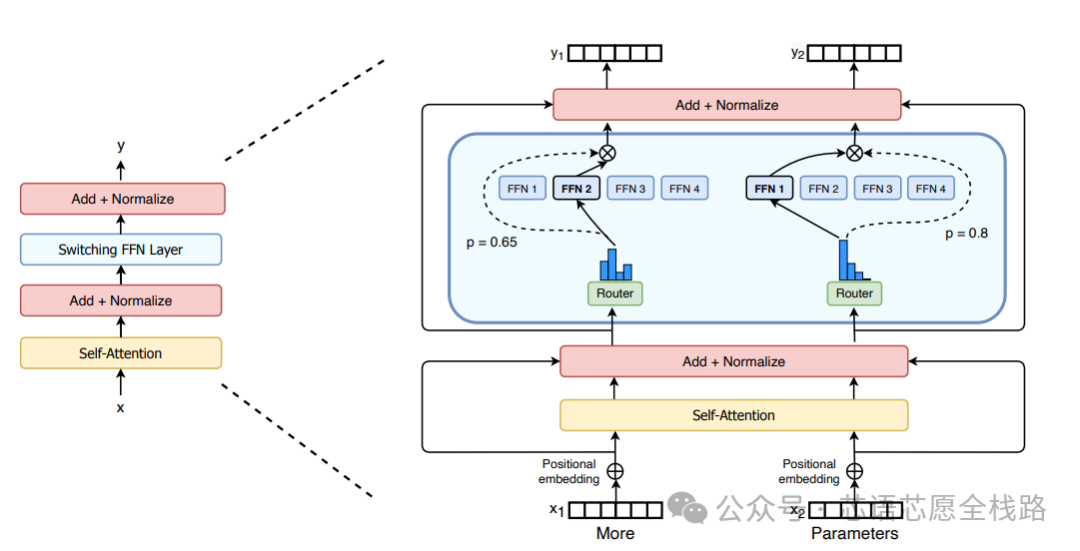
https://huggingface.co/blog/zh/moe
第三章 发展历程:NPU 的演进轨迹
3.1 萌芽期(2006---2015年)
2006年,NVIDIA发布CUDA,开创GPU通用计算新时代。2009年,吴恩达团队将GPU用于深度学习训练。2012年,AlexNet以两块GTX 580 GPU在ImageNet上将Top-5错误率从26%降至15.3%,标志着深度学习GPU加速时代的开幕。2014年,陈云霁团队发表DianNao系列论文,奠定NPU学术研究基础。谷歌TPU v1于2015年内部部署,2017年公开发表。
3.2 起飞期(2016---2020年)
2017年是NPU历史的分水岭之年:华为麒麟970首次集成寒武纪1A NPU商用,苹果A11 Bionic发布Neural Engine,Vaswani等人提出Transformer架构。2018---2019年,移动端NPU集成进入标准化阶段:高通骁龙845、联发科Helio P70、三星Exynos系列均引入NPU。2019年华为发布昇腾910,2020年NVIDIA A100发布,GPT-3以1750亿参数宣告LLM时代来临。
3.3 爆发期(2021---2023年)
2022年11月ChatGPT发布引发全球AI革命,NVIDIA H100随即供不应求,2023年NVIDIA市值突破万亿美元。Flash Attention(2022年)成为LLM效率提升的里程碑算法,FP8精度训练随H100进入产业实践。华为昇腾910B在美国出口管制压力下大规模国产替代,中国AI芯片产业快速发展。
3.4 深化期(2024年)
2024年3月,NVIDIA在GTC 2024发布Blackwell架构(B100/B200),两颗裸片通过10TB/s NVLink-C2C互联组成逻辑GPU,FP8算力峰值达9 PFLOPS,HBM3e容量192GB。同年8月,Blackwell Ultra(GB300)发布,NVFP4算力达15 PFLOPS,Rubin架构同步规划披露(2026年),Feynman架构作为后续代际亦进入规划视野。
3.5 规模化与国产化期(2025年---2026年3月)
2025年2月,NVIDIA Blackwell B200开始全面量产出货,Supermicro等OEM伙伴进入大规模部署阶段。5月,华为昇腾910C大规模供货,产能爬坡至全年约30万颗,2026年目标翻倍至60万颗。全年Blackwell积压订单约360万颗,已售罄至2026年中,体现了AI算力需求的极端旺盛。
2025年下半年,HBM4进入SK海力士量产阶段;AMD MI300X大批量供货;Intel Gaudi 3在欧洲和亚太市场取得一定份额;Groq LPU以极低延迟推理服务吸引特定客户群体。DeepSeek于2025年1月发布V3/R1,以不到600万美元的训练成本、2048块昇腾910B(或等效算力),实现接近GPT-4水平,引发全球对"以算法效率降低算力依赖"路径的重新审视。
2026年1月,NVIDIA在CES 2026发布Vera Rubin平台(7款新芯片),核心Rubin GPU基于TSMC 3nm工艺(N3P),采用双裸片设计(共336亿晶体管),配备HBM4(22TB/s带宽),第六代NVLink(3.6TB/s per GPU),NVL144 CPX系统达8 ExaFLOPS。2026年3月,GTC 2026披露Rubin正式进入全产及供货计划,AWS、Google Cloud、Microsoft、OCI将在2026年下半年率先部署。华为昇腾950PR(2026年Q1)随同公布,FP8算力1 PFLOPS,标志国产NPU继续攀升。
待续。。。
