AI-Infra双轨战略:承托当下GPU算力,布局未来CPU替代
一、战略原点:从"去IOE"到"去英伟达",历史押着相同的韵脚
十年前,企业数字化转型的核心战役是"去IOE"------摆脱IBM小型机、Oracle数据库、EMC存储的封闭捆绑,用x86服务器、开源数据库、分布式存储重构技术底座。这场运动不仅降低了80%以上的IT成本,更关键的是让企业真正掌握了技术自主权。

今天,企业智能化转型正站在同样的十字路口。AI算力高度集中于英伟达GPU生态,推理成本居高不下,供应链风险日益加剧。历史告诉我们:每一次技术垄断的终点,都是架构重构的起点。
我们的判断是:AI-Infra的未来,不是"唯GPU论",而是"场景驱动的多元算力"。
- 当场景需要极致吞吐、千亿参数、多模态推理时,GPU仍是无可替代的选择。
- 但当场景是B2B私有化部署、8B-32B参数级别、专项任务(Embedding/Rerank/Text2SQL)时,CPU具备"够用且更好"的条件。
正是这一判断,构成了我们AI-Infra双轨战略的逻辑起点。
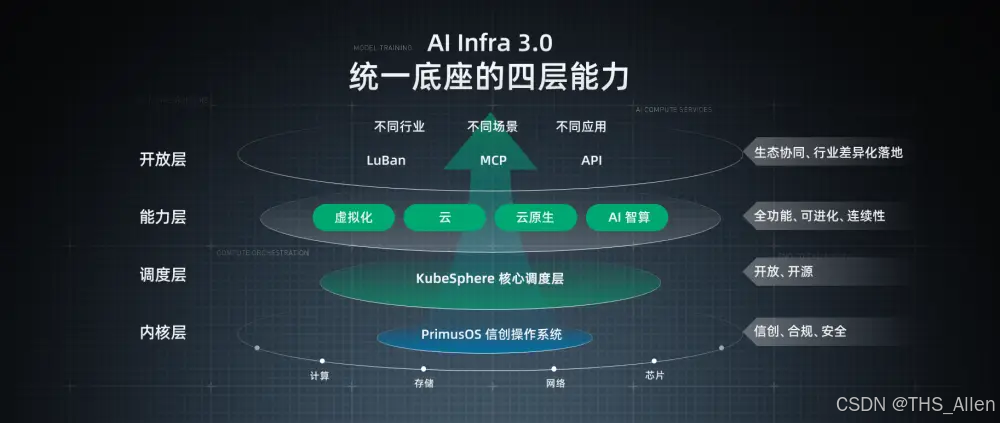
二、双轨架构:一个平台,两种能力
我们构建的AI-Infra平台,核心设计理念是 "双平面"架构:
| 维度 | 算力平面A(GPU) | 算力平面B(CPU) |
|---|---|---|
| 定位 | 服务当下:极致性能,承接高端场景 | 布局未来:降本增效,覆盖长尾场景 |
| 适用模型 | 70B+大模型、多模态、高并发推理 | 8B/32B小模型、Embedding、Rerank、Text2SQL、安全审核 |
| 核心价值 | 毫秒级延迟、万级QPS吞吐 | TCO降低60%-80%、供应链自主可控、私有化部署零门槛 |
| 技术底座 | 英伟达CUDA生态 + 自研推理加速 | Intel AMX / AMD AVX-512 + 自研CPU推理引擎 |
关键点在于:这不是二选一的对立,而是统一调度下的场景适配。 上层业务无需感知底层算力类型,AI-Infra自动根据模型规模、延迟要求、成本预算进行路由分发。
三、CPU平面的技术可行性:为什么现在时机成熟了?
CPU跑模型并非退回到原始时代,而是三重技术红利的叠加:
1. 芯片层的跃迁
Intel第四代至强(Sapphire Rapids)内置AMX加速引擎,直接支持BF16/INT8矩阵运算;AMD EPYC Genoa集成AVX-512指令集。单颗CPU的推理能力已达3年前入门GPU水平,而功耗和成本优势显著。
2. 模型层的小型化
B2B私有化场景中,7B-32B模型正在成为主流。从Embedding、Rerank到Text2SQL,这些专项模型参数量可控、任务边界清晰,天然适合CPU部署。最早的开源模型本就可在CPU上运行,技术基因从未消失。
3. 推理优化层的成熟
通过INT4/INT8量化、算子融合、KV Cache优化、Continuous Batching等技术组合,CPU推理的延迟和吞吐已能追平部分GPU方案的50%-70%------对于大量非实时、批量处理场景,这个"性能减损"完全在可接受范围内。
一句话总结:不是CPU变强了,而是场景变"小"了,模型变"专"了,优化变"精"了。三股力量交汇,CPU推理的拐点已至。

四、演进路径:四步走,从"能用"到"敢用"到"好用"
| 阶段 | 目标 | 关键动作 | 里程碑 |
|---|---|---|---|
| Phase 1:点亮 | CPU推理跑通Embedding/Rerank | 搭建Intel AMX + 自研推理引擎原型,支持主流Sentence-Transformer模型,完成延迟/吞吐/精度基准测试 | 性能损耗控制在GPU方案的30%以内 |
| Phase 2:闭环 | 覆盖Text2SQL等业务小模型 | 适配通义千问1.5B/7B、DeepSeek-Coder等模型;构建自动化量化工具链;部署首条"纯CPU链路" | 生产环境端到端可用 |
| Phase 3:延伸 | 扩展到安全审核模型 | 攻克敏感内容检测、数据脱敏等安全模型的CPU推理;建立安全场景的CPU推理基准 | 安全领域形成"CPU优先"默认策略 |
| Phase 4:替代 | 覆盖32B参数级别模型 | 自研CPU推理框架趋近成熟;形成从模型选型→量化→部署→监控的标准化方案 | 面向B2B客户推出"链家CPU推理解决方案" |
五、商业价值:为什么客户会买单?
当我们向B2B客户提出CPU替代方案时,打动他们的不是技术先进性,而是以下账本:
| 对比维度 | GPU方案 | CPU方案(链家方案) |
|---|---|---|
| 硬件成本 | A100/A800单卡10万+ | 利用现有服务器,零增量成本 |
| 供应链风险 | 进口受限,交付周期3-6个月 | x86/ARM供应充足,1-2周到位 |
| 私有化部署门槛 | 需GPU服务器,对机房散热/供电要求高 | 标准服务器即可,利旧率达90% |
| 推理延迟(7B模型) | 50-80ms/token(A100) | 100-150ms/token(Intel AMX) |
| 适用场景 | 实时对话、高并发 | 批量处理、异步任务、内部分析 |
对于大量非"毫秒级敏感"的B2B场景------内部知识库检索、报表查询、文档分析------CPU方案用60%的成本满足了95%的需求。
六、终局思考:布局的定义权
回顾"去IOE"的历程,最初没有人相信x86能替代小型机、开源数据库能替代Oracle。但当技术拐点来临,先行者定义标准、后来者被动跟随。
去英伟达,不是否定GPU的价值,而是为行业提供第二种选择。 我们的AI-Infra平台,就是要成为那个"既能驾驭GPU,也能释放CPU"的双模底座------让客户在不同阶段、不同场景下,都有最优解。
当去英伟达成为行业共识时,我们希望站在的不是"跟随者"的位置,而是"标准定义者"的位置。