目录
[1. 介绍](#1. 介绍)
[2. 相关工作](#2. 相关工作)
[2.1. 图神经网络](#2.1. 图神经网络)
[2.2. 网络嵌入](#2.2. 网络嵌入)
[3. 序言](#3. 序言)
[定义 3.1。](#定义 3.1。)
[定义 3.2。](#定义 3.2。)
[定义 3.3。](#定义 3.3。)
[4. 提议的模型](#4. 提议的模型)
[4.1. 节点级注意力](#4.1. 节点级注意力)
[4.2. 语义级注意力](#4.2. 语义级注意力)
[4.3. 所提出模型的分析](#4.3. 所提出模型的分析)
[5. 实验](#5. 实验)
[5.1. 数据集](#5.1. 数据集)
[5.2. 基线](#5.2. 基线)
[5.3. 实施细节](#5.3. 实施细节)
[5.4. 分类](#5.4. 分类)
[5.5. 聚类](#5.5. 聚类)
[5.6. 分层注意力机制分析](#5.6. 分层注意力机制分析)
[5.7. 可视化](#5.7. 可视化)
[5.8. 参数实验](#5.8. 参数实验)
[6. 结论](#6. 结论)
图神经网络概览:图神经网络分享系列-概览
异构图注意力网络
摘要
图神经网络作为一种基于深度学习的强大图表示技术,表现出了优越的性能并引起了广泛的研究兴趣。 然而,图神经网络尚未充分考虑包含不同类型节点和链接的异构图。 异构图的异构性和丰富的语义信息给设计异构图的图神经网络带来了巨大的挑战。 最近,深度学习最令人兴奋的进展之一是注意力机制,其巨大潜力已在各个领域得到充分展示。 在本文中,我们首先提出了一种基于分层注意力的新型异构图神经网络,包括节点级和语义级注意力。 具体来说,节点级注意力旨在学习节点与其基于元路径的邻居之间的重要性,而语义级注意力能够学习不同元路径的重要性。 通过从节点级和语义级注意力中学习到的重要性,可以充分考虑节点和元路径的重要性。 然后,所提出的模型可以通过以分层方式聚合来自基于元路径的邻居的特征来生成节点嵌入。 对三个现实世界异构图的广泛实验结果不仅显示了我们提出的模型相对于最先进模型的优越性能,而且还证明了其对图分析的潜在良好可解释性。
社交网络、神经网络、图分析
1. 介绍
现实世界的数据通常与图结构结合在一起,例如社交网络、引文网络和万维网。 图神经网络(GNN)作为一种强大的图数据深度表示学习方法,在网络分析方面表现出了优越的性能,并引起了人们的广泛研究兴趣。 例如,(Gori 等人, 2005; Scarselli 等人, 2009; Li 等人, 2016)利用深度神经网络根据节点特征和图结构来学习节点表示。 一些作品(Defferrard等人,2016;Kipf和Welling,2017;Hamilton等人,2017)通过将卷积操作推广到图来提出图卷积网络。 深度学习最近的一个研究趋势是注意力机制,它处理可变大小的数据并鼓励模型关注数据最显着的部分。 它展示了深度神经网络框架的有效性,并广泛应用于各种应用,例如文本分析(Bahdanau等人,2015)、知识图谱(Schlichtkrull等人,2018)和图像处理(Xu等人,2015)。 图注意力网络(GAT)(Veličković等人,2018)是一种新颖的卷积式图神经网络,利用注意力机制来处理仅包含一种类型的节点或链接的同质图。
尽管注意力机制在深度学习中取得了成功,但异构图的图神经网络框架尚未考虑它。 事实上,现实世界的图通常具有多种类型的节点和边,也被广泛称为异构信息网络(HIN)(Shi等人,2017)。 为了方便起见,本文统一将其称为异构图。 由于异构图包含更全面的信息和丰富的语义,因此在许多数据挖掘任务中得到了广泛的应用。 元路径(Sun等人,2011)是连接两个对象的复合关系,是一种广泛使用的捕获语义的结构。 以图1(a)所示的电影数据IMDB1为例,它包含电影、演员和导演三种类型的节点。 两部电影之间的关系可以通过描述合作演员关系的元路径电影-演员-电影(MAM )来揭示,而电影-导演-电影(MDM)意味着它们由同一导演执导。 可以看出,根据元路径,异构图中的节点之间的关系可以具有不同的语义。 由于异构图的复杂性,传统的图神经网络无法直接应用于异构图。
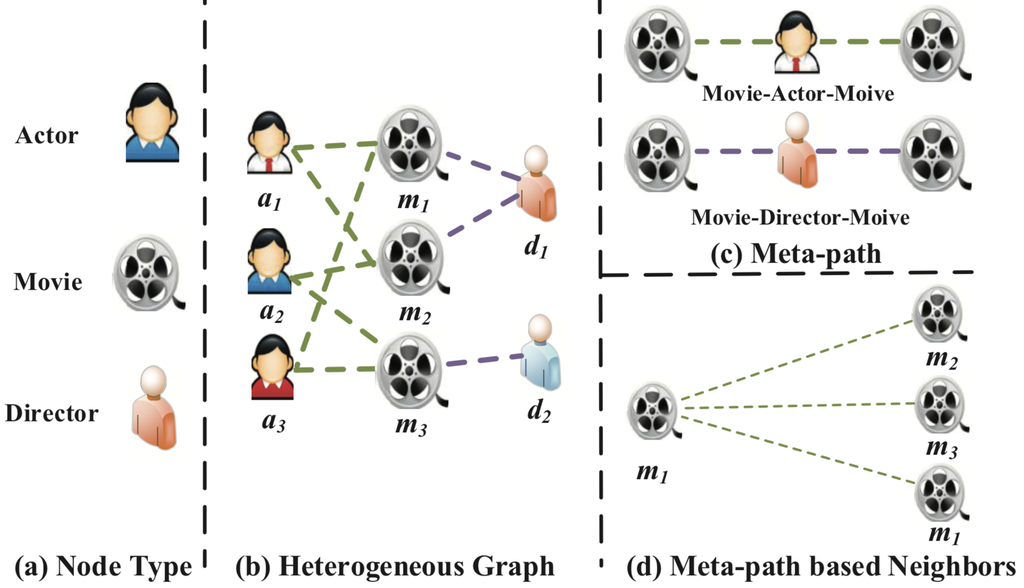
图 1. 异构图 (IMDB) 的说明性示例。 (a) 三种类型的节点(即演员、电影、导演)。 (b) 异构图 IMDB 由三种类型的节点和两种类型的连接组成。 (c) IMDB 中涉及的两个元路径(即电影-演员-电影和电影-导演-电影)。 (d) Moive m1 及其基于元路径的邻居(即 m1、m2 和 m3)。
基于上述分析,在针对异构图设计具有注意力机制的图神经网络架构时,我们需要解决以下新的需求。
图的异质性。 异构性是异构图的固有属性,即各种类型的节点和边。 例如,不同类型的节点具有不同的特征,它们的特征可能落在不同的特征空间中。 仍以IMDB为例,演员的特征可能涉及性别、年龄和国籍。 另一方面,电影的特色可能涉及到情节和演员。 如何处理如此复杂的结构信息并同时保存多样化的特征信息是一个迫切需要解决的问题。
语义级别的注意力。 异构图涉及不同的有意义且复杂的语义信息,这些信息通常通过元路径(Sun等人,2011)来体现。 异构图中的不同元路径可以提取不同的语义信息。 如何选择最有意义的元路径并融合特定任务的语义信息是一个悬而未决的问题(Li等人,2017;Chen和Sun,2017;Shang等人,2016)。 语义级注意力旨在了解每个元路径的重要性并为其分配适当的权重。 以IMDB为例,《终结者》可以通过"电影-演员-电影"路径(均由施瓦辛格主演)连接到《终结者2》,或通过"电影-年份-电影"路径(均拍摄于1984年)连接到《鸟人》。然而,在识别电影终结者 的类型时,MAM 通常比MYM扮演更重要的角色。 因此,同等对待不同的元路径是不切实际的,并且会削弱一些有用的元路径提供的语义信息。
节点级注意力。 在异构图中,节点可以通过各种类型的关系(例如元路径)连接。 给定元路径,每个节点都有许多基于元路径的邻居。 需要如何区分这些邻居的细微差别并选择一些信息丰富的邻居。 对于每个节点,节点级注意力旨在学习基于元路径的邻居的重要性,并为它们分配不同的注意力值。 仍然以 IMDB 为例,当使用元路径 电影-导演-电影 时(电影由同一导演执导),终结者 将通过导演詹姆斯·卡梅隆 连接到泰坦尼克号 和终结者2 。 为了更好地将终结者 的类型识别为科幻电影,模型应该更多地关注终结者2 ,而不是泰坦尼克号。 因此,如何设计一个能够发现邻居的细微差异并正确学习其权重的模型将是人们所期望的。
在本文中,我们提出了一种新颖的H 异构图A 注意力N 网络,称为HAN ,它同时考虑节点级 和语义级注意力。 特别是,给定节点特征作为输入,我们使用特定于类型的变换矩阵将不同类型的节点特征投影到同一空间中。 然后,节点级注意力能够学习节点与其基于元路径的邻居之间的注意力值,而语义级注意力旨在学习异构图中特定任务的不同元路径的注意力值。 基于学习到的两个级别的注意力值,我们的模型可以以分层方式获得邻居和多个元路径的最佳组合,这使得学习到的节点嵌入能够更好地捕获异构图中的复杂结构和丰富的语义信息。 之后,可以通过反向传播以端到端的方式优化整体模型。
我们的工作贡献总结如下:
• 据我们所知,这是研究基于注意力机制的异构图神经网络的首次尝试。 我们的工作使得图神经网络能够直接应用于异构图,进一步促进基于异构图的应用。
• 我们提出了一种新颖的异构图注意力网络(HAN),其中包括节点级和语义级注意力。 受益于这种分层关注,所提出的 HAN 可以同时考虑节点和元路径的重要性。 此外,我们的模型效率很高,相对于基于元路径的节点对的数量具有线性复杂度,可以应用于大规模异构图。
• 我们进行了大量的实验来评估所提出模型的性能。 通过与最先进的模型进行比较,结果表明了所提出的模型的优越性。 更重要的是,通过分析分层注意力机制,所提出的 HAN 展示了其对异构图分析的潜在良好可解释性。
2. 相关工作
2.1. 图神经网络
(Gori 等人,2005;Scarselli 等人,2009)中介绍了图神经网络(GNN),旨在扩展深度神经网络以处理任意图结构数据。 Yujia Li 等人(Li 等人, 2016)提出了一种传播模型,该模型可以结合门控循环单元在所有节点之间传播信息。 最近,对图结构数据进行泛化卷积运算的浪潮兴起。 图卷积神经工作一般分为两类,即谱域和非谱域。 一方面,谱方法使用图的谱表示。 Joan Bruna 等人 (Bruna 等人, 2013) 通过寻找相应的傅里叶基,将卷积扩展到一般图。 Michaël 等人 (Defferrard 等人, 2016) 利用 K 阶 切比雪夫 多项式来近似谱域中的平滑滤波器。 Kipf等人(Kipf and Welling, 2017)提出了一种谱方法,称为图卷积网络,通过谱图卷积的局部一阶近似来设计图卷积网络。 另一方面,我们还有非谱方法,直接在图上定义卷积,对空间上邻近的组进行操作。 Hamilton 等人 (Hamilton 等人, 2017)介绍了 GraphSAGE,它在固定大小的邻居节点上执行基于神经网络的聚合器。 它可以学习一个通过聚合节点本地邻域的特征来生成嵌入的函数。
自注意力(Vaswani等人,2017)和软注意力(Bahdanau等人,2015)等注意力机制已成为深度学习中最有影响力的机制之一。 之前的一些工作介绍了基于图的应用程序的注意力机制,例如推荐(Hu等人,2018;Han等人,2018)。 受注意力机制的启发,提出图注意力网络(Veličković等人,2018)来学习节点与其邻居之间的重要性,并融合邻居来进行节点分类。 然而,上述图神经网络无法处理各种类型的节点和边,只能应用于齐次图。
2.2. 网络嵌入
网络嵌入,即网络表示学习(NRL),被提出将网络嵌入到低维空间中,同时保留网络结构和属性,以便学习到的嵌入可以应用于下游网络任务。 例如,基于随机游走的方法(Perozzi 等人,2014;Grover and Leskovec,2016)、基于深度神经网络的方法(Wang 等人,2016)、基于矩阵分解的方法(Ou 等人,2016;Wang 等人,2017)等,例如,LINE (Tang 等人, 2015)。 然而,所有这些算法都是针对齐次图提出的。 一些详细的评论可以在(Cui等人,2018;Goyal和Ferrara,2017)中找到。
异构图嵌入主要关注保留基于元路径的结构信息。 ESim (Shang 等人, 2016) 接受用户定义的元路径作为指导,在用户首选的嵌入空间中学习顶点向量以进行相似性搜索。 即使ESim可以利用多个元路径,它也无法了解元路径的重要性。 为了达到最佳性能,ESim需要进行网格搜索来找到hmeta路径的最佳权重。 找到特定任务的最佳组合非常困难。 Metapath2vec (Dong 等人, 2017) 设计了一种基于元路径的随机游走,并利用skip-gram来执行异构图嵌入。 然而,metapath2vec 只能利用一种元路径,并且可能会忽略一些有用的信息。 与metapath2vec类似,HERec (Shi 等人, 2018a)提出了一种类型约束策略来过滤节点序列并捕获异构图中反映的复杂语义。 HIN2Vec (Fu 等人, 2017) 执行多个预测训练任务,同时学习节点和元路径的潜在向量。 Chen 等人 (Chen 等人, 2018) 提出了一种投影度量嵌入模型,名为 PME,它可以通过欧几里德距离保留节点邻近度。 PME将不同类型的节点投影到同一关系空间中,进行异构链接预测。 为了研究异构图的综合描述问题,Chen等人(Shi等人, 2018b)提出了HEER,它可以通过边表示来嵌入异构图。 Fan等人(Fan等人, 2018)提出了一种嵌入模型metagraph2vec,最大限度地保留了结构和语义以用于恶意软件检测。 Sun等人(Sun 等人, 2018)提出了基于元图的网络嵌入模型,该模型同时考虑元图所有元信息的隐藏关系。 综上所述,上述所有算法都没有考虑异构图表示学习中的注意力机制。
3. 序言
异构图是一种特殊的信息网络,它包含多种类型的对象或多种类型的链接。
定义 3.1。
异构图(Sun和Han,2013)。 异构图表示为𝒢=(𝒱,ℰ),由对象集𝒱和链接集ℰ组成。异构图还与节点类型映射函数ϕ:𝒱→𝒜和链接类型映射函数ψ:ℰ→ℛ相关联。 𝒜和ℛ表示预定义对象类型和链接类型的集合,其中|𝒜|+|ℛ|>2。
示例。 如图1(a)所示,我们构建了一个异构图来对 IMDB 进行建模。 它由多种类型的对象(演员(A)、电影(M)、导演(D))和关系(电影与导演之间的拍摄关系、演员与电影之间的角色扮演关系)组成。
在异构图中,两个对象可以通过不同的语义路径连接,这些路径称为元路径。
定义 3.2。
元路径(Sun等人,2011)。 元路径Φ被定义为(简写为A1A2⋯Al+1)形式的路径,它描述了对象A1和Al+1之间的复合关系R=R1∘R2∘⋯∘Rl,其中∘表示关系上的复合运算符。
示例。 如图1(a)所示,两部电影可以通过多个元路径连接,例如电影-演员-电影(MAM )和电影-导演-电影(MDM )。 不同的元路径总是揭示不同的语义。 例如,MAM 表示合作演员关系,而电影-导演-电影 (MDM) 表示它们由同一导演执导。
给定一个元路径Φ,每个节点都存在一组基于元路径的邻居,它们可以在异构图中揭示不同的结构信息和丰富的语义。
定义 3.3。
基于元路径的邻居。 给定异构图中的节点i和元路径Φ,节点i的基于元路径的邻居𝒩iΦ被定义为通过元路径Φ与节点i连接的节点的集合。 请注意,该节点的邻居包括其自身。
示例。 以图1(d)为例,给定元路径Movie-Actor-Movie,m1的基于元路径的邻居包括m1(其自身)、m2和m3。 类似地,基于元路径Movie-Director-Movie的m1的邻居包括m1和m2。 显然,基于元路径的邻居可以利用异构图中结构信息的不同方面。 我们可以通过邻接矩阵序列的乘法获得基于元路径的邻居。
图神经网络被提出来处理任意图结构数据。 然而,它们都是为同构网络设计的(Kipf and Welling,2017;Veličković等人,2018)。 由于元路径和基于元路径的邻居是异构图中的两个基本结构,接下来,我们将提出一种用于异构图数据的新型图神经网络,它能够利用节点和元路径的细微差别。 表 1总结了我们将在整篇文章中使用的符号。
表 1.注释和解释。
| Notation | Explanation |
| Φ | 元路径 |
| 𝐡 | 初始节点特征 |
| | 类型特定的变换矩阵 |
| 𝐡′ | 投影后的节点特征 |
| | 基于元路径的节点对 (i,j) 的重要性 |
| | 元路径的节点级注意力向量 Φ |
| | 基于元路径的节点对 (i,j) 的权重 |
| | 基于元路径的邻居 |
| | 语义特定的节点嵌入 |
| 𝐪 | 语义级注意力向量 |
| | 元路径 Φ 的重要性 |
| | 元路径 Φ 的权重 |
| 𝐙 | 最终嵌入 |
|---|
4. 提议的模型
在本节中,我们提出了一种新颖的异构图半监督图神经网络。 我们的模型遵循分层注意力结构:节点级注意力 → 语义级注意力。 图2展示了HAN的整体框架。 首先,我们提出节点级注意力来学习基于元路径的邻居的权重并将它们聚合以获得特定于语义的节点嵌入。 之后,HAN 可以通过语义级注意力来区分元路径的差异,并针对特定任务获得特定于语义的节点嵌入的最佳加权组合。
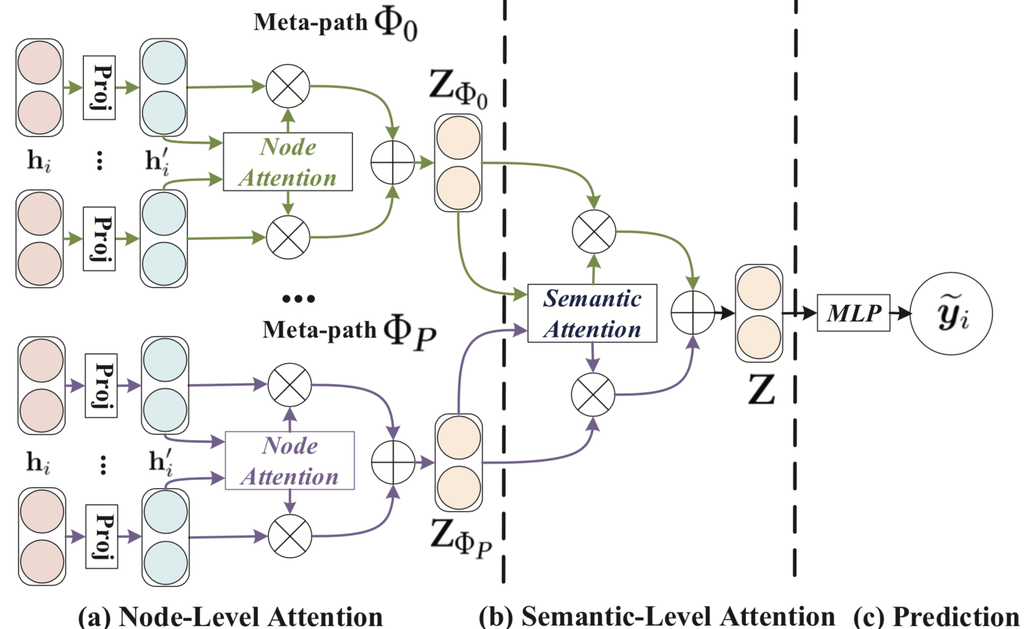
图 2.拟议HAN的总体框架。 (a)所有类型的节点都被投影到统一的特征空间中,并且可以通过节点级注意力来学习基于元路径的节点对的权重。 (b)联合学习每个元路径的权重,并通过语义级注意力融合特定于语义的节点嵌入。 (c) 计算所提出的 HAN 的损失和端到端优化。
4.1. 节点级注意力
在聚合每个节点的元路径邻居的信息之前,我们应该注意到每个节点的基于元路径的邻居在学习特定任务的节点嵌入中发挥不同的作用并表现出不同的重要性。 这里我们引入节点级注意力,可以学习异构图中每个节点基于元路径的邻居的重要性,并聚合这些有意义的邻居的表示以形成节点嵌入。
由于节点的异构性,不同类型的节点具有不同的特征空间。 因此,对于每种类型的节点(例如类型为ϕi的节点),我们设计特定类型的变换矩阵𝐌ϕi,将不同类型节点的特征投影到同一特征空间中。 与 (Hamilton 等人, 2018) 不同,特定类型的变换矩阵基于节点类型而不是边类型。 投影过程可以表示如下:
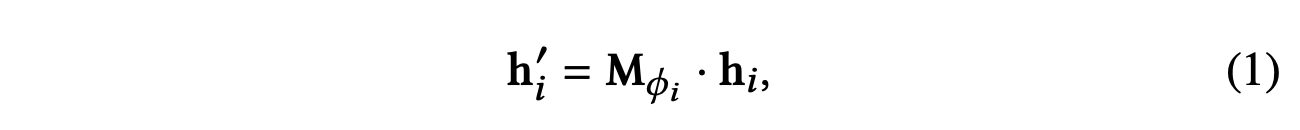
其中 𝐡i 和 𝐡i′ 分别是节点 i 的原始特征和投影特征。 通过特定于类型的投影操作,节点级注意力可以处理任意类型的节点。
之后,我们利用自注意力(Vaswani等人,2017)来学习各种节点之间的权重。 给定通过元路径Φ连接的节点对(i,j),节点级注意力eijΦ可以学习重要性eijΦ,这意味着节点j对于节点i的重要性。 基于元路径的节点对(i,j)的重要性可以表述如下:
这里attnode表示执行节点级注意力的深度神经网络。 给定元路径 Φ,attnode 为所有基于元路径的节点对共享。 这是因为一条元路径下存在一些相似的连接模式。 上式(2) 显示给定元路径Φ,基于元路径的节点对(i,j)的权重取决于它们的特征。 请注意,eijΦ是不对称的,即节点i对节点j的重要性和节点j对节点i的重要性可能相差很大。 它表明节点级注意力可以保留不对称性,这是异构图的关键属性。
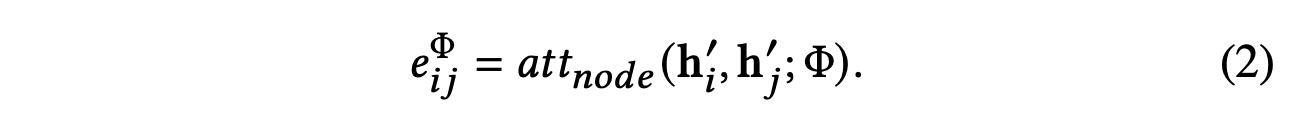
然后,我们通过屏蔽注意力将结构信息注入到模型中,这意味着我们只计算节点 j∈𝒩iΦ 的 eijΦ,其中 𝒩iΦ 表示节点 i 的基于元路径的邻居(包括其自身)。 在获得基于元路径的节点对之间的重要性后,我们通过softmax函数对它们进行归一化以获得权重系数αijΦ:
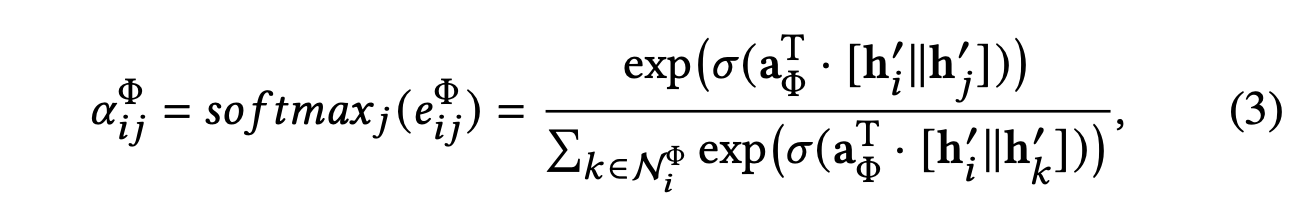
其中 σ 表示激活函数,∥ 表示连接操作,𝐚Φ 是元路径 Φ 的节点级注意力向量。 正如我们从等式中可以看到的那样。 (3),(i,j)的权重系数取决于它们的特征。 另请注意,权重系数αijΦ是不对称的,这意味着它们对彼此的贡献不同。 不仅因为分子中的连接顺序,而且因为它们具有不同的邻居,因此归一化项(分母)将有很大差异。
然后,节点 i 的基于元路径的嵌入可以通过邻居的投影特征与相应的系数进行聚合,如下所示:
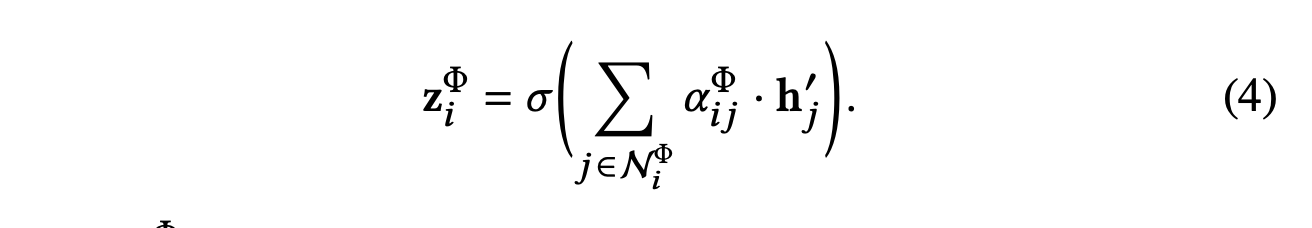
其中 𝐳iΦ 是学习到的元路径 Φ 节点 i 的嵌入。 为了更好地理解节点级的聚合过程,我们还在图3(a)中给出了简要说明。 每个节点嵌入都由其邻居聚合。 由于注意力权重αijΦ是针对单个元路径生成的,因此它是语义特定的并且能够捕获一种语义信息。
由于异构图具有无标度特性,因此图数据的方差相当高。 为了应对上述挑战,我们将节点级注意力扩展到多头注意力,以使训练过程更加稳定。 具体来说,我们重复节点级注意力 K 次,并将学习到的嵌入连接为特定于语义的嵌入:
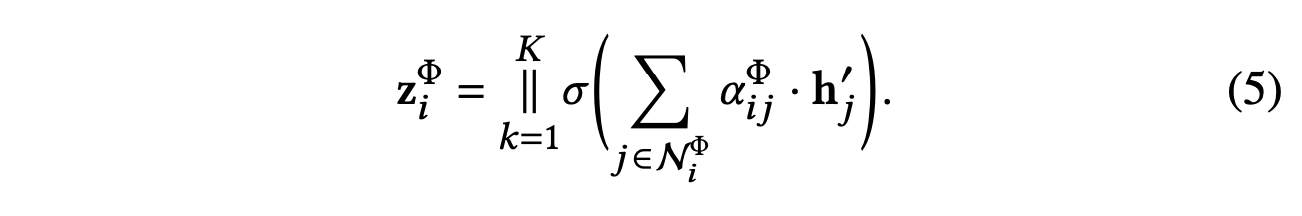
给定元路径集{Φ1,...,ΦP},将节点特征输入节点级注意力后,我们可以获得P组特定于语义的节点嵌入,表示为{𝐙Φ1,...,𝐙ΦP}。
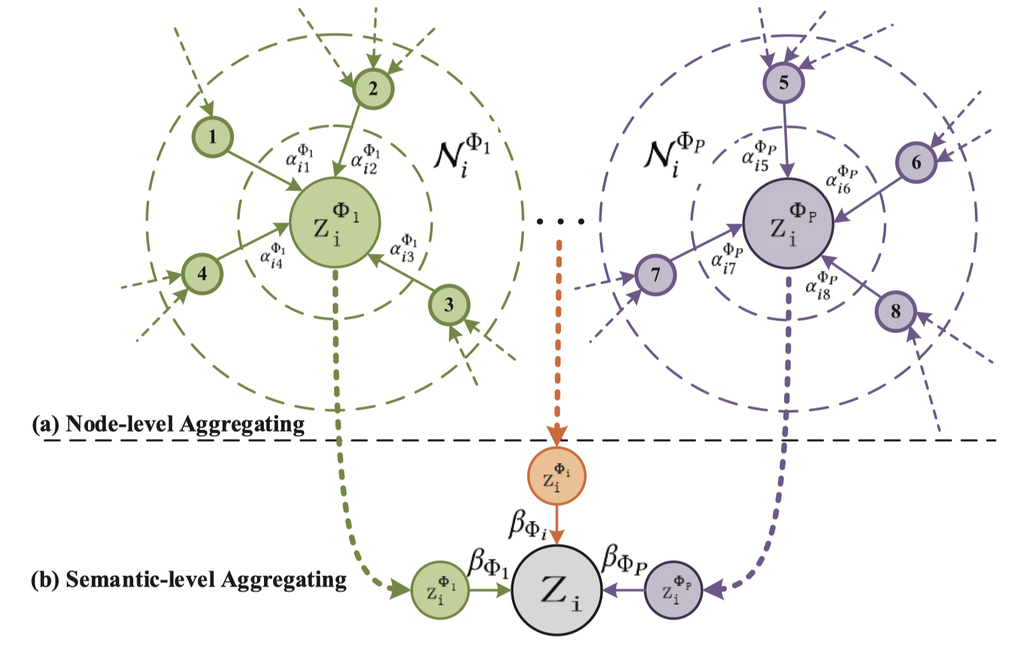
图 3.节点级和语义级聚合过程的说明。
4.2. 语义级注意力
一般来说,异构图中的每个节点都包含多种类型的语义信息,语义特定的节点嵌入只能从一个方面反映节点。 为了学习更全面的节点嵌入,我们需要融合可以通过元路径揭示的多种语义。 为了解决异构图中元路径选择和语义融合的挑战,我们提出了一种新颖的语义级注意力来自动学习不同元路径的重要性并将它们融合到特定任务中。 以从节点级注意力学习到的P组特定于语义的节点嵌入作为输入,每个元路径(βΦ1,...,βΦP)的学习权重可以如下所示:
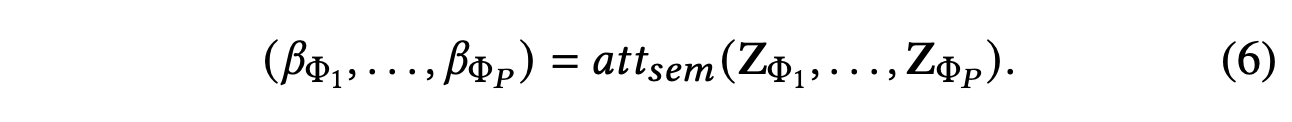
这里attsem表示执行语义级注意力的深度神经网络。 它表明语义级注意力可以捕获异构图背后的各种类型的语义信息。
为了了解每个元路径的重要性,我们首先通过非线性变换(例如,单层 MLP)来变换语义特定的嵌入。 然后,我们用语义级注意力向量 𝐪 来衡量特定于语义的嵌入的重要性,作为变换嵌入的相似性。此外,我们对所有特定于语义的节点嵌入的重要性进行平均,这可以解释为每个元路径的重要性。 每个元路径的重要性用wΦi表示,如下所示:
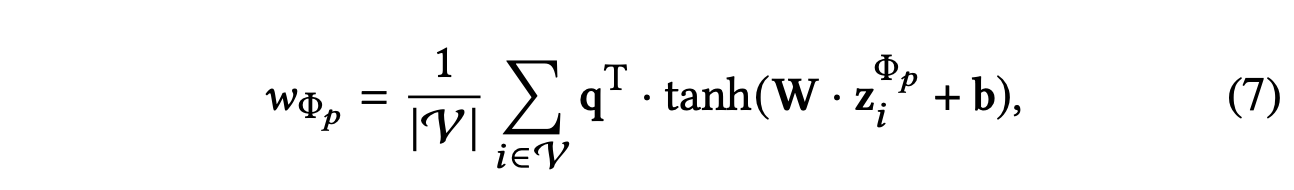
其中𝐖是权重矩阵,𝐛是偏差向量,𝐪是语义级注意力向量。 请注意,为了进行有意义的比较,所有元路径和特定于语义的嵌入共享上述所有参数。 在获得每个元路径的重要性后,我们通过softmax函数对它们进行归一化。 元路径Φi的权重,记为βΦi,可以通过使用softmax函数对上述所有元路径的重要性进行标准化得到,
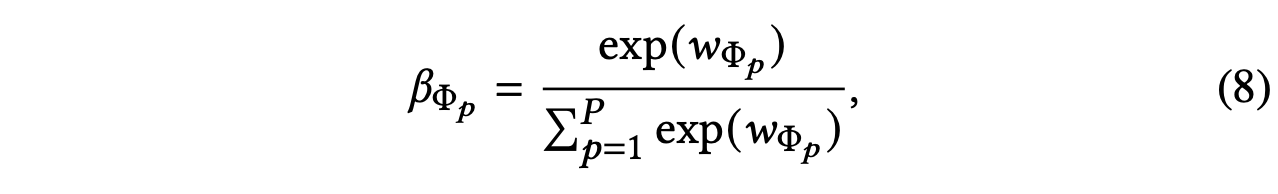
可以理解为元路径Φp对特定任务的贡献。 显然,βΦp越高,元路径Φp就越重要。 请注意,对于不同的任务,元路径 Φp 可能具有不同的权重。 使用学习到的权重作为系数,我们可以融合这些特定于语义的嵌入以获得最终的嵌入𝐙,如下所示:
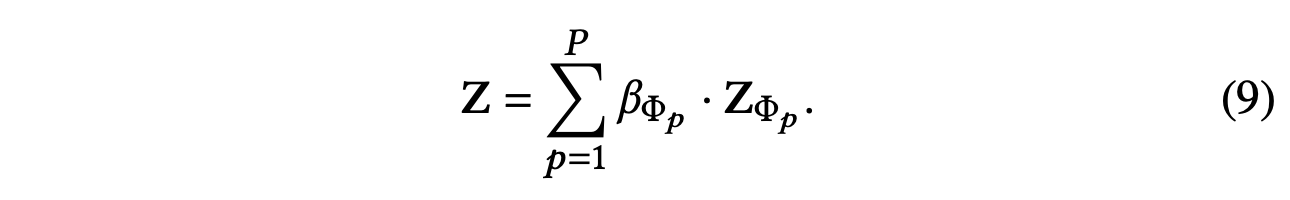
为了更好地理解语义级别的聚合过程,我们还在图3(b)中给出了简要说明。 最终的嵌入由所有特定于语义的嵌入聚合。 然后我们可以将最终的嵌入应用于特定任务并设计不同的损失函数。 对于半监督节点分类,我们可以最小化地面实况和预测之间所有标记节点的交叉熵:
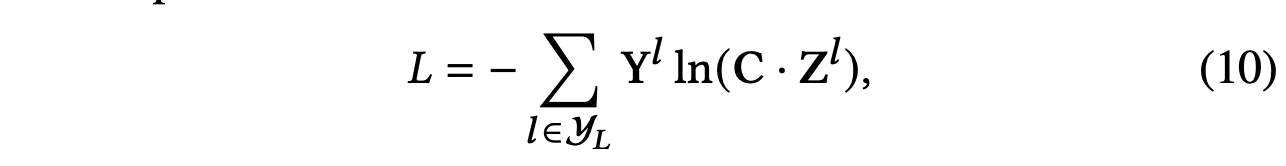
其中 𝐂 是分类器的参数,𝒴L 是具有标签的节点索引集,𝐘l 和 𝐙l 是标记节点的标签和嵌入。 在标记数据的指导下,我们可以通过反向传播来优化所提出的模型并学习节点的嵌入。 HAN的整体流程如算法1所示。
表 2.数据集的统计。
| Dataset | Relations(A-B) | Number of A | Number of B | Number of A-B | Feature | Training | Validation | Test | Meta-paths |
|---|---|---|---|---|---|---|---|---|---|
| DBLP | Paper-Author | 14328 | 4057 | 19645 | 334 | 800 | 400 | 2857 | APA |
| DBLP | Paper-Conf | 14328 | 20 | 14328 | 334 | 800 | 400 | 2857 | APCPA |
| DBLP | Paper-Term | 14327 | 8789 | 88420 | 334 | 800 | 400 | 2857 | APTPA |
| IMDB | Movie-Actor | 4780 | 5841 | 14340 | 1232 | 300 | 300 | 2687 | MAM |
| IMDB | Movie-Director | 4780 | 2269 | 4780 | 1232 | 300 | 300 | 2687 | MDM |
| ACM | Paper-Author | 3025 | 5835 | 9744 | 1830 | 600 | 300 | 2125 | PAP |
| ACM | Paper-Subject | 3025 | 56 | 3025 | 1830 | 600 | 300 | 2125 | PSP |

4.3. 所提出模型的分析
这里我们对提出的HAN进行分析如下:
• 所提出的模型可以处理各种类型的节点和关系,并在异构图中融合丰富的语义。 信息可以通过多种关系从一种节点传递到另一种节点。 受益于这种异构图注意力网络,不同类型的节点嵌入可以增强相互融合、相互促进和相互升级。
• 所提出的HAN 效率很高并且可以轻松并行化。 注意力的计算可以跨所有节点和元路径单独计算。 给定元路径Φ,节点级注意力的时间复杂度为O(VΦF1F2K+EΦF1K),其中K是注意力头的数量,VΦ是节点的数量,EΦ是基于元路径的节点对的数量,F1和F2分别是变换矩阵的行数和列数。 总体复杂性与节点和基于元路径的节点对的数量呈线性关系。 所提出的模型可以轻松并行化,因为节点级和语义级注意力可以分别跨节点对和元路径并行化。 总体复杂性与节点和基于元路径的节点对的数量呈线性关系。
• 整个异构图共享层次注意力,这意味着参数的数量不依赖于异构图的规模,并且可以用于归纳问题(Hamilton等人,2017)。 这里归纳意味着模型可以为以前未见过的节点甚至未见过的图生成节点嵌入。
• 所提出的模型对于学习的节点嵌入具有潜在的良好可解释性,这对于异构图分析来说是一个很大的优势。 通过学习节点和元路径的重要性,所提出的模型可以更多地关注特定任务的一些有意义的节点或元路径,并给出异构图的更全面的描述。 根据注意力值,我们可以检查哪些节点或元路径对我们的任务做出更高(或更低)的贡献,这有利于分析和解释我们的结果。
表 3.节点分类任务的定量结果(%)。
| Datasets | Metrics | Training | DeepWalk | ESim | metapath2vec | HERec | GCN | GAT | HANnd | HANsem | HAN |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ACM | Macro-F1 | 20% | 77.25 | 77.32 | 65.09 | 66.17 | 86.81 | 86.23 | 88.15 | 89.04 | 89.40 |
| ACM | Macro-F1 | 40% | 80.47 | 80.12 | 69.93 | 70.89 | 87.68 | 87.04 | 88.41 | 89.41 | 89.79 |
| ACM | Macro-F1 | 60% | 82.55 | 82.44 | 71.47 | 72.38 | 88.10 | 87.56 | 87.91 | 90.00 | 89.51 |
| ACM | Macro-F1 | 80% | 84.17 | 83.00 | 73.81 | 73.92 | 88.29 | 87.33 | 88.48 | 90.17 | 90.63 |
| ACM | Micro-F1 | 20% | 76.92 | 76.89 | 65.00 | 66.03 | 86.77 | 86.01 | 87.99 | 88.85 | 89.22 |
| ACM | Micro-F1 | 40% | 79.99 | 79.70 | 69.75 | 70.73 | 87.64 | 86.79 | 88.31 | 89.27 | 89.64 |
| ACM | Micro-F1 | 60% | 82.11 | 82.02 | 71.29 | 72.24 | 88.12 | 87.40 | 87.68 | 89.85 | 89.33 |
| ACM | Micro-F1 | 80% | 83.88 | 82.89 | 73.69 | 73.84 | 88.35 | 87.11 | 88.26 | 89.95 | 90.54 |
| DBLP | Macro-F1 | 20% | 77.43 | 91.64 | 90.16 | 91.68 | 90.79 | 90.97 | 91.17 | 92.03 | 92.24 |
| DBLP | Macro-F1 | 40% | 81.02 | 92.04 | 90.82 | 92.16 | 91.48 | 91.20 | 91.46 | 92.08 | 92.40 |
| DBLP | Macro-F1 | 60% | 83.67 | 92.44 | 91.32 | 92.80 | 91.89 | 90.80 | 91.78 | 92.38 | 92.80 |
| DBLP | Macro-F1 | 80% | 84.81 | 92.53 | 91.89 | 92.34 | 92.38 | 91.73 | 91.80 | 92.53 | 93.08 |
| DBLP | Micro-F1 | 20% | 79.37 | 92.73 | 91.53 | 92.69 | 91.71 | 91.96 | 92.05 | 92.99 | 93.11 |
| DBLP | Micro-F1 | 40% | 82.73 | 93.07 | 92.03 | 93.18 | 92.31 | 92.16 | 92.38 | 93.00 | 93.30 |
| DBLP | Micro-F1 | 60% | 85.27 | 93.39 | 92.48 | 93.70 | 92.62 | 91.84 | 92.69 | 93.31 | 93.70 |
| DBLP | Micro-F1 | 80% | 86.26 | 93.44 | 92.80 | 93.27 | 93.09 | 92.55 | 92.69 | 93.29 | 93.99 |
| IMDB | Macro-F1 | 20% | 40.72 | 32.10 | 41.16 | 41.65 | 45.73 | 49.44 | 49.78 | 50.87 | 50.00 |
| IMDB | Macro-F1 | 40% | 45.19 | 31.94 | 44.22 | 43.86 | 48.01 | 50.64 | 52.11 | 50.85 | 52.71 |
| IMDB | Macro-F1 | 60% | 48.13 | 31.68 | 45.11 | 46.27 | 49.15 | 51.90 | 51.73 | 52.09 | 54.24 |
| IMDB | Macro-F1 | 80% | 50.35 | 32.06 | 45.15 | 47.64 | 51.81 | 52.99 | 52.66 | 51.60 | 54.38 |
| IMDB | Micro-F1 | 20% | 46.38 | 35.28 | 45.65 | 45.81 | 49.78 | 55.28 | 54.17 | 55.01 | 55.73 |
| IMDB | Micro-F1 | 40% | 49.99 | 35.47 | 48.24 | 47.59 | 51.71 | 55.91 | 56.39 | 55.15 | 57.97 |
| IMDB | Micro-F1 | 60% | 52.21 | 35.64 | 49.09 | 49.88 | 52.29 | 56.44 | 56.09 | 56.66 | 58.32 |
| IMDB | Micro-F1 | 80% | 54.33 | 35.59 | 48.81 | 50.99 | 54.61 | 56.97 | 56.38 | 56.49 | 58.51 |
5. 实验
5.1. 数据集
这里使用的异构图的详细描述如表2所示。
• DBLP2。 我们提取了 DBLP 的一个子集,其中包含 14328 篇论文 (P)、4057 位作者 (A)、20 个会议 (C)、8789 个术语 (T)。 作者分为四个领域:数据库、数据挖掘、机器学习、信息检索 。 此外,我们根据每位作者提交的会议来标记他们的研究领域。 作者特征是由关键字表示的词袋的元素。 这里我们使用元路径集 {APA , APCPA , APTPA} 来进行实验。
• ACM3。 我们提取发表在 KDD、SIGMOD、SIGCOMM、MobiCOMM 和 VLDB 上的论文,并将论文分为三类(数据库、无线通信、数据挖掘 )。 然后我们构建了一个异构图,其中包含 3025 篇论文 (P)、5835 位作者 (A) 和 56 个主题 (S)。 论文特征对应于由关键字表示的词袋的元素。 我们使用元路径集 {PAP , PSP} 来进行实验。 在这里,我们根据论文发表的会议对论文进行标记。
• IMDB。 这里我们提取了 IMDB 的一个子集,其中包含 4780 部电影(M)、5841 名演员(A)和 2269 名导演(D)。 电影根据类型分为三类(动作、喜剧、剧情 )。 电影特征对应于表示情节的词袋的元素。 我们使用元路径集 {MAM , MDM} 来执行实验。
5.2. 基线
我们与一些最先进的基线进行比较,包括(异构)网络嵌入方法和基于图神经网络的方法,以验证所提出的 HAN 的有效性。 为了分别验证节点级注意力和语义级注意力的有效性,我们还测试了 HAN 的两种变体。
• DeepWalk (Perozzi 等人, 2014):一种基于随机游走的网络嵌入方法,针对同质图进行设计。 这里我们忽略节点的异构性,对整个异构图进行DeepWalk。
• ESim (Shang 等人, 2016):一种异构图嵌入方法,可以从多个元路径捕获语义信息。 由于搜索一组元路径的权重很困难,因此我们将从 HAN 学到的权重分配给 ESim。
• metapath2vec (Dong 等人, 2017):一种异构图嵌入方法,执行基于元路径的随机游走并利用skip-gram 嵌入异构图。 在这里,我们测试了 metapath2vec 的所有元路径并报告最佳性能。
• HERec (Shi 等人, 2018a):一种异构图嵌入方法,设计类型约束策略来过滤节点序列,并利用skip-gram来嵌入异构图。 在这里,我们测试 HERec 的所有元路径并报告最佳性能。
• GCN (Kipf and Welling,2017):它是一种针对同质图设计的半监督图卷积网络。 在这里,我们测试了 GCN 的所有元路径并报告了最佳性能。
• GAT (Veličković 等人, 2018):它是一个半监督神经网络,考虑同质图上的注意力机制。 在这里,我们测试了 GAT 的所有元路径并报告最佳性能。
• HANnd:它是HAN 的变体,它消除了节点级注意力并为每个邻居分配相同的重要性。
• HANsem:它是HAN的一个变体,它消除了语义级注意力并为每个元路径分配相同的重要性。
• HAN:提出的半监督图神经网络,同时采用节点级注意力和语义级注意力。
5.3. 实施细节
对于所提出的 HAN,我们随机初始化参数并使用 Adam (Kingma 和 Ba,2015) 优化模型。 对于所提出的 HAN,我们将学习率设置为 0.005,正则化参数设置为 0.001,语义级注意力向量 𝐪 的维度设置为 128,注意力头 K 的数量设置为 8,注意力的 dropout 设置为 0.6。 我们使用提前停止,耐心为 100,即如果验证损失在连续 100 个 epoch 内没有减少,我们就停止训练。 为了使我们的实验具有可重复性,我们在网站4公开提供我们的数据集和代码。对于 GCN 和 GAT,我们使用验证集优化其参数。 对于半监督图神经网络,包括GCN、GAT和HAN,我们分割完全相同的训练集、验证集和测试集以确保公平性。 对于基于随机游走的方法,包括 DeepWalk、ESim、metapath2vec 和 HERec,我们将窗口大小设置为 5,游走长度设置为 100,每个节点游走设置为 40,负样本数量设置为 5。 为了公平比较,我们将上述所有算法的嵌入维度设置为 64。
5.4. 分类
这里我们使用带有k=5的KNN分类器来执行节点分类。 由于图结构数据的方差可能相当高,因此我们重复该过程 10 次,并在表 3 中报告平均 Macro-F1 和 Micro-F1。
根据表3,我们可以看到HAN取得了最好的性能。 对于传统的异构图嵌入方法,可以利用多个元路径的ESim比metapath2vec表现更好。 一般来说,基于图神经网络的方法结合了结构和特征信息,例如 GCN 和 GAT,通常表现更好。 为了深入研究这些方法,与简单地对邻居节点进行平均(例如 GCN 和 HANnd)相比,GAT 和 HAN 可以正确权衡信息并提高学习嵌入的性能。 与 GAT 相比,针对异构图设计的 HAN 成功捕获了丰富的语义并显示了其优越性。 此外,如果没有节点级注意力(HANnd)或语义级注意力(HANsem),性能会比HAN差,这表明在节点和语义上建模注意力机制的重要性。 请注意,在 ACM 和 IMDB 中,HAN 比 DBLP 更显着地改善了分类结果。 主要是因为 APCPA 比其他元路径重要得多。 我们将在 5.7 节中通过分析语义级注意力来解释这一现象。
通过上述分析,我们可以发现所提出的 HAN 在所有数据集上都取得了最佳性能。 结果表明,在异构图分析中捕获节点和元路径的重要性非常重要。
表 4.节点聚类任务的定量结果(%)。
| Datasets | Metrics | DeepWalk | ESim | metapath2vec | HERec | GCN | GAT | HANnd | HANsem | HAN |
|---|---|---|---|---|---|---|---|---|---|---|
| ACM | NMI | 41.61 | 39.14 | 21.22 | 40.70 | 51.40 | 57.29 | 60.99 | 61.05 | 61.56 |
| ACM | ARI | 35.10 | 34.32 | 21.00 | 37.13 | 53.01 | 60.43 | 61.48 | 59.45 | 64.39 |
| DBLP | NMI | 76.53 | 66.32 | 74.30 | 76.73 | 75.01 | 71.50 | 75.30 | 77.31 | 79.12 |
| DBLP | ARI | 81.35 | 68.31 | 78.50 | 80.98 | 80.49 | 77.26 | 81.46 | 83.46 | 84.76 |
| IMDB | NMI | 1.45 | 0.55 | 1.20 | 1.20 | 5.45 | 8.45 | 9.16 | 10.31 | 10.87 |
| IMDB | ARI | 2.15 | 0.10 | 1.70 | 1.65 | 4.40 | 7.46 | 7.98 | 9.51 | 10.01 |
5.5. 聚类
我们还进行聚类任务来评估从上述算法中学习到的嵌入。 一旦所提出的 HAN 训练完毕,我们就可以通过前馈获得所有节点嵌入。 这里我们利用 KMeans 进行节点聚类,并将聚类数 K 设置为类数。 我们使用与节点分类相同的地面实况。 我们采用NMI 和ARI 来评估聚类结果的质量。 由于 KMeans 的性能受到初始质心的影响,我们重复该过程 10 次,并将平均结果报告在表 4 中。
从表 4 中可以看出,我们可以发现 HAN 的性能始终优于所有基线。 此外,基于图神经网络的算法通常可以获得更好的性能。 此外,如果不区分节点或元路径的重要性,metapath2vec 和 GCN 就无法表现良好。 在多个元路径的引导下,HAN 的性能明显优于 GCN 和 GAT。 另一方面,如果没有节点级注意力(HANnd)或语义级注意力(HANsem),HAN的性能就出现了不同程度的退化。 它表明,通过为节点和元路径分配不同的重要性,所提出的 HAN 可以学习更有意义的节点嵌入。
基于以上分析,我们可以发现所提出的HAN能够对异构图进行全面的描述,并取得了显着的改进。
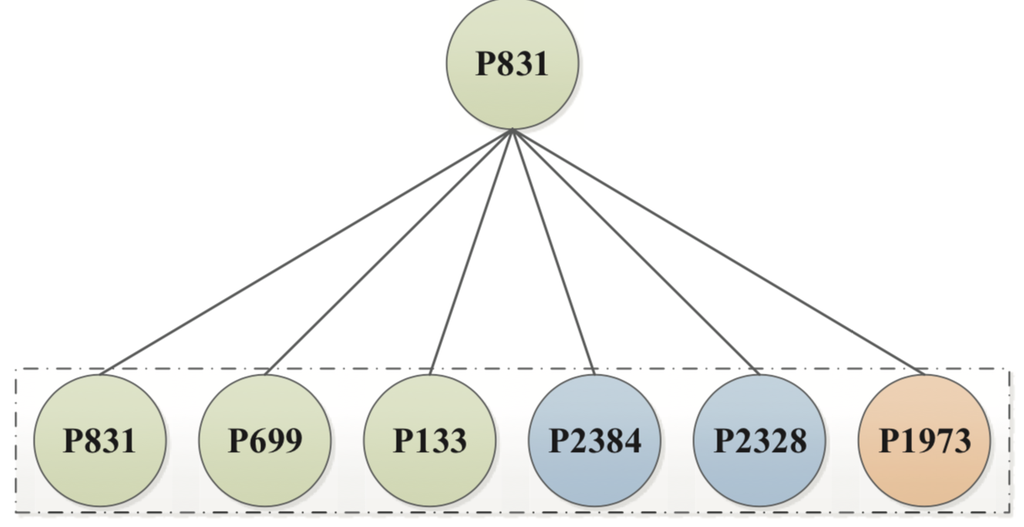
(a)P831 基于元路径的邻居
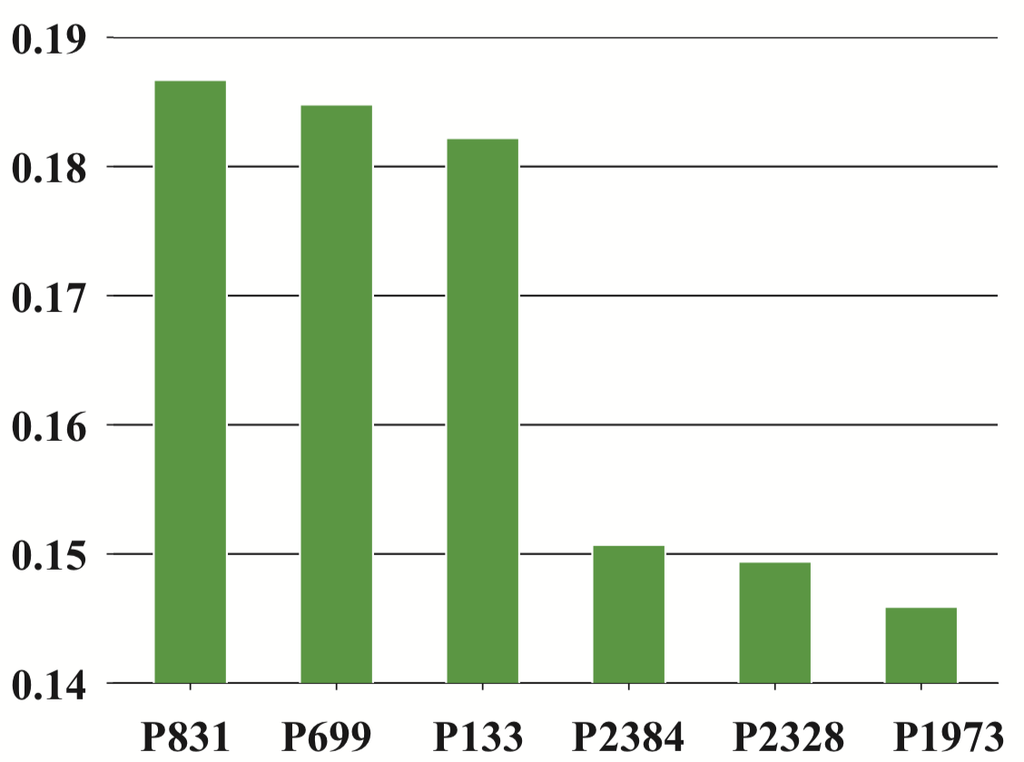
(b)P831邻居的注意力值 图 4.基于元路径的节点 P831 的邻居和相应的注意力值(不同的颜色表示不同的类别,例如,绿色 表示数据挖掘,蓝色 表示数据库,橙色表示无线通信)。
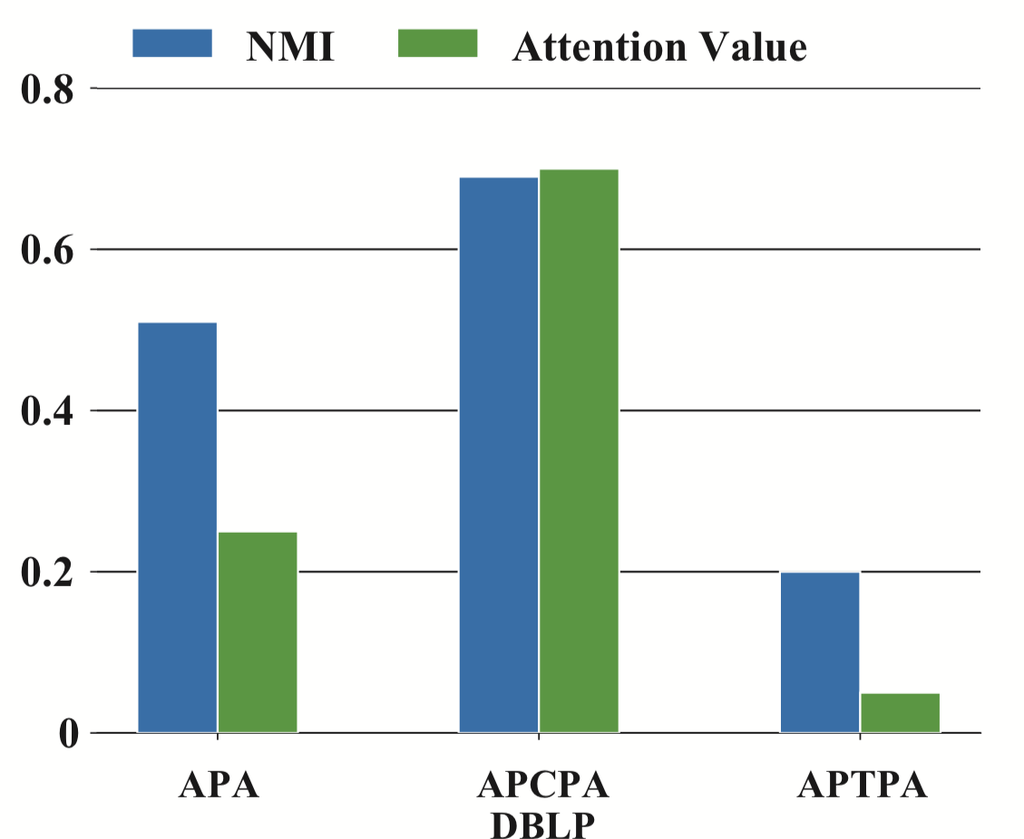
(a)DBLP 的 NMI 值
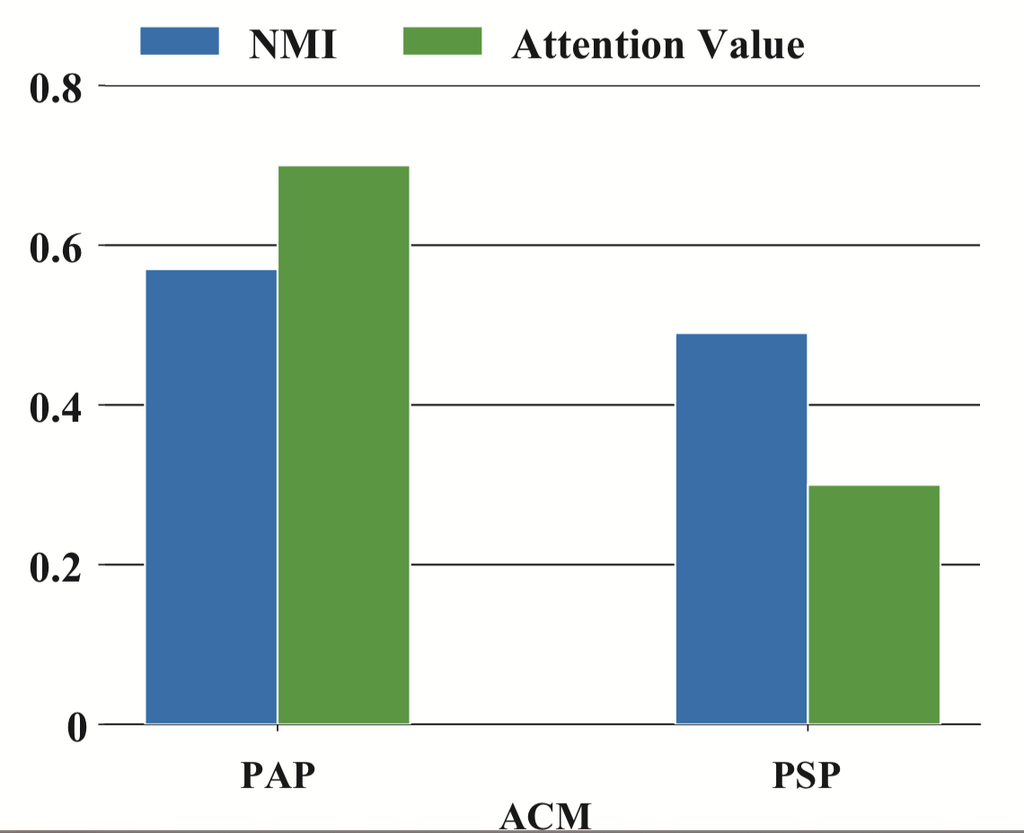
(b)ACM 上的 NMI 值 图 5.单个元路径的性能和相应的注意力值。
5.6. 分层注意力机制分析
HAN 的一个显着特性是层次机制的结合,它在学习代表性嵌入时考虑了节点邻居和元路径的重要性。回想一下,我们已经学习了节点级注意力权重 αijΦ 和语义级注意力权重 βΦi。 为了更好地理解邻居和元路径的重要性,我们对分层注意机制进行了详细分析。
节点级注意力分析。 如前所述,给定特定任务,我们的模型可以学习元路径中节点及其邻居之间的注意力值。 一些对特定任务有用的重要邻居往往具有更大的注意力值。 这里我们取纸张P831 5 以 ACM 数据集为例。 给定一个描述不同论文共同作者的元路径 Paper-Author-Paper,我们枚举了论文 P831 的基于元路径的邻居,它们的注意力值如图 4 所示。 从图4(a)中我们可以看到P831连接到P699 6 和 P133 7,都属于数据挖掘 ;连接到 P2384 8 和 P2328 9 而P2384和P2328都属于数据库 ;连接到 P197310 而P1973属于无线通信 。 从图4(b)中,我们可以看到论文P831从节点级注意力中获得了最高的注意力值,这意味着节点本身在学习其表示方面发挥着最重要的作用。 这是合理的,因为邻居支持的所有信息通常被视为一种补充信息。 除了自身之外,P699 和 P133 获得了第二和第三大关注值。 这是因为P699和P133也属于数据挖掘 ,它们可以为识别P831的类别做出重大贡献。 其余邻居获得较小的关注值,因为它们不属于数据挖掘并且不能对识别P831的类别做出重要贡献。 基于以上分析,我们可以看到,节点级注意力可以区分邻居之间的差异,并为一些有意义的邻居分配更高的权重。
(a)GCN
(b)GAT
(c)metapath2vec
(d)HAN
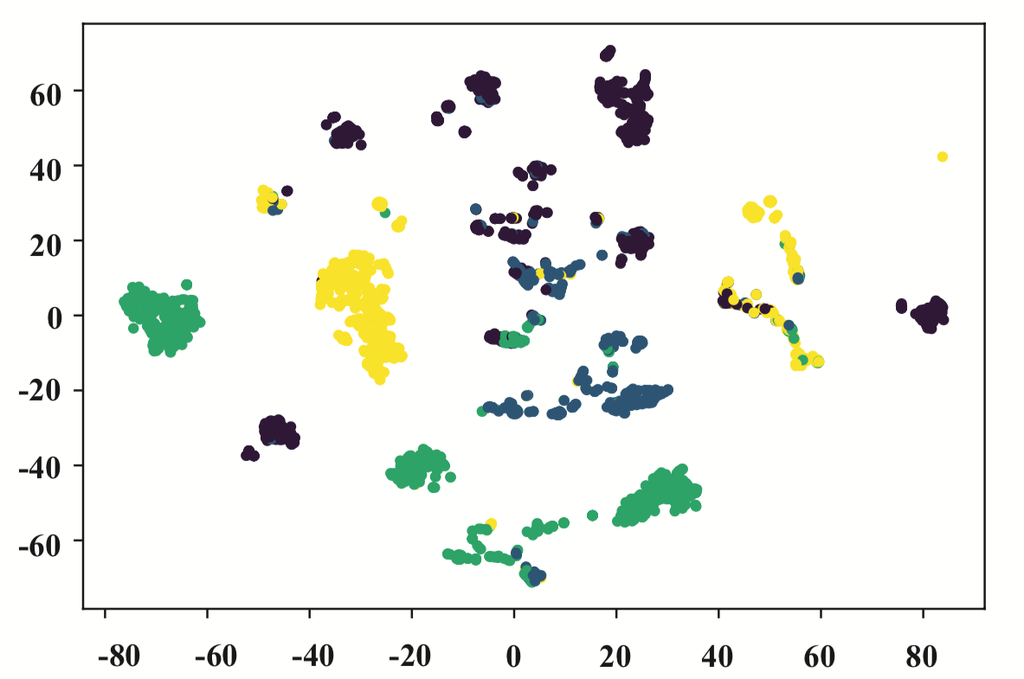
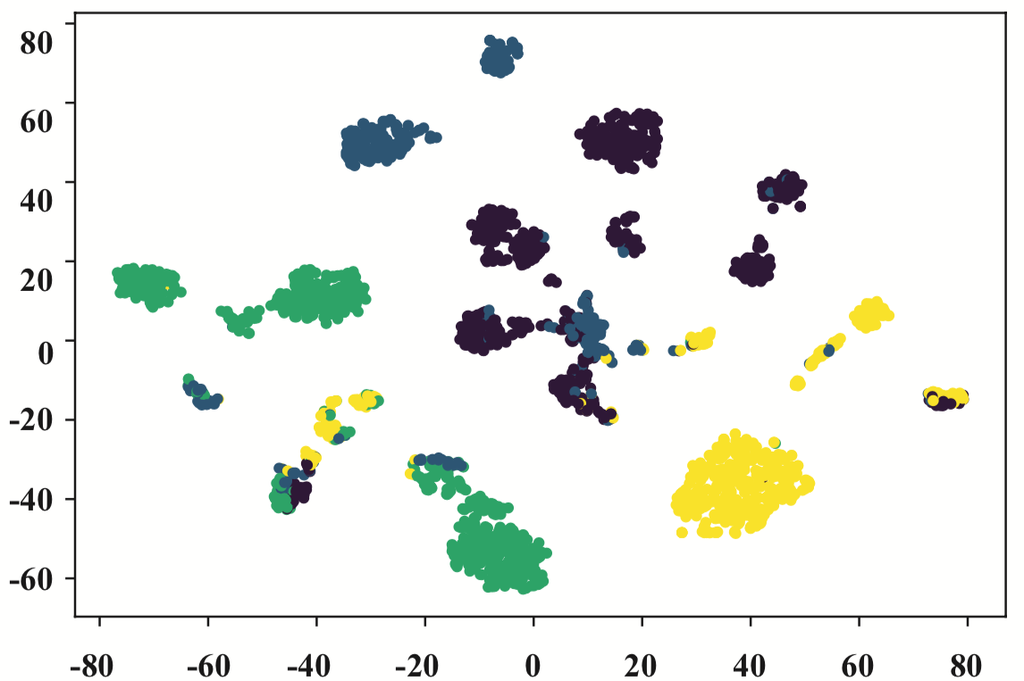
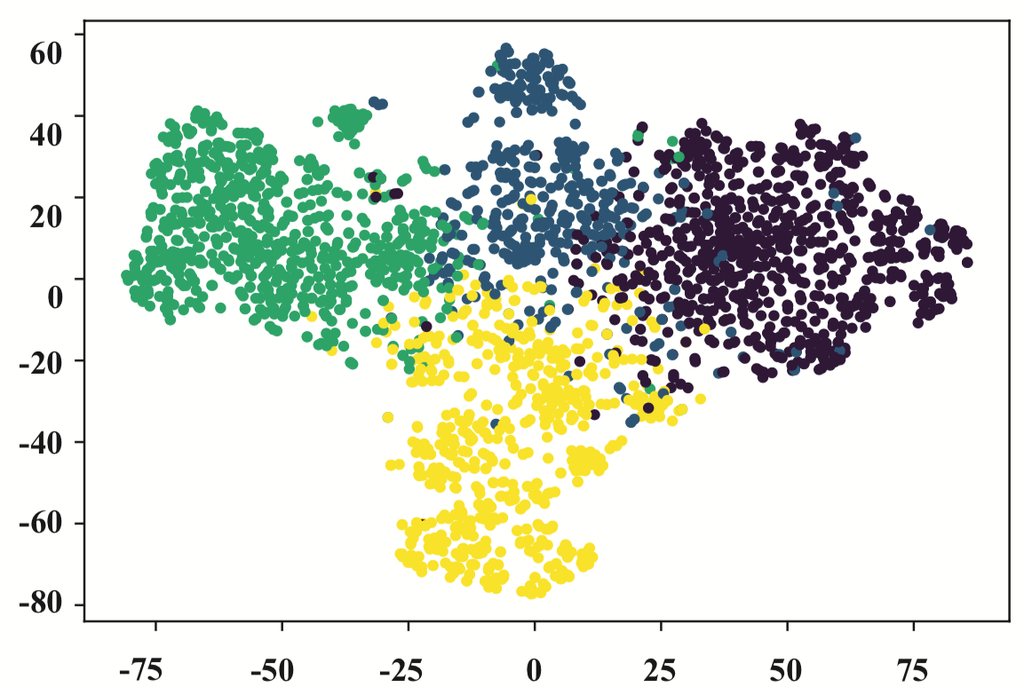
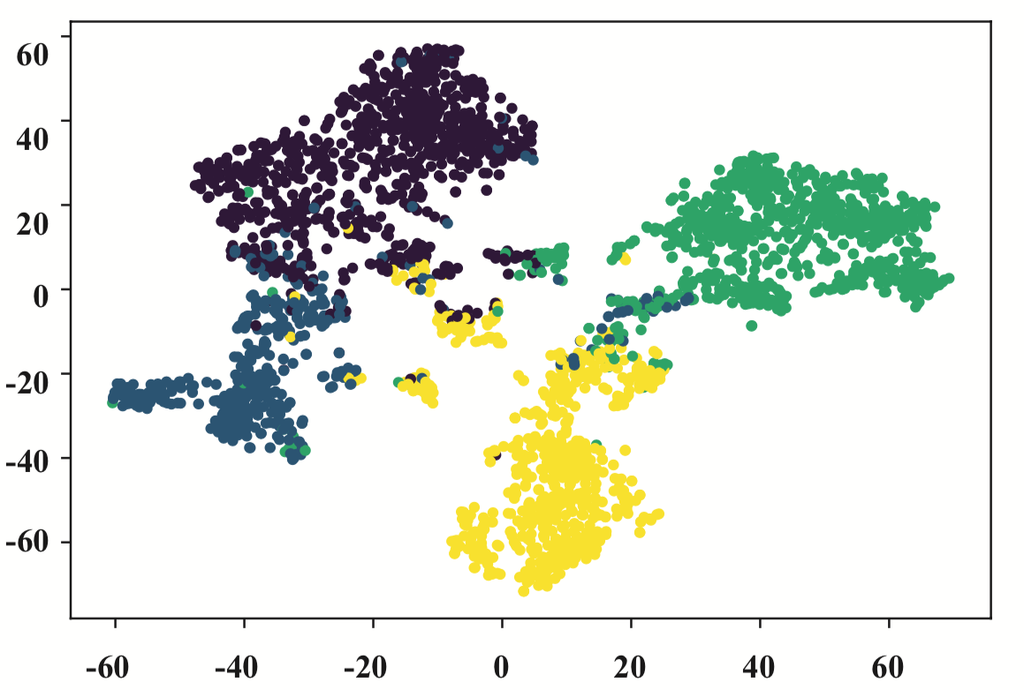
图 6.DBLP 上的可视化嵌入。 每个点代表一位作者,其颜色代表研究领域。
(a)最终嵌入的维度𝐙
(b)语义级注意力向量𝐪的维度
(c)注意力头K的数量。
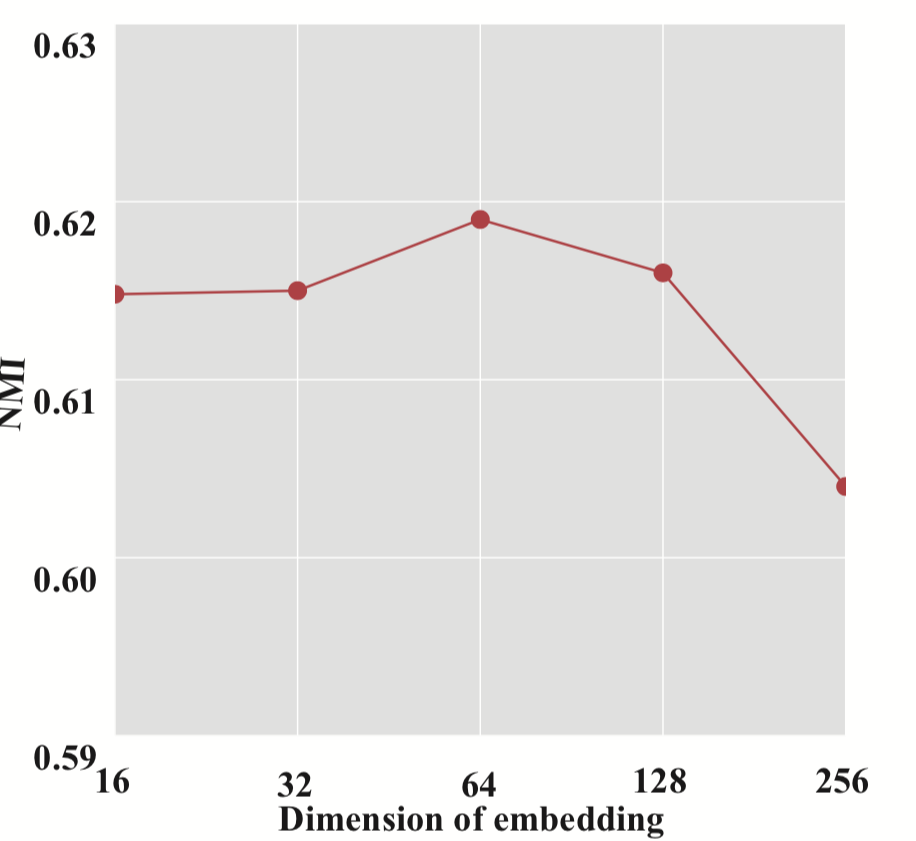
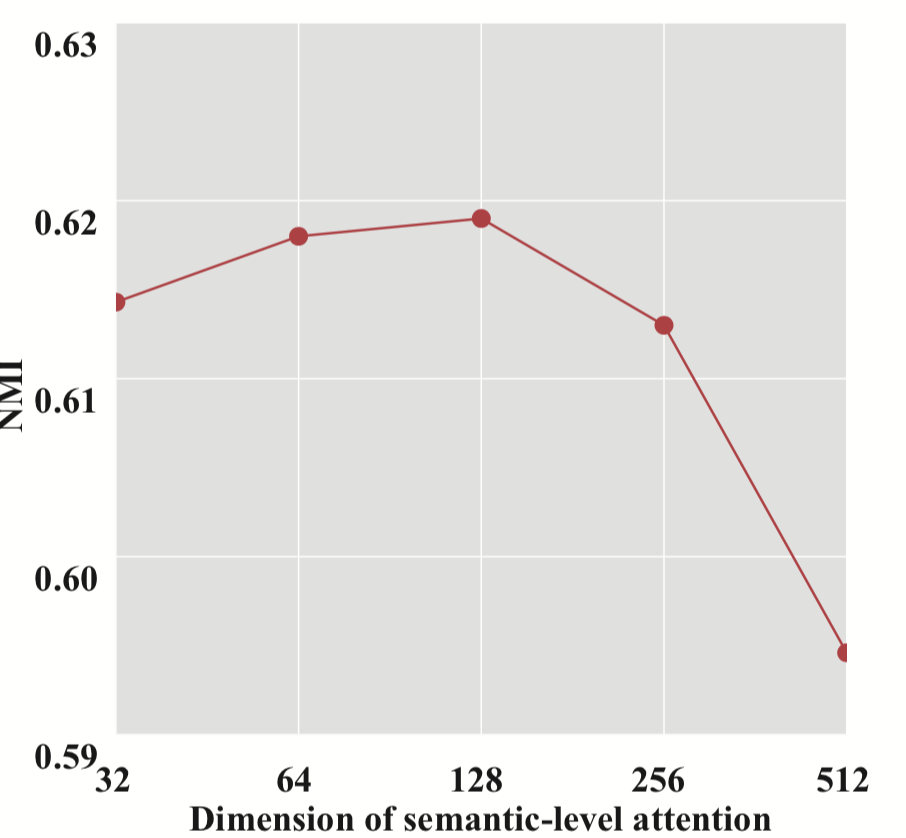
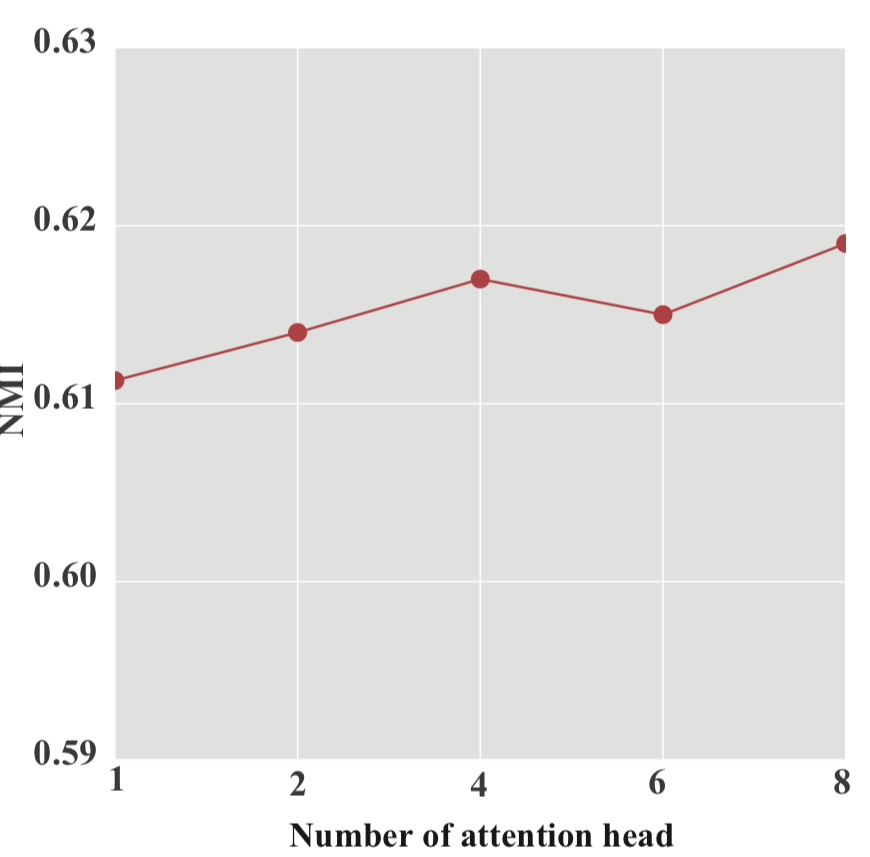
图 7.HAN w.r.t. 的参数敏感性最终嵌入的维度Z,语义级注意力向量的维度q和注意力头的数量K。
语义级注意力分析。 如前所述,所提出的 HAN 可以了解元路径对于特定任务的重要性。 为了验证语义级注意力的能力,以 DBLP 和 ACM 为例,我们在图 5 中报告了单个元路径的聚类结果(NMI )和相应的注意力值。 显然,单个元路径的性能与其注意力值之间存在正相关关系。 对于 DBLP,HAN 给予 APCPA 最大的权重,这意味着 HAN 认为 APCPA 是识别作者研究领域最关键的元路径。 这是有道理的,因为作者的研究领域和他们提交的会议高度相关。 例如,一些自然语言处理研究人员主要将论文提交给ACL或EMNLP,而一些数据挖掘研究人员可能会将论文提交给KDD或WWW。 同时,APA 也很难很好地识别作者的研究领域。 如果我们平等地对待这些元路径,例如 HANsem,性能将显着下降。根据每个元路径的注意力值,我们可以发现元路径APCPA 比APA 和APTPA 有用得多。 因此,即使提出的 HAN 可以融合它们,APCPA 仍然在确定作者的研究领域方面发挥主导作用,而 APA 和 ATPPA 则不然。 它还解释了为什么 HAN 在 DBLP 中的性能可能不如在 ACM 和 IMDB 中那么显着。 我们在 ACM 上也得到了类似的结论。 对于 ACM,结果表明 HAN 给予 PAP 的权重最大。 由于PAP 的性能略优于PSP,因此HANsem可以通过简单的平均运算获得良好的性能。 我们可以看到,语义级注意力可以揭示这些元路径之间的差异,并对它们进行适当的加权。
5.7. 可视化
为了更直观的比较,我们进行可视化任务,其目的是在低维空间上布局异构图。 具体来说,我们根据所提出的模型学习节点嵌入,并将学习到的嵌入投影到二维空间中。 在这里,我们利用 t-SNE (Maaten 和 Hinton,2008) 来可视化嵌入 DBLP 的作者,并根据他们的研究领域对节点进行着色。
从图6中,我们可以发现针对同构图设计的GCN和GAT表现不佳。 属于不同研究领域的作者相互混杂。Metapath2vec 的性能比上述同构图神经网络好得多。 它表明适当的元路径(例如,APCPA )可以对异构图分析做出重大贡献。 然而,由于metapath2vec只能考虑一条元路径,因此边界仍然模糊。 从图6可以看出HAN的可视化效果最好。 在多个元路径的引导下,HAN 学习的嵌入具有很高的类内相似性,并将不同研究领域的作者分隔开来,边界清晰。
5.8. 参数实验
在本节中,我们研究参数的敏感性,并在图 7 中报告具有各种参数的 ACM 数据集上的聚类结果 (NMI)。
• 最终嵌入的维度𝐙。 我们首先测试最终嵌入𝐙的维度的效果。 结果如图7(a)所示。 我们可以看到,随着embedding维度的增长,性能先上升,然后开始缓慢下降。 原因是HAN需要合适的维度来编码语义信息,较大的维度可能会引入额外的冗余。
• 语义级注意力向量𝐪的维度。 由于语义级注意力的能力受到语义级注意力向量𝐪维度的影响,因此我们探讨了不同维度的实验结果。 结果如图7(b)所示。 我们可以发现,HAN的性能随着语义级注意力向量的维度而增长,并且当𝐪的维度设置为128时达到最佳性能。 之后,HAN 的性能开始下降,这可能是由于过度拟合。
• 注意力头K的数量。 为了检查多头注意力的影响,我们探索了具有不同数量注意力头的 HAN 的性能。 结果如图7(c)所示。 请注意,当注意力头数量设置为 1 时,多头注意力将被移除。 从结果来看,我们可以发现,注意力头的数量越多,一般会提高HAN的性能。 然而,随着注意力头的改变,HAN 的性能仅略有提高。 同时,我们还发现多头注意力可以使训练过程更加稳定。
6. 结论
在本文中,我们解决了异构图分析中的几个基本问题,并提出了一种仅基于注意力机制的半监督异构图神经网络。 所提出的 HAN 可以捕获异构图背后的复杂结构和丰富语义。 所提出的模型利用节点级注意力和语义级注意力来分别学习节点和元路径的重要性。 同时,所提出的模型以统一的方式利用结构信息和特征信息。 分类和聚类等实验结果证明了 HAN 的有效性。 通过分析学习到的注意力权重(包括节点级和语义级),所提出的 HAN 证明了其潜在的良好可解释性。
References
- (1)
- Bahdanau et al. (2015)Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015.Neural machine translation by jointly learning to align and translate.ICLR (2015).
- Bruna et al. (2013)Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. 2013.Spectral networks and locally connected networks on graphs.arXiv preprint arXiv:1312.6203 (2013).
- Chen et al. (2018)Hongxu Chen, Hongzhi Yin, Weiqing Wang, Hao Wang, Quoc Viet Hung Nguyen, and Xue Li. 2018.PME: Projected Metric Embedding on Heterogeneous Networks for Link Prediction. In SIGKDD. 1177--1186.
- Chen and Sun (2017)Ting Chen and Yizhou Sun. 2017.Task-guided and path-augmented heterogeneous network embedding for author identification. In WSDM. 295--304.
- Cui et al. (2018)Peng Cui, Xiao Wang, Jian Pei, and Wenwu Zhu. 2018.A survey on network embedding.IEEE Transactions on Knowledge and Data Engineering (2018).
- Defferrard et al. (2016)Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. 2016.Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS. 3844--3852.
- Dong et al. (2017)Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017.metapath2vec: Scalable representation learning for heterogeneous networks. In SIGKDD. 135--144.
- Fan et al. (2018)Yujie Fan, Shifu Hou, Yiming Zhang, Yanfang Ye, and Melih Abdulhayoglu. 2018.Gotcha-sly malware!: Scorpion a metagraph2vec based malware detection system. In SIGKDD. 253--262.
- Fu et al. (2017)Tao-yang Fu, Wang-Chien Lee, and Zhen Lei. 2017.HIN2Vec: Explore Meta-paths in Heterogeneous Information Networks for Representation Learning. In CIKM. 1797--1806.
- Gori et al. (2005)Marco Gori, Gabriele Monfardini, and Franco Scarselli. 2005.A new model for learning in graph domains. In IJCNN, Vol. 2. 729--734.
- Goyal and Ferrara (2017)Palash Goyal and Emilio Ferrara. 2017.Graph embedding techniques, applications, and performance: A survey.arXiv preprint arXiv:1705.02801 (2017).
- Grover and Leskovec (2016)Aditya Grover and Jure Leskovec. 2016.node2vec: Scalable feature learning for networks. In SIGKDD. 855--864.
- Hamilton et al. (2018)Will Hamilton, Payal Bajaj, Marinka Zitnik, Dan Jurafsky, and Jure Leskovec. 2018.Embedding logical queries on knowledge graphs. In Advances in Neural Information Processing Systems. 2030--2041.
- Hamilton et al. (2017)William L. Hamilton, Rex Ying, and Jure Leskovec. 2017.Inductive Representation Learning on Large Graphs. In NIPS. 1024--1034.
- Han et al. (2018)Xiaotian Han, Chuan Shi, Senzhang Wang, S Yu Philip, and Li Song. 2018.Aspect-Level Deep Collaborative Filtering via Heterogeneous Information Networks.. In IJCAI. 3393--3399.
- Hu et al. (2018)Binbin Hu, Chuan Shi, Wayne Xin Zhao, and Philip S Yu. 2018.Leveraging Meta-path based Context for Top-N Recommendation with A Neural Co-Attention Model. In SIGKDD. 1531--1540.
- Kingma and Ba (2015)Diederik P Kingma and Jimmy Ba. 2015.Adam: A method for stochastic optimization.ICLR (2015).
- Kipf and Welling (2017)Thomas N. Kipf and Max Welling. 2017.Semi-Supervised Classification with Graph Convolutional Networks. In ICLR.
- Li et al. (2017)Xiang Li, Yao Wu, Martin Ester, Ben Kao, Xin Wang, and Yudian Zheng. 2017.Semi-supervised clustering in attributed heterogeneous information networks. In WWW. 1621--1629.
- Li et al. (2016)Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. 2016.Gated graph sequence neural networks.ICLR (2016).
- Maaten and Hinton (2008)Laurens Van Der Maaten and Geoffrey Hinton. 2008.Visualizing data using t-SNE.Journal of Machine Learning Research 9, 2605 (2008), 2579--2605.
- Ou et al. (2016)Mingdong Ou, Peng Cui, Jian Pei, Ziwei Zhang, and Wenwu Zhu. 2016.Asymmetric transitivity preserving graph embedding. In SIGKDD. 1105--1114.
- Perozzi et al. (2014)Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014.Deepwalk: Online learning of social representations. In SIGKDD. 701--710.
- Scarselli et al. (2009)Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. 2009.The graph neural network model.IEEE Transactions on Neural Networks 20, 1 (2009), 61--80.
- Schlichtkrull et al. (2018)Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. 2018.Modeling relational data with graph convolutional networks. In European Semantic Web Conference. Springer, 593--607.
- Shang et al. (2016)Jingbo Shang, Meng Qu, Jialu Liu, Lance M. Kaplan, Jiawei Han, and Jian Peng. 2016.Meta-Path Guided Embedding for Similarity Search in Large-Scale Heterogeneous Information Networks.CoRR abs/1610.09769 (2016).
- Shi et al. (2018a)Chuan Shi, Binbin Hu, Xin Zhao, and Philip Yu. 2018a.Heterogeneous Information Network Embedding for Recommendation.IEEE Transactions on Knowledge and Data Engineering (2018).
- Shi et al. (2017)Chuan Shi, Yitong Li, Jiawei Zhang, Yizhou Sun, and Philip S. Yu. 2017.A Survey of Heterogeneous Information Network Analysis.IEEE Transactions on Knowledge and Data Engineering 29 (2017), 17--37.
- Shi et al. (2018b)Yu Shi, Qi Zhu, Fang Guo, Chao Zhang, and Jiawei Han. 2018b.Easing Embedding Learning by Comprehensive Transcription of Heterogeneous Information Networks. In SIGKDD. ACM, 2190--2199.
- Sun et al. (2018)Lichao Sun, Lifang He, Zhipeng Huang, Bokai Cao, Congying Xia, Xiaokai Wei, and S Yu Philip. 2018.Joint embedding of meta-path and meta-graph for heterogeneous information networks. In 2018 IEEE International Conference on Big Knowledge (ICBK). 131--138.
- Sun and Han (2013)Yizhou Sun and Jiawei Han. 2013.Mining heterogeneous information networks: a structural analysis approach.Acm Sigkdd Explorations Newsletter 14, 2 (2013), 20--28.
- Sun et al. (2011)Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S Yu, and Tianyi Wu. 2011.Pathsim: Meta path-based top-k similarity search in heterogeneous information networks.VLDB 4, 11 (2011), 992--1003.
- Tang et al. (2015)Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. 2015.Line: Large-scale information network embedding. In WWW. 1067--1077.
- Vaswani et al. (2017)Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017.Attention is All you Need. In NIPS. 5998--6008.
- Veličković et al. (2018)Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018.Graph Attention Networks.ICLR (2018).
- Wang et al. (2016)Daixin Wang, Peng Cui, and Wenwu Zhu. 2016.Structural deep network embedding. In SIGKDD. 1225--1234.
- Wang et al. (2017)Xiao Wang, Peng Cui, Jing Wang, Jian Pei, Wenwu Zhu, and Shiqiang Yang. 2017.Community Preserving Network Embedding.. In AAAI. 203--209.
- Xu et al. (2015)Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. 2015.Show, attend and tell: Neural image caption generation with visual attention. In ICML. 2048--2057
本篇论文理论部分就分享到这里,接下来会给大家进行代码讲解~