一、Linear
如果一个事情可以用数字表示,那么他的结论就可以用线性变换来表示
举个例子:
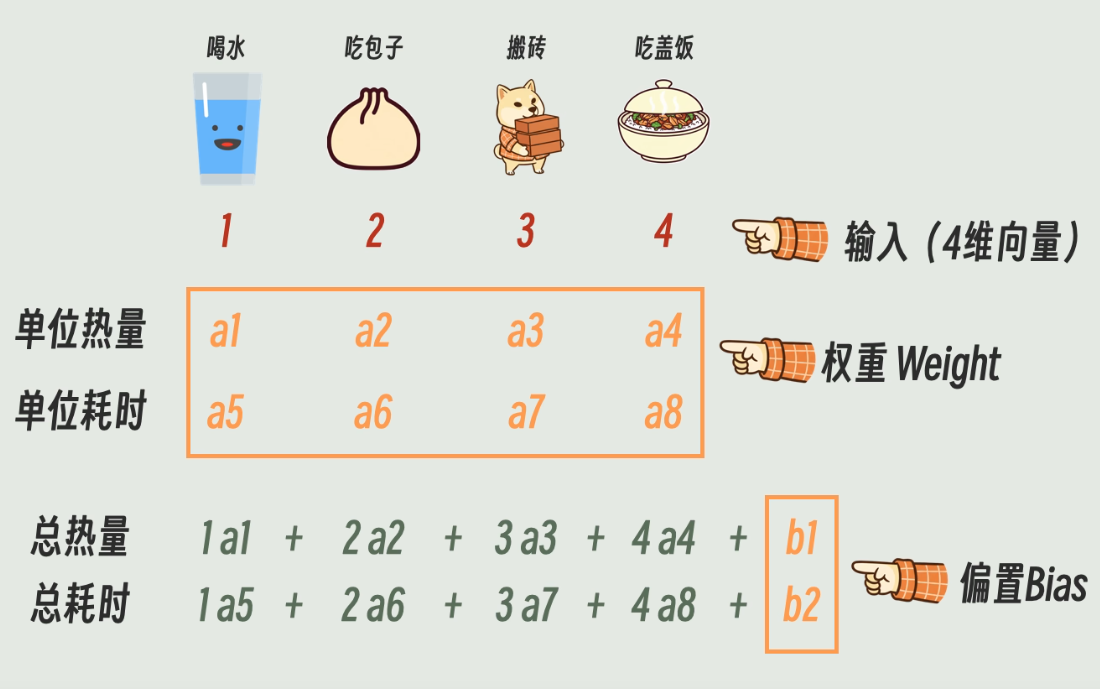
例如我们现在设计一个吃货模型,模型输出的结果是一天摄取的总热量和总耗时,此时模型的输入为一个四维向量、输出为一个二维向量,这就是一个最简单的线性变换模型。
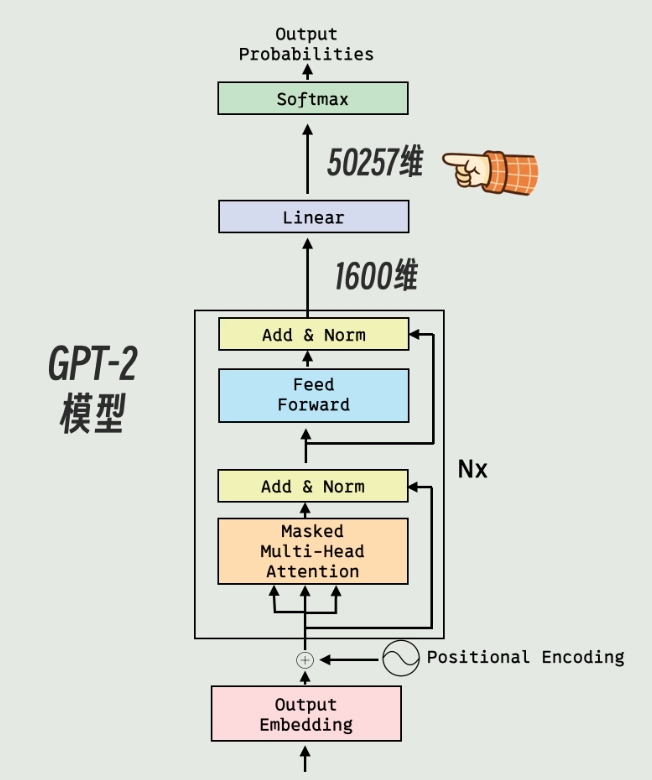
而GPT-2中的Linear所做的工作就是类似这样的,Linear的输入是1600维向量,输出是50257维向量,代表GPT-2中认识的每一个token和输入的匹配程度,匹配程度越高GPT会把该token作为下一个输出的token。
上述举例的简单模型和GPT-2的还有一个差距就是,简单模型中的权重是我们可以定义出来的,而GPT-2中的参数都是训练出来的。
拿我们的简单模型举例,我们的输入是喝水、吃包子、搬砖、吃盖饭的数量,他们代表的热量和耗时(模型的参数)为一个随机数,我们拿实际摄入的数量和实际的热量和耗时来对比,如果差别很大那就用梯度下降算法来微调随机数数值,知道输出和实际情况已经差不多,这套模型的参数就可以确定了,在中我们不需要关注模型的参数代表的是什么,我们只需要关注模型的目的可以计算出热量和耗时。
在模型训练中我们关注的是模型的目的是什么,而不是参数是什么(黑盒)
二、激活函数(Activation)
上述例子中我们的模型通过y=ax+b的方式表示,在坐标轴中表示就是一条直线,但是现实情况中并非所有的结果映射都是一条直线,如果我们想获得一条曲线类的结果呢?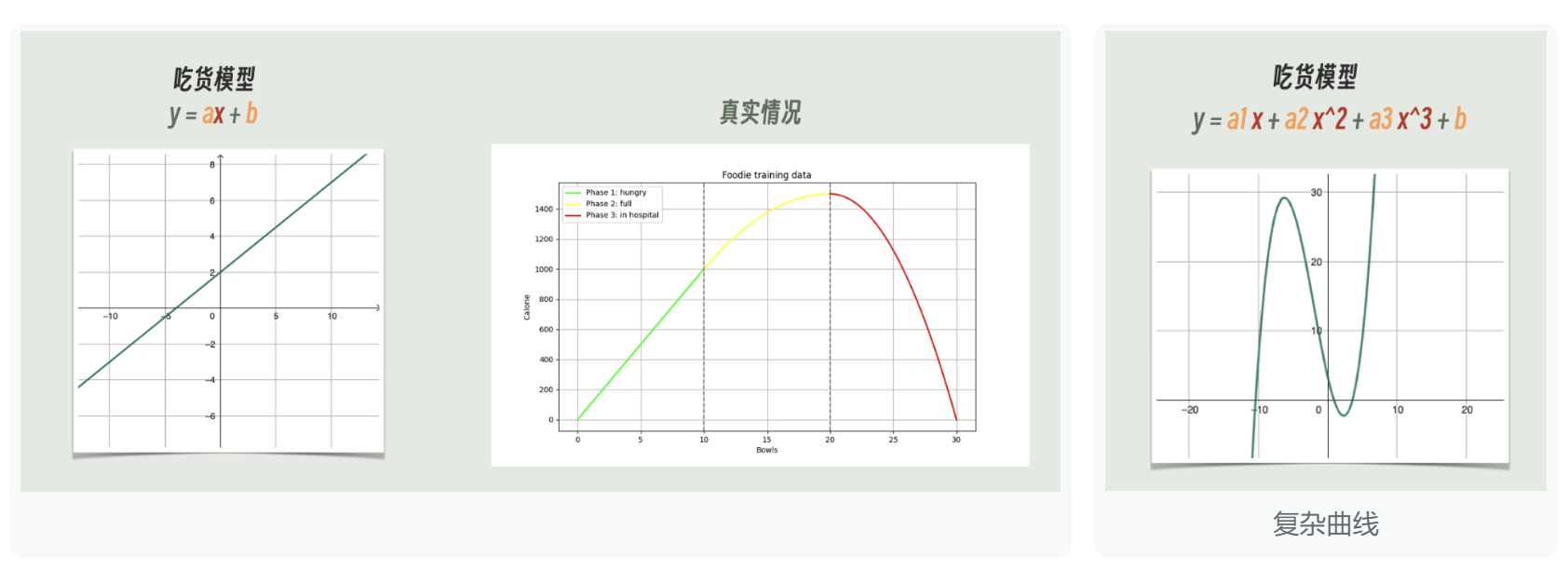
理论上我们可以通过更加复杂的数学公式来模拟出来曲线,但是在工程上行不通,原因如下:
- 训练困难:过于复杂导致无法训练。
- 通用性差:过于复杂的公式导致模型不具有通用性。
那我们如何把一个线性的计算转化为非线性的计算呢?
我们只需要在线性变换中加上一个非线性的函数,也就是激活函数。

常见的激活函数:
这几个常见的激活函数看起来很简单,但是如果其足够重要,那么就能在训练中被后续的线性变化无限放大。
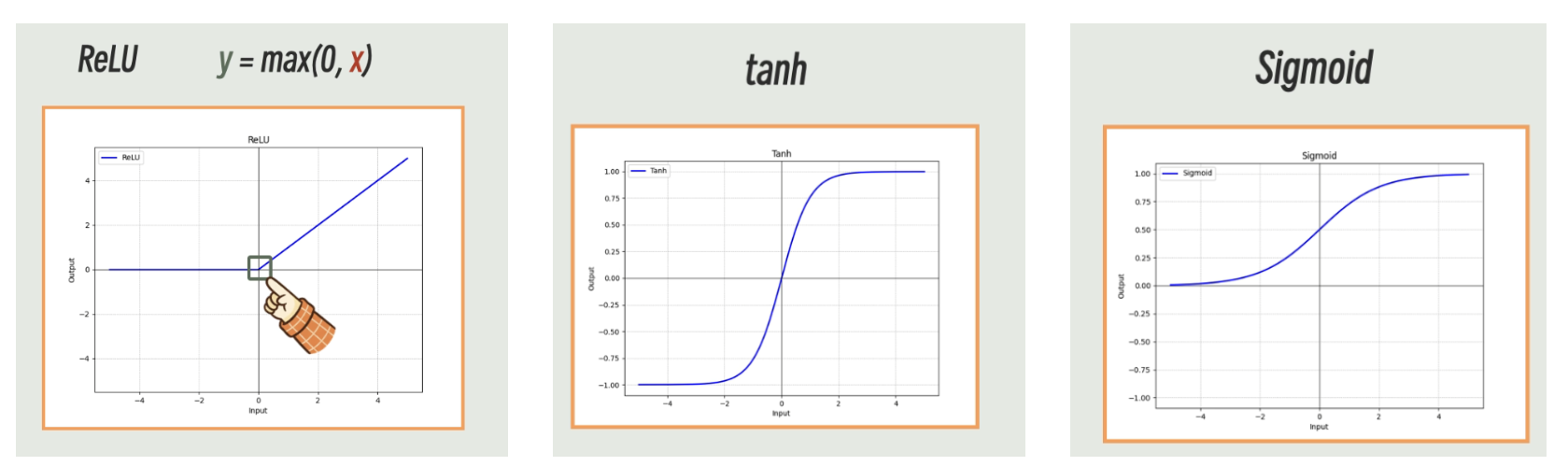
我们看起来ReLU非常简单就是粗暴的将所有的负数都改成了0,看起来好像作用不是很大,但是在工程中因为训练发现tanh、Sigmoid的效果差不多,但是又因为ReLU的表达式太简单了,在训练中的优势极其大,所以逐渐取代了tanh和Sigmiod;
ReLU激活函数的优势:
- 训练简单:ReLU的表达式太简单了,在训练中的优势极其大
- 梯度消失:因为tanh和Sigmiod在输入极大的时候输出的变化很小,但是ReLU没有这个问题。
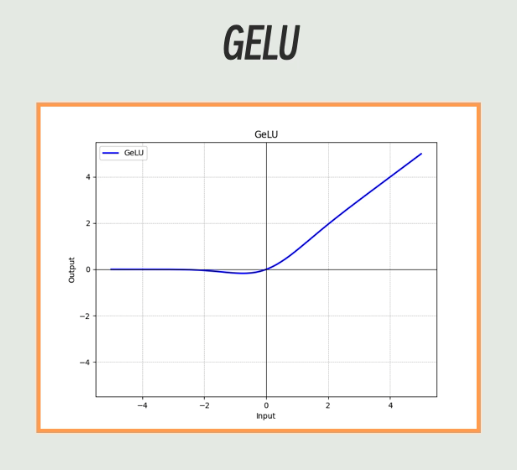
后面又出了ReLU函数的改良版,这个函数保留了ReLU的计算优势,又没有完全舍去负数的变化
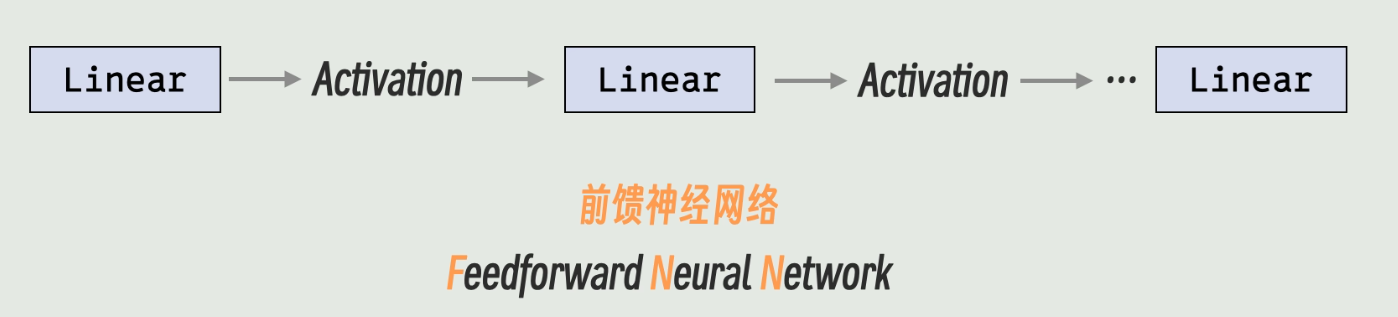
三、前馈神经网络(FNN)
我们的激活函数只是一个常量,它不存在参数训练调整的功能,只是为了引入非线性变化,我们通过Linear+Activation循环的形式组成的架构就叫做前馈神经网络(FNN),也叫多层感知机(MLP)