------复用的艺术,多态的灵魂
第一章 继承:代码复用的基石
1.1 为什么需要继承?
想象一下,你正在开发一个学校管理系统。这个系统需要处理两类人:学生 和老师。在C语言时代,你可能会这样写:
c
// C语言风格的代码
struct Student {
char name[20];
int age;
char address[100];
char tel[20];
int studentID; // 学号
float score; // 成绩
};
struct Teacher {
char name[20];
int age;
char address[100];
char tel[20];
char title[20]; // 职称
float salary; // 工资
};仔细看这两个结构体,你会发现大量的重复:姓名、年龄、地址、电话 这些字段在两个结构体中一模一样。这就是所谓代码冗余。冗余不仅让代码变长,更严重的是:如果将来系统升级,需要给所有人增加一个"邮箱"字段,你得同时修改两个地方,万一漏改一个,就会出大问题。
继承 就是为解决这个问题而生的。它允许我们先定义共同的部分 (比如"人"),然后让"学生"和"老师"自动拥有这些共同部分,同时再添加自己特有的部分。这就好比现实世界中,学生和老师首先都是"人",他们天然拥有人的所有特征,然后才各自拥有自己的专属特征。
用C++的继承思想,我们可以这样组织:
cpp
// 先定义"人"这个共同基础
class Person {
string name;
int age;
string address;
string tel;
};
// 学生是"人"的一种特殊形式
class Student : public Person {
int studentID; // 学生独有的学号
float score; // 学生独有的成绩
};
// 老师也是"人"的一种特殊形式
class Teacher : public Person {
string title; // 老师独有的职称
float salary; // 老师独有的工资
};这样写,Student和Teacher就自动拥有了 Person的所有成员变量,不需要重复书写。这就是代码复用------继承最直观的价值。
1.2 继承的基本概念
在正式学习语法之前,我们先明确几个关键术语:
| 术语 | 英文 | 含义 |
|---|---|---|
| 基类 | Base Class | 被继承的类,也叫父类 |
| 派生类 | Derived Class | 通过继承产生的新类,也叫子类 |
| 单继承 | Single Inheritance | 一个派生类只有一个直接基类 |
| 多继承 | Multiple Inheritance | 一个派生类有多个直接基类 |
继承的本质可以概括为三个字:"is-a" (是一个)。学生是一个 人,老师也是一个人。这种"is-a"关系是使用继承的根本判断标准。如果你无法用"is-a"描述两个类的关系,那就不应该用继承。
"is-a"与"has-a"的区别
判断是否应该使用继承,关键在于区分"is-a"和"has-a"关系。
- "is-a"(是一个) :派生类是基类的一种特殊形式。例如,
Circle是一个Shape;Student是一个Person。这种关系通常使用公有继承 来实现。特点是:- 派生类自动获得 基类的所有成员(除了构造函数、析构函数等特殊函数),无需重新声明(即可以直接使用,如
Student.name)。 - 继承是编译期决定的静态关系,耦合度高,子类与父类紧密绑定。
- 派生类可以重写(override)基类的虚函数,实现多态行为。
- 派生类自动获得 基类的所有成员(除了构造函数、析构函数等特殊函数),无需重新声明(即可以直接使用,如
- "has-a"(有一个) :一个类包含另一个类的对象作为成员。例如,
Car有一个Engine;Person有一个Address。这种关系应该使用组合 (composition)或聚合 (aggregation)来实现,而不是继承。特点是:- 通过包含对象来复用其功能,而不是继承(需要通过
外部对象.内部对象.属性/方法调用,如Car.engine.start();)。 - 组合是"黑盒"复用:只知道被包含对象的公有接口,不关心其内部实现。
- 组合关系更灵活,可以在运行时动态替换组件(例如使用指针)。
- 通过包含对象来复用其功能,而不是继承(需要通过
混淆"is-a"和"has-a"是初学者常犯的错误。例如,试图让Car继承Engine是不合理的,因为汽车不是一个发动机;正确的做法是在Car类中包含一个Engine类型的成员。
继承与组合的选择
虽然继承能实现代码复用,但过度使用继承可能导致类层次过深、耦合度增加,代码难以维护。现代C++编程提倡优先使用组合而非继承(Composition over Inheritance)。只有当两个类确实存在自然的"is-a"关系时,才考虑继承。
下面是一个简单的例子,展示如何判断:
cpp
// 合理的继承:Student is a Person
class Person { /* ... */ };
class Student : public Person { /* ... */ };
// 不合理的继承:Car is not an Engine
class Engine { /* ... */ };
class Car : public Engine { /* ... */ }; // 错误:Car 包含 Engine,而不是是一个 Engine
// 正确的组合:Car has an Engine
class Car {
Engine engine; // 组合
// ...
};继承的优缺点
优点:
- 代码复用,减少重复
- 清晰的层次结构,便于理解和维护
- 支持多态,提高程序扩展性
缺点:
- 基类的任何修改可能影响所有派生类,增加耦合
- 过度使用继承会导致类层次臃肿,难以维护
- 继承破坏了封装,派生类需要了解基类的实现细节
1.3 继承的基本语法
1.3.1 定义格式
C++中继承的语法非常简洁,允许派生类在声明时指定一个或多个基类(多继承将在后续章节讲解),其基本格式如下:
cpp
class 派生类名 : 继承方式 基类名 {
// 派生类新增的成员
};继承方式决定了派生类对基类成员的访问权限,有三种可选的继承方式:public(公有继承)、protected(保护继承)、private(私有继承)。如果省略继承方式,对于class定义的派生类,默认是private继承;对于struct定义的派生类,默认是public继承。
一个完整的继承示例
让我们通过一个完整的例子来理解继承是如何工作的:
cpp
#include <iostream>
#include <string>
using namespace std;
// 基类:人
class Person {
protected: // 注意这里用protected,后面解释
string name;
int age;
string address;
public:
void setBasicInfo(const string& n, int a, const string& addr) {
name = n;
age = a;
address = addr;
}
void showBasicInfo() const {
cout << "姓名:" << name << ",年龄:" << age << ",地址:" << address << endl;
}
};
// 派生类:学生
class Student : public Person { // public继承
private:
int studentID;
float score;
public:
void setStudentInfo(int id, float s) {
studentID = id;
score = s;
}
void showStudentInfo() const {
showBasicInfo(); // 调用基类的成员函数
cout << "学号:" << studentID << ",成绩:" << score << endl;
}
};
int main() {
Student stu;
stu.setBasicInfo("张三", 18, "北京市海淀区");
stu.setStudentInfo(2024001, 95.5f);
stu.showStudentInfo();
return 0;
}运行结果:
plain
姓名:张三,年龄:18,地址:北京市海淀区
学号:2024001,成绩:95.5这段代码清晰地展示了继承的几个关键点:
- 代码复用 :
Student类没有定义name、age、address等成员,却可以通过继承直接使用它们(通过基类的setBasicInfo和showBasicInfo成员函数)。 - 专注特有逻辑 :
Student类在setStudentInfo中只需处理学号和成绩,不需要重复编写基础信息的代码。 - 内存布局 :派生类对象的内存中,同时包含基类部分和派生类新增部分 。
Student对象除了拥有studentID和score,还隐式包含了基类Person的三个成员变量。
派生类定义时的注意事项
- 继承方式不能省略 :虽然
class默认是private继承,struct默认是public继承,但为了提高代码可读性,应显式写出继承方式。 - 基类必须已经定义:编译器需要知道基类的完整定义,因此基类必须在使用它之前定义(或至少前置声明,但通常需要完整定义才能确定内存布局)。
- 可以继承多个基类:C++支持多继承,即一个派生类可以同时从多个基类派生,用逗号分隔基类列表即可。
- 派生类可以添加新的成员:派生类可以添加自己的成员变量和成员函数,实现功能的扩展。
- 派生类不能继承基类的构造函数、析构函数、拷贝控制成员 (但C++11允许通过
using继承构造函数,详见类和对象篇,特殊构造函数章)。
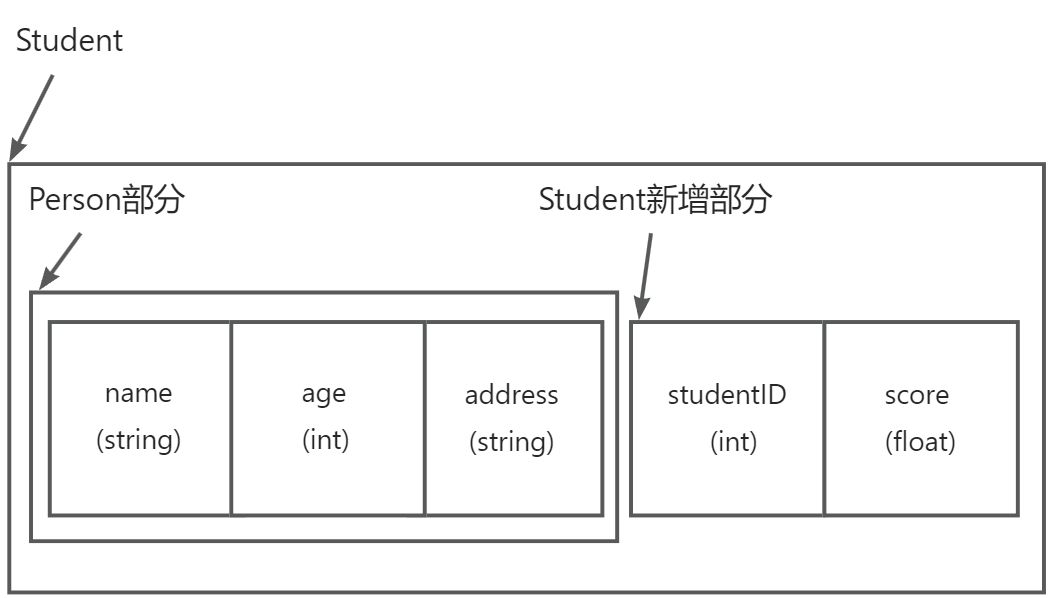
派生类对象的内存布局
当一个派生类对象被创建时,它的内存布局是:基类部分先于派生类新增部分 。以Student对象为例,内存中首先存储Person的三个成员(name、age、address),然后才是Student自己的studentID和score。这种布局确保了基类指针可以安全地指向派生类对象(指向基类部分),实现多态的基础。
多继承的格式
当一个派生类需要同时从多个基类继承时,使用逗号分隔基类列表:
cpp
class 派生类名 : 继承方式1 基类1, 继承方式2 基类2, ... {
// 派生类新增成员
};多继承的更多细节将在后续章节深入探讨。
1.3.2 继承方式与访问控制
在C++中,继承方式有三种:public、protected、private。它们与基类成员的访问限定符共同作用,决定了派生类对基类成员的访问权限。理解这些规则是掌握继承机制的基础。
1.3.2.1 基本规则
派生类对基类成员的访问权限遵循一个简洁的规则:派生类能访问的基类成员权限** = min(基类中的访问权限, 继承方式)**。这里的"min"可以理解为更严格的访问级别,其中 private < protected < public。
下表总结了所有组合下的结果:
| 继承方式 | 基类成员权限 | 在派生类中的权限 | 说明 |
|---|---|---|---|
public |
public |
public |
基类的公有成员仍是公有 |
public |
protected |
protected |
基类的保护成员仍是保护 |
public |
private |
不可见 | 基类的私有成员不能访问 |
protected |
public |
protected |
权限降级为保护 |
protected |
protected |
protected |
保持不变 |
protected |
private |
不可见 | 基类的私有成员不能访问 |
private |
public |
private |
权限降级为私有 |
private |
protected |
private |
权限降级为私有 |
private |
private |
不可见 | 基类的私有成员不能访问 |
核心要点:
- 基类的
private成员永远不可直接访问:无论使用何种继承方式,派生类都无法直接访问基类的私有成员。这是封装性的根本体现------基类不想暴露的,派生类也不能"偷看"。如果需要访问,必须通过基类提供的公有或保护成员函数。 - 继承方式决定"门槛" :
public继承保持原有访问权限(public→public,protected→protected)。protected继承把基类的public成员降级为protected,而protected成员保持不变。private继承把所有非私有成员(即public和protected)都降级为private。
1.3.2.2 详细示****例
我们通过一个具体的类继承关系来演示这些规则。
cpp
#include <iostream>
using namespace std;
class Base {
private:
int privateVal = 1; // 私有成员
protected:
int protectedVal = 2; // 保护成员
public:
int publicVal = 3; // 公有成员
};
// 公有继承
class PublicDerived : public Base {
public:
void show() {
// cout << privateVal;
// 错误:无法访问基类私有成员,该类中不可见,该类的派生类不可见,外部不可见
cout << protectedVal;
// 正确:保护成员在该类中可见,该类的派生类中可见,外部不可见
cout << publicVal;
// 正确:公有成员在该类中可见,该类的派生类中可见,外部可见
}
};
// 保护继承
class ProtectedDerived : protected Base {
public:
void show() {
// cout << privateVal;
// 错误:无法访问基类私有成员,该类中不可见,该类的派生类不可见,外部不可见
cout << protectedVal;
// 正确:保护成员在该类中可见,该类的派生类中可见,外部不可见
cout << publicVal;
// 正确:公有成员被降级为(该类的)保护,在该类中可见,该类的派生类可见,外部不可见
}
};
// 私有继承
class PrivateDerived : private Base {
public:
void show() {
// cout << privateVal;
// 错误:无法访问基类私有成员,该类中不可见,该类的派生类不可见,外部不可见
cout << protectedVal;
// 正确:保护成员被降级为(该类的)私有,在该类中可见,该类的派生类不可见,外部不可见
cout << publicVal;
// 正确:公有成员被降级为(该类的)私有,在该类中可见,该类的派生类不可见,外部不可见
}
};
int main() {
PublicDerived pub;
// pub.privateVal = 10; // 错误:私有成员不可见
// pub.protectedVal = 20; // 错误:保护成员在外部不可访问
pub.publicVal = 30; // 正确:公有继承下基类的公有成员在外部可见
ProtectedDerived prot;
// prot.publicVal = 30; // 错误:保护继承后,基类的公有成员在外部不可见(已被降级为保护)
// prot.protectedVal = 20; // 错误:保护成员在外部不可见
PrivateDerived priv;
// priv.publicVal = 30; // 错误:私有继承后,基类所有成员在外部都不可见
// priv.protectedVal = 20; // 错误:同上
}不同继承方式的语义
public** 继承**:表示"is-a"(是一种)关系。派生类对象可以替代基类对象使用(赋值兼容规则),基类的公有接口对外暴露。这是最常用的继承方式,用于建立类型层次结构。protected** 继承**:表示"implemented-in-terms-of"(用...来实现)关系。基类的公有接口变为保护接口,仅在派生类及其子类内部可见。这种继承主要用于表达"基类是派生类实现的一部分"的设计意图,常用于框架中的实现类。private** 继承**:同样表示"implemented-in-terms-of"关系,但更彻底------基类的所有非私有成员在派生类外部完全隐藏,仅在派生类内部可见。它常用于通过继承来复用基类的实现,而不希望对外暴露基类的接口。实际上,private继承与"组合"(has-a)非常相似,后者通常更简单直观,但某些场景下(如需要访问基类的保护成员或重写虚函数)private继承是必要的。
成员访问的两种视角
理解访问权限时,要区分两个概念:
- 派生类内部(成员函数)能访问什么 :取决于基类成员在派生类中的"最终权限"。即
min(基类权限, 继承方式)的结果。只要最终权限是protected或public,派生类成员函数就能访问。 - 派生类对象(外部)能访问什么 :取决于派生类中该成员的最终权限是否为
public。只有最终权限是public的成员才能被外部代码通过派生类对象访问。
例如,在 protected 继承下,基类的 public 成员最终权限是 protected,因此派生类内部可以访问,但派生类对象外部不能访问。
访问权限的进一步说明
private** 成员虽不可直接访问,但仍存在于派生类对象中**。它们可以通过基类提供的公有或保护成员函数间接访问。protected** 成员**在派生类内部可访问,但任何外部代码(包括通过派生类对象)都不能直接访问。- 继承方式仅影响派生类对基类成员的访问权限,不改变基类成员本身的权限 。基类中
private的成员永远不会变成protected或public,只是被"隐藏"了。
1.3.3 protected 访问限定符
你可能注意到了,在之前的例子中,我们把基类Person的成员设为protected。为什么不用public?为什么不用private?
在面向对象编程中,类的成员访问限定符是封装机制的具体体现。private 和 public 分别代表了最严格的隐藏和最彻底的开放。然而,在实际的类层次设计中,我们常常需要一种"中间地带":既希望派生类能够访问某些成员(以实现代码复用和功能扩展),又不想将这些成员暴露给完全无关的外部代码。这就是 protected 访问限定符存在的意义。
**protected**** 的设计目的**
protected 成员是一种特殊的成员,它在类内 和派生类内 可访问,但在类外不可访问。这种设计恰到好处地平衡了封装性与继承性:
- 封装性:保护成员不被外部无关代码直接操作,防止对象状态被随意篡改。
- 继承性:允许派生类在实现自己的逻辑时,直接使用基类的某些内部数据或操作,避免重复代码,同时保持对外隐藏。
简单来说,protected 是专为"家族内部"(即派生类)设计的接口,而 public 是对外的公开接口,private 是仅限自己使用的内部秘密。
protected** 与 private 、public 的对比**
通过一个直观的例子来理解三者的区别:
cpp
class Person {
private:
string privateSecret; // 仅本类成员可访问
protected:
string familyName; // 本类及派生类成员可访问
public:
string publicName; // 任何地方都可访问
};
class Student : public Person {
public:
void test() {
// privateSecret = "123"; // 错误!不能访问基类私有成员
familyName = "张"; // 正确!可以访问基类保护成员
publicName = "张三"; // 正确!可以访问基类公有成员
}
};
int main() {
Student stu;
// stu.familyName = "李"; // 错误!保护成员类外不能访问
stu.publicName = "李四"; // 正确!公有成员类外可以访问
}总结:
private:只有本类内部可以访问,派生类也不行,是最严格的封装。protected:本类和派生类内部可以访问,类外不行,是面向继承体系开放的接口。public:任何地方都可以访问,是完全公开的接口。
多层继承中的 protected 成员
protected 成员会沿着继承链向下传递,但受中间继承方式的影响。如果中间某层使用了 private 继承,则其后的派生类将无法访问原本是 protected 的成员(因为已被降级为私有)。这正是"权限不会在继承中自动恢复"原则的体现。
cpp
class GrandBase {
protected:
int value = 100;
};
class Parent : public GrandBase { }; // value 在 Parent 中仍为 protected
class Child1 : public Parent {
public:
void show() { cout << value << endl; } // 正确:value 仍为 protected
};
class Child2 : private Parent { };
class GrandChild2 : public Child2 {
public:
// void show() { cout << value << endl; } // 错误:value 在 Child2 中已变为 private
};protected 的典型应用场景
- 提供派生类可用的实现细节
基类可以为派生类预留一些内部接口,供其重写或直接使用。例如,在模板方法模式中,基类定义一个算法骨架,将某些步骤声明为protected虚函数,让派生类重写以提供具体实现。
cpp
class Game {
protected:
virtual void initialize() { /* 默认实现 */ }
virtual void startPlay() { /* 默认实现 */ }
virtual void endPlay() { /* 默认实现 */ }
public:
void play() { // 模板方法
initialize();
startPlay();
endPlay();
}
};
class Chess : public Game {
protected:
void initialize() override { /* 棋类初始化 */ }
void startPlay() override { /* 开始对局 */ }
void endPlay() override { /* 结束对局 */ }
};- 允许派生类访问基类的数据成员
有时基类需要让派生类直接操作某些数据成员,但又不希望外部代码看到。将这些数据成员设为protected即可。
cpp
class Shape {
protected:
double area; // 派生类可以直接计算并设置 area
};
class Circle : public Shape {
public:
void computeArea(double r) { area = 3.14 * r * r; }
};- 实现"组合/私有继承"时的内部复用
当使用private继承时,基类的protected成员在派生类中变为private,但仍然是可用的,这为派生类提供了复用的能力,而外部完全不可见。
使用建议与最佳实践
- 优先使用
public继承 +protected成员 :当派生类需要访问基类的某些内部成员时,将这些成员声明为protected,而不是public,以避免外部代码直接操作。 - **不要滥用 **
protected:过度暴露protected成员会破坏封装,使派生类与基类紧密耦合。尽量提供成员函数(protected或public)来间接操作数据,而不是直接暴露数据成员。 - **考虑使用 **
private继承 +protected成员函数 :如果派生类仅需要读/写某个内部状态,可以在基类中提供protected的成员函数(如getX()和setX()),而不是直接暴露数据成员。这样日后修改实现时,只需调整这些函数,不影响派生类代码。 - **对于纯虚函数(后续章节介绍),通常声明为 **
protected:因为这些函数是供派生类重写的内部接口,不应被外部直接调用。 - 在接口与实现分离的设计中 ,基类通常将具体实现细节放在
protected区域,将公共接口放在public区域,将完全内部细节放在private区域。
1.3.4 struct和class的默认继承方式
C++中,struct和class除了默认访问权限不同,默认继承方式也不同:
- 用
class定义的派生类,如果不写继承方式,默认是private - 用
struct定义的派生类,如果不写继承方式,默认是public
cpp
class Base { };
class Derived1 : Base { }; // 等价于 private Base
struct Derived2 : Base { }; // 等价于 public Base不过在实际编码中,强烈建议显式写出继承方式,不要依赖默认值。代码的可读性和可维护性比少敲几个字母重要得多。
1.4 赋值兼容转换(切片)
注意:该小节内容与多态关联及其密切,其中会提到一些还未讲解的知识,建议先学习1.4.1和1.4.2节,在后续学习完虚函数表章节后,完整学习该小节。
在面向对象编程中,公有继承建立了"is-a"关系:派生类对象是一种特殊的基类对象。这种关系赋予了派生类对象一种特殊的能力------它可以被当作基类对象来使用。C++允许将派生类对象赋值给基类对象、基类指针或基类引用,这个过程称为赋值兼容转换 ,其中对象赋值时会发生切片(slicing)。理解这个机制是掌握多态的基础。
1.4.1 什么是赋值兼容转换?
赋值兼容转换指的是:在公有继承体系下,派生类对象可以安全地转换为基类对象(或基类指针/引用)。这种转换是编译器自动允许的,因为它符合"派生类是一种基类"的语义。
cpp
#include <iostream>
#include <string>
using namespace std;
class Person {
protected:
string name;
int age;
public:
Person(const string& n = "", int a = 0) : name(n), age(a) {}
void show() const {
cout << "Person: " << name << ", " << age << endl;
}
};
class Student : public Person {
private:
int studentID;
public:
Student(const string& n = "", int a = 0, int id = 0)
: Person(n, a), studentID(id) {}
void showStudent() const {
cout << "Student: " << name << ", " << age << ", ID:" << studentID << endl;
}
};派生类对象可以赋值给基类对象(切片)
cpp
int main() {
Student stu("张三", 18, 1001);
// 派生类对象赋值给基类对象
Person p = stu; // 将stu中属于Person的部分拷贝给p
p.show(); // 输出:Person: 张三, 18
}这里的赋值操作会将stu对象中从Person继承的那部分数据(name和age)复制给p,而派生类自己新增的成员(studentID)被"切掉"了。这就是切片(slicing)名字的由来------派生类对象像被切片一样,只留下了基类部分。
派生类指针/引用可以赋值给基类指针/引用
cpp
// 派生类指针赋值给基类指针
Person* pp = &stu; // pp指向stu的基类部分
pp->show(); // 输出:Person: 张三, 18
// 派生类引用赋值给基类引用
Person& rp = stu; // rp引用stu的基类部分
rp.show(); // 输出:Person: 张三, 18指针和引用的赋值并不发生数据拷贝,只是让基类指针/引用指向派生类对象的基类部分,派生类的全部信息得以保留。这种方式是后续实现多态的基础。
1.4.2 为什么允许这样转换?
这种转换之所以合法,是因为派生类对象的内存布局中包含一个完整的基类子对象。例如,Student对象的内存布局是:
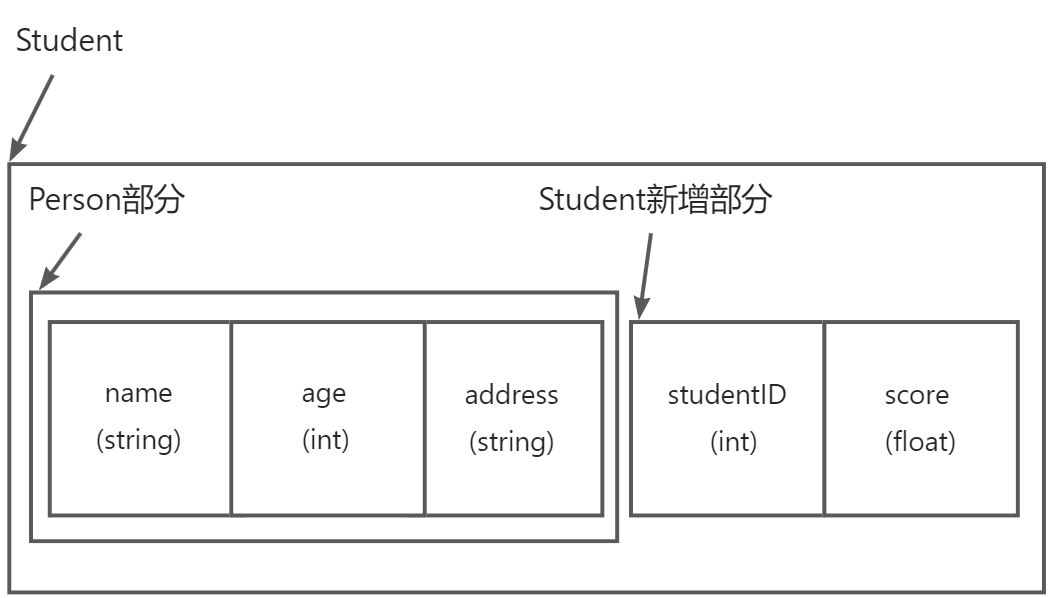
当我们将Student对象赋值给Person对象时,编译器只取前一部分(基类子对象)进行拷贝,这总是安全的,因为基类子对象确实存在。当我们将Student指针赋值给Person指针时,Person*指向的是Student对象中基类子对象的起始地址,这也是合法的。
1.4.3 切片带来的问题
切片会导致派生类特有的信息丢失。如果后续通过基类对象操作,将无法访问派生类成员。例如:
cpp
Person p = stu; // 切片:studentID丢失
// p.showStudent(); // 错误!Person对象没有showStudent成员切片通常不是我们想要的结果,因为它破坏了对象的完整性 。切片的本质是将派生类对象中基类子对象的数据拷贝到基类对象中,但派生类对象的vptr不会被拷贝 ------因为基类对象有自己的vptr,并且它是在构造时 就被设置为指向基类虚表的。
cpp
Student stu;
Person p = stu; // 切片赋值这里的p是一个全新的Person对象,它的 **vptr**指向 **Person**类的虚表 (由Person的构造函数设置)。因此,通过p调用show()时,永远调用的是Person::show,而不是Student::show。派生类的虚函数信息在切片过程中被彻底丢弃。
切片在函数参数传递中的陷阱
当函数参数为基类类型,而传入派生类对象时,会发生切片:
cpp
void func(Person p) { // 按值传递基类对象
p.show();
}
int main() {
Student stu("张三", 18, 1001);
func(stu); // 切片:stu的studentID被切掉,func内只看到Person部分
}这种隐式切片可能带来难以发现的错误,特别是当基类有虚函数时,派生类重写的虚函数将无法被调用(因为对象被切片后,虚表指针指向基类的虚表)。因此,在涉及多态的场景中,函数参数应优先使用基类的指针或引用,而不是按值传递。
1.4.4 反向转换的限制与危险
基类对象不能赋值给派生类对象
cpp
Person p("李四", 20);
Student stu;
// stu = p; // 错误!编译器不允许原因很简单:派生类对象需要包含基类部分(name和age),但还包含派生类自己的成员(如studentID)。如果允许基类对象赋值给派生类对象,那么派生类对象中的额外成员将无法被赋值,导致对象状态不完整。编译器直接禁止这种操作。
基类指针不能直接指向派生类,但可以通过强制转换指向,然而极不安全
cpp
Person p("王五", 22);
Student* sp = (Student*)&p; // 强制转换,编译通过
// sp->showStudent(); // 运行时可能崩溃!这里sp指向的是一块只有Person部分的内存,但代码却试图通过sp访问Student特有的成员studentID,这将访问到未知内存,导致未定义行为(可能崩溃、数据错误等)。这种转换是危险的,除非你能保证指针实际指向的是派生类对象,否则绝对不要使用。
1.4.5 安全使用原则
- 向上转换(派生类→基类)是安全的:可以将派生类对象赋给基类对象、基类指针、基类引用,这不会引起内存错误,只是可能会丢失派生类信息(切片)。
- 向下转换(基类→派生类)需要谨慎 :
- 如果基类指针确实指向派生类对象,那么通过
dynamic_cast(后续章节介绍)进行转换是安全的。 - 如果基类指针指向基类对象,绝对不要进行向下转换(即使通过强制类型转换也不行)。
- 如果基类指针确实指向派生类对象,那么通过
- 在需要多态时,使用基类指针或引用,而不是基类对象:这样可以避免切片,保留对象的完整类型信息。
1.4.6 切片与多态的关系
当基类中有虚函数时,切片会切断派生类与基类之间的多态联系。例如:
cpp
class Person {
public:
virtual void show() const { cout << "Person" << endl; }
};
class Student : public Person {
public:
void show() const override { cout << "Student" << endl; }
};
void func(Person p) {
p.show(); // 总是输出"Person",因为p被切片成了Person对象
}
int main() {
Student stu;
func(stu); // 输出"Person",而不是"Student"
}而使用指针或引用时,多态得以保留:
cpp
void func(Person* p) {
p->show(); // 根据实际指向的对象类型调用
}
func(&stu); // 输出"Student"这再次说明,在多态场景下,应使用基类指针或引用,避免按值传递。
1.4.7 如何避免切片?
- 函数参数使用指针或引用 :
void func(Person* p)或void func(Person& p) - 返回值使用指针或引用:当函数实际返回派生类对象但返回值类型为基类对象会发生切片,应返回指针或引用
- 容器存储指针 :如果容器需要存储多态对象,应使用基类指针(如
vector<Person*>),而不是基类对象(否则会发生切片) - 使用智能指针 :现代C++推荐使用
std::unique_ptr<Person>或std::shared_ptr<Person>来管理多态对象
1.5 继承中的作用域与名字隐藏
每个类都定义了自己的作用域,基类和派生类各有独立的作用域。当派生类中定义了与基类同名的成员时,会发生名字隐藏(Name Hiding,也称重定义)。名字隐藏是C++继承机制中的一个重要特性,理解它有助于避免代码中的歧义和错误。
1.5.1 成员变量的隐藏
当派生类定义了与基类同名的成员变量时,派生类的成员会隐藏基类的同名成员,但基类成员仍然存在于派生类对象中,只是被"遮挡"了,需要通过作用域解析运算符才能访问。
cpp
#include <iostream>
using namespace std;
class Base {
public:
int value = 100;
};
class Derived : public Base {
public:
int value = 200; // 隐藏了基类的value
void print() {
cout << "Derived::value = " << value << endl; // 200
cout << "Base::value = " << Base::value << endl; // 100(需指定作用域)
}
};
int main() {
Derived d;
d.print();
cout << "通过对象访问:" << d.value << endl; // 200
cout << "通过对象加作用域:" << d.Base::value << endl; // 100
}关键规则:
- 派生类成员隐藏基类同名成员,而不是覆盖或重载(重载要求在同一作用域内)。
- 隐藏发生在不同作用域(基类作用域 vs 派生类作用域),编译器在派生类作用域找到名字后,就不会再到基类作用域中查找。
- 通过
基类名::成员可以强制访问被隐藏的基类成员。
1.5.2 成员函数的隐藏
成员函数的隐藏规则比变量更严格:只要函数名相同,就会隐藏基类的所有同名函数,无论参数列表是否相同。这与函数重载完全不同------重载要求函数在同一作用域内,而派生类和基类是不同作用域。
cpp
#include <iostream>
using namespace std;
class Base {
public:
void func() {
cout << "Base::func()" << endl;
}
void func(int x) {
cout << "Base::func(int) x=" << x << endl;
}
};
class Derived : public Base {
public:
void func() { // 隐藏了基类所有的func
cout << "Derived::func()" << endl;
}
};
int main() {
Derived d;
d.func(); // 输出:Derived::func()
// d.func(10); // 错误!基类的func(int)被隐藏了
d.Base::func(10); // 正确:通过作用域调用
Base* p = &d;
p->func(); // 注意:这不是多态!只是静态绑定,调用Base::func()
p->func(10); // 正确:p是Base*,能看到Base的所有func
}这段代码揭示的重要现象:
- 隐藏是一刀切的 :只要派生类定义了一个名为
func的函数,基类中所有名为func的函数(无论参数列表如何)都会被隐藏。这是因为名字查找在派生类作用域找到func后,就停止继续向外(基类)查找,因此基类的其他重载版本被忽略。 - 隐藏与多态无关 :即使通过基类指针调用,也是根据指针的静态类型决定调用哪个版本(这里没有
virtual关键字)。所以p->func()调用的是Base::func(),而不是Derived::func()。 - 使用域操作符绕过隐藏 :
d.Base::func(10)可以显式访问被隐藏的基类函数。
隐藏与重载的区别
为了更清晰地理解隐藏与重载的区别,考虑以下对比:
| 特性 | 重载 | 隐藏 |
|---|---|---|
| 作用域 | 同一作用域(如同一类内) | 不同作用域(基类与派生类之间) |
| 函数名相同 | 是 | 是 |
| 参数列表 | 必须不同 | 可以相同也可以不同 |
| 基类同名函数 | 不涉及 | 被派生类函数隐藏 |
| 能否通过派生类对象访问基类版本 | 不适用 | 需使用作用域解析符基类名:: |
1.5.3 函数隐藏的更多细节
- 隐藏与函数签名无关
即使派生类函数的参数列表与基类函数完全不同,只要名字相同,基类的所有同名函数都会被隐藏。例如:
cpp
class Base {
public:
void show() {}
void show(int) {}
};
class Derived : public Base {
public:
void show(double) {} // 仅参数不同,但仍隐藏基类的两个show
};
int main() {
Derived d;
d.show(); // 错误!基类的show()被隐藏
d.show(1); // 错误!基类的show(int)被隐藏
d.show(1.0); // 正确:调用Derived::show(double)
}- 静态成员函数的隐藏
静态成员函数同样会被隐藏,但静态成员可以通过类名直接访问,因此即使隐藏,也可以通过基类::访问。
cpp
class Base {
public:
static void func() { cout << "Base" << endl; }
};
class Derived : public Base {
public:
static void func() { cout << "Derived" << endl; }
};
int main() {
Derived::func(); // 输出 Derived
Base::func(); // 输出 Base,未隐藏
Derived d;
d.func(); // 输出 Derived
d.Base::func(); // 输出 Base
}- 类型别名(typedef)的隐藏
类内部定义的类型别名(如typedef、using)也会被派生类中的同名类型别名隐藏。
cpp
class Base {
public:
using value_type = int;
};
class Derived : public Base {
public:
using value_type = double; // 隐藏Base::value_type
};
int main() {
Derived::value_type x = 3.14; // x是double
}- 多层继承中的名字隐藏
在多层继承中,名字隐藏会逐级传递,派生类中隐藏的成员在其之后的派生类中仍然可能被再次隐藏。
cpp
class GrandBase {
public:
int value = 10;
};
class Base : public GrandBase {
public:
int value = 20; // 隐藏 GrandBase::value
};
class Derived : public Base {
public:
int value = 30; // 隐藏 Base::value(同时隐藏 GrandBase::value)
};
int main() {
Derived d;
cout << d.value; // 30
cout << d.Base::value; // 20
cout << d.GrandBase::value; // 10
}1.5.4 如何解决名字隐藏问题
在实际开发中,如果派生类需要访问基类中所有被隐藏的重载函数,可以使用using声明将基类成员引入派生类作用域,从而消除隐藏。
cpp
class Base {
public:
void func() { cout << "Base::func()" << endl; }
void func(int) { cout << "Base::func(int)" << endl; }
};
class Derived : public Base {
public:
using Base::func; // 将基类的所有func引入派生类作用域
void func(double) { cout << "Derived::func(double)" << endl; }
};
int main() {
Derived d;
d.func(); // 调用 Base::func()
d.func(1); // 调用 Base::func(int)
d.func(1.0); // 调用 Derived::func(double)
}using声明将基类中所有名为func的函数带入派生类作用域,此时派生类的func(double)与基类版本构成重载 关系,而非隐藏。然而,这里有一个重要的细节需要深入探讨:如果派生类已经定义了与基类某个重载版本完全相同的函数(即同名同参数列表)会发生什么?
同名同参数的冲突处理
当派生类中已经存在一个与基类某个重载版本完全相同的函数时(包括参数类型、个数、返回类型和 const/volatile 限定符),使用using声明引入的基类同名函数不会 与派生类函数构成重载,而是被派生类函数隐藏 。这是因为 C++ 的规则规定:在同一个作用域中不能有两个完全相同的函数声明。using声明将基类函数引入派生类作用域后,如果派生类已有相同签名的函数,则基类版本被隐藏,无法通过派生类对象直接调用(除非使用作用域解析符显式指定基类)。
cpp
class Base {
public:
void func(int) { cout << "Base::func(int)" << endl; }
};
class Derived : public Base {
public:
using Base::func; // 试图引入 Base::func(int)
void func(int) { cout << "Derived::func(int)" << endl; } // 相同签名
};
int main() {
Derived d;
d.func(10); // 输出 Derived::func(int) ------ 派生类版本覆盖了基类版本
d.Base::func(10); // 输出 Base::func(int) ------ 仍可通过作用域访问
}在这个例子中,using Base::func 将基类的func(int)引入派生类作用域,但由于派生类已经定义了完全相同签名的func(int),基类版本被隐藏 ,因此通过d.func(10)调用的是派生类版本。不过,using声明仍然允许我们通过d.Base::func(10)显式调用基类版本。using声明并不是直接消除隐藏,只是将基类版本引入作用域。
如果派生类想同时保留基类版本并让它们参与重载,唯一的办法是不要在派生类中定义与基类相同签名的函数,或者改用不同的参数列表。
使用 using声明的其他注意事项
using声明可以引入基类的所有同名重载
只需写一次using Base::func;,即可引入基类中所有名为func的重载函数(无论参数列表如何)。这极大简化了代码。using声明不影响访问权限
基类中被引入的成员在派生类中的访问权限取决于基类中该成员的原始访问权限和继承方式。例如,基类的private成员即使在派生类中用using声明也无法访问。using声明可以用于构造函数的继承 (C++11 继承构造函数)
这是using的另一个重要应用,已在类和对象篇详细讨论。
第二章 派生类的默认成员函数
当类涉及继承时,六个默认成员函数(构造、拷贝构造、析构、赋值重载、取地址重载)的生成规则变得复杂。理解这些规则,是正确设计继承体系的关键。
2.1 派生类构造函数的正确写法
派生类的构造函数必须完成两个任务:
- 初始化基类部分:调用基类的构造函数
- 初始化派生类新增成员:通过初始化列表或构造函数体
2.1.1 基本原则
cpp
#include <iostream>
#include <string>
using namespace std;
class Person {
private:
string name;
int age;
public:
// 基类构造函数
Person(const string& n, int a) : name(n), age(a) {
cout << "Person构造函数" << endl;
}
// 基类默认构造函数
Person() : name(""), age(0) {
cout << "Person默认构造函数" << endl;
}
void show() const {
cout << "姓名:" << name << ",年龄:" << age << endl;
}
};
class Student : public Person {
private:
int studentID;
public:
// 正确写法:在初始化列表中调用基类构造函数
Student(const string& n, int a, int id)
: Person(n, a) // 调用基类带参构造
, studentID(id) {
cout << "Student构造函数" << endl;
}
// 如果不显式调用基类构造,会调用基类默认构造
Student(int id) : studentID(id) { // 隐式调用Person()
cout << "Student(int)构造函数" << endl;
}
void showStudent() const {
show(); // 调用基类成员函数
cout << "学号:" << studentID << endl;
}
};
int main() {
Student s1("张三", 18, 1001);
s1.showStudent();
cout << "----------------" << endl;
Student s2(1002); // 使用基类默认构造
s2.showStudent();
}运行结果:
plain
Person构造函数
Student构造函数
姓名:张三,年龄:18
学号:1001
----------------
Person默认构造函数
Student(int)构造函数
姓名:,年龄:0
学号:1002深入解析:
- 基类构造函数的选择 :派生类构造函数必须在其初始化列表中为基类部分指定一个构造函数。如果没有显式指定,编译器会尝试调用基类的默认构造函数(即无参或全缺省参数的构造函数)。如果基类没有默认构造函数,则必须显式调用。
- 基类构造函数的位置:基类构造函数的调用必须出现在初始化列表的最前面,且不能放在构造函数体内。这是因为基类子对象必须在派生类成员初始化之前完成构造。
- 多重继承的调用顺序:如果有多个基类,则按照派生类声明中基类出现的顺序依次调用它们的构造函数。
- 成员对象的初始化:成员对象的初始化顺序由它们在类中的声明顺序决定,与初始化列表中的书写顺序无关。
2.1.2 基类无默认构造函数的处理
如果基类没有提供默认构造函数,派生类必须在初始化列表中显式调用基类的带参构造函数,否则编译错误。
cpp
class Person {
private:
string name;
int age;
public:
Person(const string& n, int a) : name(n), age(a) {}
// 没有提供默认构造函数!
};
class Student : public Person {
private:
int studentID;
public:
// 错误:试图调用不存在的默认构造函数
// Student(int id) : studentID(id) {} // 编译错误!
// 正确:必须显式调用基类带参构造
Student(const string& n, int a, int id)
: Person(n, a), studentID(id) {}
};扩展说明 :
即使基类有多个带参构造函数,派生类可以选择调用其中任何一个。例如,Person类可能还提供了Person(int age, string name)这样的重载版本,派生类可以根据需要决定调用哪个。
cpp
class Person {
public:
Person(const string& n, int a) { }
Person(int a, const string& n) { } // 参数顺序不同
};
class Student : public Person {
public:
Student(const string& n, int a, int id) : Person(n, a), id(id) { } // 调用第一种
Student(int a, const string& n, int id) : Person(a, n), id(id) { } // 调用第二种
};2.1.3 构造函数的调用顺序
这是一个非常重要的知识点:构造函数的调用顺序严格按照 "先基类后派生类" 的原则。具体来说:
- 先调用基类的构造函数(按继承顺序,如果有多个基类,按声明顺序依次调用)
- 再执行派生类构造函数的初始化列表
- 最后执行派生类构造函数体
cpp
#include <iostream>
using namespace std;
class Member {
public:
Member(const string& name) {
cout << "Member " << name << " 构造" << endl;
}
};
class Base {
public:
Base() {
cout << "Base 构造" << endl;
}
};
class Derived : public Base {
private:
Member m1;
Member m2;
public:
Derived() : m2("m2"), m1("m1") { // 注意:初始化列表顺序与声明顺序不一致
cout << "Derived 构造" << endl;
}
};
int main() {
Derived d;
return 0;
}运行结果:
plain
Base 构造
Member m1 构造 // 尽管m1在初始化列表中写在后,但它先声明,所以先构造
Member m2 构造 // m2后声明,后构造
Derived 构造规则总结:
- 基类永远最先构造(不受初始化列表影响)
- 成员变量的构造顺序由声明顺序决定,与初始化列表书写顺序无关
- 派生类构造函数体最后执行
2.2 派生类拷贝构造函数
派生类的拷贝构造函数也必须负责基类部分的拷贝。所以必须在初始化列表调用基类的拷贝构造函数。
cpp
class Person {
private:
string name;
int age;
public:
Person(const string& n, int a) : name(n), age(a) {}
// 拷贝构造函数
Person(const Person& other) : name(other.name), age(other.age) {
cout << "Person拷贝构造" << endl;
}
};
class Student : public Person {
private:
int studentID;
public:
Student(const string& n, int a, int id) : Person(n, a), studentID(id) {}
// 派生类拷贝构造函数
Student(const Student& other)
: Person(other) // 调用基类拷贝构造,将other切片为Person部分
, studentID(other.studentID) {
cout << "Student拷贝构造" << endl;
}
};
int main() {
Student s1("张三", 18, 1001);
Student s2(s1); // 调用拷贝构造
}关键点 :Person(other) 这行代码利用了切片 ------other虽然是Student类型,但传递给Person的拷贝构造函数时,会自动提取它的基类部分进行拷贝。
扩展说明:
- 如果基类没有提供拷贝构造函数(例如基类禁止拷贝),则派生类的拷贝构造也会被隐式删除。
- 如果基类的拷贝构造函数是
private或=delete,则派生类的拷贝构造同样无法生成或调用。 - 拷贝构造函数的参数必须是
const引用,以避免无限递归。
如果派生类的拷贝构造函数没有显式调用基类拷贝构造,会发生什么?
cpp
class Student : public Person {
private:
int studentID;
public:
// 错误:没有调用基类拷贝构造
Student(const Student& other) : studentID(other.studentID) {
// 这里会隐式调用Person的默认构造函数!
}
};后果 :基类部分被默认构造 ,而不是拷贝构造!这意味着基类成员可能被初始化为默认值(如name为空,age为0),而不是从other中拷贝过来。这几乎肯定不是你想要的结果。
正确做法:始终在初始化列表中显式调用基类的拷贝构造函数,除非你明确知道基类默认构造是合适的(几乎从不是)。
2.3 派生类赋值运算符重载
赋值运算符重载比拷贝构造更复杂,主要因为不能通过初始化列表调用基类赋值,必须在函数体内显式调用。
cpp
class Student : public Person {
private:
int studentID;
public:
// 赋值运算符重载
Student& operator=(const Student& other) {
if (this != &other) { // 自赋值检查
Person::operator=(other); // 调用基类赋值!必须加Person::
studentID = other.studentID;
}
return *this;
}
};成员函数调用中的 **this**指针
在类的非静态成员函数内部,编译器会隐式地传递一个指向当前对象的指针,即this指针。当我们写 member_function(...) 时,编译器实际上会将其转换为 this->member_function(...)。也就是说,this是隐式存在的,不需要显式写出。
因此,在派生类成员函数中,Person::operator=(other)这种写法是合法的,它会被理解为 this->Person::operator=(other)------因为this是隐含的,而 Person:: 指明了要调用的函数是基类Person的成员。编译器会将当前对象(this)转换为基类指针,然后调用基类的赋值运算符。
为什么必须加 Person::?
因为派生类和基类的operator=函数构成隐藏 关系。如果直接写operator=(other),编译器会认为你在递归调用自己的赋值运算符,导致无限递归。因此必须通过作用域解析符指明调用的是基类的版本。
自赋值检查
自赋值是指将对象赋值给它自己,例如s = s;。如果没有自赋值检查,赋值过程会先释放当前对象的资源(如果派生类管理了资源),然后从源对象(即自己)拷贝,而此时资源已被释放,导致未定义行为。因此必须检查this != &other。
扩展:copy-and-swap 惯用法
为了提供强异常安全保证,可以在赋值运算符中使用 copy-and-swap 模式,它利用拷贝构造函数创建一个临时对象,然后交换当前对象与临时对象的资源。在继承体系中也可以采用类似手法,但要小心处理基类部分的交换。
cpp
Student& operator=(const Student& other) {
if (this != &other) {
Student temp(other); // 调用拷贝构造
swap(temp); // 自定义交换函数,交换所有成员(包括基类)
}
return *this;
}
void swap(Student& other) noexcept {
using std::swap;
Person::swap(other); // 交换基类部分
swap(studentID, other.studentID);
}返回值 :赋值运算符必须返回当前对象的引用(*this),以支持链式赋值(如a = b = c)。
2.4 派生类析构函数
析构函数的调用顺序与构造完全相反:先执行派生类析构体,然后自动调用基类析构。
cpp
class Person {
public:
~Person() {
cout << "Person析构" << endl;
}
};
class Student : public Person {
public:
~Student() {
cout << "Student析构" << endl;
// 这里结束后会自动调用Person的析构函数
}
};
int main() {
Student s;
return 0;
}运行结果:
plain
Student析构
Person析构特别提示 :析构函数在继承体系中有一个特殊处理------编译器会将析构函数的名字统一处理为destructor。这是为了实现多态析构做准备。
重要补充:虚析构函数
当通过基类指针删除派生类对象时,如果基类析构函数不是虚函数,将只调用基类析构,导致派生类部分无法正确释放资源,造成内存泄漏。因此,如果类可能被继承,其析构函数通常应声明为 virtual(虚析构函数将在后续章节详细讲解)。例如:
cpp
class Base {
public:
virtual ~Base() { } // 虚析构
};动态对象的析构顺序 :对于动态分配的对象(new创建),析构发生在delete时。如果对象有成员对象,析构顺序与局部对象相同:先执行派生类析构体,再析构成员对象,最后调用基类析构。
2.5 派生类默认成员函数生成规则总结
| 默认成员函数 | 编译器自动生成的行为 | 需要自定义的情况 |
|---|---|---|
| 默认构造 | 调用基类默认构造 + 调用成员默认构造 | 基类无默认构造,或需要特殊初始化 |
| 拷贝构造 | 调用基类拷贝构造 + 拷贝派生类成员 | 类管理资源(深拷贝需求),或基类拷贝构造不可用 |
| 移动构造 (C++11) | 调用基类移动构造 + 移动派生类成员 | 基类移动构造不可用,或需要特殊资源转移逻辑 |
| 拷贝赋值 | 调用基类拷贝赋值 + 拷贝派生类成员 | 类管理资源,或需要特殊赋值逻辑 |
| 移动赋值 (C++11) | 调用基类移动赋值 + 移动派生类成员 | 基类移动赋值不可用,或需要特殊资源转移逻辑 |
| 析构函数 | 执行派生类析构体 + 自动调用基类析构 | 类管理资源(需要释放),或需要虚析构 |
移动操作的生成规则:编译器只有在以下条件全部满足时才自动生成移动构造/移动赋值:
- 没有用户声明的拷贝构造、拷贝赋值、析构函数。
- 类的每个非静态成员都可移动(即拥有移动构造/移动赋值或可拷贝)。
=default** 与 **=delete:
- 可以使用
=default显式要求编译器生成默认版本的成员函数(例如Student() = default;)。 - 可以使用
=delete禁止某个成员函数(例如Student(const Student&) = delete;),这会使派生类也无法拷贝。
黄金法则:如果派生类需要自定义拷贝控制成员(拷贝构造、赋值、析构),通常意味着基类也需要相应处理,而且要在派生类的实现中显式调用基类的对应函数。移动操作同样需要显式调用基类的移动版本。
第三章 继承体系中的特殊成员
3.1 静态成员在继承中的表现
静态成员属于类,不属于对象。这个特性在继承体系中保持不变------无论派生类有多少层,整个继承体系共享唯一一份静态成员。派生类可以像使用基类静态成员一样使用它,但需注意静态成员的隐藏规则。
cpp
#include <iostream>
using namespace std;
class Person {
protected:
string name;
public:
Person(const string& n = "") : name(n) {
count++; // 每构造一个人,计数器+1
}
~Person() {
count--; // 每析构一个人,计数器-1
}
static int getCount() { return count; }
private:
static int count; // 统计人的数量
};
// 静态成员必须在类外定义,除非使用内联静态成员
int Person::count = 0;
class Student : public Person {
public:
Student(const string& n = "") : Person(n) {}
};
class Teacher : public Person {
public:
Teacher(const string& n = "") : Person(n) {}
};
int main() {
cout << "当前人数:" << Person::getCount() << endl; // 0
Person p1("张三");
Student s1("李四");
Teacher t1("王五");
cout << "当前人数:" << Person::getCount() << endl; // 3
cout << "通过Student访问:" << Student::getCount() << endl; // 3
cout << "通过Teacher访问:" << Teacher::getCount() << endl; // 3
{
Student s2("赵六");
cout << "进入代码块后:" << Person::getCount() << endl; // 4
} // s2被销毁
cout << "离开代码块后:" << Person::getCount() << endl; // 3
}关键结论:
- 静态成员被整个继承体系共享,无论通过基类还是派生类访问,都是同一个静态变量。
- 派生类可以直接访问基类的静态成员(通过
类名::静态成员),也可以继承基类的静态成员函数。 - 静态成员的初始化顺序:与全局变量一样,在程序启动时,先于
main执行,按照定义顺序初始化。对于继承体系中的静态成员,基类的静态成员优先于派生类的静态成员初始化。
静态成员的隐藏
如果派生类中定义了与基类同名的静态成员,则基类的静态成员会被隐藏,但二者仍然是独立的不同变量。
cpp
class Base {
public:
static int value;
};
int Base::value = 10;
class Derived : public Base {
public:
static int value; // 隐藏了 Base::value,但二者独立
};
int Derived::value = 20;
int main() {
cout << Base::value << endl; // 10
cout << Derived::value << endl; // 20
// 通过派生类对象也能访问,但默认访问派生类的静态成员
Derived d;
cout << d.value << endl; // 20
// 若想访问基类隐藏的静态成员,必须使用作用域解析符
cout << d.Base::value << endl; // 10
}静态成员函数的隐藏规则与变量相同:派生类若定义了同名静态成员函数,则会隐藏基类的同名静态函数。
3.2 友元关系不能被继承
友元关系是 C++ 中一种破坏封装的机制,允许外部函数或类访问另一个类的私有成员。然而,这种关系具有严格的限制:友元关系不传递、不继承、单向。这意味着基类的友元不会自动成为派生类的友元,派生类的友元也不会自动成为基类的友元,友元关系只授予声明它的那个类。
3.2.1 友元函数的不可继承性
当一个函数被声明为基类的友元时,它只能访问基类中的私有和保护成员。即使该函数接受派生类对象作为参数,它也无法访问派生类中新增的私有成员。这是因为"友元"的授权是基于声明的类,而不是基于对象的实际类型。
代码示例:基类友元无法访问派生类特有成员
cpp
#include <iostream>
using namespace std;
class Derived; // 前向声明
class Base {
friend void display(const Base& b, const Derived& d); // 声明友元函数
private:
int baseSecret = 100;
};
class Derived : public Base {
private:
int derivedSecret = 200; // 派生类特有的私有成员
};
// 定义友元函数
void display(const Base& b, const Derived& d) {
cout << "Base Secret: " << b.baseSecret << endl; // ✅ 正确,可以访问基类私有成员
// 尝试访问派生类的私有成员
// cout << "Derived Secret: " << d.derivedSecret << endl; // ❌ 编译错误!
// 原因:display 只是 Base 的友元,不是 Derived 的友元。
// 虽然 Derived 继承了 Base,但友元关系不继承。
}
int main() {
Base b;
Derived d;
display(b, d); // 可以传递派生类对象,但函数体内无法访问其新增私有成员
return 0;
}friendOfBase是Base的友元,因此能访问Base::baseSecret。- 当传入
Derived对象时,它被切片 为Base部分,因此函数体内只能访问Base的成员,不能访问Derived新增的私有成员。 - 友元关系不会继承:
friendOfBase不是Derived的友元,所以无法访问derivedSecret。
3.2.2 友元类的不可继承性
同样的规则也适用于友元类。如果类 A 是基类的友元,它并不会自动成为派生类的友元。A 的成员函数只能访问基类中的私有和保护成员,但无权访问派生类中新增的私有和保护成员。
代码示例:友元类的不可继承性
cpp
#include <iostream>
using namespace std;
class Base {
friend class FriendClass; // 声明 FriendClass 为友元类
private:
int baseSecret = 100;
};
class Derived : public Base {
private:
int derivedSecret = 200;
};
class FriendClass {
public:
void accessBase(Base& b) {
cout << b.baseSecret << endl; // ✅ 正确,FriendClass 是 Base 的友元
}
void accessDerived(Derived& d) {
// cout << d.derivedSecret << endl; // ❌ 编译错误!
// FriendClass 不是 Derived 的友元,因此无法访问其新增成员
cout << d.baseSecret << endl; // ✅ 正确,可以访问从 Base 继承来的成员
}
};
int main() {
Base b;
Derived d;
FriendClass fc;
fc.accessBase(b);
fc.accessDerived(d);
return 0;
}关键点 :在 accessDerived 函数中,FriendClass 可以访问 d.baseSecret(从基类继承来的成员),因为 FriendClass 是 Base 的友元。但它无法访问 d.derivedSecret(派生类自己的成员)。
3.2.3 解决方案与设计模式
如果确实需要某个函数或类同时访问基类和派生类的私有成员,有以下几种解决方案:
- 在派生类中再次声明友元
这是最直接的方案。如果希望原来的友元函数也能访问派生类的私有成员,可以在派生类中再次声明该函数为友元。
cpp
class Derived : public Base {
friend void display(const Base& b, const Derived& d); // 再次声明
private:
int derivedSecret = 200;
};
// 现在 display 函数可以同时访问 Base 和 Derived 的私有成员
void display(const Base& b, const Derived& d) {
cout << b.baseSecret << endl; // ✅ 正确
cout << d.derivedSecret << endl; // ✅ 正确,因为现在也是 Derived 的友元
}- 提供公共或保护的访问接口
如果不需要直接访问私有成员,可以在基类或派生类中提供公共的 get 或 set 方法。这种方法更符合面向对象封装的原则,虽然稍显冗长,但能更好地控制访问权限和维持代码的健壮性。
cpp
class Base {
private:
int baseSecret = 100;
public:
int getBaseSecret() const { return baseSecret; } // 公共接口
};
class Derived : public Base {
private:
int derivedSecret = 200;
public:
int getDerivedSecret() const { return derivedSecret; } // 公共接口
};- 使用辅助类或工具函数
可以创建一个专门的辅助类或一组工具函数,并将它们同时声明为基类和派生类的友元。这样,这些工具函数就可以合法地访问所有相关类的私有成员。这常用于实现某些需要深度访问类内部状态的复杂操作,例如序列化或调试工具。
3.3 设计不能被继承的类
有时需要设计一个类,禁止其他类继承它。C++ 提供了两种方式。
3.3.1 C++98 风格:私有构造函数
将类的构造函数声明为 private,派生类无法调用基类构造函数,从而无法实例化派生类对象。这种方式只能阻止派生类的实例化 ,但不能阻止派生类的声明。
cpp
class NonInherit {
private:
NonInherit() {} // 构造函数私有
public:
static NonInherit createInstance() {
return NonInherit();
}
};
// 错误:派生类无法调用基类的私有构造函数,因此无法创建对象
// class Derived : public NonInherit {}; // 编译错误(如果尝试实例化)
// 但以下声明是允许的(不实例化):
class Derived : public NonInherit; // 仅声明,不定义,编译器不报错如何创建对象?
虽然构造函数是私有的,但类本身仍然可以通过静态成员函数 (如 createInstance)在类内访问私有构造函数,从而创建对象。这是一种工厂方法模式,将对象的创建权交给类自身,外部无法直接构造对象。
cpp
int main() {
NonInherit obj = NonInherit::createInstance(); // 正确,通过静态工厂方法创建
// NonInherit obj2; // 错误,无法直接调用私有构造函数
}局限性 :
派生类虽然不能构造对象,但可以声明类型,甚至可以在派生类中定义自己的成员,只是无法创建派生类对象。这会导致一种奇怪的设计:一个可以被继承但无法实例化的类。例如:
cpp
class Derived : public NonInherit {
public:
void test() { /* 可以定义成员函数 */ }
int value; // 可以定义成员变量
};
int main() {
// Derived d; // 错误!无法调用基类私有构造,因此不能创建 Derived 对象
Derived* p = nullptr; // 可以声明指针,但不能创建对象
}这种方式的本质是禁止派生类实例化 ,但允许继承关系的存在。如果目标是彻底禁止任何类继承(包括禁止声明),那么 C++11 的 final 关键字是更合适的选择。
适用场景:
- 需要限制派生类只能被声明但不能被实例化,通常用于抽象基类或某些设计模式(如单例模式)。
- 需要与 C++98 兼容,无法使用
final关键字时。
3.3.2 C++11 风格:final 关键字
C++11 引入 final 关键字,明确表示该类不能被继承。这是最简洁、最安全的方式。
cpp
class NonInherit final {
// 正常定义构造函数,可以是 public
public:
NonInherit() {}
};
// 错误:无法从 final 类型继承
// class Derived : public NonInherit {}; // 编译错误!final 也可以用于虚函数,表示该虚函数不能被派生类重写。这能进一步增强设计意图的表达。
cpp
class Base {
public:
virtual void func() final { }
};
class Derived : public Base {
// void func() override { } // 错误:无法重写 final 函数
};推荐做法 :在需要禁止继承时,优先使用 final 关键字,它意图明确、编译期检查彻底,避免了私有构造函数带来的隐晦限制。
第四章 多继承与菱形继承问题
4.1 多继承的基本概念
多继承(Multiple Inheritance)是指一个派生类可以同时从多个基类继承,从而获得多个基类的成员属性和成员函数。C++是少数支持多继承的面向对象编程语言之一,这为代码复用提供了强大的灵活性,但也带来了额外的复杂性。
cpp
#include <iostream>
using namespace std;
class Printer {
public:
void print(const string& text) {
cout << "打印:" << text << endl;
}
};
class Scanner {
public:
void scan() {
cout << "扫描中..." << endl;
}
};
// 多功能一体机,同时继承打印和扫描功能
class AllInOne : public Printer, public Scanner {
public:
void copy(const string& text) {
print(text); // 复用Printer的功能
cout << "然后";
scan(); // 复用Scanner的功能
}
};
int main() {
AllInOne aio;
aio.print("报告.pdf");
aio.scan();
aio.copy("合同.doc");
}多继承在某些场景下非常自然:一体机既是一个打印机,也是一个扫描仪。然而,多继承也可能带来设计上的复杂性,尤其是当多个基类之间存在继承关系时,就会引发所谓的"菱形继承问题"。
4.1.1 多继承的语法与访问控制
在多继承中,派生类的定义语法为:
cpp
class 派生类名 : 访问控制符 基类1, 访问控制符 基类2, ... {
// 派生类成员
};每个基类前面都可以指定访问控制符(public、protected、private),如果不指定,默认是private。派生类会继承所有基类的成员,但继承后的访问权限受继承方式影响:
- public继承:基类的public成员在派生类中保持public,protected成员保持protected
- protected继承:基类的public和protected成员在派生类中都变为protected
- private继承:基类的public和protected成员在派生类中都变为private
4.1.2 多继承的构造函数与析构函数调用顺序
当一个派生类继承多个基类时,构造函数的调用顺序遵循以下规则:
- 虚基类(如果有)按照深度优先、从左到右的顺序优先构造
- 直接基类按照它们在类定义中声明的顺序(从左到右)依次构造
- 成员对象按照它们在类定义中声明的顺序依次构造
- 派生类自身的构造函数体最后执行
析构函数的调用顺序与构造函数完全相反(从右到左)。
cpp
class Base1 {
public:
Base1() { cout << "Base1构造" << endl; }
~Base1() { cout << "Base1析构" << endl; }
};
class Base2 {
public:
Base2() { cout << "Base2构造" << endl; }
~Base2() { cout << "Base2析构" << endl; }
};
class Derived : public Base1, public Base2 {
public:
Derived() { cout << "Derived构造" << endl; }
~Derived() { cout << "Derived析构" << endl; }
};
int main() {
Derived d;
// 输出顺序:
// Base1构造
// Base2构造
// Derived构造
// Derived析构
// Base2析构
// Base1析构
return 0;
}4.2 多继承的二义性问题
多继承可能带来一个常见的麻烦:如果两个基类包含同名的成员(变量或函数),派生类在访问这些成员时会产生二义性(Ambiguity),编译器无法确定应该使用哪个基类的成员。
cpp
class Father {
public:
int money = 1000;
void skill() {
cout << "父亲:会修电器" << endl;
}
};
class Mother {
public:
int money = 2000; // 同名成员变量
void skill() { // 同名成员函数
cout << "母亲:会做饭" << endl;
}
};
class Child : public Father, public Mother {
// 继承了父亲和母亲的所有成员
};
int main() {
Child c;
// cout << c.money << endl; // 错误!二义性,不知道是Father::money还是Mother::money
// c.skill(); // 错误!二义性
cout << c.Father::money << endl; // 正确:指定作用域
cout << c.Mother::money << endl; // 正确:指定作用域
c.Father::skill(); // 输出:父亲:会修电器
c.Mother::skill(); // 输出:母亲:会做饭
}4.2.1 解决二义性的方法
- 使用作用域解析运算符(::):显式指定要访问的基类
cpp
c.Father::money = 100;
c.Mother::skill();- 在派生类中重新定义同名成员:通过重名覆盖(name hiding)来消除二义性
cpp
class Child : public Father, public Mother {
public:
void skill() { // 重新定义skill,覆盖基类版本
Father::skill(); // 可以选择性地调用特定基类的实现
cout << "孩子:会编程" << endl;
}
};- 使用using声明:在派生类中指定使用哪个基类的成员
cpp
class Child : public Father, public Mother {
public:
using Father::skill; // 指定使用Father的skill版本
};4.2.2 成员函数的重载与隐藏
当基类之间存在同名函数时,派生类中的函数名查找规则较为复杂。派生类的作用域会嵌套所有基类的作用域,如果派生类自身定义了同名函数,则会隐藏所有基类中的同名函数(无论参数列表是否相同)。这可能导致某些重载版本无法被访问。
cpp
class Base1 {
public:
void func() { cout << "Base1::func" << endl; }
void func(int x) { cout << "Base1::func(int)" << endl; }
};
class Base2 {
public:
void func() { cout << "Base2::func" << endl; }
};
class Derived : public Base1, public Base2 {
public:
void func() { cout << "Derived::func" << endl; } // 隐藏所有基类的func
};
int main() {
Derived d;
d.func(); // 调用Derived::func
// d.func(10); // 错误!Base1::func(int)被隐藏了
d.Base1::func(10); // 必须显式指定作用域才能调用
return 0;
}4.3 菱形继承(钻石问题)
多继承最复杂的问题是菱形继承(Diamond Inheritance),也叫钻石问题(Diamond Problem)。其继承结构形如钻石/菱形:
plain
A
/ \
B C
\ /
D其中,B和C都继承自A,D又同时继承B和C。此时,D会包含两份A的成员(一份来自B路径,一份来自C路径),导致数据冗余和二义性。
cpp
#include <iostream>
using namespace std;
class Animal {
public:
int age = 0; // 动物的年龄
void breathe() {
cout << "呼吸..." << endl;
}
};
class Mammal : public Animal {
public:
int legs = 4; // 腿的数量
};
class Bird : public Animal {
public:
int wings = 2; // 翅膀的数量
};
// 蝙蝠是哺乳动物,但也会飞(像鸟)
class Bat : public Mammal, public Bird {
public:
void showInfo() {
// cout << "年龄:" << age << endl; // 错误!二义性,有两份age
cout << "腿数:" << legs << endl; // 正确,来自Mammal
cout << "翅膀数:" << wings << endl; // 正确,来自Bird
}
};
int main() {
Bat bat;
// bat.breathe(); // 错误!二义性,有两份breathe
// 解决方式:指定作用域
bat.Mammal::breathe();
bat.Bird::breathe();
cout << "Bat对象大小:" << sizeof(Bat) << endl; // 至少包含两份Animal的成员
}4.3.1 菱形继承的两个核心问题
- 数据冗余 :Bat对象中包含两份
age成员(一份来自Mammal::Animal,一份来自Bird::Animal),造成内存浪费 - 访问二义性 :直接访问
age或breathe()时,编译器无法确定使用哪个基类的版本,导致编译错误
4.3.2 菱形继承的内存布局(非虚继承)
在不使用虚继承的情况下(以D继承B、C,B和C继承A为例),Derived(D)对象的内存布局如下:
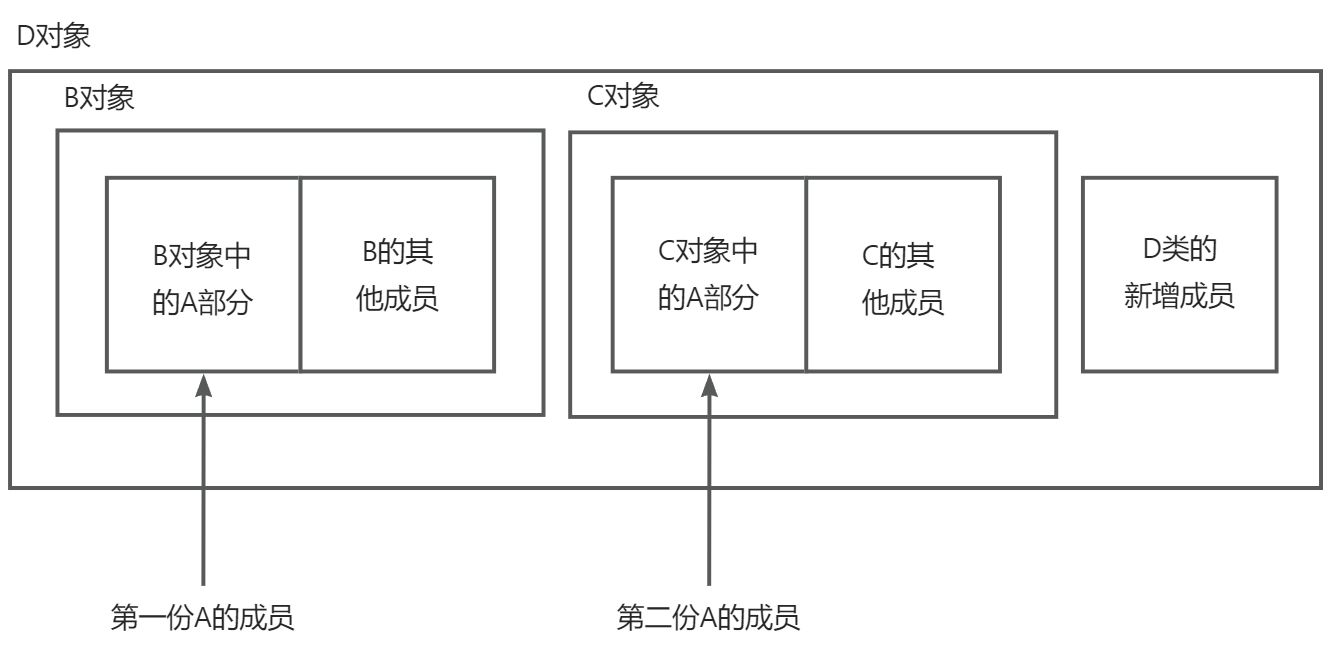
这种布局导致:
- 同一个基类A的成员在内存中被存储了两次
- 通过不同路径访问A的成员会得到不同的内存地址
- 如果修改B路径下的A成员,C路径下的A成员不会同步更新,可能造成数据不一致
4.4 虚继承:解决菱形继承
虚继承(Virtual Inheritance)是C++为解决菱形继承问题提供的机制。通过在继承时使用virtual关键字,让中间类(B和C)声明对基类A的继承是虚继承,这样最终派生类D中只会保留一份A的成员。
cpp
#include <iostream>
using namespace std;
class Animal {
public:
int age = 0;
void breathe() {
cout << "呼吸..." << endl;
}
};
// 虚继承:告诉编译器,如果Animal被多次继承,只保留一份
class Mammal : virtual public Animal {
public:
int legs = 4;
};
class Bird : virtual public Animal {
public:
int wings = 2;
};
class Bat : public Mammal, public Bird {
public:
void showInfo() {
cout << "年龄:" << age << endl; // 现在不二义了,只有一份age
cout << "腿数:" << legs << endl;
cout << "翅膀数:" << wings << endl;
}
};
int main() {
Bat bat;
bat.breathe(); // 也不二义了
bat.showInfo();
cout << "Bat对象大小:" << sizeof(Bat) << endl; // 比没虚继承时小
}4.4.1 虚继承的内存布局与虚基类指针(vbptr)
虚继承的实现涉及一个称为虚基类指针(vbptr,virtual base pointer)的概念。每个虚继承的类对象中,会包含一个指向虚基类表(vbtable,virtual base table)的指针,通过这个表可以找到虚基类成员的位置。
虚基类表(vbtable)的结构:
- 第一项:vbptr指针相对于本类对象起始位置的偏移量(通常为0)
- 第二项:vbptr指针到第一个虚基类成员起始位置的偏移量
- 第三项:vbptr指针到第二个虚基类成员起始位置的偏移量
- 第四项:..............................................................................
虚继承后的内存布局
以D继承 B、C,B和C虚继承A为例:
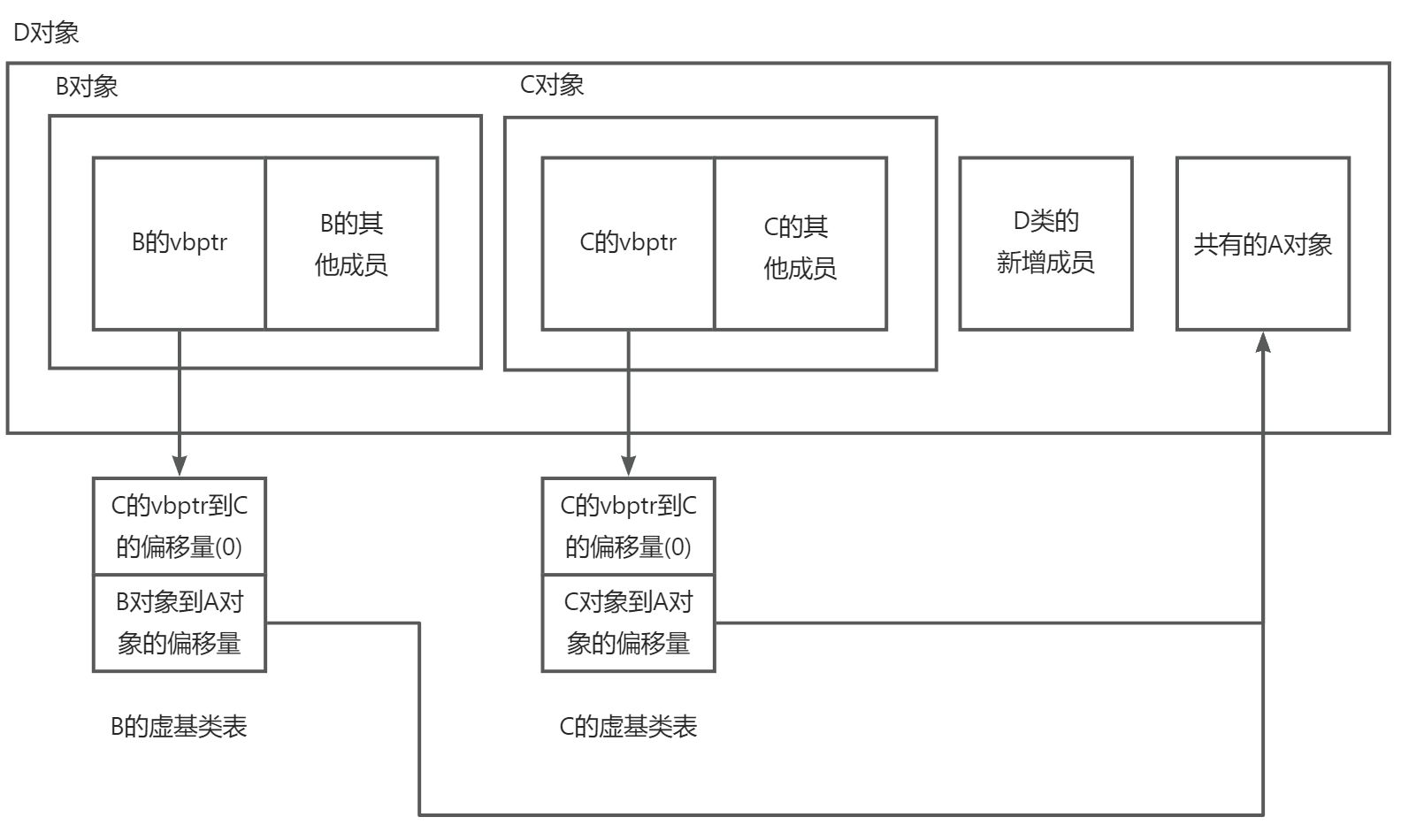
以D虚继承 B、C,B和C虚继承A为例:
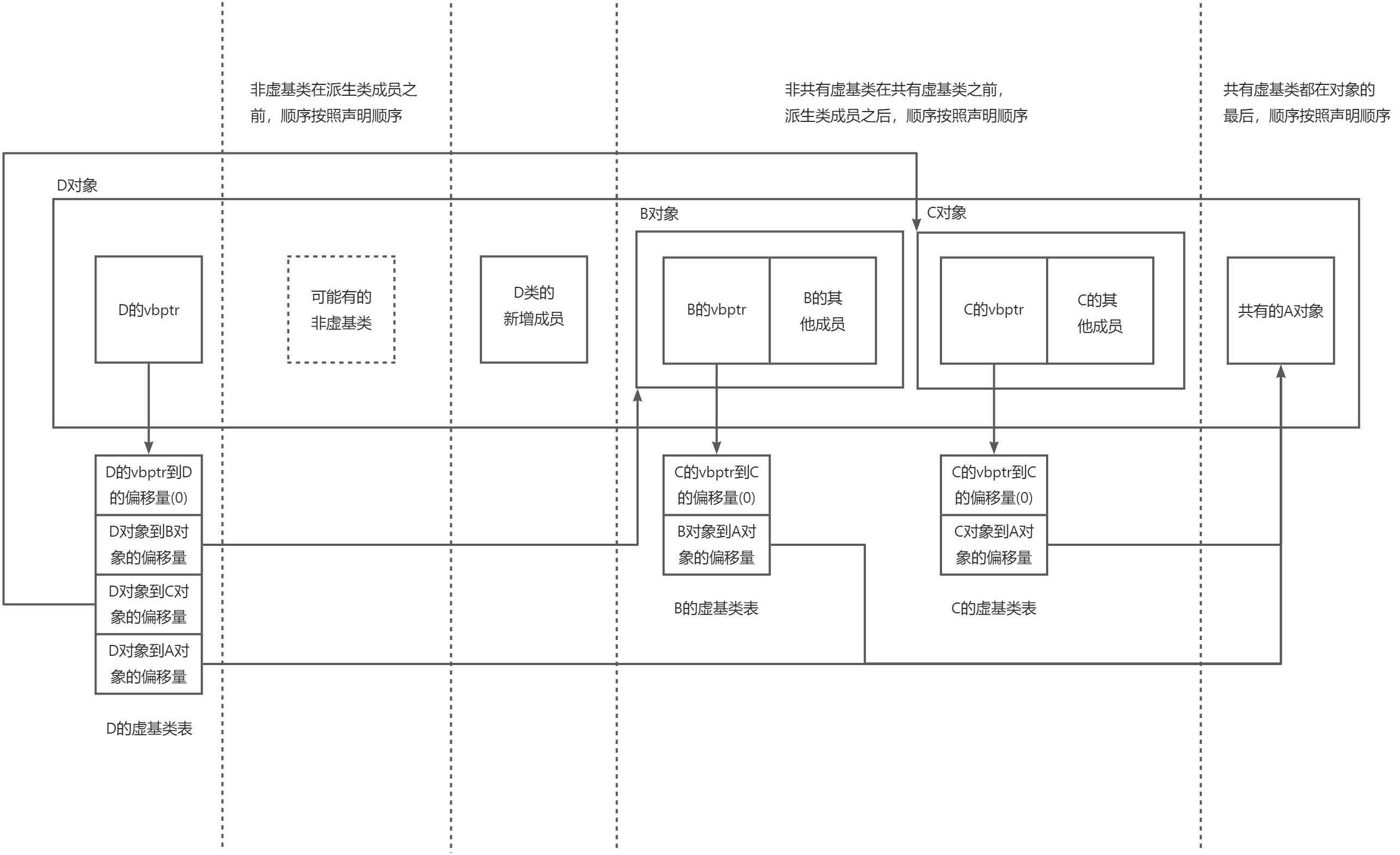
当访问虚基类成员时(如d.age),编译器会通过vbptr找到虚基类表,根据表中记录的偏移量计算出虚基类成员的实际位置,然后进行访问。这种间接访问方式比直接访问多一次指针跳转,但解决了数据冗余问题。
例如,当通过派生类指针访问虚基类成员时,编译器会:
- 通过对象地址 + vbptr偏移量 → 找到vbptr
- 通过vbptr指向的虚基类表 + 偏移量(第二项) → 得到虚基类成员的实际偏移量
- 最终计算出成员地址 = 对象地址 + 虚基类成员偏移量
这种设计保证了即使虚基类成员在对象布局中的位置不固定(因为最终派生类可能调整虚基类的位置),访问时仍能正确找到唯一的一份虚基类成员。
4.4.2 虚继承的构造函数规则
引入虚继承后,构造函数的调用顺序变得更加复杂。关键规则是:虚基类由最终派生类直接负责构造,中间类对虚基类的构造调用会被编译器忽略。
构造函数的调用优先级顺序如下:
- 虚基类(按照深度优先、从左到右的顺序)------ 由最终派生类直接调用
- 直接基类(按照声明顺序)------ 中间类对虚基类的初始化被忽略
- 成员对象(按照声明顺序)
- 派生类构造函数体
cpp
#include <iostream>
using namespace std;
class Animal {
public:
Animal(int a) : age(a) {
cout << "Animal构造,age=" << age << endl;
}
int age;
};
class Mammal : virtual public Animal {
public:
Mammal(int a, int l) : Animal(a), legs(l) { // Animal(a)会被忽略!
cout << "Mammal构造" << endl;
}
int legs;
};
class Bird : virtual public Animal {
public:
Bird(int a, int w) : Animal(a), wings(w) { // Animal(a)会被忽略!
cout << "Bird构造" << endl;
}
int wings;
};
class Bat : public Mammal, public Bird {
public:
// 注意:必须由Bat直接初始化虚基类Animal!
Bat(int a, int l, int w)
: Animal(a) // 只有这里真正初始化虚基类
, Mammal(a, l) // Mammal中对Animal的初始化被编译器忽略
, Bird(a, w) { // Bird中对Animal的初始化被编译器忽略
cout << "Bat构造" << endl;
}
};
int main() {
Bat bat(5, 4, 2);
cout << "年龄:" << bat.age << ",腿:" << bat.legs << ",翅膀:" << bat.wings << endl;
return 0;
}运行结果:
plain
Animal构造,age=5
Mammal构造
Bird构造
Bat构造
年龄:5,腿:4,翅膀:2关键理解 :虽然Mammal和Bird的初始化列表中都写了Animal(a),但实际执行时只调用了一次Animal的构造函数,且是在Bat的初始化列表中指定的。中间类对虚基类的构造调用被编译器自动忽略。
4.4.3 虚继承的底层实现机制
从编译器的实现角度来看,虚继承的底层机制涉及多个关键环节,包括对象布局的调整、额外指针的插入、特殊表的生成,以及构造和访问时的指针修正。理解这些机制有助于掌握虚继承的性能特性和使用限制。
1. vbptr 的插入
vbptr(虚基类指针) 是编译器在需要虚继承的类对象中自动插入的一个隐藏指针,用于在运行时定位虚基类子对象。
- **插入条件**:如果一个类直接或间接包含虚基类,并且该类不是虚基类本身(即该类需要访问虚基类成员),则编译器会在其对象布局中插入 vbptr。通常,每个含有虚基类的类都有一个 vbptr。
- **插入位置**:在主流编译器(如 GCC、Clang 遵循 Itanium C++ ABI)中,vbptr 通常位于对象布局的**最开头**(偏移量 0),以便快速访问。但如果类同时有虚函数(即存在 vptr),则 vptr 可能也在开头,此时 vbptr 可能紧随其后或与 vptr 合并(取决于具体实现)。
- **数量**:一个类通常只含有一个 vbptr,即使它继承了多个虚基类。这是因为所有虚基类的偏移信息都集中存储在一张虚基类表中,只需一个指针即可访问整张表。
cpp
class A {};
class B : virtual public A { int b; };
// B 对象布局(简化):
// [ vbptr ] [ b ] [ A 部分(在末尾)]2. vbtable 的生成
vbtable(虚基类表) 是编译器为每个含有虚基类的类生成的一张静态数据表,表中存储了该类对象中所有虚基类子对象的偏移量信息。
- **表的归属**:每个含有虚基类的类都有自己独立的虚基类表。例如,`B` 和 `C` 各自有一张表,`D`(如果它也包含虚基类)也有自己的表。
- **表的内容**:以 Itanium C++ ABI 为例,虚基类表的第一项存储 **vbptr 相对于对象起始的偏移量**(通常为 0),后续项按深度优先、从左到右的顺序存储每个虚基类子对象的偏移量。| 索引 | 含义 |
|---|---|
| 0 | vbptr 相对于对象起始的偏移量 |
| 1 | 第一个虚基类子对象相对于对象起始的偏移量 |
| 2 | 第二个虚基类子对象相对于对象起始的偏移量 |
| ... | ... |
- **表的共享**:如果一个类有多个虚基类,所有偏移量放在同一张表中。如果多个类共享相同的虚基类布局(极少见),编译器可能会复用表,但通常每个类独立生成。
cpp
class B : virtual public A { };
// vbtable for B:
// [0] 0 (vbptr 自身偏移)
// [1] offset_of_A (例如 8)3. 构造函数的参数调整
虚继承下,虚基类只能由最终派生类负责初始化,中间类对虚基类的构造调用会被忽略。编译器通过修改构造函数签名来实现这一机制。
- **隐藏参数**:编译器为每个含有虚基类的类的构造函数添加一个隐藏的布尔参数(通常称为 `__most_derived` 或类似名称),用于标识当前构造的对象是否为"最派生"的对象。
- **构造流程**:
1. 当最终派生类(如 `D`)构造时,它的构造函数会首先调用所有虚基类的构造函数(在初始化列表中),并将 `__most_derived` 参数设为 `true`。
2. 当中间类(如 `B`)作为子对象被构造时,编译器传递 `__most_derived = false`,从而跳过对虚基类的重复构造(B 的初始化列表中对虚基类的调用被忽略)。
- **实际效果**:虚基类只被构造一次,且由最终派生类直接负责。
cpp
// 编译器实际生成的构造函数原型(简化)
B::B(int a, bool __most_derived = true)
: /* 如果 __most_derived 为 true 才构造 A,否则忽略 */
{ ... }- **构造顺序**:虚基类在最终派生类的初始化列表中按声明顺序优先构造,然后才构造非虚基类子对象和成员变量。4. 对象切片时的偏移调整
"对象切片"通常指将派生类对象赋值给基类对象,导致派生部分被切掉。但在虚继承中,更常见的是通过基类指针访问派生类对象时的指针调整 ,以及将派生类对象转换为基类时的地址计算。这里主要讨论两类场景:
1. **通过基类指针访问虚基类成员**当使用基类指针(如 B*)指向一个派生类对象(如 D 对象)时,如果访问虚基类 A 的成员,编译器必须正确计算 A 的实际位置。由于 A 在 D 中的位置可能不同于在 B 中的位置,因此需要通过 vbptr 和 vbtable 动态获取偏移量。
cpp
D d;
B* pb = &d; // pb 指向 d 中的 B 子对象
pb->A::age = 10; // 访问虚基类 A 的成员编译器生成的访问代码大致如下:
1. 从 pb 中找到 vbptr(已知偏移量,如 0)
2. 通过 vbptr 读取虚基类表
3. 从表中取得 A 相对于对象起始的偏移量(例如 24)
4. 计算 A 的地址 = (char*)pb - vbptr_偏移 + A_偏移即:A 的地址 = (char*)pb - (vbptr 到 B 子对象的偏移) + A_偏移
这种间接访问使得虚基类成员访问比普通成员慢(多一次内存访问)。
2. **从基类指针向下转型(dynamic_cast,第六章讲解)**当使用 dynamic_cast 将基类指针转换为派生类指针时,编译器同样需要利用虚基类表来调整指针位置。dynamic_cast 通过 RTTI 信息(位于 vtable 或 vbtable 中)判断类型,并计算出正确的偏移量。例如:
cpp
D* pd = dynamic_cast<D*>(pb); // pb 指向 B 子对象dynamic_cast 会查找 pb 所指向对象的完整类型(通过 RTTI),然后根据虚基类表中存储的偏移量,将 pb 调整到 D 对象的起始地址。
3. **对象切片(赋值给基类对象)**当派生类对象赋值给基类对象时,只会复制基类部分。对于虚基类,由于在派生类中只有一份,切片时基类部分仅复制一次,且不需要特殊的指针调整(因为赋值操作直接在对象上进行,不涉及指针偏移计算)
cpp
B b = d;
// 切片:只复制 d 中的 B 和 A 子对象部分,不会重复拷贝A
// 因为 A 在 B 中也是通过指针间接访问,只需修改偏移量需要注意的是,如果 B 本身包含虚基类,赋值时仍会正常复制 B 子对象,但虚基类成员 A 在 b 中仍然存在(独立于 d 中的 A),因为切片后 b 是一个独立对象。
4.4.4 混合使用虚继承与普通继承
当一个继承体系中同时存在虚继承和普通继承时,构造顺序会更加复杂。基本规则是:虚基类总是优先于普通基类被构造,无论它们在继承列表中的位置如何。
cpp
class VBase {
public:
VBase() { cout << "VBase构造" << endl; }
};
class A : virtual public VBase {
public:
A() { cout << "A构造" << endl; }
};
class B : public VBase { // 普通继承
public:
B() { cout << "B构造" << endl; }
};
class C : public A, public B {
public:
C() : A(), B() { cout << "C构造" << endl; }
};
int main() {
C c;
// 输出顺序:
// VBase构造 ← A的虚基类(优先)
// A构造
// VBase构造 ← B的普通基类(在B构造前)
// B构造
// C构造
return 0;
}在这个例子中,虚基类VBase(来自A)被优先构造,而B中普通继承的VBase则在B构造之前构造,因此VBase被构造了两次。
4.4.5 虚继承的使用建议
虚继承虽然解决了菱形继承问题,但也带来了额外的开销:
- 内存开销:每个虚继承的类对象会增加一个vbptr指针(通常为4或8字节),以及虚基类表的存储空间
- 访问开销:访问虚基类成员需要通过vbptr间接访问,比直接访问多一次指针解引用操作
- 构造开销:虚基类的构造机制更复杂,编译器需要插入额外的代码来管理构造顺序
- 代码复杂度:虚继承的类层次结构更难以理解和维护
基于上述特性,使用虚继承时应遵循以下建议:
- 只在必要时使用:虚继承只应用于解决菱形继承问题,不要滥用。如果类层次结构中没有菱形继承,就不需要使用虚继承
- 尽量提供默认构造函数:虚基类最好提供默认构造函数,以简化最终派生类的初始化工作
- 最终派生类必须显式初始化虚基类:一旦使用虚继承,最终派生类必须负责初始化所有虚基类,无论中间类是否已经提供了初始化
- 避免复杂的多层虚继承:尽量保持类层次结构清晰简单,避免使用多层虚继承,以降低维护成本
- 考虑使用组合替代:在许多情况下,可以使用组合(Composition)模式替代复杂的继承关系,这通常能获得更好的设计灵活性
使用组合替代虚继承
在实际开发中,很多原本使用菱形继承的场景都可以通过组合(Composition)模式来更优雅地实现。组合是一种"has-a"关系,与继承的"is-a"关系形成对比。
cpp
// 使用组合替代菱形继承
class Animal {
public:
string name;
void breathe() { cout << "呼吸" << endl; }
};
class Mammal {
private:
Animal animal; // 组合:包含一个Animal对象
public:
int legs = 4;
void breathe() { animal.breathe(); } // 转发调用
Animal& getAnimal() { return animal; }
};
class Bird {
private:
Animal animal; // 组合:包含一个Animal对象
public:
int wings = 2;
void breathe() { animal.breathe(); }
Animal& getAnimal() { return animal; }
};
class Bat {
private:
Mammal mammal;
Bird bird;
public:
void setAge(int age) {
mammal.getAnimal().name = "蝙蝠";
bird.getAnimal().name = "蝙蝠";
}
void showInfo() {
cout << "腿数:" << mammal.legs << endl;
cout << "翅膀数:" << bird.wings << endl;
}
void breathe() {
mammal.breathe(); // 或者 bird.breathe()
}
};组合模式的优势:
- 无数据冗余:通过显式控制包含关系,避免重复数据
- 更灵活:可以在运行时动态替换组件
- 更清晰:类之间的关系更明确,易于理解
- 更好的封装:组合通常提供更好的封装性
何时使用组合而非继承:
- 当需要实现"has-a"关系而非"is-a"关系时
- 当继承会导致复杂的类层次结构时
- 当需要在运行时动态改变对象行为时
- 当需要更好地封装实现细节时
第五章 多态:同一个接口,不同的实现
5.1 理解多态
假设我们正在开发一个图形绘制程序,需要支持圆形、矩形、三角形等不同形状。每个形状都有自己的draw方法------画圆的方式和画矩形的方式当然不同。
如果不使用多态,你可能会这样写:
cpp
class Circle {
public:
void drawCircle() { /* 画圆的代码 */ }
};
class Rectangle {
public:
void drawRectangle() { /* 画矩形的代码 */ }
};
void drawAll() {
Circle c;
Rectangle r;
// 需要调用不同名字的函数
c.drawCircle();
r.drawRectangle();
}问题:每增加一种新形状,调用它的代码就要修改,不符合开闭原则(对扩展开放,对修改关闭)。而且你无法写一个通用的"画形状"函数,因为每个形状的函数名都不一样。
多态的思想就是:让所有形状使用同一个接口------都叫draw,但不同形状的draw做不同的事情。这样,你可以写一个通用的函数:
cpp
void drawShape(Shape* p) {
p->draw(); // 根据实际形状调用对应的draw
}这个神奇的"根据实际形状调用对应函数"的能力,就是运行时多态。
多态的价值:
- 可扩展性 :新增形状类只需继承
Shape并实现draw,无需修改已有代码。 - 统一处理:可以编写处理基类指针/引用的函数,自动适配所有派生类。
- 解耦:高层代码依赖抽象(接口),不依赖具体实现,便于维护和测试。
- 代码复用:基类可以包含通用逻辑(如颜色、位置),派生类只需关注特有行为。
在实际开发中,多态使得我们可以轻松管理一系列对象,例如在图形编辑器中,只需要遍历一个Shape*数组,对每个元素调用draw()即可完成全部绘制,新增加形状也不会破坏现有代码。
5.2 多态的分类
C++支持两种多态:
| 多态类型 | 实现方式 | 绑定时机 | 特点 |
|---|---|---|---|
| 静态多态 | 函数重载、运算符重载、模板 | 编译期 | 效率高,灵活性较低 |
| 动态多态 | 虚函数 + 继承 + 指针/引用 | 运行期 | 灵活性高,有少量运行时开销 |
本章主要讲解动态多态。
静态多态补充:静态多态在编译期就确定了具体调用哪个函数,因此没有运行时开销,且允许内联优化。例如使用模板实现的编译期多态(如CRTP奇异递归模板模式)可以在某些场景下替代虚函数以获得更高性能,这体现了C++的"零开销原则"------你不使用的功能,你不需要付出代价。
5.3 虚函数:多态的基础
5.3.1 虚函数的定义
在基类中,使用virtual关键字声明的成员函数就是虚函数。派生类可以重写(override)这些函数,提供自己的实现。
cpp
#include <iostream>
using namespace std;
class Shape {
public:
// 虚函数
virtual void draw() const {
cout << "绘制一个通用形状" << endl;
}
};
class Circle : public Shape {
public:
// 重写(覆盖)基类的虚函数
void draw() const override { // C++11起可用override关键字
cout << "绘制一个圆形" << endl;
}
};
class Rectangle : public Shape {
public:
void draw() const override {
cout << "绘制一个矩形" << endl;
}
};
// 多态的使用:通过基类指针或引用调用虚函数,切记不能切片
void render(const Shape& s) {
s.draw(); // 运行时决定调用哪个draw
}
int main() {
Circle c;
Rectangle r;
render(c); // 输出:绘制一个圆形
render(r); // 输出:绘制一个矩形
Shape* p = &c;
p->draw(); // 输出:绘制一个圆形(多态)
Shape& ref = r;
ref.draw(); // 输出:绘制一个矩形(多态)
}派生类重写基类虚函数时,**可以不显式写 ****virtual**,因为一旦基类函数是虚函数,派生类中与之签名完全相同的函数自动成为虚函数。
在 C++ 中,一旦一个成员函数被声明为 **virtual**,它将沿着继承链一直保持虚函数的特性 ,无论后续派生类中是否显式写出 virtual 关键字。
因此,当派生类(例如 Derived)再次作为基类被继承时,即使它在自己的类中重写虚函数时没有写 virtual,这个函数在 Derived 的派生类(例如 FurtherDerived)中仍然是虚函数,可以被继续重写。
但为了代码可读性,强烈建议使用 **override** 关键字(5.4.3节讲解),这样既能明确表达重写的意图,又能让编译器检查签名是否匹配。
5.3.2 实现多态的三大条件
要实现运行时多态,必须同时满足:
- 公有继承 :派生类必须公有继承自基类(
public继承)。- 如果是
protected或private继承,基类接口在派生类外部不可见,多态无法工作。
- 如果是
- 虚函数重写 :基类函数用
virtual声明,派生类重新定义该函数(函数签名必须完全相同,包括const限定符、引用限定符等)。 - 基类指针/引用调用:必须通过基类的指针或引用调用虚函数。
为什么不能通过对象调用实现多态?
cpp
Shape s = Circle(); // 切片!s被切成了Shape对象
s.draw(); // 调用Shape::draw,不是多态因为通过对象调用,调用哪个函数在编译期就根据对象的静态类型决定了(这里是Shape类型)。多态需要运行时确定类型,这就要求有间接性------指针或引用。
5.4 重写(覆盖)的规则
5.4.1 函数签名必须一致
派生类重写虚函数时,函数名、参数列表、返回值类型必须与基类完全相同。有一个例外:协变返回类型(允许返回基类指针/引用时,派生类可以返回派生类指针/引用)。
cpp
class Base {
public:
virtual Base* clone() const {
return new Base(*this);
}
};
class Derived : public Base {
public:
// 协变:返回Derived*,是Base*的子类型
virtual Derived* clone() const override {
return new Derived(*this);
}
};协变返回类型的限制:
- 只能用于指针或引用类型。
- 派生类返回类型必须是基类返回类型的"子类"(有继承关系)。
- 不能用于内置类型(如
int等)。
5.4.2 限定符必须一致
cpp
class Base {
public:
virtual void show() const { // 注意const
cout << "Base const" << endl;
}
};
class Derived : public Base {
public:
// 如果不写const,这是新函数,不是重写
void show() override { // 错误!签名不一致
cout << "Derived non-const" << endl;
}
};注意 :const、volatile、引用限定符(&/&&)都会影响函数签名。派生类中必须完全匹配。
volatile 成员函数
volatile 限定符表示该成员函数可以在 volatile 对象上调用,并且通常用于告知编译器不要对该函数中的访问进行优化(例如内存映射 I/O 或中断处理程序)。与 const 类似,volatile 也是函数签名的一部分。
cpp
class Base {
public:
virtual void func() volatile {
cout << "Base volatile" << endl;
}
};
class Derived : public Base {
public:
// 正确:重写基类的 volatile 虚函数
void func() volatile override {
cout << "Derived volatile" << endl;
}
// 错误:缺少 volatile,这是新函数(隐藏),不是重写
// void func() override { }
};重要 :const 和 volatile 可以同时使用,顺序无关(如 void func() const volatile;),重写时必须完全匹配。
引用限定符(& 和 &&)
C++11 引入了引用限定符 ,允许成员函数根据调用对象的值类别(左值或右值)进行重载。限定符放在参数列表之后,函数体之前:
&:该成员函数只能被左值对象调用。&&:该成员函数只能被右值对象调用(通常用于移动语义的优化)。
引用限定符也是函数签名的一部分,因此在重写虚函数时必须保持一致。
cpp
class Base {
public:
// 只能被左值对象调用
virtual void process() & {
cout << "Base lvalue" << endl;
}
// 只能被右值对象调用
virtual void process() && {
cout << "Base rvalue" << endl;
}
};
class Derived : public Base {
public:
// 正确:重写左值版本
void process() & override {
cout << "Derived lvalue" << endl;
}
// 正确:重写右值版本
void process() && override {
cout << "Derived rvalue" << endl;
}
// 错误:缺少引用限定符,这不是重写
// void process() override { }
};
int main() {
Derived d;
d.process(); // 调用 Derived::process() & (左值版本)
Derived().process(); // 调用 Derived::process() && (右值版本)
}引用限定符的使用场景:
- 当需要根据调用对象的值类别来优化行为时(例如,对右值对象进行移动,对左值对象进行复制)。
- 避免在临时对象上调用某些不安全的操作(例如,返回内部成员的引用)。
综合示例:const、volatile、引用限定符的组合
这些限定符可以任意组合,但必须完全匹配才能构成重写。
cpp
class Base {
public:
virtual void func() const & {
cout << "Base const lvalue" << endl;
}
virtual void func() volatile && {
cout << "Base volatile rvalue" << endl;
}
};
class Derived : public Base {
public:
// 正确:完全匹配 const &
void func() const & {
cout << "Derived const lvalue" << endl;
}
// 正确:完全匹配 volatile &&
void func() volatile && {
cout << "Derived volatile rvalue" << endl;
}
// 错误:缺少 const,隐藏
// void func() & override { }
};注意事项:
- 引用限定符不能和
static一起使用(因为静态成员函数没有this指针)。 - 如果不希望派生类重写某个版本的虚函数,可以在基类中将其声明为
final,但必须注意重载版本之间的关系。
通过理解并正确使用这些限定符,可以避免因签名不匹配而导致的多态失效,同时写出更安全、更高效的代码。
5.4.3 override 关键字(C++11)
C++11 引入 override 关键字,用于显式标记派生类中的某个函数是对基类虚函数的重写(覆盖)。它的主要价值在于:
- 提高代码可读性 :代码中明确写出
override,任何阅读者都能立即知道该函数是一个重写,而非新增的独立函数。 - 编译器静态检查 :如果基类中没有与该函数签名完全一致的虚函数(包括
const/volatile、引用限定符、参数类型等),编译器会报错,从而避免因拼写错误、签名不匹配而导致的"意外隐藏"问题。
cpp
class Base {
public:
virtual void draw() const;
virtual void move(int x, int y);
};
class Derived : public Base {
public:
void draw() const override; // 正确:重写
void move(double x, double y) override; // 错误!基类没有 move(double,double)
};为什么需要 override?
在 C++11 之前,派生类重写基类虚函数时,只要函数名相同且签名匹配,就会自动成为重写。但如果程序员写错了签名(例如漏写 const、参数类型写错),编译器并不会报错,而是会认为派生类定义了一个新的独立函数(隐藏了基类的同名函数)。这会导致:
- 多态行为失效:通过基类指针或引用调用时,永远调用的是基类版本。
- 代码维护困难:错误隐蔽,不易发现。
override 的出现正是为了在编译期捕获这类错误,让多态机制更加安全。
override 的使用规范
- 必须放在成员函数声明之后、函数体或
= default/= delete之前。 - 只能用于派生类中的虚函数重写,不能用于非虚函数或静态函数。
- 一旦使用
override,编译器会严格检查基类中是否存在可重写的虚函数。
override 与 virtual 的关系
- 基类中的虚函数必须用
virtual声明。 - 派生类重写时,可以省略
virtual,但推荐保留virtual或使用override。 - 最现代的风格是:派生类重写时使用
override,不再重复写virtual,因为override已经隐含了"这是一个虚函数"的语义(实际上编译器会把它当作虚函数)。
cpp
// 推荐写法
class Derived : public Base {
public:
void draw() const override { /* ... */ }
void move(int x, int y) override { /* ... */ }
};多重继承场景下的 override
当派生类从多个基类继承,并且多个基类中存在同名虚函数时,override 可以帮助明确重写的是哪个基类的函数(因为同名函数可以通过签名区分)。如果签名与所有基类都不匹配,编译器会报错。
当派生类从多个基类继承,且这些基类中存在签名完全相同的虚函数 时,派生类可以通过只提供一个同名同签名的函数 来同时重写所有这些基类的虚函数。这个函数会覆盖每个基类中对应的虚函数。
cpp
#include <iostream>
struct Base1 {
virtual void g() { std::cout << "Base1::g\n"; }
};
struct Base2 {
virtual void g() { std::cout << "Base2::g\n"; }
};
struct Derived : Base1, Base2 {
void g() override { // 同时重写 Base1::g 和 Base2::g
std::cout << "Derived::g\n";
}
};
int main() {
Derived d;
d.g(); // 调用 Derived::g
Base1* b1 = &d;
b1->g(); // 多态调用 Derived::g
Base2* b2 = &d;
b2->g(); // 多态调用 Derived::g
}如果派生类不提供重写,此时直接通过派生类对象调用 g() 会产生二义性,因为两个基类都有同名函数且未被覆盖。此时必须用作用域限定(如 d.Base1::g())来明确调用。
注意事项
override是关键字,但只在这个语境下生效,可以用作普通标识符(但最好不要)。- 如果一个函数同时被
override和final修饰,顺序任意,通常写作void f() override final;或void f() final override;。
5.4.4 final 关键字(C++11)
final 关键字有两种使用场景:用于类 和 用于虚函数。
- final 用于虚函数
在虚函数声明后添加 final,表示该函数不能在派生类中继续被重写。这可以用于锁定某个具体的实现,防止后续派生类修改其行为。
cpp
class Base {
public:
virtual void step1() final { cout << "Base step1" << endl; }
virtual void step2() { cout << "Base step2" << endl; }
};
class Derived : public Base {
public:
// void step1() override { } // 错误:step1 是 final
void step2() override { } // 正确:step2 仍可重写
};设计意图
- **接口稳定性**:基类设计者可能希望某个关键算法步骤不被改变,以保证整体逻辑正确。
- **性能优化**:当编译器知道一个虚函数是 `final` 时,在可以通过静态类型确定实际对象类型的情况下(例如直接调用或通过 `final` 类),可以执行**去虚化(devirtualization)优化**,将虚函数调用转换为直接调用,消除通过虚函数表查询的开销。使用原则
- `final` 只能用于虚函数,且必须位于函数声明的尾部(参数列表之后、函数体或 `=0` 之前)。
- 如果基类中的虚函数被声明为 `final`,派生类中任何试图重写该函数的行为都会导致编译错误。
- 即使派生类中不写 `override`,编译器也会因为尝试重写 `final` 函数而报错。2. final 用于类
在类定义后添加 final,表示该类不能被继承。任何试图派生自 final 类的行为都会导致编译错误。
cpp
class FinalClass final {
// ...
};
// class Derived : public FinalClass { }; // 错误!不能继承 final 类设计意图
- **防止误用**:某些类不是为继承设计的(如很多标准库类),将其设为 `final` 可以防止用户错误地继承并可能导致未定义行为(例如非虚析构函数、切片等问题)。
- **优化机会**:对于 `final` 类,编译器可以更加激进地进行去虚化,因为任何指向该类对象的指针或引用都不可能实际指向派生类对象(不存在派生类)。3. final 与 override 同时使用
final 和 override 可以同时出现在一个函数声明中,此时该函数既是重写,又禁止后续重写。常见写法:
cpp
class Derived : public Base {
public:
void foo() override final; // 重写 Base::foo,并且不能再被重写
};4. 性能影响
- 去虚化优化 :编译器如果能确定实际对象的类型,即使函数没有标记为
final,也可能进行去虚化(如通过对象直接调用)。但final关键字提供了更明确的保证,尤其是在通过基类指针或引用调用时,如果该指针指向的是一个final类对象,编译器可以直接优化。 - 二进制兼容性 :将类声明为
final后,其虚函数表布局不再需要为未来的派生类预留扩展空间,这可能对二进制接口(ABI)有影响,但在应用内部通常无需担心。
5.4.5 隐藏 vs 重载 vs 覆盖
这三个概念初学者极易混淆,我们用表格明确区分:
| 概念 | 发生条件 | 作用域 | 特点 |
|---|---|---|---|
| 重载 | 同一作用域内,函数名相同,参数列表不同 | 同一作用域 | 编译器根据参数选择调用哪个版本 |
| 隐藏 | 派生类定义同名函数(与基类函数参数无关) | 不同作用域(基类vs派生类) | 基类所有同名函数都被屏蔽 |
| 覆盖 | 派生类定义与基类虚函数完全相同的函数 | 不同作用域,但涉及虚函数表 | 实现多态,运行时根据对象类型决定 |
简单来说:
- 重载:一个类里的多个同名函数。
- 隐藏:子类和父类的同名函数(不管参数),子类把父类的屏蔽了。
- 覆盖:特指子类重写父类的虚函数,是实现多态的基础。
隐藏与覆盖的底层区别:
- 覆盖涉及虚函数表,派生类会替换虚表中对应槽位的函数地址。
- 隐藏是名称查找规则导致的:派生类作用域中的名称会"遮蔽"基类作用域中的同名名称,无论是否是虚函数。即使基类函数是虚函数,如果派生类定义了一个同名的非虚函数,也会导致基类虚函数被隐藏(但可以通过
Base::显式调用)。
析构函数重写的特例 :
如果基类的析构函数是虚函数,那么派生类的析构函数(无论是否加virtual关键字)都与基类的析构函数构成重写。虽然名字不同(~Base vs ~Derived),但编译器在内部会将析构函数统一处理为destructor,因此这属于一种特殊的重写规则。这也是为什么只要一个类可能被继承,就应该将其析构函数声明为虚函数的原因。
5.5 虚函数表(vtable)------多态的底层实现
理解虚函数表(简称虚表),是理解 C++ 多态的钥匙。虽然平时编程不需要直接操作它,但了解其原理能帮你避免很多坑。
5.5.1 什么是虚函数表?
每个包含虚函数的类,编译器都会为它生成一张虚函数表(vtable) 。这张表是一个函数指针数组,按声明顺序存储着该类所有虚函数的地址。
每个对象中会额外添加一个指针------虚表指针(vptr),指向该类对应的虚函数表。
以下是一个简单示例,用于直观展示虚函数表的内存结构:
cpp
#include <iostream>
using namespace std;
class Shape {
public:
virtual void draw() { cout << "Shape::draw" << endl; }
int x, y; // 普通成员变量
};
int main() {
Shape s;
// 获取对象的起始地址
cout << "对象地址: " << &s << endl;
// 对象的前8字节(64位系统)就是 vptr,指向虚函数表
intptr_t* vptr = *(intptr_t**)&s; // 取出 vptr 的值
// intptr_t 是一个足以容纳指针宽度的整形类型
// 在64为机器上,intptr_t 就是 long int, 在32位机器上, intptr_t 就是int
cout << "vptr 指向的虚表地址: " << vptr << endl;
// 虚表的第一个槽位就是 draw 函数的地址
cout << "虚表第一个槽位(draw地址): " << (void*)vptr[0] << endl;
// 通过函数指针调用 draw
typedef void(*DrawFunc)(Shape*);
((DrawFunc)vptr[0])(&s); // 输出 Shape::draw
return 0;
}对象内存布局:
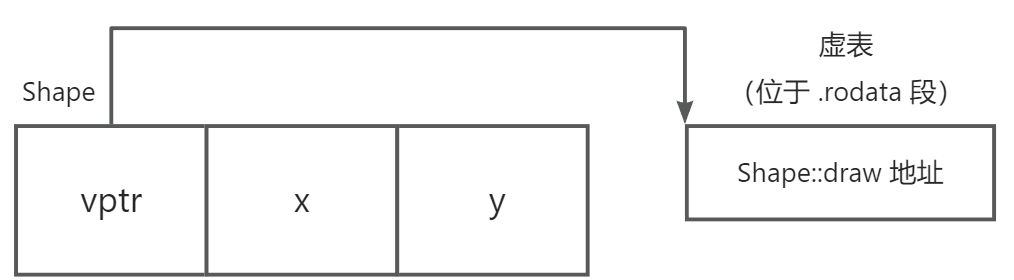
关键点:
- 每个类(只要包含虚函数)都有自己唯一的虚表,同一类的所有对象共享这一张虚表。
- 即使派生类没有新增虚函数,但只要它重写了基类的虚函数,它仍然会拥有自己独立的虚表(其中覆盖了相应槽位)。
- 不同类的虚表在内存中是独立的,绝不会共用。
虚函数表的内存位置
虚函数表存储在只读数据段(.rodata),由编译器生成,程序运行期间不会改变。虚表指针存储在对象内部,通常位于对象的起始位置。
这意味着:
- 每个对象都有自己的虚表指针(4或8字节)。
- 同一个类的所有对象共享同一张虚函数表。
- 虚函数表本身不占用对象空间,只占用代码段空间。
5.5.2 单继承下的虚函数表
cpp
class Base {
public:
virtual void func1() { cout << "Base::func1" << endl; }
virtual void func2() { cout << "Base::func2" << endl; }
};
class Derived : public Base {
public:
virtual void func1() override { cout << "Derived::func1" << endl; }
virtual void func3() { cout << "Derived::func3" << endl; } // 新增虚函数
};内存布局:
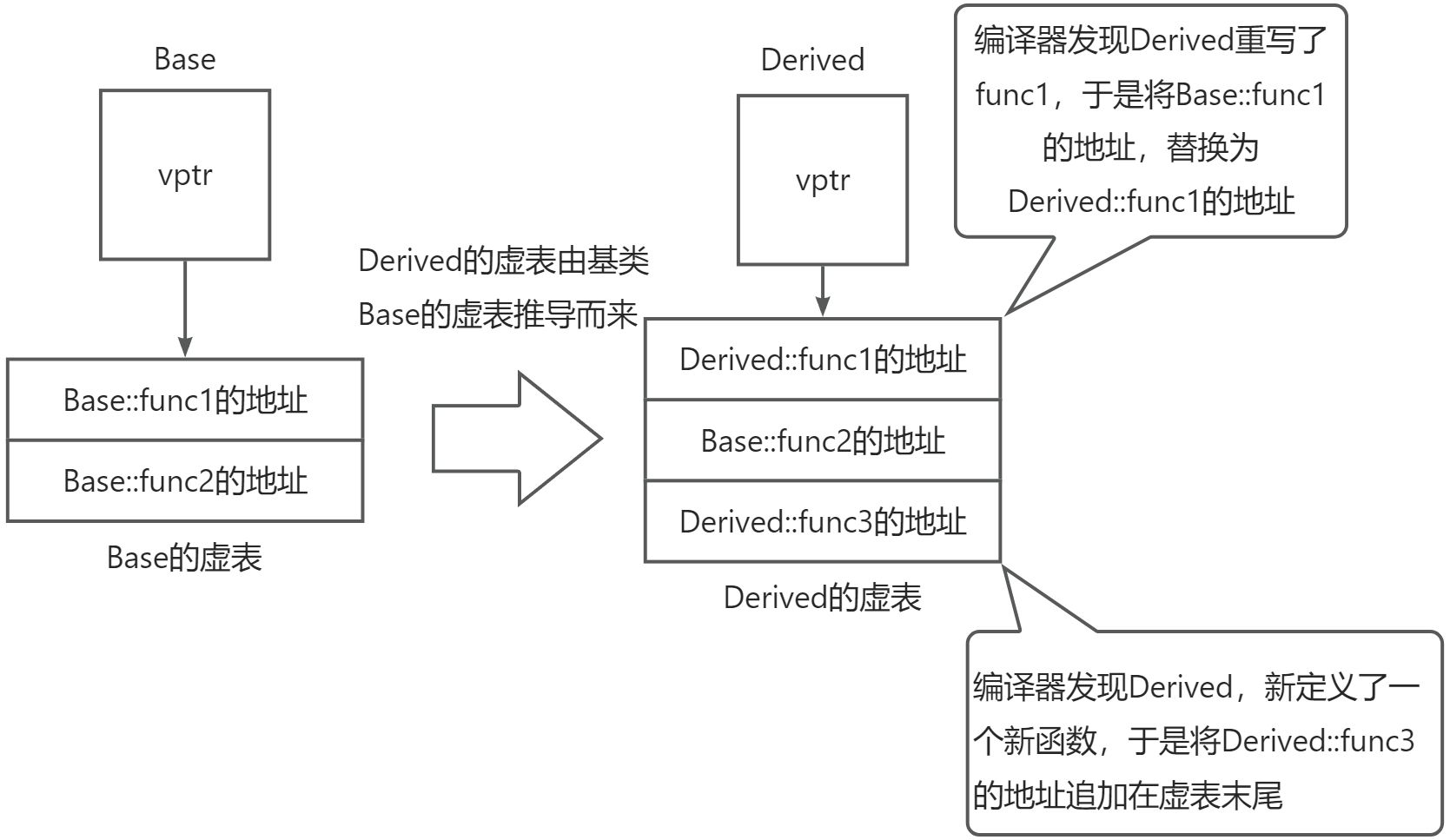
关键点:
- 重写的函数会覆盖虚表中对应位置的基类函数地址。
- 新增的虚函数追加在虚表末尾。
- 虚表是类级别的,同一个类的所有对象共享同一张虚表。
5.5.3 虚函数调用的动态绑定过程
当通过基类指针调用虚函数时,编译器将其转换为类似下面的伪代码:
cpp
// p->func()
(*(p->vptr)[函数索引])(p); // 通过虚表找到真正的函数地址并调用以p->func1()为例:
- 从对象
p指向的内存中取出vptr。 - 通过
vptr找到虚函数表。 - 在虚函数表中找到
func1对应的槽位(索引0)。 - 调用该地址指向的函数,并将
p作为this指针传入。
这个过程发生在运行时,因此称为动态绑定。
性能开销:每次虚函数调用比普通函数调用多两次内存读取(取vptr、取函数地址)和一次间接跳转。现代CPU的分支预测可以在一定程度上缓解,但在性能关键路径上仍需注意。
5.5.4 验证虚函数表的存在
我们可以通过一些技巧,窥探虚函数表的内容:
cpp
#include <iostream>
using namespace std;
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
int main() {
Base b;
// 将对象地址转换为int*,取前4/8字节(vptr的值)
intptr_t* vptr = (intptr_t*)*(intptr_t*)&b;
cout << "虚函数表地址:" << vptr << endl;
cout << "第一个虚函数地址:" << (void*)vptr[0] << endl;
cout << "第二个虚函数地址:" << (void*)vptr[1] << endl;
cout << "第三个虚函数地址:" << (void*)vptr[2] << endl;
// 直接通过函数指针调用
typedef void(*FuncPtr)();
((FuncPtr)vptr[0])(); // 输出:Base::f
((FuncPtr)vptr[1])(); // 输出:Base::g
((FuncPtr)vptr[2])(); // 输出:Base::h
}这个例子展示了虚函数表确实是一个连续的数组,里面存放着函数地址。
5.5.5 多重继承下的虚函数表
当类从多个基类继承时,虚表机制更加复杂。每个基类都有自己的虚表,派生类会生成多张虚表(每个基类对应一张),并包含多个vptr。
cpp
class Base1 {
public:
virtual void f1() {}
int b1;
};
class Base2 {
public:
virtual void f2() {}
int b2;
};
class Derived : public Base1, public Base2 {
public:
virtual void f1() override {}
virtual void f2() override {}
virtual void f3() {}
int d;
};Derived对象内存布局(典型实现):
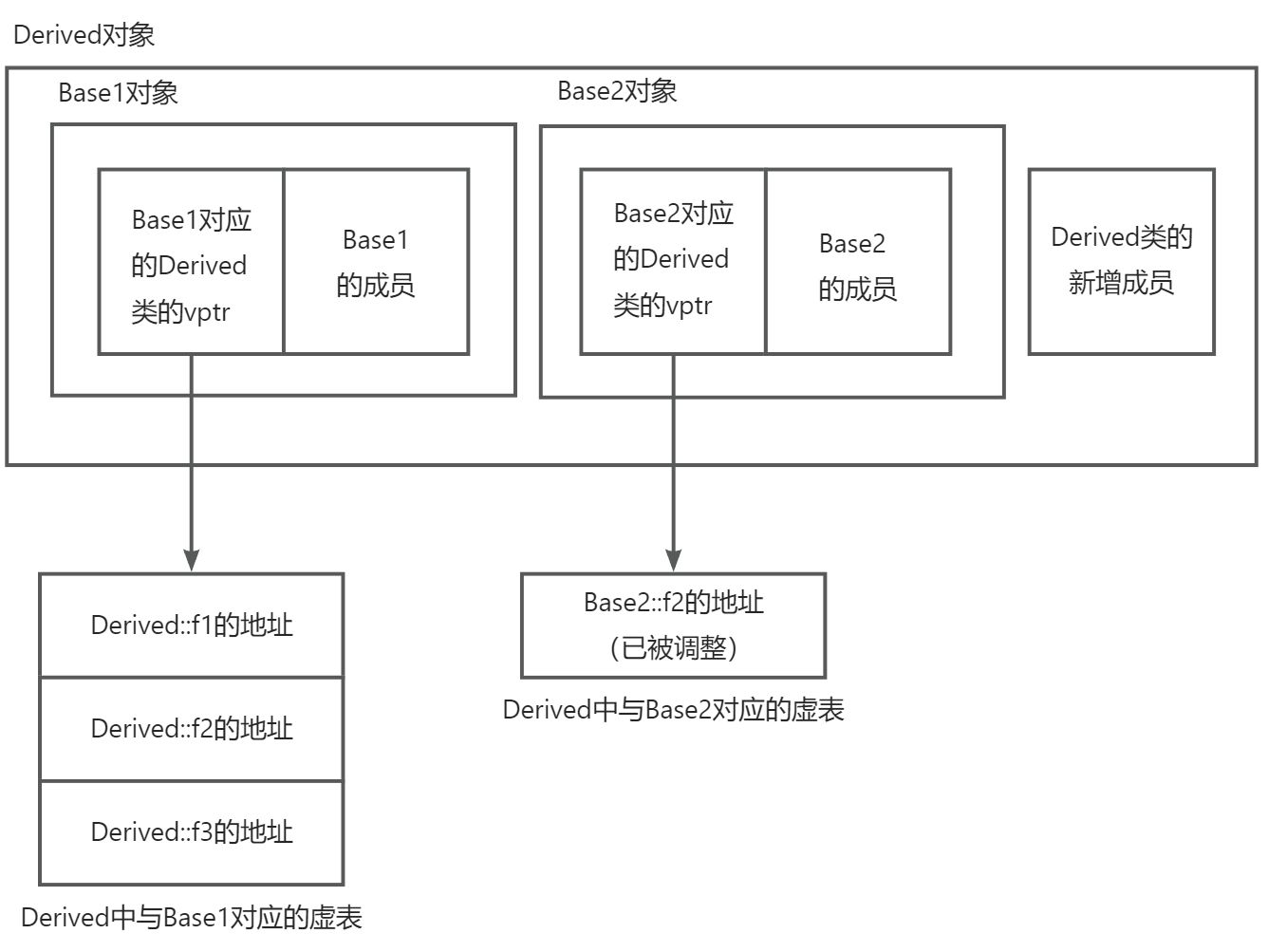
虚表内容
- 与
Base1对应的虚表:[Derived::f1, Derived::f2?, Derived::f3?]。实际上,这张虚表包含:- 从
Base1继承的虚函数(若Derived重写则替换)。 Derived新增的虚函数(如f3)通常追加在第一张虚表的末尾。- 对于来自
Base2但需要从Base1子对象调用的函数(如f2),编译器可能会在虚表中插入thunk (调整块),用于在调用前将this指针调整到正确的子对象位置。
- 从
- 与
Base2对应的虚表:[Derived::f2],仅包含与Base2相关的虚函数(包括重写),不包含新增的f3。
this指针调整
当通过Base2*指针调用f2()时,编译器需要将this从Base2子对象的起始位置调整为Derived对象的起始位置(即减去sizeof(Base1))。这种调整通过thunk 实现,thunk是一小段代码,位于虚表槽位,先调整this,再跳转到真正的函数。例如:
当我们通过 Base2* 指针调用 f2() 时:
cpp
Derived d;
Base2* p = &d; // p 指向 Base2 子对象的起始位置(即偏移了 sizeof(Base1))
p->f2(); // 需要调用 Derived::f2此时 p 指向的是 Base2 子对象的开头,而不是整个 Derived 对象的开头。而 Derived::f2 的 this 指针期望的是 Derived* 类型,指向对象起始处。因此,在跳转到 Derived::f2 之前,需要将 this 从 Base2* 调整为 Derived*(即减去 sizeof(Base1))。
thunk 正是完成这一调整的小段代码。
thunk 的工作原理
在 Derived 的第二张虚表(对应 Base2)中,f2 的槽位并不直接存放 Derived::f2 的地址,而是存放一个 thunk 的地址。这个 thunk 的伪代码大致如下:
z80
; thunk 代码(x86-64 示例)
adjust_this:
sub rdi, offset_of_Base2 ; 将 this 从 Base2* 调整为 Derived*
jmp Derived::f2 ; 跳转到真正的函数(其中 rdi 是 this 指针所在的寄存器)
当通过 Base2* 调用 f2() 时:
- 从
Base2子对象的 vptr 中找到虚表,取出第f2个槽位(即 thunk 地址)。 - 调用 thunk,thunk 将
this指针调整后,再跳转到真正的Derived::f2。 - 在
Derived::f2中,this已经是正确的Derived*,可以安全访问所有成员。
thunk 在内存中的位置
- thunk 通常紧邻虚表,存储在只读代码段(如
.text段)。 - 编译器为每个需要调整的虚函数槽位生成一个 thunk。
- 不同类、不同继承关系的 thunk 各不相同。
为什么派生类不能共用基类的虚表?
即使Derived没有重写Base2的任何函数,它的第二张虚表与Base2的虚表在函数指针内容上可能相同,但绝不能共用,原因如下:
- RTTI信息(第六章讲解)不同 :虚表中通常包含指向
type_info的指针,Derived对象的第二张虚表必须指向Derived的类型信息,而Base2的虚表指向Base2的类型信息。 - 调整信息不同 :
Derived的第二张虚表可能需要包含thunk以正确调整this指针,而Base2的虚表没有这些调整。 - 独立性:每个类拥有自己独立的虚表是C++对象模型的基本要求,确保了类型安全和多态的正确性。
5.5.6 虚继承下的虚函数表
虚继承(virtual继承)用于解决菱形继承问题,它的虚表机制更加复杂。虚基类子对象的位置不是固定的,而是通过虚基类指针(vbptr)或虚基类偏移表(vbtable)来定位。
cpp
class A { virtual void f(); int a; };
class B : virtual public A { virtual void g(); int b; };
class C : virtual public A { virtual void h(); int c; };
class D : public B, public C { virtual void i(); int d; };D对象布局(典型实现,如Itanium ABI):
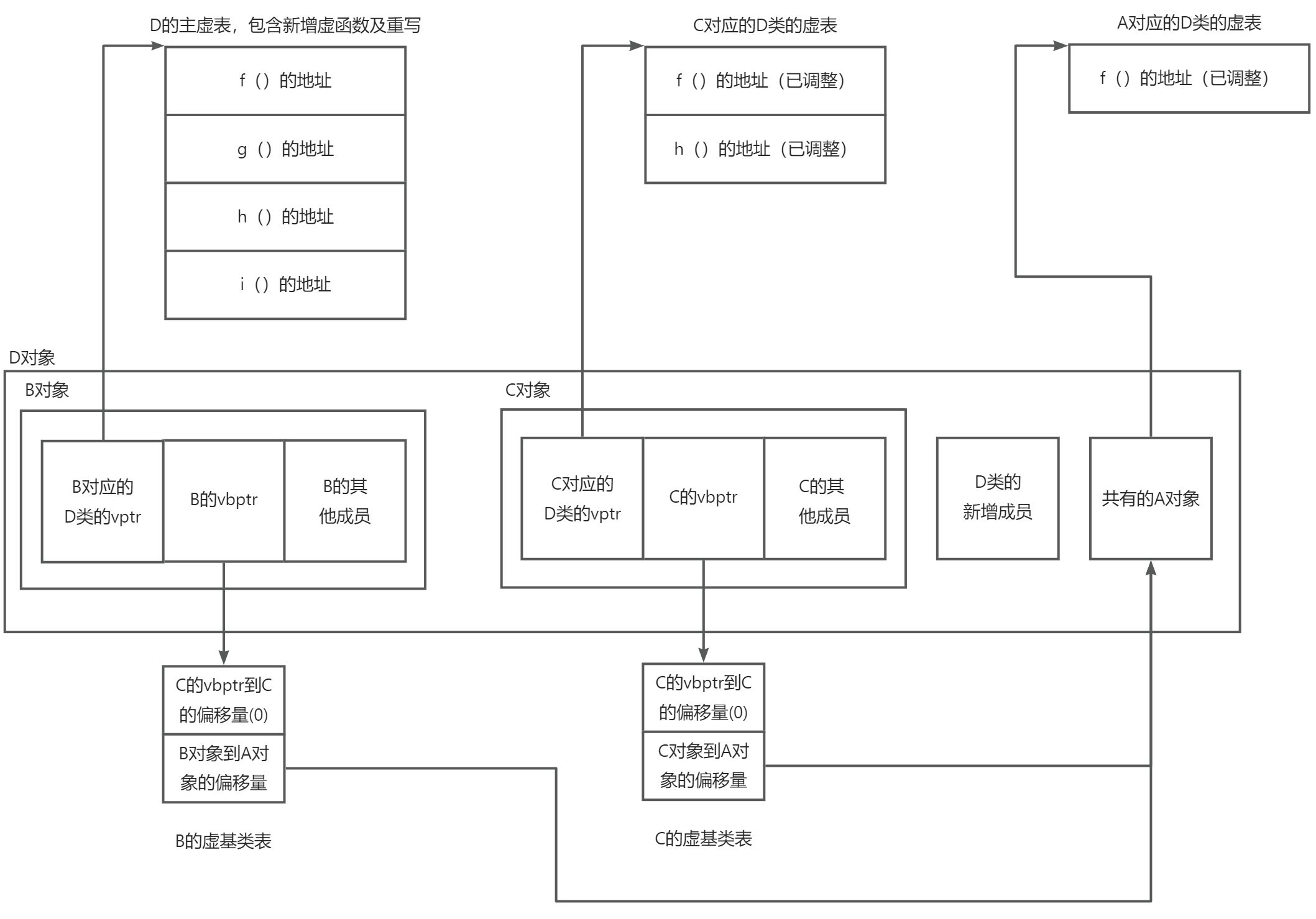
关键点:
- 每个含有虚基类的子对象(
B、C)都有一个vbptr,指向一个虚基类偏移表(vbtable),表中存储了该子对象到各个虚基类子对象的偏移量。 - 虚基类子对象(
A)只存在一份,位于对象末尾。 - 虚表本身也可能包含偏移信息(尤其在MSVC中),以便在通过虚基类指针调用虚函数时正确计算
this。
vptr与vbptr的顺序 :
通常,vptr位于子对象的最前面,vbptr紧随其后(或与vptr合并)。在Itanium ABI中,每个子对象内部布局为:[vptr][vbptr][成员]。因此,vptr在前,vbptr在后。
虚函数调用在虚继承下的额外开销 :
通过虚基类指针调用虚函数时,需要先通过vbptr定位虚基类子对象,再通过vptr找到虚表,增加了两次间接访问。
5.5.7 虚表的构建过程与构造顺序
在构造对象时,vptr的指向会随着构造阶段的推进而逐步更新。编译器在生成的构造函数中隐式插入设置vptr的代码。
单继承示例:
cpp
class Base { virtual void f(); };
class Derived : public Base { void f() override; };构造顺序:
- 进入
Derived构造函数前,先调用Base构造函数。 - 在
Base构造函数中,对象的vptr被设置为指向Base的虚表。 Base构造函数体执行。- 返回
Derived构造函数,编译器将vptr重新设置为指向Derived的虚表。 Derived构造函数体执行。
多重继承示例 :
构造顺序:先构造第一个基类(设置其子对象的vptr),再构造第二个基类,最后构造派生类(设置所有vptr指向派生类的对应虚表)。
虚继承示例 :
构造顺序更复杂:先构造虚基类,再按继承顺序构造其他基类,最后构造最派生类。在每个阶段,相应的vptr和vbptr都会被设置。
关键结论:
- 在构造函数中 调用虚函数,不会发生多态,因为此时vptr仍指向当前正在构造的类的虚表,而不是最终派生类的虚表。
- 析构函数中同样如此,vptr随着析构的进行逐步恢复为基类虚表。
5.5.8 常见陷阱
- 跨编译器/平台兼容性 :虚函数表的布局是实现定义的,不同编译器(GCC、Clang、MSVC)的细节不同。因此,跨DLL传递多态对象时需谨慎,最好使用接口类(纯虚类)并保持相同的编译器版本。
- 构造函数中vptr的变化:在构造函数中,对象的vptr会随着构造的深入而改变(从基类逐步指向当前类),这就是为什么构造函数中调用虚函数不会发生多态。
- 对象切片:将派生类对象按值赋给基类对象时,派生类的vptr丢失,多态失效。
- 误用final与override :合理使用
final和override可以帮助编译器进行去虚化优化,提高性能。 - 不要依赖虚表布局:直接操作vptr或虚表是未定义行为,仅用于教学或极端调试。
通过深入理解虚函数表的原理、布局以及构造过程中的行为,可以编写出更安全、高效的多态代码,并有效避免常见的陷阱。
5.6 虚析构函数
5.6.1 为什么需要虚析构函数?
考虑这样一个场景:通过基类指针指向动态分配的派生类对象,然后delete这个指针。
cpp
#include <iostream>
using namespace std;
class Base {
public:
Base() { cout << "Base构造" << endl; }
~Base() { cout << "Base析构" << endl; } // 非虚析构
};
class Derived : public Base {
public:
Derived() { cout << "Derived构造" << endl; }
~Derived() { cout << "Derived析构" << endl; }
};
int main() {
Base* p = new Derived();
delete p; // 会发生什么?
}运行结果:
plain
Base构造
Derived构造
Base析构看到问题了吗?Derived的析构函数没有被调用!这会导致派生类中可能分配的资源(如堆内存)无法释放,造成内存泄漏。
为什么?因为delete p时,编译器看到p是Base*类型,根据静态类型决定调用Base::~Base()。它不知道(也不关心)p实际指向的是Derived对象。
5.6.2 虚析构函数
析构函数是一种特殊的成员函数。当一个类定义了虚析构函数,编译器会将其放入该类的虚函数表中,就像普通的虚函数一样。
- 如果基类
Base的析构函数是virtual,那么派生类Derived的析构函数自动成为虚函数 (即使没有显式写virtual)。 - 派生类的析构函数会覆盖基类析构函数在虚表中的槽位。
因此,将基类的析构函数声明为virtual,问题就解决了:
cpp
class Base {
public:
virtual ~Base() { cout << "Base析构" << endl; }
};
// 派生类的析构函数自动成为虚函数(即使不加virtual)现在运行结果:
plain
Base构造
Derived构造
Derived析构
Base析构原理 :析构函数被声明为虚函数后,delete p会通过虚函数表动态绑定,调用p实际指向对象的析构函数。Derived的析构函数执行完后,会自动调用基类析构函数(这是析构函数的默认行为)。
注意:对于含有虚析构函数的类,其析构函数地址会存放在虚表的某个固定槽位(通常是第一个槽位,或者紧随其他虚函数之后,具体取决于实现)。
5.6.2 使用法则
- 只要一个类可能被继承,就应该将析构函数声明为虚函数。
- 如果一个类不是作为基类使用(比如不会被继承),则不需要虚析构(可以节省一个虚表指针的空间)。
标准库中的很多类(如string、vector)都不是为继承设计的,因此它们的析构函数不是虚函数。如果你继承它们并多态使用,就会出问题。
5.7 构造函数与虚函数
5.7.1 构造函数为什么不能是虚函数?
这是一个经典的面试题。原因有几点:
- 构造对象必须知道具体类型:调用虚函数需要通过虚表,而虚表指针是在构造函数执行期间才初始化的。在构造函数执行前,虚表指针是未初始化的或指向当前类的虚表。如果构造函数是虚函数,需要先通过虚表找到构造函数,但此时虚表指针尚未设置,形成循环依赖。
- 虚函数调用依赖于对象:虚函数是对象级别的多态,而构造函数执行时对象还没有完全构造好。在基类构造过程中,派生类部分尚未存在,因此无法调用派生类的函数(就无法构成多态)。
- 语法上不支持 :C++规定
virtual不能用于构造函数。
5.7.2 构造函数中调用虚函数会怎样?
cpp
#include <iostream>
using namespace std;
class Base {
public:
Base() {
cout << "Base构造中:";
func(); // 在构造函数中调用虚函数
}
virtual void func() { cout << "Base::func" << endl; }
};
class Derived : public Base {
public:
Derived() {
cout << "Derived构造中:";
func();
}
void func() override { cout << "Derived::func" << endl; }
};
int main() {
Derived d;
}运行结果:
plain
Base构造中:Base::func
Derived构造中:Derived::func结论 :构造函数中调用虚函数,不会发生多态,只会调用当前类的版本。这是因为基类构造时,派生类部分还没构造,虚表指针指向的是基类的虚表。
vptr变化过程:
- 进入
Base构造函数:vptr→Base的虚表 Base构造函数体执行完毕- 进入
Derived构造函数:vptr→Derived的虚表 Derived构造函数体执行
5.7.3 析构函数中调用虚函数
这个规则同样适用于析构函数:析构函数中调用虚函数,也是调用当前类的版本(因为派生类部分可能已经被析构了)。在析构函数执行过程中,对象的vptr会随着析构的进行逐步恢复为基类的虚表(从派生类到基类)。
cpp
class Base {
public:
virtual ~Base() {
func(); // 调用的是 Base::func
}
virtual void func() { cout << "Base::func" << endl; }
};
class Derived : public Base {
public:
~Derived() override { }
void func() override { cout << "Derived::func" << endl; }
};当Derived对象析构时,先进入Derived析构函数(此时vptr指向Derived的虚表),执行完毕后vptr被调整为指向Base的虚表,然后调用Base析构函数,其中func()调用的是Base::func。
5.8 纯虚函数与抽象类
5.8.1 纯虚函数的定义
有些基类本身不应该被实例化,它存在的意义是定义接口,让派生类去实现。这种类称为抽象类。定义抽象类的方法是在类中声明纯虚函数。
纯虚函数 是一个在基类中声明但没有(或可以没有)实现的虚函数,通过 = 0 标记,强制派生类必须提供自己的实现。
cpp
class Shape {
public:
// 纯虚函数:没有函数体,用 =0 标记
virtual double area() const = 0;
virtual void draw() const = 0;
};5.8.2 抽象类的特性
- 不能实例化抽象类:
cpp
// Shape s; // 错误!不能创建抽象类的对象
Shape* p; // 可以声明指针- 派生类必须实现所有纯虚函数,否则派生类也是抽象类:
cpp
class Circle : public Shape {
public:
// 如果没有实现 area 和 draw,Circle 也是抽象类
double area() const override { return 3.14 * r * r; }
void draw() const override { cout << "画圆" << endl; }
private:
double r;
};- 抽象类可以包含非纯虚函数和成员变量。
cpp
class Animal {
public:
// 成员变量
string name;
int age;
// 纯虚函数(接口规范)
virtual void sound() = 0;
// 非纯虚函数(有默认实现)
virtual void move() {
cout << "Animal moves." << endl;
}
// 普通成员函数
void printInfo() {
cout << name << ", " << age << endl;
}
};
class Dog : public Animal {
public:
// 必须实现纯虚函数
void sound() override {
cout << "Woof!" << endl;
}
// 可以选择不重写 move(),直接使用 Animal::move()
};
int main() {
// Animal a; // 错误:抽象类不能实例化
Dog d;
d.sound(); // 必须实现
d.move(); // 使用基类默认实现
d.printInfo(); // 继承的普通函数
}- 纯虚函数可以有定义(在类外提供实现),但仍然是纯虚函数,派生类必须重写它:
cpp
class Animal {
public:
virtual void sound() = 0; // 纯虚函数
};
void Animal::sound() { // 可以提供实现
cout << "某个声音" << endl;
}
class Dog : public Animal {
public:
void sound() override {
Animal::sound(); // 调用基类实现
cout << "汪汪" << endl;
}
};- 纯虚析构函数:如果析构函数被声明为纯虚,则类成为抽象类,但必须在类外提供函数体,因为析构函数在对象销毁时总会调用。
cpp
class AbstractBase {
public:
virtual ~AbstractBase() = 0; // 纯虚析构
};
AbstractBase::~AbstractBase() { } // 必须提供实现5.8.3 纯虚函数的应用场景
- 定义接口规范:例如图形库、插件系统,强制所有派生类实现规定的接口。
- 模板方法模式:基类定义算法骨架,派生类实现具体步骤。
cpp
class DataParser {
public:
void parse() { // 模板方法(非虚)
openFile();
readData();
processData();
closeFile();
}
protected:
virtual void openFile() = 0;
virtual void readData() = 0;
virtual void processData() = 0;
virtual void closeFile() = 0;
};- 防止基类被实例化:基类概念太抽象,不应该有实例。
- 提供默认实现:如前面所示,纯虚函数可以提供实现,派生类可以选择调用基类实现,实现"强制重写但允许复用"的设计。
- 工厂模式:抽象类作为产品基类,工厂方法返回抽象类指针,具体产品由派生类实现。
5.8.4 接口类(纯接口)
在 C++ 中,可以定义一个纯接口类------所有成员函数都是纯虚函数,没有成员变量。这类似于 Java 中的接口。
cpp
class IDrawable {
public:
virtual ~IDrawable() = default; // 虚析构
virtual void draw() const = 0;
};
class IClickable {
public:
virtual ~IClickable() = default;
virtual void onClick(int x, int y) = 0;
};
// 一个类可以实现多个接口
class Button : public IDrawable, public IClickable {
public:
void draw() const override { /* 绘制按钮 */ }
void onClick(int x, int y) override { /* 响应点击 */ }
};接口类的设计原则:
- 所有成员函数应为
public virtual(通常为纯虚)。 - 不应包含数据成员(否则会暴露实现细节,破坏接口的抽象性)。
- 必须提供虚析构函数(
virtual ~Interface() = default;),以确保通过接口指针删除对象时正确调用派生类的析构函数。 - 可以包含
protected辅助函数或static成员,但应保持接口简洁。
非虚接口(NVI)模式:有时为了统一控制接口行为,可以将公共接口设计为非虚,而将具体实现委托给私有虚函数。这既保持了接口的稳定性,又允许派生类定制行为。
cpp
class Base {
public:
void process() { // 非虚接口(NVI)
before();
doProcess();
after();
}
private:
virtual void doProcess() = 0; // 由派生类实现
void before() { /* 通用前置操作 */ }
void after() { /* 通用后置操作 */ }
};5.8.5 纯虚析构函数
纯虚析构函数是一个特例,其作用是让类成为抽象类,同时仍然允许对象被正确析构。
cpp
class Abstract {
public:
virtual ~Abstract() = 0; // 纯虚析构,使类抽象
};
Abstract::~Abstract() { } // 必须提供实现
class Concrete : public Abstract {
public:
~Concrete() override { } // 派生类析构函数自动调用 ~Abstract
};注意:
- 即使析构函数是纯虚的,派生类也不需要显式重写它(因为析构函数总是自动重写基类版本)。
- 如果忘记提供纯虚析构函数的实现,链接时会报错。
第六章 运行时类型识别(RTTI)
6.1 什么是RTTI?
RTTI(Run-Time Type Identification,运行时类型识别)是C++提供的一组机制,允许程序在运行时获取对象的实际类型信息。RTTI主要用于处理多态场景下的类型判断,是面向对象编程中解决类型转换、动态分发等问题的重要工具。
C++通过以下方式支持RTTI:
typeid运算符 :获取表达式的类型信息,返回std::type_info对象的引用dynamic_cast运算符:安全地将基类指针/引用转换为派生类指针/引用
RTTI主要应用于多态场景,需要类包含至少一个虚函数。这是因为RTTI的实现依赖于虚函数表(vtable),编译器会在虚表中存储指向类型信息的指针。
RTTI的设计目标:
- 处理异构容器(如存储基类指针的容器,实际元素是不同派生类对象)
- 复杂对象的序列化/反序列化
- 调试与日志中的类型信息记录
- 设计模式(如Visitor模式)的实现
6.2 typeid
6.2.1 基本用法
typeid 是 C++ 运行时类型识别(RTTI)的核心运算符,用于获取表达式的类型信息。它返回一个 std::type_info 对象的常量引用,该对象封装了类型的具体信息。
cpp
#include <iostream>
#include <typeinfo>
int main() {
int i;
std::cout << typeid(i).name() << std::endl; // 输出取决于编译器(可能为"int"或"i")
std::cout << typeid(double).name() << std::endl; // 可能为"double"或"d"
Animal* p = new Dog();
std::cout << typeid(p).name() << std::endl; // 输出指针类型:"Animal*"
std::cout << typeid(*p).name() << std::endl; // 输出实际对象类型:"Dog"(多态)
delete p;
}关键点:
typeid可以作用于类型名 或表达式。- 当作用于表达式时,如果该表达式的类型是多态类型 (即类包含虚函数),则
typeid在运行时计算表达式的动态类型;否则,在编译期确定静态类型。 - 返回的
std::type_info引用在程序整个生命周期内有效。
6.2.2 多态与非多态类型的行为差异
typeid 的行为完全取决于操作数的类型是否为多态类型(即类是否至少有一个虚函数)。下表总结了关键区别:
| 场景 | 非多态类型(无虚函数) | 多态类型(有虚函数) |
|---|---|---|
| 变量直接类型 | 静态类型(声明类型) | 静态类型(声明类型) |
| 基类指针指向派生类对象 | 静态类型(基类) | 动态类型(派生类) |
| 基类引用绑定派生类对象 | 静态类型(基类) | 动态类型(派生类) |
示例:
cpp
#include <iostream>
#include <typeinfo>
using namespace std;
class NonPolyBase {}; // 非多态类(无虚函数)
class NonPolyDerived : public NonPolyBase {};
class PolyBase { public: virtual ~PolyBase() = default; }; // 多态类
class PolyDerived : public PolyBase {};
int main() {
// 非多态类型测试
NonPolyBase* npb = new NonPolyDerived();
cout << "Non-poly typeid(*npb): " << typeid(*npb).name() << endl; // 输出NonPolyBase
// 多态类型测试
PolyBase* pb = new PolyDerived();
cout << "Poly typeid(*pb): " << typeid(*pb).name() << endl; // 输出PolyDerived
delete npb;
delete pb;
return 0;
}深层原理:
- 对于非多态类型,编译器可以直接从静态类型推导出
type_info信息,因此在编译时就能确定。 - 对于多态类型,对象的虚表指针(vptr)指向的虚表中包含了该类的
type_info指针。typeid(*p)实际上是通过 vptr 获取该指针,从而得到动态类型信息。
6.2.3 type_info 类的使用
std::type_info 是标准库中唯一用于表示类型信息的类,定义在 <typeinfo> 头文件中。它提供了以下成员函数和操作符:
cpp
const type_info& ti1 = typeid(Dog);
const type_info& ti2 = typeid(*animalPtr);
// 比较类型是否相同
if (ti1 == ti2) {
cout << "是同一种类型" << endl;
}
// 获取类型名称(编译器相关)
cout << ti1.name() << endl;
// 排序用的哈希值(可用于map)
cout << ti1.hash_code() << endl;
// 比较类型的排序顺序(用于关联容器)
if (ti1.before(ti2)) {
cout << "ti1排在ti2之前" << endl;
}重要特性:
- 不可复制 :
type_info类的拷贝构造函数和赋值运算符是私有的(C++98)或删除的(C++11),因此不能直接复制type_info对象。只能通过typeid返回的引用来访问。 - 生命周期 :
type_info对象由编译器生成并存储在静态存储区,其生命期贯穿整个程序运行期,因此引用可以安全保存。 name()** 返回值**:返回一个实现定义的字符串,通常为类型修饰名(mangled name)。在 GCC/Clang 中,需要解修饰才能获得可读名称;MSVC 返回的字符串可能已经可读(如class Dog)。before()** 函数**:提供类型的严格弱序,可用于在关联容器(如std::map)中作为键,但需注意不同编译单元中同一类型的type_info对象可能不同,导致before()行为不一致。实际中,更常用hash_code()或直接比较name()字符串。hash_code()** 函数**(C++11 起):返回一个与类型关联的哈希值,可用于无序容器(如std::unordered_map)中作为键。
6.2.4 类型名称美化(解修饰)
在 GCC 和 Clang 中,typeid(T).name() 返回的是修饰后的名称(mangled name),例如:
int→iconst int*→PKistd::string→NSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEEDog→3Dog(或类似)
为了获得可读的类型名称,可以使用 <cxxabi.h> 中的 __cxa_demangle 函数进行解修饰:
cpp
#include <iostream>
#include <typeinfo>
#include <cxxabi.h>
#include <memory>
std::string demangle(const char* name) {
int status;
std::unique_ptr<char, void(*)(void*)> demangled(
abi::__cxa_demangle(name, nullptr, nullptr, &status),
std::free
);
return (status == 0) ? demangled.get() : name;
}
int main() {
Dog d;
std::cout << demangle(typeid(d).name()) << std::endl; // 输出 "Dog"
}注意 :__cxa_demangle 是 Itanium C++ ABI 的一部分,因此仅适用于遵循该 ABI 的编译器(如 GCC、Clang)。在 MSVC 上,typeid(T).name() 通常返回已修饰但可读的名称(如 class Dog),无需解修饰,但也可以通过 Windows API 的 UnDecorateSymbolName 进一步处理。
跨平台兼容性:如果需要跨编译器获取可读类型名,可以定义一个宏或函数,根据编译器选择不同的实现。
6.2.5 typeid 的异常情况
当 typeid 作用于一个空指针的解引用 时,会抛出 std::bad_typeid 异常。这是因为空指针没有有效的对象,无法获取其动态类型信息。
cpp
Animal* p = nullptr;
try {
std::cout << typeid(*p).name() << std::endl; // 抛出 bad_typeid 异常
} catch (const std::bad_typeid& e) {
std::cout << "Exception: " << e.what() << std::endl;
}注意:
- 对于非多态类型的空指针,
typeid(*p)的行为是未定义的(通常会导致程序崩溃或未定义行为)。 - 对于多态类型的空指针,标准规定必须抛出
bad_typeid异常(C++ 标准 expr.typeid/3)。
6.2.6 typeid 的实现原理与性能
typeid 的实现依赖于编译器在虚函数表中存储的 RTTI 信息。以 Itanium ABI 为例,每个多态类的虚函数表(vtable)前部会包含一个指向 std::type_info 对象的指针:
plain
虚函数表布局(简化):
+---------------------+
| offset_to_top | ← 从当前子对象到完整对象起始的偏移
+---------------------+
| typeinfo pointer | ← 指向 std::type_info 对象
+---------------------+
| virtual function 1 |
+---------------------+
| ... |
+---------------------+对于多态类型,typeid(*ptr) 的典型操作流程:
- 从
ptr指向的对象中读取 vptr(虚表指针)。 - 通过 vptr 减去一个固定偏移(如 -8 或 -4)得到
typeinfo pointer的地址。 - 返回该
typeinfo对象的引用。
对于非多态类型,typeid(T) 直接在编译期确定并返回全局唯一的 type_info 对象引用,没有运行时开销。
性能开销:
- 对于多态类型,
typeid类似于一次虚函数调用,代价是一次内存读取(取 vptr)和一次指针算术,非常轻量。 - 对于非多态类型,
typeid完全在编译期,零开销。 - 因此,在性能敏感场景中,如果可以通过编译期多态(如模板)避免
typeid,则优先采用。
6.2.7 类型比较的陷阱与注意事项
跨模块的 **typeid**** 比较**
当多态对象跨越 DLL 边界传递时,typeid 比较可能失败,因为不同模块中同一类的 type_info 对象可能是独立的副本,导致地址不同(在 Itanium ABI 中直接比较地址)。这会导致 typeid(obj) == typeid(Dog) 返回 false,即使对象的实际类型是 Dog。
解决方案:
- 确保所有模块使用相同的编译器和链接设置,并共享 RTTI 信息(如在 Windows 上使用
/MD链接同一 CRT)。 - 使用接口类与工厂模式,避免跨模块暴露具体类型(见 6.2.8 节)。
- 比较
typeid(obj).name()字符串(但需注意不同模块中name()返回的字符串可能相同,但比较字符串效率较低)。
与 dynamic_cast 的关系
typeid 用于获取类型信息,而 dynamic_cast 用于安全转换。两者都依赖于 RTTI,但用途不同:
typeid直接告诉你是哪种类型。dynamic_cast尝试将指针/引用转换为目标类型,转换失败时返回 null(或抛出异常)。
示例对比:
cpp
// 使用 typeid 判断类型
if (typeid(*animal) == typeid(Dog)) {
Dog* dog = static_cast<Dog*>(animal); // 需要 static_cast,但需确保类型正确
dog->bark();
}
// 使用 dynamic_cast 判断类型并转换
if (Dog* dog = dynamic_cast<Dog*>(animal)) {
dog->bark(); // 安全,转换成功
}通常,dynamic_cast 更安全,因为它自动进行指针调整(尤其是在多重继承中)并返回 null 失败。而 typeid 结合 static_cast 可能在多重继承下出现错误(如未调整指针)。
多重继承下的类型信息
在多重继承中,一个对象可能同时包含多个基类子对象。typeid 始终返回最派生类的类型信息(如果该类是多态的)。例如:
cpp
class A { virtual ~A() = default; };
class B : public A {};
class C : public A {};
class D : public B, public C {};
D d;
A* a1 = static_cast<B*>(&d);
A* a2 = static_cast<C*>(&d);
std::cout << typeid(*a1).name() << std::endl; // 输出 D(或修饰名)
std::cout << typeid(*a2).name() << std::endl; // 输出 D这是因为 a1 和 a2 实际上都指向同一个 D 对象的不同子对象,但虚表指针仍然指向 D 的虚表(其中存储了 type_info 指针指向 D 的类型信息)。
6.2.8 编译器的扩展与 RTTI 开关
大多数编译器允许通过编译选项关闭 RTTI,例如:
- GCC/Clang:
-fno-rtti - MSVC:
/GR-
当 RTTI 关闭时:
dynamic_cast不能用于多态类型(编译错误或行为未定义)。typeid对多态类型的行为未定义(可能返回静态类型或编译错误)。- 因此,在需要 RTTI 的代码中,必须确保编译选项中启用了 RTTI。
嵌入式/实时系统 :为减少代码大小和运行时开销,有时会禁用 RTTI,此时应完全避免使用 typeid 和 dynamic_cast。
6.2.9 标准库中的 typeid 使用
C++ 标准库中的一些组件也利用 typeid 实现类型擦除或调试,例如:
std::function内部可能使用typeid来检查可调用对象的类型(但标准未强制,具体实现可能不同)。- 异常类
std::bad_cast和std::bad_typeid继承自std::exception,可在 catch 块中使用typeid识别具体异常类型。
6.2.10 最佳实践
- 优先使用虚函数 :能用虚函数解决的问题,不要用
typeid判断类型。 - 使用
dynamic_cast而非typeid+static_cast:在需要转换时,用dynamic_cast更安全,尤其涉及多重继承。 - **避免在热路径中使用 **
typeid:虽然开销小,但仍有内存访问,对于极高性能场景可考虑编译期方案(如模板)。 - 跨模块传递对象时,慎用
typeid比较:使用接口类和工厂模式隔离 RTTI 依赖。 - 调试时使用解修饰的名称:在日志或错误消息中,使用解修饰后的类型名提高可读性。
- 注意
typeid与空指针 :确保指针非空再解引用,或捕获bad_typeid异常。
6.3 dynamic_cast
6.3.1 基本用法
dynamic_cast是C++提供的运行时类型识别(RTTI)操作符,用于在多态类型之间进行安全的向下转换(downcast,从基类到派生类)和交叉转换(crosscast,在兄弟类之间转换)。它是C++中唯一在运行时进行类型检查的转换操作符。
cpp
#include <iostream>
#include <typeinfo>
using namespace std;
class Animal {
public:
virtual ~Animal() = default; // 必须有虚函数才能使用dynamic_cast
};
class Dog : public Animal {
public:
void bark() { cout << "汪汪!" << endl; }
void wagTail() { cout << "摇尾巴" << endl; }
};
class Cat : public Animal {
public:
void meow() { cout << "喵喵~" << endl; }
void scratch() { cout << "抓挠" << endl; }
};
void playWithAnimal(Animal* animal) {
// 尝试转换为Dog* - 安全检查
Dog* dog = dynamic_cast<Dog*>(animal);
if (dog) {
cout << "这是狗:";
dog->bark();
dog->wagTail(); // 可以安全调用Dog特有的方法
return;
}
// 尝试转换为Cat*
Cat* cat = dynamic_cast<Cat*>(animal);
if (cat) {
cout << "这是猫:";
cat->meow();
cat->scratch(); // 可以安全调用Cat特有的方法
return;
}
cout << "未知动物类型" << endl;
}
int main() {
Dog dog;
Cat cat;
playWithAnimal(&dog); // 输出:这是狗:汪汪!摇尾巴
playWithAnimal(&cat); // 输出:这是猫:喵喵~抓挠
Animal a;
playWithAnimal(&a); // 输出:未知动物类型
}为什么必须有虚函数?
dynamic_cast依赖运行时类型信息(RTTI)来进行类型检查,而RTTI信息存储在类的虚函数表(vtable)中。只有定义了至少一个虚函数的类才会生成虚函数表,因此:
- 如果类没有虚函数,编译器不会为其生成RTTI信息
- 对非多态类型使用
dynamic_cast会导致编译错误
cpp
class NonPoly { }; // 没有虚函数
class Poly { virtual void f() { } }; // 有虚函数
NonPoly* np = new NonPoly();
Poly* p = new Poly();
// dynamic_cast<NonPoly*>(np); // 编译错误!NonPoly不是多态类型
// dynamic_cast<Poly*>(p); // 正确6.3.2 转换失败的返回值处理
dynamic_cast对于指针和引用的失败处理方式不同,这是由C++语言的基本设计决定的:指针可以为空,但引用不能为空。
指针转换失败 :返回nullptr,可以安全地进行条件判断。
cpp
void processAnimal(Animal* animal) {
Dog* dog = dynamic_cast<Dog*>(animal);
if (dog) {
// 转换成功,可以安全使用dog指针
dog->bark();
} else {
// 转换失败,dog为nullptr
cout << "这不是一只狗" << endl;
}
}引用转换失败 :抛出std::bad_cast异常,因为引用不能为nullptr。
cpp
#include <stdexcept>
void handleCat(Animal& animal) {
try {
Cat& cat = dynamic_cast<Cat&>(animal);
cat.meow();
cat.scratch();
} catch (const bad_cast& e) {
cout << "这不是猫,无法处理: " << e.what() << endl;
}
}
int main() {
Dog dog;
handleCat(dog); // 抛出bad_cast异常,被catch捕获
}为什么引用转换失败要抛异常?
引用在语义上永远不能是空引用(null reference),抛出异常是唯一安全的方式,让调用者有机会处理错误。
最佳实践:
- 指针转换:使用
if (ptr)检查,适合作为条件分支 - 引用转换:使用
try-catch块,适合在无法继续执行的场景中使用
6.3.3 向上转换(Upcast)
从派生类到基类的转换是向上转换,这种转换在编译时就可以确定是安全的,因为派生类对象一定包含基类子对象。因此:
- 不需要
dynamic_cast,编译器可以隐式完成 - 即使使用
dynamic_cast,它也会退化为静态转换(static_cast),没有运行时开销
cpp
Dog dog;
Animal* pa = &dog; // 隐式向上转换,安全
Animal& ra = dog; // 隐式向上转换,安全
// 显式使用dynamic_cast也可以,但没必要
Animal* pa2 = dynamic_cast<Animal*>(&dog); // 等价于隐式转换向上转换的内存布局 :
当派生类对象被转换为基类指针时,指针的值可能发生变化(尤其是在多重继承中)。这是因为派生类对象的内存布局中,基类子对象不一定位于对象的起始位置。
cpp
class Base1 { virtual void f1() { } int b1; };
class Base2 { virtual void f2() { } int b2; };
class Derived : public Base1, public Base2 { int d; };
Derived d;
Base2* p = &d; // p指向的是Derived对象中Base2子对象的起始位置
// 这个地址与&d不同(偏移了sizeof(Base1))6.3.4 三种转换场景
场景1:向上转换(Upcast)- 从派生类到基类
向上转换是安全的,编译器会自动处理指针偏移,无需运行时检查。
cpp
class Base {
public:
virtual void func() { cout << "Base::func()" << endl; }
};
class Derived : public Base {
public:
void func() override { cout << "Derived::func()" << endl; }
void derivedOnly() { cout << "Derived only" << endl; }
};
int main() {
Derived d;
Base* base_ptr = &d; // 隐式向上转换
base_ptr->func(); // 输出:Derived::func()(多态调用)
// base_ptr->derivedOnly(); // 错误!基类指针无法调用派生类特有方法
}场景2:向下转换(Downcast)- 从基类到派生类
向下转换是RTTI的核心应用场景,用于从基类指针获取派生类指针,以便访问派生类特有的成员。
cpp
#include <iostream>
#include <typeinfo>
using namespace std;
class Animal {
public:
virtual ~Animal() = default;
virtual void sound() const { cout << "Animal makes sound" << endl; }
};
class Dog : public Animal {
public:
void sound() const override { cout << "Dog barks" << endl; }
void wagTail() const { cout << "Dog wags tail" << endl; }
};
class Cat : public Animal {
public:
void sound() const override { cout << "Cat meows" << endl; }
void scratch() const { cout << "Cat scratches" << endl; }
};
void interactWithAnimal(Animal* animal) {
// 尝试转换为Dog指针
Dog* dog = dynamic_cast<Dog*>(animal);
if (dog) {
dog->sound();
dog->wagTail(); // 调用Dog特有方法
return;
}
// 尝试转换为Cat指针
Cat* cat = dynamic_cast<Cat*>(animal);
if (cat) {
cat->sound();
cat->scratch(); // 调用Cat特有方法
return;
}
cout << "Unknown animal type, only base behavior" << endl;
animal->sound(); // 调用基类的sound
}
int main() {
Animal* animals[] = {new Dog(), new Cat(), new Animal()};
for (auto animal : animals) {
interactWithAnimal(animal);
delete animal;
}
return 0;
}向下转换的内部原理 :
当执行dynamic_cast<Dog*>(animal)时,编译器生成的代码会:
- 从
animal指针指向的对象中取出vptr - 通过vptr找到虚函数表
- 从虚函数表中获取RTTI信息(通常存储在虚表的前面或后面)
- 遍历继承层次结构,检查目标类型(Dog)是否在对象的继承链中
- 如果找到,返回调整后的指针(可能需要偏移);如果未找到,返回nullptr
**场景3:交叉转换(Crosscast)- 兄弟类之间的转换 **
交叉转换是dynamic_cast独有的能力,用于在同一继承层次中的兄弟类之间进行转换,前提是它们有共同的虚基类。
cpp
class A {
public:
virtual ~A() = default;
virtual void a() { cout << "A::a" << endl; }
};
class B : public A {
public:
virtual void b() { cout << "B::b" << endl; }
};
class C : public A {
public:
virtual void c() { cout << "C::c" << endl; }
};
class D : public B, public C {
public:
void d() { cout << "D::d" << endl; }
};
void crosscastDemo() {
D d;
B* b_ptr = &d; // 向上转换到B
C* c_ptr = dynamic_cast<C*>(b_ptr); // 交叉转换:从B*到C*
if (c_ptr) {
cout << "交叉转换成功!" << endl;
c_ptr->c(); // 可以调用C的方法
}
// 更常见的场景:从A*转换到B*或C*
A* a_ptr = &d;
B* b2 = dynamic_cast<B*>(a_ptr); // 向下转换:A* -> B*
C* c2 = dynamic_cast<C*>(a_ptr); // 向下转换:A* -> C*
if (b2 && c2) {
cout << "都可以成功转换" << endl;
}
}交叉转换的底层原理 :
交叉转换需要dynamic_cast遍历整个对象的内存布局,找到目标子对象的位置。这涉及:
- 从源指针(如
B*)定位到完整的派生类对象(D)的起始位置 - 然后找到目标子对象(
C)的位置 - 返回指向该子对象的指针
这种操作比简单的向下转换更耗时,因为它需要更复杂的偏移计算。
为什么C风格转换不能正确处理交叉转换?
使用C风格强制转换((C*)b_ptr)会导致严重的错误:它只是简单地将指针值按位复制,而不进行任何调整。由于B和C子对象在D对象中位于不同的偏移位置,直接使用未调整的指针会导致:
- 访问错误的成员变量(指向了
B子对象的成员,但用C的类型来解释) - 调用虚函数时
this指针错误,可能导致程序崩溃
cpp
// 危险的C风格转换
B* b_ptr = &d;
C* bad_c = (C*)b_ptr; // 危险的!指针没有调整
bad_c->c(); // 未定义行为:可能崩溃或产生错误结果
// 正确的dynamic_cast
C* good_c = dynamic_cast<C*>(b_ptr); // 指针被正确调整
good_c->c(); // 安全6.3.5 实现原理与性能分析
底层实现机制
dynamic_cast的实现依赖于编译器在虚函数表中存储的RTTI信息。以Itanium C++ ABI(GCC、Clang使用)为例:
虚函数表布局(包含RTTI信息):
plain
+---------------------+
| offset_to_top | ← 从当前子对象到完整对象起始的偏移
+---------------------+
| typeinfo pointer | ← 指向std::type_info对象的指针
+---------------------+
| virtual function 1 | ← 第一个虚函数地址
+---------------------+
| virtual function 2 | ← 第二个虚函数地址
+---------------------+
| ... |
+---------------------+offset_to_top:用于在转换时调整this指针。当从派生类指针转换为基类指针时,需要知道基类子对象在完整对象中的偏移量。typeinfo pointer:指向类的类型信息,用于运行时类型比较。
转换过程(以向下转换为例):
- 从对象中获取vptr
- 通过vptr找到虚函数表
- 从虚函数表中获取
typeinfo pointer - 遍历继承层次,比较目标类型与对象的实际类型
- 如果匹配,根据
offset_to_top(或目标类型的偏移)调整指针 - 返回调整后的指针,或nullptr(如果转换失败)
性能开销
dynamic_cast的性能开销包括:
| 开销类型 | 说明 | 量级 |
|---|---|---|
| 内存访问 | 读取vptr和虚函数表 | 2-3次内存读取 |
| 类型比较 | 遍历继承层次,比较type_info | 取决于继承深度 |
| 指针调整 | 计算并应用偏移 | 少量算术运算 |
| 缓存影响 | 间接跳转可能影响分支预测 | 取决于CPU架构 |
性能优化建议:
- 优先使用虚函数 :如果可能,通过虚函数实现多态行为,避免使用
dynamic_cast - 缓存转换结果:如果需要多次使用转换结果,保存指针而不是重复转换
- 避免在热路径使用:在高频调用的代码中,考虑替代方案
- 调试时验证,发布时优化 :在调试版本中使用
dynamic_cast进行安全检查,在确认逻辑正确后,发布版本可改用static_cast(配合断言)
cpp
// 优化模式:缓存转换结果
class Handler {
Dog* cachedDog = nullptr;
bool isDog = false;
public:
void process(Animal* animal) {
if (!isDog) {
cachedDog = dynamic_cast<Dog*>(animal);
isDog = (cachedDog != nullptr);
}
if (isDog) {
// 使用缓存的cachedDog
}
}
};6.3.6 注意事项与常见陷阱
| 注意事项 | 说明 | 示例 |
|---|---|---|
| 必须有虚函数 | dynamic_cast仅对多态类型有效 |
类必须至少有一个虚函数(包括虚析构函数) |
| 指针转换失败返回nullptr | 适用于指针类型向下转型 | if (Dog* d = dynamic_cast<Dog*>(p)) |
| 引用转换失败抛出异常 | 适用于引用类型向下转型 | 必须用try-catch处理bad_cast |
| 不适用于非多态类 | 编译器无法进行运行时类型检查 | 编译错误 |
| 性能开销 | 需要RTTI支持,运行时有一定开销 | 避免在高频循环中使用 |
| 多重继承下的指针调整 | 转换可能改变指针值 | 不能假设指针值不变 |
| 空指针检查 | 对空指针进行dynamic_cast返回nullptr |
不会抛出异常 |
空指针的特殊行为:
cpp
Animal* p = nullptr;
Dog* dog = dynamic_cast<Dog*>(p);
// dog == nullptr,不会抛出异常纯虚函数与RTTI :
即使类只有纯虚函数,只要声明了虚函数(包括纯虚),RTTI信息就会被生成,dynamic_cast可以正常工作。
cpp
class Abstract {
public:
virtual ~Abstract() = 0; // 纯虚析构函数,仍然生成RTTI
virtual void f() = 0;
};
Abstract::~Abstract() { } // 必须提供实现
class Concrete : public Abstract {
public:
void f() override { }
};
Concrete c;
Abstract* a = &c;
Concrete* c2 = dynamic_cast<Concrete*>(a); // 正确6.3.7 与static_cast的对比
| 特性 | dynamic_cast | static_cast |
|---|---|---|
| 类型检查 | 运行时检查 | 编译时检查 |
| 失败处理 | 指针→nullptr,引用→异常 | 未定义行为 |
| 适用范围 | 仅多态类型 | 任何类型 |
| 性能 | 有运行时开销 | 无运行时开销 |
| 交叉转换 | 支持 | 不支持 |
| 安全性 | 高 | 中等(需程序员保证正确性) |
什么时候用static_cast代替dynamic_cast?
- 当程序员100%确定转换一定成功时(例如已经通过其他方式验证了类型)
- 在性能敏感的热路径代码中,且已通过断言验证
- 向上转换(从派生类到基类)时,直接用隐式转换即可
cpp
// 性能关键路径:已经通过其他方式确认类型
void fastPath(Animal* animal) {
assert(dynamic_cast<Dog*>(animal) != nullptr); // 调试时验证
Dog* dog = static_cast<Dog*>(animal); // 发布版本使用static_cast
dog->bark();
}6.3.8 编译器实现差异与跨 DLL 的 dynamic_cast 问题()
不同编译器对 dynamic_cast 的底层实现存在差异,这直接影响跨 DLL(动态链接库)传递多态对象的兼容性。理解这些差异有助于避免跨模块 RTTI 失效的陷阱。
各主流编译器的 RTTI 实现
| 编译器 | ABI 规范 | RTTI 存储位置 | 类型比较方式 |
|---|---|---|---|
| GCC / Clang | Itanium C++ ABI | 虚函数表头部(偏移 -1 或 -2 槽位) | 直接比较 type_info 对象地址 |
| MSVC | Microsoft C++ ABI | 虚函数表尾部(通过 __RTTICompleteObjectLocator 间接访问) |
比较 type_info 字符串或地址 |
GCC/Clang 的 Itanium ABI 实现
- 虚函数表(vtable)布局如下(以 64 位为例):
plain
偏移 -8 → offset_to_top (从当前子对象到完整对象起始的偏移)
偏移 -4 → typeinfo pointer (指向 std::type_info 对象)
偏移 0 → first virtual function(第一个虚函数地址)typeid返回的type_info对象是全局唯一的,不同编译单元中同一个类的type_info对象会被合并(通过 COMDAT 折叠)。dynamic_cast通过比较type_info指针地址来确定类型是否匹配。
MSVC 的实现
- 虚函数表不直接存储
type_info指针,而是存储一个指向CompleteObjectLocator的结构,其中包含:signature(4 字节)offset(从 vptr 到完整对象起始的偏移)cdOffset(构造偏移)pTypeDescriptor(指向type_info对象的指针)
- 类型比较通过比较
type_info对象中的name()字符串或地址来完成(取决于具体实现)。
跨 DLL 的 dynamic_cast 失败原因
当在多态对象跨越 DLL 边界传递时,dynamic_cast 可能返回 nullptr 或抛出异常,根本原因在于 RTTI 信息不共享:
- 独立 RTTI 副本
每个 DLL 在编译时都会为类生成自己的虚函数表和type_info对象。即使代码相同,不同 DLL 中的同一类会有不同的虚表地址和type_info地址。 - 类型比较基于地址
在 GCC/Clang 下,dynamic_cast直接比较type_info指针地址。如果对象在 DLL A 中创建,但其type_info来自 DLL B,地址不相等,类型检查失败。
在 MSVC 中,虽然可能比较字符串,但如果不同 DLL 中的type_info对象独立,比较也可能失败(取决于是否启用/GR和链接方式)。 - 虚表指针不一致
对象在 DLL A 中构造,其 vptr 指向 DLL A 的虚表。当通过 DLL B 中的基类指针访问时,dynamic_cast仍会使用对象内建的 vptr(来自 DLL A),然后去查 DLL B 的 RTTI 信息,导致不匹配。
跨 DLL 安全使用 dynamic_cast 的解决方案
方案一:统一编译环境与链接方式
- 所有参与跨模块多态的代码使用相同的编译器、相同的编译选项 (特别是 RTTI 开关,如
/GR或-frtti)。 - 使用静态链接(将相关代码编译进同一个可执行文件),避免跨 DLL 传递多态对象。
- 如果必须使用 DLL,确保所有 DLL 链接同一个 C++ 运行库 (CRT),并启用跨模块的 RTTI 共享 。在 Windows 上,可以使用
/MD(动态链接 CRT)并确保所有模块使用相同的 CRT 版本。
方案二:使用接口类与工厂模式
将多态对象封装在 DLL 内部,通过纯虚接口(接口类)暴露,并使用工厂函数创建对象。这样,对象的完整类型只在 DLL 内部已知,外部只通过接口指针操作,避免在外部使用 dynamic_cast。
cpp
// 接口类(头文件,在多个模块间共享)
class IAnimal {
public:
virtual ~IAnimal() = default;
virtual void sound() = 0;
// 不暴露任何实现细节
};
// DLL 内部实现
class Dog : public IAnimal {
public:
void sound() override { std::cout << "Woof\n"; }
};
// 工厂函数(在 DLL 中导出)
extern "C" __declspec(dllexport) IAnimal* CreateDog() {
return new Dog();
}
// 外部使用
IAnimal* p = CreateDog();
p->sound(); // 无需 dynamic_cast
delete p;优点 :完全避免跨模块 RTTI 依赖。
缺点:无法访问派生类特有的成员(除非通过接口方法暴露),且需要显式管理对象生命周期。
方案三:COM 风格的 QueryInterface 机制
模仿 COM 的 QueryInterface 方式,为每个类定义一个唯一的标识符(如 GUID),并在基类中提供类型查询方法。这种方式不依赖编译器 RTTI,完全由程序员控制。
cpp
// 基类
class IAnimal {
public:
virtual ~IAnimal() = default;
virtual bool IsKindOf(const std::string& type) const = 0;
virtual void* As(const std::string& type) = 0;
};
// 具体实现
class Dog : public IAnimal {
public:
bool IsKindOf(const std::string& type) const override {
return type == "Dog" || type == "IAnimal";
}
void* As(const std::string& type) override {
if (type == "Dog") return static_cast<Dog*>(this);
if (type == "IAnimal") return static_cast<IAnimal*>(this);
return nullptr;
}
void Bark() { /* ... */ }
};
// 使用
IAnimal* p = CreateDog();
Dog* dog = static_cast<Dog*>(p->As("Dog"));
if (dog) dog->Bark();优点 :完全跨平台、跨编译器,不依赖 RTTI。
缺点 :需要手动实现类型转换逻辑,增加了代码量,且 void* 转换需要程序员保证正确性。
方案四:避免在跨模块场景使用 dynamic_cast
重新设计代码,用虚函数替代需要类型判断的场景。例如,将特定行为抽象为虚函数,让派生类自己实现,而不是在外部判断类型后调用特有方法。
cpp
// 基类
class Animal {
public:
virtual void performAction() = 0;
};
// 派生类实现具体行为
class Dog : public Animal {
public:
void performAction() override { bark(); }
private:
void bark() { /* ... */ }
};
class Cat : public Animal {
public:
void performAction() override { meow(); }
private:
void meow() { /* ... */ }
};
// 外部调用
Animal* p = CreateAnimal();
p->performAction(); // 无需 dynamic_cast编译器特定选项与技巧
- GCC/Clang :使用
-fvisibility=hidden隐藏非导出符号时,需确保 RTTI 信息被正确导出。可以通过__attribute__((visibility("default")))标记接口类。 - MSVC :使用
__declspec(dllexport)导出类时,会自动导出虚函数表和 RTTI 信息。但如果基类和派生类在不同的 DLL 中,需要确保基类的 RTTI 信息被导出(通常基类也需导出)。
总结
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 统一编译环境 | 能控制所有模块的构建 | 简单直接 | 难以在第三方库中保证 |
| 接口类 + 工厂 | 需要隐藏实现细节 | 彻底隔离 RTTI 依赖 | 无法访问派生类特有接口 |
| COM 风格 QueryInterface | 需要运行时类型查询 | 可移植、可扩展 | 代码量增加 |
| 避免 dynamic_cast | 能用多态替代时 | 性能最佳 | 设计限制 |
在跨 DLL 开发中,最稳妥的方式是避免跨模块传递需要 RTTI 的多态对象 ,而是采用接口隔离和工厂模式。如果必须使用 dynamic_cast,则应确保所有模块使用完全一致的编译环境,并仔细验证 RTTI 信息是否被正确共享。
6.3.9 工程实践建议
何时使用dynamic_cast:
- 处理异构容器中的对象,需要调用派生类特有方法
- 实现插件架构或框架中的类型安全转换
- 调试和日志记录中需要确认对象类型
何时避免使用dynamic_cast:
- 高频调用的热路径代码
- 可以重新设计为虚函数解决的场景
- 嵌入式系统或实时系统对性能有严格要求
- 需要禁用RTTI的编译环境
最佳实践总结:
- 始终检查
dynamic_cast指针转换的结果是否为空 - 使用引用转换时始终使用try-catch处理
bad_cast异常 - 优先使用虚函数设计,减少对类型判断的依赖
- 在需要频繁使用的地方缓存转换结果
- 多重继承场景优先使用
dynamic_cast而非C风格转换 - 考虑使用设计模式(如Visitor)替代复杂的类型判断逻辑
通过深入理解dynamic_cast的原理、性能特性和使用场景,可以在保证类型安全的同时,写出高效、可维护的C++代码。
6.4 RTTI的代价与替代方案
6.4.1 性能开销分析
RTTI虽然强大,但有一定代价:
内存开销:
- 每个多态类需要在虚表中存储一个指向
type_info结构的指针 - 可执行文件大小略有增加(存储类型信息结构)
时间开销:
typeid:相当于一次虚函数调用,开销很小dynamic_cast:需要遍历继承层次结构,相对较慢
知名C++专家指出,
dynamic_cast的运行时成本取决于所涉及的两个类在类层次结构中的相对位置,向下转换和交叉转换可能非常慢。
6.4.2 替代方案(了解)
在性能敏感的场景(如游戏引擎、高频交易系统、嵌入式实时系统)中,RTTI 的运行时开销可能成为瓶颈,或者由于某些编译环境(如使用 -fno-rtti)导致 RTTI 被禁用。此时,开发者需要寻找替代方案来在编译期或运行时以更低成本获取类型信息或实现多态行为。以下介绍五种主流替代方案,并补充其细节、实现技巧及适用场景。
虚函数:用多态替代类型判断
虚函数是 C++ 实现运行时多态的核心机制,本身就提供了"根据实际类型执行不同行为"的能力。许多需要 typeid 或 dynamic_cast 的场景都可以通过重新设计接口,将类型判断逻辑转换为虚函数调用来消除 RTTI 依赖。
原理:
基类声明一个或多个虚函数,派生类重写这些函数,将原本在外部通过 typeid 或 dynamic_cast 判断后执行的特有行为封装到虚函数中。外部代码仅需通过基类指针或引用调用虚函数,无需关心具体类型。
示例:
cpp
// 不推荐:使用 typeid 判断类型
void handleAnimal(Animal* a) {
if (typeid(*a) == typeid(Dog)) {
static_cast<Dog*>(a)->wagTail();
} else if (typeid(*a) == typeid(Cat)) {
static_cast<Cat*>(a)->scratch();
}
}
// 推荐:使用虚函数
class Animal {
public:
virtual void performAction() = 0;
};
class Dog : public Animal {
public:
void performAction() override { wagTail(); }
};
class Cat : public Animal {
public:
void performAction() override { scratch(); }
};
void handleAnimal(Animal* a) {
a->performAction(); // 运行时多态
}优点
- 零 RTTI 开销 :虚函数调用仅涉及一次间接跳转(通过 vptr),比
dynamic_cast快得多。 - 类型安全:编译器保证函数签名匹配,不会出现转换失败。
- 易于扩展:新增类型只需实现虚函数,外部代码无需修改。
缺点
- 无法访问派生类独有成员:如果行为仅需要调用派生类特有成员,而该成员不应当成为公共接口的一部分,则虚函数可能不合适(但这往往暗示设计问题)。
- 虚函数调用开销:相比普通函数调用,多了一次内存访问和间接跳转,但对大多数场景影响很小。
- 无法处理"多类型联合"逻辑:某些算法需要根据两个对象类型组合选择不同行为(双重分派),虚函数本身无法直接解决。
适用场景
- 外部代码只需要"触发某种行为",而不关心具体类型。
- 行为完全可以通过基类虚函数接口描述。
类型枚举
在基类中添加一个类型枚举(enum)或整数 ID,派生类在构造函数或通过虚函数返回自己的类型标识。外部代码通过该标识进行类型判断,然后使用 static_cast 进行转换。这种方法在游戏引擎中非常常见,因为它避免了 RTTI 开销,且可以手动控制类型的序列化和网络传输。
原理:
每个派生类返回一个唯一的枚举值,外部代码检查该值后,用 static_cast 安全地转换(因为已通过枚举值确认了类型)。
示例:
cpp
class Animal {
public:
enum Type { DOG, CAT, UNKNOWN };
virtual Type getType() const = 0;
virtual ~Animal() = default;
};
class Dog : public Animal {
public:
Type getType() const override { return DOG; }
void wagTail() { /* ... */ }
};
class Cat : public Animal {
public:
Type getType() const override { return CAT; }
void scratch() { /* ... */ }
};
void handleAnimal(Animal* a) {
switch (a->getType()) {
case Animal::DOG:
static_cast<Dog*>(a)->wagTail();
break;
case Animal::CAT:
static_cast<Cat*>(a)->scratch();
break;
default:
// 未知类型
break;
}
}优点
- 极低开销 :
getType()通常是一个返回常量值的虚函数(或非虚),开销极小(甚至可内联)。 - 可跨模块:类型标识是整数,不依赖 RTTI 地址比较,因此跨 DLL 也能正常工作。
- 便于序列化:可以将类型 ID 保存到文件中,用于对象持久化或网络传输。
缺点
- 手动维护枚举:每增加一种新类型,需要扩展枚举并确保值唯一,容易出错。
- 类型安全弱化 :
static_cast没有运行时检查,如果枚举值与对象实际类型不匹配,将导致未定义行为。 - 无法处理多重继承:枚举只能表示一种类型,不能表达"既是 Dog 又是 Pet"这样的关系。
改进技巧
- 使用
uint64_t类型 ID 和哈希字符串(如constexpr哈希)自动生成唯一值,避免手动维护枚举。 - 将类型 ID 存储为静态成员变量,通过虚函数返回其地址或引用,避免虚函数调用开销(见下面"类型标识"技巧)。
cpp
class Animal {
public:
virtual const uint64_t& getTypeId() const = 0;
};
template<typename T>
class AnimalBase : public Animal {
public:
static const uint64_t TypeId; // 在 .cpp 中初始化
const uint64_t& getTypeId() const override { return TypeId; }
};适用场景
- 需要频繁进行类型判断和转换的性能关键代码。
- 需要跨模块或跨网络传递类型信息的场景。
访客模式(Visitor Pattern)
访客模式是一种经典的设计模式,用于在不修改类层次结构的前提下定义新的操作。它通过双重分派(double dispatch)解决"需要根据两个对象的类型执行不同行为"的问题,可以完全避免 RTTI。
原理:
- 定义一个抽象的访客类,其中包含针对每个具体派生类的重载函数(如
visit(Dog&)、visit(Cat&))。 - 每个具体类实现一个
accept(Visitor&)方法,该方法调用访客对象对应的重载,并将this传递过去。这样,在运行时,accept根据对象的实际类型选择正确的visit重载。
示例:
cpp
// 前向声明
class Dog;
class Cat;
// 访客基类
class AnimalVisitor {
public:
virtual void visit(Dog&) = 0;
virtual void visit(Cat&) = 0;
virtual ~AnimalVisitor() = default;
};
// 被访问的类层次
class Animal {
public:
virtual void accept(AnimalVisitor& v) = 0;
virtual ~Animal() = default;
};
class Dog : public Animal {
public:
void accept(AnimalVisitor& v) override { v.visit(*this); }
void wagTail() { /* ... */ }
};
class Cat : public Animal {
public:
void accept(AnimalVisitor& v) override { v.visit(*this); }
void scratch() { /* ... */ }
};
// 具体访客:实现某种操作
class ActionVisitor : public AnimalVisitor {
public:
void visit(Dog& dog) override {
dog.wagTail();
}
void visit(Cat& cat) override {
cat.scratch();
}
};
void handleAnimal(Animal& a) {
ActionVisitor visitor;
a.accept(visitor);
}优点
- 完全消除 RTTI:所有类型识别通过函数重载在编译期完成,运行时仅涉及虚函数调用。
- 支持"双重分派":可以轻松实现根据两个对象类型执行不同操作(如碰撞检测),这是单纯虚函数难以实现的。
- 易于添加新操作:只需增加新的访客类,无需修改被访问的类层次(前提是类层次稳定)。
缺点
- 类层次变化时成本高 :当增加新的派生类时,必须修改所有访客类,添加对应的
visit重载(违反开闭原则)。不过可以通过使用std::variant或 CRTP 来缓解。 - 代码冗余 :每个派生类都需要实现
accept方法。 - 侵入性 :被访问的类必须实现
accept,且访客必须知道所有派生类类型。
变体:Acyclic Visitor
为了解决类层次变化导致的修改问题,可以采用 Acyclic Visitor 模式,通过动态 dynamic_cast 或类型 ID 来在访客中判断是否支持该类型,但这里又回到了 RTTI 依赖。在禁用 RTTI 的环境下,可以使用类型枚举配合 static_cast 实现类似功能。
适用场景
- 需要对对象执行多种不同操作,且操作种类可能增加。
- 需要双重分派(如物理引擎中的碰撞检测、编译器中的 AST 遍历)。
类型擦除( std::any** 与 std::variant)**
C++17 引入了 std::any 和 std::variant,它们提供了两种不同的类型擦除方式,可用于在不需要继承的情况下实现多态行为。
std::variant:带类型的联合体
std::variant 是一个类型安全的联合体,可以存储一组预定义类型中的一个值。它不需要虚函数,类型信息在编译期已知,通过 std::visit 结合泛型 lambda 实现类似多态的分发。
cpp
#include <variant>
#include <iostream>
class Dog {
public:
void bark() const { std::cout << "Woof\n"; }
};
class Cat {
public:
void meow() const { std::cout << "Meow\n"; }
};
using Animal = std::variant<Dog, Cat>;
void handleAnimal(const Animal& a) {
std::visit([](const auto& animal) {
// 使用 if constexpr 或重载进行类型判断
if constexpr (std::is_same_v<decltype(animal), const Dog&>) {
animal.bark();
} else if constexpr (std::is_same_v<decltype(animal), const Cat&>) {
animal.meow();
}
}, a);
}优点:
- 零运行时开销:
std::visit通常被编译器优化为跳转表或 switch,效率接近手动类型枚举。 - 类型安全:编译器确保 variant 只能存储声明的类型。
- 无需继承和虚函数。
缺点:
- 类型集合必须固定(编译期已知),无法在运行时扩展。
- 所有类型的操作必须通过
std::visit分发,可能导致代码模板膨胀。
std::any:擦除类型的容器
std::any 可以存储任意类型的值,但类型信息被擦除,需要通过 any_cast 进行类型恢复,这可能涉及 RTTI 或类型比较(依赖于实现)。
cpp
#include <any>
#include <iostream>
class Dog {
public:
void bark() const { std::cout << "Woof\n"; }
};
class Cat {
public:
void meow() const { std::cout << "Meow\n"; }
};
void handleAny(const std::any& a) {
if (auto dog = std::any_cast<Dog>(&a)) {
dog->bark();
} else if (auto cat = std::any_cast<Cat>(&a)) {
cat->meow();
}
}优点:
- 可以存储任意类型,类型集合不固定。
- 灵活性高。
缺点:
any_cast内部可能使用 RTTI(取决于实现),性能不如std::variant。- 类型转换失败会抛出异常(指针版本返回 nullptr)。
适用场景
std::variant:类型集合固定且有限,追求高性能的场景。std::any:需要存储未知类型(如配置系统、脚本绑定),且性能要求不极端时。
CRTP(奇异递归模板模式)
CRTP 是一种静态多态技术,通过模板将派生类类型作为参数传递给基类,从而实现编译期的虚函数替代。它完全没有运行时开销,所有多态行为在编译期确定。
原理
基类是一个模板类,接受派生类类型作为模板参数。基类通过 static_cast<Derived*>(this) 调用派生类的方法,实现静态分派。
cpp
template<typename Derived>
class Animal {
public:
void performAction() {
static_cast<Derived*>(this)->actionImpl();
}
};
class Dog : public Animal<Dog> {
public:
void actionImpl() { bark(); }
void bark() { std::cout << "Woof\n"; }
};
class Cat : public Animal<Cat> {
public:
void actionImpl() { meow(); }
void meow() { std::cout << "Meow\n"; }
};
// 使用
Dog d;
d.performAction(); // 调用 Dog::bark注意:CRTP 无法直接用于异构容器(因为基类类型不同),但可以通过类型擦除或公共基类结合使用。
优点
- 零开销:所有调用在编译期解析,可以内联,性能优于虚函数。
- 类型安全:编译器检查,不会出现运行时转换错误。
- 可实现接口重用:基类可以包含公共代码,减少重复。
缺点
- 不能用于运行时多态 :无法将
Dog和Cat放入同一容器并通过基类指针调用。 - 模板导致代码膨胀:每个派生类实例化一份基类代码。
- 调试困难:模板错误信息冗长。
扩展:CRTP 与类型擦除结合
可以通过在 CRTP 基类上再加一层抽象基类(包含虚函数)来实现多态容器,但这样会引入虚函数开销,不过可以保留 CRTP 的代码复用优势。
适用场景
- 需要编译期多态(如编译时策略选择)。
- 代码重用场景,避免重复实现相同逻辑。
- 性能极度敏感且类型在编译期已知。
其他替代方案
除了上述五种,还有一些技巧常用于替代 RTTI:
- 静态多态(函数重载、模板):当类型在编译期已知时,完全可以通过模板参数推导实现,无需任何运行时机制。
- 函数对象表(VTable 手动实现):模仿虚函数表但自行管理,可用于嵌入式系统或特殊 ABI 约束场景。
- 函数指针表:在结构体中存储函数指针,不同"类型"使用不同的函数指针表,手动实现多态。
- 枚举 + 函数指针数组:类似 C 风格的多态,性能极高,但安全性低。
对比总结与选择指南
| 替代方案 | 开销 | 可扩展性 | 适用场景 | 是否需要 RTTI |
|---|---|---|---|---|
| 虚函数 | 低(间接跳转) | 高(新增派生类) | 大多数多态需求 | 否(但需虚表) |
| 类型枚举 | 极低 | 中(需修改枚举) | 性能关键,类型固定 | 否 |
| 访客模式 | 低(双重虚调用) | 中(添加新操作容易,添加新类型难) | 多重分派 | 否(纯虚函数) |
std::variant |
极低(跳转表) | 低(类型集合固定) | 类型固定、数量少 | 否 |
std::any |
中(可能含 RTTI) | 高 | 任意类型存储 | 依赖实现 |
| CRTP | 零 | 低(编译期) | 编译期多态,代码复用 | 否 |
选择建议:
- 如果目标是运行时多态 且类型层次会扩展,优先使用虚函数。
- 如果性能极为关键且类型集合固定,使用类型枚举 或
std::variant。 - 如果需要双重分派 (如碰撞检测),考虑访客模式。
- 如果类型完全在编译期确定且需要代码复用,使用 CRTP。
- 如果需要存储任意类型,且性能要求不极端,使用
std::any。
在实际项目中,往往组合使用多种技术:例如,游戏引擎中可能同时使用虚函数处理高层逻辑,而在底层物理系统中使用类型枚举和 CRTP 实现高效碰撞检测。
通过合理选择替代方案,可以在保持代码清晰和可维护性的同时,获得接近手写 C 代码的性能。
小节
经过前六章的深入探讨,我们已经系统学习了 C++ 中继承与多态的语法、原理及底层实现。从继承的基石作用,到虚函数表的精密布局,再到 RTTI 的运行时支撑,我们见证了 C++ 如何在保持高性能的同时,提供强大的面向对象抽象能力。然而,掌握语法只是第一步,真正写出健壮、可维护的代码,还需要深刻理解其背后的设计哲学,并遵循一系列工程实践原则。本章将对这些关键原则进行总结,帮助读者在实际项目中游刃有余地运用继承与多态。
- "is-a"与"has-a"的正确抉择
继承的本质是"is-a"(是一种)关系。当且仅当派生类可以完全替代基类(Liskov 替换原则)时,才应使用公有继承。常见的错误是将"has-a"(有一个)关系误用为继承,例如让 Car 继承 Engine,而正确的设计应是 Car 包含一个 Engine 成员。组合(composition)往往比继承更灵活、耦合度更低,应作为优先选择。
- 继承的使用场景:需要表现多态行为、重用接口、实现抽象基类时。
- 组合的使用场景:复用实现、动态组合行为、避免类层次臃肿时。
现代 C++ 提倡"优先使用组合而非继承",但在确实需要表现类型层次时,继承仍是不可或缺的工具。
- 公有继承的语义约束
公有继承建立的是"子类型"关系,派生类必须满足基类的所有契约。这意味着:
- 派生类不应削弱基类的接口(如将 public 成员重定义为 private)。
- 派生类不应改变基类成员函数的预期行为(即应遵循里氏替换原则)。
- 如果基类有虚函数,派生类重写时应保持相同的语义,不能随意改变功能。
任何违背这些原则的设计都会导致多态失效或代码难以理解。
- 访问控制与封装:protected 的双刃剑
protected 是专为继承体系设计的访问级别,它允许派生类访问基类的内部细节,同时对外部隐藏。但过度使用 protected 会使基类与派生类紧密耦合,破坏封装。经验法则:
- 尽量将数据成员设为
private,通过protected或public的成员函数来操作。 - 仅为派生类提供必要的
protected接口,而不是直接暴露数据。 - 对于纯虚函数,通常声明为
protected,因为它们是供派生类实现的内部钩子。
- 虚析构函数:多态删除的保障
黄金法则 :只要一个类可能被继承,就应该将其析构函数声明为 virtual。这是避免资源泄漏的根本保障。当通过基类指针删除派生类对象时,只有虚析构函数才能保证派生类的析构函数被正确调用。
- 对于非多态基类(即不包含虚函数),若不确定是否会被继承,也应将析构函数声明为虚函数(虽然多了一个 vptr 开销,但安全)。
- 接口类(纯虚类)必须提供虚析构函数,以便通过接口指针安全删除对象。
- 构造与析构中的虚函数陷阱
在构造函数和析构函数中调用虚函数时,动态绑定不会发生。因为此时对象的 vptr 指向当前正在构造或析构的类的虚表,而不是最终派生类。这是 C++ 对象模型的安全设计,避免访问未初始化的派生类成员。
- 最佳实践:避免在构造/析构函数中调用虚函数。如果需要类似行为,考虑使用工厂方法或二阶段初始化,将虚函数调用放在对象完全构造之后。
- 析构函数中调用虚函数同样如此,应予以避免。
- 名字隐藏与 using 声明
派生类中的同名成员(无论是否为虚函数)会隐藏基类的所有同名成员。这常常导致意外,尤其是当基类有多个重载版本时。解决办法:
- 在派生类中使用
using Base::func;将基类的同名函数引入派生类作用域,从而与派生类的新重载构成重载集合。 - 重写虚函数时,务必使用
override关键字,让编译器检查签名是否匹配,避免意外隐藏。
- 多态设计:虚函数优先于 RTTI
RTTI(dynamic_cast 和 typeid)虽然提供了运行时类型信息,但应作为最后手段。优先使用虚函数来表现多态行为,因为虚函数调用更高效、更安全,且更符合面向对象的设计理念。仅当虚函数无法满足(如需要根据类型执行不同操作、需要访问派生类特有成员)时,才考虑 RTTI。
dynamic_cast用于安全向下转换,但应避免在热路径中使用,因其有遍历继承链的开销。typeid主要用于调试和日志,跨模块传递时需注意 RTTI 信息可能不共享。
- 虚函数与性能的权衡
虚函数调用比普通函数多两次内存访问和一次间接跳转,但在现代 CPU 上开销通常可接受。当性能极端敏感时,可考虑:
- 使用
final关键字帮助编译器进行去虚化优化。 - 对于编译期已知的类型,使用模板或 CRTP 实现静态多态。
- 使用类型枚举(如
enum)加static_cast替代dynamic_cast。
但应优先保持代码清晰,仅在确实成为瓶颈时再优化。
- 多重继承的谨慎使用
多重继承强大但复杂,尤其容易引发菱形继承问题。应遵循以下原则:
- 尽量使用单继承,避免不必要的多重继承。
- 若必须多重继承,优先使用"接口类"(纯虚类)的组合,而不是多个实现类。
- 菱形继承必须使用虚继承解决,但要清楚其带来的额外开销(vbptr、构造复杂性)。
- 在多重继承中,注意成员访问的二义性,并显式使用作用域解析符。
- 虚继承的代价与替代
虚继承解决了菱形继承的数据冗余,但引入了额外的间接访问(vbptr)和复杂的构造顺序。除非确实需要,否则避免使用虚继承。在某些场景,可以用组合模式替代虚继承:例如,将共享的基类作为成员对象,各派生类通过转发调用实现。这样既能复用代码,又避免了复杂的继承关系。
- 移动语义与继承
C++11 起,移动语义在继承体系中的传播需要特别注意。当派生类定义了移动操作时,应显式调用基类的移动操作,否则基类部分可能被拷贝或默认构造。此外,若基类禁止移动(如将移动操作定义为 =delete),派生类的移动操作也会被隐式删除。
- 使用
=default和=delete明确控制默认成员函数的生成。 - 在派生类移动构造函数中,调用
Base(std::move(other))来移动基类部分。 - 遵循"零规则"或"五规则",合理管理资源。
- 抽象类与接口的现代实践
抽象类用于定义接口,强制派生类实现特定行为。现代 C++ 中,接口类应满足:
- 所有成员函数为
public virtual(通常为纯虚)。 - 提供虚析构函数。
- 不包含数据成员(保持接口纯粹)。
- 可包含非虚的辅助函数(如 NVI 模式中的模板方法)。
接口设计应遵循"接口隔离原则",小而精的接口比庞大的全能接口更易复用和维护。
总结
继承与多态是 C++ 面向对象编程的核心,但也是最容易被误用的领域。掌握其底层原理(如虚函数表、RTTI)有助于写出正确、高效的代码,而遵循设计原则(如里氏替换、优先组合)则能保证代码的长期可维护性。在实际项目中,应时刻权衡灵活性、性能与复杂度,选择最适合当前场景的抽象方式。通过本章总结的最佳实践,相信读者能够在未来的 C++ 开发中游刃有余,真正领略"复用的艺术,多态的灵魂"。