
论文标题:Apt-Serve: Adaptive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving
作者团队:SHIHONG GAO, XIN ZHANG, YANYAN SHEN, LEI CHEN(中国科学技术大学)
💡 全文核心概述
当前大语言模型(LLM)规模化产业落地持续深化,推理服务吞吐量已成为衡量算力成本、用户体验及业务承载上限的核心指标。高并发场景下,行业普遍面临首令牌延迟陡增、SLO达成率暴跌、批处理规模难以扩容的痛点,根源在于KV缓存显存刚性瓶颈与FCFS僵化调度两大难题。
本篇论文提出的Apt-Serve协同优化方案,依托异构混合缓存架构+运行时自适应调度机制,实现LLM推理有效吞吐量最高提升8.8倍,高并发下SLO达成率从10%-20%大幅攀升至60%-99%,兼顾内存利用率、计算效率与服务稳定性,是LLM推理优化领域的前沿落地思路。
📌 背景剖析:LLM推理的两大核心性能瓶颈
现有主流推理引擎(vLLM、Sarathi-Serve、DeepSpeed-FastGen等)均难以实现吞吐量的规模化突破,论文团队经实证分析,将核心瓶颈归结为以下两点:
一、KV缓存:显存资源刚性消耗,批处理规模受限
KV缓存是LLM解码阶段的标准加速手段,通过缓存注意力层键值向量,规避重复计算,将注意力复杂度从O(n²)降至O(n),显著提升单请求推理速度。
但该机制存在不可忽视的短板:KV缓存显存占用与序列长度呈严格线性正相关,有限的GPU高带宽显存被快速挤占,直接锁死批处理规模上限。高并发流量下,新增请求被迫进入排队队列,进而引发首令牌延迟失控、服务响应恶化等连锁问题。
二、FCFS调度:策略刚性滞后,资源利用率偏低
当前主流推理系统普遍采用先到先服务(FCFS)调度逻辑,该策略仅以请求到达时间为唯一依据,完全忽略不同请求的内存需求差异、等待时延敏感度及服务优先级。
这种僵化调度模式极易造成批处理组合失衡、GPU算力空转、缓存碎片化等问题,进一步加剧SLO违规率,始终无法实现显存与算力资源的高效协同利用,吞吐量提升陷入瓶颈。
🚀 核心技术方案:Apt-Serve双引擎优化架构
Apt-Serve并未颠覆现有推理引擎底层架构,而是聚焦缓存管理与调度层开展创新性优化,通过两大核心模块深度协同,实现内存占用、计算开销与系统吞吐量的全局动态平衡。
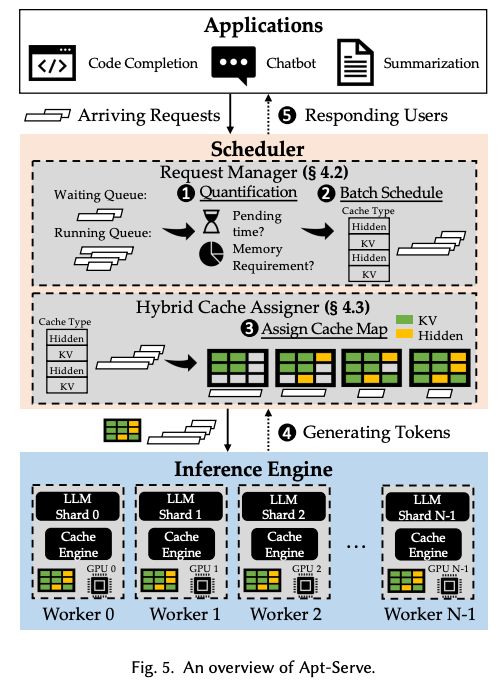
一、混合缓存机制:兼顾计算效率与内存利用率
混合缓存是Apt-Serve的核心创新点,摒弃传统单一KV缓存模式,构建计算高效型+内存高效型异构双缓存体系,支持实时动态切换与按需分配,兼顾推理速度与显存利用率。
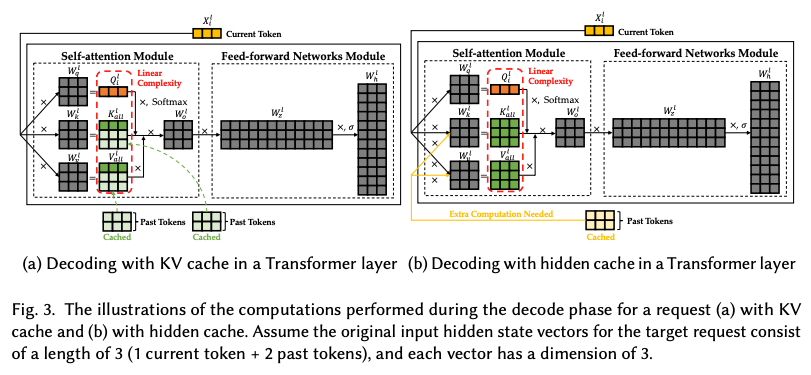
-
标准KV缓存:保留传统缓存低计算开销的优势,推理延迟可控,适用于短序列、低并发的稳定推理场景,但显存占用密度高,扩容空间有限;
-
隐藏状态缓存:创新性轻量化缓存设计,仅存储输入隐藏状态向量,无需同步存储键、值双向量,显存占用直降50%;仅需通过单次线性变换即可恢复KV向量,以极小的计算开销损耗,换取大幅显存收益。
Apt-Serve内置实时GPU显存监控模块,当显存使用率逼近阈值、批处理规模即将触顶时,系统自动将部分在途请求的KV缓存切换为隐藏状态缓存,新增请求直接分配隐藏状态缓存,实现同等显存下更高并发承载能力,既保障核心推理速度,又突破批处理规模上限。
二、自适应调度机制:面向SLO的动态优化调度
针对FCFS调度的固有缺陷,Apt-Serve设计了运行时感知-价值量化-贪心择优的自适应调度器,每轮推理迭代均动态优化批处理组合,最大化资源利用效率与SLO达成率。
核心执行流程:
-
运行时状态全量追踪:实时采集各请求等待时长、最大内存需求、序列长度等指标,精准刻画系统负载与请求特征;
-
多维度调度价值量化:构建综合价值评估模型,统筹等待时间收益、隐藏缓存计算开销、SLO优先级等维度,生成精细化请求调度权重;
-
近似最优批处理筛选:针对批处理优化的NP难问题,设计高效贪心算法,保障2倍近似比,毫秒级完成最优批处理组合筛选,兼顾调度效率与优化效果。
简言之,该调度器可实现优先级化调度:优先处理等待时长较长、内存占用较小、对SLO影响关键的请求,摒弃无序排队模式,实现GPU资源的精准调配。
📊 实验验证:性能指标全面超越主流框架
论文团队搭建标准化实验环境,基于NVIDIA A100 GPU,选取OPT-13B/30B/66B大模型开展基准测试,与vLLM、Sarathi-Serve、DeepSpeed-FastGen三大主流推理引擎横向对比,实验结果具备充分的严谨性与说服力。
核心性能指标:
-
吞吐量量级提升:相较于当前业界最优(SOTA)系统,有效吞吐量最高提升8.8倍;90% SLO达成率约束下,请求处理速率平均提升2.3-7.5倍;
-
SLO保障能力显著增强:高并发压力场景下,传统FCFS调度SLO达成率仅10%-20%,Apt-Serve可稳定实现60%-99%的达成率;
-
流量鲁棒性优异:请求突发场景下,Apt-Serve的SLO达成率最高达基线系统的7.5倍,抗流量波动能力突出;
-
调度开销近乎可忽略:批量调度1600个请求仅耗时10.8ms,远低于单轮推理计算耗时,无额外性能损耗。
多场景通用性验证
研究团队进一步在ShareGPT(对话交互场景)、HumanEval(代码生成场景)、LongBench(长文本推理场景)三大经典数据集,以及LLaMA3、Yi等主流开源模型上开展泛化测试,Apt-Serve均实现稳定性能增益;尤其在长上下文、高突发流量场景中,性能优势更为凸显。
🔍 技术优势解析:Apt-Serve的核心竞争力
- 柔性权衡内存与计算,无极端取舍
区别于单纯压缩KV缓存导致模型精度受损、或盲目扩大批处理引发延迟飙升的单一优化思路,Apt-Serve通过混合缓存实现内存效率与计算开销的柔性平衡,以极小的计算代价换取翻倍显存收益,适配绝大多数工业级落地场景,兼顾性能与稳定性。
- 缓存与调度深度协同,闭环优化
Apt-Serve并非孤立优化缓存或调度模块,而是实现二者深度联动:自适应调度依据实时缓存状态制定决策,缓存分配配合调度优先级动态调整,构建"感知-决策-执行"闭环优化体系,实现1+1>2的协同性能增益。
- 通用性强,工程落地成本低
Apt-Serve可无缝兼容vLLM、Sarathi-Serve等现有主流推理框架,无需重构底层计算架构,接入门槛低、改造量小,具备极高的工程落地与集成价值。
💡 总结与研究展望
KV缓存显存瓶颈长期制约LLM推理的规模化落地,Apt-Serve依托混合缓存架构+自适应调度机制的组合优化方案,提供了一条低成本、高效率的破局路径,8.8倍的吞吐量提升效果足以对现有推理服务架构实现迭代升级。
从工程实践角度来看,该方案兼具理论创新性与落地实用性:调度算法高效轻量化、缓存切换灵活无感知、兼容现有生态,适用于云原生大模型服务、高并发对话系统、长文本推理等各类工业场景。
论文同时指明了后续优化方向:进一步平衡尾延迟与SLO达成率,结合流量预测实现前置调度优化,未来在大模型推理部署、多模型混部等领域具备广阔的应用前景。