链表的七十二变------从LRU缓存到手写浏览器前进后退
写在前面的目录
[二、链表的底层解构------不止是 next 指针](#二、链表的底层解构——不止是 next 指针)
[2.1 单向链表:最简单的链式结构](#2.1 单向链表:最简单的链式结构)
[2.2 双向链表:前后眼的设计哲学](#2.2 双向链表:前后眼的设计哲学)
[2.3 链表反转四步拆解](#2.3 链表反转四步拆解)
[2.4 哨兵节点------让边界消失](#2.4 哨兵节点——让边界消失)
[2.5 跳表------给链表加个索引](#2.5 跳表——给链表加个索引)
[3.1 浏览器前进后退------双向链表实现标签页导航](#3.1 浏览器前进后退——双向链表实现标签页导航)
[3.2 LRU 缓存淘汰------HashMap + 双向链表的 O(1) 魔法](#3.2 LRU 缓存淘汰——HashMap + 双向链表的 O(1) 魔法)
[四、源码避坑指南与 Debug 日记](#四、源码避坑指南与 Debug 日记)
[五、面试连环炮 Mock Interview](#五、面试连环炮 Mock Interview)
一、真实面试真题引入
Q1:"用双向链表 + HashMap 实现一个 LRU 缓存,要求 get 和 put 都是 O(1)。"
Q2:"怎么判断一个单链表有环?快慢指针为什么一定相遇,不会刚好错过?"
Q3:"跳表(Skip List)为什么在 Redis 里替代了红黑树?"
三道题下来,前两道挂了的人占了一半。第三道直接刷掉 80%。
链表这个数据结构,数据结构课都学过,但面试里考的不是"你会不会定义一个 ListNode"。考的是你能不能把链表的指针操作摸透,然后在陌生场景里自己搭积木------LRU 缓存、环形检测、跳表索引,全是链式思维的变种。
前两期我们聊了 ArrayList 的数组底层和扩容机制,这一期我们把目光转向它的"表兄弟"------链表。如果说数组是连续公寓楼,那链表就是一串散落在城市各处的独栋,每个房子只知道隔壁的门牌号。
二、链表的底层解构------不止是 next 指针
2.1 单向链表:最简单的链式结构
java
class ListNode {
int val;
ListNode next;
ListNode(int val) { this.val = val; }
}就这么简单:一个数据域,一个指向下一个节点的指针。遍历从头开始,顺着 next 一个一个往后找。找到尾(next == null)为止。
单向链表的问题也出在这个"只有一个方向"上------你想删当前节点,必须知道它的前驱,但 next 只能往后看。所以标准删除操作要维护一个 prev 指针,从表头一路跟到目标的前一个位置。
java
// 删除值为 target 的节点
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode prev = dummy;
while (prev.next != null) {
if (prev.next.val == target) {
prev.next = prev.next.next; // 绕过目标
break;
}
prev = prev.next;
}
return dummy.next;加了虚拟头节点(dummy)的好处是:如果目标恰好是 head,不需要特殊分支。dummy 把"删除头节点"和"删除中间节点"统一了。
2.2 双向链表:前后眼的设计哲学
给每个节点多加一个 prev 指针,单向变双向:
java
class DListNode {
int val;
DListNode prev;
DListNode next;
DListNode(int val) { this.val = val; }
}双向链表的优势在"删除自己"------给定当前节点,不需要从表头开始找前驱,直接 node.prev.next = node.next 就完成了。这也是 LRU 缓存必须用双向链表的原因:缓存淘汰要频繁删除任意位置的节点,单向链表每次都从头找,O(n);双向链表 O(1)。
Java 的 LinkedList 底层就是双向链表:
java
// LinkedList.java (JDK 17, 简化)
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}LinkedList 的 get(int index) 不是 O(1)------它要根据 index 和 size 的一半比较,决定从头部还是尾部开始遍历。第4期我们实际测过:LinkedList 随机访问比 ArrayList 慢 100 倍以上。根源在于链表节点在堆上离散分布,CPU 缓存行一次能预读的连续内存对链表无效------每次 next 都可能触发一次缓存未命中。
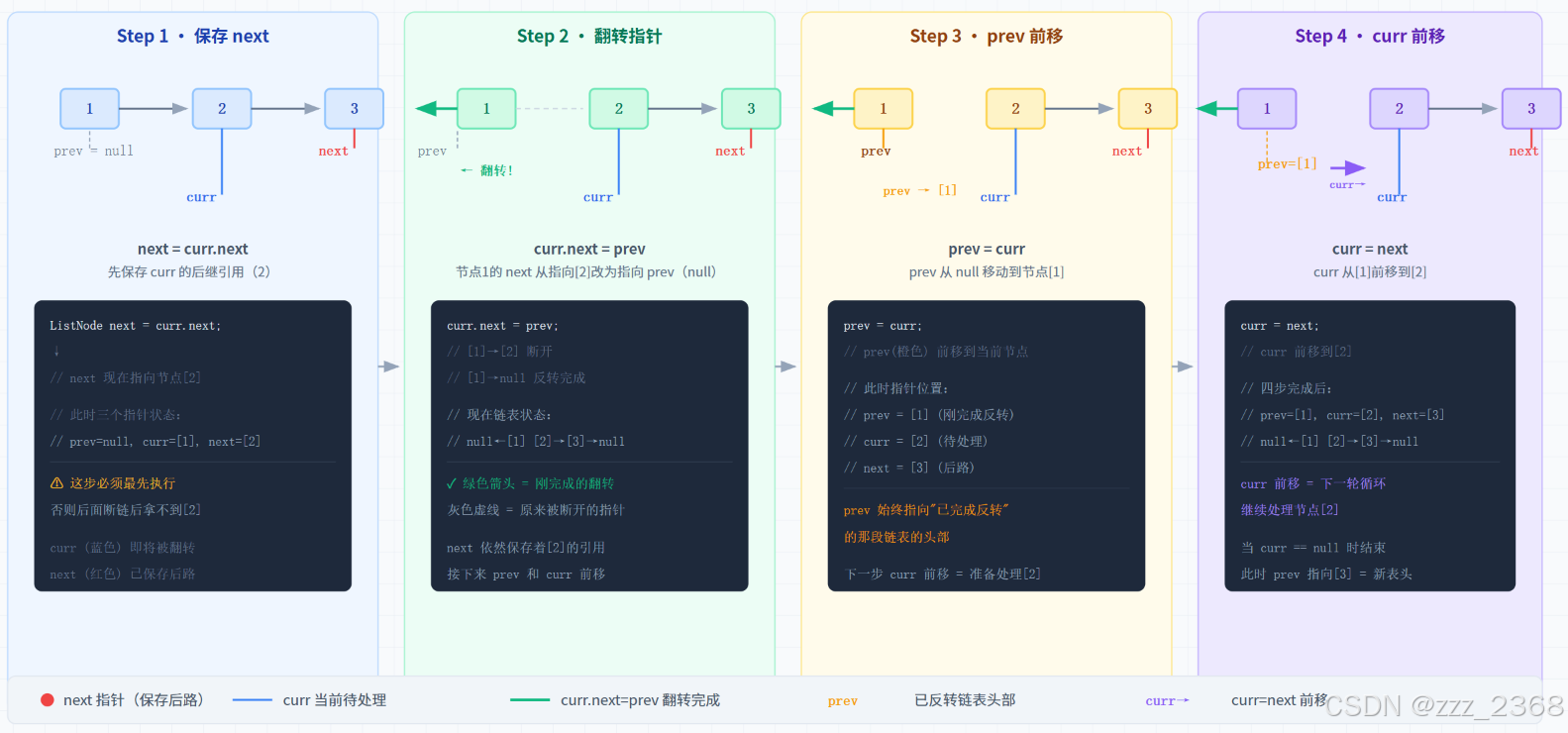
2.3 链表反转四步拆解
反转链表是面试必考题,也是理解指针操作最经典的练习。三个指针 prev、curr、next,每步四件事:
初始: null [1] → [2] → [3] → null
prev curr next
第1步: 保存 next = curr.next (next = 2)
第2步: 翻转 curr.next = prev (1 → null)
第3步: prev 前移 = curr (prev = 1)
第4步: curr 前移 = next (curr = 2)
重复...
java
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next; // 1. 保存后路
curr.next = prev; // 2. 翻转指针
prev = curr; // 3. 前移 prev
curr = next; // 4. 前移 curr
}
return prev; // 新表头
}这四步的顺序不能乱。第 1 步必须最先------你不先把 curr.next 存起来,第 2 步一翻,原来的后路就断了,链就找不回来了。
2.4 哨兵节点------让边界消失
写过链表的人都被空指针折磨过。删除最后一个节点,prev.next 是 null;从空链表删除,head 本身就是 null。边界条件越多,bug 越密集。
哨兵节点(Sentinel Node)的思路:给链表套一个不存数据的"壳",head 永远指向哨兵,哨兵的 next 才是真正数据。所有操作都在哨兵之后进行,不用单独判断 head 是不是 null。
java
class SentinelList {
private ListNode sentinel; // 不存数据,永不删除
public SentinelList() {
sentinel = new ListNode(0); // 哨兵
}
public void add(int val) {
ListNode cur = sentinel;
while (cur.next != null) cur = cur.next; // 找尾部
cur.next = new ListNode(val);
}
public boolean remove(int val) {
ListNode prev = sentinel;
while (prev.next != null) {
if (prev.next.val == val) {
prev.next = prev.next.next;
return true;
}
prev = prev.next;
}
return false;
}
}sentinel 的存在让 remove 和 add 不需要任何 null 检查------多一个节点,省掉所有边界分支。空间换简洁。
2.5 跳表------给链表加个索引
链表的软肋是查找慢:找第 k 个元素要遍历 k 步。数组可以用二分查找,但链表的节点不是连续内存,没法直接跳到中间。
跳表的思路粗暴但有效:给链表建"快速通道"------每隔几个节点抽一个出来做索引,索引上再建索引,直到顶层只剩两个节点。查找时从顶层开始,能跳就跳,不能跳就降一层。查询复杂度 O(log n)。
Level 2: [1] ---------------------------------------------→ [9]
Level 1: [1] ---------------→ [5] ---------------→ [9]
Level 0: [1]→[3]→[5]→[7]→[9]
找 7:Level 2 从 1 看到 9(7<9,下降)
Level 1 从 1→5(7>5)→9(7<9,下降)
Level 0 从 5→7 找到Redis 的有序集合(Sorted Set)底层就是跳表而不是红黑树。原因有三个:跳表实现简单(几百行 C 代码),范围查询天然支持(跳表层与层之间天然有序),并发友好(红黑树 rebalance 要锁整棵树,跳表只锁局部)。
JDK 的 ConcurrentSkipListMap 就是一个线程安全的跳表实现,基于无锁 CAS 方案,先不展开,留个印象。
三、"纯手工、零依赖"原创案例实战
3.1 浏览器前进后退------双向链表实现标签页导航
打开 Chrome,按 Ctrl+Tab 切换标签页,按后退回到上一个页面,按前进又跳回来。这背后就是一个双向链表。
我们自己撸一个"纯手工"版本:
java
class TabNode {
String url;
String title;
TabNode prev;
TabNode next;
TabNode(String url, String title) {
this.url = url;
this.title = title;
}
}
public class BrowserTabHistory {
private TabNode head; // 最早打开的页面
private TabNode current; // 当前正在看的页面
// 打开新标签页(在当前位置后面插入,丢弃后面的历史)
public void openTab(String url, String title) {
TabNode newNode = new TabNode(url, title);
if (current == null) {
head = current = newNode;
} else {
newNode.prev = current;
current.next = newNode;
current = newNode;
}
System.out.println("[打开] " + title + " → " + url);
}
// 后退一个页面
public boolean goBack() {
if (current == null || current.prev == null) {
System.out.println("[后退] 已在最早页面,无法后退");
return false;
}
current = current.prev;
System.out.println("[后退] → " + current.title);
return true;
}
// 前进一个页面
public boolean goForward() {
if (current == null || current.next == null) {
System.out.println("[前进] 已在最新页面,无法前进");
return false;
}
current = current.next;
System.out.println("[前进] → " + current.title);
return true;
}
// 打印导航历史
public void printHistory() {
System.out.println("===== 标签页历史 =====");
TabNode cur = head;
while (cur != null) {
String marker = (cur == current) ? " ◀ 当前" : "";
System.out.printf(" %s (%s)%s%n", cur.title, cur.url, marker);
cur = cur.next;
}
}
public static void main(String[] args) {
BrowserTabHistory browser = new BrowserTabHistory();
browser.openTab("https://google.com", "Google");
browser.openTab("https://github.com", "GitHub");
browser.openTab("https://stackoverflow.com", "Stack Overflow");
browser.printHistory();
browser.goBack(); // → GitHub
browser.goBack(); // → Google
browser.goForward(); // → GitHub
browser.openTab("https://leetcode.com", "LeetCode"); // 新建时丢弃 SO
browser.printHistory();
}
}跑一遍输出:
[打开] Google → https://google.com
[打开] GitHub → https://github.com
[打开] Stack Overflow → https://stackoverflow.com
===== 标签页历史 =====
Google (https://google.com)
GitHub (https://github.com)
Stack Overflow (https://stackoverflow.com) ◀ 当前
[后退] → GitHub
[后退] → Google
[前进] → GitHub
[打开] LeetCode → https://leetcode.com
===== 标签页历史 =====
Google (https://google.com)
GitHub (https://github.com)
LeetCode (https://leetcode.com) ◀ 当前后退到 GitHub 后从 GitHub 打开了 LeetCode,之前的 Stack Overflow 被丢弃------真实的浏览器行为也是这样。
3.2 LRU 缓存淘汰------HashMap + 双向链表的 O(1) 魔法
LRU(Least Recently Used)是面试里链表应用题的天花板,原题出自 LeetCode 146。思路不复杂:一个双向链表维护访问顺序(最近访问的放头部),一个 HashMap 做 O(1) 查找。每次 get 或 put 时把节点移到链表头部,容量满了就删链表尾部。
java
import java.util.HashMap;
public class LRUCache {
static class Node {
int key, value;
Node prev, next;
Node(int k, int v) { key = k; value = v; }
}
private final int capacity;
private final HashMap<Integer, Node> map;
private final Node head; // 哨兵头
private final Node tail; // 哨兵尾
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new HashMap<>();
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
}
public int get(int key) {
Node node = map.get(key);
if (node == null) return -1;
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
Node node = map.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
} else {
Node newNode = new Node(key, value);
map.put(key, newNode);
addToHead(newNode);
if (map.size() > capacity) {
Node removed = removeTail();
map.remove(removed.key);
}
}
}
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
private Node removeTail() {
Node node = tail.prev;
removeNode(node);
return node;
}
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1)); // 1 → 访问后 1 移到头部
cache.put(3, 3); // 容量满,删除尾部(2)
System.out.println(cache.get(2)); // -1(已被淘汰)
cache.put(4, 4); // 容量满,删除尾部(1)
System.out.println(cache.get(1)); // -1
System.out.println(cache.get(3)); // 3
System.out.println(cache.get(4)); // 4
}
}几个细节值得留意:用了头尾两个哨兵节点,所以 addToHead 和 removeNode 都不需要判空;HashMap 存的是 Node 引用,双向链表的指针操作跟 HashMap 完全解耦------HashMap 只管"快速定位"。两个结构分工明确,合在一起实现 O(1) 的 get 和 put。
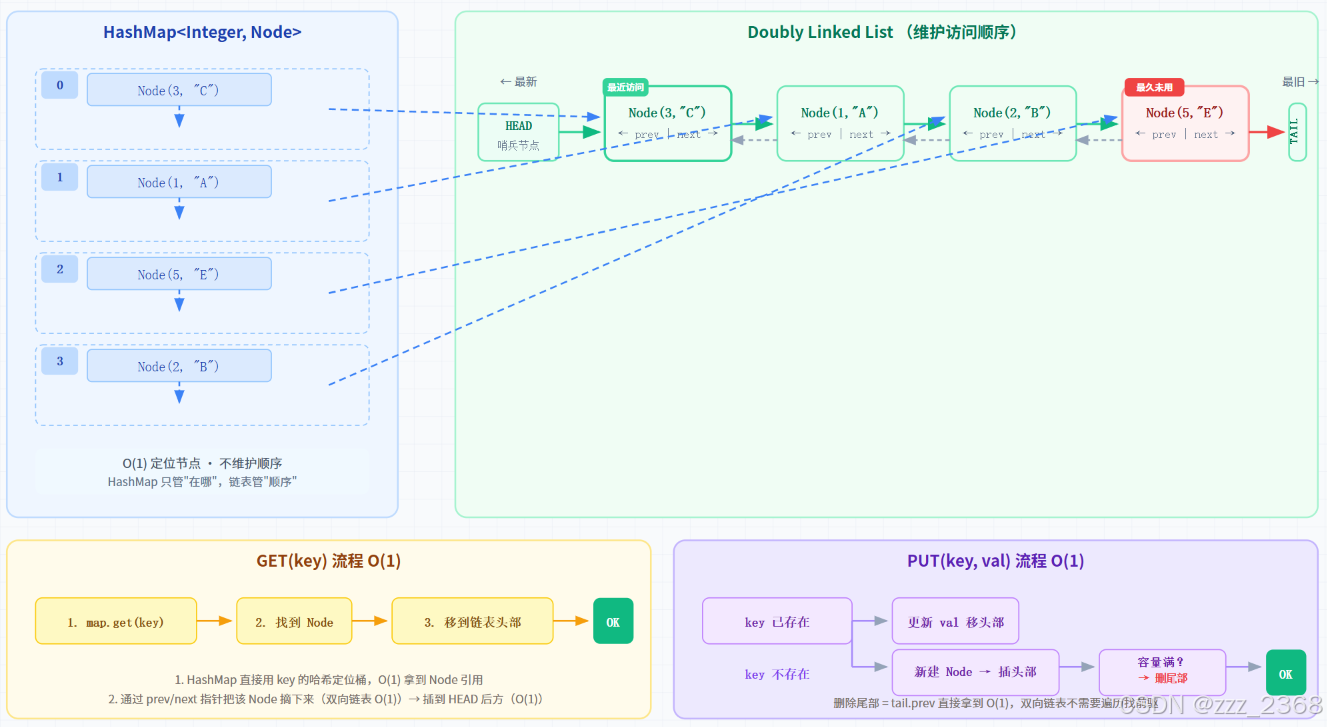
四、源码避坑指南与 Debug 日记
刷链表题掉过的坑,挑几个最典型的:
坑1:链表反转时忘记保存 next
java
while (curr != null) {
curr.next = prev; // 先把后路断了...
prev = curr;
curr = curr.next; // ❌ curr.next 已经指向 prev 了,死循环
}反转链表的四步顺序不能改。先把 next 存下来,再断指针。
坑2:双向链表删除节点后没有断开指针
java
// 错误做法
node.prev.next = node.next;
node.next.prev = node.prev;
// node.prev = null; 没做
// node.next = null; 没做如果程序的其他地方还持有这个 node 的引用,它能通过 prev/next 访问到已经不属于它的链表。悬空指针不清理,先不说并发安全问题,GC 也可能被拖累。养成删完清空的习惯。
坑3:判空只检查了 curr,没检查 curr.next
java
while (curr != null && curr.next != null) {
// 快慢指针逻辑
}快慢指针遍历链表时,快指针一次走两步,必须同时检查 fast != null && fast.next != null。单检查一个,快指针走完第一步后第二步就空指针。
坑4:LinkedList 的 get(i) 当 O(1) 用
第4期数据在那摆着:随机访问 LinkedList 比 ArrayList 慢 100 倍。所有带"链表"字的面试官听到 O(1) 随机访问都会摇头。
五、面试连环炮 Mock Interview
面试官:"手写一个 LRU 缓存,要求 get 和 put 都是 O(1)。"
回答:"底层用 HashMap + 双向链表。HashMap 负责 O(1) 查找,双向链表维护访问顺序。get 时从 HashMap 拿到节点,通过 prev/next 指针把节点摘下来插到链表头部------双向链表的删除和头部插入都是 O(1)。put 时分三种情况:key 已存在则更新 value 并移到头部;key 不存在则新建节点加入头部;容量满了则从链表尾部删除最久未使用的节点,同时在 HashMap 里移除。头尾各用一个哨兵节点简化边界处理。"
面试官:"为什么用双向链表,单向链表不行吗?"
回答 :"删除链表尾部的节点需要找到它的前驱。双向链表通过 tail.prev 直接拿到 O(1);单向链表只能从头遍历 O(n)。LRU 淘汰的是尾部,如果删除尾部变 O(n),整个 put 就不是 O(1) 了。"
面试官:"判断单链表有环,快慢指针为什么一定相遇?快指针步长为 3 行不行?"
回答:"设环外长度为 a,环长度为 b。快指针步长为 2,慢指针步长为 1。进入环后,快指针每次比慢指针多走 1 步,相当于快指针在环内以相对速度 1 追慢指针。最坏情况下快指针落后慢指针 b-1 步,每轮追 1 步,最多 b 轮追上------步长差为 1 保证了不会'跳过去'。步长为 3 的话快慢步长差为 2,有可能刚好跳过永远不相遇。步长差必须和环长度互质,差为 1 跟任何整数都互质,所以步长差为 1 最可靠。"
面试官:"Redis 的有序集合为什么用跳表而不用红黑树?"
回答 :"三个原因。第一,跳表实现简单,几百行 C 代码就能搞定;红黑树的插入删除 rebalance 逻辑绕得多。第二,跳表天然支持范围查询------找到起点后沿着 Level 0 直接往后扫,时间复杂度 O(log n + m);红黑树做范围查询要不断中序遍历找后继。第三,并发场景下跳表只锁局部------插入节点时只影响前后几个节点的指针;红黑树 rebalance 可能一直上溯到根,影响范围大得多。ZSet 的 ZRANGE 命令本质上就是范围查询,跳表是更好的选择。"
六、通俗类比小结
小时候玩贪吃蛇,蛇身就是一串节点------每个节点只知道下一个节点在哪(单向链表)。蛇头一动,整条蛇跟着扭。但如果你想让蛇头知道尾巴在哪(双向链表),就得给每个节点加一个 prev 指针,这样蛇头能直接找到尾巴,不用顺着身体一节节数过去。
跳表像是给贪吃蛇加了"瞬移井":隔几节放一个传送门(索引节点),蛇头要找第 100 节------传送门一跳跳到第 50 节,再看一眼发现 100 在更后面,继续跳。不用一节节爬。
LRU 缓存则是:蛇身长度有限(容量上限),每次吃到新东西蛇头长一节,尾巴掉一节。HashMap 像个雷达,让蛇头不用挨节找就能直接定位任意一节。
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!
