最近爆火的ai出现了一堆新词,Token,LLM,Context,prompt,Tool,Agent Skill,MCP等,大家也许都听说过,但是大家不一定能够准确描述出这些词的准确含义,本篇将用简短精炼的语言,聊聊这些词语的概念究竟是什么,相信看完这篇文章,能让你对ai的理解更进一步。
一、什么是LLM(全称:Large Language Model)
市面上基本所有大模型都是基于Transfer(如下图所示) 这套架构训练出来的,这就是大模型的底层引擎 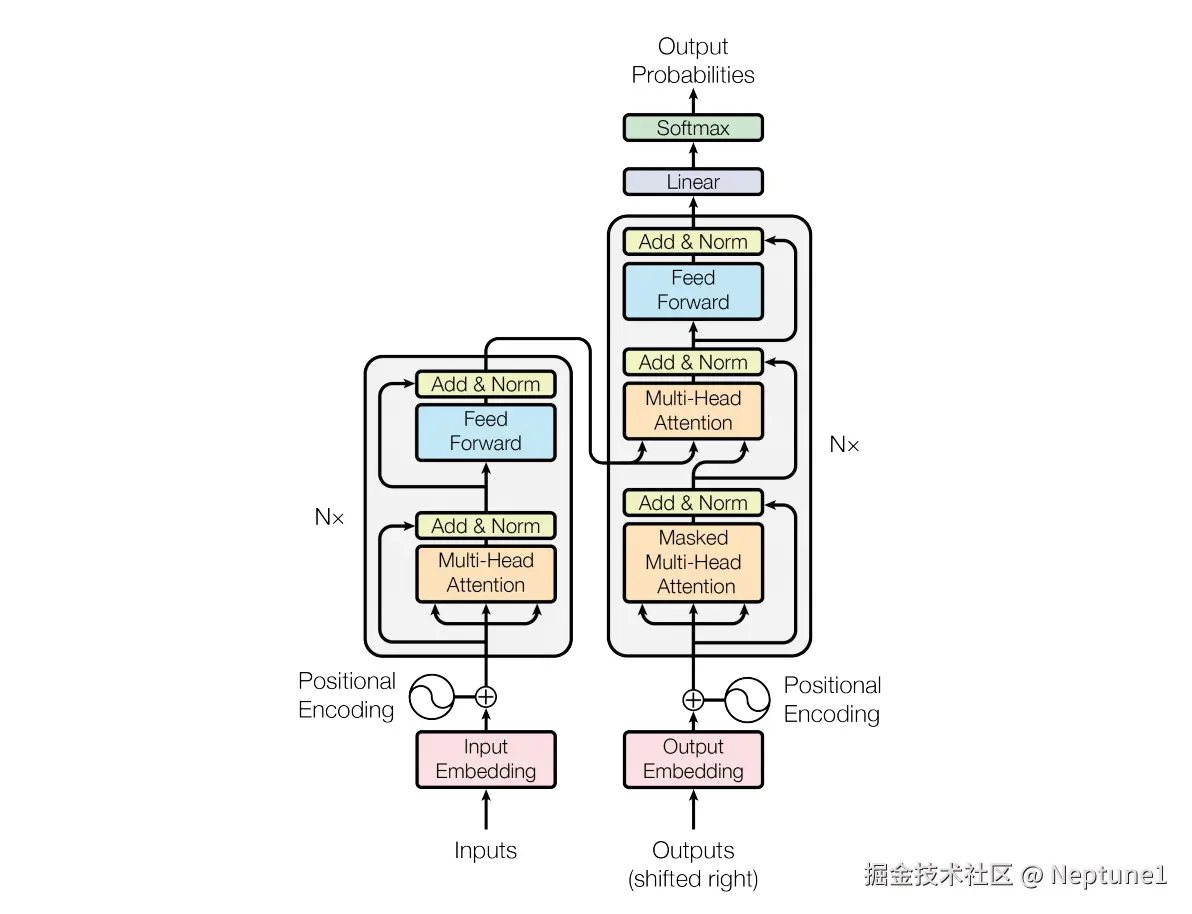
大模型工作原理:
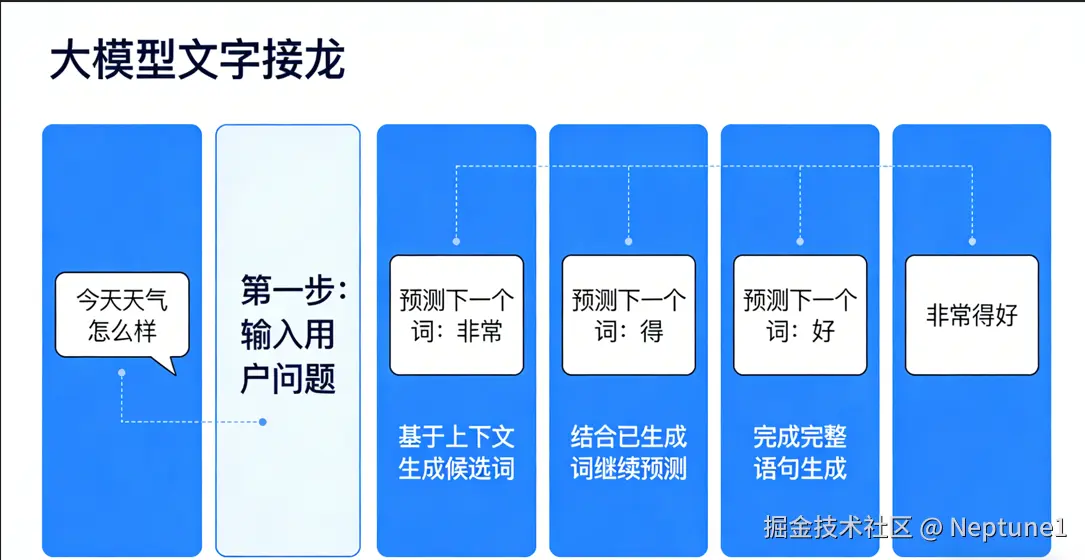
1. 文字接龙本质:大模型本质是文字接龙游戏,接收问题后预测下一个概率最高的词,将其追加到输入继续预测,直至输出结束标识符。
比如我们来举一个例子:当我们询问今天的天气怎么样,模型在接收到我们发给他的这句话后,内部经过运算后,会对下一个概率最高的词进行预测,比如"非常",当模型输出"非常"这个词后,他会将输出的"非常这个词再拿回来",追加到刚刚的你刚刚的输入后面,然后拿着这个拼接过后的输入再去预测下一个字比如说是"得",然后他会再把"得"塞回去,然后再拿着拼接后的句子再进行预测下一个字,比如说"好"。这个时候大模型发现他要说的话已经说完了,这个时候他就会输出一个结束词。这个回答就结束了,这样我们就拿到了大模型的输出结果"特别的好",这就是大模型的最底层生成原理,这就是为什么大模型要一个词一个词地输出答案
2. 中间人 Tokenizer 以及 Token是什么
为什么要有Tokenizer?
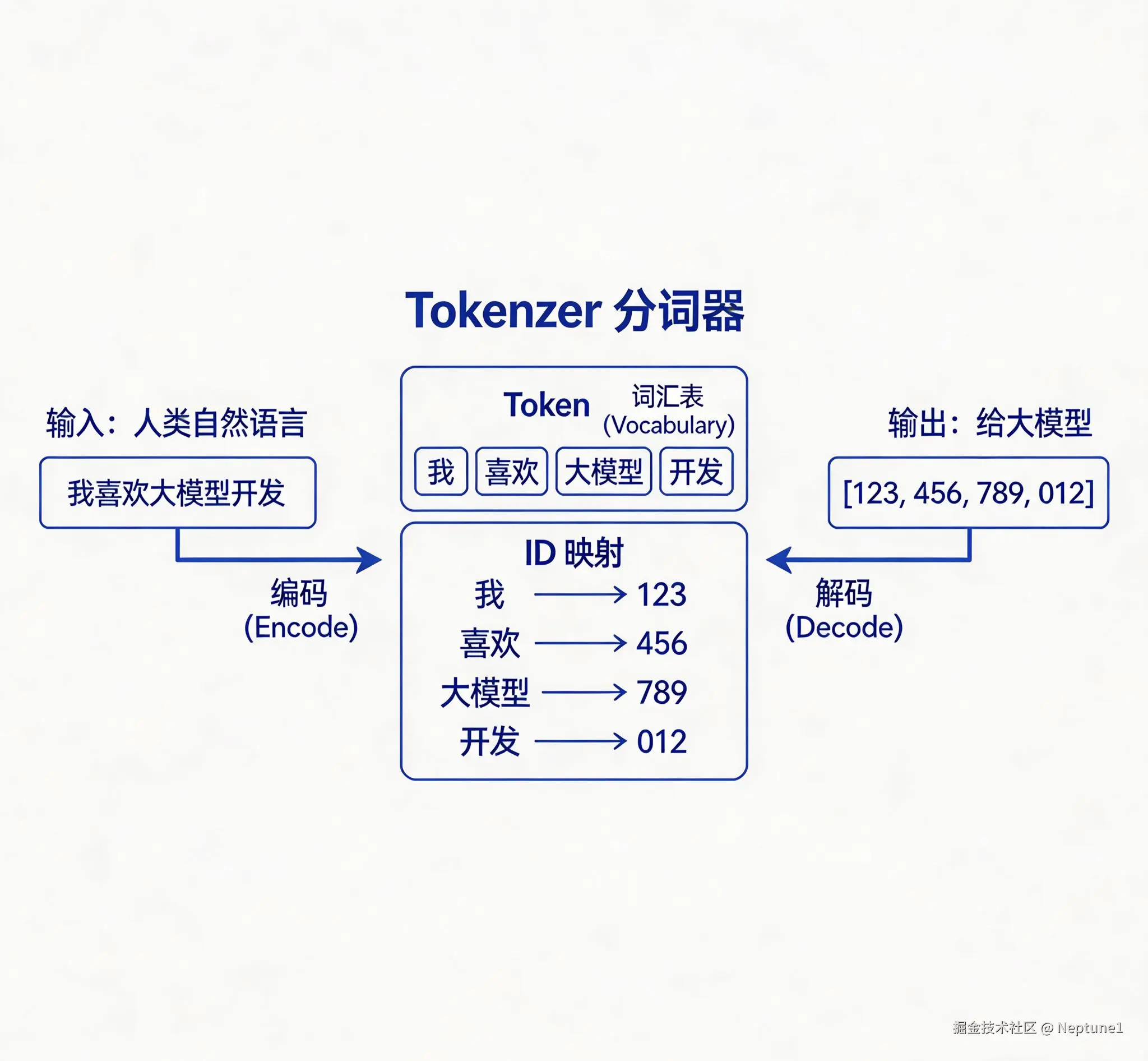
由于大模型本质就是一个数学函数+矩阵运算,他只认数字,不认文字、标点等。所以你如果输入给大模型一串文字和标点,那么他就无法读懂你的意思。而Tokenizer就是大模型中连接人类语言和模型数字运算的核心翻译官,负责把人类文字编码成大模型能运算的数字序列,再把大模型输出的数字转换为人类能读的文字,可以说,没有Tokenizer,大模型就是文盲
Token是什么
Token是大模型处理文本的基本单元,与词无明确一对一关系,平均 1 个 TOKEN 约等于 0.75 个英文单词或 1.5 个汉字,他也是是模型处理文本的最小语义单元,可以是:
- 完整单词(如
ChatGPT) - 子词(如
program→program+mer) - 单个字符(如
a、中) - 特殊符号(如
<|endoftext|>、[CLS])
Tokenizer如何工作
1.编码 :
- 将文本预处理,统一格式,插入特殊标记等
- 分词:将处理好的文本切割成Token序列
- 映射为Token ID :查词汇表,将每一个Token对应唯一数字
2.解码
- 模型输出一串Token ID
- Tokenizer反向查表
- 拼接成自然文本返回给用户
了解了Tokenizer与Token后,我们就能发现,由于主流的大模型API是按照Token收费,我们通过优化Tokenizer解码方式与输入的内容,可以节省费用
二、什么是上下文(Context)
我们平时使用大模型时,发现他好像能记住之前说过的话,但是你是否好奇过,明明大模型本质上只是一个函数,你给他输入,他就给你输出,并不像真实的人一样有记忆,那么他是怎么记住你之前说的话呢?

1. Context:
答案就是当我们每次给大模型发送消息时,并不只会发送我们的问题,还会自动将你之前的整段对话历史找出来一起发过去,这样的对话历史和用户问题一起发送过去后,模型每次都能看到完整的对话内容,所以他能知道之前发生了什么,而Context就代表着大模型每次处理任务时能接受到的消息总和,而用户问题和对话历史都是大模型所接受到的消息,所以用户问题和对话历史也就是Context的一部分,除此之外,Context内还有许多东西,比如大模型正在输出的每一个Token都会被计入在内,以及工具列表,SystemPrompt等信息,所以我们就能简单理解为Context就是大模型每次处理任务时所接受到的消息总和,某种程度上也可以将Context理解成大模型的一个临时记忆体。
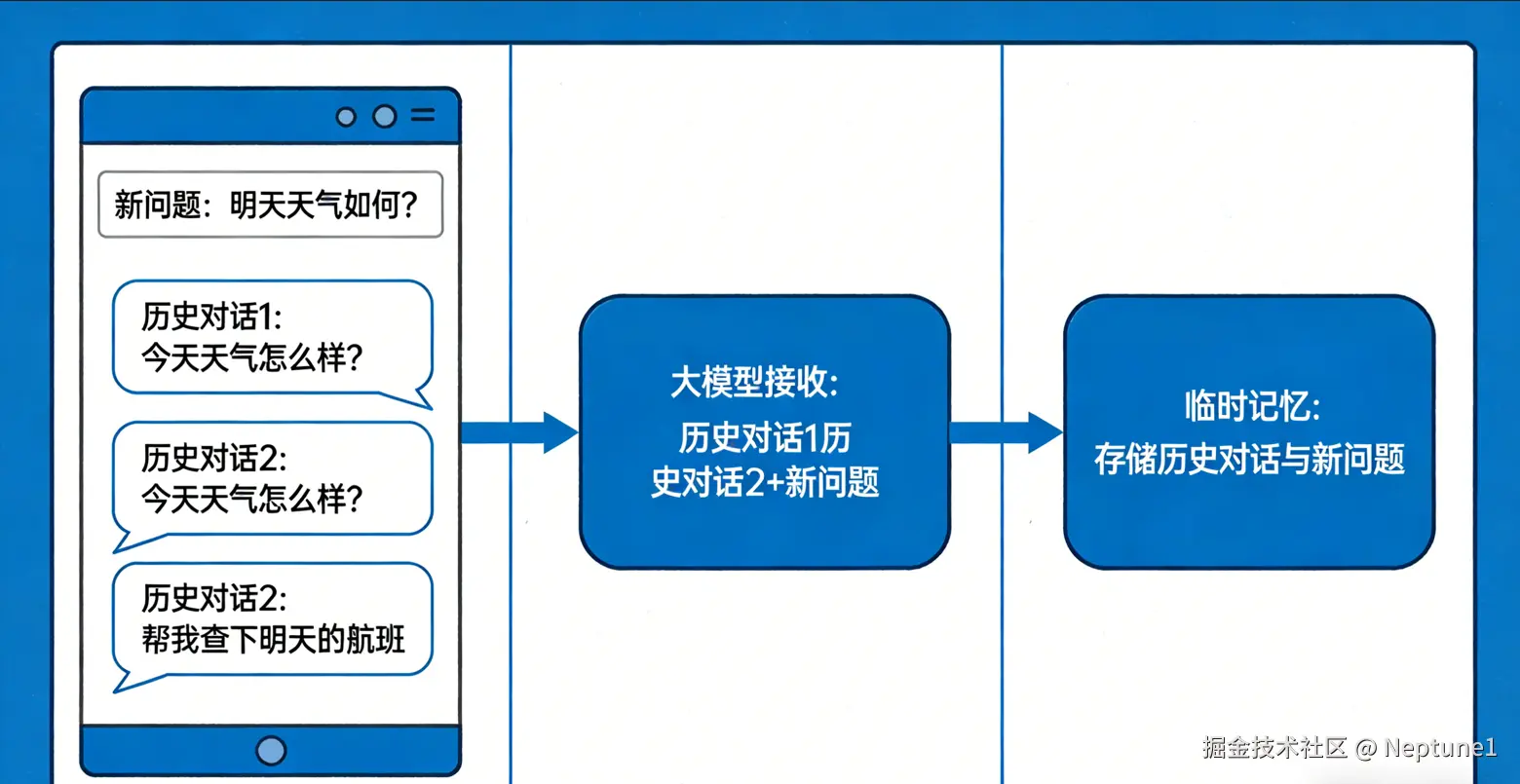
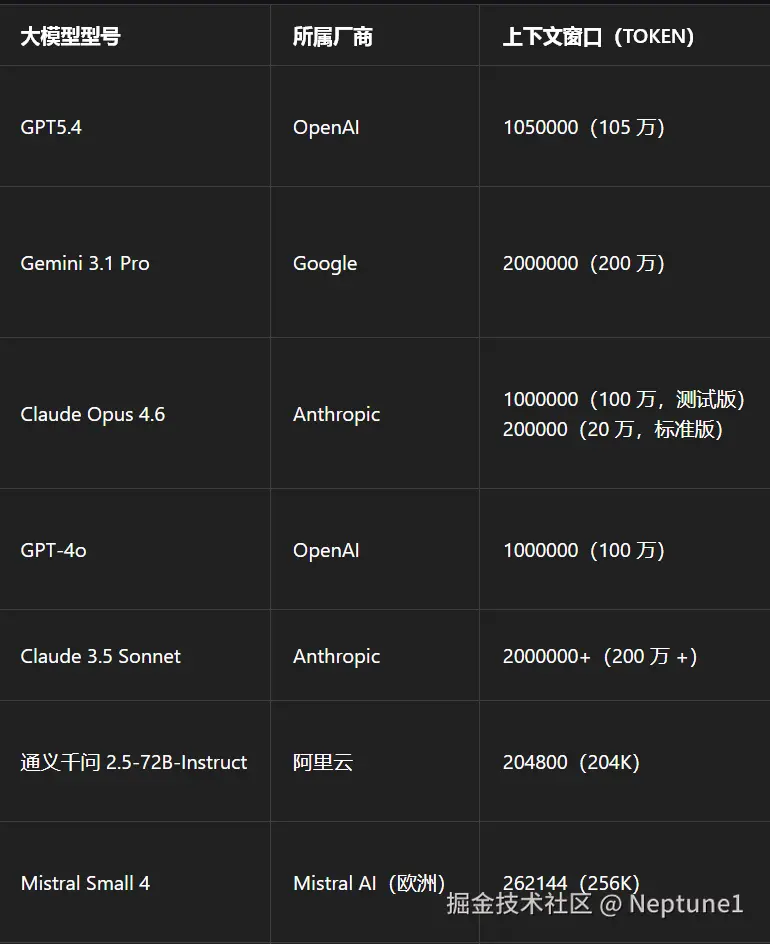
2. Context能有多大,能放多少东西
Context Window(上下文窗口),Content Window直接决定了Context能有多大,下图是目前主流大模型的Context Window的大小,100万Token的大小大约可以放下150万的汉字数量。
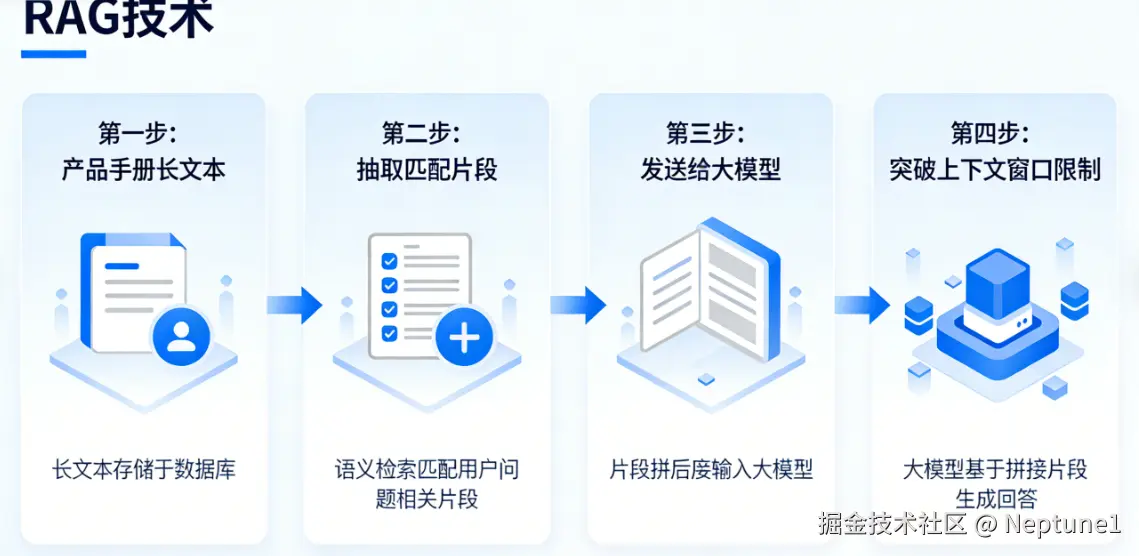
当你想要让大模型读取一本数十万字的产品手册,你希望大模型能够根据该产品手册来回答用户的各种问题,那么我们该如何实现呢,难道需要将这个数十万字的产品手册和用户问题一起扔给大模型吗,由于这个内容量太大,即使大模型的Context Window能够容下,大模型读取该产品手册所花费的Token也是你难以承受的成本,为了来解决这个问题,于是我们就引入了RAG技术
3. 什么是RAG技术,有什么用
当处理长文本如公司产品手册时,可使用 RAG 技术抽取与用户问题最匹配的片段发给大模型,这样就能不受 context window 限制且降低成本了。