这里有一个小问题,当瓶颈在消费者(渲染线程,GPU)时,缓冲区会长时间处于填满的状态,生产者(主线程)可能频繁被休眠和唤醒从而影响帧率;另外在缓冲区被填满时,渲染线程的帧可能会落后主线程多帧,
https://zhuanlan.zhihu.com/p/44116722
主线程提交渲染指令到缓冲区渲染线程从缓冲区取出这些数据处理,经典的生产者与消费者模式。缓冲区被填满时,渲染线程的帧可能会落后主线程多帧,方案一(双队列+帧同步)
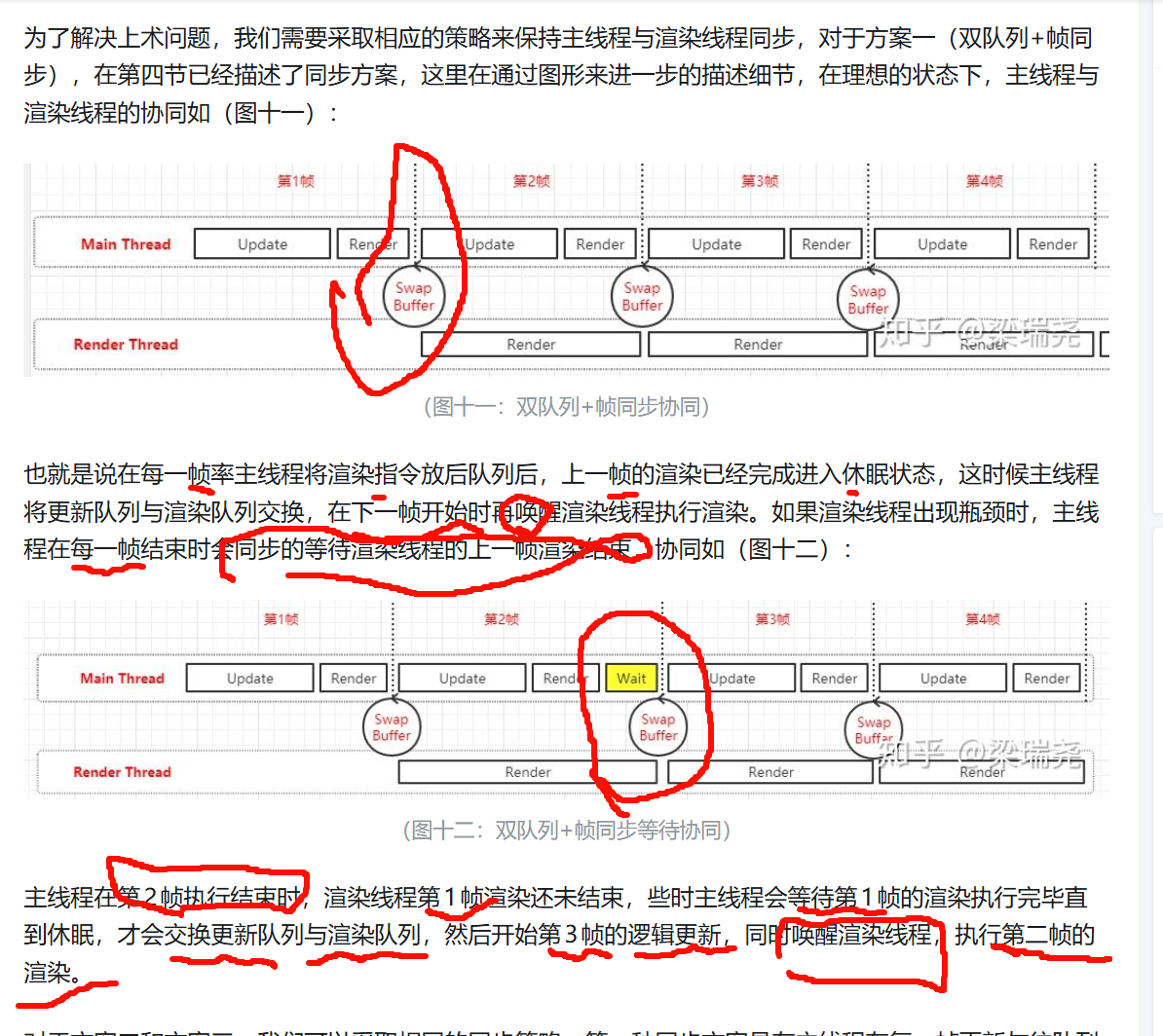
等待第1帧的渲染执行完毕直到休眠,才会交换更新队列与渲染队列每一帧渲染结束时,主线程提交Present指令VBO(Vertex Buffer Object)是 OpenGL 中用于在 GPU 显存中存储顶点数据的核心技术,通过减少 CPU 与 GPU 之间的数据传输,显著提升渲染效率。传统方式需通过 glBegin()/glEnd() 逐顶点传输数据,而 VBO 只需初始化时传输一次,后续绘制直接从 GPU 读取。
cpp
// 初始化 VBO(仅执行一次)
unsigned int vbo;
glGenBuffers(1, &vbo); // 创建 VBO 对象
glBindBuffer(GL_ARRAY_BUFFER, vbo); // 绑定为顶点数据缓冲区
float vertices[] = { /* 顶点数据 */ };
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW); // 数据传入 GPU绑定 VBO 后,通过 glDrawArrays 或 glDrawElements 触发绘制。
cpp
// 每帧绘制
glBindBuffer(GL_ARRAY_BUFFER, vbo); // 绑定 VBO
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3*sizeof(float), (void*)0); // 定义数据格式
glEnableVertexAttribArray(0); // 启用顶点属性
glDrawArrays(GL_TRIANGLES, 0, 3); // 绘制 3 个顶点组成的三角形在 OpenGL 3.3+ 核心模式中,顶点数组对象(VAO)是必需的,它记录 VBO 的数据格式和绑定状态,简化多模型切换时的状态管理。
cpp
unsigned int vao;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao); // 绑定 VAO 后配置 VBO
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3*sizeof(float), (void*)0);
glEnableVertexAttribArray(0);续绘制只需绑定 VAO:glBindVertexArray(vao); glDrawArrays(...);。简化代码 :VAO 可封装多个 VBO 的配置,切换模型时无需重复设置顶点格式。混淆 VBO 与绘制函数 :drawVBO 并非标准函数,实际绘制需通过 glDrawArrays 或 glDrawElements 实现。忽视 VAO :OpenGL 3.3+ 核心模式强制要求使用 VAO,否则绘制会失败。数据传输效率 :频繁更新 VBO 数据会降低性能,应根据数据变化频率选择 GL_STATIC_DRAW(静态)或 GL_DYNAMIC_DRAW(动态)。Vertex Buffer Objects (VBOs) are not exclusive to OpenGL . The core concept of a VBO---storing vertex data in the graphics card's memory for efficient rendering---is fundamental to modern graphics programming and exists across various graphics APIs.VBOs are an OpenGL feature, standardized in OpenGL 1.5, to replace inefficient "immediate mode" rendering. Similar functionality is available in other APIs under different names:
- Direct3D (DirectX): The equivalent concept is known as a Vertex Buffer.
- Vulkan and Metal: These lower-level APIs also use the concept of memory buffers (often called just "buffers") stored on the GPU to hold vertex data, providing similar or greater control over memory management.
DrawVBOCMD
表示队列中的一条命令记录,意思类似于:
"请在渲染线程上执行一次 DrawVBO"
而右边 RenderThread 里的 DrawVBO
表示真正执行这条命令对应的渲染动作。
虚线框,通常表示:
这一步不是当前线程立即执行的实体逻辑,而是被封装/排队/异步化的命令项,或者是逻辑上的步骤而非当前阶段直接运行。
MainThread 里面的虚线框 SetMaterial、DrawVBO,意思更像是:
-
这些原本是逻辑上需要做的渲染操作
-
但在这个线程模型里,它们不会直接在 MainThread 上真正执行
-
而是会被转成
CMD推进队列,由 RenderThread 真正执行
如果让主线程将渲染指令提交到队列继续下一帧的更新,会让帧率变得更平滑,因此我们可以采用延时一帧的等待策略,将图形API的调用直接封装成渲染指令,提到到渲染队列有返回值的图形API,在主线程将渲染指令提交到队列时,应该返回什么值?带宽代表的是有多少事情可以同时做性能(处理速度)说的是一件在逻辑上必须按顺序处理的事情本身可以多快完成。软件多线程不足: 如果你的软件(如老旧游戏或单线程程序)只写了"做一项任务",那么系统只能让一个 CPU 核心负责它。其他核心即使加了,也只会显示 0% 使用率。
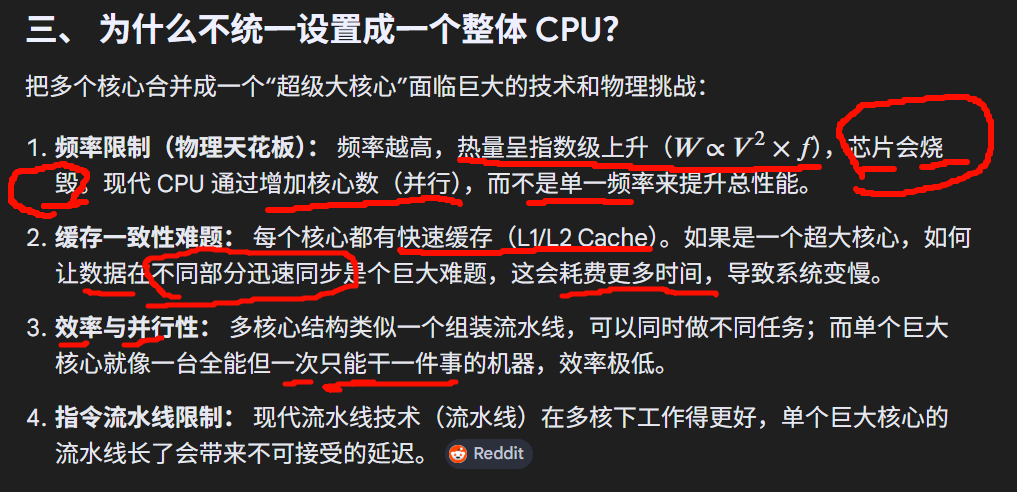
操作系统利用 CPU0 处理复杂的中断和管理(效率),让其余核心在需要时爆发(性能)
十多年前,主流观点主张在可能的情况下优先选择多进程而非多线程。
https://tech.meituan.com/2024/07/19/multi-threading-and-multi-thread-synchronization.html
多线程技术在很大程度上改善了程序的性能和响应能力,使其能够更加高效地利用系统资源,这不仅归功于多核处理器的普及和软硬件技术的进步,还归功于开发者对多线程编程的深入理解和技术创新。那么什么是线程呢?线程是一个执行上下文,它包含诸多状态数据:每个线程有自己的执行流、调用栈、错误码、信号掩码、私有数据。Linux内核用任务(Task)表示一个执行流。与逻辑线程对应的是硬件线程,这是逻辑线程被执行的物质基础。从软件的视角来看,无须区分是真正的Core和超出来的VCore,基本上可以认为是2个独立的执行单元,每个执行单元是一个逻辑CPU,从软件的视角看CPU只需关注逻辑CPU。一个软件线程由哪个CPU/核心去执行,以及何时执行,不归应用程序员管,它由操作系统决定,操作系统中的调度系统负责此项工作。这个整型数组分成多个小数组,或者表示成二维数组(数组的数组),每个线程负责一个小数组的求和,多个线程并发执行,最后再累加结果。
一个例子来阐述线程、核心和函数之间的关系,假设有遛狗、扫地两类工作要做:
- 遛狗就是为狗系上绳子然后牵着它在小区里溜达一圈,这句话就描述了遛狗的逻辑,即对应到函数定义,它是一个对应到设计的静态的概念。
- 每项工作,最终需要人去做,人就对应到硬件:CPU/Core/VCore,是任务被完成的物质基础。
多线程并不一定需要多CPU多Core,单CPU单Core系统依然可以运行多线程程序(虽然最大化利用多CPU多Core的处理能力是多线程程序设计的一个重要目标)。1个人无法同时做多件事,单CPU/单Core也不可以进程和线程是操作系统领域的两个重要概念,两者既有区别又有联系。操作系统领域的C/C++源文件经过编译器(编译+链接)处理后,会产生可执行程序文件,
不同系统有不同格式,比如Linux系统的ELF格式、Windows系统的EXE格式,可执行程序文件是一个静态的概念。
可执行程序exe在操作系统上对应一个进程的一次执行
先看看linus的论述,在1996年的一封邮件里,Linus详细阐述了他对进程和线程关系的深刻洞见,他在邮件里写道:
- 把进程和线程区分为不同的实体是背着历史包袱的传统做法,没有必要做这样的区分,甚至这样的思考方式是一个主要错误。
- 进程和线程都是一回事:一个执行上下文(context of execution),简称为COE,其状态包括:
- CPU状态(寄存器等)
- MMU状态(页映射)
- 权限状态(uid、gid等)
- 各种通信状态(打开的文件、信号处理器等)
- 传统观念认为:进程和线程的主要区别是线程有CPU状态(可能还包括其他最小必要状态),而其他上下文来自进程;然而,这种区分法并不正确,这是一种愚蠢的自我设限。
- Linux内核认为根本没有所谓的进程和线程的概念,只有COE(Linux称之为任务),不同的COE可以相互共享一些状态,通过此类共享向上构建起进程和线程的概念。
- 从实现来看,Linux下的线程目前是LWP实现,线程就是轻量级进程,所有的线程都当作进程来实现,因此线程和进程都是用task_struct来描述的。这一点通过/proc文件系统也能看出端倪,线程和进程拥有比较平等的地位。对于多线程来说,原本的进程称为主线程,它们在一起组成一个线程组。
简言之,内核不要基于进程/线程的概念做设计,而应该围绕COE的思考方式去做设计,然后,通过暴露有限的接口给用户去满足pthreads库的要求。用户态的多执行流,上下文切换成本比线程更低,微信用协程改造后台系统后,获得了更大吞吐能力和更高稳定性。
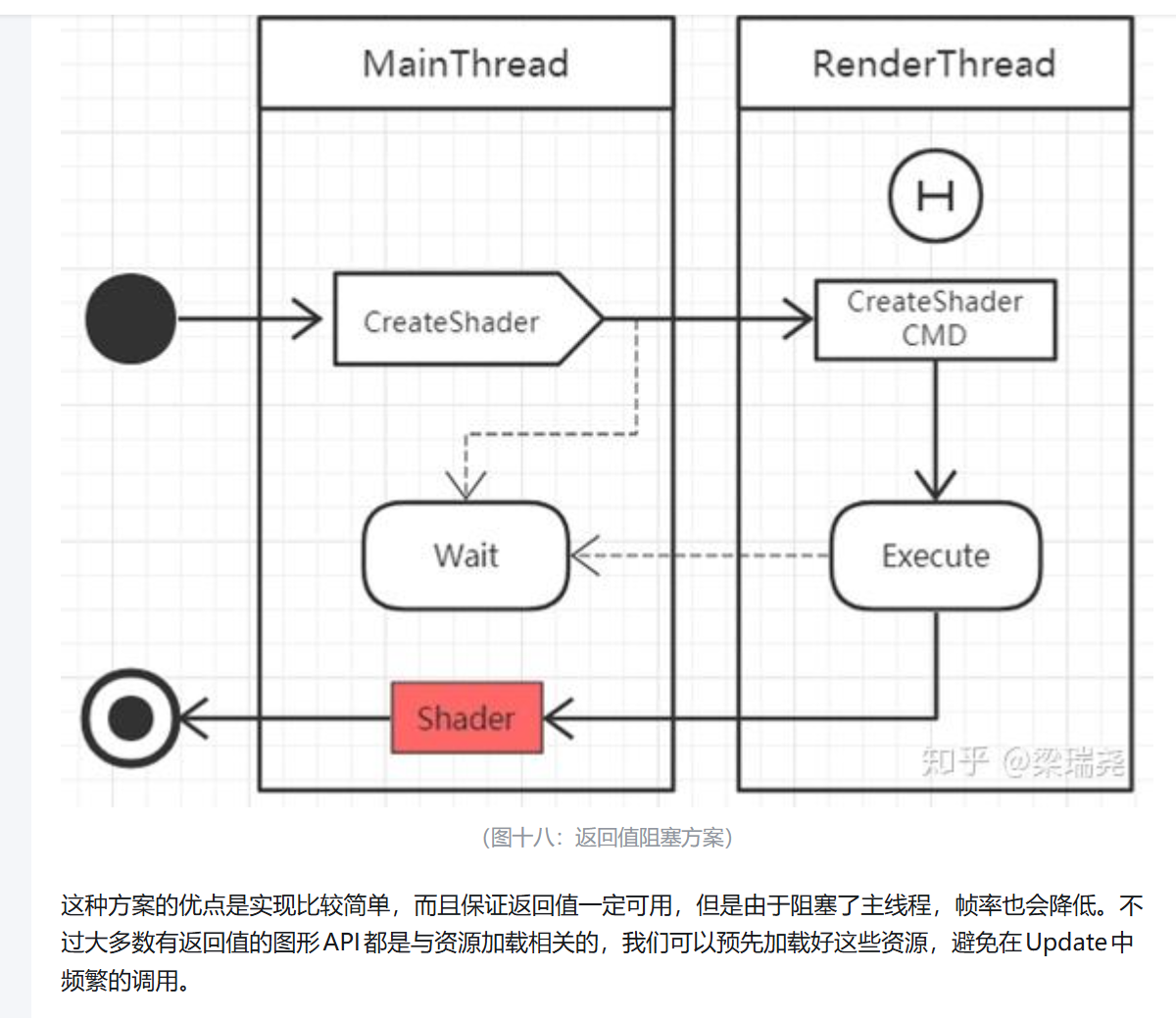
大多数有返回值的图形API都是与资源加载相关的创建一个被封装的对象直接返回对象作为渲染指令的参数传递到队列,渲染线程执行到该指令后创建好正真的对象,再将真正的对象赋值给封装的对象主线程中创建的封装对象后,刚好提交到队列时就在主线程中删除了该对象,那么渲染线程指令到这条指令时,有可能会引进崩溃将删除对象调用封装成一条指令提交到队列,让渲染线程来执行删除阻塞时长封装阻塞时长为5微平均被阻塞时长虽然只有0.9毫秒每一次调用opengl的api
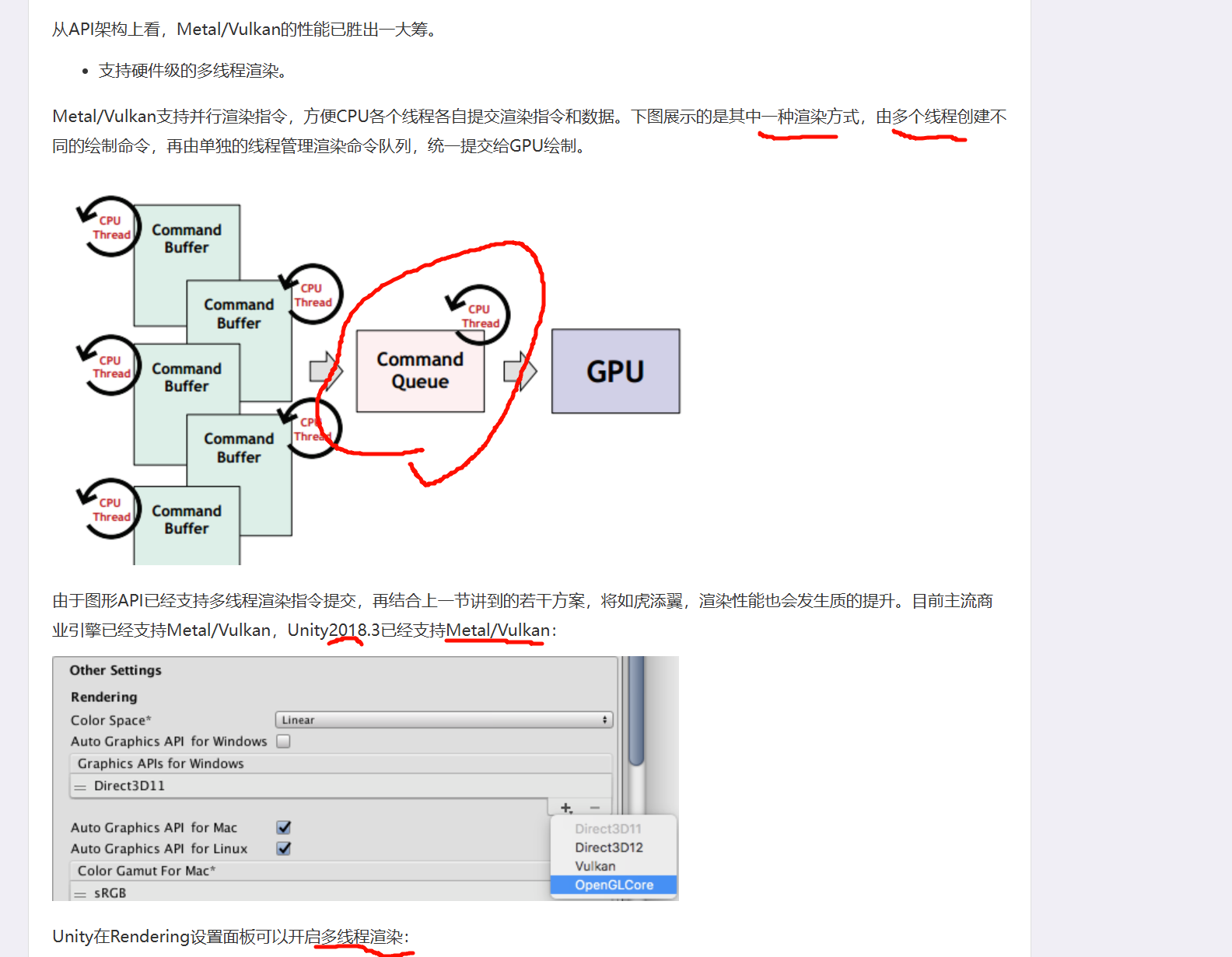
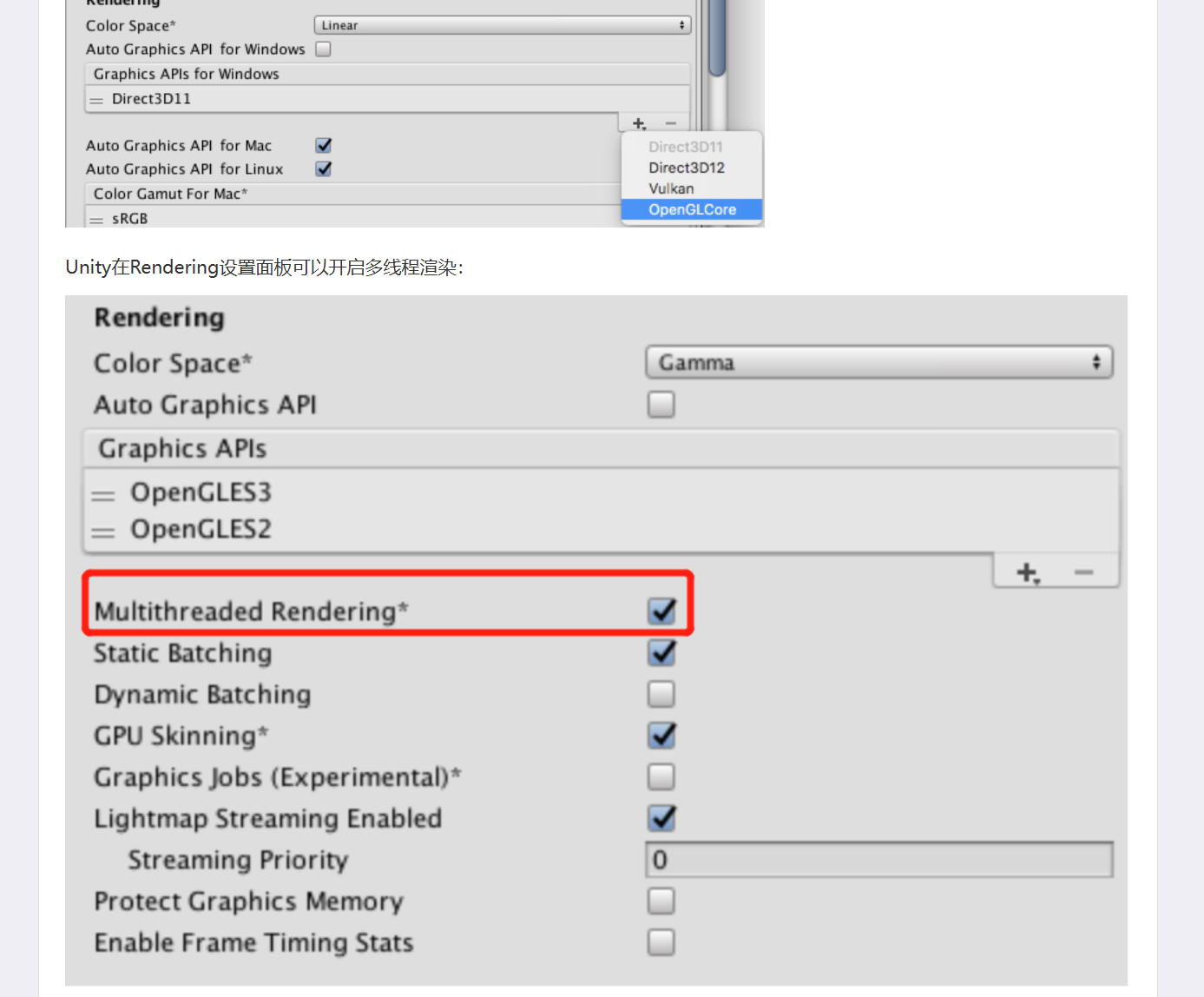
"真正的多线程渲染"现在是常态,但实现重心已经从 DX11 式 deferred context,转到了 DX12 / Vulkan / Metal 这类显式命令录制模型。
你图里那套"一个 Rendering Thread + 多个 Secondary Thread 录 command list,再汇总执行"的思想,到今天仍然成立;只是现代 API 把它做成了一等公民。Microsoft Learn+2Vulkan Documentation+2
更具体地说:
在 DX11 时代,确实有 Immediate Context + Deferred Context + Command List 这套机制。微软文档也明确说,deferred context 用来在其他线程记录图形命令,之后交给主渲染线程提交。也就是说,你图里的模型在 DX11 语义下是对的。只是这套东西在业界口碑一直比较一般,能用,但不是后来主流高性能渲染架构的终点。Microsoft Learn+1
到了 DX12 ,微软直接把旧的 immediate context 模型拿掉了。官方文档写得很直白:D3D12 不再有和 device 绑定的 immediate context,应用改为记录 command lists,再提交到 command queues ;而且 command lists 可以从多个线程提交到一个或多个 command queues。微软还特别强调,CPU 成本的大头通常在 command list building ,而不是 command list execution。这个变化本质上就是把"多线程录制命令"从 DX11 的补充机制,升级成了 API 的基础设计。Microsoft Learn+2Microsoft Learn+2
Vulkan 则更彻底。它天生就是按多线程命令录制来设计的:不同线程可以同时记录不同的 command buffers,primary command buffer 还可以执行 secondary command buffers。Khronos 的教程和样例都明确把 multithreaded recording 当成 Vulkan 的典型优势,并且建议在合适场景下把 draw call 分摊到多个线程去录 secondary command buffers。Vulkan Documentation+2Vulkan Documentation+2
Metal 也类似。Apple 文档说明 command queue 是线程安全的,可以同时创建并编码多个 command buffers;此外还有 MTLParallelRenderCommandEncoder,专门支持把同一个 render pass 的图形编码任务并行分发到多个 subordinate render encoders。也就是说,Metal 不是照搬 DX11 deferred context,而是用自己的 command buffer / parallel encoder 模型解决同类问题。Apple Developer+2Apple Developer+2
所以如果你问"如今呢",可以直接记成这三句:
第一,真正的多线程渲染早就不是 DX11 独有概念了 。现代 API 基本都把"多线程录制命令、单点或多队列提交 GPU"作为基础能力。Microsoft Learn+2Vulkan Documentation+2
第二,今天的重点不是多个线程同时直接碰 GPU,而是多个 CPU 线程并行准备 GPU work 。也就是并行构建 command lists / command buffers,最后再提交给 queue。
游戏里常见的主线程、渲染线程、资源线程、音频线程、任务线程池,本质上都建立在"线程是执行流、由 OS 调度到硬件执行单元"这套模型上。文章用"把大任务拆成多个可并发的小任务"的方式解释多线程价值,这和现代引擎里的 job 化完全同构。游戏里的动画评估、可见性剔除、骨骼蒙皮准备、batch build、导航更新、资源解压,都常被拆成一批小任务丢进线程池。线程的创建和销毁需要内核参与,开销很大。池化技术(复用)能显著提高系统响应速度。
锁、竞态、死锁、同步的系统性讲解,对游戏开发是高度相关的。
更适合作为"并发基础总复习"。它不会直接替代下面这些更贴游戏的知识:
-
渲染线程/RHI 线程/提交线程模型
-
Frame graph / render graph 的并行构建
-
GPU-CPU 同步与 pipeline stall
-
DX12/Vulkan/Metal 的 command recording
-
引擎级 task graph、fiber job system、work stealing
-
ECS 数据布局与 cache locality
所以最准确的评价是:
和游戏领域关系很大,尤其对引擎、性能优化、资源系统、任务系统非常相关;但它属于"并发底层通识",不是"游戏渲染专项教程"。
线程并非无限的。操作系统创建和销毁线程(如分配1MB栈空间、与内核交互)非常昂贵。线程池通过复用现有线程处理新任务,彻底消除了这些开销。
轻量化的驱动层。
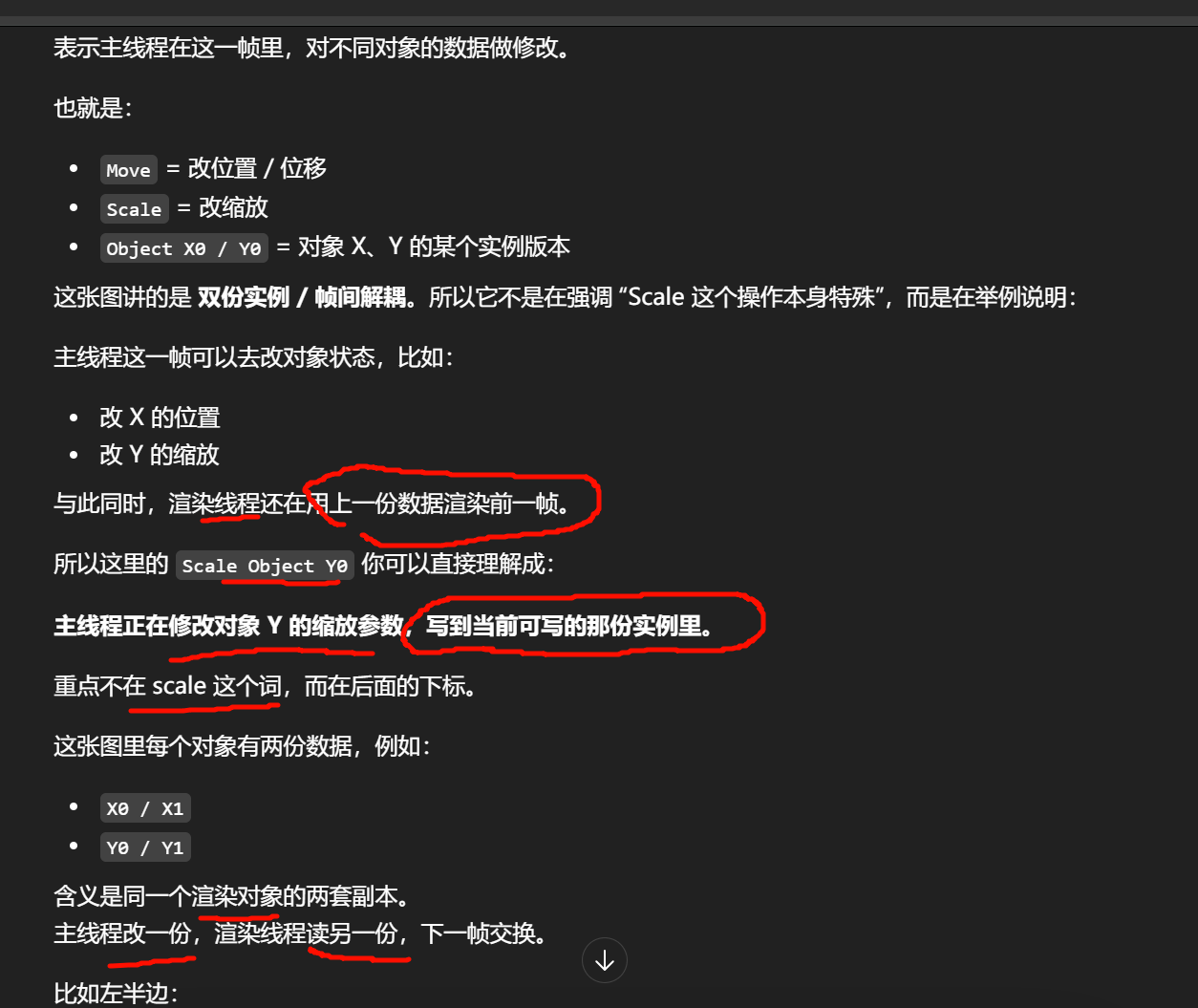
如果你的模型在导入时没有正确设置"硬边"(Hard Edges),虚幻引擎可能会尝试插值顶点法线。Shading Model 改为 Unlit(无光照)。
自动曝光 (Auto Exposure / Eye Adaptation)
UE 使用电影级的色调映射(Tone Mapper)来处理颜色。
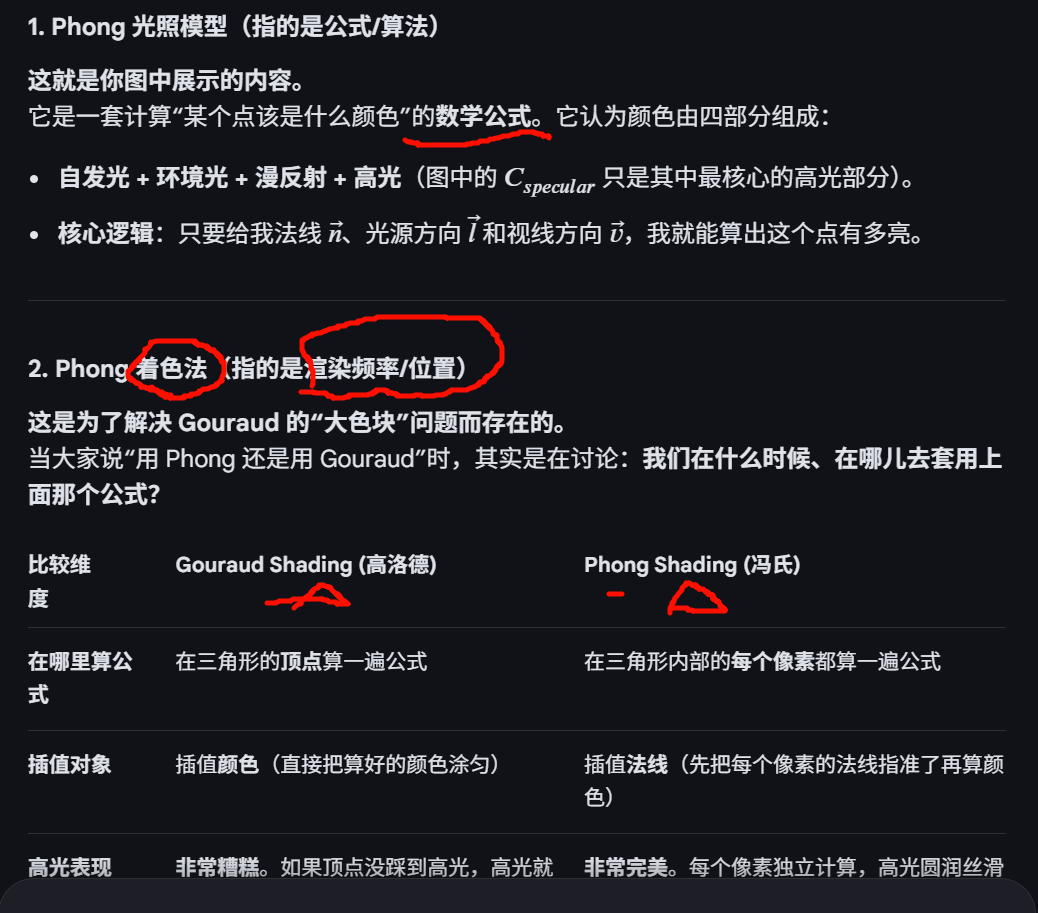
与 Phong Shading 的区别:
- Gouraud Shading :在顶点处算颜色,在像素处插值颜色。计算开销小,但难以表现精细的高光(Specular Highlights)。
- Phong Shading :在顶点处传法线,在像素处插值法线后再算颜色。效果更细腻,但计算量更大。
简单来说,Gouraud Shading(高洛德着色)存在的意义就是:
用极小的计算代价,让"满身棱角"的 3D 模型看起来变光滑。
在它出现之前(1971年以前),3D 渲染主要靠 Flat Shading(平直着色)。你可以对比一下它们的区别:
- 解决"打马赛克"的问题 (Flat Shading 的痛点)
- Flat Shading :一个三角形面只计算一次光照,整个面都是一个颜色。
- 结果:球体会变成像"迪斯科转球"一样的方块组合,边缘极其生硬 1, 2。
- Gouraud Shading :在三角形的三个顶点 分别算颜色,中间的像素颜色靠"混合"(插值)出来。
- 结果:颜色在面与面之间平滑过渡,原本有棱角的模型看起来像流线型了 3, 4。
- 算力不够时的"权宜之计"
你可能会问:"为什么不直接每个像素都精确计算光照?"
- 因为太慢了。在 70-90 年代的硬件条件下,逐像素计算(Phong Shading)会让显卡"冒烟"。
- Gouraud 的聪明之处:它只在顶点(Vertex)做复杂的数学运算(法线、光源向量等),而像素点(Fragment)的颜色只需要做简单的加法运算(线性插值) 4, 5。
- 效率对比 :如果一个三角形有 1000 个像素,Gouraud 只需算 3 次 光照逻辑;而逐像素着色需要算 1000 次 5。
它的主要缺陷(为什么现在用得少了)
虽然它让物体变光滑了,但它有个致命伤: 高光(Specular Highlights)会丢失或变形。
- 如果高光点刚好落在三角形中间(没碰到顶点),Gouraud 就完全算不出来,导致高光看起来像一团模糊的色块,或者随着视角移动忽明忽暗 5, 6。



光照计算在顶点,所以效果和消耗跟4.5.2 Gouraud Shading类似,是早期GPU使用较多的一种渲染方式。"获取几何信息 -> 写入 RT"这套流程重复了 10 遍。
它是"逐物体"的写入
对于场景中的 10 个物体,GPU 的工作方式如下:
- 处理物体 A :经过 VS、GS、FS(计算颜色),直接把结果**写入并混合(Blending)**到 Render Target 的对应像素位置。
- 处理物体 B :同样经过一遍管线,再次写入/覆盖 Render Target 的相同区域。
- ...以此类推,重复 10 遍。
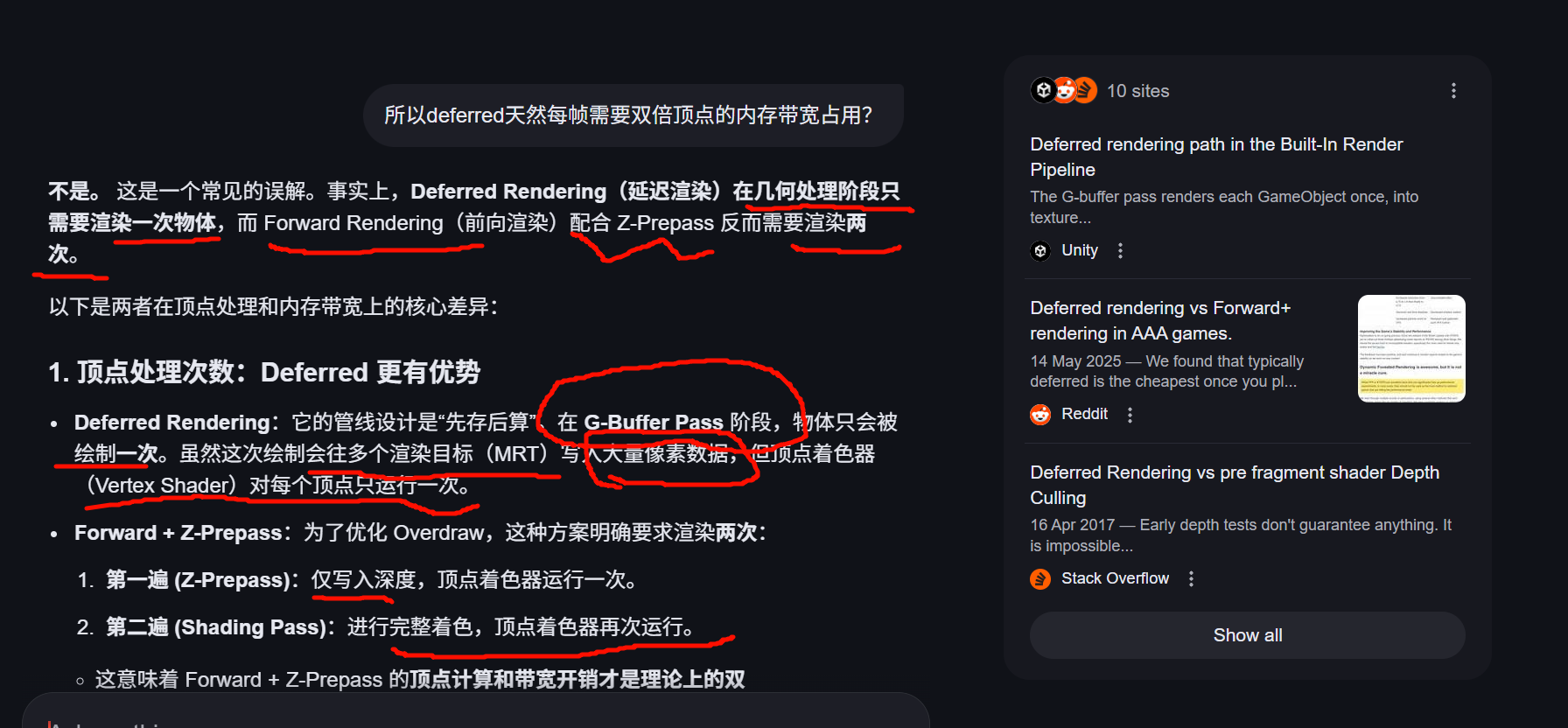
最大的问题是,一堆geo在场景里,但是不知道他们的前后顺序,这个排序很消耗,所以prepass z,deferred
在 Forward Rendering(前向渲染)中
在传统的前向渲染中,Z-Prepass 通常作为一个 可选的优化步骤。
- 做法:在正式进行复杂的着色(Lighting/Shading)之前,先用一个极简的 Shader 将场景物体的深度(Z值)写入深度缓冲区(Depth Buffer),此时不写颜色。
- 目的 :减少 Overdraw(过度绘制)。通过预先生成的深度图,后续昂贵的像素着色器(Pixel Shader)可以通过硬件的 Early-Z 测试,只对最终可见的像素执行,从而大幅节省计算资源。
- 代价:需要双倍的顶点处理开销(Draw Call 数量翻倍)。
带宽压力的来源:像素 vs 顶点
你感觉到的"带宽占用高"通常是指 像素带宽而非顶点带宽。
- Deferred 的带宽瓶颈 :由于需要同时向多个纹理(Albedo, Normal, Depth, Roughness 等)写入数据,G-Buffer Pass 阶段对 像素填充速率(Fillrate)和显存带宽 的压力极大。
- Forward 的带宽瓶颈:主要集中在纹理采样和光照计算。如果不加 Z-Prepass,严重的 Overdraw 会导致大量的无效像素着色计算。
什么延迟渲染有时看起来"慢"?
虽然 Deferred 在顶点上更节省,但它有以下沉重的"负担":
- 显存占用:G-Buffer 需要存储多张高分辨率纹理(如 1080P 下每张约 8MB),这对移动端显存极不友好。
- 读写开销:光照阶段需要重新读取这些庞大的 G-Buffer 数据。
- 无法抗锯齿:传统的硬件 MSAA 在延迟渲染中难以直接使用,通常需要昂贵的后期方案(如 TAA)。

在 Deferred Rendering(延迟渲染)中
在延迟渲染中,Z-Prepass 的概念被集成到了管线的 核心步骤中。
概念误区:光追不需要"渲染管线",它需要"加速结构"
- 延迟渲染(Deferred) 处理的是**光栅化(Rasterization)**阶段。
- 光追(Ray Tracing) 依赖的是 BVH(层次包围盒) 等空间加速结构。
- 真相 :无论你用 Forward 还是 Deferred,只要你想做硬件级实时光追(RTX/DXR),你都必须额外维护一套场景的 BVH 树。延迟渲染生成的 G-Buffer 恰恰是光追极佳的发射起点。
延迟渲染 + 光追(Hybrid Rendering)是行业标准
目前的 3A 大作(如《赛博朋克 2077》)基本都是这种架构:
- 第一步 (Deferred Pass):生成 G-Buffer。这告诉了 GPU 每个像素的起点位置、法线和材质。
- 第二步 (Ray Tracing Pass) :从 G-Buffer 取数据作为射线起点。如果射线撞击了物体,再去查询 BVH 得到交点。
- 优势 :你不需要为每个遮挡的像素做光追,只需要为 G-Buffer 中最终可见的像素发射射线。这反而极大节省了光追开销。
关于 Raymarching(光线步进 / Raystep)
如果说的是 SSLR(屏幕空间局部反射) 这种 Raymarching:
- 错误点 :恰恰相反,Raymarching 极其依赖 Deferred。
- 原因:Raymarching 需要知道场景的深度信息来判断是否"撞击"。Deferred 提供的深度图(Depth Buffer)是 Raymarching 的核心数据源。没有深度信息,你连光线往哪走、在哪停都不知道。
光追与延迟渲染的结合 (Ray Tracing + Deferred)
在现代高性能游戏引擎(如虚幻引擎5)中,Deferred 是主渲染管线,而光线追踪则被用于计算高质量的特效。
- 协同工作模式: 系统先使用延迟渲染绘制场景的几何体并填充G-Buffer,随后使用光线追踪技术(如 RTGI)计算高质量的全局光照,最终利用计算结果对画面进行后处理降噪,生成最终影像。
- 性能权衡: 实时光追非常昂贵,通常与AI降噪技术(如DLSS)配合使用,以在保证画质的同时维持可用的帧率。
显卡RT Core计算单元光线追踪 (Ray Tracing)主要成本
简单来说,光线追踪(RT)的成本与 Shader 中的 ALU(算术逻辑单元)计算
在硬件架构上是部分独立的,但在执行流程和资源占用上是深度耦合的。
支持硬件加速的显卡(如 NVIDIA RTX 或 AMD RX 6000+)中,光追最耗时的两项任务由 专用硬件单元完成,不占用通用的 ALU:
- BVH 遍历 (Traversal): 在复杂的场景树结构中寻找光线可能碰到的物体。
- 相交检测 (Intersection): 计算光线是否真的撞击到了三角形。
- 优势: 这些专用单元(如 RT Core)比通用 ALU 效率高出数倍甚至十倍。如果这些工作交给 ALU 做(即"软件光追"),帧率会大幅下降。
执行流程的耦合:接力赛跑
尽管"找撞击点"是独立的,但光线追踪并不是只有找点。一个完整的光追 Shader 流程通常如下:
- 生成光线 (Ray Gen): ALU 计算初始光线的方向。
- 追踪 (Trace): 此时 ALU 闲置,RT 单元接管进行遍历和检测。
- 着色 (Shading): 一旦撞击到物体,ALU 再次上场,根据该点的材质计算颜色、贴图采样或发射新光线(反弹)。
结论: ALU 的计算成本(比如复杂的 PBR 材质计算)会叠加在光追的遍历成本之上。
虽然 RT 单元和 ALU 是不同的物理模块,但它们 共享显卡的许多底层资源:
- 寄存器与缓存 (L1/L2 Cache): 光追会导致严重的内存访问不连续(随机性高),这会造成缓存污染,进而拖慢 ALU 正在进行的普通计算。
- 调度带宽: GPU 的调度器需要分配指令给不同的单元。如果光追产生的任务流过于庞大,可能会导致 ALU 等待数据,造成闲置(Stall)。
- 显存带宽: RT 需要频繁读取 BVH 结构数据,这与 ALU 读取贴图、缓冲区数据竞争显存带宽。
The BBC (British Broadcasting Corporation) is
the UK's publicly funded national broadcaster , established to provide impartial news, entertainment, and educational content.


真的是有点疑惑,这样的仅仅一个边缘光真的有这么重要吗,
整个画面上看,我觉得最突出的地方在dof
轻微但是恰当,而且一直有从上到中的skylight的感觉,在室内和室外都是这样,室内的可能就找光源然后发方向散光
toon shader感觉不toon啊
-
做分离
红发和深色背景、蓝色贝雷帽与树干背景有部分接近,轮廓提一点亮,人物会更干净地抠出来。
-
保持角色"发光感"
很多日系镜头不追求真实,而追求角色像被空气包起来一样。这个感觉经常靠很轻的 rim / wrap / soft fresnel。
每有特别狠的太阳直射高光,也没有特别深的黑位,整体亮度被压在一个很窄的舒适区间里。这样的素材,tonemapping 的"性格"天然就不容易被看出来。你不会看到很明显的 shoulder roll-off,也不会看到高光压缩带来的电影感。
高光结构不靠 tonemapper。

明度设计。暗部有没有环境反射色 线条与形体的主从关系。轮廓线是不是比内部线更强,线条有没有体积表达明暗.
压缩率降低的gif就看出来头发上的层次了,