摘要:荔枝是高价值热带水果,产量直接关系果农收益,但果园枝叶遮挡、果实重叠、光照不均等问题突出,导致传统人工计数估产效率低、误差大、劳动强度高。本文基于
YOLO26深度学习框架,通过2163张实际场景中果园荔枝的相关图片,训练了可进行荔枝目标检测的模型,可以很好的检测荔枝树上的荔枝并统计数量。最终基于训练好的模型制作了一款带UI界面的果园荔枝检测与计数系统,更便于进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
研究背景
荔枝作为高经济价值的热带水果,其产量直接关系果农收益,但果园环境复杂,枝叶遮挡、果实密集重叠、光照不均等问题突出,导致传统人工计数与估产方式效率极低、误差大,且劳动强度极高。本系统基于YOLO深度学习框架,构建高精度荔枝检测与计数模型,可自动识别并统计果园中的荔枝数量,突破人工监测在复杂场景下的精度与效率瓶颈。这对于实现荔枝精准估产、科学规划采摘及降低果农劳动成本具有重要价值。
应用场景
果园精准估产与采摘规划:采摘季前快速扫描果园,统计荔枝数量预测总产量,提前调配人力、运输及冷链资源。自动化采摘机器人视觉引导:作为机器人核心视觉模块,实时识别定位荔枝,引导机械臂精准抓取,实现无损自动化采摘。精细化农事管理:生长关键期统计幼果数量、评估坐果率,辅助果农调整疏果与水肥管理策略。产量数据记录与分析:积累历年荔枝数量与分布数据,形成产量趋势图,优化种植品种与田间管理。
主要工作内容
本文的主要内容包括以下几个方面:
-
搜集与整理数据集:搜集整理实际场景中果园荔枝的相关数据图片,并进行相应的数据处理,为模型训练提供训练数据集; -
训练模型:基于整理的数据集,根据最前沿的YOLOv26目标检测技术训练目标检测模型,实现对需要检测的对象进行有效检测的功能; -
模型性能评估:对训练出的模型在验证集上进行了充分的结果评估和对比分析,主要目的是为了揭示模型在关键指标(如Precision、Recall、mAP50和mAP50-95等指标)上的表现情况。 -
可视化系统制作:基于训练出的目标检测模型,搭配Pyqt5制作的UI界面,用python开发了一款界面简洁的软件系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。其目的是为检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。
软件初始界面如下图所示:
检测结果界面如下:
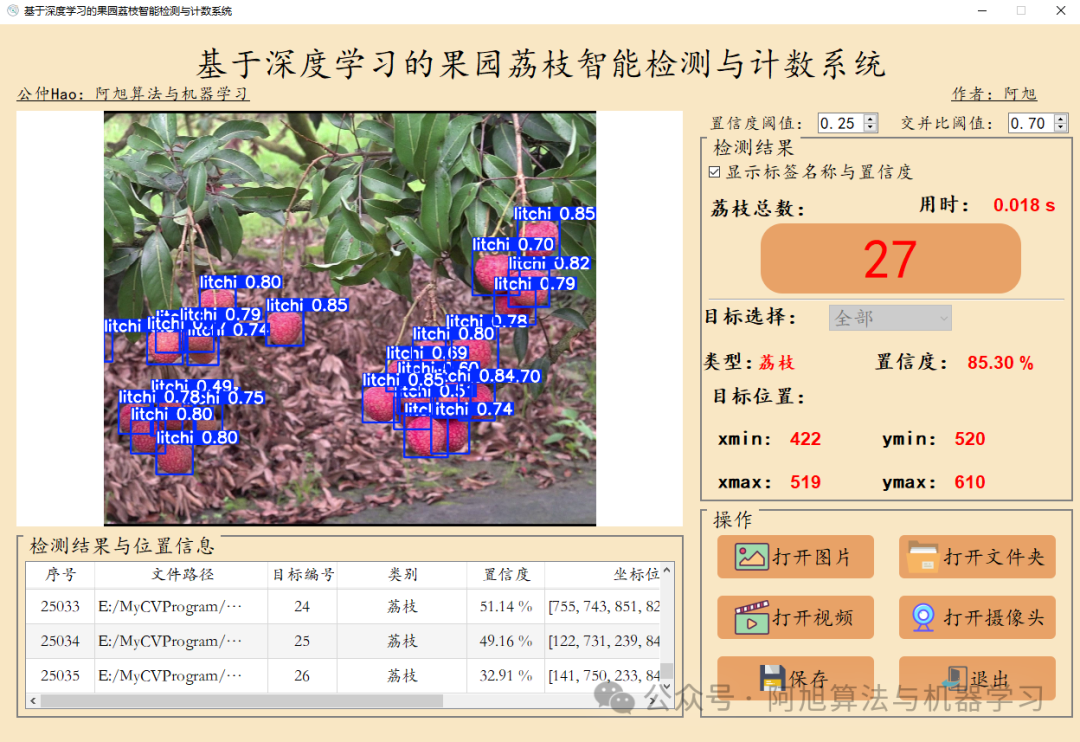
一、软件核心功能介绍及效果演示
软件主要功能
**1. 可用于实际场景中的荔枝检测,只有1个检测类别:['荔枝'];
-
支持
图片、视频及摄像头进行检测,同时支持图片的批量检测; -
界面可实时显示
目标位置、目标总数、置信度、用时等信息; -
支持
图片或者视频的检测结果保存; -
支持将图片的检测结果保存为
csv文件;**
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

界面参数设置说明

在这里插入图片描述
置信度阈值:也就是目标检测时的conf参数,只有检测出的目标框置信度大于该值,结果才会显示; 交并比阈值:也就是目标检测时的iou参数,对检测框重叠比例iou大于该阈值的目标框进行过滤【也就是说假如两检测框iou大于该值的话,会过滤掉其中一个,该值越小,重叠框会越少】;
检测结果说明
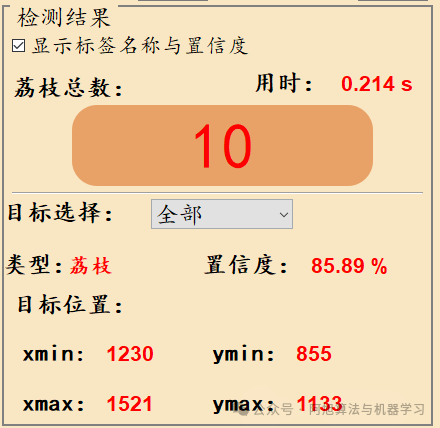
在这里插入图片描述
显示标签名称与置信度:表示是否在检测图片上标签名称与置信度,显示默认勾选,如果不勾选则不会在检测图片上显示标签名称与置信度;总目标数:表示画面中检测出的目标数目;目标选择:可选择单个目标进行位置信息、置信度查看。目标位置:表示所选择目标的检测框,左上角与右下角的坐标位置。默认显示的是置信度最大的一个目标信息;
主要功能说明
功能视频演示见文章开头,以下是简要的操作描述。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

(1)图片检测说明
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:点击目标下拉框后,可以选定指定目标的结果信息进行显示。 点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下,同时会将图片检测信息保存csv文件。注:1.右侧目标位置默认显示置信度最大一个目标位置,可用下拉框进行目标切换。所有检测结果均在左下方表格中显示。
(2)视频检测说明
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。 点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测说明
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
(4)保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存,对于图片图片检测还会保存检测结果为csv文件,方便进行查看与后续使用。检测的图片与视频结果会存储在save_data目录下。 【注:暂不支持视频文件的检测结果保存为csv文件格式。】
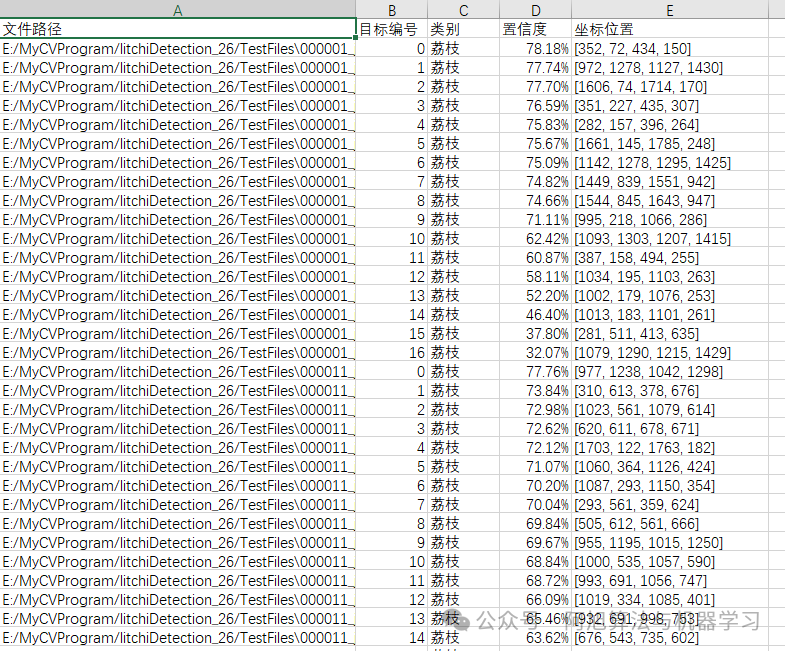
保存的检测结果文件如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。
二、模型的训练、评估与推理
1.YOLO26介绍
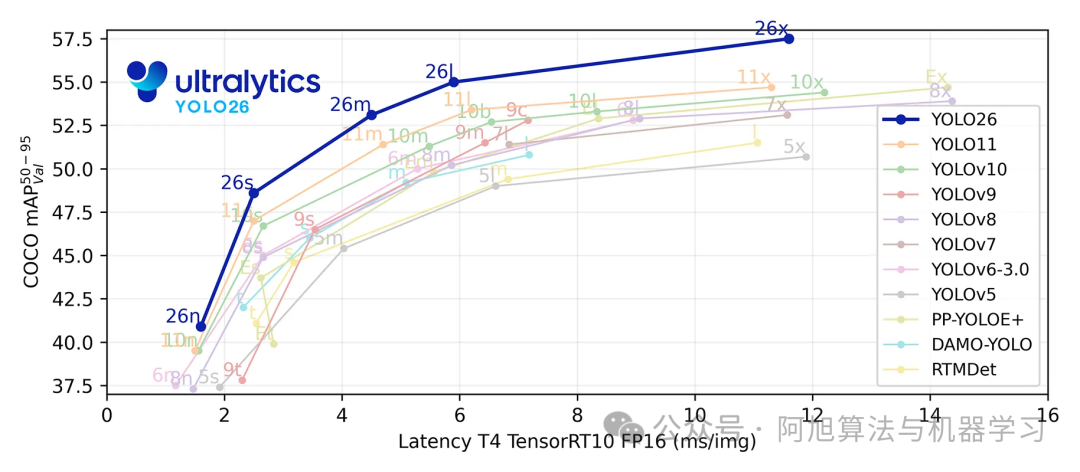
本项目采用的是最新的YOLO26模型。YOLO26 是 Ultralytics 2026 年 1 月推出的新一代计算机视觉模型,主打边缘优先、高效部署。它采用端到端免 NMS 架构,移除 DFL 模块,CPU 推理速度较前代提升 43%;搭配 MuSGD 优化器与 ProgLoss+STAL 损失策略,强化小目标检测能力,支持检测、分割、姿势估计等多任务,可无缝适配树莓派、嵌入式设备等终端,广泛应用于智慧农业、安防监控等领域。YOLO各版本性能对比:
数据集准备与训练
本文主要基于YOLO26n模型进行模型训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。
1. 数据集准备与训练
通过网络上搜集关于实际场景中果园荔枝的相关图片,并使用Labelimg标注工具对每张图片进行标注,分1个检测类别:['荔枝']。
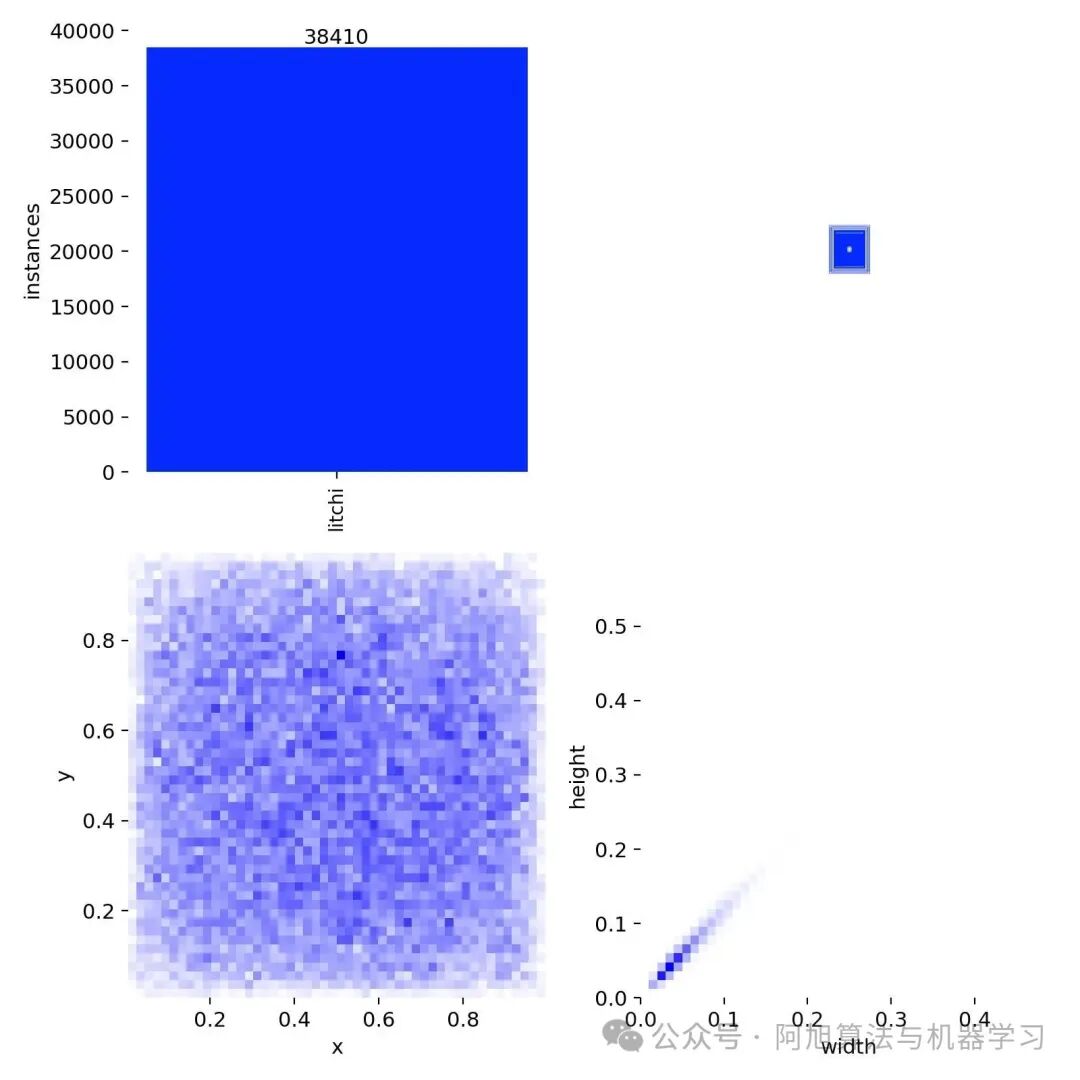
**最终数据集一共包含2163张图片,其中训练集包含1731张图片,验证集包含216张图片,测试集包含216张图片。**部分图像及标注如下图所示:


数据集各类别数目分布情况如下:
2.模型训练
准备好数据集后,将图片数据以如下格式放置在项目目录中。在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。
同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLO在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: E:\MyCVProgram\litchiDetection_26\datasets\train/images
val: E:\MyCVProgram\litchiDetection_26\datasets\valid/images
test: E:\MyCVProgram\litchiDetection_26\datasets\test/images
nc: 1
names: ['litchi']注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,optimizer设定的优化器为SGD,训练代码如下:
#coding:utf-8
from ultralytics import YOLO
import matplotlib
matplotlib.use('TkAgg')
# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/26/yolo26.yaml"
#数据集配置文件
data_yaml_path = r'datasets/data.yaml'
#预训练模型
pre_model_name = 'yolo26n.pt'
if __name__ == '__main__':
#加载预训练模型
model = YOLO(model_yaml_path).load(pre_model_name)
#训练模型
results = model.train(data=data_yaml_path,
epochs=150,
batch=32,
name='train_26')模型常用训练超参数参数说明: YOLO26 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。以下是一些常用的模型训练参数和说明:

在这里插入图片描述
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLO26在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

各损失函数作用说明: 定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。本文训练结果如下:
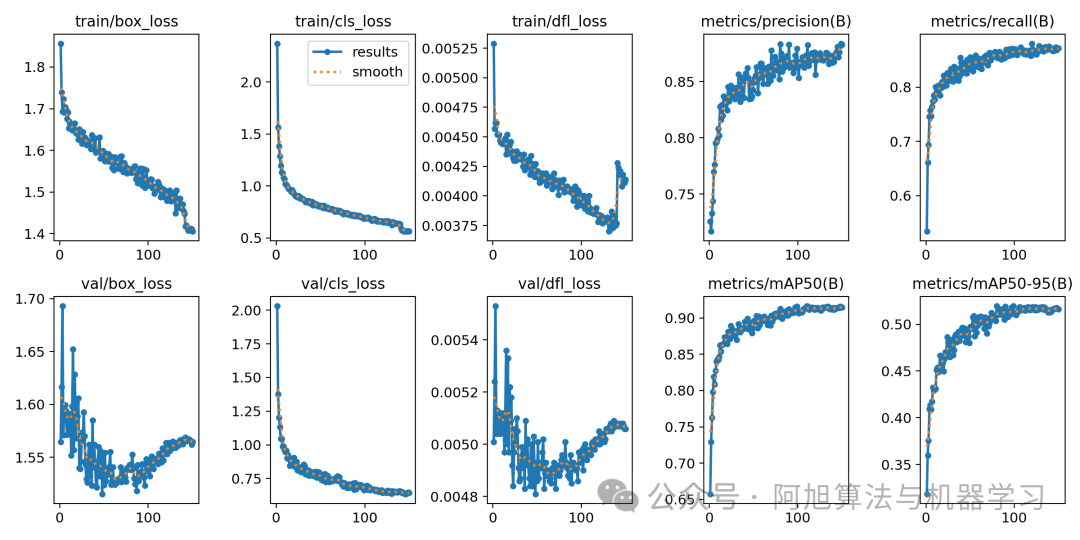
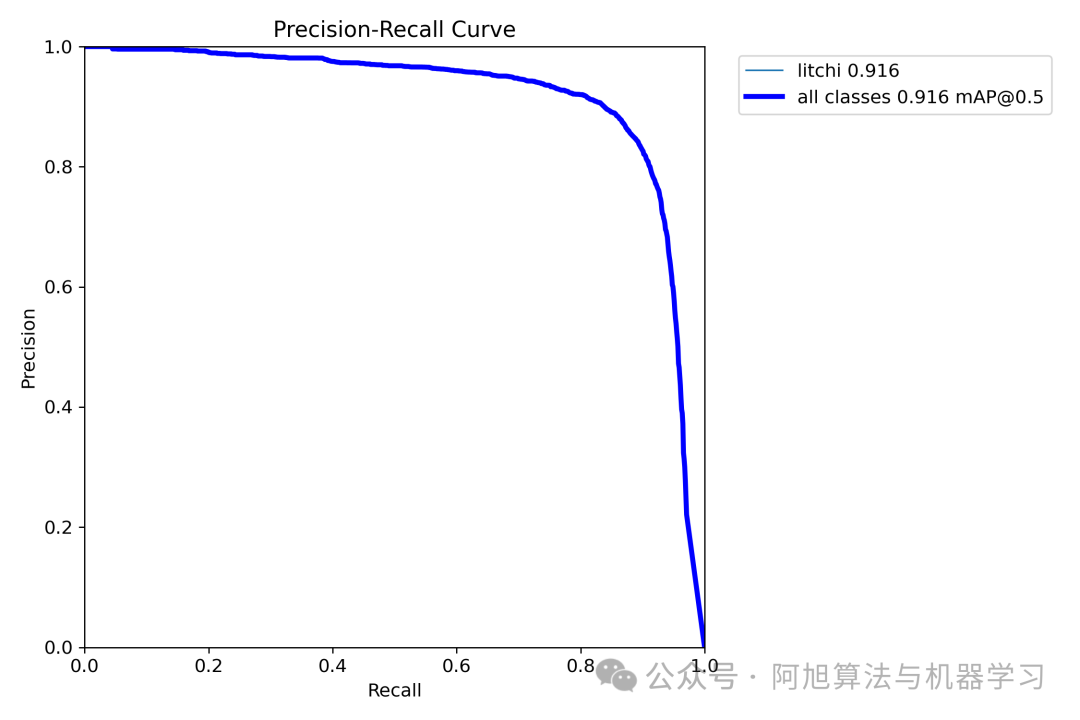
我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5值为0.916,结果还是十分不错的。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

4. 使用模型进行推理
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。 图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/000022_jpg.rf.55d8a76753bd8cb1ad40abc1d16ca838.jpg"
# 加载预训练模型
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
print(results)
res = results[0].plot()
res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("Detection Result", res)
cv2.waitKey(0)执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

更多检测结果示例如下:

四、可视化系统制作
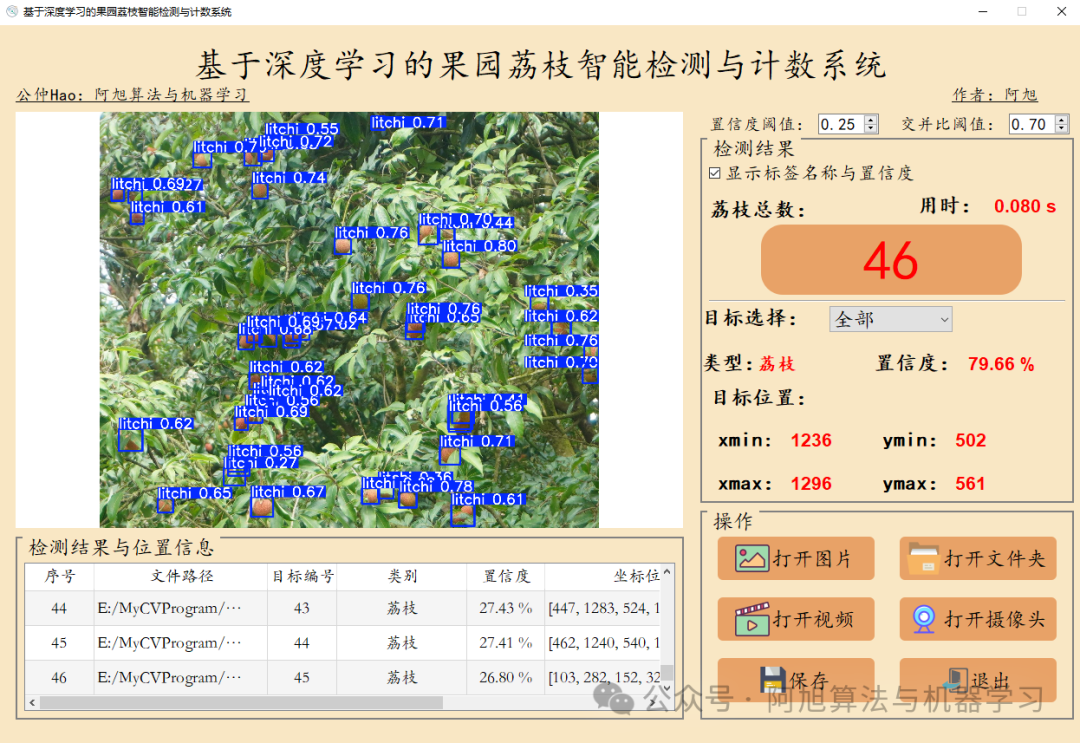
基于上述训练出的目标检测模型,为了给此检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。博主基于Pyqt5开发了一个可视化的系统界面,通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。【系统详细展示见第一部分内容】
Pyqt5详细介绍
关于Pyqt5的详细介绍可以参考之前的博客文章:《Python中的Pyqt5详细介绍:基本机构、部件、布局管理、信号与槽、跨平台》,地址:
❝
系统制作
博主基于Pyqt5框架开发了此款果园荔枝检测与计数系统,即文中第一部分的演示内容 ,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。这不仅提升了系统的可用性和用户体验,还使得检测过程更加直观透明,便于结果的实时观察和分析。此外,GUI还可以集成其他功能,如检测结果的保存与导出、检测参数的调整,从而为用户提供一个全面、综合的检测工作环境,促进智能检测技术的广泛应用。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、训练好的模型、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可
