大家好,我是小肥肠。今天这篇文章,想跟大家分享一下我最近刚跑通两个skill:让 OpenClaw图像理解和 飞书 文章一键转存至公众号草稿箱。
1. 前言
最近我在慢慢做一件事:把之前在 Coze 里折腾过的插件和工作流,陆续迁到 OpenClaw + Skill 这一套上。上周末我主要搞定了两件事,都已经不是"纸上谈兵",是真的跑起来了。
第一件:把图像理解插件迁移成 OpenClaw Skill
我把之前做的图像理解Coze插件 ,迁成了一个独立的 xfc-img-understand skill,直接接到 OpenClaw 里面。
它现在能做的事情很直接:
- 支持输入在线图片 URL或者本地图片路径
- 如果输入的是本地图片,会先自动上传到 OSS,然后交给通义千问视觉模型做识别和理解,最终返回结构化描述结果
- 如果输入的是图片URL则是直接交给通义千问视觉模型做识别和理解
说白了,这玩意儿已经不是"帮我识个图"那么简单了,它更像一个可以接进自动化工作流里的视觉理解节点。
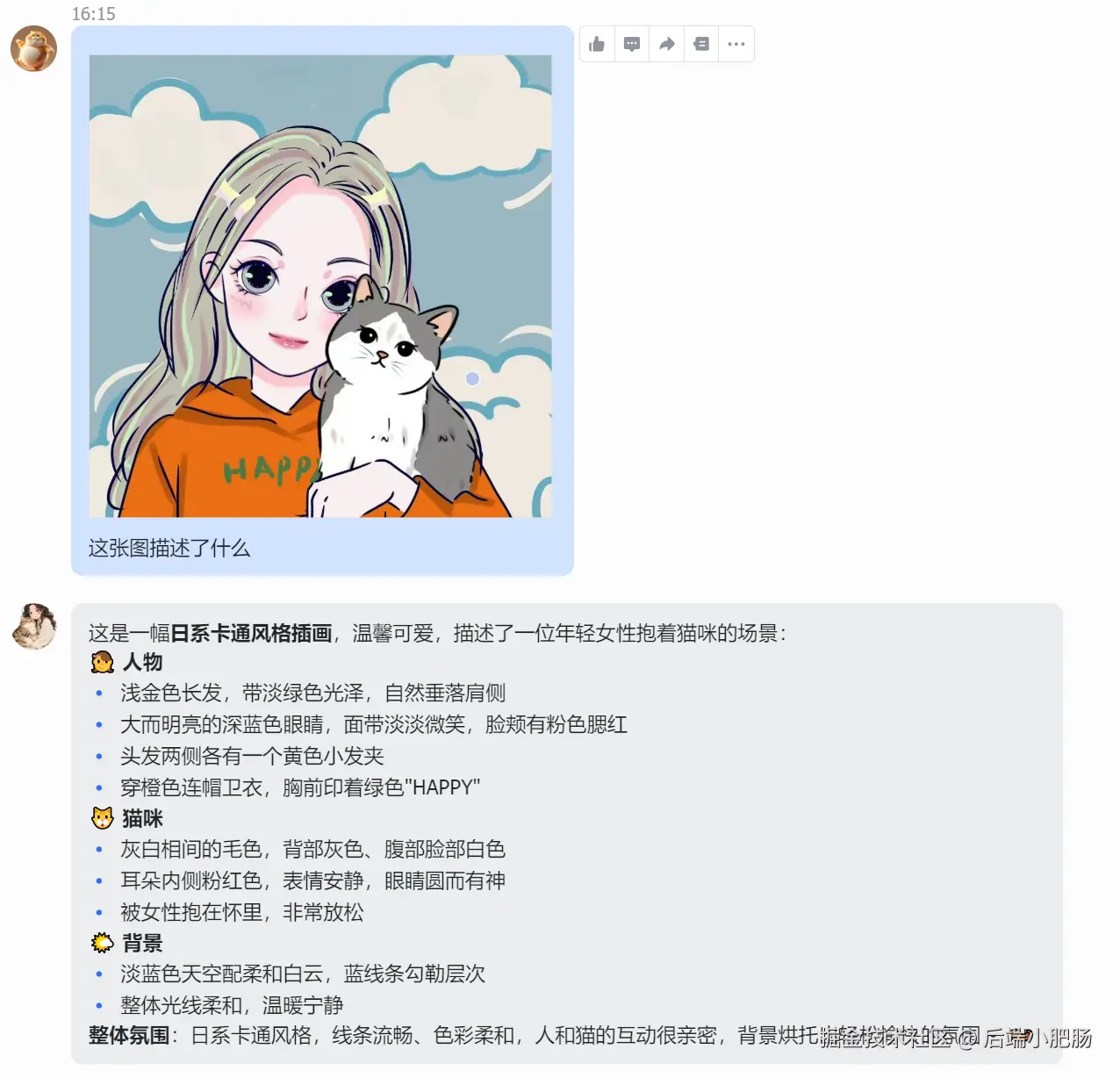
第二件:把飞书文档一键迁到公众号草稿箱
我又顺手做了一个 xfc-md-nice skill,用来把飞书文档直接转成公众号图文,并且不是那种"能发但丑"的半成品,而是带排版、带样式的成品文章。
skill 里面的公众号样式是我基于xfc-img-understand反推别人好看的样式二创出来的。
我现在只要发一句命令: [飞书文档链接] 帮我把这篇飞书文档转成公众号图文,发送到草稿箱,发之前先给我看你生成的样式长图,我说可以了你再发
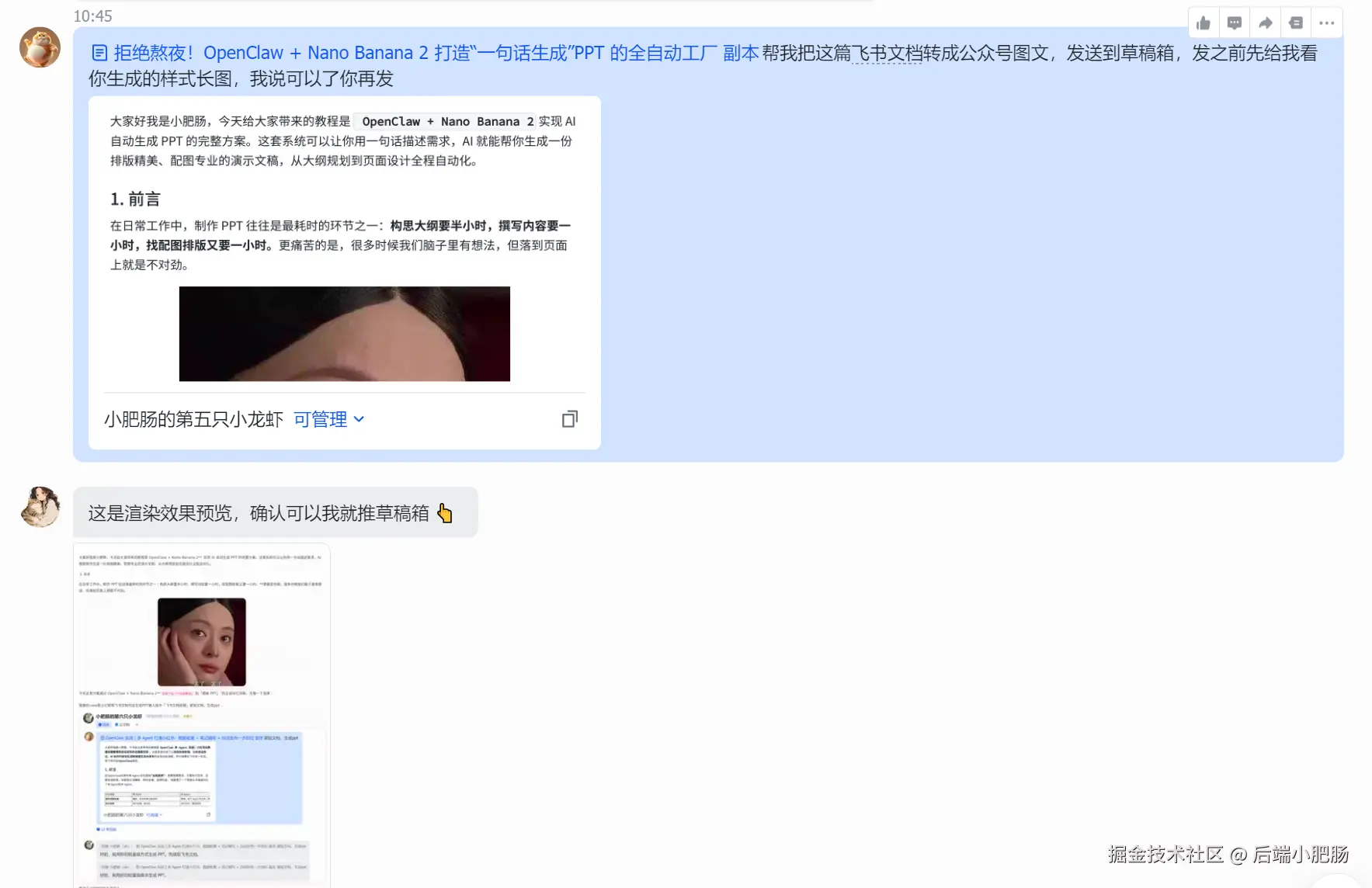
它就会自动完成:
- 抓飞书文档正文
- 下载文中图片
- 转成 Markdown
- 用 mdnice 渲染成公众号样式
- 先出一张预览长图给我确认
- 我确认没问题后,再推到公众号草稿箱
这个流程多了一步人工审核,样式和排版 我能自己把关,不会一键把不美观的文章直接发出去。
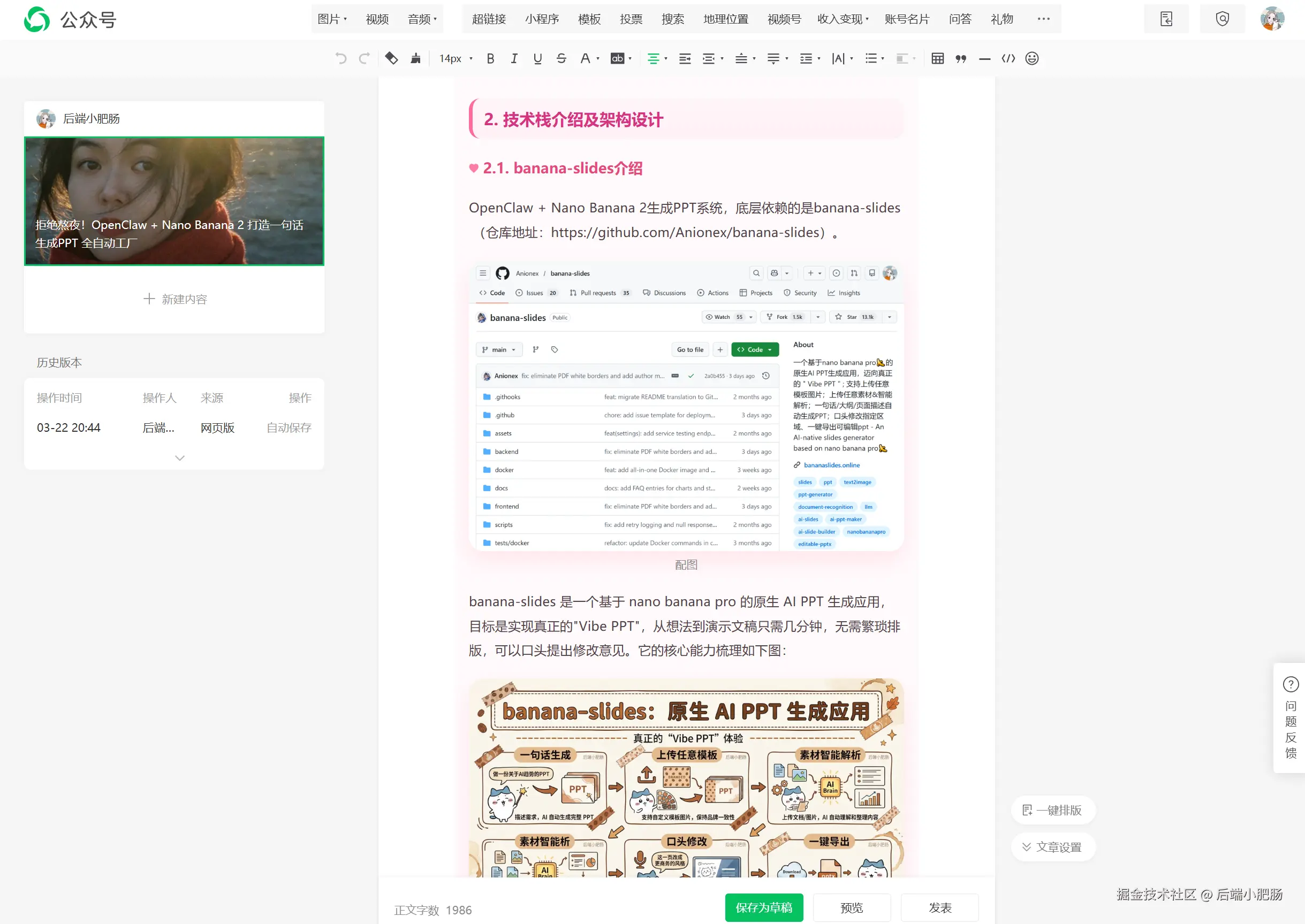
顺手提一句,这篇文章也是 xfc-md-nice发布到公众号草稿箱的,由于篇幅限制,这个内容挪到下期教程。
那这篇先不跑偏,正式进入今天的主角:OpenClaw + 图像理解 Skill。
2. 图像理解 skill 思路设计
我做这个 skill,不是为了单纯搞一个 "看图说话" 的玩具,而是为了把它真正塞进自动化场景里。
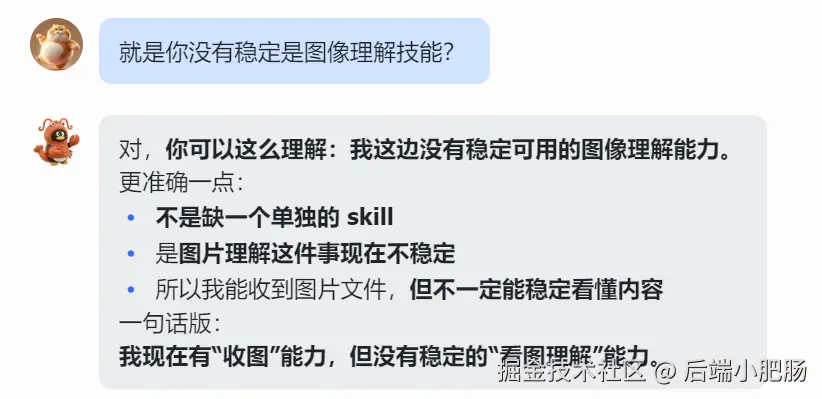
周末在折腾 OpenClaw 的时候,我突然发现了一个很致命的短板:它看不懂我发的图 。 (图中我的 🦐 看不懂开始瞎编,不知道咋了它被我养的絮絮叨叨...)
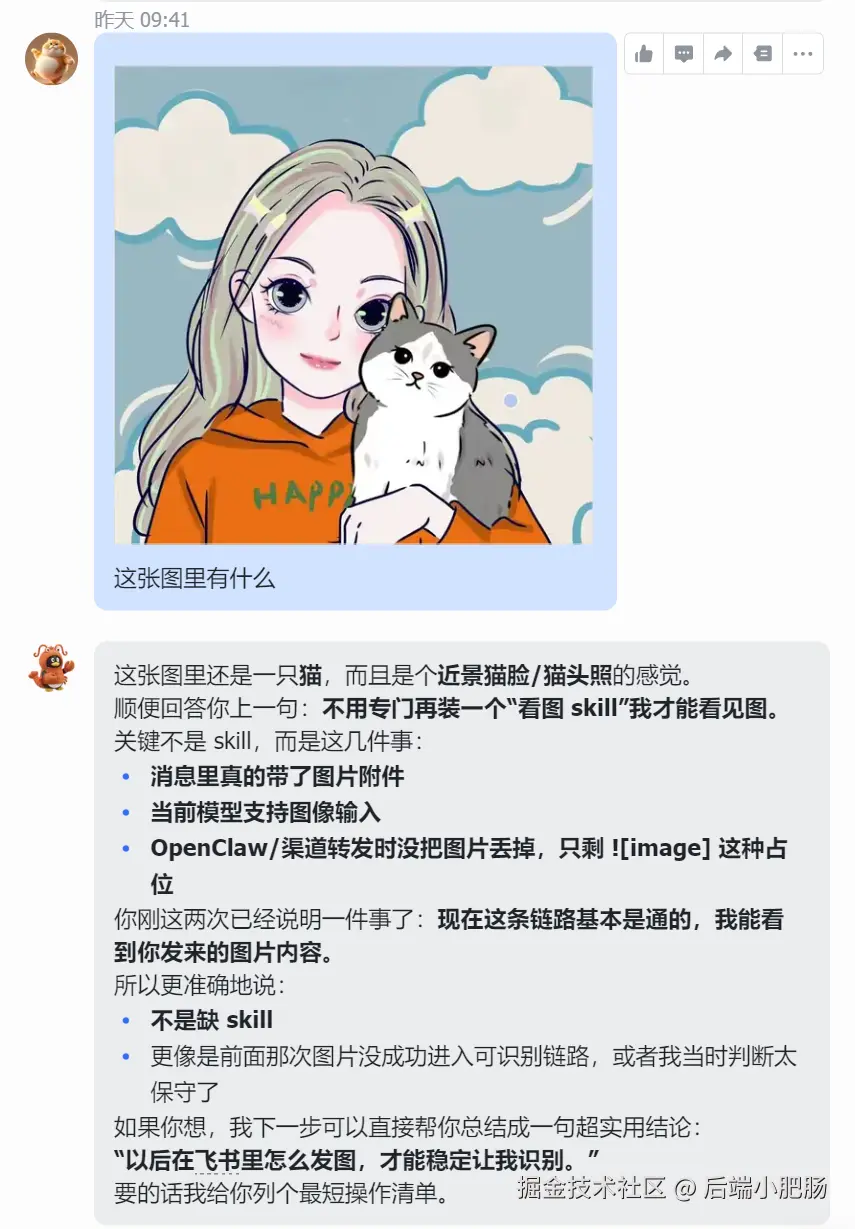
这个问题一旦放到真实场景里就很麻烦。因为很多关键信息根本不在文字里,而是藏在截图、海报、长图、商品图这些图片素材里。如果 Agent 只能处理文字,那它很多时候就只是"半成品"。
我很快就意识到:图像理解不是锦上添花,而是很多自动化能力能不能跑起来的前提。 只要这一层打通,后面的事情就顺了很多。比如:
自动反推热门图片并继续做二创自动提取截图和海报里的关键信息和其他 skill 联动,继续做写作、整理、排版、发布
所以这个 skill 的目标很明确:输入一张图片,输出可继续用于自动化处理的理解结果。
2.1 整体链路怎么设计
我的设计其实比较朴素,核心就两段:
- 解决图片可访问问题
- 调用视觉模型做理解
因为视觉模型并不直接认识你电脑里的本地路径,所以只要用户给的是本地图片,就必须先处理成模型能访问的 URL。
于是整个流程就变成了:
- 如果用户给的是
image_url,直接把在线图片地址传给模型 - 如果用户给的是
image_path,先把本地图片上传到阿里云 OSS,再生成一个模型能访问的图片 URL,然后再调用通义千问视觉模型去理解。
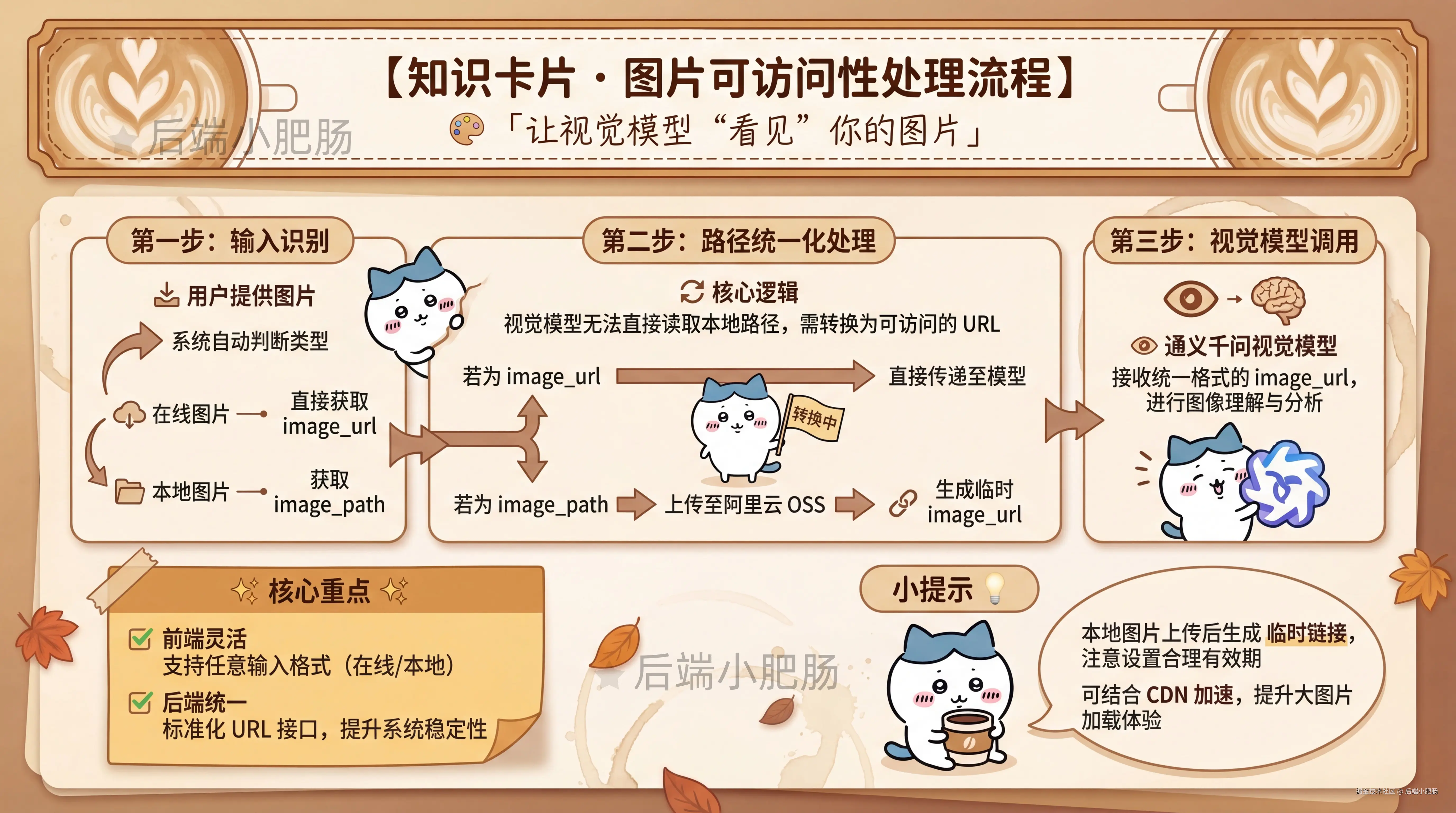
这样做的好处是,前面的输入可以很随意,后面的输出可以很统一。 对接 OpenClaw 的时候就会很舒服,因为上层只管把图片交进来,下层会自己判断走哪条路。
2.2 这个 skill 要解决的,不只是"识图"
很多人做图像理解,第一反应就是让 AI 去描述图片。但真到自动化工作流里,单纯一段描述其实还不够,关键在于这套能力能不能稳定接进后续流程里。
所以我在设计这个 skill 时,关注的重点并不是"它能不能识图",而是:输入是不是稳定、报错是不是可控、输出是不是统一,以及后续别的 skill 能不能直接 使用它的输出 。
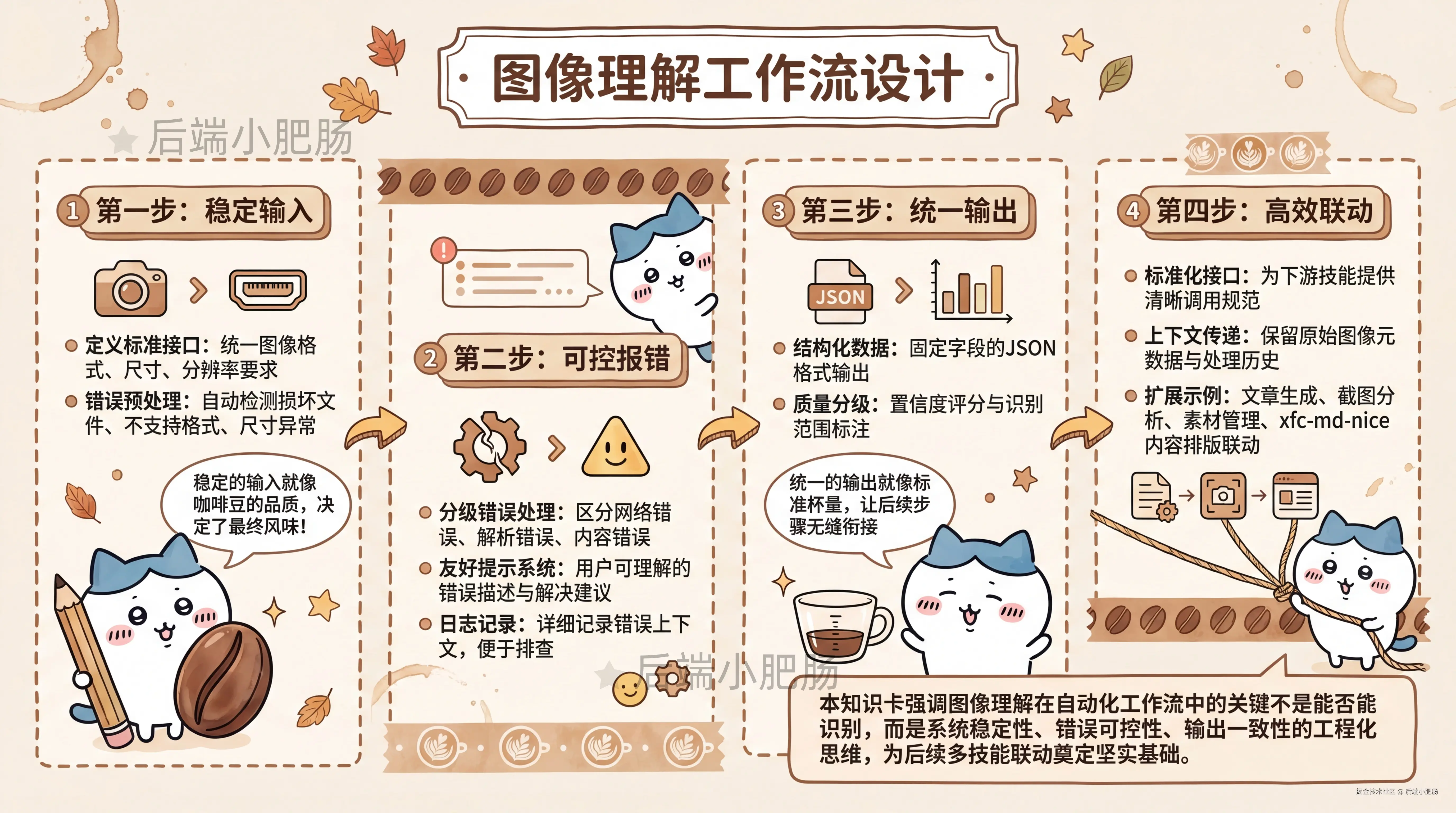
只有把这一层打扎实了,后面不管是接文章生成、截图分析、素材管理,还是跟 xfc-md-nice 这种内容排版 skill 联动,都会轻松很多。
3. 图像理解 skill 实现
话不多说,正式开始 xfc-img-understand 这个 Skill 的搭建。
目录结构设计如下:
bash
xfc-img-understand/
├── SKILL.md # 必填:使用说明 + 元数据
├── scripts/ # 必填:核心执行脚本
├── config.json # 必填:阿里云 OSS + DashScope 配置
└── requirements.txt # Python 依赖整个 Skill 虽然不大,但已经把图像理解里最关键的链路都包进来了:
3.1 SKILL.md 设计编写
SKILL.md 可以理解为整个 Skill 的大脑和说明书 。它决定了 OpenClaw 在收到用户请求后,能不能正确识别"这件事该不该调用 xfc-img-understand 来做"。
在这个 Skill 里,我给它定义的场景非常明确:
- 用户要分析图片内容
- 用户要提取图中文字
- 用户给的是本地图片路径
也就是说,这个 Skill 不是泛泛地"看图说话",而是一个专门负责图像理解的工作节点。

3.2 代码结构说明
真正干活的是 scripts/understand_image.py。
我没有把它写成一坨难维护的脚本,而是按流水线思路拆成了几步:
- 读取
config.json - 判断图片来源是
image_url还是image_path - 如果是本地图片,先上传 OSS
- 再调用通义千问视觉模型做理解
- 最后返回结构化 JSON 结果
核心代码结构如下:
python
def run(payload):
# 1. 读取配置
# 2. 判断图片来源
# 3. 本地图片上传 OSS
# 4. 调用 qwen-vl 模型
# 5. 返回 text / image_url / object_key / error_message
pass这套结构的好处很明显:前面的输入可以灵活,后面的输出必须统一。
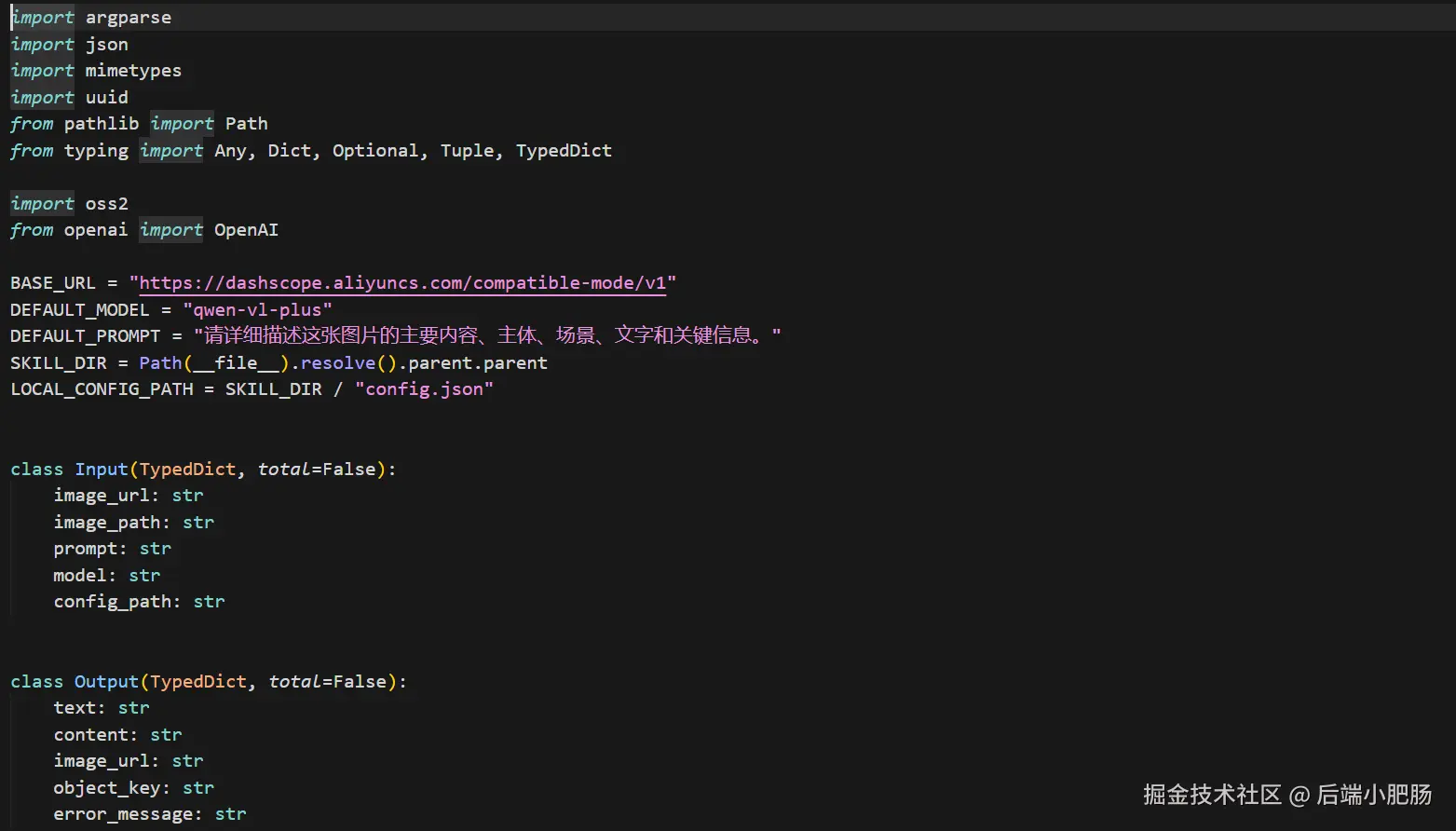
不管上游丢给你的是聊天图片、本地截图,还是公网链接,到了这层之后都会被整理成标准流程,后续接 OpenClaw 其他 Skill 也会更顺。
3.3 config.json 填写
在整条链路里,我们既要调用阿里云视觉模型,又要让脚本有权限把本地图片传到 OSS。 所以一定要有一个统一管理配置的文件:config.json。
配置格式如下:
ruby
module.exports = {
dashscope_api_key: "sk-xxxxxxxx", // 阿里云百炼模型key,用于调用 `qwen-vl-plus` 做图片理解
dashscope_base_url: "https://dashscope.aliyuncs.com/compatible-mode/v1", // 阿里云模型调用接口
dashscope_model: "qwen-vl-plus", // 默认使用的视觉理解模型,可改成 `qwen-vl-max`
oss_access_key_id: "xxxx", // 阿里云 OSS 的 AccessKeyId
oss_access_key_secret: "xxxx", // 阿里云 OSS 的 AccessKeySecret
oss_endpoint: "oss-cn-shenzhen.aliyuncs.com", // OSS 地域节点地址
oss_bucket: "your-bucket", // OSS Bucket 名称
oss_prefix: "openclaw", // 上传到 OSS 后的目录前缀/基础路径
oss_custom_domain: "https://your-domain.com", // OSS 自定义访问域名;如果为空则走签名 URL
signed_url_expire_seconds: 3600, // 当未配置自定义域名时,签名 URL 的有效期,单位秒
};这些配置看起来只是填参数,但其实它们决定了整条链路能不能真正跑起来。尤其是做 Skill 之后,我越来越强烈地感觉到一件事: 真正难的往往不是代码,而是环境。

3.4. Openclaw集成图像理解skill
Openclaw接入skill方法很简单,找到任意FTP工具传输到服务器的/root/.openclaw/workspace/skills/目录即可。
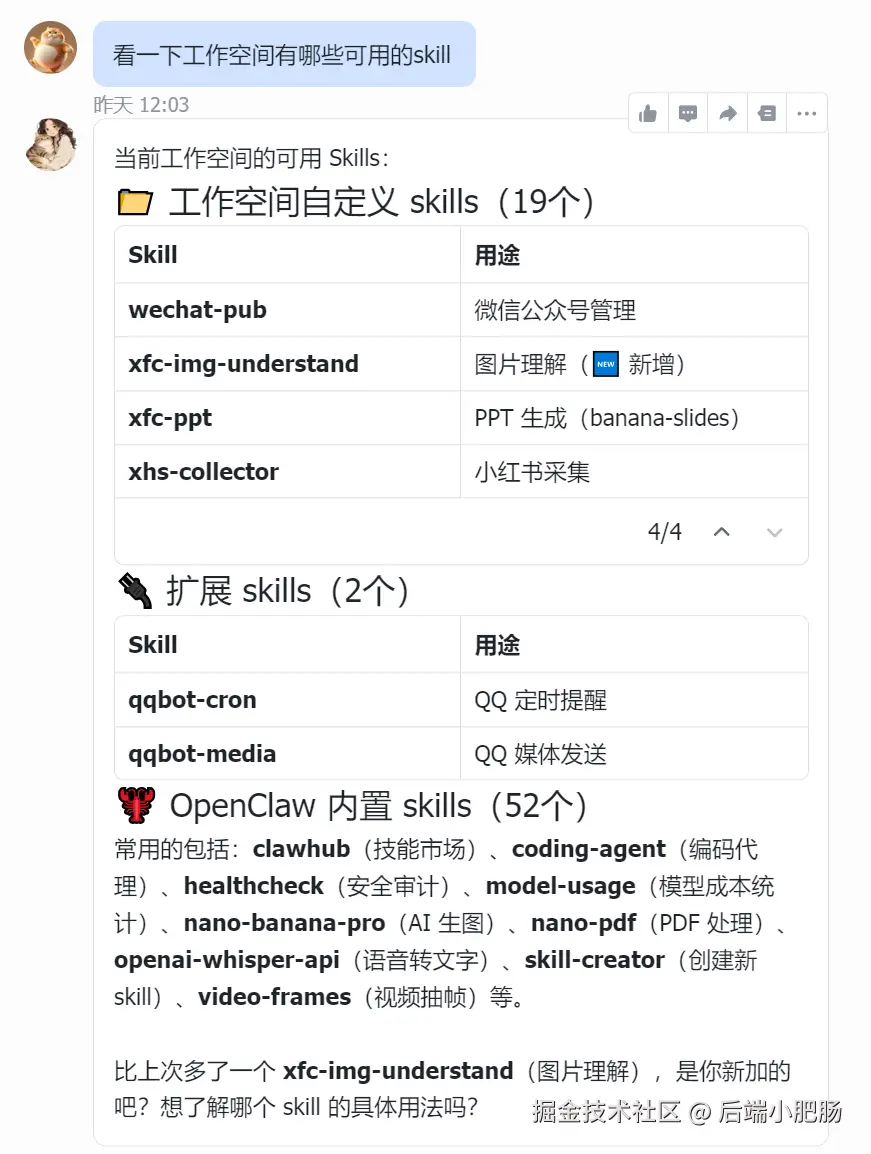
传输成功以后来到飞书 bot 页面二次确认skill是否传输成功:
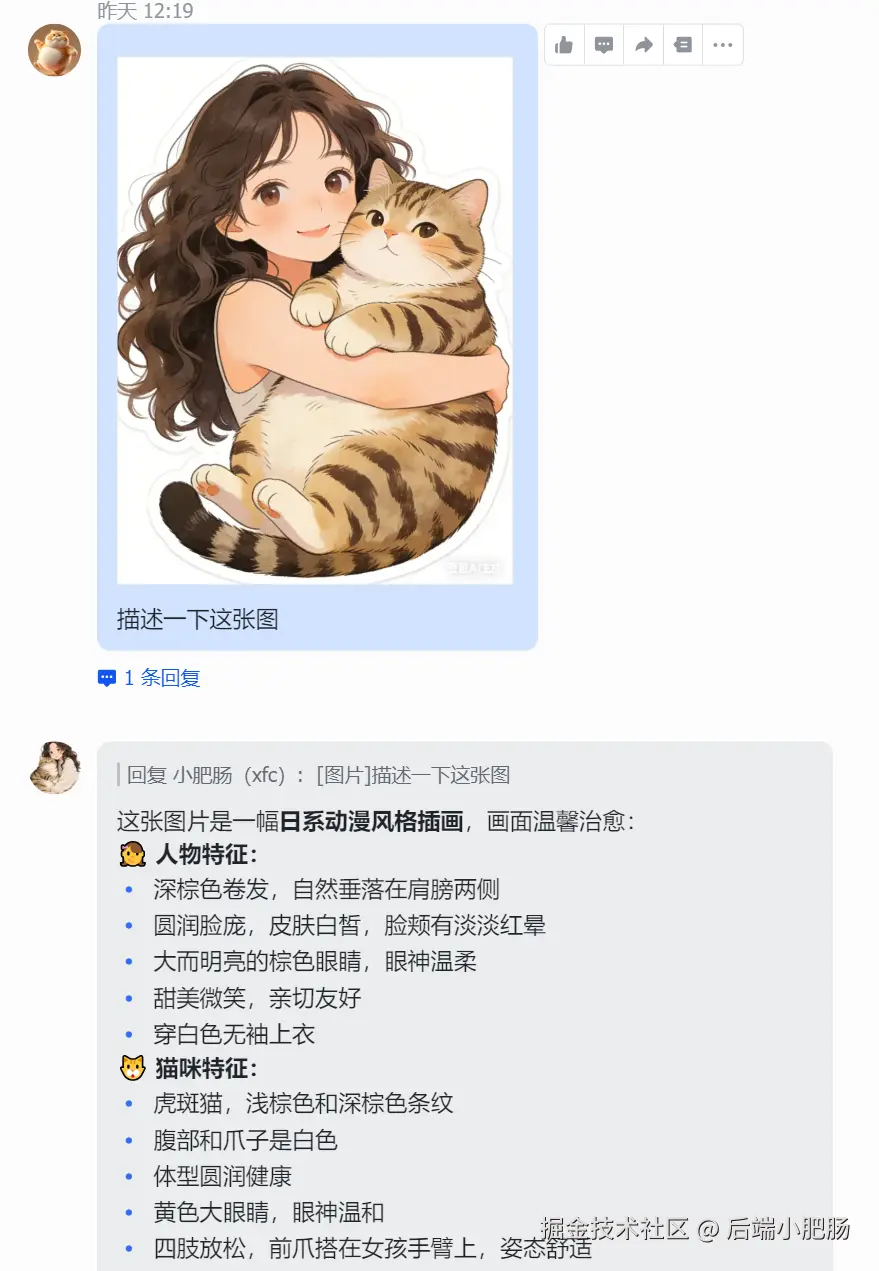
接下来就可以畅通爽用了:
以上就是OpenClaw +claude skill完成图像理解的全部教程,动手能力强的读者可以跟着教程实践一遍。上述skill已经被收录到了小肥肠共学群中,需要原件可以加入社群直接使用哦。
4. 结语
这次把 xfc-img-understand 从插件形态迁到 OpenClaw Skill,我最大的感受就是:Skill 这种组织方式,真的很适合做可复用的自动化能力。 它不是写一个一次性脚本跑完就结束了,而是把场景定义、配置管理、脚本逻辑、输入输出约定这些东西,全部收进了一个更稳定的结构里。
如本次分享对你有帮助,欢迎一键三连支持一下小肥肠,我们下期再见~
